The post Why Use “Real-Time Digital Twins” for Streaming Analytics? appeared first on ScaleOut Software.
]]>
What Problems Does Streaming Analytics Solve?
To understand why we need real-time digital twins for streaming analytics, we first need to look at what problems are tackled by popular streaming platforms. Most if not all platforms focus on mining the data within an incoming message stream for patterns of interest. For example, consider a web-based ad-serving platform that selects ads for users and logs messages containing a timestamp, user ID, and ad ID every time an ad is displayed. A streaming analytics platform might count all the ads for each unique ad ID in the latest five-minute window and repeat this every minute to give a running indication of which ads are trending.
Based on technology from the Trill research project, the Microsoft Stream Analytics platform offers an elegant and powerful platform for implementing applications like this. It views the incoming stream of messages as a columnar database with the column representing a time-ordered history of messages. It then lets users create SQL-like queries with extensions for time-windowing to perform data selection and aggregation within a time window, and it does this at high speed to keep up with incoming data streams.
Other streaming analytic platforms, such as open-source Apache Storm, Flink, and Beam and commercial implementations such as Hazelcast Jet, let applications pass an incoming data stream through a pipeline (or directed graph) of processing steps to extract information of interest, aggregate it over time windows, and create alerts when specific conditions are met. For example, these execution pipelines could process a stock market feed to compute the average stock price for all equities over the previous hour and trigger an alert if an equity moves up or down by a certain percentage. Another application tracking telemetry from gas meters could likewise trigger an alert if any meter’s flow rate deviates from its expected value, which might indicate a leak.
What’s key about these stream-processing applications is that they focus on examining and aggregating properties of data communicated in the stream. Other than by observing data in the stream, they do not track the dynamic state of the data sources themselves, and they don’t make inferences about the behavior of the data sources, either individually or in aggregate. So, the streaming analytics platform for the ad server doesn’t know why each user was served certain ads, and the market-tracking application does not know why each equity either maintained its stock price or deviated materially from it. Without knowing the why, it’s much harder to take the most effective action when an interesting situation develops. That’s where real-time digital twins can help.
The Need for Real-Time Digital Twins
Real-time digital twins shift the application’s focus from the incoming data stream to the dynamically evolving state of the data sources. For each individual data source, they let the application incorporate dynamic information about that data source in the analysis of incoming messages, and the application can also update this state over time. The net effect is that the application can develop a significantly deeper understanding about the data source so that it can take effective action when needed. This cannot be achieved by just looking at data within the incoming message stream.
For example, the ad-serving application can use a real-time digital twin for each user to track shopping history and preferences, measure the effectiveness of ads, and guide ad selection. The stock market application can use a real-time digital twin for each company to track financial information, executive changes, and news releases that explain why its stock price starts moving and filter out trades that don’t fit desired criteria.
Also, because real-time digital twins maintain dynamic information about each data source, applications can aggregate this highly curated data instead of just aggregating data in the data stream. This gives users deeper insights into the overall state of all data sources and boosts “situational awareness” that is hard to maintain by just looking at the message stream.
An Example
Consider a trucking fleet that manages thousands of long-haul trucks on routes throughout the U.S. Each truck periodically sends telemetry messages about its location, speed, engine parameters, and cargo status (for example, trailer temperature) to a real-time monitoring application at a central location. With traditional streaming analytics, personnel can detect changes in these parameters, but they can’t assess their significance to take effective, individualized action for each truck. Is a truck stopped because it’s at a rest stop or because it has stalled? Is an out-of-spec engine parameter expected because the engine is scheduled for service or does it indicate that a new issue is emerging? Has the driver been on the road too long? Does the driver appear to be lost or entering a potentially hazardous area?
The use of real-time digital twins provides the context needed for the application to answer these questions as it analyzes incoming messages from each truck. For example, it can keep track of the truck’s route, schedule, cargo, mechanical and service history, and information about the driver. Using this information, it can alert drivers to impending problems, such as road blockages, delays or emerging mechanical issues. It can assist lost drivers, alert them to erratic driving or the need for rest stops, and help when changing conditions require route updates.
