The post Founder & CEO William Bain Discusses Real-Time Digital Twins with TechStrong TV appeared first on ScaleOut Software.
]]>Watch the video here.

The post Founder & CEO William Bain Discusses Real-Time Digital Twins with TechStrong TV appeared first on ScaleOut Software.
]]>The post Track Thousands of Assets in a Time of Crisis Using Real-Time Digital Twins appeared first on ScaleOut Software.
]]>What are real-time digital twins and why are they useful here?
A “real-time digital twin” is a software concept that can track the key parameters for an individual asset, such as a box of masks or a ventilator, and update these parameters in milliseconds as messages flow in from personnel in the field (or directly from smart devices). For example, the parameters for a ventilator could include its identifier, make and model, current location, status (in use, in storage, broken), time in use, technical issues and repairs, and contact information. The real-time digital twin software tracks and updates this information using incoming messages whenever significant events affecting the ventilator occur, such as when it moves from place to place, is put in use, becomes available, encounters a mechanical issue, has an expected repair time, etc. This software can simultaneously perform these actions for hundreds of thousands of ventilators to keep this vital logistical information instantly available for real-time analysis.
With up-to-date information for all ventilators immediately at hand, analysts can ask questions like:
- “Where are all the available ventilators at this moment?”
- “Show me a list of currently available or soon to be available ventilators in my county right now.”
- “What is the average time that ventilators have been in use per patient for each state?
- “Which hospital in a given state has the most unused ventilators?”
- “How many ventilators currently are in repair by make?”
These questions can be answered using the latest data as it streams in from the field. Within seconds, the software performs aggregate analysis of this data for all real-time digital twins. By avoiding the need to create or connect to complex databases and ship data to offline analytics systems, it can provide timely answers quickly and easily.
Besides just tracking assets, real-time digital twins also can track needs. For example, real-time digital twins of hospitals can track quantities of needed supplies in addition to supplies of assets on hand. This allows quick answers to questions such as:
- “Show me the percentage shortfall in ventilators by state.”
- “Which hospitals in a state currently have more than a 25% shortfall (or excess) in ventilators?”
Unlike powerful big data platforms which focus on deep and often lengthy analysis to make future projections, what real-time digital twins offer is timeliness in obtaining quick answers to pressing questions using the most current data. This allows decision makers to maximize their situational awareness in rapidly evolving situations.
Of course, keeping data up to date relies on the ability to send messages to the software hosting real-time digital twins whenever a significant event occurs, such as when a ventilator is taken out of storage or activated for a patient. Field personnel with mobile devices can send these messages over the Internet to the cloud service. It also might be possible for smart devices like ventilators to send their own messages automatically when activated and deactivated or if a problem occurs.
The following diagram illustrates how real-time digital twins running in a cloud service can receive messages from thousands of physical data sources across the country:
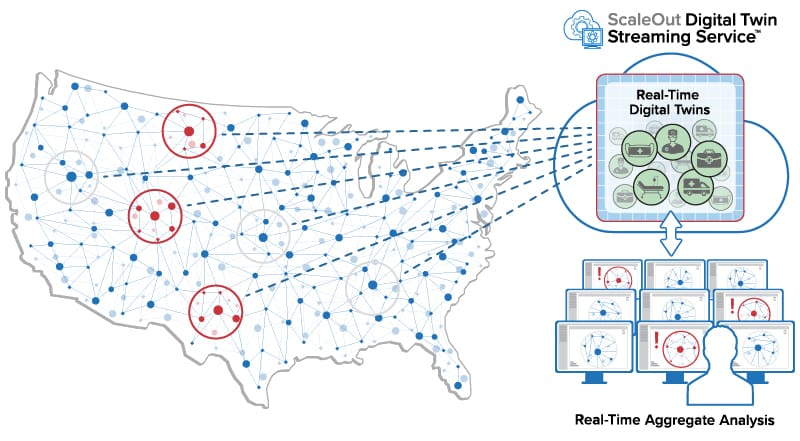
How Do Real-Time Digital Twins Work?
What gives real-time digital twins their agility compared to complex, enterprise-based data management systems is their simplicity. A real-time digital twin consists of two components: a software object describing the properties of the physical asset being tracked and a software method (that is, code) which describes how to update these properties when an incoming message arrives. This method also can analyze changes in the properties and send an alert when conditions warrant.
Consider a simple example in which a message arrives signaling that a ventilator has been activated for a patient. The software method receives the message and then records the activation time in a property within the associated object. When the ventilator is deactivated, the method can both record the time and update a running average of usage time for each patient. This allows analysts to ask, for example, “What is the average time in use for all ventilators by state?” which could serve as indication of increased severity of cases in some states.
Because of this extremely simple software formulation, real-time digital twins can be created and enhanced quickly and easily. For example, if analysts observe that several ventilators are being marked as failed, they could add properties to track the type of failure and the average time to repair.
The power of real-time digital twin approach lies in the use of a scalable, in-memory computing system which can host thousands (or even millions) of twins to track very large numbers of assets in real time. The computing system also has the ability to perform aggregate analytics in seconds on the continuously evolving data held in the twins. This enables analysts to obtain immediate results with the very latest information and make decisions within minutes.
In this time of crisis, it’s likely the case that the technology of real-time digital twins has arrived at the right time to help our overtaxed medical professionals.
Note: To the extent possible, ScaleOut Software will make its cloud-based ScaleOut Digital Twin Streaming Service available free of charge (except for fees from the cloud provider) for institutions needing help tracking data to assist in the COVID19 crisis.
available free of charge (except for fees from the cloud provider) for institutions needing help tracking data to assist in the COVID19 crisis.
The post Track Thousands of Assets in a Time of Crisis Using Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post The Next Generation in Logistics Tracking with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>Traditional platforms for streaming analytics don’t offer the combination of granular data tracking and real-time aggregate analysis that logistics applications in operational environments such as these require. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. What’s needed is the ability to easily track incoming telemetry from each individual store so that issues can be quickly analyzed, prioritized, and handled. At the same time, it’s important to be able to combine data and generate analytics results for all stores in real time so that strategic decisions, such as running flash sales or replenishing hot-selling inventory, can be made without unnecessary delay.
The answer to these challenges is a new software concept called the “real-time digital twin.” This breakthrough approach for streaming analytics lets application developers separately track and analyze incoming telemetry from each individual store while the platform handles the task of filtering out telemetry associated with other stores. This dramatically simplifies application code and automatically scales its use by letting the execution platform run this code simultaneously for all stores. In addition, the platform provides fast, in-memory data storage so that the application can easily and quickly record both telemetry and analytics results for each store. Lastly, built-in, aggregate analysis tools make it easy to immediately roll up these analytics results across all stores and continuously keep track of the big picture.
The ScaleOut Digital Twin Streaming Service, which runs in the Microsoft Azure cloud, hosts real-time digital twins for applications like these that need to track thousands of data sources. It can receive telemetry from retail stores over the Internet using event delivery systems such as Azure IoT Event Hub, AWS, Kafka, and REST, and it can respond back to the retail stores in milliseconds. In addition, the cloud service hosts aggregate analytics that can continuously complete every few seconds, avoiding the need to wait for offline results from a data lake.
The following diagram illustrates a nationwide chain of retail outlets streaming telemetry to their counterpart real-time digital twins running in the cloud service. It also shows real-time aggregate results being fed to displays for immediate consumption by operations managers.
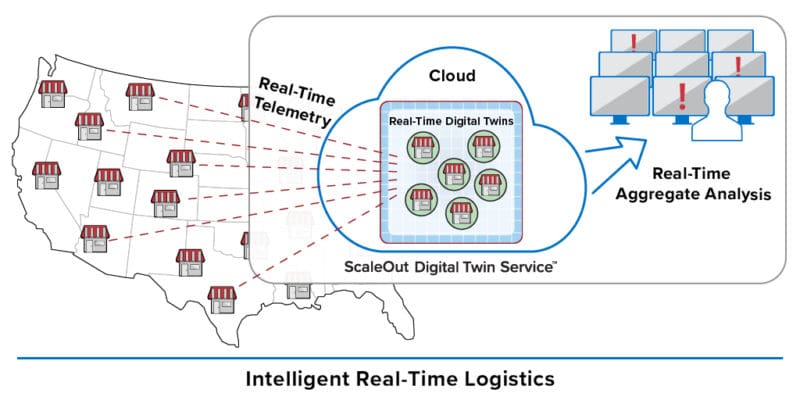
With this ground-breaking technology, operations managers now can easily manage logistics for thousands of retail outlets, immediately identify and respond to issues, and optimize operations in real time. By harnessing the power and simplicity of the real-time digital twin model, application developers can quickly implement and customize streaming analytics to meet these mission-critical requirements. With the real-time digital twin model, the next generation of streaming analytics has arrived.
The post The Next Generation in Logistics Tracking with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Reports of Scale-Out’s Demise Are Greatly Exaggerated appeared first on ScaleOut Software.
]]>Scale-Up Versus Scale-Out
Scaling up is the process of migrating to an increasingly more powerful single server to process a workload faster or to handle a growing workload that fits within the server. Usually this means moving to a server with more CPU cores, greater memory capacity, and higher-end networking and storage options.

At some point, scaling up becomes costly, and workloads grow beyond what even a high end server can handle. To overcome this limitation, scaling out distributes a workload across a cluster of servers working together. Now CPU, memory, and storage resources can grow without predefined limits. Unless network bandwidth also grows proportionally to the number of servers, it usually becomes the limiter in scaling. (Supercomputing systems use scalable networks such as torus interconnects; commodity clusters typically use Ethernet switches with fixed bandwidth.)
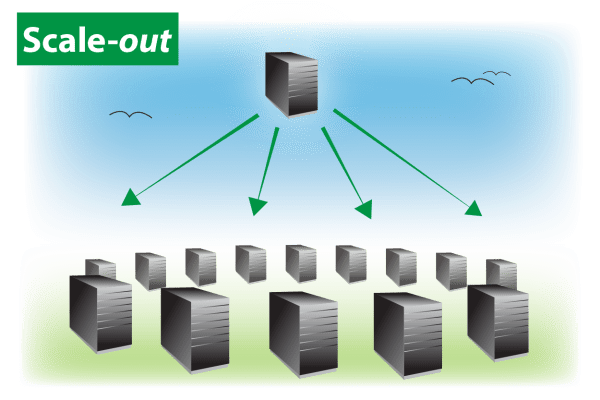
There are several reasons why scaling out will continue to serve an important role, and to be sure, it’s more than the size of the workload that matters. First, scaling out enables computing capacity to be deployed incrementally and economically as the size of the workload increases using clusters of relatively small servers (instead of investing in a single, expensive multicore server to handle the highest anticipated workload). Second, scale-out’s ability to provide high availability will always be important to mission-critical applications, even if the problem size fits within one server. Third, technology changes so fast that today’s pricey, top of the line server will quickly become tomorrow’s dusty objet d’art as it awaits recycling. (Cloud computing just changes that to a per-hour calculation – top-of-the-line servers may not be cost-effective.)
Moreover, in our experience, many analytics applications host data sets much larger than the 100 GB size Microsoft cites as a typical upper bound, and new applications drive this trend by taking advantage of newly available memory. (We often host data sets in the terabytes in our in-memory data grid.) These data sets require a cluster to keep in memory. For example, a recent data set used in an e-commerce analytics application held 40 million objects totaling about 2 TB of data including replicas. This data set could not be stored in one server on Amazon EC2, even using their largest instance type; it required a cluster of servers to hold the entire data set in memory. Also, it’s often not advisable to store such large data sets in the smallest possible cluster of servers; there are benefits to using a larger cluster of small servers (see below).
That said, it’s clear that scale-out infrastructures, including middleware execution platforms like Hadoop, need to evolve to make full use of large memory capacity and many cores available within each server. As Hadoop gained popularity over the last few years, software architects have been focused on efficiently scaling out with minimum overhead, and the Microsoft paper reminds us to rethink our scale-up algorithms and extract maximum value out of new technology as it enters the mainstream. For example, fully using available cores with multi-threading and minimizing latency for inter-process data transfers with memory-mapped files can squeeze more performance out of modern servers.
