The post How Do In-Memory Data Grids Differ from Storm? appeared first on ScaleOut Software.
]]>Quick Review: IMDGs Provide Fast Data Storage
(The following description of in-memory data grids (IMDGs) is excerpted from last week’s blog post; see that post for more details.)
IMDGs host data in memory and distribute it across a cluster of commodity servers. Using an object-oriented data storage model, they provide APIs for updating data objects typically in well under a millisecond (depending on the size of the object). This enables operational systems to use IMDGs for storing, accessing, and updating fast-changing, “live” data, while maintaining fast access times even as the storage workload grows.
Data storage needs can easily grow as more users store data within an IMDG. IMDGs accommodate this growth by adding servers to the cluster and automatically rebalancing stored data across the servers. This ensures that both capacity and throughput scale linearly with growth in the workload, and access and update times remain low regardless of the workload’s size. Moreover, IMDGs maintain stored data with high availability using data replication so that if a server fails, operational systems can continuously handle access requests and update requests without delay.
IMDGs Perform Data-Parallel Computation
Because IMDGs store data in memory distributed across a cluster of servers, they easily can perform data-parallel computations on stored data; they simply make use of the cluster’s processing power to analyze data “in place,” that is, without the need to migrate it to other servers. This enables IMDGs to provide fast results (often in milliseconds) with minimal overhead.
The following diagram of the architecture used by ScaleOut Analytics Server and ScaleOut hServer shows a stream of incoming changes which are applied to the grid’s memory-based data store using API updates. The real-time analytics engine performs data parallel computation on stored data, combines the results across the cluster, and outputs a combined stream of alerts to the operational system.
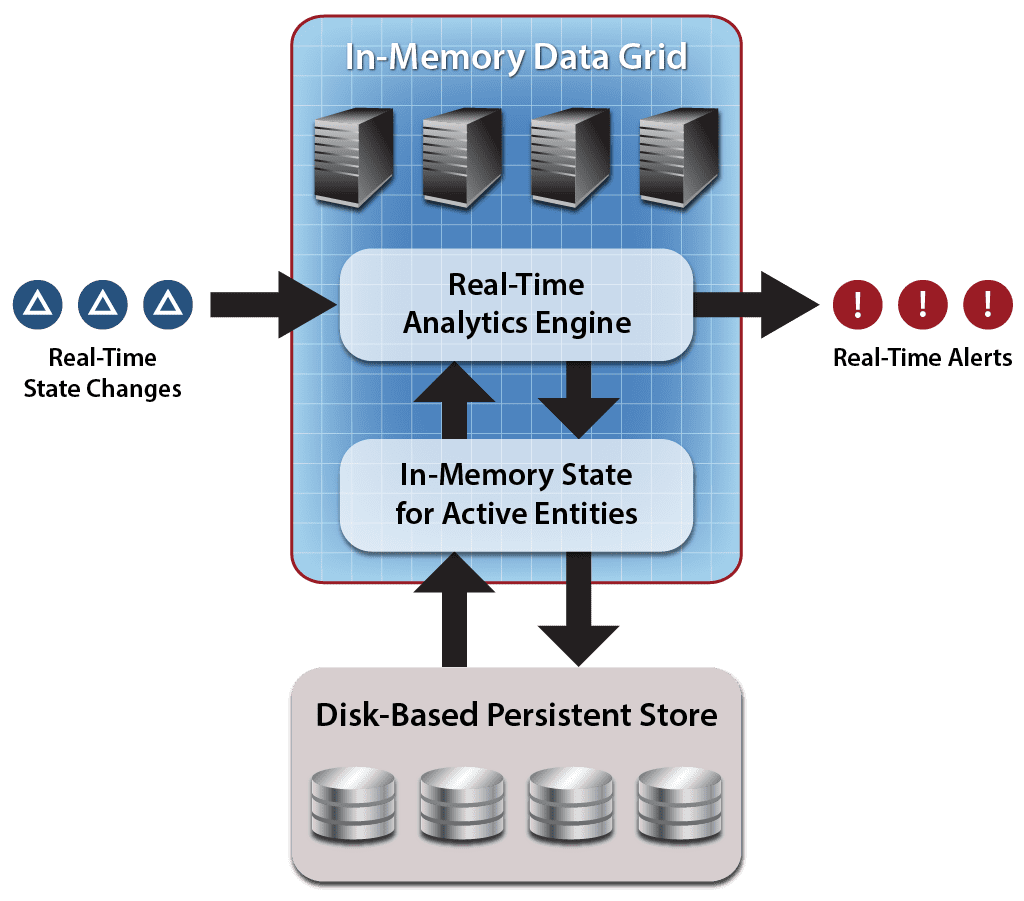
A significant aspect of the IMDG’s architecture for data analytics is that it performs computations on data hosted in memory – not specifically on an incoming data stream. This memory-based storage is continuously updated by an incoming data stream, so the computation has access to the latest changes to the data. However, the computation also has access to the history of changes manifested by the current state of data stored in the grid. This gives the computation a rich data set for analysis that includes both the incoming data stream and the application’s persistent state.
