The post Introducing Geospatial Mapping for Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
The goal of real-time streaming analytics is to get answers fast. Mission-critical applications that manage large numbers of live data sources need to quickly sift through incoming telemetry, assess dynamic changes, and immediately pinpoint emerging issues that need attention. Examples abound: a telematics application tracking a fleet of vehicles, a vaccine distribution system managing the delivery of thousands of shipments, a security or safety application analyzing entry points in a large infrastructure (physical or cyber), a healthcare application tracking medical telemetry from a population of wearable devices, a financial services application watching wire transfers and looking for potential fraud — the list goes on. In all these cases, when a problem occurs (or an opportunity emerges), managers need answers now.
Conventional streaming analytics platforms are unable to separate messages from each data source and analyze them as they flow in. Instead, they ingest and store telemetry from all data sources, attempt a preliminary search for interesting patterns in the aggregated data stream, and defer detailed analysis to offline batch processing. As a result, they are unable to introspect on the dynamic, evolving state of each data source and immediately alert on emerging issues, such as the impending failure of a truck engine, an unusual pattern of entries and exits to a secure building, or a potentially dangerous pattern of telemetry for a patient with a known medical condition.
In-memory computing with software components called real-time digital twins overcomes these obstacles and enables continuous analysis of incoming telemetry for each data source with contextual information that deepens introspection. While processing each message in a few milliseconds, this technology automatically scales to simultaneously handle thousands of data sources. It also can aggregate and visualize the results of analysis every few seconds so that managers can graphically track the state of a complex live system and quickly pinpoint issues.