Finding the Right Balance
Once we accept that scale-out is an integral element of mission-critical deployments, it’s finding the right balance between memory, CPU, and network bandwidth that matters in driving overall performance. One or more of these resources tends to lag in performance at any point as technology’s evolves, and software design has to compensate for that. For example, right now network bandwidth in commodity networks tends to be the laggard, making it costly (in time) to ship the 100s of gigabytes a server can now hold. (For example, a 10 Gbps network requires 80 seconds at maximum bandwidth to send 100 gigabytes between servers; scatter/gather of many objects greatly increases that time.) As the amount of data stored in each server grows, load-balancing between servers takes longer, and the delays eventually can impact availability. Scaling out can help this by distributing the data set across more servers, thereby reducing network delays in rebalancing workloads after a server is added or removed.
In sum, it’s not “either-or” — scale-out is here to stay. However, it’s absolutely true that maintaining support for the latest memory and processor technology is crucial to reaping the benefits of scale-up, integrating it with scale-out, and thereby maximizing performance, availability, and cost-effectiveness.
The post Reports of Scale-Out’s Demise Are Greatly Exaggerated appeared first on ScaleOut Software.
]]>The post Using In-Memory Data Grids for ETL on Streaming Data appeared first on ScaleOut Software.
]]>
Using ETL to Feed the Data Warehouse
A key challenge for any data warehouse is to supply data to it in a format that can be readily ingested and analyzed, and this is the role of the well-known process called “extract-transform-load” (ETL). In the case of Hadoop, this usually means extracting data from external sources and transforming them into a form that can be stored in HDFS for use by MapReduce applications. When incoming data arrives as collections of files, it’s a straightforward matter either to just copy them into HDFS or to periodically run a batch MapReduce application which reads in the files, transforms the data as needed, and outputs it to HDFS.
Consider a company that sends end-of-day reports from its field offices to the data warehouse for aggregate analysis. The data warehouse can start up a MapReduce application after the last report has been uploaded to read from an external file system, reorganize it, and then output the results to HDFS. For example, this application might use the keys output from the mappers to join data for various fields (such as, revenue, volume, etc.) across all offices so that the reducers can output this data to HDFS by field instead of by office.
Implementing ETL using MapReduce offers several advantages. It makes use of the data warehouse’s parallel infrastructure to quickly process the data on a cluster of servers. It also leverages the development team’s skill sets in developing MapReduce applications to minimize overall cost. Lastly, it avoids the need to deploy a variety of technologies, which creates unnecessary complexity and headaches for system administrators.
The Challenge: Real-Time ETL
Running ETL using a batch MapReduce job works fine for static data, such as file-based, end-of-day reports. But what about streaming data that continuously flows into the data warehouse? For example, consider an e-commerce website that accepts orders which flow to the data warehouse for analysis to identify patterns and issues. The website generates a continuous stream of orders which must be stored as HDFS files by an ETL processing step, as illustrated by the following diagram:
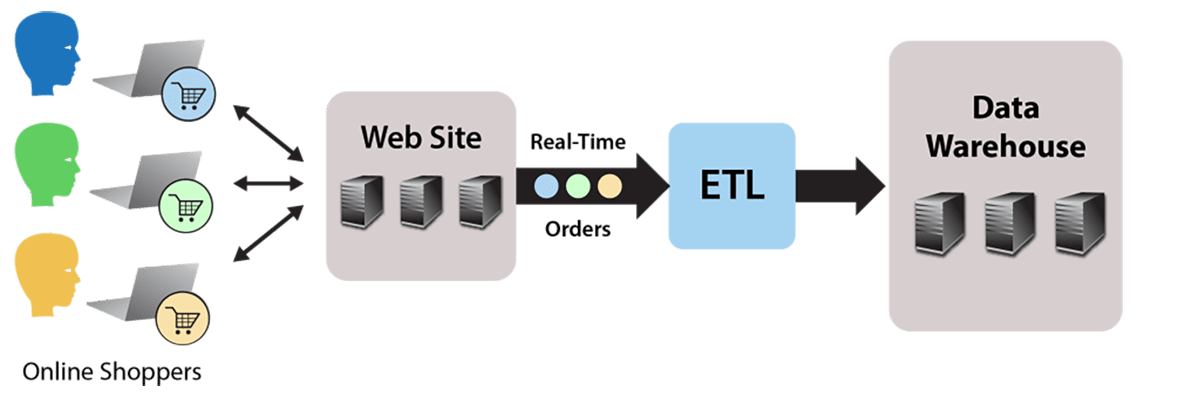
The simplest possible approach to this problem is to store the incoming orders as individual files in HDFS. Of course, this does not allow for any data translation prior to saving the files in the data warehouse. Also, this creates many file I/O operations both when loading HDFS and later when reading large numbers of small files during each analysis.
A better solution would be to run a MapReduce application that reads the input stream and outputs to HDFS. This enables the translation step to reorganize and consolidate the data as necessary and to efficiently output it to HDFS. By using standard MapReduce instead of another stream processing platform, such as Spark or Storm, the skill sets already employed for the data warehouse can be used instead of requiring a different software stack to perform ETL.
However, the data warehouse’s batch-oriented MapReduce execution environment incurs high scheduling latency (typically 15 seconds or longer) that makes it unsuitable for processing an incoming data stream. Furthermore, this MapReduce application would need to run continuously, tying up resources that were intended for data analysis, not ongoing ETL.
The Solution: Offload to an In-Memory Data Grid Running MapReduce
The streaming ETL challenge can be met by deploying an in-memory data grid with an integrated MapReduce engine, such as ScaleOut hServer, to capture the data stream in real time, perform ETL, and offload the data warehouse. Let’s take a look at how this works.
IMDGs host data in memory and distribute it across a cluster of commodity servers. Using an object-oriented data storage model, they provide APIs for storing, accessing, and updating data objects in well under a millisecond (depending on the size of the object). This enables operational systems to use IMDGs for storing fast-changing, “live” data, such as the data warehouse’s incoming order stream.
An IMDG provides an ideal repository for the data stream, buffering orders as objects within the grid and running the ETL application using built-in MapReduce (more on that below). The IMDG matches the arrival rate of the incoming data stream by adding servers as needed to its cluster, ensuring that both storage capacity and update throughput scale linearly while keeping update times fast. Also, the IMDG maintains high availability using data replication so that if a server fails, the IMDG can continue to handle update requests without delay.
Because IMDGs store data in memory distributed across a cluster of servers, they can easily perform data-parallel computations on stored data, such as the ETL function needed by the data warehouse; they simply make use of the cluster’s processing power to analyze data “in place,” that is, without the need to migrate it to other servers. This enables IMDGs to complete ETL fast (possibly in less than a second) with minimal overhead.
Some IMDGs, such as ScaleOut hServer, can execute standard Hadoop MapReduce applications (i.e., applications which are fully code-compatible with Apache Hadoop), allowing these applications to access in-memory data from the grid and output to HDFS. This enables the ETL function to be deployed as a conventional MapReduce application within the IMDG. The application extracts orders from the grid’s memory, transforms them as required for storage in the data warehouse, and then outputs them to HDFS using standard MapReduce techniques, as illustrated in the following diagram:
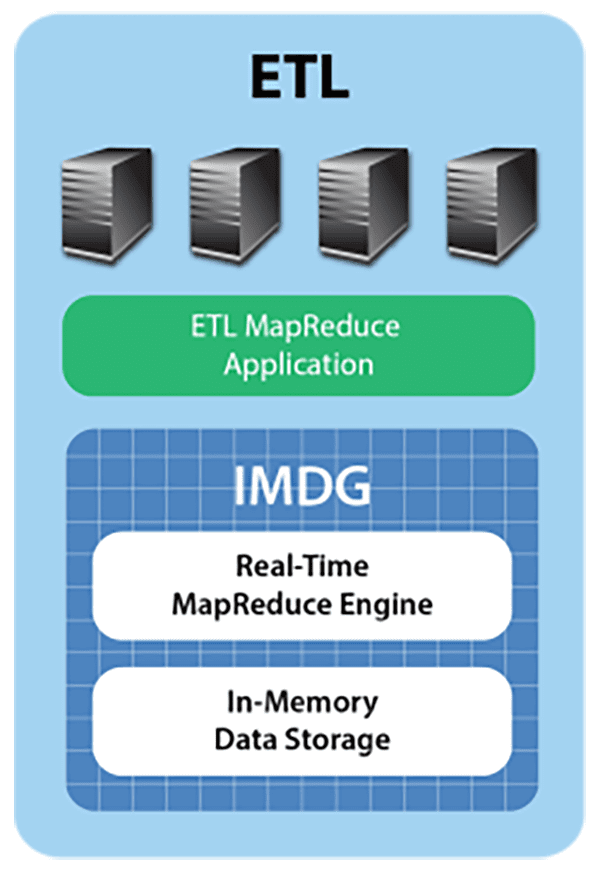
Ensuring Continuous Processing
The use of an IMDG offloads the data warehouse, allowing the MapReduce application performing ETL to run continuously. It also dramatically reduces the latency required to start up each iteration from 15+ seconds to a few milliseconds. Buffering orders in memory while simultaneously migrating them to HDFS ensures that ETL processing seamlessly keeps up with the incoming data stream.
To show how continuous processing can be achieved, the following diagram depicts the use of a “double buffering” strategy to perform ETL processing. IMDGs organize collections of objects within name spaces that can be identified and used as input to a MapReduce application. In this case, while incoming orders are added to one name space, which serves as an input buffer, the MapReduce application extracts orders from a second name space that was previously filled; it then organizes them into an appropriate format and outputs the data to HDFS. Upon completion, the extracted orders are cleared from the associated name space, the name spaces are switched, and the MapReduce application is restarted on the other name space:
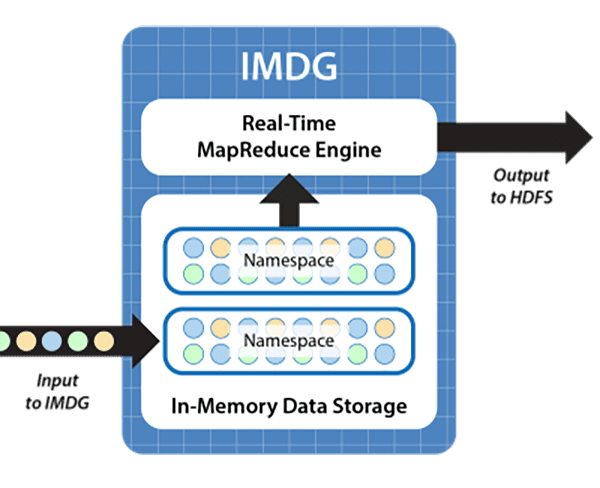
This technique uses the memory of the IMDG to allow orders to flow smoothly into the IMDG while processing by the MapReduce ETL application is ongoing. It requires that sufficient memory be available in the IMDG to buffer incoming order objects during the processing time of the application. Because the IMDG can scale memory capacity by adding servers and because the IMDG fast start-up and data-parallel execution minimize the ETL application’s processing time, continuous processing of incoming orders is ensured.
Summing Up
Hadoop’s powerful analytics capabilities are rapidly making it the centerpiece of next-generation data warehouses. The ability of IMDGs to implement ETL for streaming data enables them to serve as a vital component of these infrastructures. IMDGs which can run MapReduce applications provide the threefold benefits of meeting the low latency requirements for ingesting streaming data, offloading the data warehouse’s execution environment, and leveraging existing Hadoop skills. ETL on streaming data is yet another example of real-time analytics and a prime application for IMDGs.
Perhaps most exciting is that hosting ETL in an IMDG’s real-time analytics engine opens the door to analyzing the order stream (or a clickstream) in real time and generating instant feedback for web users. Over time, the ETL function can evolve to perform real-time analysis, provide guidance, and thereby drive incremental sales. The IMDG’s analytics engine forms a bridge from the data warehouse to customers, helping push the benefits of data analytics to the point of sale where it can have maximum impact.
The post Using In-Memory Data Grids for ETL on Streaming Data appeared first on ScaleOut Software.
]]>The post How Do In-Memory Data Grids Differ from Storm? appeared first on ScaleOut Software.
