The post The Power of Integrated Analytics Within an IMDG appeared first on ScaleOut Software.
]]>
In-Memory Data Grids for Fast-Changing Data
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. Typical uses include storing session-state and ecommerce shopping carts, product descriptions, airline reservations, financial portfolios, news stories, online learning data, and many others.
From its inception, the design philosophy behind ScaleOut StateServer has been to simultaneously maximize both performance and ease of use. Because IMDGs have complex internal mechanisms, they need to automate them as much as possible so that the developer can just focus on application concerns and not on the inner workings of the IMDG. For this reason, the product incorporates features such as automatic discovery of servers, transparent load-balancing when servers are added to the cluster or removed, automatic data replication for high availability with transparent placement of replicas, quorum-based updating of replicas to ensure consistency, integrated client libraries, and coherent client-side caching. The net effect is that applications maintain a straightforward view of the IMDG as a unified key/value store for serialized application objects.
The Challenges with Parallel Queries
Although IMDGs are optimized for key-based access, applications often need to retrieve groups of objects with matching properties. For example, if an application is storing shopping carts, it might be useful to find all shopping carts with a total value that exceeds a specified threshold so that these shoppers can be given special attention. To this end, ScaleOut StateServer incorporates a property-based, distributed query API that returns a collection of matching objects. To simplify development for .NET applications, it uses Microsoft’s language integrated query (LINQ) to specify queries. (Java applications use a similar mechanism.)
Queries in an IMDG can create interesting performance challenges. Because IMDGs have highly scalable storage capacity, they can easily return large numbers of matching objects to the client application, and this leads to network bottlenecks transferring large amounts of data from the IMDG back to the client. Once all objects are delivered, the client is then faced with the task of analyzing potentially huge numbers of objects. This can saturate the client’s CPU and delay responses, as illustrated in the following diagram:
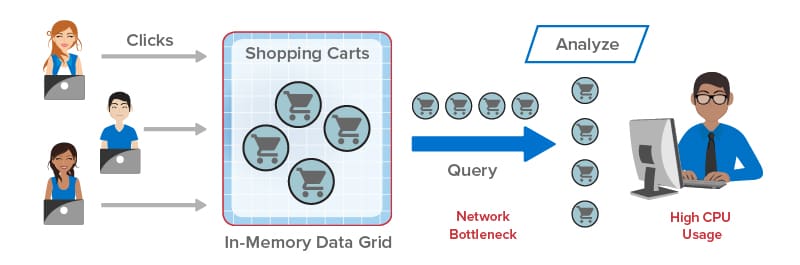
ScaleOut StateServer Pro: Integrated Data Analytics
To address these challenges, ScaleOut Software has introduced ScaleOut StateServer Pro, an advanced version of ScaleOut StateServer that integrates data analytics within the IMDG. Instead of querying objects from the IMDG and analyzing them in the client, applications can now simply run this analysis within the IMDG itself using APIs available in ScaleOut StateServer Pro. Because all the work is performed with the IMDG, this has the two-fold advantage of offloading both the network and the client’s CPU. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
Take a look at how integrated data analytics can help client applications. In the following illustration, the client library sends the application’s analysis method (“Analyze”) to the IMDG for execution in parallel on all shopping carts selected by a query. The results are combined within the IMDG and returned to the application:
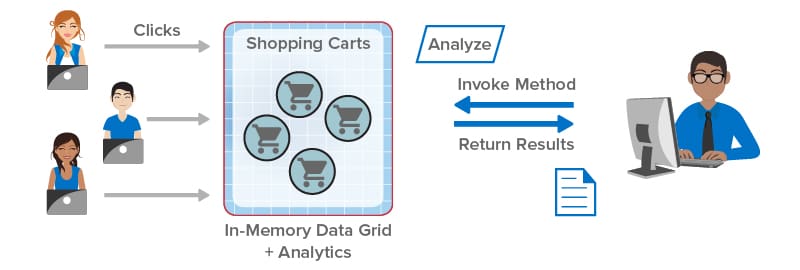
Keeping with the design philosophy of maximizing both performance and ease of use, ScaleOut StateServer Pro lets developers easily construct data analytics by specifying an object-oriented method that analyzes each matching object selected by a query and a second method for combining the results. In .NET applications, this data-parallel execution structure can be described using a distributed version of Microsoft’s popular Parallel.ForEach API, which ScaleOut StateServer Pro integrates with LINQ query. Application code is automatically shipped by the client library to the IMDG for execution and runs fully in parallel across all servers for maximum performance.