The ScaleOut Digital Twin Streaming Service is an Azure-based cloud service that uses real-time digital twins to perform continuous data ingestion, analysis by data source, aggregation, and visualization, as illustrated below. What’s key about this approach is that the system visualizes state information that results from real-time analysis — not raw telemetry flowing in from data sources. This gives managers curated data that intelligently focuses on the key problem areas (or opportunities). For example, instead of looking at fluctuating oil temperature, telematics dispatchers see the results of predictive analytics. There’s not enough time for managers to examine all the raw data, and not enough time to wait for batch processing to complete. Maintaining situational awareness requires real-time introspection for each data source, and real-time digital twins provide it.
is an Azure-based cloud service that uses real-time digital twins to perform continuous data ingestion, analysis by data source, aggregation, and visualization, as illustrated below. What’s key about this approach is that the system visualizes state information that results from real-time analysis — not raw telemetry flowing in from data sources. This gives managers curated data that intelligently focuses on the key problem areas (or opportunities). For example, instead of looking at fluctuating oil temperature, telematics dispatchers see the results of predictive analytics. There’s not enough time for managers to examine all the raw data, and not enough time to wait for batch processing to complete. Maintaining situational awareness requires real-time introspection for each data source, and real-time digital twins provide it.
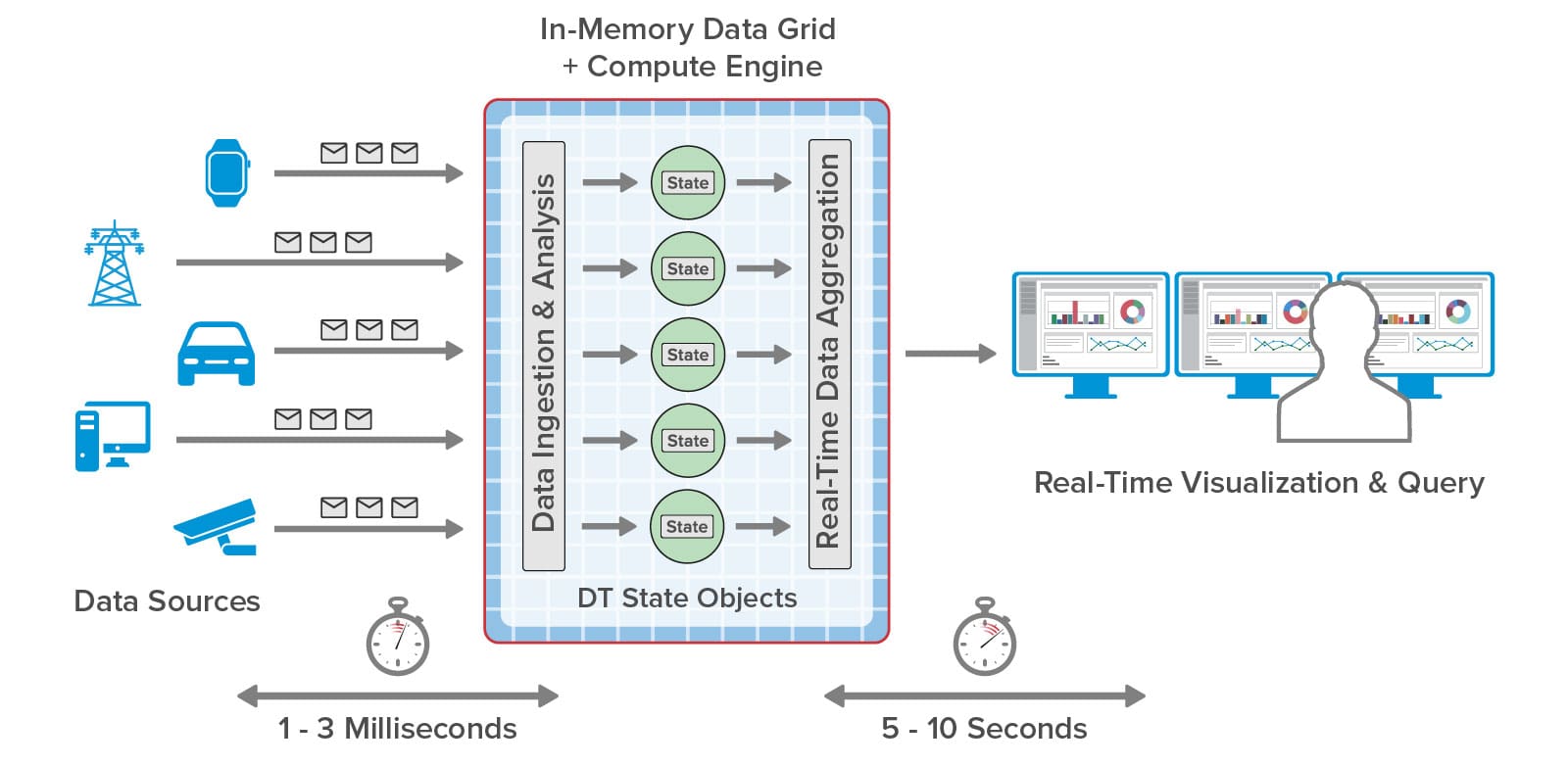
In the ScaleOut Digital Twin Streaming Service, real-time data visualization can take the form of charts and tables. Dynamic charts effectively display the results of aggregate analytics that combine data from all real-time digital twins to show emerging patterns, such as the regions of the country with the largest delivery delays for a vaccine distribution system. This gives a comprehensive view that helps managers maintain the “big picture.” To pinpoint precisely which data sources need attention, users can query analytics results for all real-time digital twins and see the results in a table. This enables managers to ask questions like “Which vaccination centers in Washington state are experiencing delivery delays in excess of 1 hour and have seen more than 100 people awaiting vaccinations at least three times today?” With this information, managers can immediately determine where vaccine shipments should be delivered first.
