The post Steve Smith Review: Simplify Redis Clustering with ScaleOut IMDB appeared first on ScaleOut Software.
]]>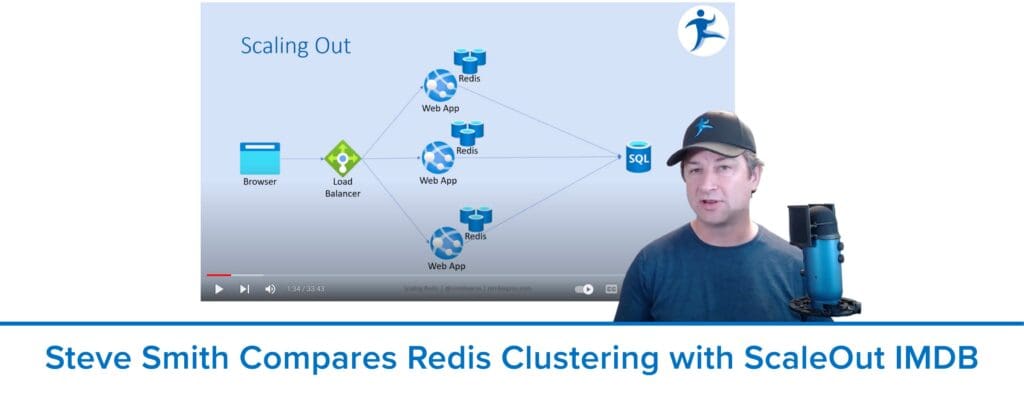
Check out the blog post and video from distinguished software architect and .NET guru Steve “ardalis†Smith on the challenges of scaling single-server Redis and how ScaleOut In-Memory Database tackles them with fully automated cluster technology to avoid complex manual configuration steps.
tackles them with fully automated cluster technology to avoid complex manual configuration steps.
Steve Smith is a well-known entrepreneur and software developer. He is passionate about building quality software and spreading his knowledge through training workshops, speaking at developer conferences, and sharing his experience on his blog and podcast. Steve Smith has also been recognized as a Microsoft MVP for over ten consecutive years.
Â
Â
The post Steve Smith Review: Simplify Redis Clustering with ScaleOut IMDB appeared first on ScaleOut Software.
]]>The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>
by Brandon Ripley, Senior Software Engineer
ScaleOut Software introduces a new Java client API for our distributed caching platform, ScaleOut StateServer®, that adds important new features for Java applications. It was designed with cloud-based deployments in mind, enabling clients to access ScaleOut in-memory data grids (IMDGs also called distributed caches) in multiple availability zones. It introduces the use of connection strings with DNS support for connecting Java clients to IMDGs, and it allows multiple, simultaneous connections to different caches. It also includes asynchronous APIs that add flexibility to application development.
You can download the JAR for the client API from ScaleOut’s Maven repository at https://repo.scaleoutsoftware.com. Simply connect your build tool to the repository and reference the API as a dependency to get started. The online User Guide can help you setup a project. Alternatively, you can download the JAR directly from the repo and then host the JAR with your build tool of choice. You can find an API reference here.
Let’s take a brief tour of the new Java APIs and look at an example using Docker for accessing multiple IMDGs.
A Quick Tour of the Java Client
The ScaleOut client API for Java lets client applications store and retrieve POJOs (plain old java objects) from a ScaleOut IMDG and provides an easy to use, fast, cloud-ready caching API. It can be used within any web application and is independent of any framework. This means that you can use the ScaleOut client API within your existing application architecture.
To simplify the developer experience, the API is logically divided into three primary packages:
Client Package
The client package houses the GridConnection class for connecting to a ScaleOut IMDG via a connection string. Each instance of GridConnection maintains a set of TCP connections to a ScaleOut cache and transparently handles retries, host failures, and load balancing.
The client package is also the place to register for event handling. ScaleOut servers can fire events for objects that are expiring and events for backing store operations (that is, read-through, refresh-ahead, write-behind, and erase-behind). The ServiceEvents class is used to register an event handler for events fired by the grid.
Caching Package
The caching package contains the strongly typed Cache<K,V> class that is used for all caching operations to store and retrieve POJOs of type V using a key of type K from a name space within the IMDG. All caching operations return a CacheResponse that details the result of the cache access.
For example, a successful access that adds a value to the cache using:
cache.add(key, value)
returns a CacheResponse with the status ObjectAdded, which can be obtained by calling the CacheResponse.getStatus() method. However, if the cache already contained an object for the key and the access was called again, CacheResponse.getStatus() would return ObjectAlreadyExists. (See the Javadoc for all possible responses.)
Query Package
The query package lets you perform queries to select objects from the IMDG. Queries are constructed using query filters created using the FilterFactory class. A filter can consist of a simple equality predicate, or it can combine multiple predicates to query with finer granularity.
Sample Applications
The following samples show how the ScaleOut Java client API can be used within a microservices architecture to access cached data and process events. The client API make it easy to develop modern web applications.
In these samples we will:
- Write an application that connects to two ScaleOut IMDGs to store and retrieve objects. (The two caches are configured to replicate data to each other using ScaleOut GeoServer®.)
- Write a second application that registers for and handles ScaleOut expiration events.
- Create four dockerfiles: the caching application, the expiration event handling application, and two ScaleOut IMDGs.
- Use the Docker compose command to spawn all four containers and run the two applications.
You can find the full samples, including the dockerfiles, on GitHub. Let’s look at the code for these two applications.
Accessing Multiple IMDGs
The first application’s goal is to verify ScaleOut GeoServer replication between two IMDGs. It first connects to the two IMDGs, creates an instance of Cache(K,V) for each IMDG, and then performs accesses.
The application connects to the grid using the GridConnection.connect() static method to instantiate a GridConnection object for each IMDG (named store1 and store2 here):
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
The next step is to create an instance of Cache(K,V) for each IMDG. Caches are instantiated with a GridConnection which associates the instance with a specific IMDG. This allows different instances to connect to different IMDGs.
The Java client API uses a builder pattern to instantiate caches. For applications using dependency injection, the immutable cache guarantees that the defaults we set at build time will stay consistent for the lifetime of the app. This is great for large applications with many caches as it guarantees there will be no unexpected modifications.
On the builder we can specify properties for defaults. Here is an example that sets an object timeout of fifteen seconds and a timeout type of Absolute (versus ResetOnUpdate or Sliding). The string “example†specifies the cache’s name space:
Cache<Integer, String> store1Cache = new CacheBuilder<Integer, String>(store1Connection, "example", Integer.class)Â Â
      .objectTimeout(Duration.ofSeconds(15))       Â
.timeoutType(TimeoutType.Absolute)Â Â Â Â Â Â Â
.build();
The Cache(K,V) class has multiple signatures for storing and retrieving objects from the IMDG. These signatures follow traditional Java naming semantics for distributed caching. For example, the add(key,value) method assumes that no key/value object mapping exists in the cache, whereas update(key,value) assumes than a key/value mapping exists in the cache.
This application uses the add method to insert an item into store1Cache and then checks the response for success. Here’s a code sample that adds two items to the cache:
CacheResponse<String, String> addResponse = store1Cache.add(“MyKeyâ€, "SomeValue");       Â
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
addResponse = store1Cache.add(“MyFavoriteKeyâ€, "MyFavoriteValue");       Â
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
The application’s goal is to verify that ScaleOut GeoServer replicates stored objects from the store1 IMDG to store2. It creates an instance of Cache(K,V) for the same namespace on store2 and then attempts to retrieve the object with the read API:
CacheResponse<String, String> readResponse = store2Cache.read(“Keyâ€);       Â
if(readResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
Registering for Events
This sample application demonstrates how an application can have fine grain control over which objects will be removed from the IMDG after a time interval elapses. With the object timeout and timeout-type properties established, objects added to the IMDG will be subject to expiration. When an object expires, the ScaleOut grid will fire an expiration event.
