The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>
by Brandon Ripley, Senior Software Engineer
ScaleOut Software introduces a new Java client API for our distributed caching platform, ScaleOut StateServer®, that adds important new features for Java applications. It was designed with cloud-based deployments in mind, enabling clients to access ScaleOut in-memory data grids (IMDGs also called distributed caches) in multiple availability zones. It introduces the use of connection strings with DNS support for connecting Java clients to IMDGs, and it allows multiple, simultaneous connections to different caches. It also includes asynchronous APIs that add flexibility to application development.
You can download the JAR for the client API from ScaleOut’s Maven repository at https://repo.scaleoutsoftware.com. Simply connect your build tool to the repository and reference the API as a dependency to get started. The online User Guide can help you setup a project. Alternatively, you can download the JAR directly from the repo and then host the JAR with your build tool of choice. You can find an API reference here.
Let’s take a brief tour of the new Java APIs and look at an example using Docker for accessing multiple IMDGs.
A Quick Tour of the Java Client
The ScaleOut client API for Java lets client applications store and retrieve POJOs (plain old java objects) from a ScaleOut IMDG and provides an easy to use, fast, cloud-ready caching API. It can be used within any web application and is independent of any framework. This means that you can use the ScaleOut client API within your existing application architecture.
To simplify the developer experience, the API is logically divided into three primary packages:
Client Package
The client package houses the GridConnection class for connecting to a ScaleOut IMDG via a connection string. Each instance of GridConnection maintains a set of TCP connections to a ScaleOut cache and transparently handles retries, host failures, and load balancing.
The client package is also the place to register for event handling. ScaleOut servers can fire events for objects that are expiring and events for backing store operations (that is, read-through, refresh-ahead, write-behind, and erase-behind). The ServiceEvents class is used to register an event handler for events fired by the grid.
Caching Package
The caching package contains the strongly typed Cache<K,V> class that is used for all caching operations to store and retrieve POJOs of type V using a key of type K from a name space within the IMDG. All caching operations return a CacheResponse that details the result of the cache access.
For example, a successful access that adds a value to the cache using:
cache.add(key, value)
returns a CacheResponse with the status ObjectAdded, which can be obtained by calling the CacheResponse.getStatus() method. However, if the cache already contained an object for the key and the access was called again, CacheResponse.getStatus() would return ObjectAlreadyExists. (See the Javadoc for all possible responses.)
Query Package
The query package lets you perform queries to select objects from the IMDG. Queries are constructed using query filters created using the FilterFactory class. A filter can consist of a simple equality predicate, or it can combine multiple predicates to query with finer granularity.
Sample Applications
The following samples show how the ScaleOut Java client API can be used within a microservices architecture to access cached data and process events. The client API make it easy to develop modern web applications.
In these samples we will:
- Write an application that connects to two ScaleOut IMDGs to store and retrieve objects. (The two caches are configured to replicate data to each other using ScaleOut GeoServer®.)
- Write a second application that registers for and handles ScaleOut expiration events.
- Create four dockerfiles: the caching application, the expiration event handling application, and two ScaleOut IMDGs.
- Use the Docker compose command to spawn all four containers and run the two applications.
You can find the full samples, including the dockerfiles, on GitHub. Let’s look at the code for these two applications.
Accessing Multiple IMDGs
The first application’s goal is to verify ScaleOut GeoServer replication between two IMDGs. It first connects to the two IMDGs, creates an instance of Cache(K,V) for each IMDG, and then performs accesses.
The application connects to the grid using the GridConnection.connect() static method to instantiate a GridConnection object for each IMDG (named store1 and store2 here):
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
The next step is to create an instance of Cache(K,V) for each IMDG. Caches are instantiated with a GridConnection which associates the instance with a specific IMDG. This allows different instances to connect to different IMDGs.
The Java client API uses a builder pattern to instantiate caches. For applications using dependency injection, the immutable cache guarantees that the defaults we set at build time will stay consistent for the lifetime of the app. This is great for large applications with many caches as it guarantees there will be no unexpected modifications.
On the builder we can specify properties for defaults. Here is an example that sets an object timeout of fifteen seconds and a timeout type of Absolute (versus ResetOnUpdate or Sliding). The string “example” specifies the cache’s name space:
Cache<Integer, String> store1Cache = new CacheBuilder<Integer, String>(store1Connection, "example", Integer.class)
.objectTimeout(Duration.ofSeconds(15))
.timeoutType(TimeoutType.Absolute)
.build();
The Cache(K,V) class has multiple signatures for storing and retrieving objects from the IMDG. These signatures follow traditional Java naming semantics for distributed caching. For example, the add(key,value) method assumes that no key/value object mapping exists in the cache, whereas update(key,value) assumes than a key/value mapping exists in the cache.
This application uses the add method to insert an item into store1Cache and then checks the response for success. Here’s a code sample that adds two items to the cache:
CacheResponse<String, String> addResponse = store1Cache.add(“MyKey”, "SomeValue");
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
addResponse = store1Cache.add(“MyFavoriteKey”, "MyFavoriteValue");
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
The application’s goal is to verify that ScaleOut GeoServer replicates stored objects from the store1 IMDG to store2. It creates an instance of Cache(K,V) for the same namespace on store2 and then attempts to retrieve the object with the read API:
CacheResponse<String, String> readResponse = store2Cache.read(“Key”);
if(readResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
Registering for Events
This sample application demonstrates how an application can have fine grain control over which objects will be removed from the IMDG after a time interval elapses. With the object timeout and timeout-type properties established, objects added to the IMDG will be subject to expiration. When an object expires, the ScaleOut grid will fire an expiration event.