With the latest release, the streaming service now offers geospatial mapping of query results combined with continuous queries that refresh the map every few seconds. For example, using this cloud service, a telematics system for a trucking fleet can continuously display the locations of specific trucks which have issues (the red dots on the map) in addition to watching aggregate statistics:
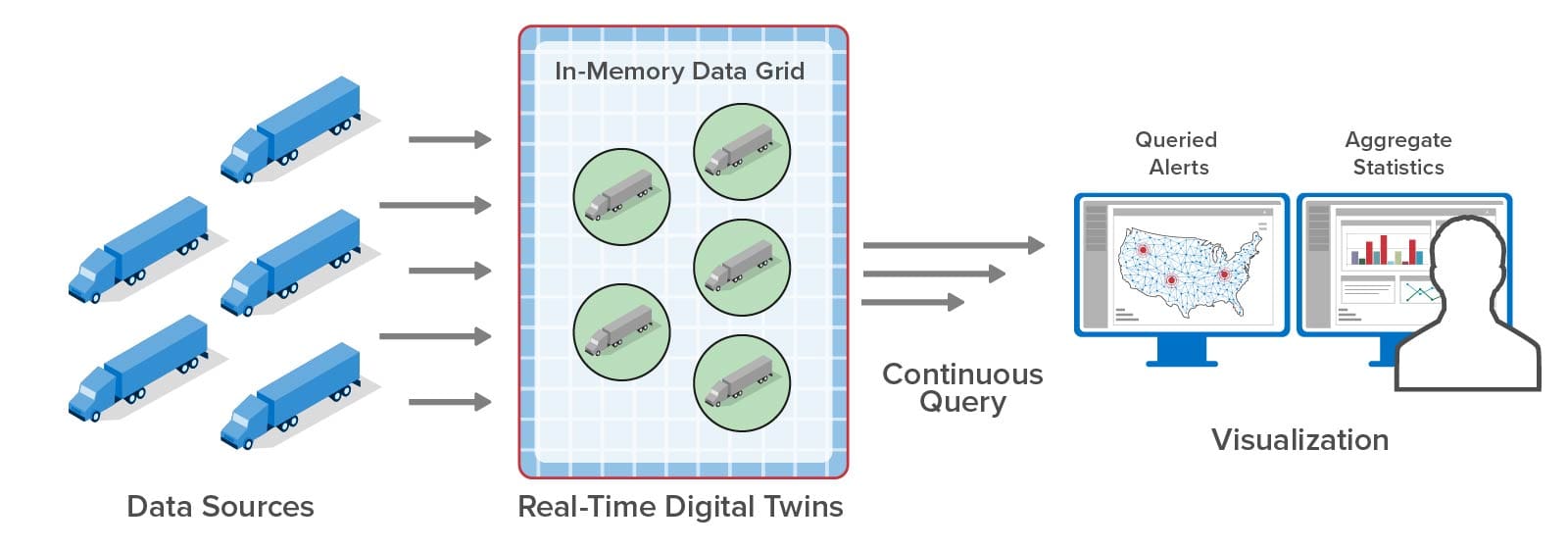
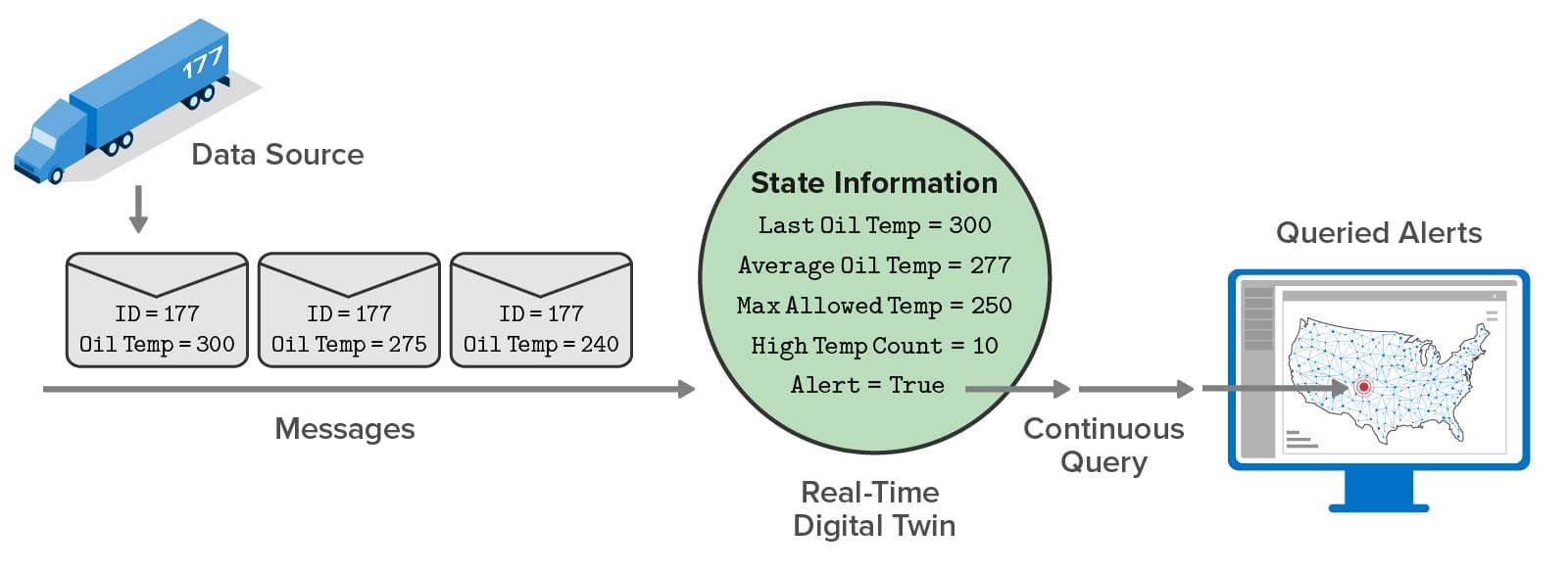
For applications like this, a mapped view of query results offers valuable insights about the locations where issues are emerging that would otherwise be more difficult to obtain from a tabular view. Note that the queried data shows the results of real-time analytics which are continuously updated as messages arrive and are processed. For example, instead of displaying the latest oil temperature from a truck, the query reports the results of a predictive analytics algorithm that makes use of several state variables maintained by the real-time digital twin. This declutters the dispatcher’s view so that only alertable conditions are highlighted and demand attention:
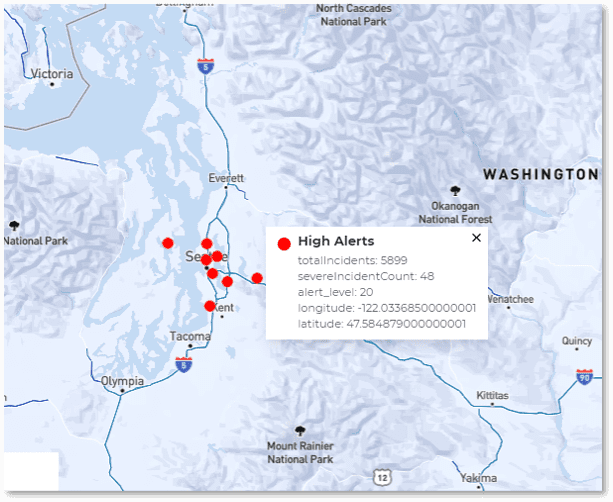
The following image shows an example of actual map output for a hypothetical security application that tracks possible intrusions within a nationwide power grid. The goal of the real-time digital twins is to assess telemetry from each of 20K control points in the power grid’s network, filter out false-positives and known issues, and produce a quantitative assessment of the threat (“alert level”). Continuous queries map the results of this assessment so that managers