Our application can register to handle expiration events by supplying an instance of Cache(K,V) and an appropriate lambda (or implementing class) to the ServiceEvents static method. The following code removes all objects other than a cache entry mapping with the key, “MyFavoriteKeyâ€:
ServiceEvents.setExpirationHandler(cache, new CacheEntryExpirationHandler<Integer, String>() {Â Â Â Â Â Â Â
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<Integer, String> cache, String key) {Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â
System.out.println("ObjectExpired: " + key);Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â
if(key.compareTo(“MyFavoriteKeyâ€) == 0)                          Â
return CacheEntryDisposition.Save;Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â
return CacheEntryDisposition.Remove;Â Â Â Â Â Â Â
}});
Running the Applications
We’ve created code snippets for connecting to a ScaleOut grid, creating a cache, and registering for ScaleOut expiration events. We can put all these pieces together to create the two applications with two Java classes called CacheRunner and CacheExpirationListener.
CacheRunner connects to two ScaleOut IMDGs that are setup for push replication using ScaleOut GeoServer. (This is handled by the infrastructure via the dockerfiles and not done in code.) It creates an instance of Cache(K,V) associated with one of the IMDG (called store1) that has a very small absolute timeout for each object and another instance for the other IMDG (called store2). It stores an object in store1 and then retrieves it from store2 to verify that the object was pushed from one IMDG to the other.
Here is the code for CacheRunner:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.caching.*;
import java.time.Duration;
public class CacheRunner {
   public static void main(String[] args) throws CacheException, GridConnectException {
       System.out.println("Connecting to store 1...");
       GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
       System.out.println("Connecting to store 2...");
       GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
       Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
            .geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
            .objectTimeout(Duration.ofSeconds(15))
            .objectTimeoutType(TimeoutType.Absolute)
            .build();
       Cache<String, String> store2Cache = new CacheBuilder<String, String>(store2Connection, "sample", String.class)
            .build();
       System.out.println("Adding object to cache in store 1!");
       CacheResponse<String, String> addResponse = store1Cache.add("MyKey", "MyValue");
       System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
       addResponse = store1Cache.add("MyFavoriteKey", "MyFavoriteValue");
       System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
       System.out.println("Reading object from cache in store 2!");
       CacheResponse<String,String> readResponse = store2Cache.read("foo");
       System.out.println("Object " + ((readResponse.getStatus() == RequestStatus.ObjectRetrieved ?
"retrieved" : "not retrieved.")) + " from cache in store 2.");
   }
}
CacheExpirationListener connects to one ScaleOut IMDG, create an instance of Cache(K,V), and registers for expiration events. Here is its code:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.ServiceEvents;
import com.scaleout.client.ServiceEventsException;
import com.scaleout.client.caching.*;
import java.io.IOException;
import java.time.Duration;
import java.util.concurrent.CountDownLatch;
public class ExpirationListener {
   public static void main(String[] args) throws ServiceEventsException, IOException, InterruptedException,
GridConnectException {
       GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
       Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
               .geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
               .objectTimeout(Duration.ofSeconds(15))
               .objectTimeoutType(TimeoutType.Absolute)
               .build();
       ServiceEvents.setExpirationHandler(store1Cache, new CacheEntryExpirationHandler<String, String>() {
           @Override
           public CacheEntryDisposition handleExpirationEvent(Cache<String, String> cache, String key) {
               CacheEntryDisposition disposition = CacheEntryDisposition.NotHandled;
               System.out.printf("Object (%s) expired\n", key);
               if(key.equals("MyFavoriteKey"))
                   disposition = CacheEntryDisposition.Save;
               else disposition = CacheEntryDisposition.Remove;
               return disposition;
           }
       });
   }
}
To run these applications, we’ll use the Docker compose command to build Docker containers. We will have 4 services, each defined in their own respective dockerfile, which are all provided and available on the GitHub repo. You can clone the repository and then run the deployment with the following command:
docker-compose -f ./docker-compose.yml up -d –build
Here is the expected output for CacheRunner:
Adding object to cache in store 1! Object added to cache in store 1. Object added to cache in store 1. Reading object from cache in store 2! Object retrieved. from cache in store 2.
Here is the output for ExpirationListener:
Connected to store1! Object (MyFavoriteKey) expired Object (MyKey) expired
Summing Up
The new ScaleOut client API for Java adds important features that support the development of modern web and cloud applications. Built-in support for connection strings enables simultaneous connections to multiple IMDGs using DNS entries. Full support for asynchronous accesses also assists in application development. Let us know what you think with your comments on our community forum.
Â
The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>
ScaleOut Software is excited to announce the release of ScaleOut In-Memory Database, which offers a new, highly scalable, clustered server platform for running Redis commands. This platform uses ScaleOut’s patented, quorum-based clustering technology to replace open-source Redis’s cluster implementation. It fully automates Redis cluster management while preserving the use of open-source Redis code to process commands. In doing so, ScaleOut In-Memory Database lets enterprise Redis users manage server clusters with much greater ease and lower both their acquisition and management costs (TCO) — while preserving a native execution environment for Redis applications. ScaleOut In-Memory Database runs on both Linux and Windows systems.Â
What sets ScaleOut’s cluster architecture apart
When ScaleOut Software first developed its clustering technology for scalable in-memory data storage in 2003, we had to tackle several technical challenges. We needed to: Â
- implement a scalable cluster membership,
- partition the in-memory data store across multiple servers,
- replicate updates with zero data loss (i.e., avoid eventual consistency), and
- maximize throughput with multi-threading on multicore servers.
We also realized that it was important not to expose all these complexities to users. The cluster had to be easy to manage, making a simple learning curve for system administrators. It was also vital to have a straightforward view of the data store for applications (that is, maintain location transparency and full consistency) so developers could target it easily.Â
Automated clusteringÂ
Our clustering architecture has many leading-edge automated clustering features. These include the ability to: Â
- self-organize multiple servers into a cluster,
- automatically partition data and distribute it across the cluster,
- load-balance stored data as servers are added or removed,
- automatically create and maintain replicas,
- detect server and network failures,
- recover from failures by promoting replicas to replace failed primary partitions, and
- “self-heal†by creating new replicas to replace lost ones.
