The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
]]>Real-Time Device Tracking with In-Memory Computing Can Fill an Important Gap in Today’s Streaming Analytics Platforms
We are increasingly surrounded by intelligent IoT devices, which have become an essential part of our lives and an integral component of business and industrial infrastructures. Smart watches report biometrics like blood pressure and heartrate; sensor hubs on long-haul trucks and delivery vehicles report telemetry about location, engine and cargo health, and driver behavior; sensors in smart cities report traffic flow and unusual sounds; card-key access devices in companies track entries and exits within businesses and factories; cyber agents probe for unusual behavior in large network infrastructures. The list goes on.
The Limitations of Today’s Streaming Analytics
How are we managing the torrent of telemetry that flows into analytics systems from these devices? Today’s streaming analytics architectures are not equipped to make sense of this rapidly changing information and react to it as it arrives. The best they can usually do in real-time using general purpose tools is to filter and look for patterns of interest. The heavy lifting is deferred to the back office. The following diagram illustrates a typical workflow. Incoming data is saved into data storage (historian database or log store) for query by operational managers who must attempt to find the highest priority issues that require their attention. This data is also periodically uploaded to a data lake for offline batch analysis that calculates key statistics and looks for big trends that can help optimize operations.
![]()
What’s missing in this picture? This architecture does not apply computing resources to track the myriad data sources sending telemetry and continuously look for issues and opportunities that need immediate responses. For example, if a health tracking device indicates that a specific person with known health condition and medications is likely to have an impending medical issue, this person needs to be alerted within seconds. If temperature-sensitive cargo in a long haul truck is about to be impacted by an erratic refrigeration system with known erratic behavior and repair history, the driver needs to be informed immediately. If a cyber network agent has observed an unusual pattern of failed login attempts, it needs to alert downstream network nodes (servers and routers) to block the kill chain in a potential attack.
A New Approach: Real-Time Device Tracking
To address these challenges and countless others like them, we need autonomous, deep introspection on incoming data as it arrives and immediate responses. The technology that can do this is called in-memory computing. What makes in-memory computing unique and powerful is its two-fold ability to host fast-changing data in memory and run analytics code within a few milliseconds after new data arrives. It can do this simultaneously for millions of devices. Unlike manual or automatic log queries, in-memory computing can continuously run analytics code on all incoming data and instantly find issues. And it can maintain contextual information about every data source (like the medical history of a device wearer or the maintenance history of a refrigeration system) and keep it immediately at hand to enhance the analysis. While offline, big data analytics can provide deep introspection, they produce answers in minutes or hours instead of milliseconds, so they can’t match the timeliness of in-memory computing on live data.
The following diagram illustrates the addition of real-time device tracking with in-memory computing to a conventional analytics system. Note that it runs alongside existing components. It adds the ability to continuously examine incoming telemetry and generate both feedback to the data sources (usually, devices) and alerts for personnel in milliseconds:
![]()
In-Memory Computing with Real-Time Digital Twins
Let’s take a closer look at today’s conventional streaming analytics architectures, which can be hosted in the cloud or on-premises. As shown in the following diagram, a typical analytics system receives messages from a message hub, such as Kafka, which buffers incoming messages from the data sources until they can be processed. Most analytics systems have event dashboards and perform rudimentary real-time processing, which may include filtering an aggregated incoming message stream and extracting patterns of interest. These real-time components then deliver messages to data storage, which can include a historian database for logging and query and a data lake for offline, batch processing using big data tools such as Spark:
![]()
Conventional streaming analytics systems run either manual queries or automated, log-based queries to identify actionable events. Since big data analyses can take minutes or hours to run, they are typically used to look for big trends, like the fuel efficiency and on-time delivery rate of a trucking fleet, instead of emerging issues that need immediate attention. These limitations create an opportunity for real-time device tracking to fill the gap.
As shown in the following diagram, an in-memory computing system performing real-time device tracking can run alongside the other components of a conventional streaming analytics solution and provide autonomous introspection of the data streams from each device. Hosted on a cluster of physical or virtual servers, it maintains memory-based state information about the history and dynamically evolving state of every data source. As messages flow in, the in-memory compute cluster examines and analyzes them separately for each data source using application-defined analytics code. This code makes use of the device’s state information to help identify emerging issues and trigger alerts or feedback to the device. In-memory computing has the speed and scalability needed to generate responses within milliseconds, and it can evaluate and report aggregate trends every few seconds.
![]()
Because in-memory computing can store contextual data and process messages separately for each data source, it can organize application code using a software-based digital twin for each device, as illustrated in the diagram above. Instead of using the digital twin concept to model the inner workings of the device, a real-time digital twin tracks the device’s evolving state coupled with its parameters and history to detect and predict issues needing immediate attention. This provides an object-oriented mechanism that simplifies the construction of real-time application code that needs to evaluate incoming messages in the context of the device’s dynamic state. For example, it enables a medical application to determine the importance of a change in heart rate for a device wearer based on the individual’s current activity, age, medications, and medical history.
Summing Up
The complex web of communicating devices that surrounds us needs intelligent, real-time device tracking to extract its full benefits. Conventional streaming analytics architectures have not kept up with the growing demands of IoT. With its combination of fast data storage, low-latency processing and ease of use, in-memory computing can fill the gap while complementing the benefits provided by historian databases and data lakes. It can add the immediate feedback that IoT applications need and boost situational awareness to a new level, finally enabling IoT to deliver on its promises.
The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
]]>The post Introducing Geospatial Mapping for Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
The goal of real-time streaming analytics is to get answers fast. Mission-critical applications that manage large numbers of live data sources need to quickly sift through incoming telemetry, assess dynamic changes, and immediately pinpoint emerging issues that need attention. Examples abound: a telematics application tracking a fleet of vehicles, a vaccine distribution system managing the delivery of thousands of shipments, a security or safety application analyzing entry points in a large infrastructure (physical or cyber), a healthcare application tracking medical telemetry from a population of wearable devices, a financial services application watching wire transfers and looking for potential fraud — the list goes on. In all these cases, when a problem occurs (or an opportunity emerges), managers need answers now.
Conventional streaming analytics platforms are unable to separate messages from each data source and analyze them as they flow in. Instead, they ingest and store telemetry from all data sources, attempt a preliminary search for interesting patterns in the aggregated data stream, and defer detailed analysis to offline batch processing. As a result, they are unable to introspect on the dynamic, evolving state of each data source and immediately alert on emerging issues, such as the impending failure of a truck engine, an unusual pattern of entries and exits to a secure building, or a potentially dangerous pattern of telemetry for a patient with a known medical condition.
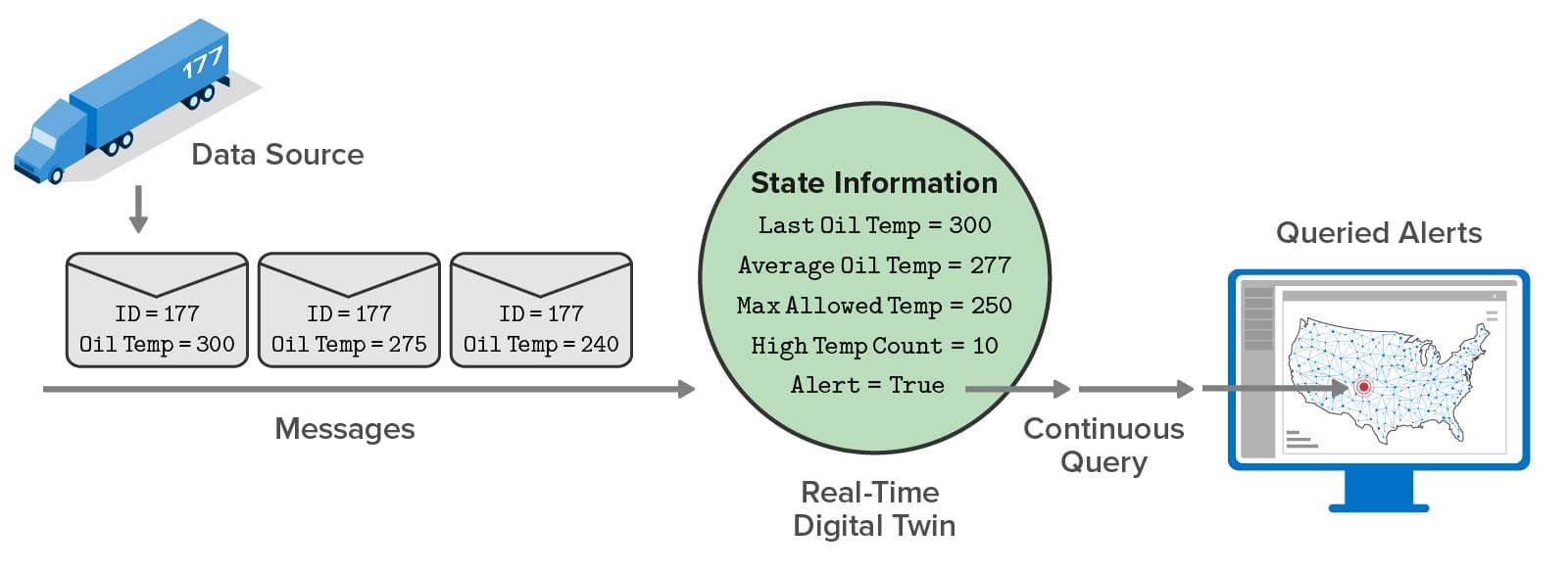
In-memory computing with software components called real-time digital twins overcomes these obstacles and enables continuous analysis of incoming telemetry for each data source with contextual information that deepens introspection. While processing each message in a few milliseconds, this technology automatically scales to simultaneously handle thousands of data sources. It also can aggregate and visualize the results of analysis every few seconds so that managers can graphically track the state of a complex live system and quickly pinpoint issues.