What is Storm?
Storm originally was developed by Nathan Marz at Backtype to overcome the limitations of Hadoop in analyzing streams of incoming data, such as Twitter streams and web log files. Its goal was to provide real-time, continuous computation that is both scalable and fault tolerant. Described both as stream processing and event processing, its computation model incorporates a combination of task parallelism and pipelining. The developer describes two basic entities: “spouts,” which generate streams of data in the form of ordered tuples, and “bolts,” which process incoming streams and optionally generate outgoing streams for other bolts. Spouts and bolts are organized into an acyclic, directed graph to create an executable configuration. (See this slide deck, among many available, for a more detailed explanation.)
The following diagram illustrates a Storm configuration of streams and bolts processing a set of input streams and generating a set of output streams. The green circles represent tuples within an input stream, and the blue boxes represent bolts. Note that spouts which generate the input streams are not shown in the diagram. The orange circles represent an optional output data stream, which may be implemented by the bolts in an arbitrary manner (e.g., as API calls to an external agent instead of as a stream of tuples).
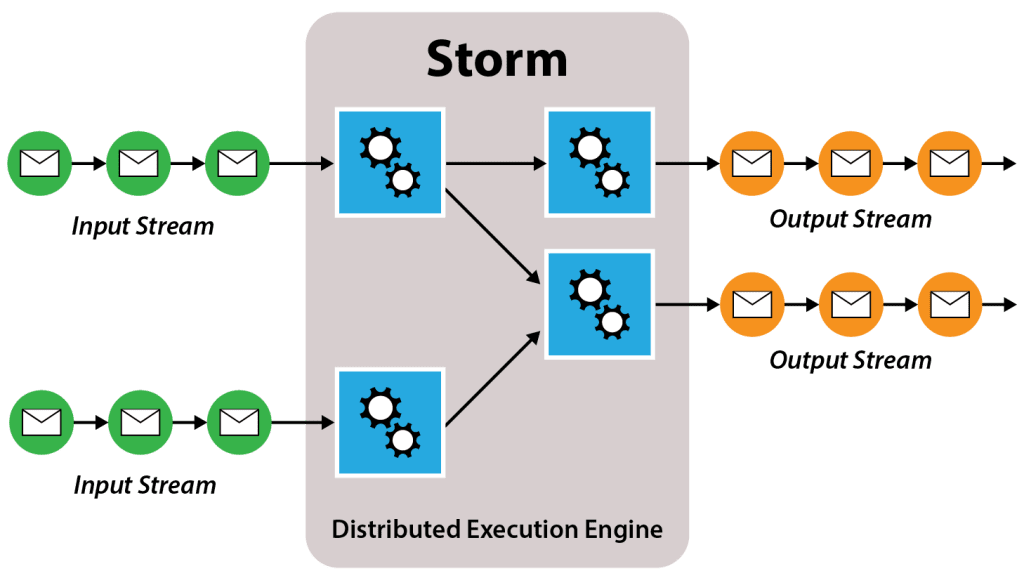
Application developers specify several aspects of the configuration, such as the number of tasks that can be spawned to execute each bolt, and the manner in which an incoming stream’s tuples are distributed across these tasks. Various groupings implement characteristics that correspond to behaviors found in Hadoop MapReduce. For example, the shuffle grouping implements a random distribution of tuples to tasks akin to input to mappers, and the field grouping implements a key-based partitioning very close to that used as input to reducers. Other groupings also are available, such as “all,” which is equivalent to multicast.
Storm implements and executes a specified configuration using a hierarchy of nodes whose state and fault-tolerance are maintained by the open-source Zookeeper cluster manager. A master node (called Nimbus) manages a set of worker nodes (called Supervisors), which run tasks. Strategies are available to handle failures of each of these components and to ensure that stream tuples are reliably processed.
Comparison of IMDGs to Storm: Providing Continuous Execution
A major strength of Storm is its continuous execution model. Once a configuration has been deployed, incoming data streams can be processed without scheduling delays, thereby providing uninterrupted, real-time results. This overcomes a major drawback of Hadoop MapReduce, which processes data in batch jobs with significant latency (often 15+ seconds) in starting up each job.