]]>Quick Review: IMDGs Provide Fast Data Storage
(The following description of in-memory data grids (IMDGs) is excerpted from last week’s blog post; see that post for more details.)
IMDGs host data in memory and distribute it across a cluster of commodity servers. Using an object-oriented data storage model, they provide APIs for updating data objects typically in well under a millisecond (depending on the size of the object). This enables operational systems to use IMDGs for storing, accessing, and updating fast-changing, “live” data, while maintaining fast access times even as the storage workload grows.
Data storage needs can easily grow as more users store data within an IMDG. IMDGs accommodate this growth by adding servers to the cluster and automatically rebalancing stored data across the servers. This ensures that both capacity and throughput scale linearly with growth in the workload, and access and update times remain low regardless of the workload’s size. Moreover, IMDGs maintain stored data with high availability using data replication so that if a server fails, operational systems can continuously handle access requests and update requests without delay.
IMDGs Perform Data-Parallel Computation
Because IMDGs store data in memory distributed across a cluster of servers, they easily can perform data-parallel computations on stored data; they simply make use of the cluster’s processing power to analyze data “in place,” that is, without the need to migrate it to other servers. This enables IMDGs to provide fast results (often in milliseconds) with minimal overhead.
The following diagram of the architecture used by ScaleOut Analytics Server and ScaleOut hServer shows a stream of incoming changes which are applied to the grid’s memory-based data store using API updates. The real-time analytics engine performs data parallel computation on stored data, combines the results across the cluster, and outputs a combined stream of alerts to the operational system.
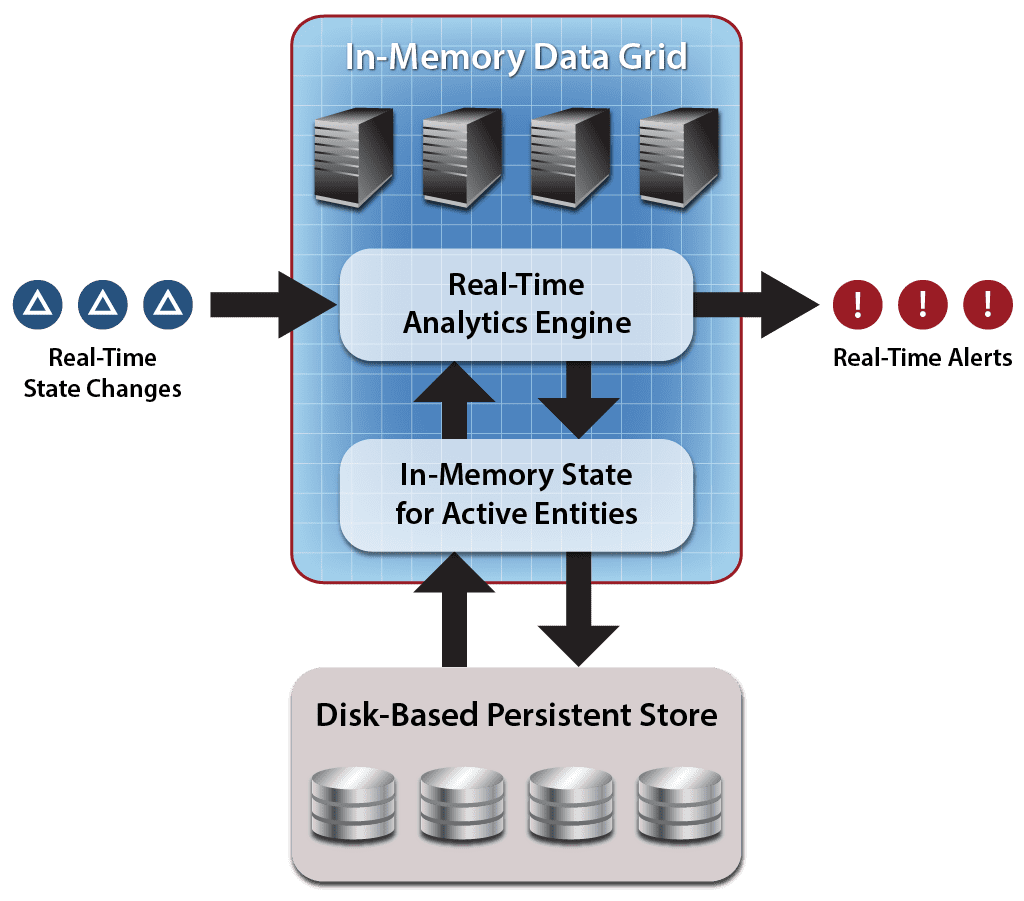
A significant aspect of the IMDG’s architecture for data analytics is that it performs computations on data hosted in memory – not specifically on an incoming data stream. This memory-based storage is continuously updated by an incoming data stream, so the computation has access to the latest changes to the data. However, the computation also has access to the history of changes manifested by the current state of data stored in the grid. This gives the computation a rich data set for analysis that includes both the incoming data stream and the application’s persistent state.
What is Storm?
Storm originally was developed by Nathan Marz at Backtype to overcome the limitations of Hadoop in analyzing streams of incoming data, such as Twitter streams and web log files. Its goal was to provide real-time, continuous computation that is both scalable and fault tolerant. Described both as stream processing and event processing, its computation model incorporates a combination of task parallelism and pipelining. The developer describes two basic entities: “spouts,” which generate streams of data in the form of ordered tuples, and “bolts,” which process incoming streams and optionally generate outgoing streams for other bolts. Spouts and bolts are organized into an acyclic, directed graph to create an executable configuration. (See this slide deck, among many available, for a more detailed explanation.)
The following diagram illustrates a Storm configuration of streams and bolts processing a set of input streams and generating a set of output streams. The green circles represent tuples within an input stream, and the blue boxes represent bolts. Note that spouts which generate the input streams are not shown in the diagram. The orange circles represent an optional output data stream, which may be implemented by the bolts in an arbitrary manner (e.g., as API calls to an external agent instead of as a stream of tuples).
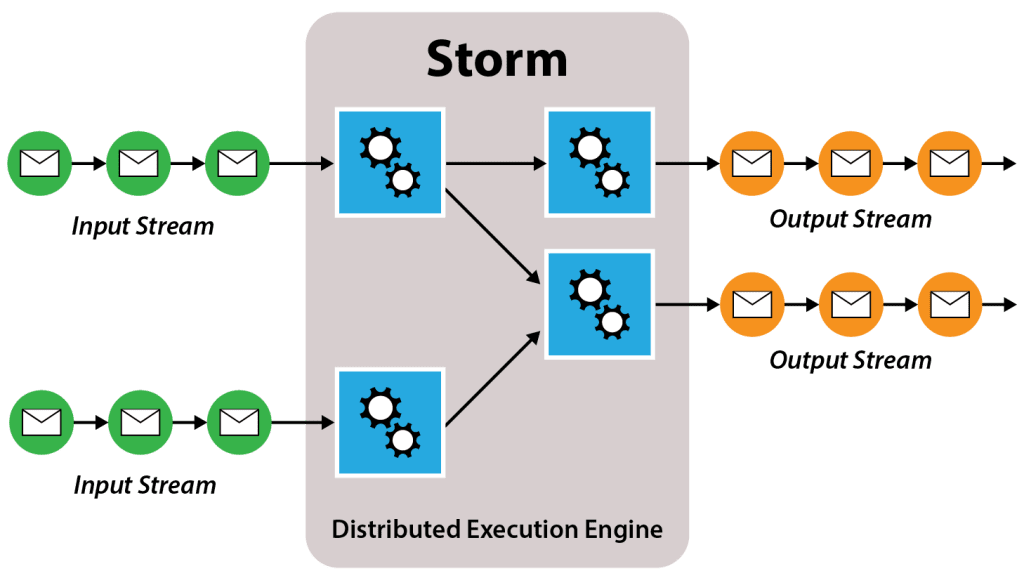
Application developers specify several aspects of the configuration, such as the number of tasks that can be spawned to execute each bolt, and the manner in which an incoming stream’s tuples are distributed across these tasks. Various groupings implement characteristics that correspond to behaviors found in Hadoop MapReduce. For example, the shuffle grouping implements a random distribution of tuples to tasks akin to input to mappers, and the field grouping implements a key-based partitioning very close to that used as input to reducers. Other groupings also are available, such as “all,” which is equivalent to multicast.
Storm implements and executes a specified configuration using a hierarchy of nodes whose state and fault-tolerance are maintained by the open-source Zookeeper cluster manager. A master node (called Nimbus) manages a set of worker nodes (called Supervisors), which run tasks. Strategies are available to handle failures of each of these components and to ensure that stream tuples are reliably processed.
Comparison of IMDGs to Storm: Providing Continuous Execution
A major strength of Storm is its continuous execution model. Once a configuration has been deployed, incoming data streams can be processed without scheduling delays, thereby providing uninterrupted, real-time results. This overcomes a major drawback of Hadoop MapReduce, which processes data in batch jobs with significant latency (often 15+ seconds) in starting up each job.
IMDGs approximate Storm’s continuous execution model in two ways. First they allow continuous, overlapped updates to in-memory state, enabling them to handle high arrival rates of incoming data (e.g., 1000s of updates per second for each IMDG server in a cluster). Both IMDGs and Storm scale out to increase throughput. Second, some IMDGs allow data-parallel operations to be performed continuously with very low startup delay (typically a few milliseconds). This allows IMDGs to output a stream of analysis results that matches the low latency required by operational systems. (Unlike Storm, IMDGs such as ScaleOut hServer also precisely match Hadoop’s MapReduce semantics, which require that reducers be able to process all key-value pairs emitted by the mappers in a given computation.)
Stateless versus Stateful Data Model
Storm’s data model describes a set of tuple streams. Bolts analyze and filter these streams, creating new streams to hold their results. While bolts are unconstrained in their ability to access and update external stores, such as IMDGs or file-based NoSQL stores (e.g., Mongo DB or Cassandra), this is not a central aspect of their processing model. Put another way, Storm does not provide any particular semantics for managing stateful data.
In contrast, IMDGs are organized around a stateful data model implemented by an object-oriented, in-memory store which is both scalable and highly available. This store is intended to hold ongoing, business-logic state implemented by collections of objects representing fast-changing data used in operational environments. In previous blog posts, we have seen examples in e-commerce (e.g., session-state and shopping carts) and financial services (e.g., portfolios and stock histories). Incoming data streams update these entities, which hold information that persists and evolves over their lifetimes. Making these entities “first class” citizens in the computation model simplifies the design of business logic while enabling stream processing using a combination of object-oriented updates and data-parallel computation to both modify and analyze this state.
Complexity of the Computation Model
Where IMDGs and Storm really differ is in their approaches to managing the complexity of the computation model. Like Microsoft Dryad and other parallel execution platforms with task precedence graphs, Storm defines a computation using a directed graph of execution nodes, each of which has a variable number of tasks. While the modular nature of an execution pipeline has appeal, its complexity can quickly become daunting. One reason for this is that the configuration’s graph is represented by sequential code describing bolts and the streams to which they are connected. As the number of bolts and streams grows, it becomes increasingly difficult to visualize their relationships and grasp the application’s overall behavior.
Other parallel systems like Storm with task precedence graphs, such as messaging passing systems and actor models, have demonstrated substantial complexity over the last few decades. Also, the Storm application developer must specify the number of tasks executed by each bolt. As the number of bolts and streams increase, it becomes challenging for the developer to manage the graph, predict the dynamics of its execution, and tune for best performance.
A central reason that IMDGs employ a data-parallel computation model is its simplicity, both in exposition and execution. (Another key reason is that data-parallel computation minimizes data motion which limits scalability. Storm’s data motion between bolts may incur more network overhead than IMDGs and impact scalability, but we have not evaluated this.) Since their application code is inherently straightforward, data-parallel programs are relatively easy to understand, and they don’t need extensive tuning for high performance. Also, separating updates to business logic state from data-parallel analytics simplifies integration into operational systems.
Summing Up
IMDGs offer a platform for scalable, memory-based storage and data-parallel computation which was specifically designed for use in operational systems. Because it incorporates API support for accessing and updating individual data objects and data-parallel analytics, IMDGs are easily integrated into the business logic of these systems.