Stability and consistencyÂ
The server cluster uses peer-to-peer algorithms to avoid single points of failure. Running on one or more servers, it maintains availability to applications even if all but one server fails. It uses a patented quorum algorithm to implement full (strong) consistency when updating stored data across multiple servers. Lastly, it executes multiple requests at once using a multi-threaded architecture.Â
Industry-leading ease of useÂ
ScaleOut’s cluster architecture does all this without showing its inner workings to developers or system administrators. Developers see a single, reliable data store that happens to be distributed across multiple servers. System administrators see a set of servers on a single network subnet, each running a single service process. Â
Once the service is configured to select a specific subnet (if multiple NICs are in use), it joins the cluster with one click and is ready to take on its share of the workload. Building a server cluster is just a matter of adding servers (called “nodes†in Redis documentation):Â
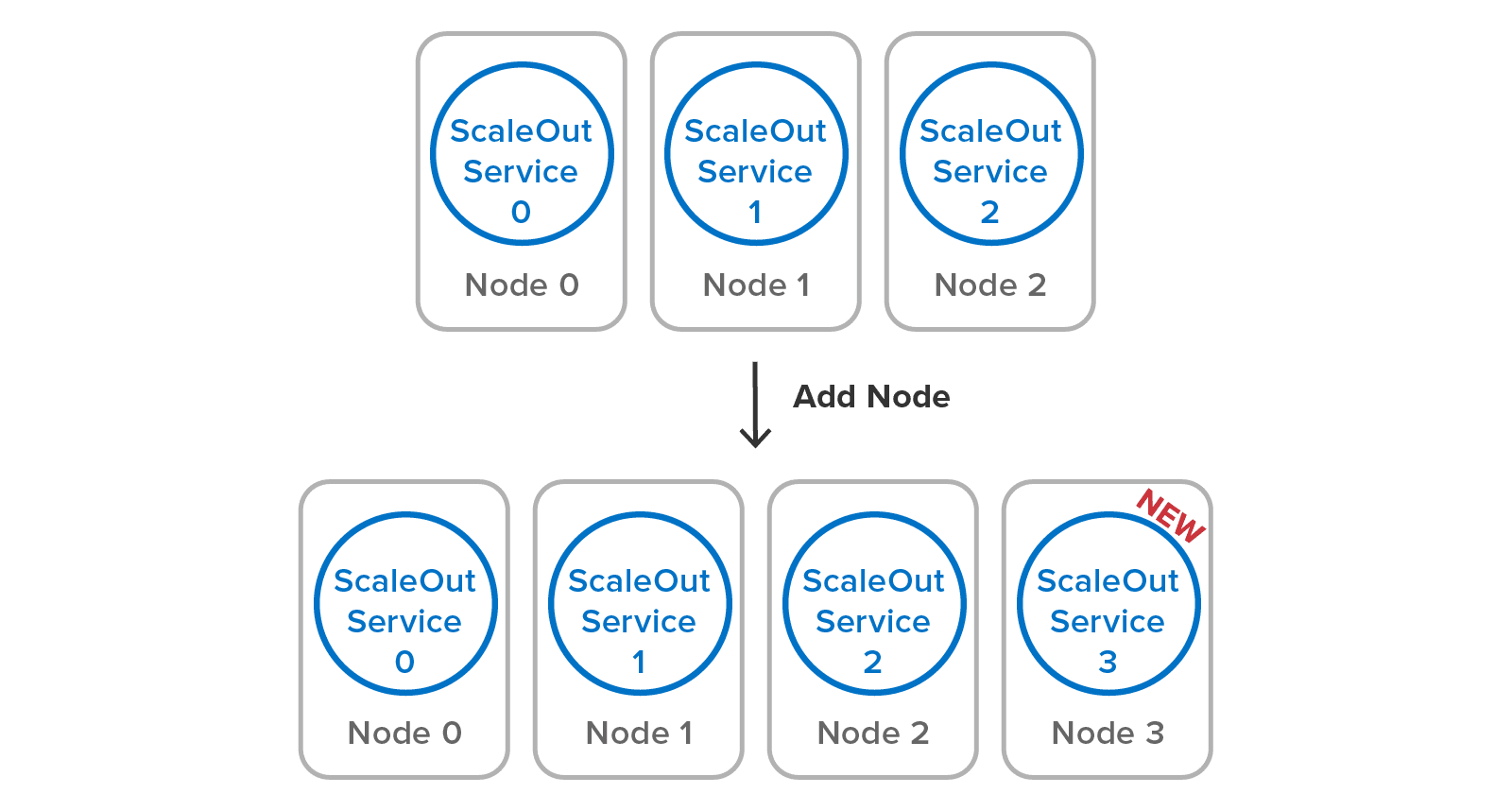 All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
Enter Redis
Open-source Redis was first created in 2009 for use on a single server, with clustering added in 2015. It has gained widespread popularity because of its rich set of data structures and commands. At the enterprise level, it has seen fast-growing adoption across many applications. As a result, the need to streamline cluster management procedures and increase data reliability for Redis users has become more urgent.Â
Introducing automated Redis clustering with ScaleOut In-Memory DatabaseÂ
We created ScaleOut In-Memory Database to meet this need. This product integrates open-source Redis code (version 6.2.5) that implements all the popular Redis data structures (strings, lists, sets, hashes, streams, and more) into ScaleOut’s automated cluster architecture and execution platform. Now, system administrators don’t need to manage Redis concepts like hashslots and shards. Instead, ScaleOut takes over these tasks using its built-in, fully automated mechanisms. Automated recovery and self-healing eliminate the need for manual intervention and increase uptime. What’s more, ScaleOut’s quorum-based updates replace Redis’s eventual consistency mechanism to deliver reliable data storage across servers. Applications can depend on the server cluster to survive a server failure without data loss, and the cluster remains available even if multiple servers fail.Â
To boost throughput and automatically make full use of all available processing cores, ScaleOut In-Memory Database integrates Redis command execution with its multi-threaded processing of client requests. Achieving this meant eliminating Redis’s native, single-threaded event-loop execution model without introducing a global lock that would constrain performance. The result is that each server in the cluster can run Redis commands simultaneously on all processing cores using a single service process.Â