IMDGs approximate Storm’s continuous execution model in two ways. First they allow continuous, overlapped updates to in-memory state, enabling them to handle high arrival rates of incoming data (e.g., 1000s of updates per second for each IMDG server in a cluster). Both IMDGs and Storm scale out to increase throughput. Second, some IMDGs allow data-parallel operations to be performed continuously with very low startup delay (typically a few milliseconds). This allows IMDGs to output a stream of analysis results that matches the low latency required by operational systems. (Unlike Storm, IMDGs such as ScaleOut hServer also precisely match Hadoop’s MapReduce semantics, which require that reducers be able to process all key-value pairs emitted by the mappers in a given computation.)
Stateless versus Stateful Data Model
Storm’s data model describes a set of tuple streams. Bolts analyze and filter these streams, creating new streams to hold their results. While bolts are unconstrained in their ability to access and update external stores, such as IMDGs or file-based NoSQL stores (e.g., Mongo DB or Cassandra), this is not a central aspect of their processing model. Put another way, Storm does not provide any particular semantics for managing stateful data.
In contrast, IMDGs are organized around a stateful data model implemented by an object-oriented, in-memory store which is both scalable and highly available. This store is intended to hold ongoing, business-logic state implemented by collections of objects representing fast-changing data used in operational environments. In previous blog posts, we have seen examples in e-commerce (e.g., session-state and shopping carts) and financial services (e.g., portfolios and stock histories). Incoming data streams update these entities, which hold information that persists and evolves over their lifetimes. Making these entities “first class” citizens in the computation model simplifies the design of business logic while enabling stream processing using a combination of object-oriented updates and data-parallel computation to both modify and analyze this state.
Complexity of the Computation Model
Where IMDGs and Storm really differ is in their approaches to managing the complexity of the computation model. Like Microsoft Dryad and other parallel execution platforms with task precedence graphs, Storm defines a computation using a directed graph of execution nodes, each of which has a variable number of tasks. While the modular nature of an execution pipeline has appeal, its complexity can quickly become daunting. One reason for this is that the configuration’s graph is represented by sequential code describing bolts and the streams to which they are connected. As the number of bolts and streams grows, it becomes increasingly difficult to visualize their relationships and grasp the application’s overall behavior.
Other parallel systems like Storm with task precedence graphs, such as messaging passing systems and actor models, have demonstrated substantial complexity over the last few decades. Also, the Storm application developer must specify the number of tasks executed by each bolt. As the number of bolts and streams increase, it becomes challenging for the developer to manage the graph, predict the dynamics of its execution, and tune for best performance.
A central reason that IMDGs employ a data-parallel computation model is its simplicity, both in exposition and execution. (Another key reason is that data-parallel computation minimizes data motion which limits scalability. Storm’s data motion between bolts may incur more network overhead than IMDGs and impact scalability, but we have not evaluated this.) Since their application code is inherently straightforward, data-parallel programs are relatively easy to understand, and they don’t need extensive tuning for high performance. Also, separating updates to business logic state from data-parallel analytics simplifies integration into operational systems.
Summing Up
IMDGs offer a platform for scalable, memory-based storage and data-parallel computation which was specifically designed for use in operational systems. Because it incorporates API support for accessing and updating individual data objects and data-parallel analytics, IMDGs are easily integrated into the business logic of these systems.
Storm was designed for a different purpose, namely to analyze streams of data using a continuously running execution pipeline. Its more complex computation model fits this purpose well, and, as a result, Storm embodies a different set of tradeoffs than IMDGs. Clearly, the term “real-time analytics” encompasses a variety of solutions designed to meet diverse business requirements.
The post How Do In-Memory Data Grids Differ from Storm? appeared first on ScaleOut Software.
]]>The post What’s New in ScaleOut StateServer® Version 5.1 appeared first on ScaleOut Software.
]]>New C++ APIs
We introduced ScaleOut StateServer® almost exactly nine years ago and have worked continuously since then to add features requested by our customers and boost the product’s performance. Version 5.1 contains several exciting new capabilities, led by our introduction of C++ APIs. Our goal was to make these C++ APIs as easy to use as possible. So the first decision was to make them open source. This allows developers to build the APIs for a variety of compilers starting with GCC 4.4 (circa 2009) and newer. To strike a balance that allows support for the older compilers used on some enterprise-grade distributions of Linux, some newer C++11 features were not used, and the APIs use the widely-available Boost C++ libraries instead. (Releases of Boost going back to version 1.41 have been verified to work.) So, for example, rather than returning a std::shared_ptr to a retrieved object, the API returns a boost::shared_ptr. The C++ APIs are also available for Windows developers; we ship pre-built libraries for Visual Studio 2013 users in the release.
