The post Use Parallel Analysis – Not Parallel Query – for Fast Data Access and Scalable Computing Power appeared first on ScaleOut Software.
]]>To help ensure fast data access and scalability, IMDGs usually employ a straightforward key/value storage model. This model works well for storing large, object-oriented collections of business-logic state, such as the examples listed above. Each object is stored in the grid as a serialized version of the application’s in-memory counterpart and is accessed with a unique key defined within a namespace (as shown in the diagram below). (Namespaces typically hold objects of a single, language-defined type.) In contrast to relational, graph-oriented, and other more complex storage models, key/value stores usually deliver faster data access because key lookups can be quickly completed with low overhead.
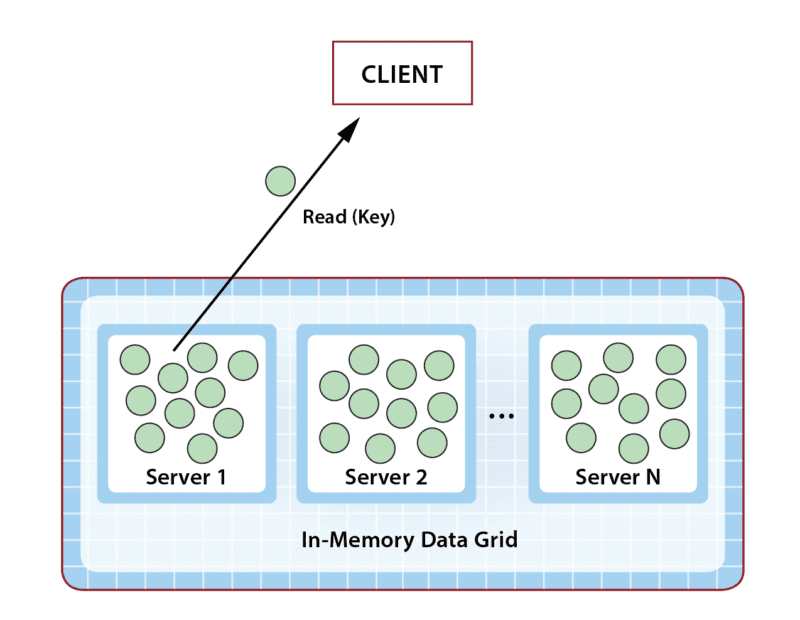
Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database. For example, it can be used to host short-lived business logic state used to prepare transactions. Offloading the database boosts performance, reduces bottlenecks, and lowers costs.
When used as a cache, developers often view an IMDG with a database mindset and access grid data using traditional, database-oriented techniques, such as SQL query, instead of key-based lookup. For example, an object describing a customer might be retrieved by querying the customer’s last name instead of performing a key-based lookup of the customer’s unique account number. That’s where performance problems can begin.
When used in an IMDG, a typical query seeks to access a set of objects matching specific properties. Just as a relational database queries a table by attributes, an IMDG queries a distributed, in-memory, object collection by matching class-based properties. In both cases, many results may match a query and be returned to the requesting client. When used sparingly, IMDG queries work quite well. However, when applications rely on query as the primary access model, access throughput can be seriously degraded, and overall application performance can suffer in two ways.
First, unlike key-based access, which is directed to a specific grid server to retrieve an object, a query requires the participation of all grid servers. This enables the IMDG to find all matching objects, which potentially reside on multiple servers within the distributed store. So the overhead to perform a query requires O(N) overhead on a cluster of N grid servers, while a key lookup only requires O(1) overhead. Since an IMDG typically has many clients simultaneously making access requests, the combined overhead for many parallel queries can quickly grow. For this reason, query should be avoided when a key lookup will suffice.