Power with simplicity
We designed ScaleOut’s peer-to-peer cluster architecture to serve as the foundation for all user services. Hence, functions like clearing the database and backup/restore were built from the outset to run in parallel across all servers. This approach reduces the system administrator’s workload and delivers fast performance. To give Redis users the benefit of a fully parallel architecture, ScaleOut In-Memory Database provides a cluster-wide implementation of many Redis commands, such as PUBLISH and FLUSHALL.Â
ScaleOut In-Memory Database also overcomes the single-server limitation of the Redis SAVE command. It provides a cluster-wide implementation of backup/restore using its built-in parallel backup/restore utility. This allows system administrators to backup all Redis objects with one click in ScaleOut’s management console, and it delivers parallel speedup by running simultaneously on all servers. The user can backup either to local disks:Â
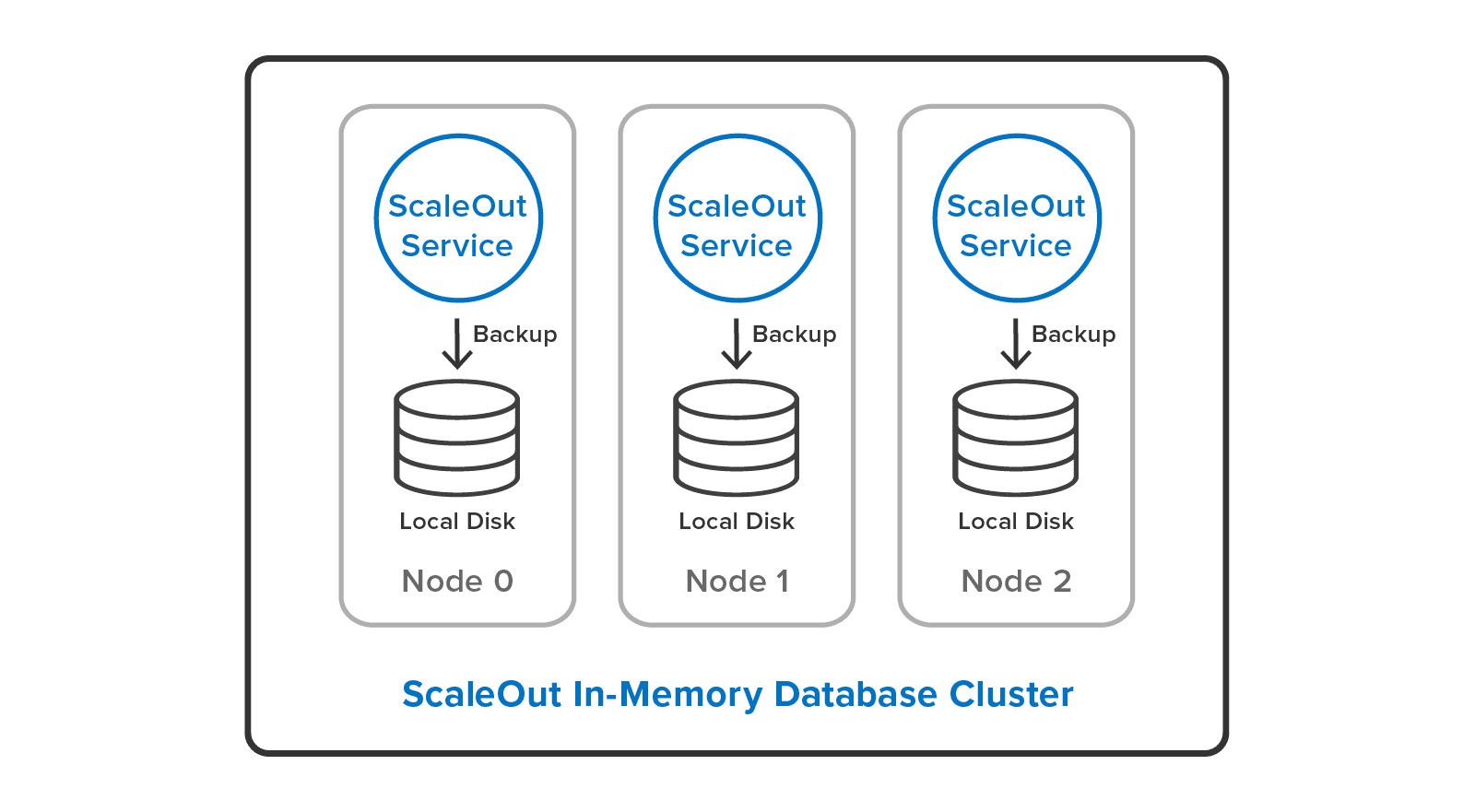
or to a single, shared disk:
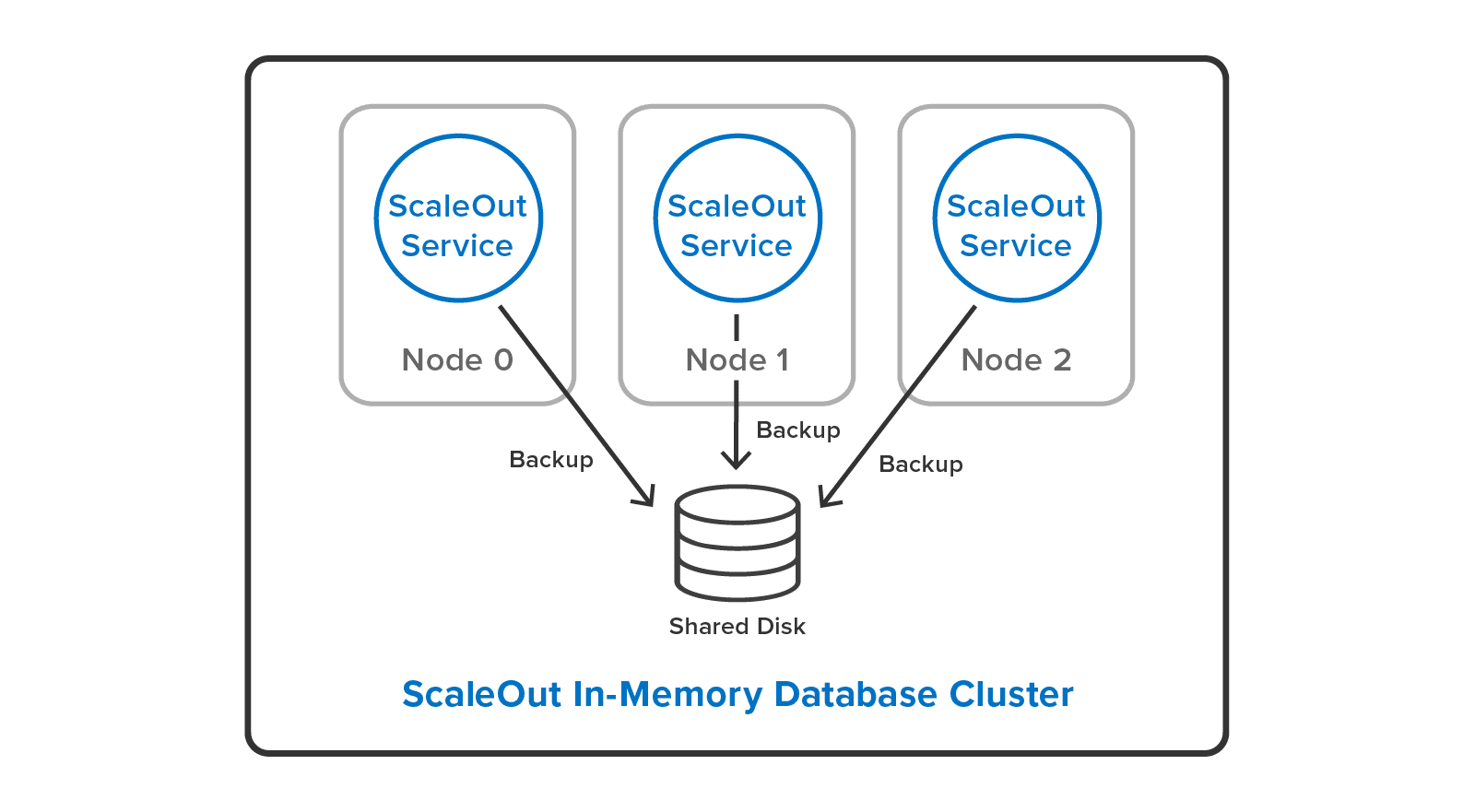
System administrators can cut down their workload by restoring backup files to a different cluster configuration than they used to make the backup. For example, it’s possible to restore a backup from a three-server cluster to a two-server cluster with a different hashslot mapping:Â
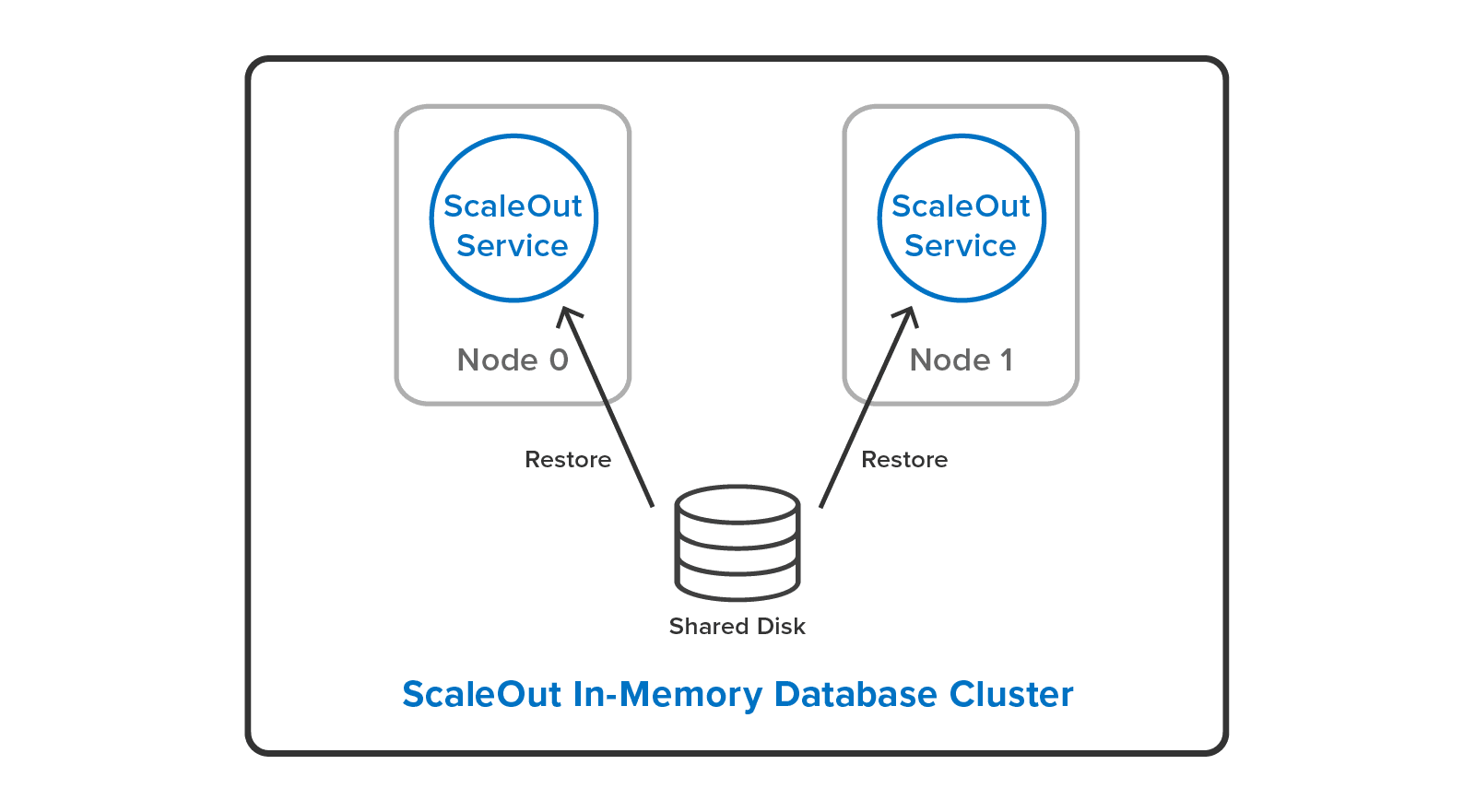
There’s a lot more in the new ScaleOut In-Memory Database than there’s room to discuss in depth here. For example, ScaleOut’s cluster stalls Redis command execution automatically when it moves hashslots between nodes for load-balancing, or when it performs recovery. This means clients always have a consistent view of the cluster. Also, the cluster stores Redis objects in their own ScaleOut namespace side-by-side with objects that ScaleOut’s native APIs manage. This lets users access the full power of ScaleOut’s in-memory computing features, including cluster-wide, data-parallel operations and stream processing with digital twins.Â
Summing Up
ScaleOut In-Memory Database makes scalable processing more convenient, reliable, and cost-effective for enterprise Redis users than ever before. By automating Redis cluster management, improving data reliability, and adding multi-threaded command execution, this product can significantly drive down the total cost of ownership for Redis deployments, even in comparison to commercial Redis alternatives. We invite you to check it out and see how it performs for you. We’d love to hear your feedback.Â
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>The post Introducing A New Execution Platform for Redis Clients appeared first on ScaleOut Software.
]]>
The Challenge