The ScaleOut Digital Twin Streaming Service is an Azure-based cloud service that uses real-time digital twins to perform continuous data ingestion, analysis by data source, aggregation, and visualization, as illustrated below. What’s key about this approach is that the system visualizes state information that results from real-time analysis — not raw telemetry flowing in from data sources. This gives managers curated data that intelligently focuses on the key problem areas (or opportunities). For example, instead of looking at fluctuating oil temperature, telematics dispatchers see the results of predictive analytics. There’s not enough time for managers to examine all the raw data, and not enough time to wait for batch processing to complete. Maintaining situational awareness requires real-time introspection for each data source, and real-time digital twins provide it.
is an Azure-based cloud service that uses real-time digital twins to perform continuous data ingestion, analysis by data source, aggregation, and visualization, as illustrated below. What’s key about this approach is that the system visualizes state information that results from real-time analysis — not raw telemetry flowing in from data sources. This gives managers curated data that intelligently focuses on the key problem areas (or opportunities). For example, instead of looking at fluctuating oil temperature, telematics dispatchers see the results of predictive analytics. There’s not enough time for managers to examine all the raw data, and not enough time to wait for batch processing to complete. Maintaining situational awareness requires real-time introspection for each data source, and real-time digital twins provide it.
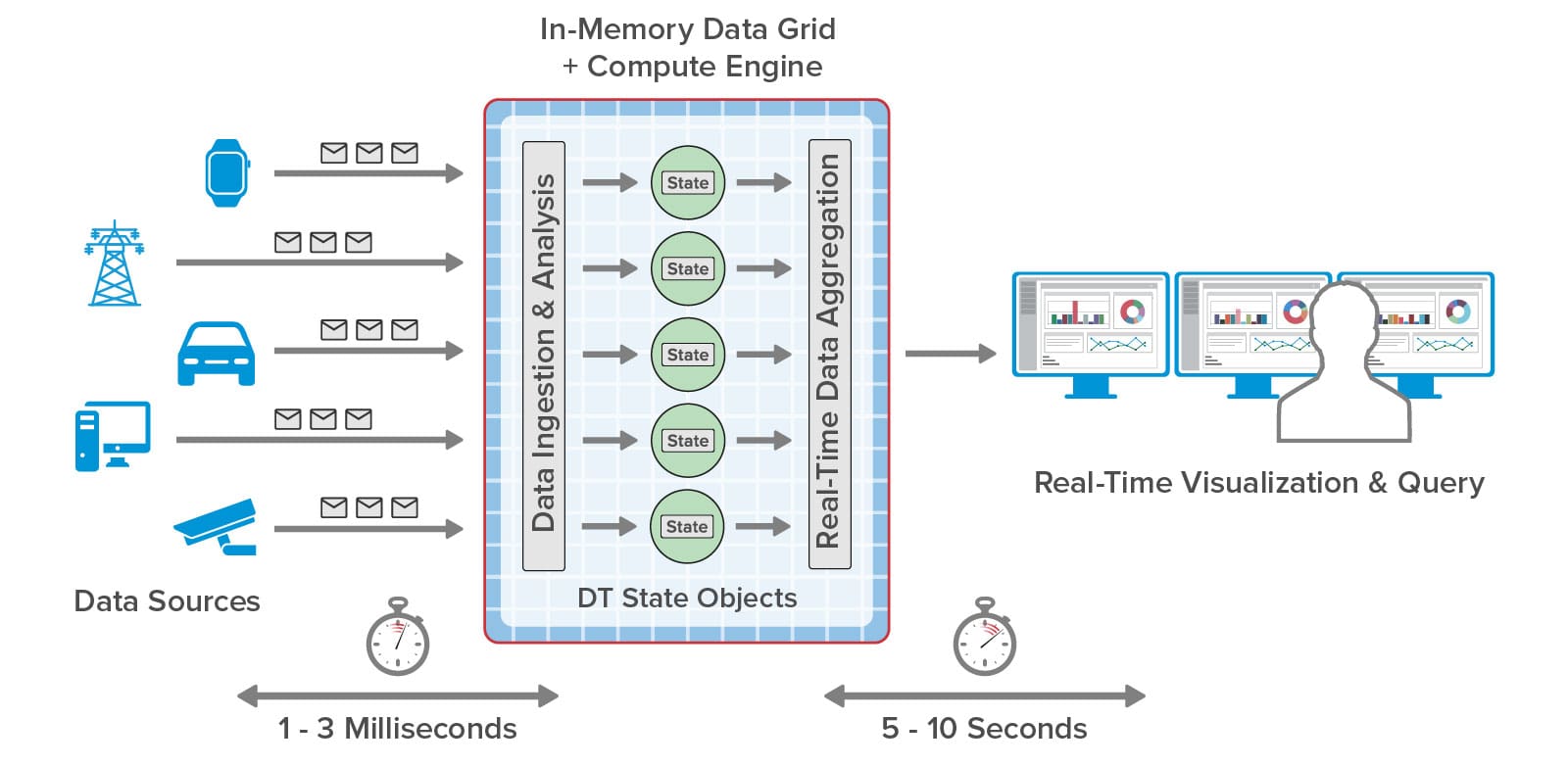
In the ScaleOut Digital Twin Streaming Service, real-time data visualization can take the form of charts and tables. Dynamic charts effectively display the results of aggregate analytics that combine data from all real-time digital twins to show emerging patterns, such as the regions of the country with the largest delivery delays for a vaccine distribution system. This gives a comprehensive view that helps managers maintain the “big picture.” To pinpoint precisely which data sources need attention, users can query analytics results for all real-time digital twins and see the results in a table. This enables managers to ask questions like “Which vaccination centers in Washington state are experiencing delivery delays in excess of 1 hour and have seen more than 100 people awaiting vaccinations at least three times today?” With this information, managers can immediately determine where vaccine shipments should be delivered first.
