The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times. For more than two decades, the answer to this challenge has proven to be a technology called in-memory computing.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers. Assuming bottlenecks are avoided, this enables transparent throughput scaling that matches an increase in workload, which in turn keeps response times low for users. It can also take advantage of the elastic computing resources available in cloud infrastructures to quickly and cost-effectively scale throughput to meet changes in demand.
Harnessing the power of in-memory computing requires software platforms that can make in-memory computing’s scalability readily available to applications using APIs while hiding the complexity of its implementation. Emerging in the early 2000s, the first such platforms provided distributed caching on clustered servers with straightforward APIs for storing and retrieving in-memory objects. When first introduced, distributed caching offered a breakthrough for applications by storing fast-changing data in memory on a server cluster for consistently fast response times, while simultaneously offloading database servers that would otherwise become bottlenecked. For example, ecommerce applications adopted distributed caching to store session-state, shopping carts, product descriptions, and other data that shoppers need to be able to access quickly.
Software platforms for distributed caching, such as ScaleOut StateServer®, which was introduced in 2005, hide internal mechanisms for cluster membership, throughput scaling, and high availability to take full advantage of the cluster’s scalable memory without adding complexity to applications. They transparently distribute stored objects across the cluster’s servers and ensure that data is not lost if a server or network component fails.
As distributed caching has evolved over the last two decades, additional mechanisms for in-memory computing have been incorporated to take advantage of the computing power available in the server cluster. Parallel query enables stored objects on all servers to be scanned simultaneously to retrieve objects with desired properties. Data-parallel computing analyzes objects on the server cluster to extract and report patterns of interest; it scales much better than parallel query by avoiding network bottlenecks and by using the cluster’s computing resources.
Most recently, stream-processing has been implemented with in-memory computing to simultaneously analyze telemetry from thousands or even millions of data sources and track dynamic state information for each data source. ScaleOut Software’s real-time digital twin model provides straightforward APIs for implementing stream-processing applications within its ScaleOut Digital Twin Streaming Service , an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
, an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins. Each step in the evolution has built on the previous one to add new capabilities that take advantage of the scalable computing power and fast data access that in-memory computing enables.
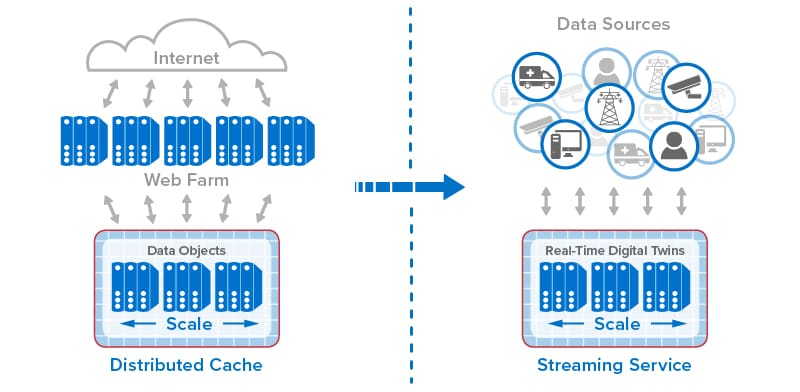
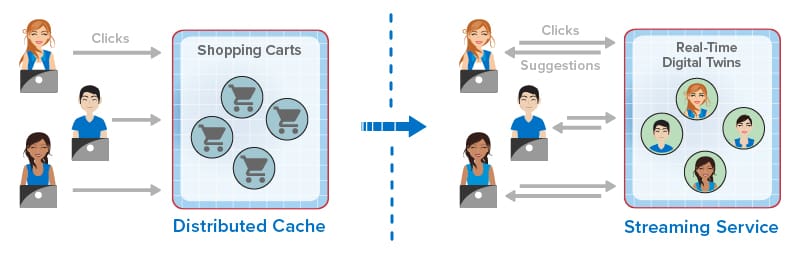
For ecommerce applications, this evolution has created new capabilities that dramatically improve the experience for online shoppers. Instead of just passively hosting session-state and shopping carts, online applications now can mine shopping carts for dynamic trends to evaluate the effectiveness of product descriptions and marketing programs (such as flash sales). They can also employ real-time digital twins or similar techniques to track each shopper’s behavior and make recommendations. By analyzing a click-stream of product selections in the context of knowledge of a shopper’s preferences and demographics, an ecommerce site can make highly focused recommendations to assist the shopper.