The following diagram shows a truck communicating with its associated real-time digital twin. (The parallelogram represents application code.) Because the twin holds unique contextual data for each truck, analysis code for incoming messages can provide highly focused feedback that goes well beyond what is possible with traditional streaming analytics:
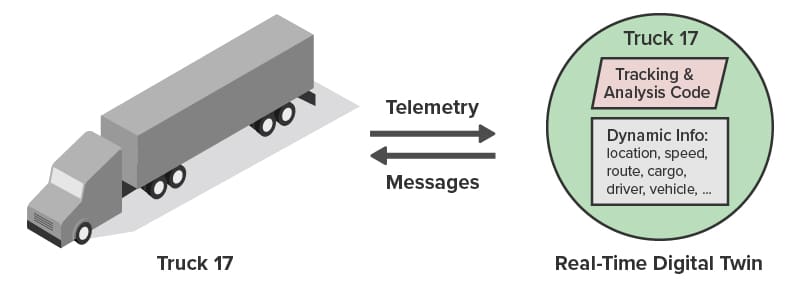
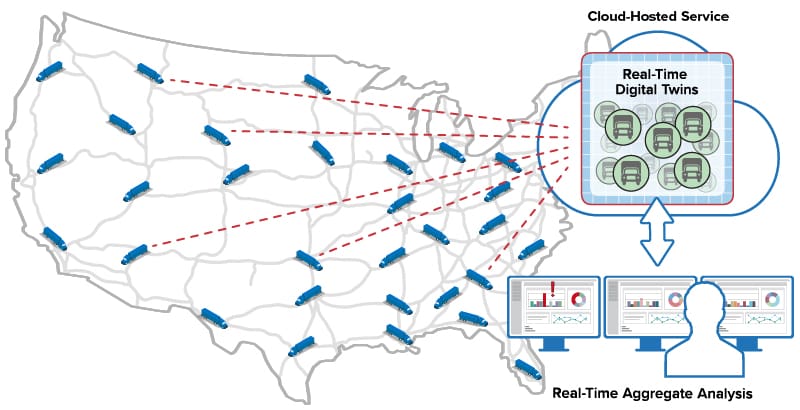
As illustrated below, the ScaleOut Digital Twin Streaming Service runs as a cloud-hosted service in the Microsoft Azure cloud to provide streaming analytics using real-time digital twins. It can exchange messages with thousands of trucks across the U.S., maintain a real-time digital twin for each truck, and direct messages from that truck to its corresponding twin. It simplifies application code, which only needs to process messages from a given truck and has immediate access to dynamic, contextual information that enhances the analysis. The result is better feedback to drivers and enhanced overall situational awareness for the fleet.
runs as a cloud-hosted service in the Microsoft Azure cloud to provide streaming analytics using real-time digital twins. It can exchange messages with thousands of trucks across the U.S., maintain a real-time digital twin for each truck, and direct messages from that truck to its corresponding twin. It simplifies application code, which only needs to process messages from a given truck and has immediate access to dynamic, contextual information that enhances the analysis. The result is better feedback to drivers and enhanced overall situational awareness for the fleet.
Lower Complexity and Higher Performance
While the functionality implemented by real-time digital twins can be replicated with ad hoc solutions that combine application servers, databases, offline analytics, and visualization, they would require vastly more code, a diverse combination of skill sets, and longer development cycles. They also would encounter performance bottlenecks that require careful analysis to measure and resolve. The real-time digital twin model running on ScaleOut Software’s integrated execution platform sidesteps these obstacles.
Scaling performance to maintain high throughput creates an interesting challenge for traditional streaming analytics platforms because the work performed by their task pipelines does not naturally map to a set of processing cores within multiple servers. Each pipeline stage must be accelerated with parallel execution, and some stages require longer processing time than others, creating bottlenecks in the pipeline.
In contrast, real-time digital twins naturally create a uniformly large set of tasks that can be evenly distributed across servers. To minimize network overhead, this mapping follows the distribution of in-memory objects within ScaleOut’s in-memory data grid, which holds the state information for each twin. This enables the processing of real-time digital twins to scale transparently without adding complexity to either applications or the platform.
Summing Up
Why use real-time digital twins? They solve an important challenge for streaming analytics that is not addressed by other, “pipeline-oriented” platforms, namely, to simultaneously track the state of thousands of data sources. They use contextual information unique to each data source to help interpret incoming messages, analyze their importance, and generate feedback and alerts tailored to that data source.
Traditional streaming analytics finds patterns and trends in the data stream. Real-time digital twins identify and react to important state changes in the data sources themselves. As a result, applications can achieve better situational awareness than previously possible. This new way of implementing streaming analytics can be used in a wide range of applications. We invite you to take a closer look.
The post Why Use “Real-Time Digital Twins” for Streaming Analytics? appeared first on ScaleOut Software.
]]>The post The Digital Twin: A Foundational Concept for Stateful Stream Processing appeared first on ScaleOut Software.