With the latest release, the streaming service now offers geospatial mapping of query results combined with continuous queries that refresh the map every few seconds. For example, using this cloud service, a telematics system for a trucking fleet can continuously display the locations of specific trucks which have issues (the red dots on the map) in addition to watching aggregate statistics:
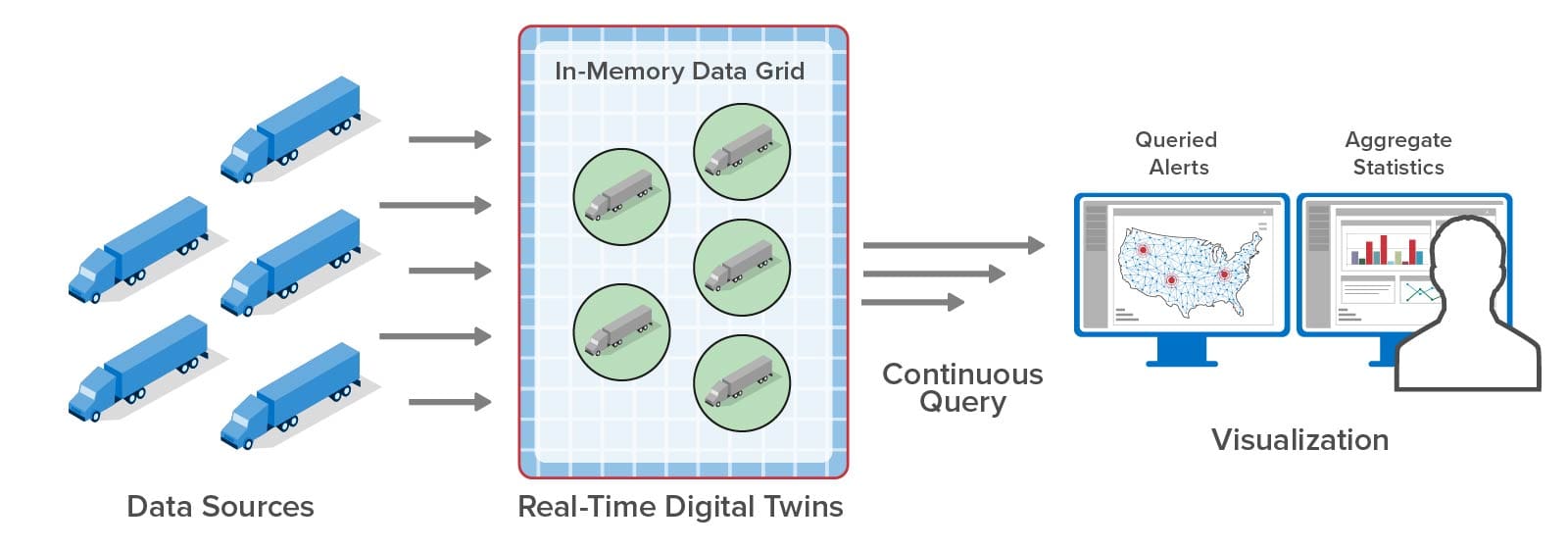
For applications like this, a mapped view of query results offers valuable insights about the locations where issues are emerging that would otherwise be more difficult to obtain from a tabular view. Note that the queried data shows the results of real-time analytics which are continuously updated as messages arrive and are processed. For example, instead of displaying the latest oil temperature from a truck, the query reports the results of a predictive analytics algorithm that makes use of several state variables maintained by the real-time digital twin. This declutters the dispatcher’s view so that only alertable conditions are highlighted and demand attention:
The following image shows an example of actual map output for a hypothetical security application that tracks possible intrusions within a nationwide power grid. The goal of the real-time digital twins is to assess telemetry from each of 20K control points in the power grid’s network, filter out false-positives and known issues, and produce a quantitative assessment of the threat (“alert level”). Continuous queries map the results of this assessment so that managers can immediately spot a real threat, understand its scope, and take action to isolate it. The map shows the results of results three continuous queries: high alerts requiring action, medium alerts that just need watching, and offline nodes (with the output suppressed here):
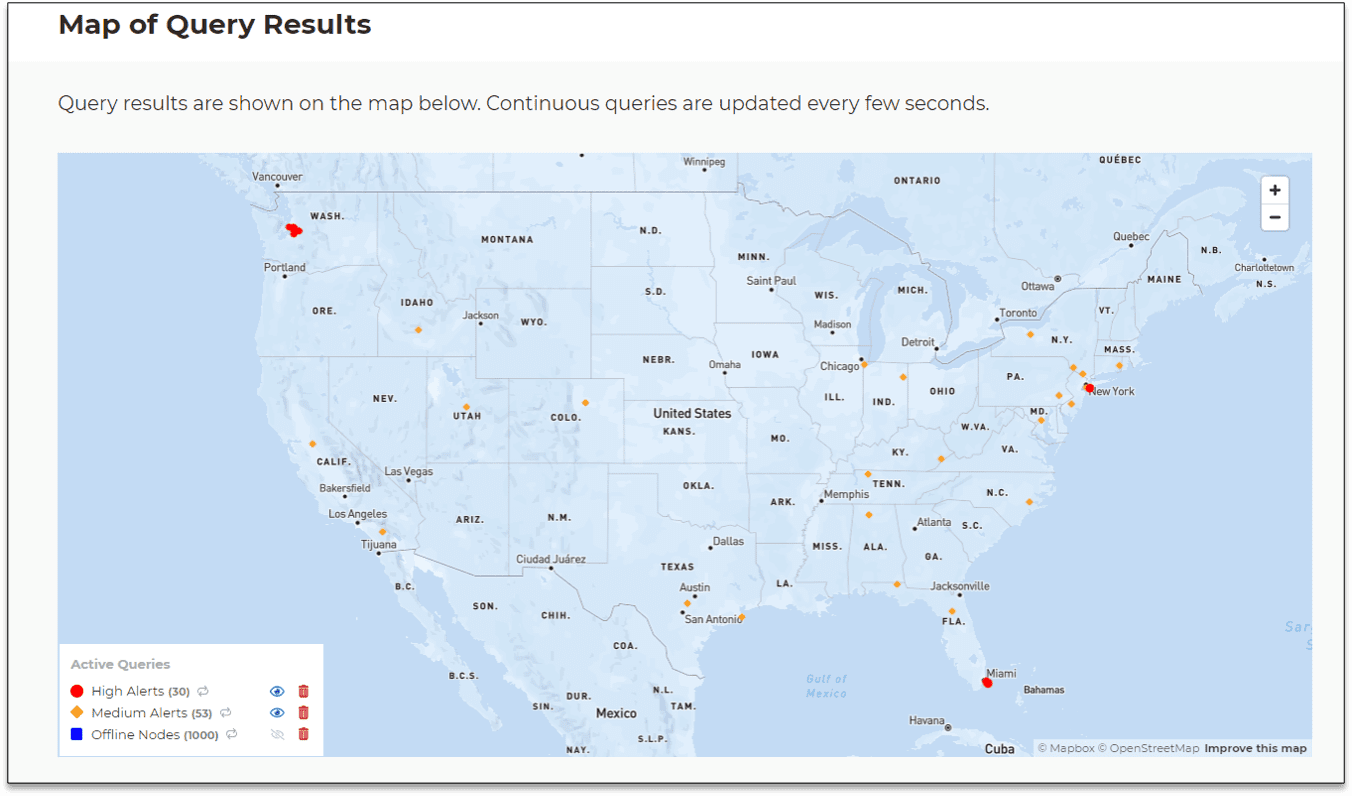
In this scenario a high alert has suddenly appeared in the grid at three locations (Seattle, New York, and Miami) indicating a serious, coordinated attack on the network. By zooming in and hovering over dots in the graph, users can display the detailed query results for each corresponding data source. Within seconds, managers have immediate, actionable information about threat assessments and can quickly visualize the locations and scope of specific threats.
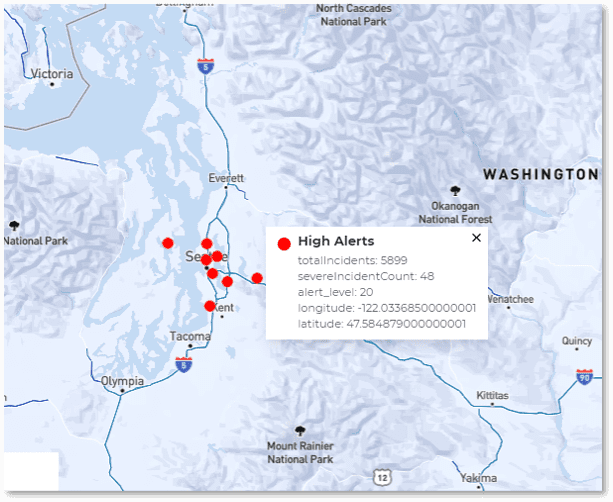
In applications like these and many others, the power of in-memory computing with real-time digital twins gives managers a new means to digest real-time telemetry from thousands of data sources, combine it with contextual information that enhances the analysis, and then immediately visualize the results. This powerful technology boosts situational awareness and helps guide responses much better and faster than was previously possible.