Our application can register to handle expiration events by supplying an instance of Cache(K,V) and an appropriate lambda (or implementing class) to the ServiceEvents static method. The following code removes all objects other than a cache entry mapping with the key, “MyFavoriteKey”:
ServiceEvents.setExpirationHandler(cache, new CacheEntryExpirationHandler<Integer, String>() {
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<Integer, String> cache, String key) {
System.out.println("ObjectExpired: " + key);
if(key.compareTo(“MyFavoriteKey”) == 0)
return CacheEntryDisposition.Save;
return CacheEntryDisposition.Remove;
}});
Running the Applications
We’ve created code snippets for connecting to a ScaleOut grid, creating a cache, and registering for ScaleOut expiration events. We can put all these pieces together to create the two applications with two Java classes called CacheRunner and CacheExpirationListener.
CacheRunner connects to two ScaleOut IMDGs that are setup for push replication using ScaleOut GeoServer. (This is handled by the infrastructure via the dockerfiles and not done in code.) It creates an instance of Cache(K,V) associated with one of the IMDG (called store1) that has a very small absolute timeout for each object and another instance for the other IMDG (called store2). It stores an object in store1 and then retrieves it from store2 to verify that the object was pushed from one IMDG to the other.
Here is the code for CacheRunner:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.caching.*;
import java.time.Duration;
public class CacheRunner {
public static void main(String[] args) throws CacheException, GridConnectException {
System.out.println("Connecting to store 1...");
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
System.out.println("Connecting to store 2...");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
.geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
.objectTimeout(Duration.ofSeconds(15))
.objectTimeoutType(TimeoutType.Absolute)
.build();
Cache<String, String> store2Cache = new CacheBuilder<String, String>(store2Connection, "sample", String.class)
.build();
System.out.println("Adding object to cache in store 1!");
CacheResponse<String, String> addResponse = store1Cache.add("MyKey", "MyValue");
System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
addResponse = store1Cache.add("MyFavoriteKey", "MyFavoriteValue");
System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
System.out.println("Reading object from cache in store 2!");
CacheResponse<String,String> readResponse = store2Cache.read("foo");
System.out.println("Object " + ((readResponse.getStatus() == RequestStatus.ObjectRetrieved ?
"retrieved" : "not retrieved.")) + " from cache in store 2.");
}
}
CacheExpirationListener connects to one ScaleOut IMDG, create an instance of Cache(K,V), and registers for expiration events. Here is its code:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.ServiceEvents;
import com.scaleout.client.ServiceEventsException;
import com.scaleout.client.caching.*;
import java.io.IOException;
import java.time.Duration;
import java.util.concurrent.CountDownLatch;
public class ExpirationListener {
public static void main(String[] args) throws ServiceEventsException, IOException, InterruptedException,
GridConnectException {
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
.geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
.objectTimeout(Duration.ofSeconds(15))
.objectTimeoutType(TimeoutType.Absolute)
.build();
ServiceEvents.setExpirationHandler(store1Cache, new CacheEntryExpirationHandler<String, String>() {
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<String, String> cache, String key) {
CacheEntryDisposition disposition = CacheEntryDisposition.NotHandled;
System.out.printf("Object (%s) expired\n", key);
if(key.equals("MyFavoriteKey"))
disposition = CacheEntryDisposition.Save;
else disposition = CacheEntryDisposition.Remove;
return disposition;
}
});
}
}
To run these applications, we’ll use the Docker compose command to build Docker containers. We will have 4 services, each defined in their own respective dockerfile, which are all provided and available on the GitHub repo. You can clone the repository and then run the deployment with the following command:
docker-compose -f ./docker-compose.yml up -d –build
Here is the expected output for CacheRunner:
Adding object to cache in store 1! Object added to cache in store 1. Object added to cache in store 1. Reading object from cache in store 2! Object retrieved. from cache in store 2.
Here is the output for ExpirationListener:
Connected to store1! Object (MyFavoriteKey) expired Object (MyKey) expired
Summing Up
The new ScaleOut client API for Java adds important features that support the development of modern web and cloud applications. Built-in support for connection strings enables simultaneous connections to multiple IMDGs using DNS entries. Full support for asynchronous accesses also assists in application development. Let us know what you think with your comments on our community forum.
The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>The post ScaleOut Software Announces the Availability of ScaleOut GeoServer® Pro appeared first on ScaleOut Software.
]]>BELLEVUE, Wash – November 17, 2020 – ScaleOut Software today announced ScaleOut GeoServer® Pro, a new software product release that integrates site-to-site data replication with fully coherent data access for its battle-tested ScaleOut StateServer® in-memory data grid (IMDG) and distributed cache. This release extends the company’s ScaleOut GeoServer® DR product, which provides asynchronous, site-to-site data replication to protect against site-wide failures and currently is in production use.
For more than fifteen years, ScaleOut StateServer has set the standard for high performance reliability and industry-leading ease of use at hundreds of enterprise sites around the world. The product stores fast-changing data in a wide variety of applications, including ecommerce, financial services, online learning, airline reservations, gaming and much more.
“With the release of ScaleOut GeoServer Pro, we are excited to offer our customers breakthrough capabilities for multi-site storage of their fast-changing data,” said Dr. William L. Bain, founder and CEO of ScaleOut Software. “Now they can take advantage of our industry-leading technology that replicates data across sites to protect against data center failures while making fully coordinated use of the sites.”
By harnessing ScaleOut GeoServer Pro, users can now take in-memory data storage and distributed caching to the next level with an integrated solution for disaster recovery and synchronized data access across multiple sites. This technology enables applications to both protect against site-wide failures and to maintain a consistent view of data stored at all data centers.