Redis®* offers a compelling set of data structures that enhance the capabilities of a distributed cache beyond just storing serialized objects. Created in 2009 as a single-server store to assist in the design of a web server, Redis gives applications numerous useful options for organizing stored data, including sets, lists, and hashes. Cluster support was added later, and it introduced specialized concepts, like hashslots and master/replica shards, that system administrators must understand and manage. Along with its use of eventual consistency, this has created complexity that makes cluster management challenging while reducing flexibility in configurations.
In contrast, ScaleOut StateServer®, a distributed cache for serialized objects and first released in 2005, was designed from the ground up to run on a server cluster with automated load-balancing, data replication, and recovery while storing data with full consistency (i.e., sequential consistency) across replicas. It also executes client requests using all available processing cores for maximum throughput. These features dramatically simplify cluster management, especially for enterprise users, improve flexibility, and lower TCO. For example, unlike Redis, ScaleOut server clusters can seamlessly grow from a single to multiple servers, and system administrators do not need to manage hashslots or master/replica shards. See a recent blog post that discusses how ScaleOut StateServer simplifies cluster management in comparison to Redis.
ScaleOut Software recognized that running Redis commands on a ScaleOut StateServer cluster would offer Redis users the best of both worlds: familiar and rich data structures combined with significantly simpler cluster management and full data consistency. However, the ideal implementation would need to use Redis open-source code to execute Redis commands so that client commands would behave identically to open-source Redis clusters. The challenge is then to integrate Redis code into ScaleOut StateServer’s execution platform and take advantage of ScaleOut’s highly automated clustering features while eliminating the single-threaded constraints of Redis’s event-loop architecture.
Integrating Redis into ScaleOut StateServer
Released as a community preview, version 5.11 of ScaleOut StateServer introduces support for the most popular Redis data structures (strings, sets, lists, hashes, and sorted sets) plus publish/subscribe commands, transactions, and various utility commands (such as FLUSHDB and EXPIRE). Both Windows and Linux versions are available. This release uses open-source Redis version 6.2.5 to process Redis commands.
Redis clients connect to any ScaleOut StateServer server in a cluster using the standard RESP protocol. (A cluster can contain one or more servers.) Client libraries internally obtain the mapping of hashslots to servers using either the CLUSTER SLOTS or CLUSTER NODES commands and then direct Redis access requests to the appropriate ScaleOut server. To maximize throughput, each ScaleOut server processes incoming Redis commands on multiple threads using all available processor cores; there is no need to deploy multiple shards on each server for this purpose.