The post Introducing Geospatial Mapping for Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Deploying Real-Time Digital Twins On Premises with ScaleOut StreamServer DT appeared first on ScaleOut Software.
]]>
With the ScaleOut Digital Twin Streaming Service, an Azure-hosted cloud service, ScaleOut Software introduced breakthrough capabilities for streaming analytics using the real-time digital twin concept. This new software model enables applications to easily analyze telemetry from individual data sources in 1-3 milliseconds while maintaining state information about data sources that deepens introspection. It also provides a basis for applications to create key status information that the streaming platform aggregates every few seconds to maximize situational awareness. Because it runs on a scalable, highly available in-memory computing platform, it can do all this simultaneously for hundreds of thousands or even millions of data sources.
The unique capabilities of real-time digital twins can provide important advances for numerous applications, including security, fleet telematics, IoT, smart cities, healthcare, and financial services. These applications are all characterized by numerous data sources which generate telemetry that must be simultaneously tracked and analyzed, while maintaining overall situational awareness that immediately highlights problems of concern an/or opportunities of interest. For example, consider some of the new capabilities that real-time digital twins can provide in fleet telematics and vaccine distribution during COVID-19.
To address security requirements or the need for tight integration with existing infrastructure, many organizations need to host their streaming analytics platform on-premises. Scaleout StreamServer® DT was created to meet this need. It combines the scalable, battle-tested in-memory data grid that powers ScaleOut StreamServer with the graphical user interface and visualization features of the cloud service in a unified, on-premises deployment. This gives users all of the capabilities of the ScaleOut Digital Twin Streaming Service with complete infrastructure control.
As illustrated in the following diagram, ScaleOut StreamServer DT installs its management console on a standalone server that connects to ScaleOut StreamServer’s in-memory data grid. This console hosts the graphical user interface that is securely accessed by remote workstations within an organization. It also deploys real-time digital twin models to the in-memory data grid, which hosts instances of digital twins (one per data source) and runs application-defined code to process incoming messages. Message are delivered to the grid using messaging hubs, such as Azure IoT Hub, AWS IoT Core, Kafka, a built-in REST service, or directly using APIs.
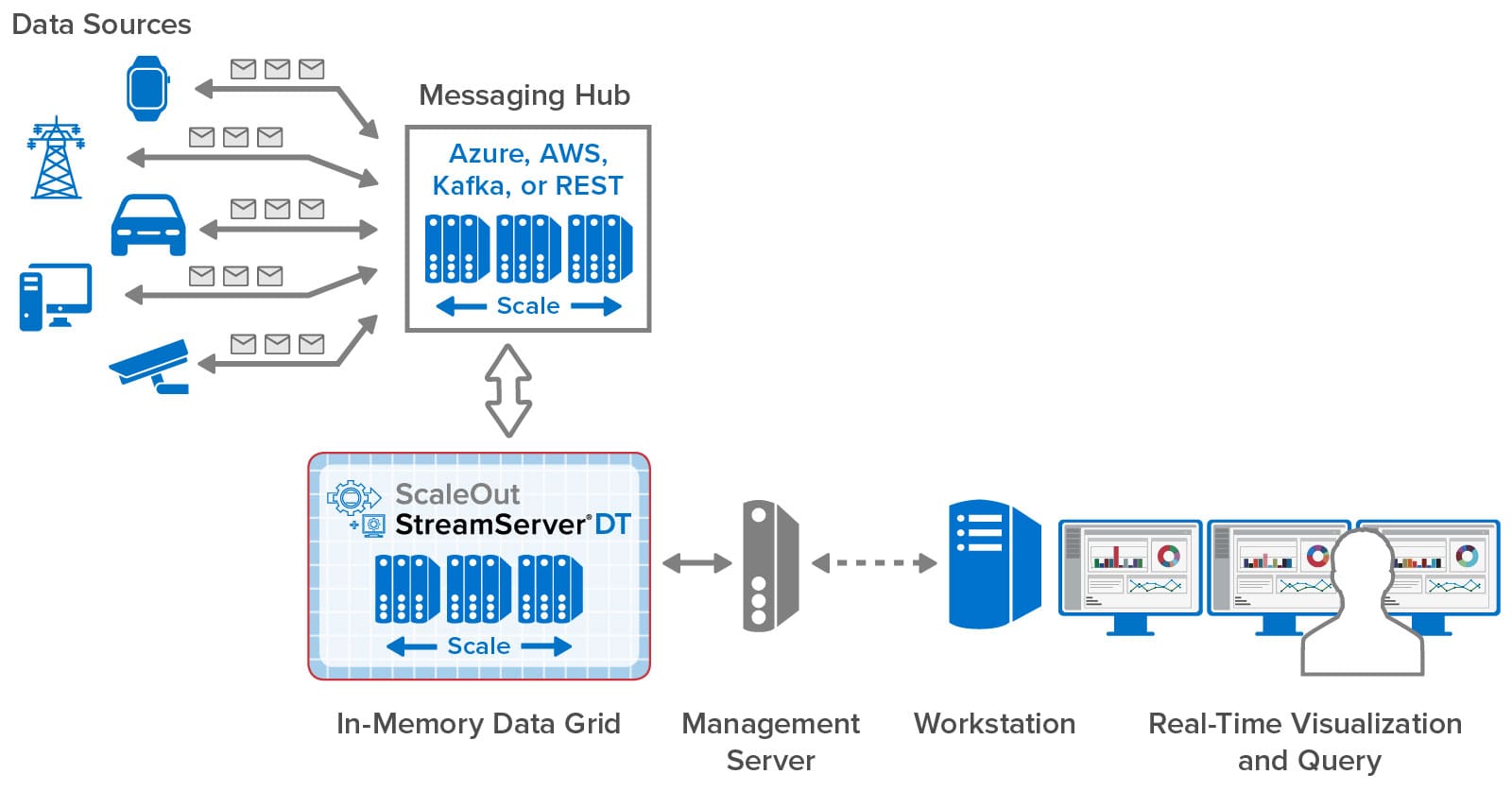
The management console installs as a set of Docker containers on the management server. This simplifies the installation process and ensures portability across operating systems. Once installed, users can create accounts to control access to the console, and all connections are secured using SSL. The results of aggregate analytics and queries performed within the in-memory data grid can then be accessed and visualized on workstations running throughout an organization.
Because ScaleOut’s in-memory data grid runs in an organization’s data center and avoids the requirement to use a cloud-hosted message hub or REST service, incoming messages from data sources can be processed with minimum latency. In addition, application code running in real-time digital twins can access local resources, such as databases and alerting systems, with the best possible performance and security. Use of dedicated computing resources for the in-memory data grid delivers the highest possible throughput for message processing and real-time analytics.
While cloud hosting of streaming analytics as a SaaS (software-as-a-service) offering creates clear advantages in reducing capital costs and providing access to highly elastic computing resources, it may not be suitable for organizations which need to maintain full control of their infrastructures to address security and performance requirements. ScaleOut StreamServer DT was designed to meet these needs and deliver the important, unique benefits of streaming analytics using real-time digital twins to these organizations.
The post Deploying Real-Time Digital Twins On Premises with ScaleOut StreamServer DT appeared first on ScaleOut Software.
]]>The post Real-Time Digital Twins Maximize Situational Awareness appeared first on ScaleOut Software.
]]>As a simple example, consider a “smart” city which delivers real-time telemetry to a control center from thousands of sensors distributed across a metropolitan area. Real-time digital twins can track this telemetry and intelligently analyze it for patterns of interest by making use of contextual information, such as each device’s parameters, specific location, service history, and time-ordered log of recent events. Continuous, aggregate analysis requiring under five seconds to complete can identify those sensors with the highest alerting priority and reveal patterns of dynamic changes which indicate how a threat is evolving. For example, this can show the scope of an attack or fire and the areas likely to be affected next, and it can help direct an emergency response to best contain and resolve the situation.