A bigger problem with query is that when it matches many results, a large amount of data may need to be returned over the network to the requesting client for processing, as illustrated below. This can quickly saturate the network (and bog down the client). When you consider that an IMDG can easily host terabytes of data distributed across several servers, it’s not surprising to see a single query return 10s of megabytes (MB) of results. A gigabit network can only move about a peak of 128MB/sec (although delays can start increasing at about half that), so large queries can (and often do) overload the network. And after a query returns the requested objects to the client for processing, the client must then wade through them all, potentially creating another bottleneck on the client.
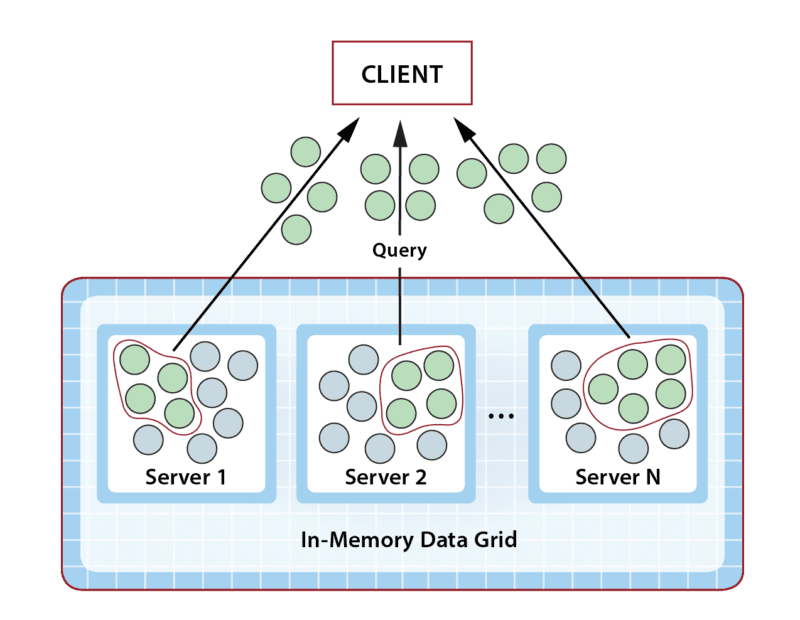
What’s interesting about this dilemma is that the IMDG’s apparent weakness is actually its key strength. It’s all in how the application looks at the problem to be solved. Instead of querying the grid, what if we just moved this work from the client into the grid and performed it there? This would enable the application to avoid bottlenecks and harness the IMDG’s scalable computing power to boost performance.
The technique is called data-parallel computing, and many IMDGs (like ScaleOut StateServer Pro®) provide APIs that make it easy to use in languages like Java, C#, and C++. In its simplest form, the application ships off a class-defined method (call it “Eval”) to execute in the grid along with a query specification, and the IMDG distributes the work across all of its servers, querying each server locally and then running the application’s method on the selected objects. The application optionally can define a second method (call it “Merge”) to combine the results and return them back to the client. Running a method in the grid can be compared to executing a stored procedure in a database. The following diagram illustrates this concept:
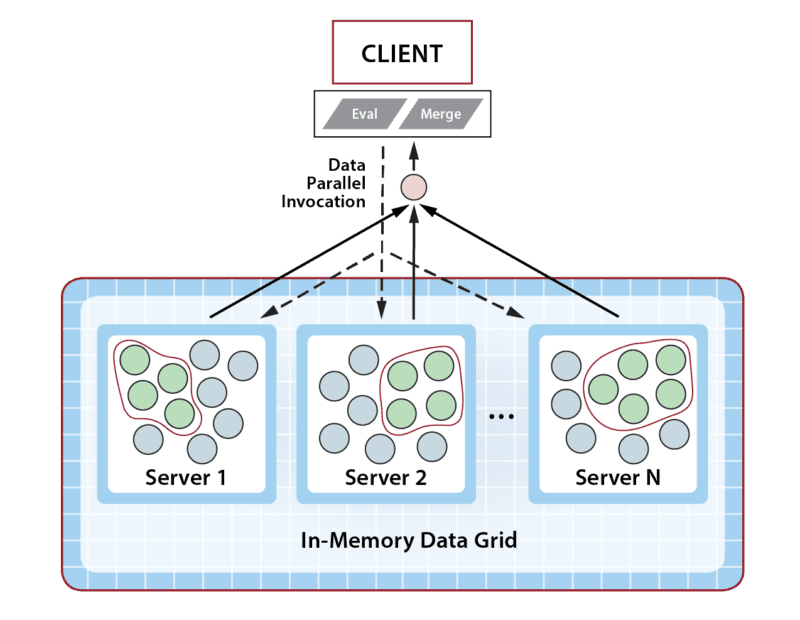
Using data-parallel computing instead of parallel query gives an application two big wins. First, moving the code to the data dramatically reduces the amount of data transferred over the network since the results of the computation are usually dramatically smaller than the size of the original query results. Second, the grid’s scalable computing power reduces execution time while avoiding a bottleneck in the client. This scales the application’s throughput as the size of the workload increases.