The following diagram shows a set of Redis clients connecting to a ScaleOut StateServer cluster. Note that the complexities of hashslots and shards have been eliminated:
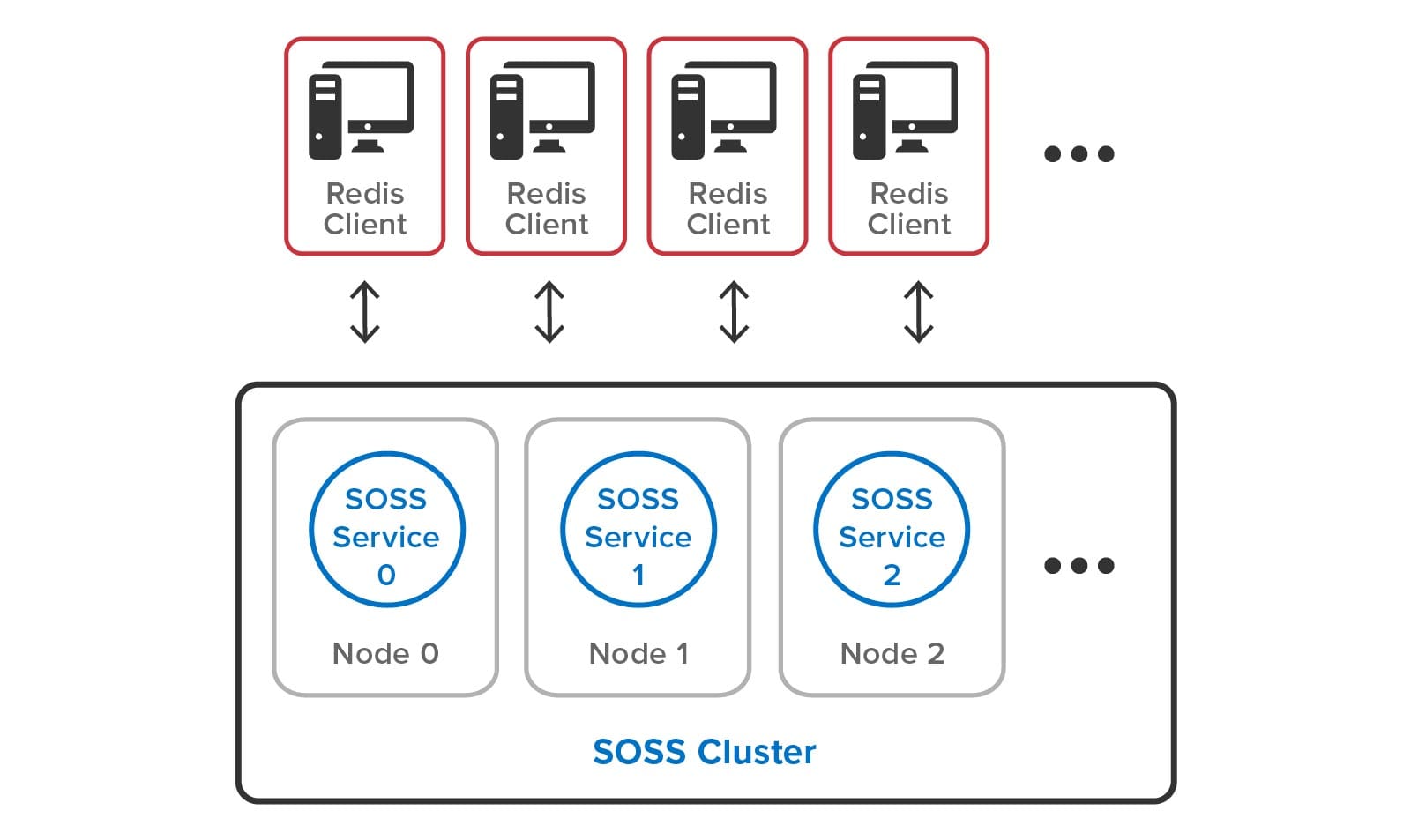
As the need for additional throughput grows, system administrators can simply join new servers to the cluster. ScaleOut StateServer automatically rebalances the hashslots across the cluster as servers are added or removed. It also delays execution of Redis commands during load-balancing (and recovery) to give clients a consistent picture of hashslot placement and avoid client exceptions. After a hashslot has fully migrated to a remote server, a requesting client is returned the Redis -MOVED indication so that it can redirect its request to the new server.
The following diagram illustrates how ScaleOut StateServer automatically manages hashslots. In this example, it migrates half of the hashslots to a second server that joins a cluster:
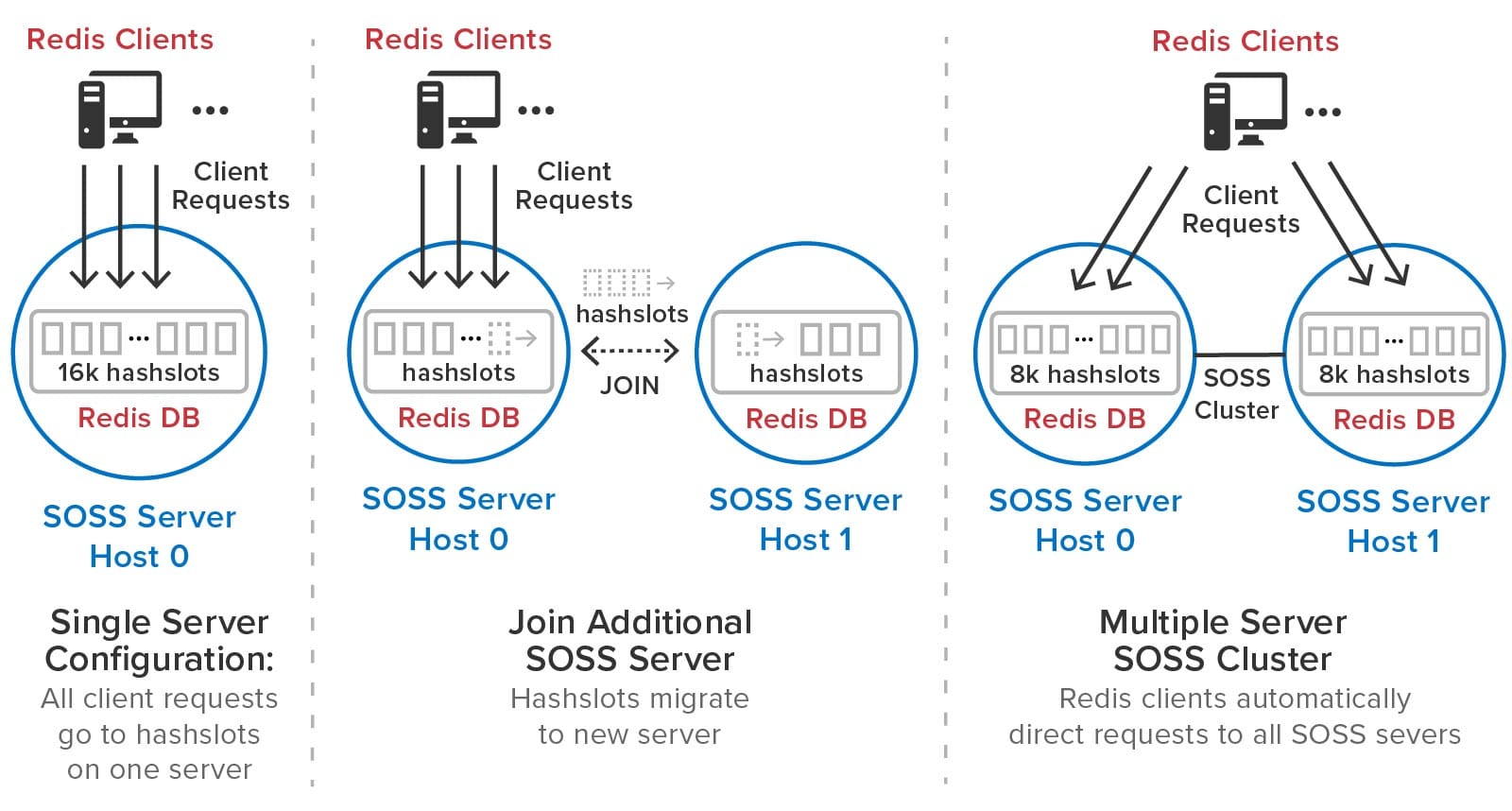
ScaleOut StateServer automatically creates replicas for all hashslots. There is no need for system administrators to manually create master and replica shards or move them from server to server during membership changes and recovery. ScaleOut StateServer automatically places replicas on different servers from their corresponding primary hashslots and migrates them as necessary during membership changes to ensure optimal load-balancing. If a server fails or has a network outage, ScaleOut StateServer automatically “self-heals†by promoting replicas to primaries and creating new replicas as necessary.