The following diagram illustrates how city-wide sensors can direct telemetry to real-time digital twins hosted in an in-memory computing platform, which runs the analysis algorithms and provides real-time alerts to personnel:
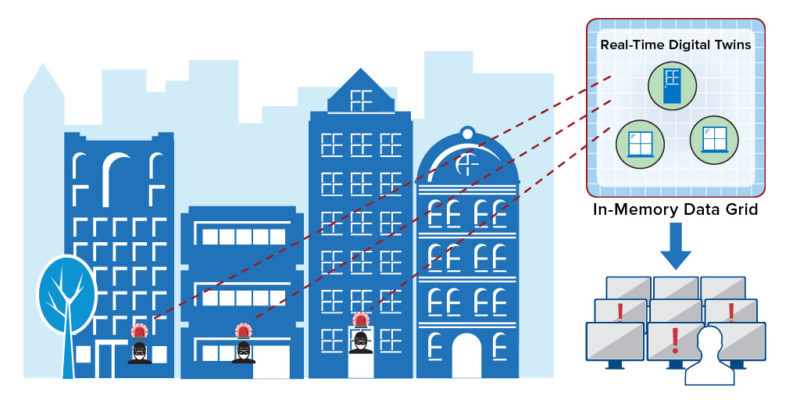
The key to the power of real-time digital twins is their implementation on a software-based, in-memory computing platform which provides highly scalable, memory-based data storage and integrated, data-parallel computing for performing both stateful stream-processing and aggregate data analysis. Learn more about ScaleOut Software’s in-memory computing platform for stream-processing with real-time digital twins, called ScaleOut StreamServer®, here. This product hosts application-defined, real-time digital twin models written in Java, C#, or JavaScript using the ScaleOut Digital Twin Builder software toolkit; learn more about this toolkit here.
The post Real-Time Digital Twins Maximize Situational Awareness appeared first on ScaleOut Software.
]]>The post Intelligent Real-Time Monitoring Using Real-Time Digital Twins appeared first on ScaleOut Software.
]]>Real-time digital twins offer unique advantages for intelligent, real-time monitoring, especially for thousands of telemetry streams, such as from car/truck fleets, intrusion sensors, or other IoT applications. By maintaining dynamic context information for all data sources and benefiting from automatic event correlation, digital twins can track and respond to these telemetry streams in milliseconds. In addition, digital twins provide a basis for aggregate analysis that can identify developing trends in seconds and prioritize the data sources that need immediate attention. In short, the use of real-time digital twins for streaming analytics offers a powerful new tool for boosting “situational awareness” in applications that perform real-time monitoring.
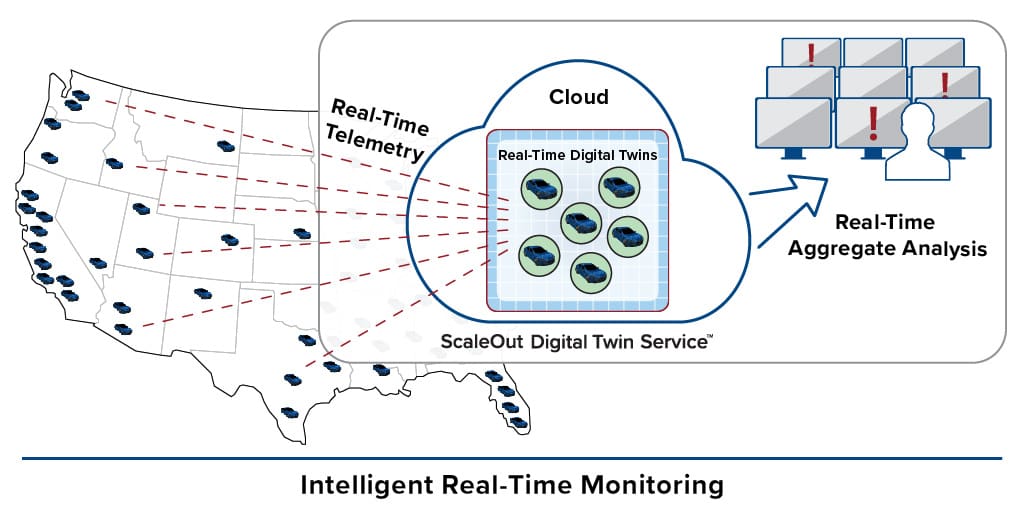
Consider a rental car or truck fleet that easily can comprise more than 100K vehicles. Real-time digital twins can monitor and continuously assess each vehicle’s progress and condition with important context information about both the vehicle and driver, such as intended route, maintenance history, and the driver’s profile. This enables more intelligent introspection on incoming telemetry if a vehicle is delayed, becomes lost, or behaves erratically.
In addition, aggregate analysis across all vehicles quickly pinpoints emerging trends, such as highway blockages due to accidents or floods, that may require immediate attention or feedback to the vehicles. The ability to triage the state of an entire fleet within a few seconds enables monitoring personnel to immediately focus attention on the most important problems and not overlook critical issues due to the sheer volume of incoming telemetry.
ScaleOut Software’s in-memory computing technology makes this all possible. ScaleOut StreamServer® provides a scalable, highly available software platform for hosting real-time digital twin models created in C#, Java, or JavaScript using the ScaleOut Digital Twin Builder software toolkit. By hosting these digital twins as memory-based objects and automatically correlating incoming telemetry by data source, this platform enables application developers to easily construct real-time analytics code which can introspect on incoming telemetry. The use of digital twins ensures immediate access to dynamic state information for each data source. Typical event processing times are less than 5 milliseconds. In addition, data-parallel analytics can perform MapReduce analytics across all digital twins every few seconds to identify emerging trends and boost situational awareness. These capabilities create important breakthroughs in software technology for real-time stream-processing, enabling simplified design, deeper introspection, and integrated, data-parallel computing for improved situational awareness.
The post Intelligent Real-Time Monitoring Using Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Object-Oriented Programming Simplifies Digital Twins appeared first on ScaleOut Software.
]]>When using the digital twin model, each data source in a physical system has a corresponding software object in the stream-processing platform as depicted here:
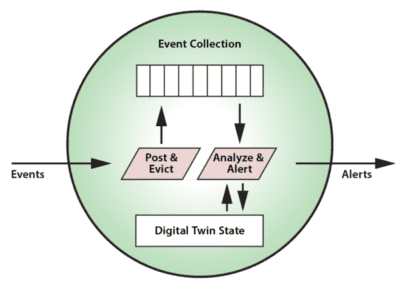
This object encapsulates both state information and code. State information includes a time-ordered list of the device’s incoming event messages along with key state information about the dynamic state of the data source. This information could include parameters, service history, known issues, and much more. Application code handles the management of the event list and the real-time analysis of incoming events, along with APIs for performing device commands. This code benefits from the rich context provided by dynamic state information, enabling deeper introspection than analyzing the event stream alone.
The secret to keeping event analysis times low when handling events from thousands of data sources is to host these digital twin objects in an in-memory data grid (IMDG) with an integrated compute engine, such as ScaleOut StreamServer. IMDGs harness the memory and computing power of multiple commodity (or cloud-based) servers to scale computing resources, and they minimize network bottlenecks by analyzing events within the grid. Their NoSQL, object-oriented storage precisely fits the requirements for digital twin objects, making it straightforward to deploy and host these objects with both scalable performance and high availability.