can immediately spot a real threat, understand its scope, and take action to isolate it. The map shows the results of results three continuous queries: high alerts requiring action, medium alerts that just need watching, and offline nodes (with the output suppressed here):
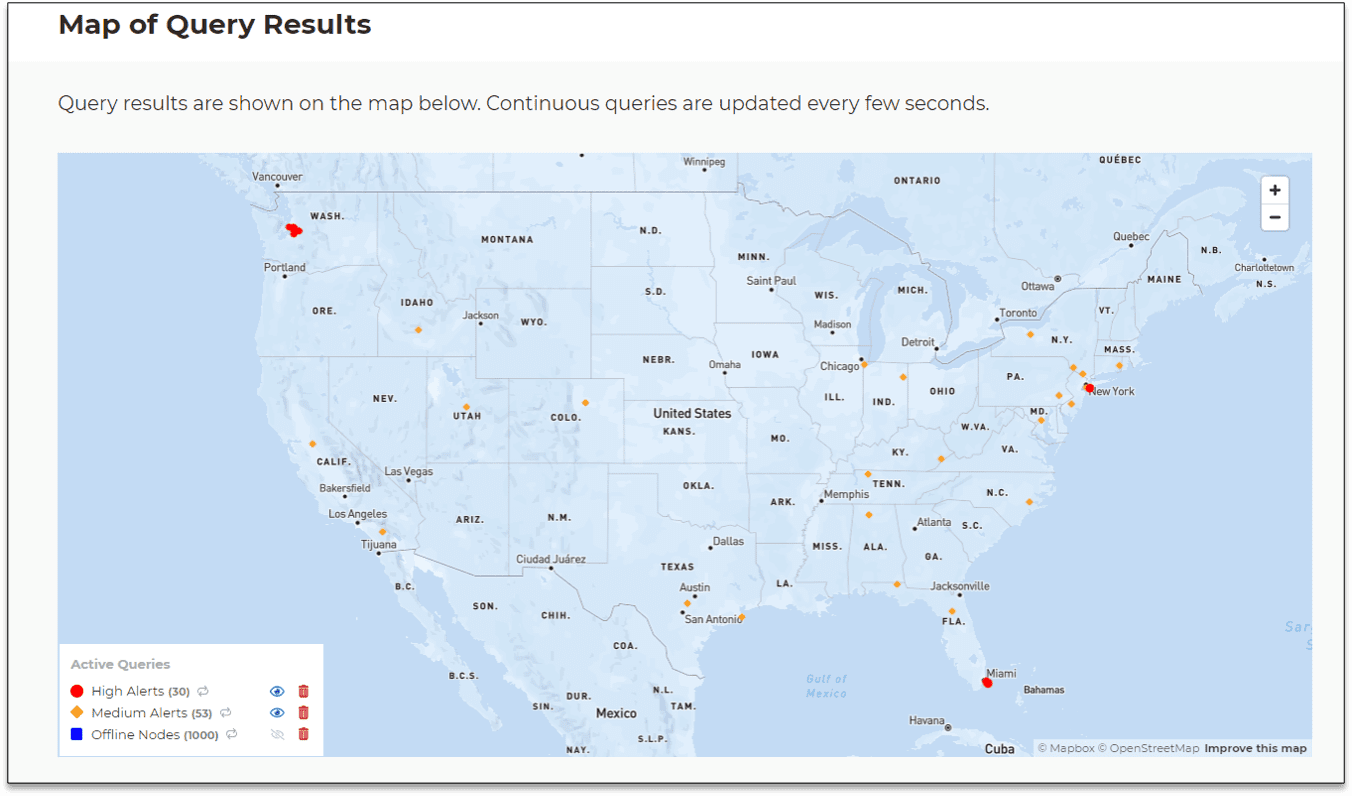
In this scenario a high alert has suddenly appeared in the grid at three locations (Seattle, New York, and Miami) indicating a serious, coordinated attack on the network. By zooming in and hovering over dots in the graph, users can display the detailed query results for each corresponding data source. Within seconds, managers have immediate, actionable information about threat assessments and can quickly visualize the locations and scope of specific threats.
In applications like these and many others, the power of in-memory computing with real-time digital twins gives managers a new means to digest real-time telemetry from thousands of data sources, combine it with contextual information that enhances the analysis, and then immediately visualize the results. This powerful technology boosts situational awareness and helps guide responses much better and faster than was previously possible.
The post Introducing Geospatial Mapping for Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post What’s New in ScaleOut StateServer® Version 5.1 appeared first on ScaleOut Software.
]]>New C++ APIs