For example, one of ScaleOut Software’s customers recently upgraded from just using distributed caching to scale its ecommerce application. This customer now incorporates stream-processing capabilities using ScaleOut StreamServer® to capture click-streams and score users so that its web site can make more effective real-time offers.
The following diagram illustrates how the evolution of in-memory computing has enhanced the online experience for ecommerce shoppers by providing in-the-moment suggestions:
Starting with its development for parallel supercomputing in the late 1990s and evolving into its latest form as a cloud-based service, in-memory computing has offered powerful, software based APIs for building applications that serve large populations of users and data sources. It has helped assure that these applications deliver predictably fast performance and scale to meet the demands of growing workloads. In the next few years, we should continued innovation from in-memory computing to help ecommerce and other applications maintain their competitive edge.
The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>The post Scaling Real-Time Analytics with an IMDG appeared first on ScaleOut Software.
]]>Scale Out to Handle Growing Workloads
Scaling out contrasts to the alternative technique of scaling “up” computing power by adding processors or special purpose processing hardware, such as a vector processor or GPU, to a single, shared memory, multiprocessor system. This technique originally gained popularity with mainframe systems prior to the advent of parallel supercomputing. However, mainframe architect Gene Amdahl recognized that the slowest element of a computing system constrains its overall throughput when executing a fixed size problem; he codified this as Amdahl’s Law. For example, if half of the computation time for a problem is consumed by a vector calculation that could be offloaded to an infinitely fast vector processor, the overall computation only runs 2X faster. Even if 90% of the computation time could be accelerated in this manner, the computation speeds up by no more than 10X.
Scaling out solves this problem by avoiding it. Scaling out adds servers to a cluster so that it can handle larger problem sizes and continue to increase throughput without increasing computation time (as long as the overheads do not grow faster than the number of servers!). This benefit was first observed independently by Cleve Moler and John Gustafson and codified as Gustafson’s Law of scalable speedup. When scaling out, the goal changes from trying to reduce the computation time for a fixed size problem to maintaining the same computation time as the workload increases in size. This nicely matches the needs of system architects who need to scale their systems to keep up with fast growing workloads.
IMDGs Scale Out Access to Data
Scaling out enables in-memory data grids to scale both in-memory data storage capacity and computing power so that they can perform real-time analytics on fast changing data. For example, consider the basic function of an IMDG to let client applications seamlessly access memory-based objects distributed across a cluster of servers. To read an object stored in an IMDG, a client application calls an API which makes a network request to an IMDG server. Assuming the client library can keep track of which server holds the specified object, this request can be satisfied with a single network round trip, consuming a small amount of CPU and NIC bandwidth on the server. As more requests arrive at the server, they consume increasing amounts of CPU and NIC bandwidth until these resources are maxed out.
This is where scalable speedup takes over. Even though the overall request rate that a server can handle is constrained by its available resources, adding a second server doubles the request rate without increasing response time. Likewise, adding more servers to the cluster linearly increases the throughput while maintaining fixed response times until the cluster’s network infrastructure eventually is saturated. Scaling out enables IMDGs to handle growing workloads just by adding servers.
IMDGs Scale Out Updates to Data
Storing and updating objects in an IMDG requires more network bandwidth than accessing them. To maintain high availability, IMDGs store one or more copies of every object on additional servers so that if a server or network connection fails, data can be accessed from an alternative server within the cluster. So, at a minimum, an update request requires twice as much network bandwidth as an access request. As a result, an update-heavy workload tends to saturate the NICs and network infrastructure faster than an access-heavy workload. However, in both cases, the overhead is still proportional to the request rate and also proportional to the number of servers in the cluster. This means that we can expect linear throughput growth as we add IMDG servers until the network itself is saturated. (At that point, we need a faster network, such as 10 Gbps Ethernet or InfiniBand.)
It’s easy to see the importance of the IMDG’s automatic, dynamic load balancing of stored objects in maintaining scalable speedup. This mechanism evenly distributes the workload across all servers within the IMDG’s cluster to make sure that maximum throughput is obtained, avoiding “hot spots” which would direct too many requests to a few servers and limit throughput.