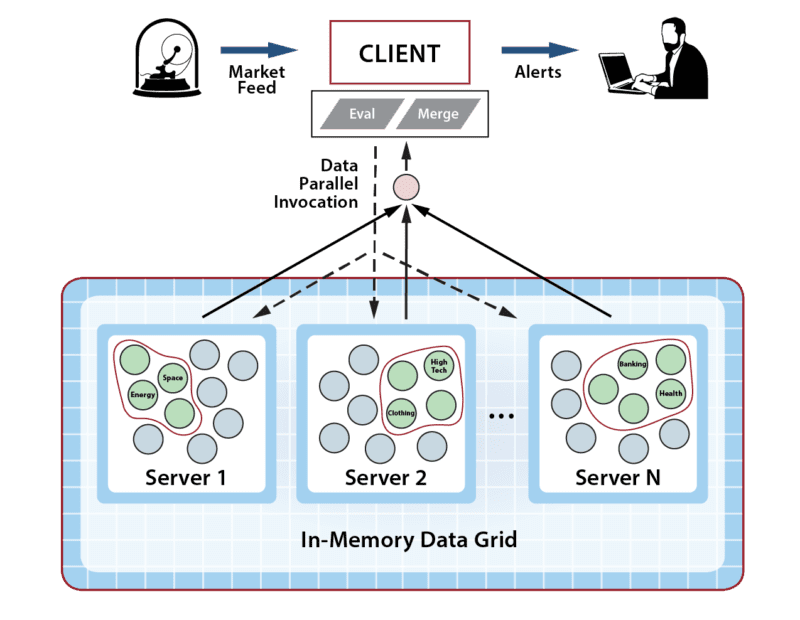
We have seen this computing model’s utility in countless applications. Consider, for example, a hedge fund storing portfolios of stocks in an IMDG as objects, where each portfolio tracks a given market sector (high tech, energy, healthcare, etc.). When the stock exchange’s ticker feed updates a stock price, the hedge fund needs to evaluate all corresponding portfolios to see if rebalancing is needed. The obvious way to implement this is to query the grid for all portfolios containing the updated stock and then analyze them in the client. However, this requires large amounts of data to cross the network and creates lots of work for the client. Instead, the client can simply kick off a data-parallel computation in the grid on all portfolios that contain the stock and let the grid perform this work quickly (and scalably). Using this technique, a hedge fund was able to see the time for rebalancing drop from several minutes to less than half a second.
Although it often masquerades as a distributed cache, an IMDG actually is a scalable, in-memory computing platform – not that different from a parallel supercomputer running on commodity hardware. With a small change in mindset, developers easily can harness its computing power to eliminate bottlenecks and reap big dividends in performance.
The post Use Parallel Analysis – Not Parallel Query – for Fast Data Access and Scalable Computing Power appeared first on ScaleOut Software.
]]>