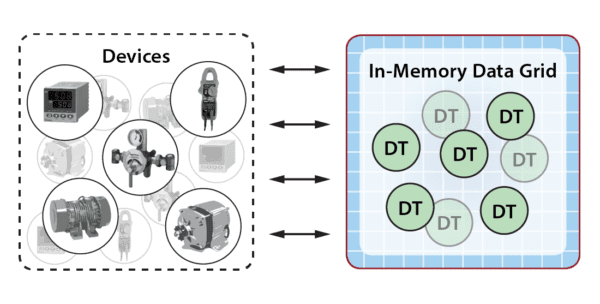
The following diagram depicts an IMDG hosting a large set of digital twin objects in an IoT application. The IMDG transparently distributes the digital twin objects across a cluster of commodity servers for scalable processing. These objects receive telemetry from various devices and perform real-time analysis:
Let’s take a look at how object-oriented techniques can simplify the design of digital twins. Because a digital twin encapsulates state information and associated analysis code, it naturally can be represented as a user-defined data type (often called a class) within an object-oriented language, such as Java or C#. The use of an object class to represent the controller conveniently encapsulates the data and code as a single unit and allows us to create many instances of this type to manage different devices. For example, consider the digital twin for a basic controller with class properties (status and event collection) describing the controller’s status and class methods for analyzing events and performing device commands. This class can be depicted graphically as follows:
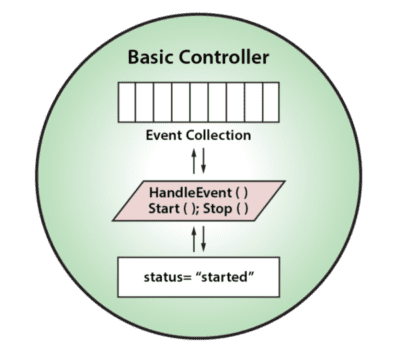
Here’s how a basic controller class could be written in Java:
public class BasicController {
private List<Event> eventCollection;
private DeviceStatus status;
public void start() {…}
public void stop() {…}
public void handleEvent() {…}
}
We also can make use of the class definition to construct various special purpose digital twins as subclasses, taking advantage of the object-oriented technique called inheritance. For example, we can define the digital twin for a hot water valve as a subclass of a basic controller that adds new properties, such as temperature and flow rate, with associated methods for managing them:
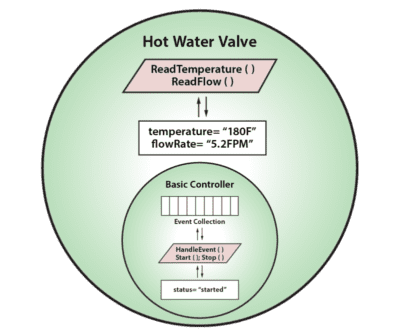
This subclass inherits all of the properties of a basic controller while adding new capabilities to manage specialized controller types. Using this object-oriented approach maximizes code reuse and saves development time.
Here’s a Java example that illustrates how inheritance could be used to create the hot water valve class. It also shows how the hot water valve class can override the implementation of the Start and Stop methods defined by the basic controller:
public abstract class BasicController {
protected List<Event> eventCollection;
protected DeviceStatus status;
public abstract void start();
public abstract void stop();
public abstract void handleEvent();
}
public class HotWaterValve extends BasicController {
private double temperature;
private double flowRate;
public double readTemperature() {
return temperature;
}
public double readFlowRate() {
return flowRate;
}
@Override
public void start() {…}
@Override
public void stop() {…}
@Override
public void handleEvent() {…}
}
As discussed in an earlier blog, we also can build a hierarchy of digital twins that represent successively higher levels of analysis and management for complex systems, and this hierarchy can further leverage object-oriented techniques. Consider the following set of interconnected digital twin instances used in managing a hypothetical pump room:
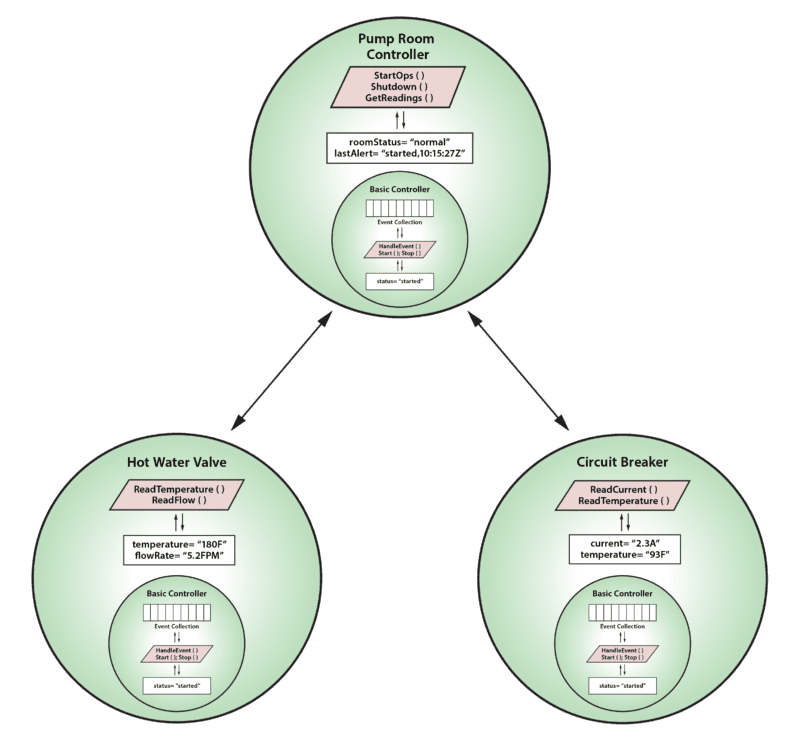
In this example, the pump room has two digital twins connected directly to devices, one for a hot water valve and another for a circuit breaker. These twins are both implemented as subclasses of a basic controller and add properties and methods specific to their devices. They feed telemetry to a higher-level digital twin instance which manages overall operations for the pump room. This digital twin also can be implemented as a subclass of a basic controller even though it is not connected directly to a device. What’s important to observe about this example is how both object inheritance and hierarchy play separate roles in defining the digital twin objects which work together to analyze event streams. Inheritance lets us refine the behavior of digital twin models to customize their actions, and hierarchy lets us build systems of interconnected digital twins which process events at successively higher levels of abstraction.
Digital twin models for stateful stream-processing have evolved from concepts largely unrelated to object-oriented programming, in particular, product life-cycle management and industrial IoT (where they are often called device twins). Object-oriented techniques give software developers powerful tools for applying digital twins to stateful stream-processing and streaming analytics. Applications now can benefit from automatic event correlation, stateful event analysis for deeper introspection, and the scalable computing power of IMDGs.
The post Object-Oriented Programming Simplifies Digital Twins appeared first on ScaleOut Software.
]]>The post Digital Twins Enable Seamless Use of Edge Computing in IoT appeared first on ScaleOut Software.
]]>We also saw how digital twins can be organized in a hierarchy in which the lowest level twins represent individual devices and higher-level twins represent subsystems, possibly organized at multiple levels, which control these devices. Higher-level twins receive events from lower-level twins in the same manner that the lowest-level twins receive events from physical devices. Likewise, twins at all levels can send messages downwards in the hierarchy for purposes of control, eventually resulting in signals being sent to the devices.
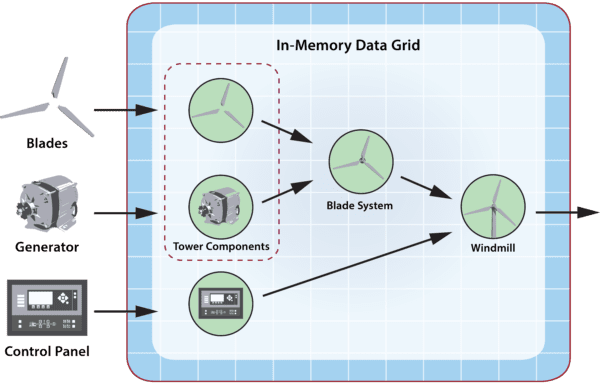
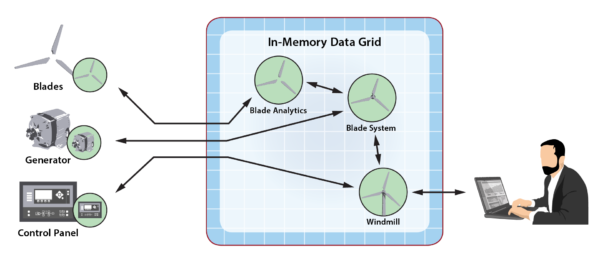
As described in the blog cited above, the following diagram illustrates the use of a digital twin hierarchy to implement a hypothetical windmill:
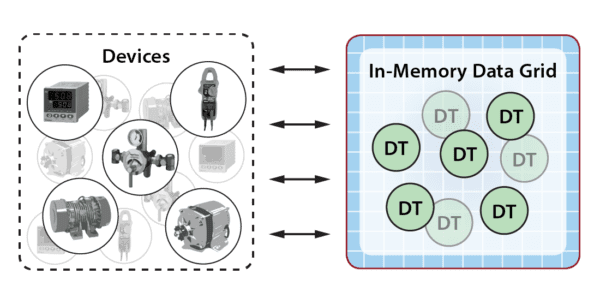
Observing that digital models cleanly match the semantics of object-oriented programming, we can implement them in a straightforward manner as object instances that correspond to individual devices or higher-level subsystems. Because real-world IoT applications can track thousands of devices or other entities (e.g., medical patients, ecommerce shoppers), distributed, in-memory data grids (IMDGs) with integrated in-memory computing (such as ScaleOut StreamServer) provide a natural platform for hosting these objects and executing their event-handling functions. IMDGs enable transparent performance scaling, which is required to ensure fast event handling, and they typically have built-in high availability. The following diagram depicts a population of devices and their corresponding digital twins running in an IMDG:
As computing power at the edge inexorably grows, it makes increasing sense to provide enhanced intelligence close to the devices. This minimizes event-handling latency and enables better management of local operations, while still providing strategic analysis and control by remote (cloud-based or on-premises) IoT applications. The challenge is to determine how to partition application logic between the cloud and edge, and more specifically, how to easily migrate functionality to the edge. What is required is a software architecture that enables seamless migration without requiring application code to be reimplemented for execution on edge-based platforms.