Key ScaleOut GeoServer Pro Benefits:
ScaleOut GeoServer Pro enables organizations to store, access and protect fast-changing data at multiple sites, while maintaining a consistent view of the data at all times. The technology ensures that critical data is always accessible and synchronized across locations.
- Transparent Replication Across Data Centers: Applications can automatically replicate all stored data across multiple data centers for continuous availability in case a data center fails. This includes replicating in-memory data across different cloud regions, while automatically coordinating access to data stored at these sites.
- Integrated, Synchronized Data Access: ScaleOut GeoServer Pro introduces optional, synchronized access to replicated data across multiple data centers. This enables applications that distribute workloads across data centers to maintain a straightforward, unified view of stored data. For example, web applications which use a global load balancer to share user data held in two data centers can now use both data centers in an “active-active” configuration.
- Automatic Recovery from WAN Failures: In the event of a WAN failure between data centers, applications can independently access data at each data center. When WAN connectivity is re-established, ScaleOut GeoServer Pro automatically resolves inconsistencies in stored data due to duplicate updates during the WAN outage known as a “split-brain” condition.
- Maximize Application Performance: To maximize overall performance, ScaleOut GeoServer Pro’s caches offer flexible coherency policies so that applications can select the appropriate combination of coherency and access latency according to data usage. This avoids unnecessary WAN data usage and associated delays.