Storm was designed for a different purpose, namely to analyze streams of data using a continuously running execution pipeline. Its more complex computation model fits this purpose well, and, as a result, Storm embodies a different set of tradeoffs than IMDGs. Clearly, the term “real-time analytics” encompasses a variety of solutions designed to meet diverse business requirements.
The post How Do In-Memory Data Grids Differ from Storm? appeared first on ScaleOut Software.
]]>The post Transforming Retail with Real-Time Analytics appeared first on ScaleOut Software.
]]>Operational Systems Need In-Memory Data Grids
Operational systems typically manage fast-changing client data that constantly streams in for processing by business logic, which updates existing state information and initiates appropriate responses. Some responses provide feedback to clients and others commit changes to persistent storage. For example, an e-commerce system receives requests to view products from web browsers, displays requested products and offers, and sends requested information back to clients. It also receives orders from clients, which it commits to permanent storage, and then it sends out messages to other systems to process these orders.
In-memory data grids (IMDGs) have been used for several years within operational systems to ensure fast responses and to scale throughput as workloads grow. In-memory data grids enable the execution of business logic to scale out across a cluster of servers while holding fast-changing application state in memory accessible to all servers. Memory-based data storage helps minimize response times, and servers can add CPU capacity to handle incremental growth in the workload.
For example, an in-memory data grid can hold session state and shopping carts for an e-commerce web farm, enabling all web servers to quickly and seamlessly access this data as they handle incoming browser requests (which are distributed by an IP load-balancer to web servers):
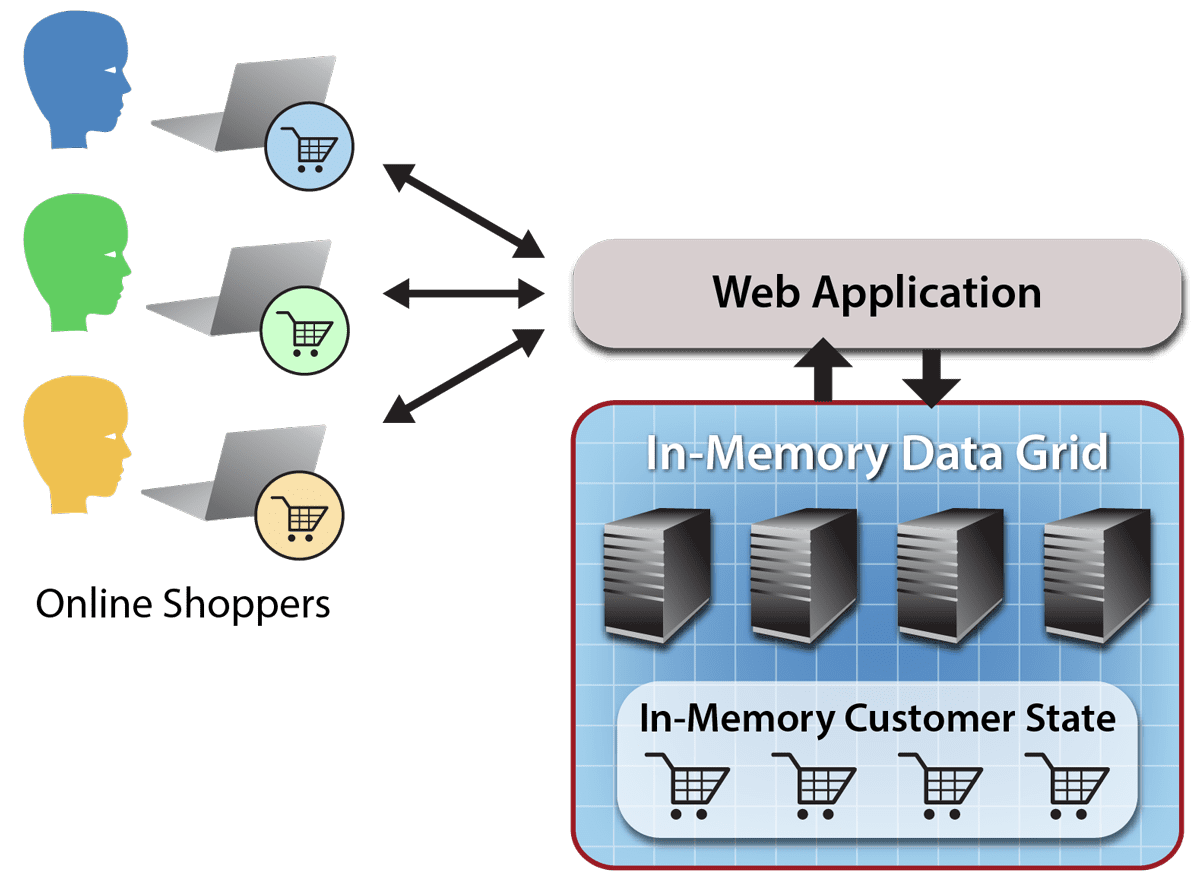
In-Memory Computing: The Engine of Real-Time Analytics
The next step for operational systems is to add real-time analytics, and the easiest way to insert real-time analytics into an operational system is to integrate it with the system’s business logic using an IMDG. By adding real-time analytics to an in-memory data grid, it becomes instantly available to analyze fast-changing data flowing through the system and produce immediate results:
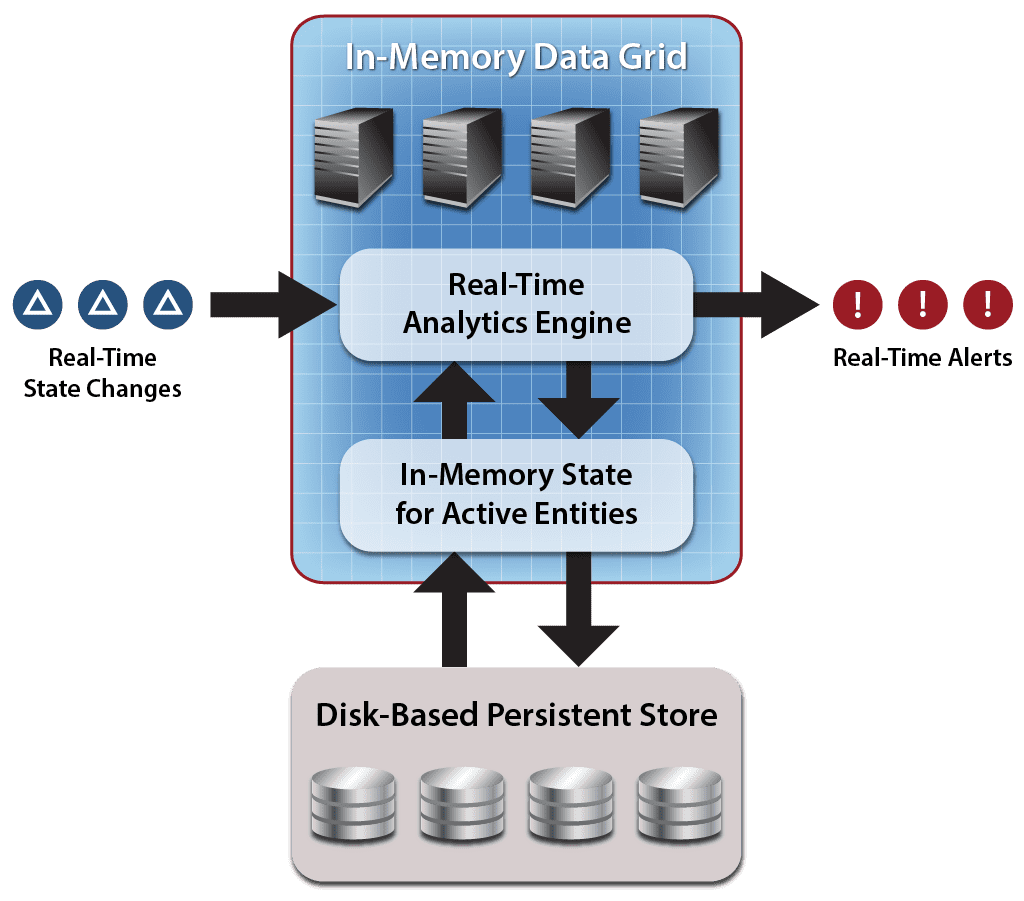
As we have explored in previous blogs, the key to fast response times for real-time analytics is data-parallel programming, that is, examining many data items in parallel using a single algorithm. This approach has two major strengths: (a) it enables the algorithm to be distributed across the grid’s cluster of servers for fast execution, and (b) it avoids moving data between servers for processing. The net result is that large, memory-based data sets can be quickly analyzed to generate timely responses.
Some IMDGs, such as ScaleOut Analytics Server, offer an integrated real-time analytics engine that automatically ships analytics code to all grid servers and then executes the code in parallel on a specified collection of data stored within the IMDG. This simplifies the task of embedding real-time analytics within an operational system and ensures high performance.
Real-time analytics also can be constructed using the Hadoop MapReduce programming model, which offers a very popular data-parallel design pattern. ScaleOut hServer hosts Hadoop MapReduce applications using its real-time analytics engine and eliminates the overheads of task scheduling and data motion usually associated with Hadoop, thereby opening the door to using MapReduce in operational systems.
Adding Real-Time Analytics to an E-Commerce System
Let’s look at how real-time analytics can be integrated into an e-commerce system. In addition to sending basic page requests to the system from clients browsing a website, the browser also can be instrumented to send detailed information about which products customers are examining and the time they are spending on each product. Combining all of this information, the system can build a history of site usage for each customer and collect a set of preferences for that customer. To support a large population of customers, customer information can be persisted in a database or NoSQL store and then brought into the IMDG when the customer starts browsing.
As illustrated in the following diagram, real-time analytics can continuously examine all active customers in parallel to identify special offers that are appropriate for the customer based on a combination of his/her preferences, shopping history, and current browsing behavior. By analyzing access patterns, the site also can determine if a customer is having difficulty finding products or services and suggest remedies. Inactive customers can be flagged and sent emails to remind them to complete purchases in their shopping carts. In addition, common patterns across customers can be identified and used to steer strategic decisions influenced by buying trends.
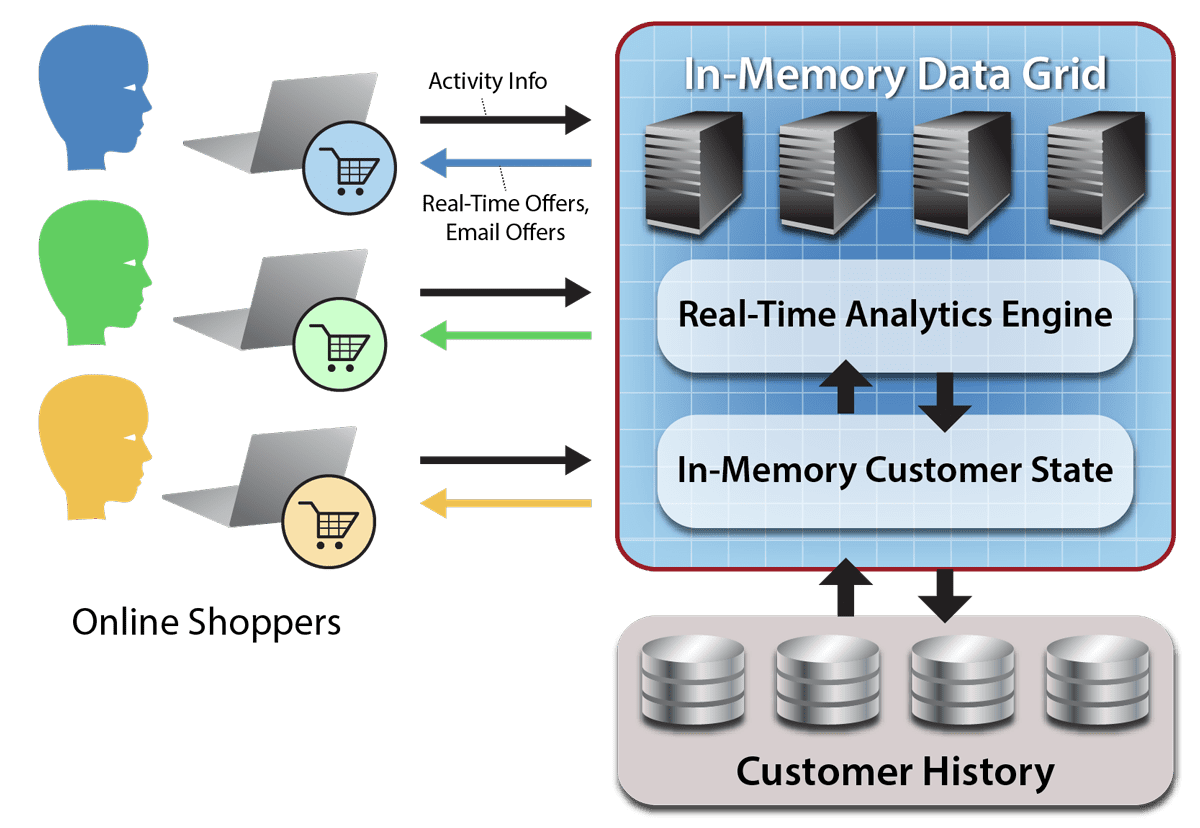
Using Real-Time Analytics in a Brick and Mortar Retail Store
As e-commerce has gained increasing dominance with the shopping public, brick and mortar stores have responded by personalizing the shopping experience. High end retailers are now beginning to send real-time information from the point of sale to back-office servers for analysis in order to provide immediate feedback to sales staff. This enables the retailer to dramatically enhance the shopping experience.