Consider the above example of querying shopping carts exceeding a threshold value. Suppose the application’s goal is to periodically analyze high value shopping carts to make upsell offers based on the contents of each cart. Instead of querying the IMDG and returning thousands of shopping carts to the client, the application can implement a method which analyzes these carts within the IMDG to determine which carts should receive upsell offers (and possibly determine which upsell offers to make). This analysis runs in parallel within the IMDG and then returns its results to the client for further action. This dramatically reduces the workload on the network and client, and it ensures consistently high performance.
Summing Up: Extracting Maximum Value from an IMDG
Since their inception, IMDGs have to a large extent been underutilized by viewing them as passive key/value stores. Because they are actually designed as a data-parallel execution platform, they can do much more than just store and serve memory-hosted, live data. They also can perform analysis quickly and efficiently — where the data lives.
Taking full advantage of this powerful capability requires just a shift in thinking about where application work should be performed. In many cases, it’s a much better choice to analyze data within the IMDG instead of transferring it to the client for analysis. ScaleOut StateServer Pro makes it easy to do just that, and it delivers fast, scalable performance. Now developers can finally extract full value from their IMDGs.
The post The Power of Integrated Analytics Within an IMDG appeared first on ScaleOut Software.
]]>The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times. For more than two decades, the answer to this challenge has proven to be a technology called in-memory computing.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers. Assuming bottlenecks are avoided, this enables transparent throughput scaling that matches an increase in workload, which in turn keeps response times low for users. It can also take advantage of the elastic computing resources available in cloud infrastructures to quickly and cost-effectively scale throughput to meet changes in demand.
Harnessing the power of in-memory computing requires software platforms that can make in-memory computing’s scalability readily available to applications using APIs while hiding the complexity of its implementation. Emerging in the early 2000s, the first such platforms provided distributed caching on clustered servers with straightforward APIs for storing and retrieving in-memory objects. When first introduced, distributed caching offered a breakthrough for applications by storing fast-changing data in memory on a server cluster for consistently fast response times, while simultaneously offloading database servers that would otherwise become bottlenecked. For example, ecommerce applications adopted distributed caching to store session-state, shopping carts, product descriptions, and other data that shoppers need to be able to access quickly.
Software platforms for distributed caching, such as ScaleOut StateServer®, which was introduced in 2005, hide internal mechanisms for cluster membership, throughput scaling, and high availability to take full advantage of the cluster’s scalable memory without adding complexity to applications. They transparently distribute stored objects across the cluster’s servers and ensure that data is not lost if a server or network component fails.
As distributed caching has evolved over the last two decades, additional mechanisms for in-memory computing have been incorporated to take advantage of the computing power available in the server cluster. Parallel query enables stored objects on all servers to be scanned simultaneously to retrieve objects with desired properties. Data-parallel computing analyzes objects on the server cluster to extract and report patterns of interest; it scales much better than parallel query by avoiding network bottlenecks and by using the cluster’s computing resources.
Most recently, stream-processing has been implemented with in-memory computing to simultaneously analyze telemetry from thousands or even millions of data sources and track dynamic state information for each data source. ScaleOut Software’s real-time digital twin model provides straightforward APIs for implementing stream-processing applications within its ScaleOut Digital Twin Streaming Service , an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
, an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
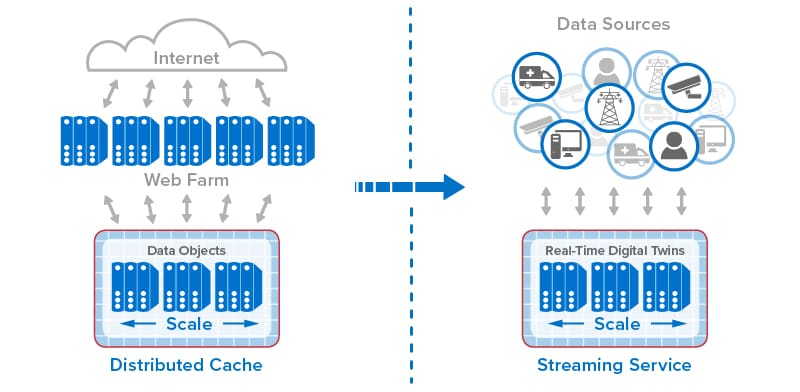
The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins. Each step in the evolution has built on the previous one to add new capabilities that take advantage of the scalable computing power and fast data access that in-memory computing enables.