Additional Resources:
For more information about ScaleOut GeoServer Pro, please visit:
- ScaleOut GeoServer Pro announcement blog post
- ScaleOut GeoServer Pro product page
About ScaleOut Software
Founded in 2003, ScaleOut Software develops leading-edge software that delivers scalable, highly available, in-memory computing and streaming analytics technologies to a wide range of industries. ScaleOut Software’s in-memory computing platform enables operational intelligence by storing, updating, and analyzing fast-changing, live data so that businesses can capture perishable opportunities before the moment is lost. It has offices in Bellevue, Washington and Beaverton, Oregon.
For more information, please visit www.scaleoutsoftware.com and follow @scaleout_inc
###
Contact:
RH Strategic for ScaleOut Software
The post ScaleOut Software Announces the Availability of ScaleOut GeoServer® Pro appeared first on ScaleOut Software.
]]>The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>
Web applications, such as ecommerce sites and financial services, often need to replicate fast-changing, in-memory data across multiple data centers or cloud regions. As part of an overall strategy for disaster recovery, cross-site data replication ensures that mission-critical data is continuously available, even if one site goes offline.
Many applications need to use two (and sometimes more) sites in an “active-active” manner, distributing the workload across the sites. Here are some real-world applications we have seen. Ecommerce applications need to maintain shopping carts at multiple sites and distribute the workload from their shoppers with a global load-balancer. Cell phone providers need to keep their lists of available mobile numbers consistent across sites as individual stores allocate them. Conference-management companies need to keep attendee lists and schedules consistent at conference sites and their central data center.