We introduced ScaleOut StateServer® almost exactly nine years ago and have worked continuously since then to add features requested by our customers and boost the product’s performance. Version 5.1 contains several exciting new capabilities, led by our introduction of C++ APIs. Our goal was to make these C++ APIs as easy to use as possible. So the first decision was to make them open source. This allows developers to build the APIs for a variety of compilers starting with GCC 4.4 (circa 2009) and newer. To strike a balance that allows support for the older compilers used on some enterprise-grade distributions of Linux, some newer C++11 features were not used, and the APIs use the widely-available Boost C++ libraries instead. (Releases of Boost going back to version 1.41 have been verified to work.) So, for example, rather than returning a std::shared_ptr to a retrieved object, the API returns a boost::shared_ptr. The C++ APIs are also available for Windows developers; we ship pre-built libraries for Visual Studio 2013 users in the release.
The next big challenge with the C++ APIs was how to handle data serialization, which is needed to store objects within an out-of-process, in-memory data grid (IMDG). We first introduced C# APIs in 2005, and then added Java APIs in 2008. Unlike C++, both of these languages have built-in serializers; ScaleOut StateServer uses these serializers by default to keep application development as simple for the user as possible. Looking at other IMDGs in the market, we did not want to go down the same path of requiring the use of serialization APIs provided by the IMDG vendor (us in this case). So we chose to offer integrated support for the popular Google Protocol Buffer encoding standard (with optional indexing of annotated fields to support parallel query) and also provide an extensible API mechanism that allows users to build custom serializers.