For ecommerce applications, this evolution has created new capabilities that dramatically improve the experience for online shoppers. Instead of just passively hosting session-state and shopping carts, online applications now can mine shopping carts for dynamic trends to evaluate the effectiveness of product descriptions and marketing programs (such as flash sales). They can also employ real-time digital twins or similar techniques to track each shopper’s behavior and make recommendations. By analyzing a click-stream of product selections in the context of knowledge of a shopper’s preferences and demographics, an ecommerce site can make highly focused recommendations to assist the shopper.
For example, one of ScaleOut Software’s customers recently upgraded from just using distributed caching to scale its ecommerce application. This customer now incorporates stream-processing capabilities using ScaleOut StreamServer® to capture click-streams and score users so that its web site can make more effective real-time offers.
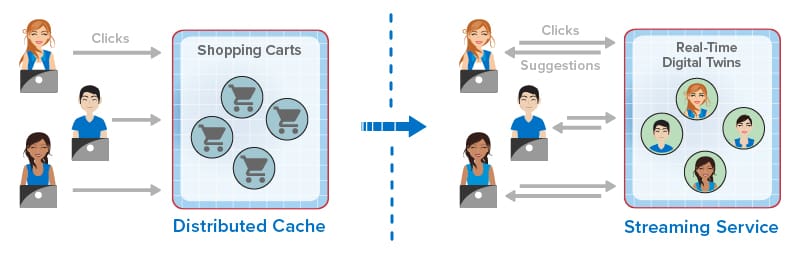
The following diagram illustrates how the evolution of in-memory computing has enhanced the online experience for ecommerce shoppers by providing in-the-moment suggestions:
Starting with its development for parallel supercomputing in the late 1990s and evolving into its latest form as a cloud-based service, in-memory computing has offered powerful, software based APIs for building applications that serve large populations of users and data sources. It has helped assure that these applications deliver predictably fast performance and scale to meet the demands of growing workloads. In the next few years, we should continued innovation from in-memory computing to help ecommerce and other applications maintain their competitive edge.
The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>The post IMDGs: Next Generation Parallel Supercomputers appeared first on ScaleOut Software.
]]>Pioneering Technology from Caltech
Back in the 1980s, IBM, Intel, and nCube (among others) began commercializing parallel computing (“multicomputing”) technology pioneered by professors Charles Seitz and Geoffrey Fox at Caltech. They recognized that commodity servers could be clustered using a high speed network to run parallel programs which deliver highly scalable performance well beyond the power of shared memory multiprocessing servers. With the development of message passing libraries, these multicomputers were programmed using C and Fortran to implement parallel applications in matrix algebra, structural mechanics, fluid dynamics, distributed simulation, and many other areas.
While this multicomputing architecture had the potential to deliver very high scalability, it introduced several challenges. Chief among them was hiding network overhead and latency which could easily dominate processing time and impede scalability. Hardware architects developed novel high speed networks, such as Bill Dally’s pipelined torus and mesh routers, to minimize message passing latency. (Standard 10 Mbps Ethernet LANs of the 1980s were quickly determined to be too slow for use in multicomputers.)
Achieving Scalable Speedup
However, to really deliver scalable performance, Cleve Moler (the creator of Matlab, then working at Intel)– and, independently, John Gustafson at Sandia Labs – recognized that scaling the size of an application (e.g., the size of a matrix being multiplied) as more servers are added to the cluster helps mask networking overhead and enable linear growth in performance; this is called Gustafson’s Law. At first glance, this insight might seem counter-intuitive since one expects that adding computing power will speed up processing for a fixed size application. (See Amdahl’s Law.) But adding servers to a computing cluster to handle larger problem sizes actually is very natural: for example, think about adding web servers to a farm as a site’s incoming web load grows.