Let’s take a closer look at an ecommerce site using a global load-balancer to distribute incoming web requests to multiple sites. This approach lets the web application take advantage of the processing power at multiple sites during normal operations. However, it creates the challenge of coordinating access to in-memory objects which are replicated across two or more sites. This can add substantial complexity if handled by the application.
Here’s an example of an ecommerce site using a global load-balancer to distribute incoming web requests across two sites, each of which hosts shopping carts within an in-memory data grid (also called a distributed cache), such as ScaleOut StateServer®. A web shopper might select a pair of shoes and place them in the shopping cart followed by selecting a tennis racket. As shown in the following diagram, the global load-balancer sends the first request to site 1 and the second request to site 2 in this example:
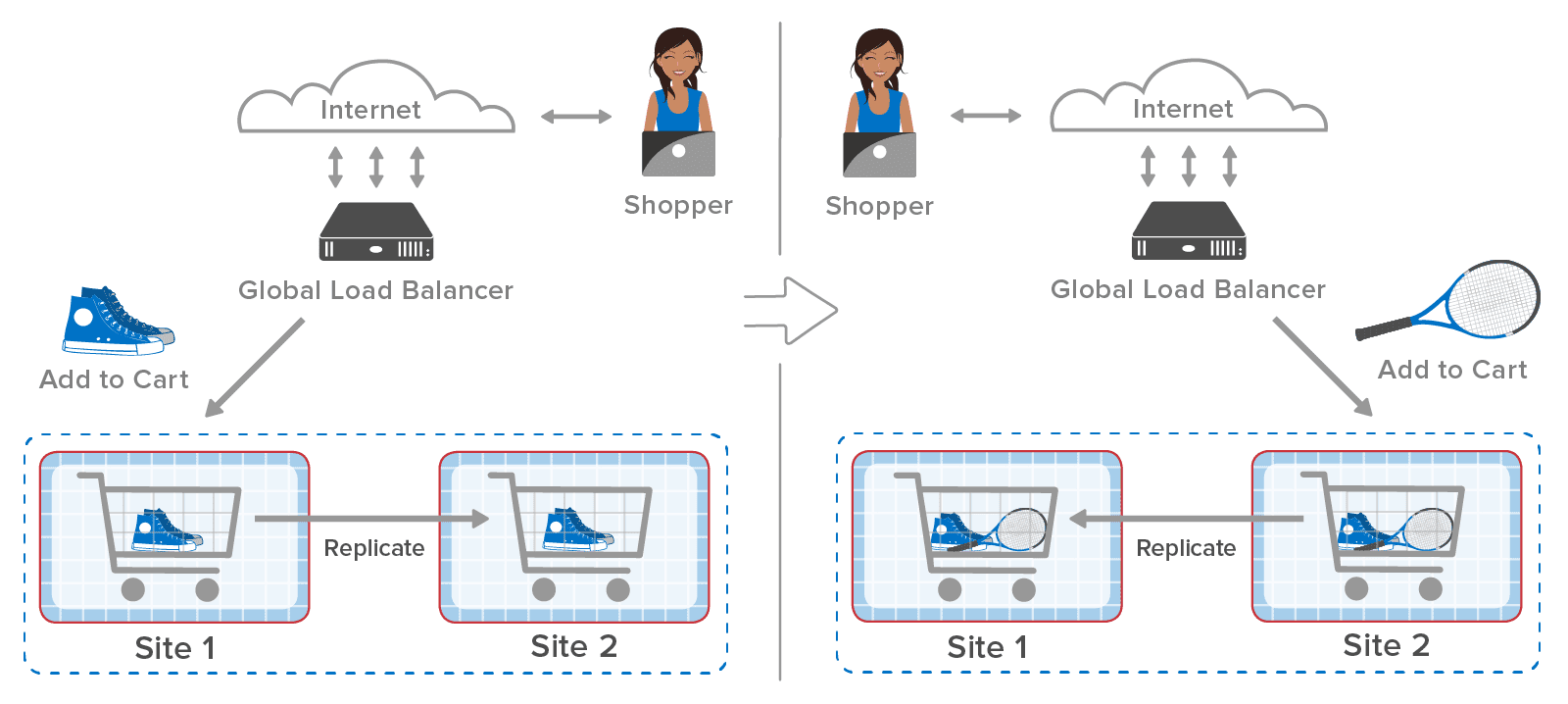
After the first request completes, the in-memory data grid at site 1 replicates the cart to site 2. The global load-balancer then sends the second request to site 2, which adds the tennis racket to the cart. Finally, site 2 replicates the changes back to site 1 so that both sites have the latest copy of the shopping cart.
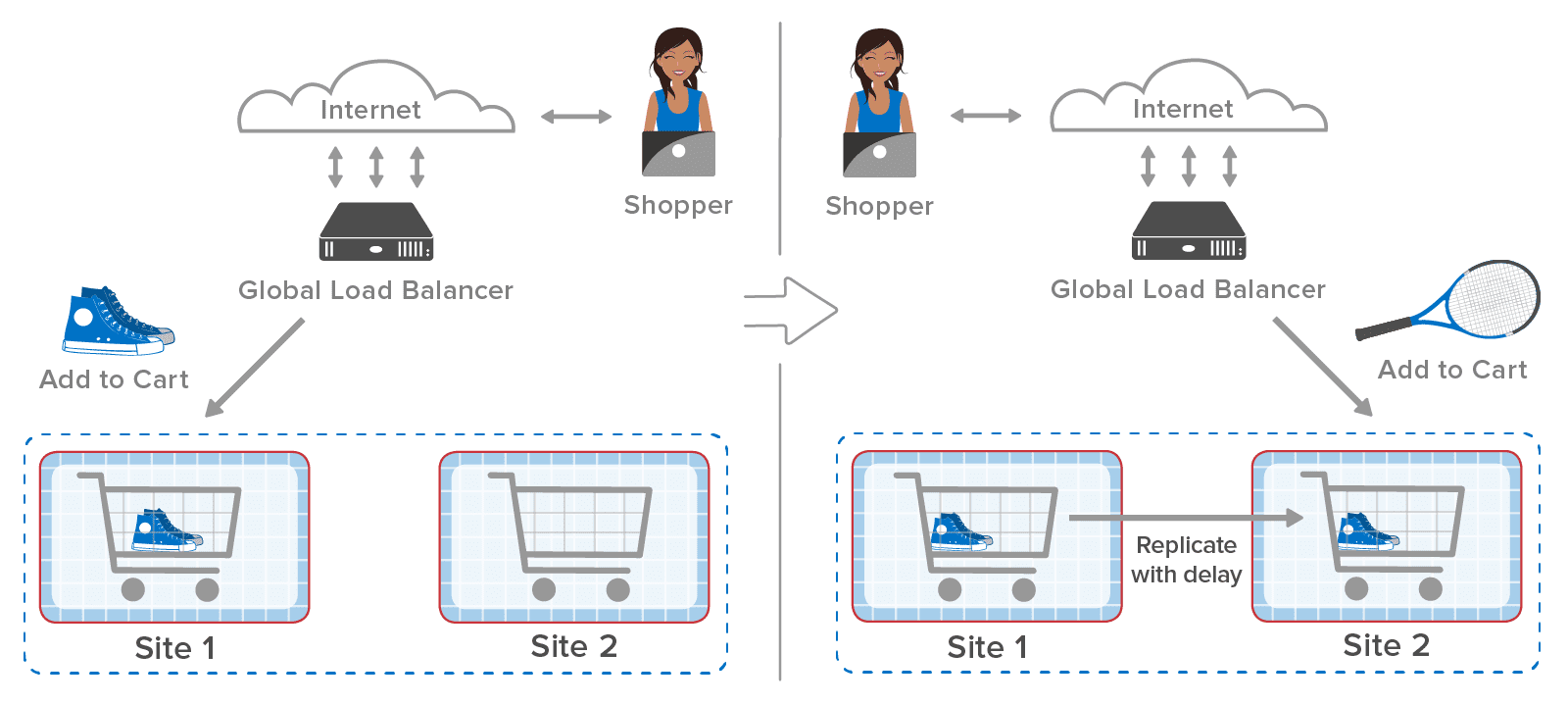