The digital twin provides a powerful answer to this challenge. We can leverage its data and code encapsulation to transparently migrate low-level event handling functionality to the edge – where the devices live. Instead of re-implementing application code for use at the edge, we can simply migrate the lowest level digital twins to edge-based execution platforms without changing their code or messaging protocols. For example, consider how the windmill’s digital twins can be migrated downwards to the windmill itself while keeping the overall digital twin hierarchy intact, as shown in the following diagram:
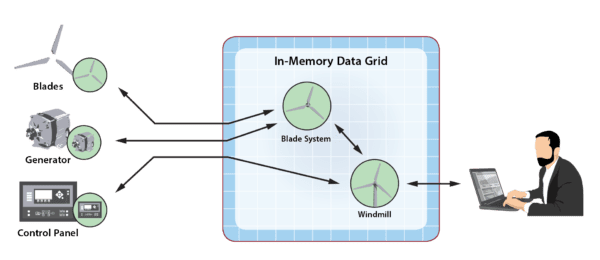
The lowest-level digital twins now are hosted at the edge next to their corresponding devices without any changes to the code. Container-based execution can replicate the IMDG’s execution environment so that application code is unaware of the migration other than by observing dramatically lower event-handling latency. The higher-level digital twins continue to run in the cloud or on-premises – wherever the required computing resources are located.
Looking beyond this simple example, the use of the digital twin model does not require that all device-specific functionality migrate to the edge. Consider a more complex application in which a device is represented by a pair of digital twins, a low-level twin that directly manages the device’s operations, and a higher-level twin that implements predictive analytics, perhaps using a compute-intensive, machine-learning (ML) algorithm, based on telemetry received from the low-level twin. In this application, it may make sense to migrate the low-level twin to the edge for better responsiveness and uninterrupted operations, while keeping the high-level, “strategic” twin in the cloud where computing resources are available to execute its predictive analytics algorithm. The following diagram illustrates this scenario for the windmill:
Transparent migration of event-handling functionality to the edge represents yet another way the digital twin model adds value to stateful, stream-processing applications. This model takes full advantage of object-oriented concepts to both simplify application design and create new capabilities which would be daunting and complex to implement at the application level or with conventional stream-processing platforms. Our list of digital twin capabilities now includes:
- automatic event correlation for each device,
- seamless, fast access to per-device state information,
- straightforward separation of low and high-level functions into a hierarchy, and
- transparent migration of event handling functionality to the edge.
The digital twin model is worth a close look when designing the next generation of IoT applications.
The post Digital Twins Enable Seamless Use of Edge Computing in IoT appeared first on ScaleOut Software.
]]>The post The Power of an In-Memory Data Grid for Hosting Digital Twin Models appeared first on ScaleOut Software.
]]>The secret to the power of the digital twin model is its focus on organizing real-time data by the data source to which it corresponds. What this means is that all event messages from each data source are correlated into a time-ordered collection, which is associated with both dynamic state information and historical knowledge of that data source. This gives the stream-processing application a rich context for analyzing event messages and determining what actions need to be taken in real time.
For example, consider an application which tracks a rental car fleet to look for drivers who are lost or driving recklessly. This application can use the digital twin model to correlate real-time telemetry (e.g., location, speed) for each car in the fleet and combine that with data about the driver’s contract, safety record with the rental car company, and possibly driving history. Instead of just examining the latest incoming events, the application now has much more information instantly available to judge when and whether to signal an alert.
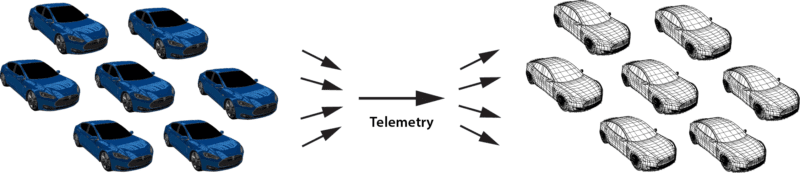
When implementing a stateful stream-processing application using the digital twin model, an object-oriented approach offers obvious leverage in managing the data and event processing associated with this model. For each type of data source, the developer can create a data type (object “class”) which describes the event collection, real-time state data, and analysis code to be executed when a new event message arrives. Instances of this data type then can be created for each unique data source as its digital twin for stream-processing. Here is a depiction of a digital twin object and its associated methods:
This object-oriented approach makes an in-memory data grid (IMDG) with integrated in-memory computing, (e.g., ScaleOut StreamServer) an excellent stream-processing platform for real-time digital twin models. IMDGs have a long history dating back almost two decades. They were originally created as middleware software to host large populations of fast-changing data objects, such as ecommerce session-state and shopping carts, in memory instead of database servers, thereby speeding up access. An IMDG implements a software-based, key-value store of serialized objects that spans a cluster of commodity servers (or cloud instances). Its architecture provides cost-effective scalability and high availability, while hiding the complexity of distributed in-memory storage from the applications which use them. It also can take full advantage of a cluster’s computing power to run application code within the IMDG — where the data lives — to maximize performance and avoid network bottlenecks.
Using an example from financial services, the following diagram illustrates an application’s logical view of an IMDG as a collection of objects (stock sectors in this case) and its physical implementation as in-memory storage spanning a cluster of servers:
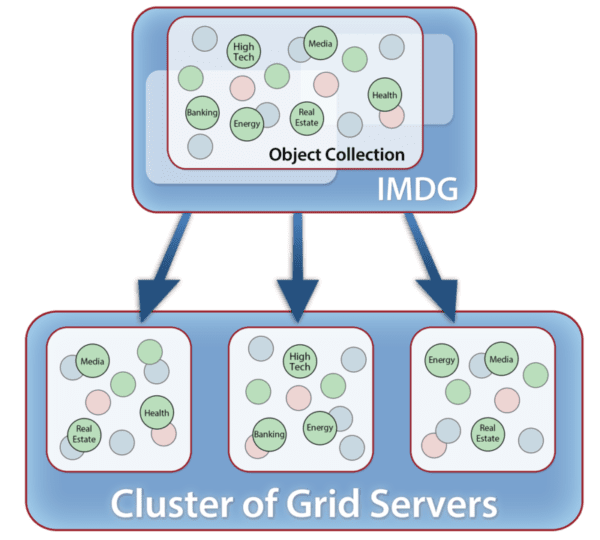
It should now be clear why IMDGs offer a great way to host digital twin models and perform stateful-stream processing. An IMDG can store instances of a digital twin model and scale its storage capacity and event-processing throughput by adding servers to hold many thousands of instances as needed for all the data sources. The grid’s key-value storage model automatically correlates incoming event messages for the corresponding digital twin instance based on the data source’s identifying key. When the grid delivers an event to its digital twin, it then runs the model’s application code for event ingestion, analysis, and alerting in real time.
As an example, the following diagram illustrates the use of an IMDG to host digital twin objects for rental cars. The arrows indicate that the IMDG directs events from each car to its corresponding digital twin for event-processing.