For example, opt-in customers can identify themselves to sales staff on arrival so that their preferences and history can be used to help suggest products of interest. Products can be tracked with RFID tags to alert the sales staff when an active customer’s size is not present on the sales floor and must be retrieved from the stockroom (preferably before the customer requests it). These tags also can identify which products are being taken from the shelves or racks so that buying trends can be tracked. This also helps the store determine which products are repeatedly left in the changing rooms and not purchased, increasing the store’s buying power with the manufacturer. These are some of the many potential uses for real-time analytics in brick and mortar retail.
As the following diagram illustrates, IMDGs with integrated real-time analytics provide a fast and highly scalable platform for hosting customer information and analytics algorithms used by brick and mortar stores. Streams of information regarding customer activity and product motion can be fed to an IMDG to update in-memory state information for customers and products. Using data-parallel execution, analytics algorithms can continuously analyze this in-memory state and generate alerts for the sales staff which are delivered to point of sale terminals or tablets.
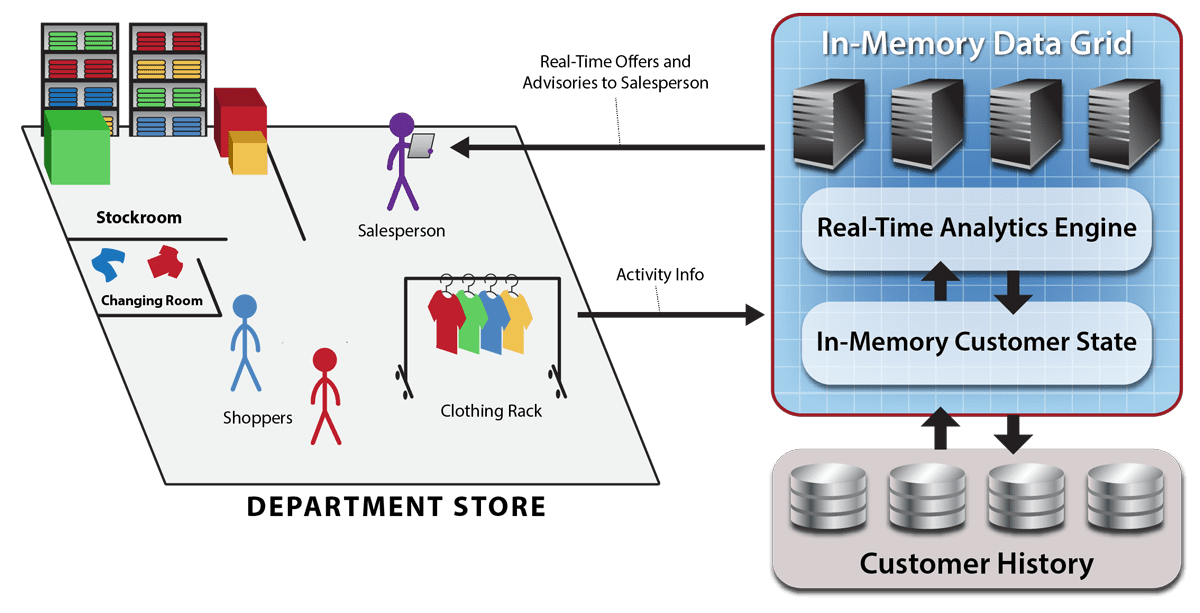
Summing Up
These examples show the power of real-time analytics to enhance operational systems which manage retail purchases, whether online or in brick and mortar stores. By hosting real-time analytics within an IMDG, these systems easily can host customer and product information which is repeatedly updated by streams of activity data. Unlike pure streaming systems, IMDGs can integrate these two types of information to provide a more complete picture of customer activity, leading to a deeper understanding of behavior, preferences, and customer needs. Lastly, IMDGs which host data-parallel analytics algorithms can deliver fast results, avoiding the batch processing overheads of conventional analytics systems, while ensuring scalable performance to handle growing workloads.
The post Transforming Retail with Real-Time Analytics appeared first on ScaleOut Software.
]]>The post How Object-Oriented Programming Simplifies Data-Parallel Analytics appeared first on ScaleOut Software.
]]>The First Step: Object-Oriented Business Logic State
The evolution of in-memory data grids (IMDGs) over the past twelve or so years has paved the way for in-memory computing and analytics. IMDGs, such as ScaleOut StateServer, originally were developed to provide scalable, memory-based data storage for operational systems. For example, IMDGs host session-state and shopping carts for e-commerce web server farms and stock trades for financial systems. These applications and their associated IMDGs often run on clusters of physical or virtual servers to maintain fast response times for growing workloads.
Because web server applications, financial applications, and many others typically use object-oriented languages, such as Java, C#, or C++, to implement their business logic, they naturally structure fast-changing state information as collections of objects. For example, consider a website hosting an e-commerce application. This site’s shopping carts can be stored as instances of a “shopping cart” type, enabling business logic to directly manage these objects and leverage the benefits of object-oriented programming (e.g., data encapsulation and inheritance).
It is useful to think of a collection of objects as analogous to rows in a relational database table, with object properties corresponding to the table’s attributes. However, when objects are input from (or output to) a database or other persistent storage repository, a conversion to/from an object-oriented representation is performed. Tools such as Hibernate help perform these conversions.
To maximize ease of use, IMDGs are designed to integrate into an application’s object-oriented business logic and store fast-changing application state. They enable the application to seamlessly share data across servers and synchronize access by threads running on different servers. For example, consider a server cluster hosting a web server farm with a load-balancer distributing incoming browser connections to the web servers. If an e-commerce web application stores shopping carts within an IMDG, it can access the carts from any web server. Also, multiple browser connections can coordinate access to the shopping carts by using the IMDG’s APIs for distributed locking.
Note that IMDGs usually are not used for long term, persistent storage; that is the job of database and file servers. That said, IMDGs usually incorporate mechanisms to ensure the high availability of data after server outages so that they can be employed in mission-critical applications.
Partitioning Business Logic State into Object Collections
To enable IMDGs to store business logic state for scaled-out applications, their APIs provide an object-oriented view of data. IMDGs organize stored data as unstructured collections of objects, called “namespaces,” with each collection holding objects of a single type. These collections directly reflect mechanisms provided by object-oriented languages, such as Java maps and C# collections. To make objects globally accessible by the IMDG across a cluster of servers, the application supplies an identifying name, or “key,” for each stored object, usually in the form of a string, a number, or sometimes another object. For this reason, IMDGs are sometimes called “key-value stores.”
IMDGs automatically distribute objects within each namespace across the IMDG’s cluster of servers to maximize storage capacity and access throughput (by avoiding hot spots on individual servers). Well-designed IMDGs are “elastic” in the sense that they can transparently rebalance the storage workload as servers are added to handle more data or as servers are removed if the workload shrinks. In addition, IMDGs typically maintain redundant copies of stored objects on different servers so that data is not lost if a server fails or becomes unreachable. If such a failure occurs, the IMDG self-heals by restoring full redundancy to stored data on the surviving servers.
Take a look at the following diagram which depicts how an IMDG distributes collections of objects across a cluster of servers:
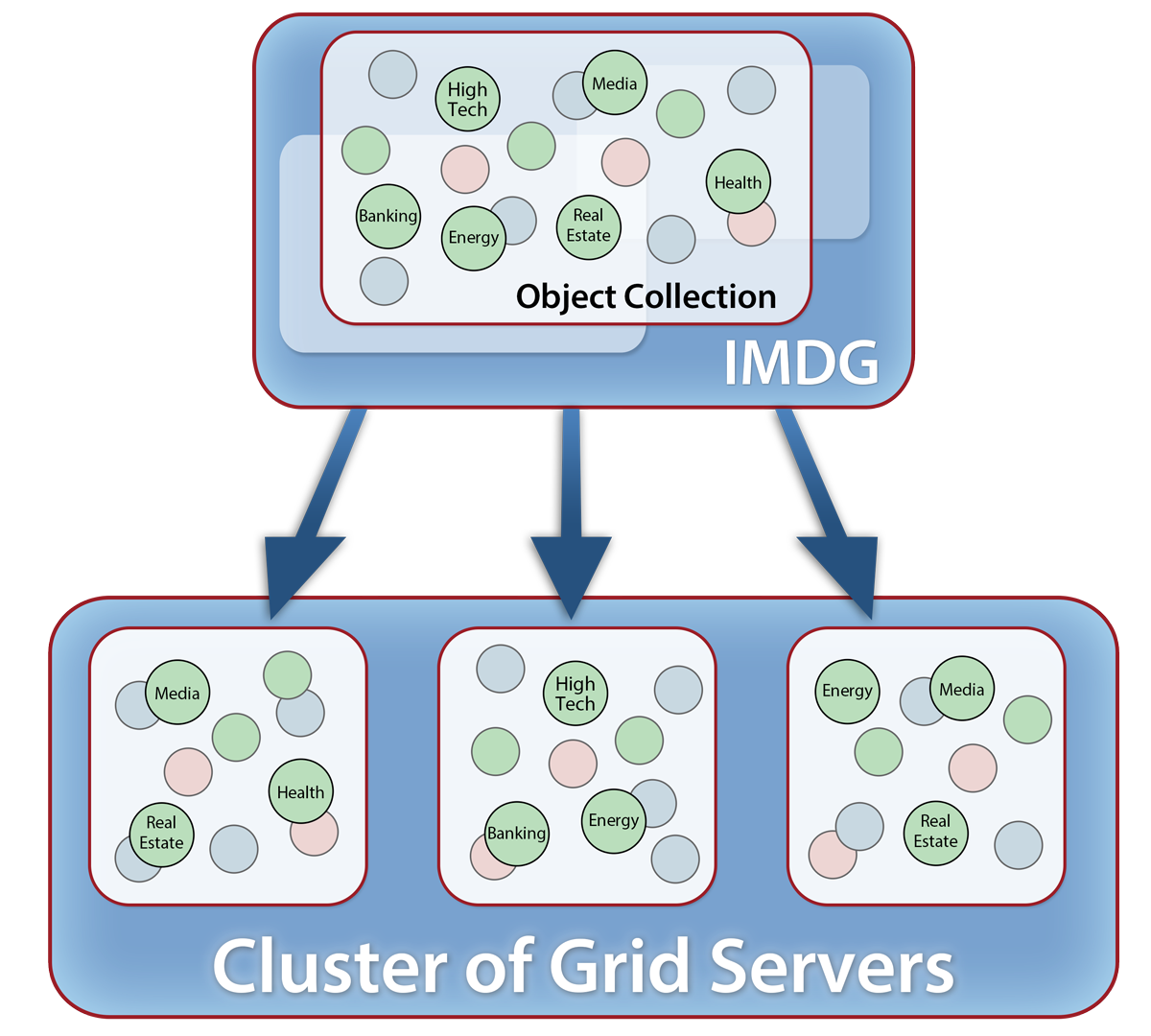
Because an IMDG’s memory is held in service processes running separately from applications, stored objects must be serialized into byte streams which are sent to the IMDG using inter-process or network communication. IMDGs typically store objects as “blobs” of serialized, uninterpreted data accessed by their keys. However, they also use client-side caches within the address space of applications to hold deserialized copies and thereby speed up retrieval.