Maintaining Scalable Speedup in Analytics Computations
What happens if we create a workload that induces network overhead which grows faster than the number of servers? This problem was often encountered in parallel supercomputing and gave rise to the aphorism “embarrassingly parallel” for applications which minimize communication overhead. It is just as relevant today: real-time analytics applications must make sure this problem does not occur and kill scalable speedup as the workload grows.
For example, consider a data analytics computation distributed across a set of clients, one per server in an IMDG cluster with N servers, with the client application running on the grid servers. Also assume each server’s computation must access and analyze N or more objects. This makes the total number of accesses required to perform the computation proportional to N*N. If these objects are randomly distributed within the IMDG, the network overhead to process this workload will grow as N-squared and quickly saturate the network, drastically limiting scalable speedup. A “task-parallel” application which parcels out tasks to the clients (one task per object) to complete this analysis could be expected to exhibit this behavior since it randomly selects objects in the IMDG.
However, if we arrange to perform the same analysis as a “data-parallel” computation in which each client only analyzes the objects which are located on the same servers as the client, we can avoid data motion and thereby eliminate order-N-squared network overhead (although we still have order-N inter-process communication overhead between the IMDG’s service process and clients). This is accomplished by letting the IMDG perform the analysis tasks in parallel across all cluster servers on local objects within each server. (In the same manner, Hadoop MapReduce task trackers perform map operations on co-located “splits” within HDFS.)
IMDGs Avoid Data Motion with Data-Parallel Computing
ScaleOut StateServer Pro’s “parallel method invocation” (PMI) feature implements a data-parallel computation model. This feature lets the user specify a Java or C# method to analyze an object and another method to combine the results of two analyses. (These are analogous to a Hadoop mapper and combiner except that, unlike Hadoop, PMI automatically combines results across all servers into a single result object.) The user also specifies a parallel query to select the objects to be analyzed. To run a PMI, the IMDG pre-stages the code on all grid servers, performs the parallel query, and then analyzes all selected objects in place without moving them across the network. Lastly, it combines the results on each server and then combines the results across the servers using a binary combining tree which minimizes execution time.
Performance Gain from Avoiding Data Motion
The performance benefits of the data-parallel approach are dramatic. To illustrate this, we captured performance measurements of a risk analysis computation in financial services called “back testing.” This analysis compares a variety of stock trading algorithms using recorded price histories for a collection of equities. Each price history was stored in a single object within the IMDG, and the clients were assigned equities to analyze. (Note that the IMDG’s object-oriented storage also could dynamically update the price histories from a ticker feed to enable real-time feedback to a trading system.)
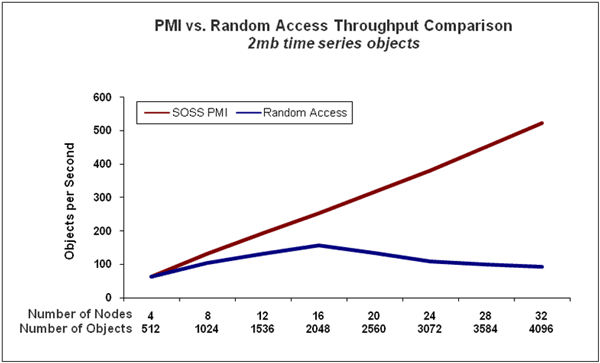
We compared the task-parallel technique in which the clients analyzed a random set of equities to the data-parallel technique in which the clients only examined equities stored on the same server; the data-parallel technique was implemented using PMI. The following chart shows the throughput obtained for both the task-parallel and data-parallel techniques. Note how the data-parallel approach (red line) maintains linear performance scaling as the workload increases and IMDG servers are added to the cluster. In contrast, the task-parallel approach (blue line) fails to achieve performance scaling due to accessing objects from remote servers which creates substantial networking overhead.
IMDGs take full advantage of scalable speedup to scale their handling of access requests and to perform data-parallel computations. This enables them to run real-time analytics on fast-changing data held in the IMDG and maintain fast response time for large workloads. Unlike pure streaming systems, they combine the IMDG’s in-memory storage with scalable computation to implement complex applications in real-time analytics. We will explore some of these applications in an upcoming blog.
The post Scaling Real-Time Analytics with an IMDG appeared first on ScaleOut Software.
]]>