The next big challenge with the C++ APIs was how to handle data serialization, which is needed to store objects within an out-of-process, in-memory data grid (IMDG). We first introduced C# APIs in 2005, and then added Java APIs in 2008. Unlike C++, both of these languages have built-in serializers; ScaleOut StateServer uses these serializers by default to keep application development as simple for the user as possible. Looking at other IMDGs in the market, we did not want to go down the same path of requiring the use of serialization APIs provided by the IMDG vendor (us in this case). So we chose to offer integrated support for the popular Google Protocol Buffer encoding standard (with optional indexing of annotated fields to support parallel query) and also provide an extensible API mechanism that allows users to build custom serializers.
Replicating Data to the Cloud
With version 5.1, we also extended support for data replication and remote access to IMDGs hosted in public clouds using our ScaleOut GeoServer® product. This product lets users connect a local IMDG to one or more remote IMDGs so that data can be replicated off-site in case of a site-wide failure; it also allows transparent access to data stored at remote sites using the IMDG’s APIs for local data access. With this release, remote IMDGs hosted in Amazon Web Services or Windows Azure can be accessed by ScaleOut GeoServer (and by client applications) with full support for secure connections using SSL.
The challenge with accessing cloud-based IMDGs is that it is clumsy to bootstrap connectivity using IP addresses, as is standard practice for on-premise grids, since these IP addresses are highly dynamic. To solve this problem, we created a simple mechanism (first introduced in version 5.0 for remote clients) which binds clients and remote IMDGs to a cloud-hosted IMDG using a simple combination of account credentials and a “store” name. We then retrieve cloud-based metadata to automatically identify and configure the current IP addresses and ports for the client or remote IMDG. The net effect is that configuring ScaleOut GeoServer to access a cloud-hosted IMDG is simple and secure.
Real-Time Hadoop MapReduce for Windows
With 5.1, we also rolled out the Windows version of our ScaleOut hServer® product, which lets developers create and run Hadoop MapReduce applications on grid-based data. This enables analysis of “live”, fast-changing data held within the IMDG, and it also delivers real-time results in milliseconds to a few seconds (instead of the minutes to hours required by standard, open source Hadoop distributions). Now users can run ScaleOut hServer on both Linux and Windows. We also added support for the Cloudera CDH4 Hadoop APIs to supplement support for the Apache Hadoop 1.X APIs.
Eliminating Network Bottlenecks
Some of the most exciting enhancements in version 5.1 deal with the internal architecture of ScaleOut’s IMDG. Over the last nine years, we have watched advances in CPU, memory, and networking technology. Unfortunately, these advances occur at different times and put stress in varying parts of the IMDG’s architecture. Today’s IMDGs often are deployed on clusters of servers each with 32 GB memory or higher (instead of 2 GB, which was common in 2005) and 8 or more i7 or Xeon cores. However, network bandwidth has only jumped 10X to 1 Gbps from 100 Mbps since 2005, while 10 Gbps Ethernet and Infiniband await widespread adoption in clusters of commodity servers. The net effect is that IMDG applications can easily saturate a gigabit network as servers are added to the cluster, especially when large objects are stored.
To help address this, we have streamlined the IMDG’s internal transport protocol used for load-balancing to boost its effective throughput by as much as 5X. This allows load-balancing to complete much faster after a server is added or removed from the IMDG.
Detecting Failures in Virtualized Environments
Another big technology change we have seen over the last nine years is the migration to virtualized environments; many if not most of our customer deployments are now hosted on virtual servers. Because it’s all too easy to overload the underlying physical servers with too many VMs, we often see intermittent network or processing delays caused by maxing out the CPU and NIC and sometimes by paging grid-hosted memory. These transient delays make it difficult to build a reliable heart-beating mechanism to recognize and recover from server or network outages (by looking for missing heartbeat messages between servers). Version 5.0 incorporated an adaptive heart-beating mechanism that responded to intermittent delays but could be spoofed by the unpredictable behavior of virtualized systems.
We now have fully revised this mechanism with new heuristics that more effectively identify and ignore these transient delays. ScaleOut StateServer measures the network for a full 24 hours before tightening its parameters for treating a heartbeat delay as a real outage, and it fully re-measures the network after a failure is detected. (Because it’s important to handle real outages quickly, allowed heartbeat delays must be kept as short as possible.) Our tests show that this approach minimizes service interruptions caused by erratic delays endemic to virtualized environments. However, it’s important to note that because of its heuristic nature, heart-beating can interpret communication delays as server failures.
We hope this tour of version 5.1 has helped illustrate our ongoing goals to maximize both ease of use and application performance, two core objectives of our IMDG and analytics technology. Please let us know your thoughts and comments.
The post What’s New in ScaleOut StateServer® Version 5.1 appeared first on ScaleOut Software.
]]>