Using Parallel Query to Select Objects
Because an IMDG runs on a cluster of servers, it incorporates scalable computing power that grows with storage capacity. IMDGs use this computing power both to scale access throughput and to select data using parallel query. IMDGs can query objects within a namespace by their object properties. Queries take the form of an expression which filters objects based on the values of these properties and generates a collection of keys identifying those objects which match the query criteria.
IMDG queries are similar to database queries except that they operate on object properties instead of relational attributes. For example, if an IMDG holds a collection describing equities in the stock market, a query could select all stocks which are in the high tech sector and have price/earnings ratios greater than 15. The following diagram depicts a parallel query in an IMDG:
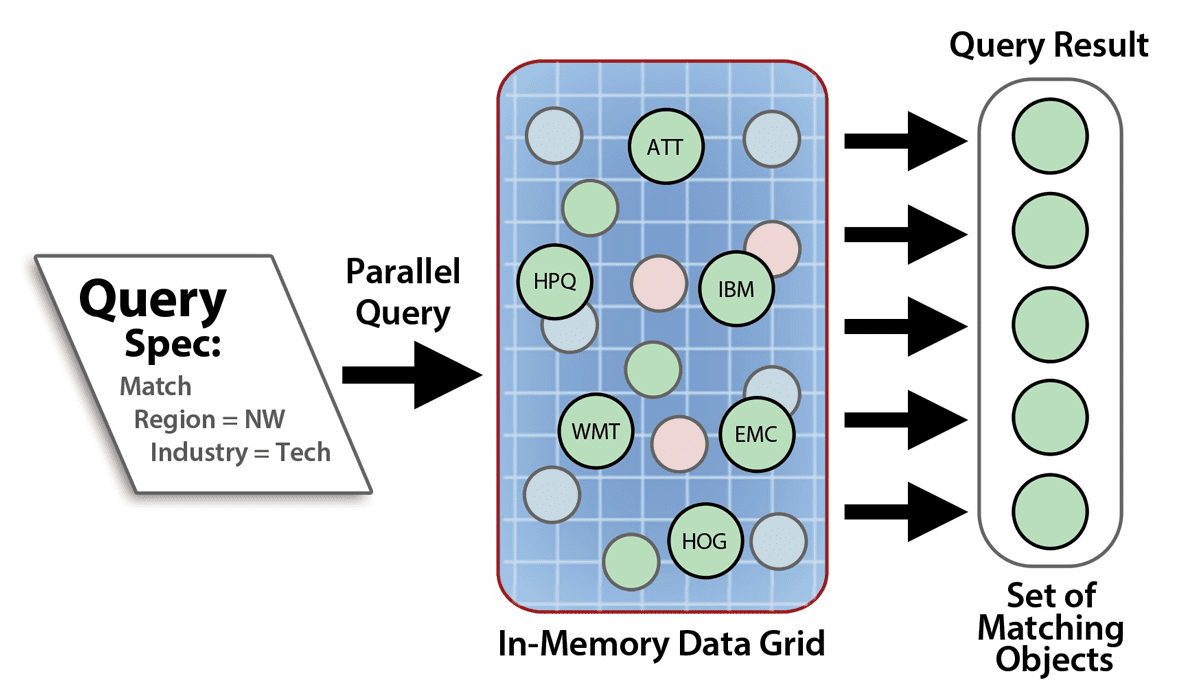
ScaleOut StateServer takes advantage of Microsoft’s language integrated query (LINQ) to implement C# queries with a straightforward syntax similar to SQL. It constructs Java queries by composing methods which filter property values and creating Boolean expressions of these filters.
Various techniques are available to index objects for fast query so that they do not have to be deserialized to evaluate their properties when a query is performed. The net effect is that IMDGs can take full advantage of the cluster’s computing power to quickly select the objects of interest within a large collection stored in the IMDG.
Parallel Queries Can Create Performance Bottlenecks
However, efficiently managing the results of a parallel query without creating a performance bottleneck is a major challenge. If a query matches many objects, a large set of keys must be collected and delivered to the requesting application, and this can consume a great deal of network bandwidth. For example, matching 1M objects with 40-byte keys requires delivering 40MB to an application, which can take half a second on a gigabit network. Moreover, the application has to retrieve all 1M objects to process the selected data, which can take several seconds depending on the amount and complexity of the data.
Another issue with parallel queries is that they must be used judiciously to avoid saturating the CPUs and network. Because each query generates work for all servers, if many application threads simultaneously perform queries, the total amount of work can grow quadratically and overload the servers or network.
The Solution: Data-Parallel Computing
While parallel queries provide a powerful means to identify the objects of interest for further analysis, the key to scalable speedup without performance bottlenecks is to analyze objects in place on the grid servers. Instead of shipping the keys and objects to an application thread for analysis, it is far more efficient to ship the analytics code to the IMDG’s servers for parallel analysis. This minimizes data motion, scales the computation, and ensures that results can be returned as quickly as possible.
When performing a data-parallel computation, a parallel query serves to filter the objects that are submitted for analysis on each grid server. This avoids the performance bottleneck caused by shipping keys and objects across the network. The data-parallel computation also reduces the usage of parallel queries by moving the analysis into the IMDG.
The object-oriented data model simplifies the construction of data-parallel analysis in several ways. First, it partitions the data set into a collection of logically related entities (instances of a type) which can be independently analyzed. These objects form the domain decomposition needed for parallel execution, as discussed in the previous blog. Second, it enables the analysis code to be conveniently represented as a method on the type. Lastly, it enables the results of the parallel analysis to be structured as another collection of objects, usually of a different type, which can be combined or fed to another data-parallel operation (as is the case with Hadoop MapReduce).
Because the IMDG distributes the objects within a collection to all grid servers, it automatically ensures that the domain for data-parallel execution is load-balanced across the cluster. This maximizes overall throughput by balancing the analysis workload across the servers.
For example, consider the financial services example we saw in the previous blog in which the IMDG holds a collection of “strategy” objects for a hedge fund, each of which represents a market sector, such as high tech or real estate, and holds the equity positions and rules for that market sector. A data-parallel computation can independently update each strategy object with a snapshot of market price changes and then evaluate the strategy to determine if stock trades are needed. By performing this analysis in parallel across all strategies, results can be generated in milliseconds instead of several minutes needed by conventional disk-based, sequential analysis.
The following diagram shows how each IMDG server within a cluster can analyze local objects resulting from a parallel query, thereby avoiding data motion across the network. This diagram illustrates the multi-core “parallel method invocation” engine implemented by ScaleOut StateServer Pro. Note that locally selected objects are analyzed using the application’s Analyze method; analysis results then are combined by the Merge method and flow back into the server’s local memory for optional combining across servers.
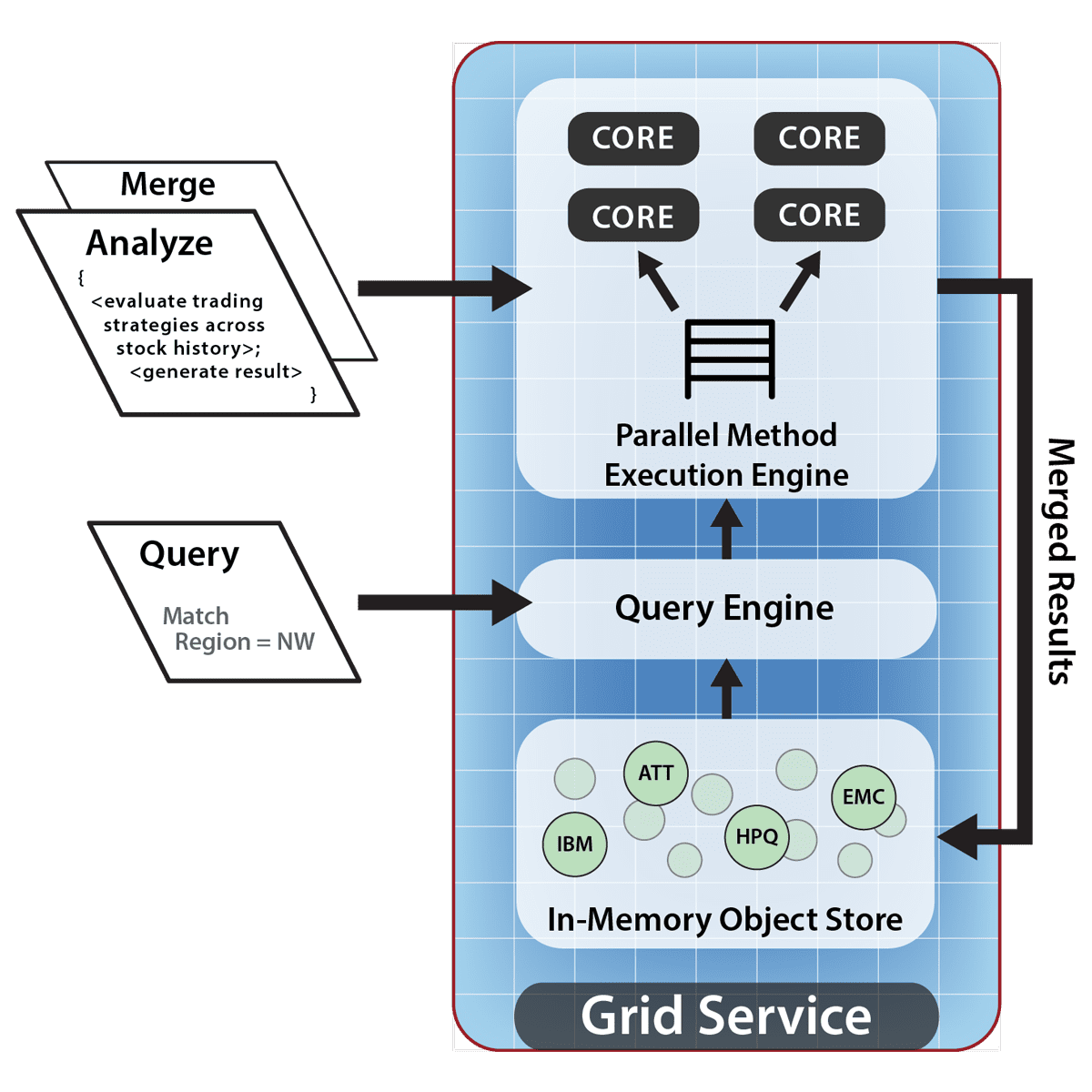
Each server in the IMDG’s cluster run a portion of the data-parallel computation on locally selected objects, as illustrated below:
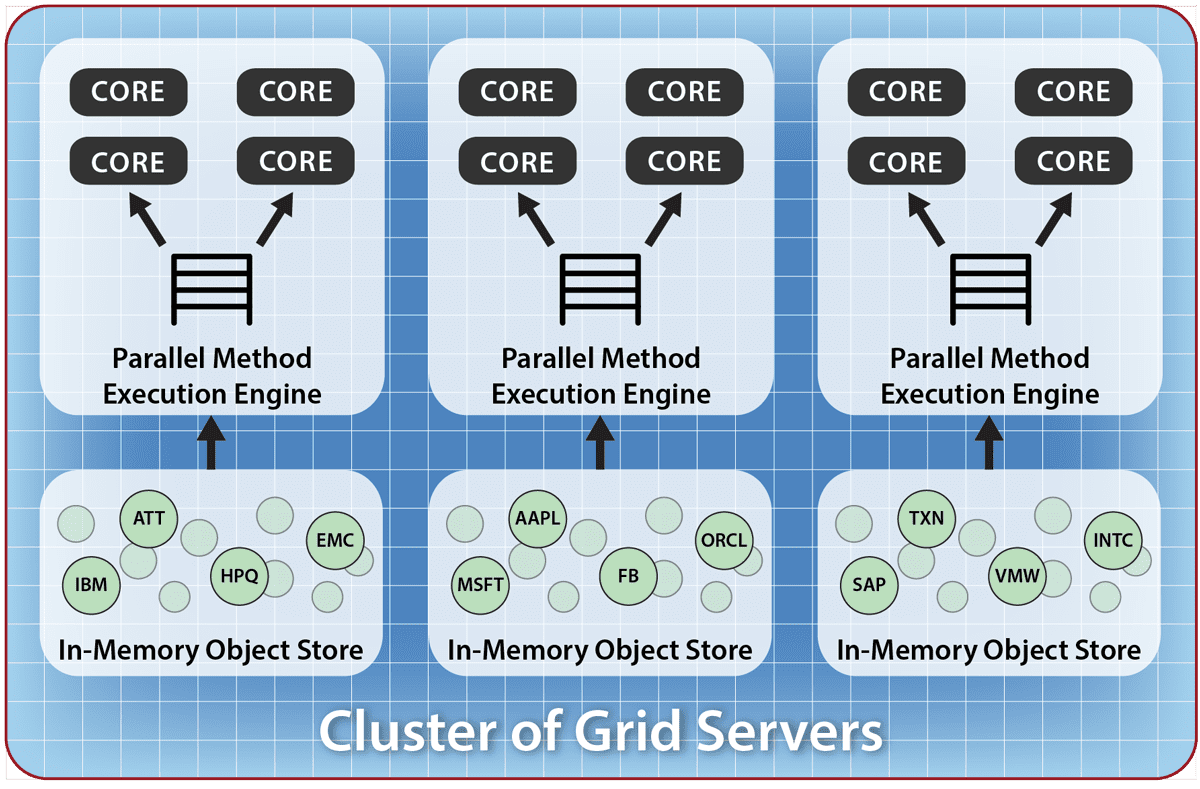
To simplify running data-parallel analyses, some IMDGs, such as ScaleOut StateServer Pro, can ship the application code to all grid servers and initialize the execution environment (i.e., start up JVMs or .NET runtimes). In addition, the IMDG’s use of object collections streamlines multiple data-parallel operations. For example, ScaleOut hServer uses the IMDG to run both the Map and Reduce phases as data-parallel operations, staging intermediate data within the IMDG to minimize overall execution time. Object collections also reduce the complexity and overhead of Hadoop’s input and output formats and enable automatic optimizations (e.g., automatically creating splits and partitions).