What happens if replication from site 1 to site 2 is slightly delayed? After site 2 puts the tennis racket in the cart, the incoming replicated update arrives and overwrites the cart. This causes both sites to lose the update at site 2, and the shopper will undoubtedly be annoyed to find that the tennis racket is missing from the cart:
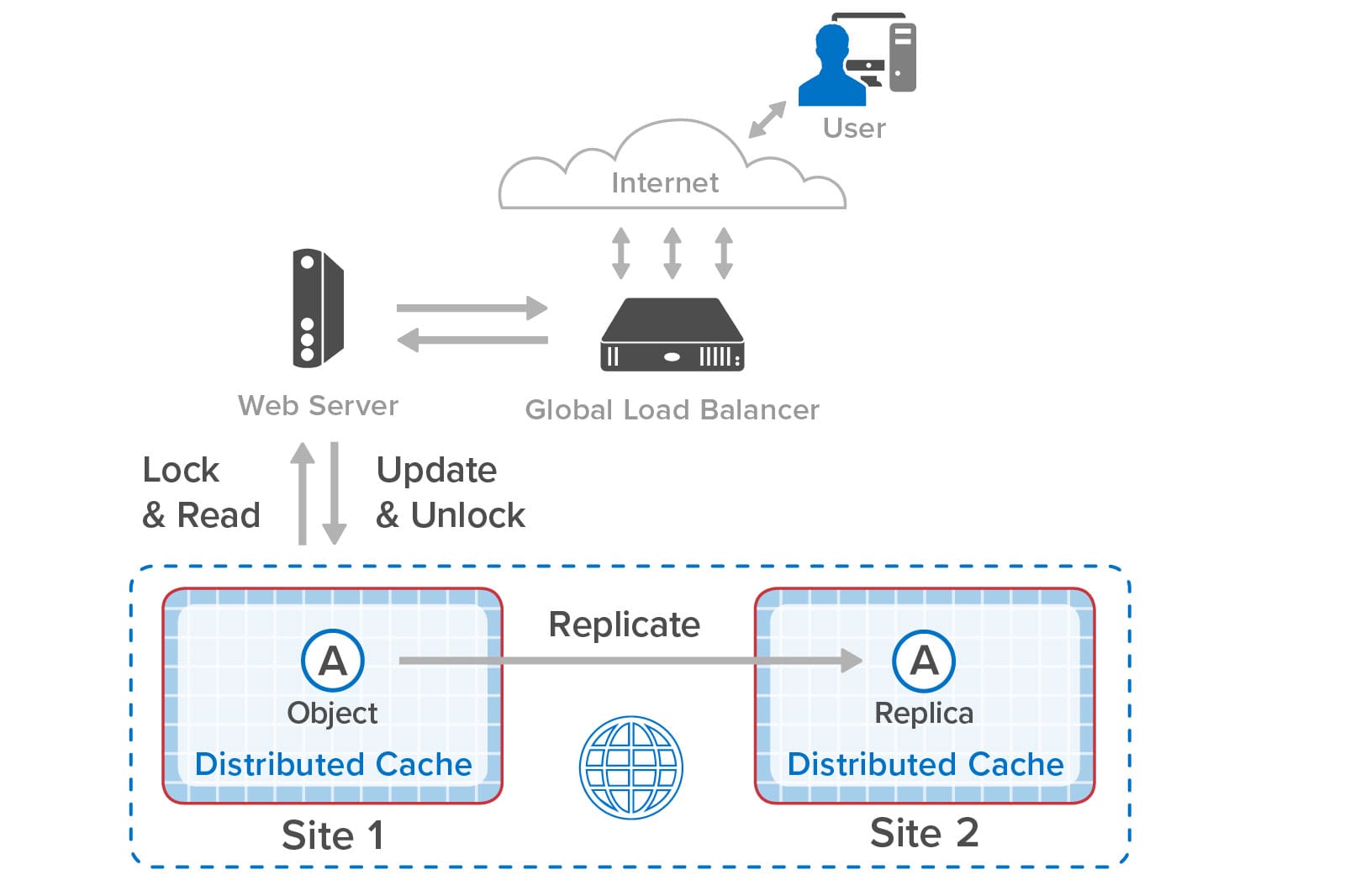
The solution to this problem is to have the web applications at both sites synchronize updates to the shopping carts. This ensures that only one site at a time updates the shopping cart and that each site always sees the latest version of the in-memory object. Using ScaleOut GeoServer Pro, applications can use standard object-locking APIs for this purpose, just as they would to coordinate object access within a single in-memory data grid:
After the web application on site 1 updates and unlocks object A (the shopping cart in our example), site 1 replicates the update to site 2. When the global load-balancer sends the next request to site 2, the web application on that site 2 also locks and reads the object, updates it, and then unlocks it:
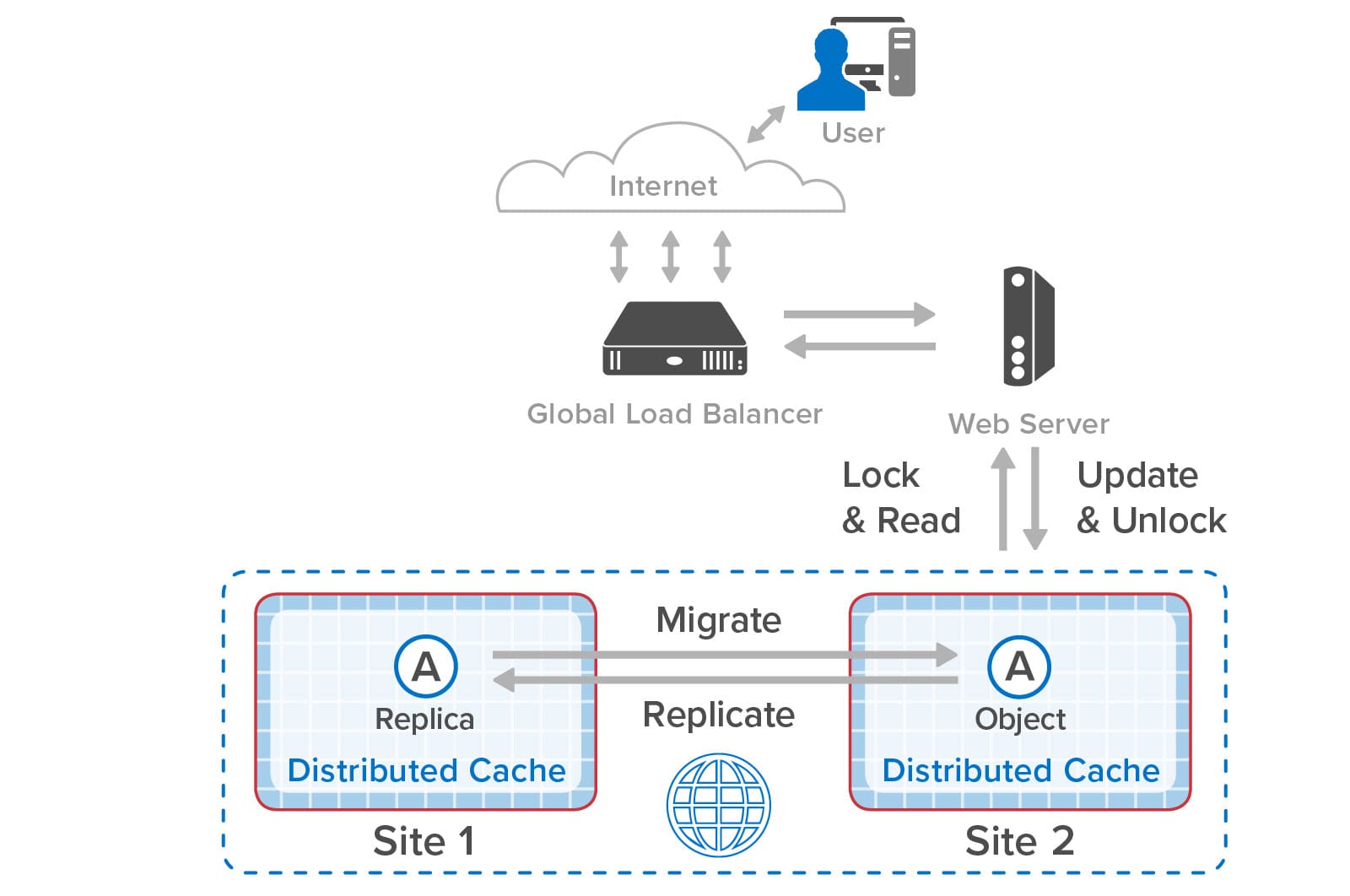
When the object is locked on site 2, ScaleOut GeoServer Pro makes sure that the application sees the latest version of the object. It does so by migrating ownership of the object to site 2 and checking that it has the latest version. Although this requires a round trip to site 1, once a site gains ownership, all further accesses are local until the other site again attempts to lock the object and request ownership. If the global load-balancer avoids ping-ponging between sites with every web request, the latency to lock an object remains low.