]]>The following diagram depicts a typical stream processing pipeline processing events from many data sources:
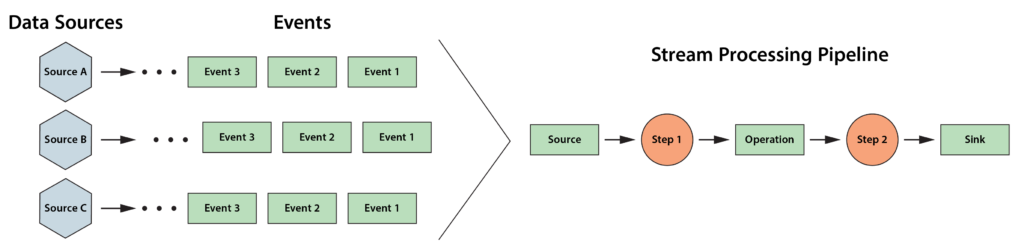
More recent stream-processing platforms, such as Apache Flink, have incorporated stateful stream processing into their architectures in the form of key-value stores or databases that the application can make use of to enhance its analysis. But they do not offer a specific semantic model which applications can leverage to organize and track useful state information and thereby deepen their ability to analyze data streams.
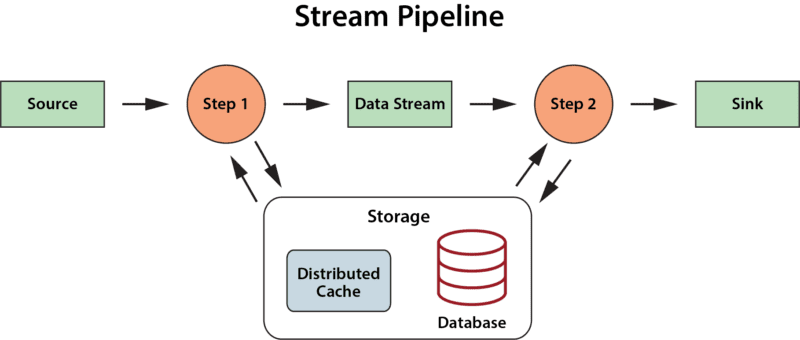
The answer to this challenge may be found in the digital twin model. While this term was coined by Dr. Michael Grieves (U. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report. This model offers key insights into how state data can be organized within stream-processing applications for maximum effectiveness. In particular, it suggests that applications implement a stateful model of the physical data sources that generate event streams, and that the application maintain separate state information for each data source. For example, using the digital twin model, a rental car company can track and analyze telemetry from each car in its fleet with digital twins:
The digital twin model thereby provides an intuitive approach to organizing state data, and, by shifting the focus of analysis from the event stream to the data sources, it potentially enables much deeper introspection than previously possible. With the digital twin model, an application can conveniently track all relevant information about the evolving state of physical data sources. It can then analyze incoming events in this rich context to provide high quality insights, alerting, and feedback. For example, digital twins of medical freezers could track detailed facts about the specific model, its service history, environmental conditions, and usage patterns for each physical unit to help analyze telemetry from a temperature sensor and make more informed predictions about possible impending failures.
Beyond providing a powerful semantic model for stateful stream processing, digital twins also offer advantages for software engineering because they can take advantage of well understood object-oriented programming techniques. A digital twin can be implemented as a data class which encapsulates both state data (including a time-ordered event collection) and methods for updating and analyzing that data. Analytics methods can range from simple sequential code to machine learning algorithms or rules engines. These methods also can reach out to databases to access and update historical data sets.
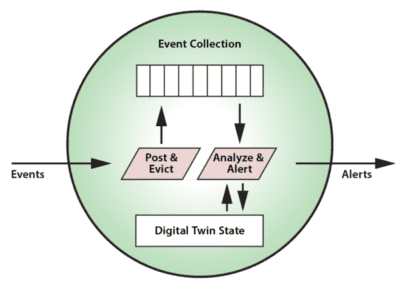
For each physical data source, an instance of a digital twin model is created by the stream-processing system to receive and analyze events. It is the responsibility of the system to correlate data from a given data source for delivery to each instance of a physical twin. In many applications, a stream-processing system may host thousands (or more) digital twins to handle the workload from its data sources. In an upcoming blog, we will look at how in-memory data grids provide a highly scalable platform for hosting digital twins.
One parting thought concerns the granularity of a digital twin. Does it encompass a model of a single sensor or that of a subsystem comprising multiple sensors? As with object-oriented programming in general, the answer is in the hands of the application developer, who must make choices about which data (and event streams) are logically related and need to be encapsulated in a single entity for analysis to meet the application’s goals.
The digital twin model provides a powerful organizational tool that focuses on the state of data sources instead of just the data within event streams. With this additional context, it magnifies the developer’s ability to implement deep introspection and represents a new way of thinking about stateful stream processing.
The post The Digital Twin: A Foundational Concept for Stateful Stream Processing appeared first on ScaleOut Software.
]]>