Replicating Data to the Cloud
With version 5.1, we also extended support for data replication and remote access to IMDGs hosted in public clouds using our ScaleOut GeoServer® product. This product lets users connect a local IMDG to one or more remote IMDGs so that data can be replicated off-site in case of a site-wide failure; it also allows transparent access to data stored at remote sites using the IMDG’s APIs for local data access. With this release, remote IMDGs hosted in Amazon Web Services or Windows Azure can be accessed by ScaleOut GeoServer (and by client applications) with full support for secure connections using SSL.
The challenge with accessing cloud-based IMDGs is that it is clumsy to bootstrap connectivity using IP addresses, as is standard practice for on-premise grids, since these IP addresses are highly dynamic. To solve this problem, we created a simple mechanism (first introduced in version 5.0 for remote clients) which binds clients and remote IMDGs to a cloud-hosted IMDG using a simple combination of account credentials and a “store” name. We then retrieve cloud-based metadata to automatically identify and configure the current IP addresses and ports for the client or remote IMDG. The net effect is that configuring ScaleOut GeoServer to access a cloud-hosted IMDG is simple and secure.
Real-Time Hadoop MapReduce for Windows
With 5.1, we also rolled out the Windows version of our ScaleOut hServer® product, which lets developers create and run Hadoop MapReduce applications on grid-based data. This enables analysis of “live”, fast-changing data held within the IMDG, and it also delivers real-time results in milliseconds to a few seconds (instead of the minutes to hours required by standard, open source Hadoop distributions). Now users can run ScaleOut hServer on both Linux and Windows. We also added support for the Cloudera CDH4 Hadoop APIs to supplement support for the Apache Hadoop 1.X APIs.
Eliminating Network Bottlenecks
Some of the most exciting enhancements in version 5.1 deal with the internal architecture of ScaleOut’s IMDG. Over the last nine years, we have watched advances in CPU, memory, and networking technology. Unfortunately, these advances occur at different times and put stress in varying parts of the IMDG’s architecture. Today’s IMDGs often are deployed on clusters of servers each with 32 GB memory or higher (instead of 2 GB, which was common in 2005) and 8 or more i7 or Xeon cores. However, network bandwidth has only jumped 10X to 1 Gbps from 100 Mbps since 2005, while 10 Gbps Ethernet and Infiniband await widespread adoption in clusters of commodity servers. The net effect is that IMDG applications can easily saturate a gigabit network as servers are added to the cluster, especially when large objects are stored.
To help address this, we have streamlined the IMDG’s internal transport protocol used for load-balancing to boost its effective throughput by as much as 5X. This allows load-balancing to complete much faster after a server is added or removed from the IMDG.
Detecting Failures in Virtualized Environments
Another big technology change we have seen over the last nine years is the migration to virtualized environments; many if not most of our customer deployments are now hosted on virtual servers. Because it’s all too easy to overload the underlying physical servers with too many VMs, we often see intermittent network or processing delays caused by maxing out the CPU and NIC and sometimes by paging grid-hosted memory. These transient delays make it difficult to build a reliable heart-beating mechanism to recognize and recover from server or network outages (by looking for missing heartbeat messages between servers). Version 5.0 incorporated an adaptive heart-beating mechanism that responded to intermittent delays but could be spoofed by the unpredictable behavior of virtualized systems.
We now have fully revised this mechanism with new heuristics that more effectively identify and ignore these transient delays. ScaleOut StateServer measures the network for a full 24 hours before tightening its parameters for treating a heartbeat delay as a real outage, and it fully re-measures the network after a failure is detected. (Because it’s important to handle real outages quickly, allowed heartbeat delays must be kept as short as possible.) Our tests show that this approach minimizes service interruptions caused by erratic delays endemic to virtualized environments. However, it’s important to note that because of its heuristic nature, heart-beating can interpret communication delays as server failures.
We hope this tour of version 5.1 has helped illustrate our ongoing goals to maximize both ease of use and application performance, two core objectives of our IMDG and analytics technology. Please let us know your thoughts and comments.
The post What’s New in ScaleOut StateServer® Version 5.1 appeared first on ScaleOut Software.
]]>