Should the wide area network (WAN) connecting the two sites fail, or if the remote site goes offline, the two sites can operate independently; this is called “split brain” mode in distributed systems. They detect the WAN failure and automatically promote local replica objects as needed to gain ownership when requesting a lock. This enables uninterrupted operations that make use of object replicas held at each site. By combining object replication with synchronized access, applications enjoy the full benefits of synchronized object access across sites during normal operations and uninterrupted access during WAN or site outages:
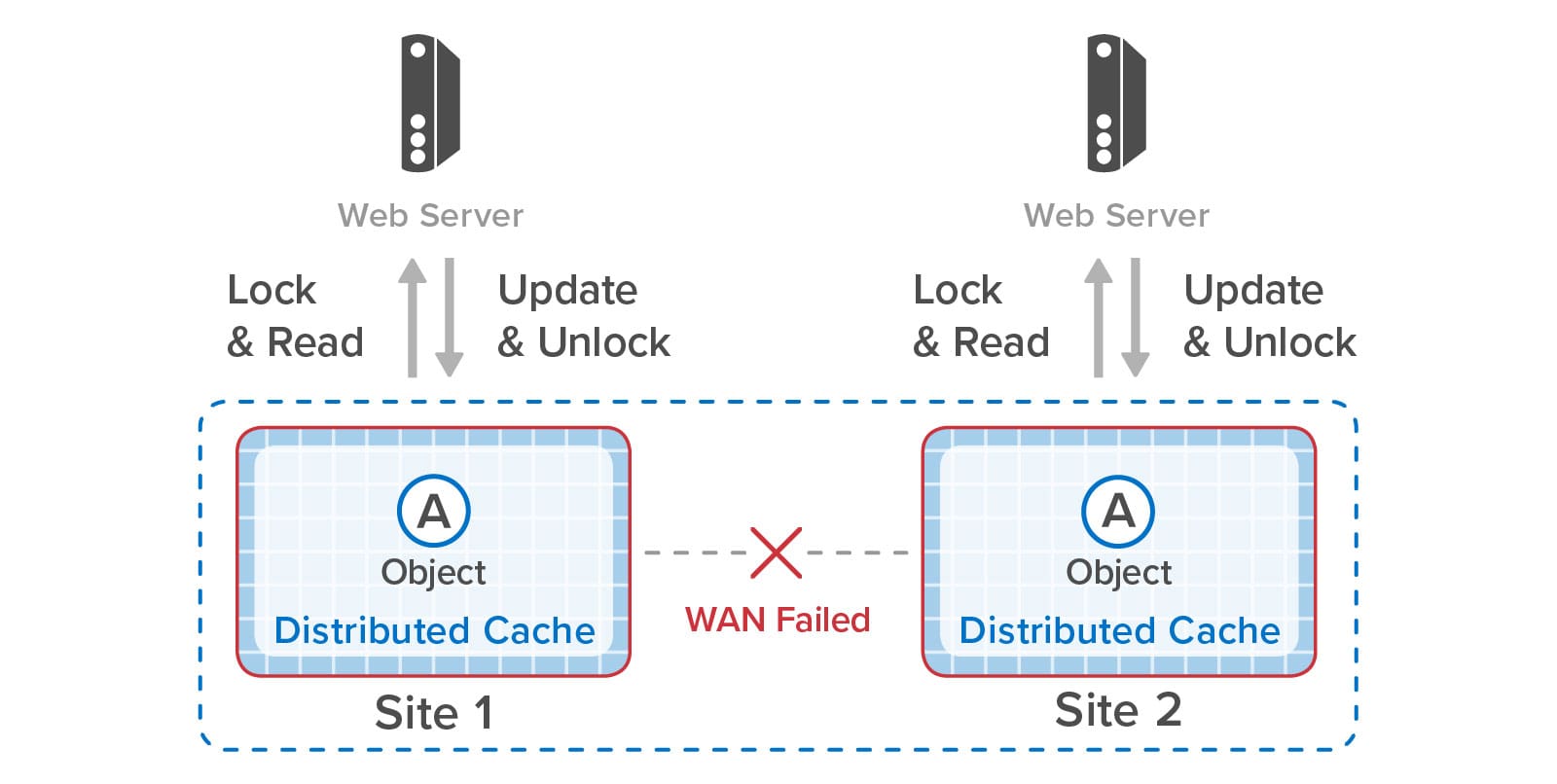
A key challenge created by split-brain mode is how to restore normal operations after an outage has been corrected. For example, the following diagram shows the two sites in our shopping example operating independently during a WAN outage that occurs between the two web requests. Site 1 adds the shoes to its shopping cart but is unable to replicate that update to site 2. The web application on site 2 then places the tennis racket in its shopping cart:
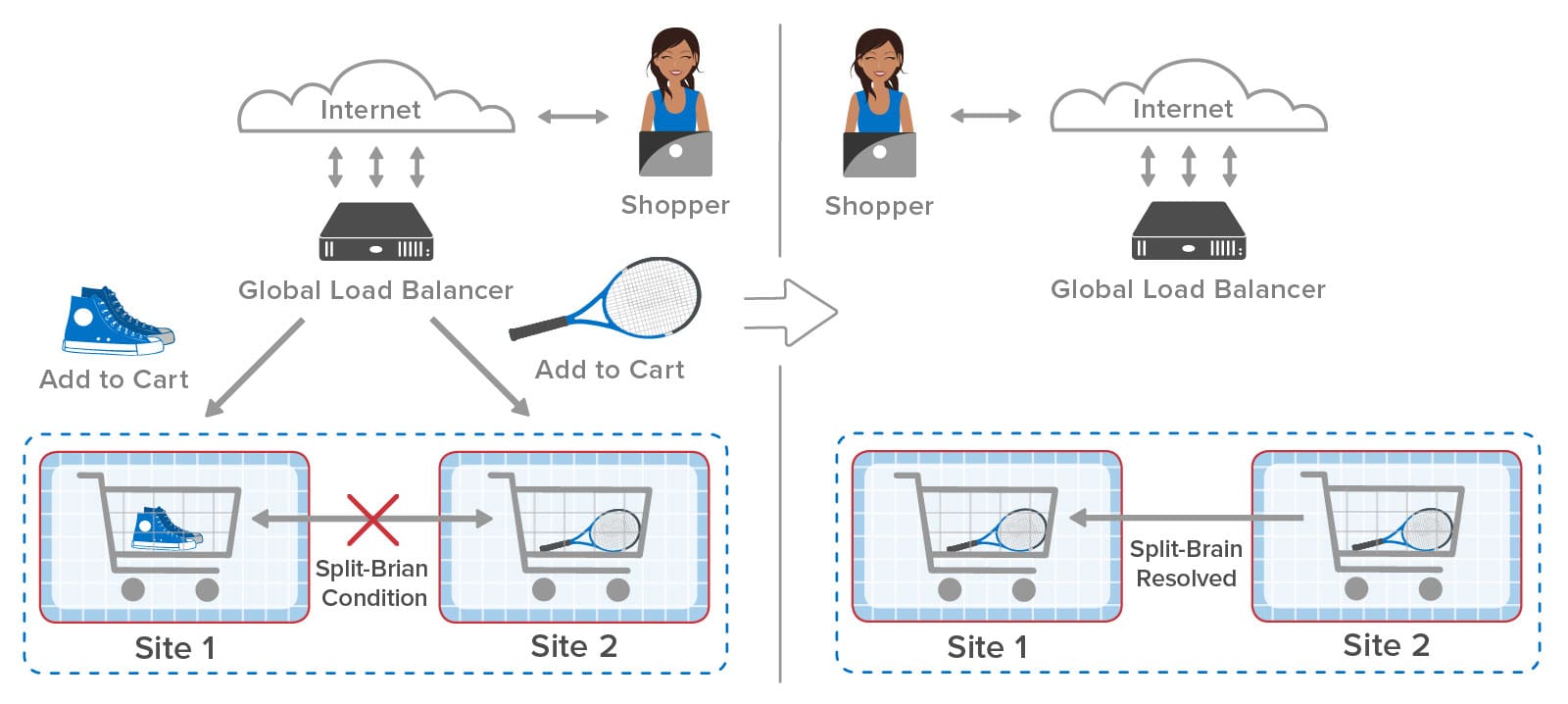
After the WAN is restored, the two sites have to resolve the differences in the contents of their copies of stored objects. Unless the application uses special, conflict-free data types that can be merged (and this is rare for most applications), a heuristic needs to be used to resolve conflicts. ScaleOut GeoServer Pro automatically resolves conflicts for each pair of object copies by selecting the copy with the latest update time or randomly picking one of the copies if the update times are the same. So in this case, both sites are updated with the version of the shopping cart holding the tennis racket. (This will be another source of annoyance for our shopper, but at least the ecommerce site survived a WAN outage without interruption.)