Summing Up
Object-oriented programming gives IMDGs an efficient and well understood means to hold business logic state, perform queries, and structure data-parallel computations. This allows IMDGs to be seamlessly integrated into operational systems and perform real-time analytics on “live” data, opening up many new opportunities to add value to these systems.
The post How Object-Oriented Programming Simplifies Data-Parallel Analytics appeared first on ScaleOut Software.
]]>The post Creating Data-Parallel Computations for Real-Time Analytics appeared first on ScaleOut Software.
]]>The Starting Point: Domain Decomposition
Going back to the 1980s, application developers realized that determining how to partition data so that each portion can be analyzed in parallel, a technique often called “domain decomposition,” is the fundamental design decision in data-parallel programming. Once this is accomplished, the domain can be parceled out among the servers within a computational cluster, and the analysis can proceed in parallel on all servers. The cluster speeds up the computation and also allows more servers to be added as the workload (i.e., the domain) grows in size.
The key to domain decomposition is determining which data within the state of an application to use as the domain for parallel analysis. In many cases, the domain is easy to identify, especially when the application is analyzing a physical entity. For example, in an earlier blog we saw how a climate simulation divides the atmosphere, land, and ocean into a grid of boxes which are analyzed independently at each time interval. Likewise, structural mechanics and fluid dynamics typically use grids that model physical systems.
The process of domain decomposition can be more challenging for applications whose data sets can be partitioned in different ways. Consider the hedge fund example above. Do we analyze the data by partitioning the stock symbols across the servers and then analyzing all strategies which hold a given stock? Alternatively, should we partition the strategies and analyze all positions within the strategy? Is there still another domain decomposition?
Minimize Data Motion: An Example in Financial Services
The best approach to choose usually is dictated by the need to minimize data motion. If a given decomposition induces data motion at each analysis step, this can kill performance while saturating the network. For example, if the hedge fund analysis partitions stock symbols, it would need to query all strategies affected by the stock symbol to obtain information needed to perform the analysis, and this requires substantial data motion for each stock symbol. (This assumes that the strategies as well as the stock symbols – and, in general, all data sets – are distributed across the cluster of servers performing the data-parallel computation, as is the case for data sets stored within an in-memory data grid (IMDG).
Instead, the computation could partition the strategies across the servers and analyze all strategies in parallel. In this case, it would need to query the latest stock prices for all positions within each strategy; this also induces data motion. In either case, if the strategies and stock prices are stored in separate data sets, unacceptable data motion will be incurred by the data-parallel computation.
However, if the stock prices for all relevant positions are kept up to date within the strategies instead of storing this data elsewhere, no data motion is needed to perform the data-parallel analysis, and maximum performance is achieved. Bearing in mind that multiple strategies maintain positions in a given stock, how can we efficiently update the strategies as price changes flow in from a market feed? The answer lies in leveraging data-parallel computation to both analyze and update the strategies. We can distribute a snapshot of price changes to all strategies at the start of each analysis and use this information to update each strategy’s positions prior to performing the analysis. This easily can be accomplished by tracking all price changes since the last analysis step and efficiently distributing them to the servers as part of the invocation mechanism for the analysis.
The following diagram illustrates how an IMDG can host a set of strategies and perform parallel analysis on the strategies while updating them with a live market feed containing snapshots of price changes. The analysis produces a stream of alerts to the trader (or to an automated trading system) for strategies that need rebalancing. In ScaleOut Analytics Server, the data parallel analysis can be implemented using a feature called parallel method invocation (PMI):
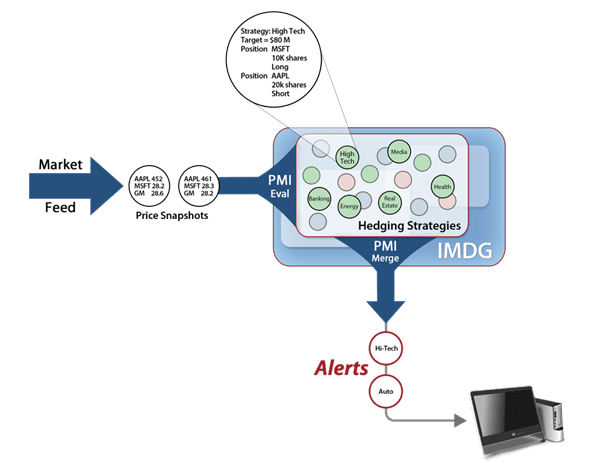
The net effect is that the hedge fund in real time can update its strategies and obtain alerts regarding positions that require rebalancing based on current market conditions. Take a look at this demo of a proof of concept implementation for 2K strategies tracking and analyzing a total of 40K positions using a cluster of four servers. This demo was implemented using a real-time Hadoop MapReduce engine implemented within ScaleOut hServer and delivered alerts within about 330 milliseconds (instead of more than 15 seconds for standard Hadoop).
Another Example: Inventory Reconciliation in E-Commerce
Consider another example of an e-commerce application that needs to reconcile orders and inventory in real time to avoid a shortfall in inventory. Orders flow into the system for a set of products (“SKUs”), and inventory changes flow into the system from several sources: orders to outside vendors are placed, products arrive at the warehouse, orders from customers are filled, defects are detected, etc. Especially with perishable goods, it’s vital to precisely track order commitments so that orders can be accurately filled (and customers stay happy).
Several different domain decompositions for reconciling orders to inventory could be used. Do we partition based on the orders, the inventory changes, or on some other basis? If we reconcile based on pending orders, we have to query the inventory changes for all items within each order, inducing substantial, performance-killing data motion. Likewise, if we partition the inventory changes, we have to query all orders that include a given inventory item, again inducing data motion.
To solve this problem, we can collect pending orders and inventory changes within their common SKUs and then use the SKUs to form a domain decomposition. As orders come into the system, we update the SKUs for all items within each order to track those orders. Likewise, as inventory changes flow in, we update the SKUs to maintain the latest inventory updates. This continuous process updates the SKUs on a real-time basis in a manner analogous to an ongoing database join operation. Now, a data-parallel analysis of the SKUs can reconcile all relevant orders and inventory changes for that SKU without causing data motion. This enables the cluster to perform a reconciliation across all SKUs in seconds instead of minutes.
The following diagram illustrates an IMDG hosting a collection of data representing SKUs that are being updated by incoming orders and inventory changes. The IMDG performs data-parallel reconciliation (“Eval”) of the SKUs and combines the results (“Merge”) while operations are ongoing:
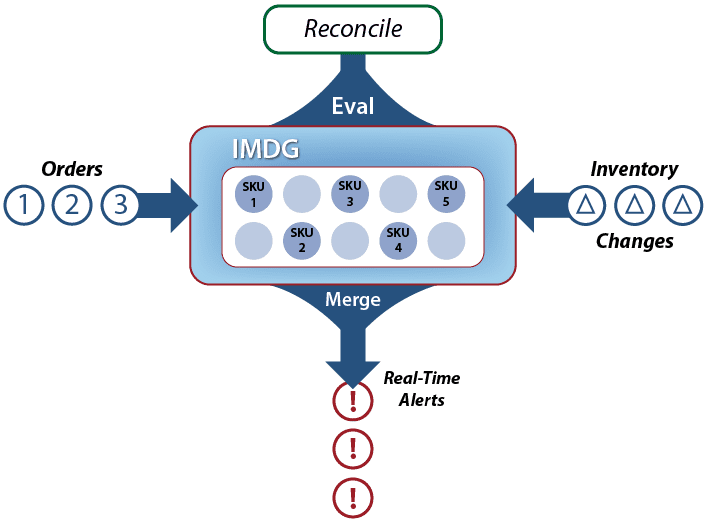
Note that in this example, we do not use the data-parallel invocation mechanism to perform updates to the application’s state as we did with the hedge fund example. Instead, individual order and inventory updates flow into the application on a continuous basis, and the data-parallel analysis is performed on the state information as it changes. In both cases, the integration of data-parallel analysis within an operational system handling live data demonstrates the value of real-time analytics: analysis results are continuously generated and fed back to the system to optimize its ongoing operations.
Using an IMDG to Host a Data-Parallel Application
Lastly, note that an IMDG serves as an ideal host for both the application’s state and the data-parallel analysis. By storing data in memory and distributing it across a cluster of servers, it can keep up with continuous updates and scale to handle growing workloads (while maintaining high availability) just by adding servers. And it can perform data-parallel analysis on domains of data distributed across the servers, leveraging the IMDG’s automatic load-balancing and avoiding data motion across the network during the analysis.
Interestingly, the object-oriented programming model supported by IMDGs helps us to structure, distribute, identify, query, and analyze domains that we construct for real time analysis. We will explore that in an upcoming blog.
The post Creating Data-Parallel Computations for Real-Time Analytics appeared first on ScaleOut Software.
]]>The post Scaling Real-Time Analytics with an IMDG appeared first on ScaleOut Software.
]]>Scale Out to Handle Growing Workloads
Scaling out contrasts to the alternative technique of scaling “up” computing power by adding processors or special purpose processing hardware, such as a vector processor or GPU, to a single, shared memory, multiprocessor system. This technique originally gained popularity with mainframe systems prior to the advent of parallel supercomputing. However, mainframe architect Gene Amdahl recognized that the slowest element of a computing system constrains its overall throughput when executing a fixed size problem; he codified this as Amdahl’s Law. For example, if half of the computation time for a problem is consumed by a vector calculation that could be offloaded to an infinitely fast vector processor, the overall computation only runs 2X faster. Even if 90% of the computation time could be accelerated in this manner, the computation speeds up by no more than 10X.