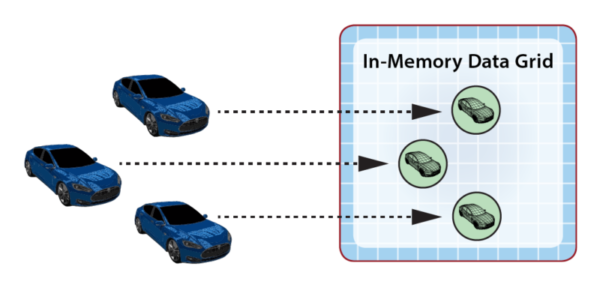
As part of event-processing, digital twins can create alerts for human attention and/or feedback directed at the corresponding data source. In addition, the collection of digital twin objects stored in the IMDG can be queried or analyzed using data-parallel techniques (e.g., MapReduce) to extract important aggregate patterns and trends. For example, the rental car application could alert managers when a driver repeatedly exceeds the speed limit according to criteria specific to the driver’s age and driving history. It also could allow a manager to query the status of a specific car or compute the maximum excessive speeding for all cars in a specified region. These data flows are illustrated in the following diagram:
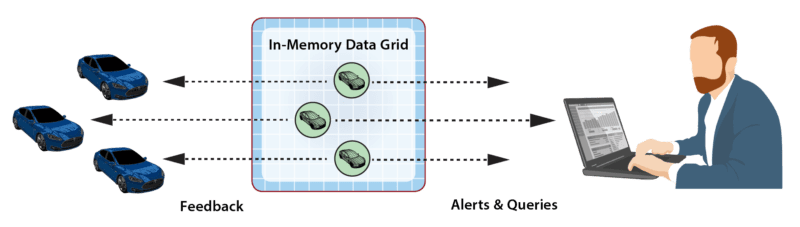
Because they are hosted in memory, digital twin models can react very quickly to incoming events, and the IMDG can scale by adding servers to keep event processing times fast even when the number of instances (objects) and/or event rates become very large. Although the in-memory state of a digital twin is restricted to the event and state data needed for real-time processing, the application can reference historical data from external database servers to broaden its context, as shown below. For example, the rental car application could access driving history only when incoming telemetry indicates a need for it. It also could store past events in a database for archival purposes.
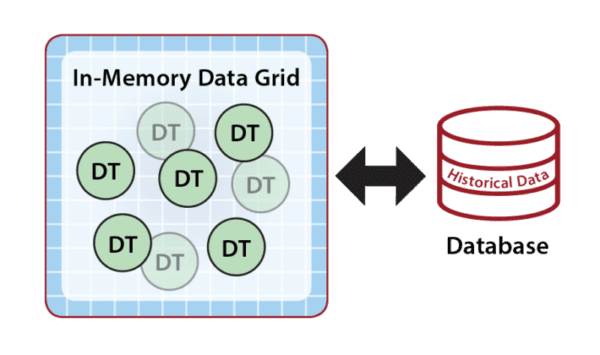
What makes an IMDG an excellent fit for stateful stream-processing is its ability to transparently host both the state information and application code within a fast, highly scalable, in-memory computing platform and then automatically direct incoming events to their respective digital twin instances within the grid for processing. These two key capabilities, namely correlating events by data sources and analyzing these events within the context of the digital twin’s real-time state information, give applications powerful new tools and create an exciting new way to think about stateful stream-processing.
The post The Power of an In-Memory Data Grid for Hosting Digital Twin Models appeared first on ScaleOut Software.
]]>The post The Digital Twin: A Foundational Concept for Stateful Stream Processing appeared first on ScaleOut Software.
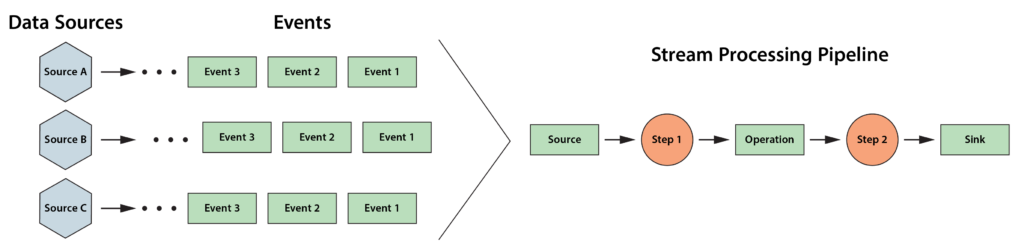
]]>The following diagram depicts a typical stream processing pipeline processing events from many data sources:
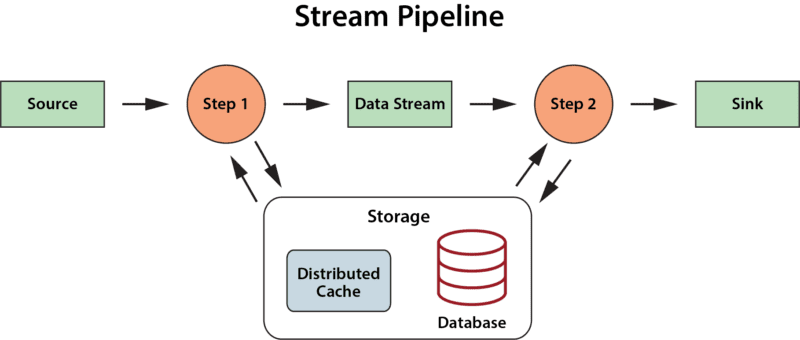
More recent stream-processing platforms, such as Apache Flink, have incorporated stateful stream processing into their architectures in the form of key-value stores or databases that the application can make use of to enhance its analysis. But they do not offer a specific semantic model which applications can leverage to organize and track useful state information and thereby deepen their ability to analyze data streams.
The answer to this challenge may be found in the digital twin model. While this term was coined by Dr. Michael Grieves (U. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report. This model offers key insights into how state data can be organized within stream-processing applications for maximum effectiveness. In particular, it suggests that applications implement a stateful model of the physical data sources that generate event streams, and that the application maintain separate state information for each data source. For example, using the digital twin model, a rental car company can track and analyze telemetry from each car in its fleet with digital twins:
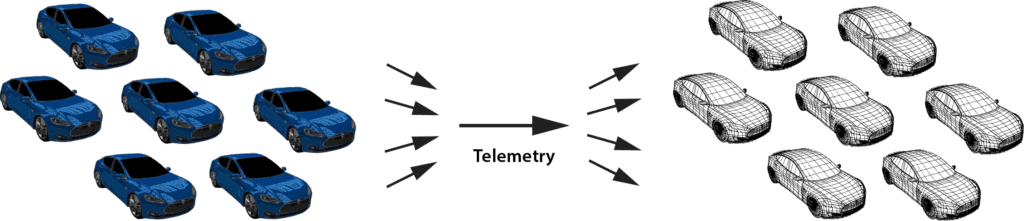
The digital twin model thereby provides an intuitive approach to organizing state data, and, by shifting the focus of analysis from the event stream to the data sources, it potentially enables much deeper introspection than previously possible. With the digital twin model, an application can conveniently track all relevant information about the evolving state of physical data sources. It can then analyze incoming events in this rich context to provide high quality insights, alerting, and feedback. For example, digital twins of medical freezers could track detailed facts about the specific model, its service history, environmental conditions, and usage patterns for each physical unit to help analyze telemetry from a temperature sensor and make more informed predictions about possible impending failures.
Beyond providing a powerful semantic model for stateful stream processing, digital twins also offer advantages for software engineering because they can take advantage of well understood object-oriented programming techniques. A digital twin can be implemented as a data class which encapsulates both state data (including a time-ordered event collection) and methods for updating and analyzing that data. Analytics methods can range from simple sequential code to machine learning algorithms or rules engines. These methods also can reach out to databases to access and update historical data sets.
For each physical data source, an instance of a digital twin model is created by the stream-processing system to receive and analyze events. It is the responsibility of the system to correlate data from a given data source for delivery to each instance of a physical twin. In many applications, a stream-processing system may host thousands (or more) digital twins to handle the workload from its data sources. In an upcoming blog, we will look at how in-memory data grids provide a highly scalable platform for hosting digital twins.
One parting thought concerns the granularity of a digital twin. Does it encompass a model of a single sensor or that of a subsystem comprising multiple sensors? As with object-oriented programming in general, the answer is in the hands of the application developer, who must make choices about which data (and event streams) are logically related and need to be encapsulated in a single entity for analysis to meet the application’s goals.
The digital twin model provides a powerful organizational tool that focuses on the state of data sources instead of just the data within event streams. With this additional context, it magnifies the developer’s ability to implement deep introspection and represents a new way of thinking about stateful stream processing.
The post The Digital Twin: A Foundational Concept for Stateful Stream Processing appeared first on ScaleOut Software.
]]>