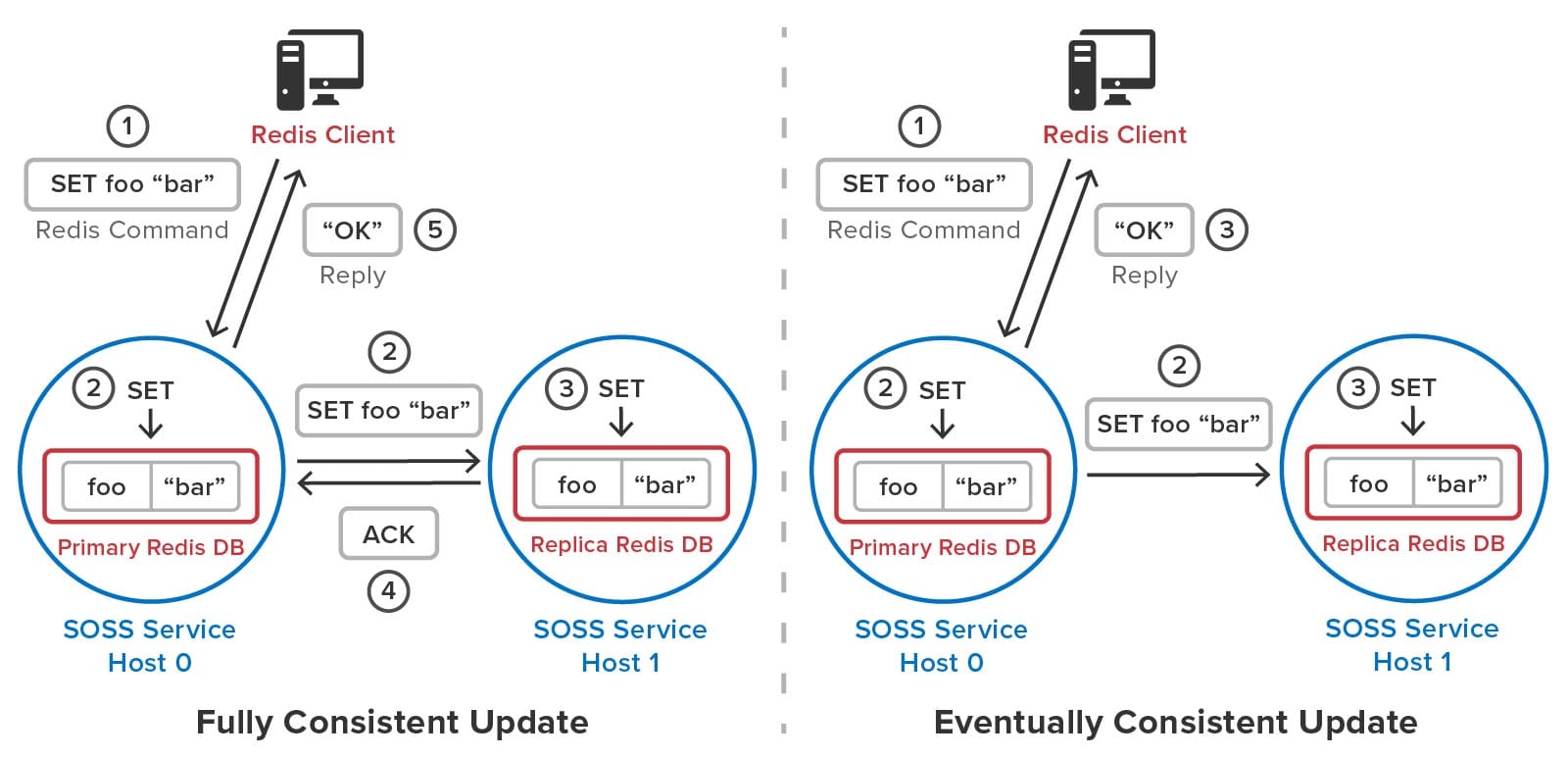
To avoid serving stale data to clients after recovery from an outage, ScaleOut StateServer uses a patented quorum algorithm to implement fully consistent updates to stored objects. In contrast, Redis uses an eventual consistency model for updating replicas. (To maximize throughput at the expense of data consistency, ScaleOut StateServer can optionally be configured for eventual consistency.) When a server receives a Redis command, it executes this command on a quorum containing the primary hashslot and replicas (one or two in the current implementation) prior to returning to the client. Transactions are processed in the same manner.
The following diagram compares the full and eventually consistent models for updating replicas and shows how they differ in behavior. A fully consistent update waits for the replica to be updated prior to returning to the client, whereas an eventually consistent update does not. If a primary server should fail prior to committing the replica’s update, the cluster could lose the update and serve stale data to clients.
Implementation Details
The following diagram shows how Redis open-source code has been integrated into ScaleOut StateServer:
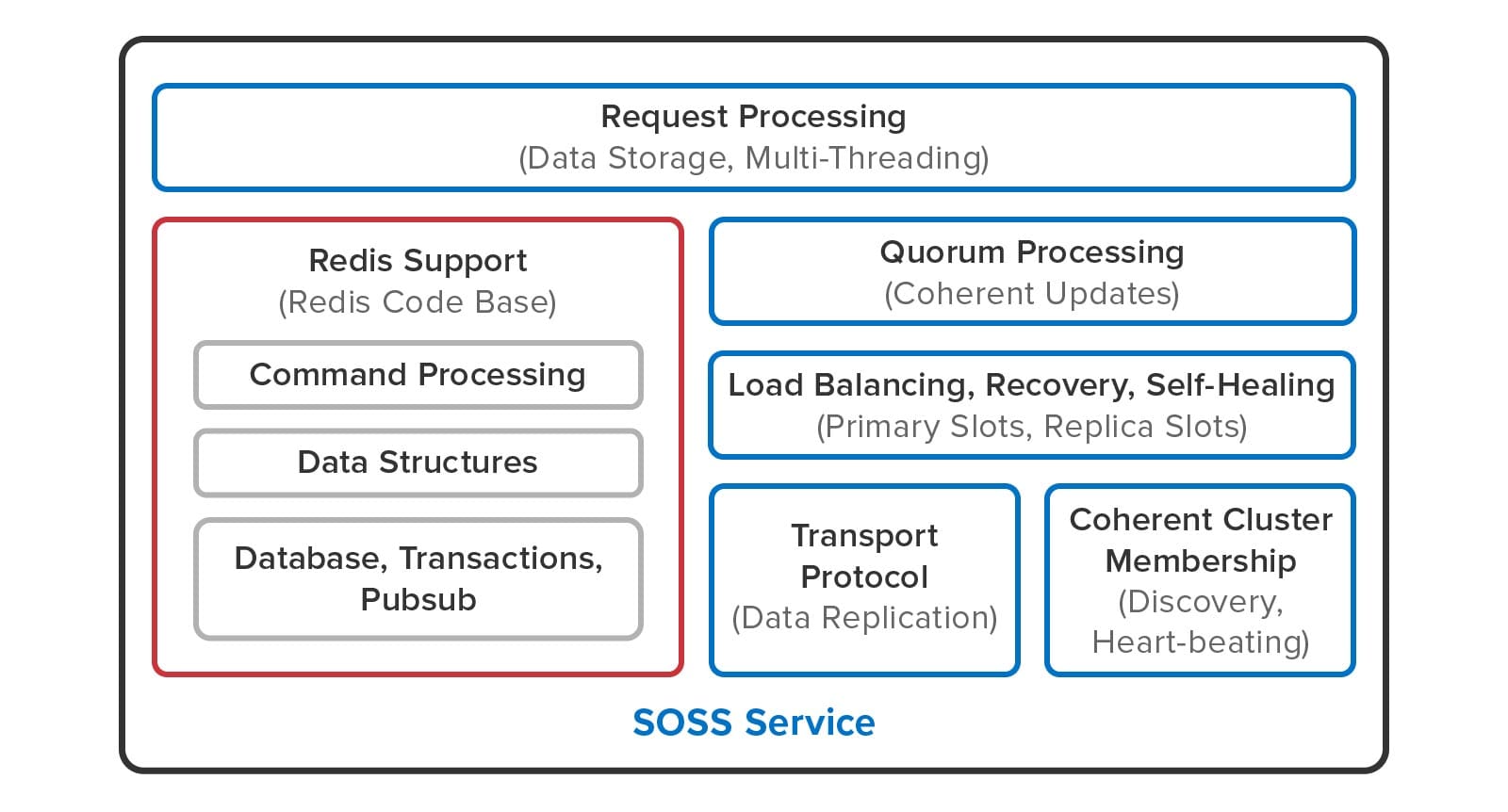
Redis open-source code (shown in the red box) implements command parsing and processing, the data structure commands, transactions, publish/subscribe commands, and blocking commands. ScaleOut StateServer takes over all clustering functions, including request processing, membership, quorum processing of updates, load-balancing, recovery, and self-healing. It also uses a proprietary transport protocol for server-to-server communication.