Scaling out solves this problem by avoiding it. Scaling out adds servers to a cluster so that it can handle larger problem sizes and continue to increase throughput without increasing computation time (as long as the overheads do not grow faster than the number of servers!). This benefit was first observed independently by Cleve Moler and John Gustafson and codified as Gustafson’s Law of scalable speedup. When scaling out, the goal changes from trying to reduce the computation time for a fixed size problem to maintaining the same computation time as the workload increases in size. This nicely matches the needs of system architects who need to scale their systems to keep up with fast growing workloads.
IMDGs Scale Out Access to Data
Scaling out enables in-memory data grids to scale both in-memory data storage capacity and computing power so that they can perform real-time analytics on fast changing data. For example, consider the basic function of an IMDG to let client applications seamlessly access memory-based objects distributed across a cluster of servers. To read an object stored in an IMDG, a client application calls an API which makes a network request to an IMDG server. Assuming the client library can keep track of which server holds the specified object, this request can be satisfied with a single network round trip, consuming a small amount of CPU and NIC bandwidth on the server. As more requests arrive at the server, they consume increasing amounts of CPU and NIC bandwidth until these resources are maxed out.
This is where scalable speedup takes over. Even though the overall request rate that a server can handle is constrained by its available resources, adding a second server doubles the request rate without increasing response time. Likewise, adding more servers to the cluster linearly increases the throughput while maintaining fixed response times until the cluster’s network infrastructure eventually is saturated. Scaling out enables IMDGs to handle growing workloads just by adding servers.
IMDGs Scale Out Updates to Data
Storing and updating objects in an IMDG requires more network bandwidth than accessing them. To maintain high availability, IMDGs store one or more copies of every object on additional servers so that if a server or network connection fails, data can be accessed from an alternative server within the cluster. So, at a minimum, an update request requires twice as much network bandwidth as an access request. As a result, an update-heavy workload tends to saturate the NICs and network infrastructure faster than an access-heavy workload. However, in both cases, the overhead is still proportional to the request rate and also proportional to the number of servers in the cluster. This means that we can expect linear throughput growth as we add IMDG servers until the network itself is saturated. (At that point, we need a faster network, such as 10 Gbps Ethernet or InfiniBand.)
It’s easy to see the importance of the IMDG’s automatic, dynamic load balancing of stored objects in maintaining scalable speedup. This mechanism evenly distributes the workload across all servers within the IMDG’s cluster to make sure that maximum throughput is obtained, avoiding “hot spots” which would direct too many requests to a few servers and limit throughput.
Maintaining Scalable Speedup in Analytics Computations
What happens if we create a workload that induces network overhead which grows faster than the number of servers? This problem was often encountered in parallel supercomputing and gave rise to the aphorism “embarrassingly parallel” for applications which minimize communication overhead. It is just as relevant today: real-time analytics applications must make sure this problem does not occur and kill scalable speedup as the workload grows.
For example, consider a data analytics computation distributed across a set of clients, one per server in an IMDG cluster with N servers, with the client application running on the grid servers. Also assume each server’s computation must access and analyze N or more objects. This makes the total number of accesses required to perform the computation proportional to N*N. If these objects are randomly distributed within the IMDG, the network overhead to process this workload will grow as N-squared and quickly saturate the network, drastically limiting scalable speedup. A “task-parallel” application which parcels out tasks to the clients (one task per object) to complete this analysis could be expected to exhibit this behavior since it randomly selects objects in the IMDG.
However, if we arrange to perform the same analysis as a “data-parallel” computation in which each client only analyzes the objects which are located on the same servers as the client, we can avoid data motion and thereby eliminate order-N-squared network overhead (although we still have order-N inter-process communication overhead between the IMDG’s service process and clients). This is accomplished by letting the IMDG perform the analysis tasks in parallel across all cluster servers on local objects within each server. (In the same manner, Hadoop MapReduce task trackers perform map operations on co-located “splits” within HDFS.)
IMDGs Avoid Data Motion with Data-Parallel Computing
ScaleOut StateServer Pro’s “parallel method invocation” (PMI) feature implements a data-parallel computation model. This feature lets the user specify a Java or C# method to analyze an object and another method to combine the results of two analyses. (These are analogous to a Hadoop mapper and combiner except that, unlike Hadoop, PMI automatically combines results across all servers into a single result object.) The user also specifies a parallel query to select the objects to be analyzed. To run a PMI, the IMDG pre-stages the code on all grid servers, performs the parallel query, and then analyzes all selected objects in place without moving them across the network. Lastly, it combines the results on each server and then combines the results across the servers using a binary combining tree which minimizes execution time.
Performance Gain from Avoiding Data Motion
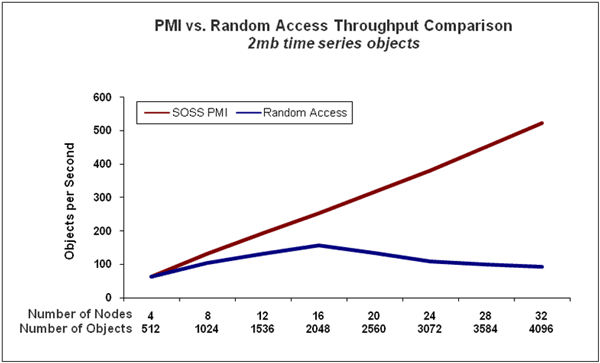
The performance benefits of the data-parallel approach are dramatic. To illustrate this, we captured performance measurements of a risk analysis computation in financial services called “back testing.” This analysis compares a variety of stock trading algorithms using recorded price histories for a collection of equities. Each price history was stored in a single object within the IMDG, and the clients were assigned equities to analyze. (Note that the IMDG’s object-oriented storage also could dynamically update the price histories from a ticker feed to enable real-time feedback to a trading system.)
We compared the task-parallel technique in which the clients analyzed a random set of equities to the data-parallel technique in which the clients only examined equities stored on the same server; the data-parallel technique was implemented using PMI. The following chart shows the throughput obtained for both the task-parallel and data-parallel techniques. Note how the data-parallel approach (red line) maintains linear performance scaling as the workload increases and IMDG servers are added to the cluster. In contrast, the task-parallel approach (blue line) fails to achieve performance scaling due to accessing objects from remote servers which creates substantial networking overhead.
IMDGs take full advantage of scalable speedup to scale their handling of access requests and to perform data-parallel computations. This enables them to run real-time analytics on fast-changing data held in the IMDG and maintain fast response time for large workloads. Unlike pure streaming systems, they combine the IMDG’s in-memory storage with scalable computation to implement complex applications in real-time analytics. We will explore some of these applications in an upcoming blog.
The post Scaling Real-Time Analytics with an IMDG appeared first on ScaleOut Software.
]]>The post IMDGs: Next Generation Parallel Supercomputers appeared first on ScaleOut Software.
]]>Pioneering Technology from Caltech
Back in the 1980s, IBM, Intel, and nCube (among others) began commercializing parallel computing (“multicomputing”) technology pioneered by professors Charles Seitz and Geoffrey Fox at Caltech. They recognized that commodity servers could be clustered using a high speed network to run parallel programs which deliver highly scalable performance well beyond the power of shared memory multiprocessing servers. With the development of message passing libraries, these multicomputers were programmed using C and Fortran to implement parallel applications in matrix algebra, structural mechanics, fluid dynamics, distributed simulation, and many other areas.
While this multicomputing architecture had the potential to deliver very high scalability, it introduced several challenges. Chief among them was hiding network overhead and latency which could easily dominate processing time and impede scalability. Hardware architects developed novel high speed networks, such as Bill Dally’s pipelined torus and mesh routers, to minimize message passing latency. (Standard 10 Mbps Ethernet LANs of the 1980s were quickly determined to be too slow for use in multicomputers.)
Achieving Scalable Speedup
However, to really deliver scalable performance, Cleve Moler (the creator of Matlab, then working at Intel)– and, independently, John Gustafson at Sandia Labs – recognized that scaling the size of an application (e.g., the size of a matrix being multiplied) as more servers are added to the cluster helps mask networking overhead and enable linear growth in performance; this is called Gustafson’s Law. At first glance, this insight might seem counter-intuitive since one expects that adding computing power will speed up processing for a fixed size application. (See Amdahl’s Law.) But adding servers to a computing cluster to handle larger problem sizes actually is very natural: for example, think about adding web servers to a farm as a site’s incoming web load grows.
Keeping It Simple with Data-Parallel Programming
The daunting complexity inherent in the creation of parallel programs with message passing posed another big obstacle for multicomputers. It became clear that just adding message passing APIs to “dusty deck” applications could easily lead to frustrating and inscrutable deadlocks. Developers realized that higher level design patterns were needed; two that emerged were the “task parallel” and “data parallel” approaches. Data-parallel programming is by far the simpler of the two, since the developer need not write application-specific synchronization code, which can be complex and error prone. Instead, the multicomputer executes a single, sequential method on a collection of data that has been distributed across the servers in the cluster. This code automatically runs in parallel across all servers to deliver scalable performance. (Of course, message passing may be needed between execution steps to exchange data between parts of the application.)
For example, consider a climate simulation model such as NCAR’s Community Climate Model. Climate models typically partition the atmosphere, land, and oceans into a grid of boxes and model each box independently using a sequential code. They repeatedly simulate each box’s behavior and exchange data between boxes at every time step in the simulation. Using a multicomputer, the boxes all can be held in memory and distributed across the servers in the cluster, thereby avoiding disk I/O which impedes performance. The cluster can be scaled to hold larger models with more boxes to improve resolution and generate more accurate results. The multicomputer provides scalable performance, and it runs data-parallel applications to help keep development as simple as possible.
IMDGs Use Parallel Computing Architecture
So what does all this have to do with in-memory data grids? IMDGs make use of the same parallel computing architecture as multicomputers. They host service processes on a clustered set of servers to hold application data which they spread across the servers. This data is stored as one or more collections of serialized objects, such as instances of Java, C#, or C++ objects, and accessed using simple create/read/update/delete (“CRUD”) APIs. As the data set grows in size, more servers can be added to the cluster to ensure that all data is held in memory and access throughput grows linearly.
By doing all of this, IMDGs keep access times constant, which is exactly the characteristic needed by applications which have to handle growing workloads. For example, consider a website holding shopping carts in an IMDG. As more and more customers are attracted to the site, web servers must be added to handle increasing traffic. Likewise, IMDG servers must be added to hold more shopping carts, scale access throughput, and keep response times low. In a real sense, the IMDG serves as a parallel supercomputer for hosting application data, delivering the same benefits as it does for climate models and other scientific applications.
IMDGs Run Data-Parallel Applications
However, the IMDG’s relationship to parallel supercomputers runs deeper than this. Some IMDGs can host data-parallel applications to update and analyze data stored on the grid’s servers. For example, ScaleOut Analytics Server uses its “parallel method invocation” (PMI) APIs to run Java, C#, or C++ methods on a collection of objects specified by a parallel query. It also uses this mechanism to execute Hadoop MapReduce applications with very low latency. In this way, the IMDG serves as a parallel supercomputer by directly running data-parallel applications. These applications can implement real-time analytics on live data, such as analyzing the effect of market fluctuations on a hedge fund’s financial holdings (more on that in an upcoming blog).
IMDGs Offer Next Generation Parallel Computing Techniques
IMDGs bring parallel supercomputing to the next generation in significant ways. Unlike multicomputers, they can be deployed on cloud infrastructures to take full advantage of the cloud’s elasticity. They host an object-oriented data storage model with property-based query that integrates seamlessly into the business logic of object-oriented applications. IMDGs automatically load balance stored data across all grid servers, ensuring scalable speedup and relieving the developer of this burden. They provide built-in high availability to ensure that both data and the results of a parallel computation are not lost if a server or network component fails. Lastly, they can ship code from the developer’s workstation to the grid’s servers and automatically stage the execution environment (e.g., a JVM or .NET runtime on every grid server) to simplify deployment.
Although they share a common heritage, IMDGs are not your parent’s parallel supercomputer. They represent the next generation in parallel computing: easily deployable in the cloud, object-oriented, elastic, highly available, and powerful enough to run data-parallel applications and deliver real-time results.
The post IMDGs: Next Generation Parallel Supercomputers appeared first on ScaleOut Software.
]]>