Keeping It Simple with Data-Parallel Programming
The daunting complexity inherent in the creation of parallel programs with message passing posed another big obstacle for multicomputers. It became clear that just adding message passing APIs to “dusty deck” applications could easily lead to frustrating and inscrutable deadlocks. Developers realized that higher level design patterns were needed; two that emerged were the “task parallel” and “data parallel” approaches. Data-parallel programming is by far the simpler of the two, since the developer need not write application-specific synchronization code, which can be complex and error prone. Instead, the multicomputer executes a single, sequential method on a collection of data that has been distributed across the servers in the cluster. This code automatically runs in parallel across all servers to deliver scalable performance. (Of course, message passing may be needed between execution steps to exchange data between parts of the application.)
For example, consider a climate simulation model such as NCAR’s Community Climate Model. Climate models typically partition the atmosphere, land, and oceans into a grid of boxes and model each box independently using a sequential code. They repeatedly simulate each box’s behavior and exchange data between boxes at every time step in the simulation. Using a multicomputer, the boxes all can be held in memory and distributed across the servers in the cluster, thereby avoiding disk I/O which impedes performance. The cluster can be scaled to hold larger models with more boxes to improve resolution and generate more accurate results. The multicomputer provides scalable performance, and it runs data-parallel applications to help keep development as simple as possible.
IMDGs Use Parallel Computing Architecture
So what does all this have to do with in-memory data grids? IMDGs make use of the same parallel computing architecture as multicomputers. They host service processes on a clustered set of servers to hold application data which they spread across the servers. This data is stored as one or more collections of serialized objects, such as instances of Java, C#, or C++ objects, and accessed using simple create/read/update/delete (“CRUD”) APIs. As the data set grows in size, more servers can be added to the cluster to ensure that all data is held in memory and access throughput grows linearly.
By doing all of this, IMDGs keep access times constant, which is exactly the characteristic needed by applications which have to handle growing workloads. For example, consider a website holding shopping carts in an IMDG. As more and more customers are attracted to the site, web servers must be added to handle increasing traffic. Likewise, IMDG servers must be added to hold more shopping carts, scale access throughput, and keep response times low. In a real sense, the IMDG serves as a parallel supercomputer for hosting application data, delivering the same benefits as it does for climate models and other scientific applications.
IMDGs Run Data-Parallel Applications
However, the IMDG’s relationship to parallel supercomputers runs deeper than this. Some IMDGs can host data-parallel applications to update and analyze data stored on the grid’s servers. For example, ScaleOut Analytics Server uses its “parallel method invocation” (PMI) APIs to run Java, C#, or C++ methods on a collection of objects specified by a parallel query. It also uses this mechanism to execute Hadoop MapReduce applications with very low latency. In this way, the IMDG serves as a parallel supercomputer by directly running data-parallel applications. These applications can implement real-time analytics on live data, such as analyzing the effect of market fluctuations on a hedge fund’s financial holdings (more on that in an upcoming blog).
IMDGs Offer Next Generation Parallel Computing Techniques
IMDGs bring parallel supercomputing to the next generation in significant ways. Unlike multicomputers, they can be deployed on cloud infrastructures to take full advantage of the cloud’s elasticity. They host an object-oriented data storage model with property-based query that integrates seamlessly into the business logic of object-oriented applications. IMDGs automatically load balance stored data across all grid servers, ensuring scalable speedup and relieving the developer of this burden. They provide built-in high availability to ensure that both data and the results of a parallel computation are not lost if a server or network component fails. Lastly, they can ship code from the developer’s workstation to the grid’s servers and automatically stage the execution environment (e.g., a JVM or .NET runtime on every grid server) to simplify deployment.
Although they share a common heritage, IMDGs are not your parent’s parallel supercomputer. They represent the next generation in parallel computing: easily deployable in the cloud, object-oriented, elastic, highly available, and powerful enough to run data-parallel applications and deliver real-time results.
The post IMDGs: Next Generation Parallel Supercomputers appeared first on ScaleOut Software.
]]>