As illustrated below, ScaleOut StateServer uses multi-threaded execution for Redis commands to take advantage of all processing cores and eliminate the need for multiple primary shards on each server. In contrast, Redis executes commands using an event loop that processes commands sequentially on a single processing core:
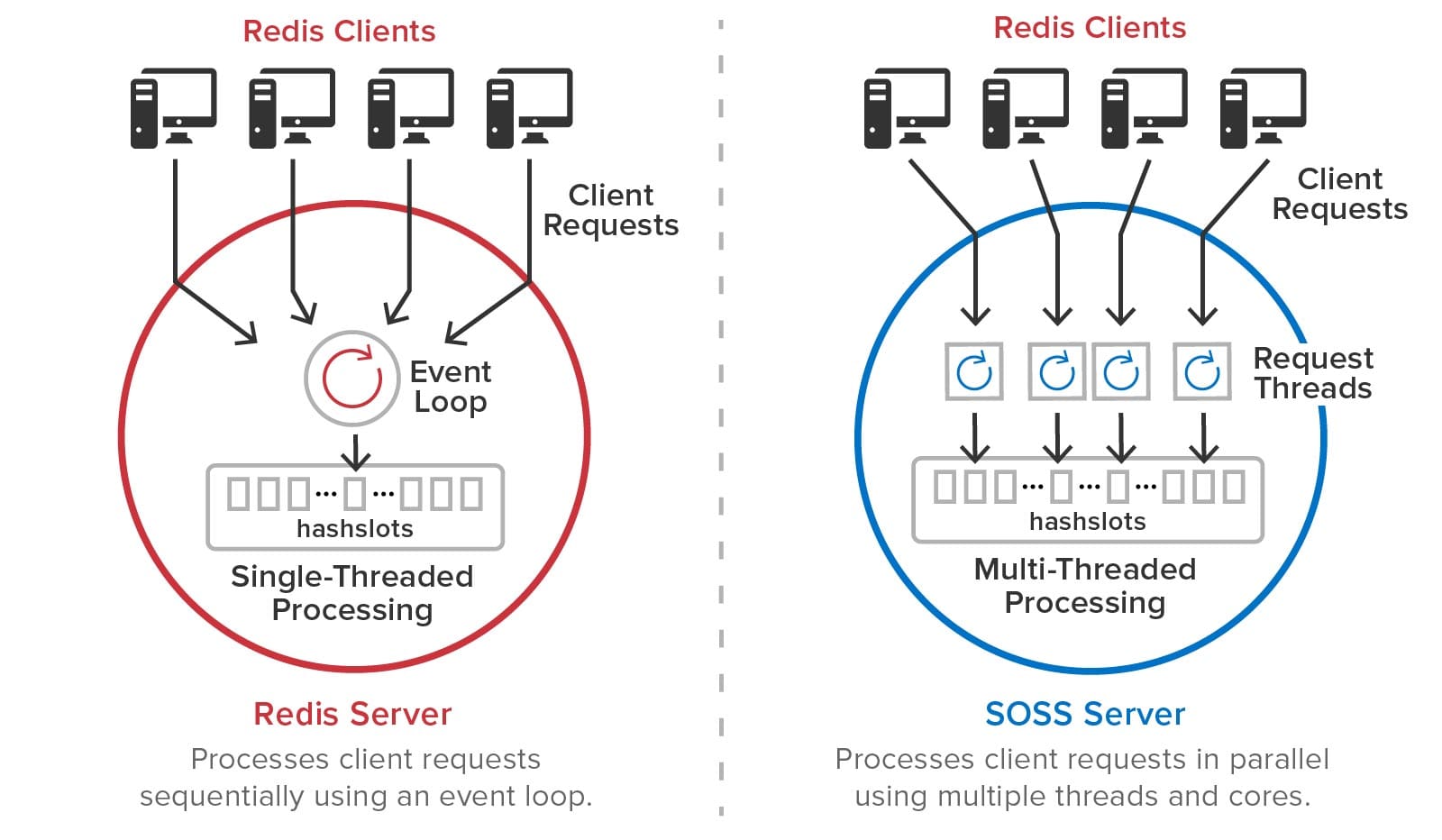
To accomplish this, ScaleOut StateServer has implemented a command scheduler that independently executes commands for each hashslot so that they can run in parallel without global locking.
What’s Missing?
The community preview release focuses on demonstrating support for Redis data structures, which represent the widely used core of Redis functionality. It does not include support for Redis streams, Lua scripting, modules, AOL/RDB persistence, ACLs, and Redis configuration files. In addition, many utility commands which are not required, such as cluster commands for manually moving hashslots, are not supported. Lastly, this version does not incorporate all of the performance enhancements in development for the production release.
Summing Up
ScaleOut’s new integration of Redis open-source code into ScaleOut StateServer was designed to bring powerful new capabilities to Redis users while ensuring native-Redis behavior for client applications. Targeted to meet the needs of enterprise users, it dramatically simplifies the management of Redis clusters by automating all cluster operations, and it ensures that fully consistent updates are performed by Redis commands. In addition, this integration runs alongside ScaleOut StateServer’s native APIs, which incorporate advanced features not available on open-source Redis clusters, such as data-parallel computing, streaming analytics, and coherent, wide-area data replication.
ScaleOut Software is excited to hear your feedback about the community preview and learn what additional features you would like to see in the upcoming production release. You can download ScaleOut StateServer, which incorporates the preview release, here for Linux or Windows and try it out now. Let us know what you think.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Introducing A New Execution Platform for Redis Clients appeared first on ScaleOut Software.
]]>