ScaleOut GeoServer Pro resolves split-brain conflicts as it detects them when updates are performed and then are successfully replicated across the WAN. It also has to resolve the fact that both sites now think they own the same object, and it handles this by randomly picking a site to retain ownership. As the two sites attempt to lock and read the object, ownership will then automatically migrate to the site where it’s needed.
One more key benefit of ScaleOut GeoServer Pro is that it lets applications efficiently access objects that have slowly changing contents (such as product descriptions, schedules, and portfolio lists) without making repeated WAN accesses. Sites that are configured for bi-directional replication have immediate access to replicas when just reading but not updating remote objects. Other sites can be configured to maintain local copies of remote objects (called “proxies”) that can periodically poll for updates using a configurable timeout. This minimizes WAN accesses while allowing applications to track changes in objects stored at remote sites.
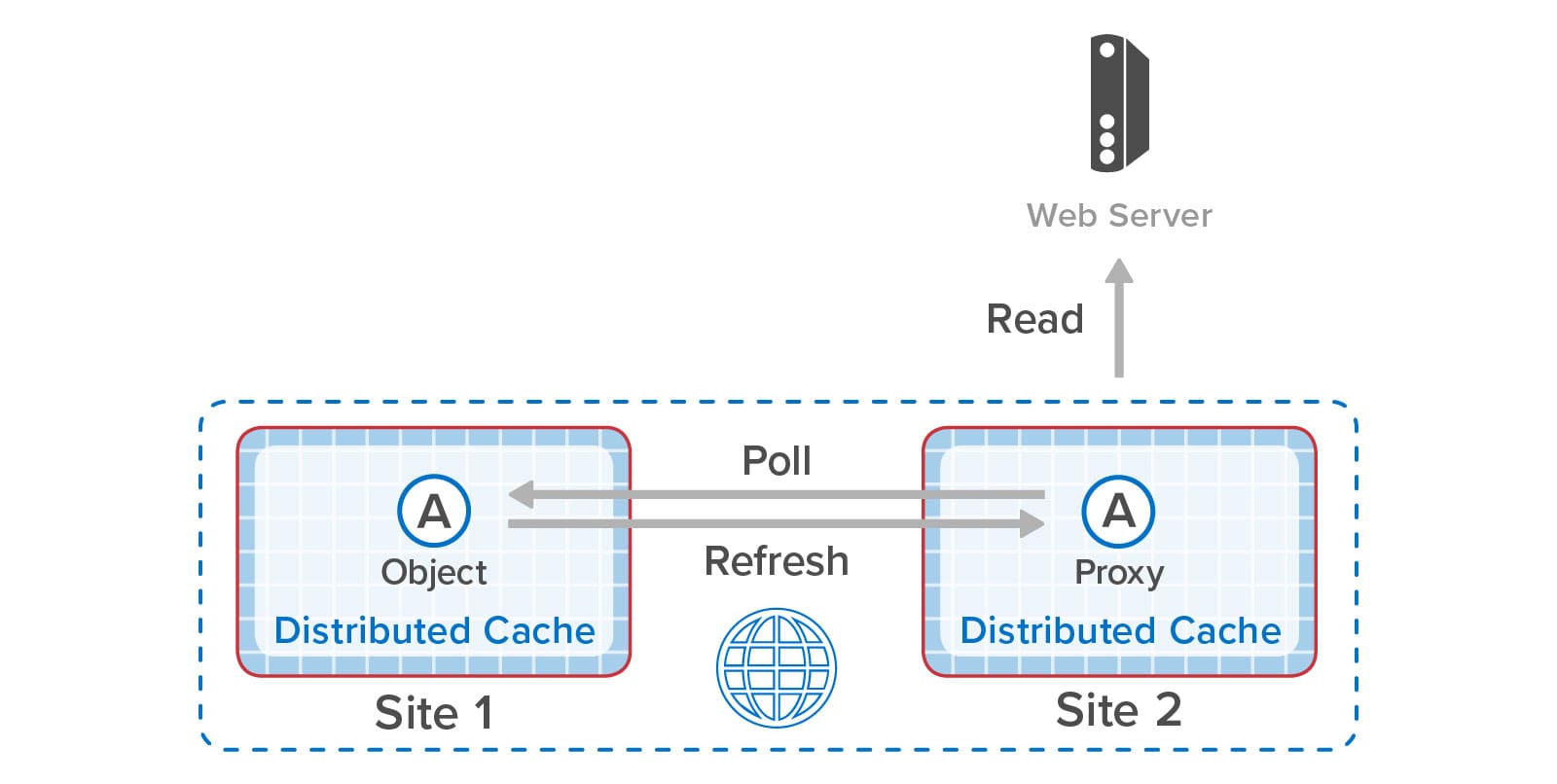
To illustrate how all of these features can work together, the following diagram shows two sites on the west coast of the U.S. configured for bi-directional replication and synchronized access along with additional “satellite” sites in other states that are periodically polling to read data held in the “live” data centers:
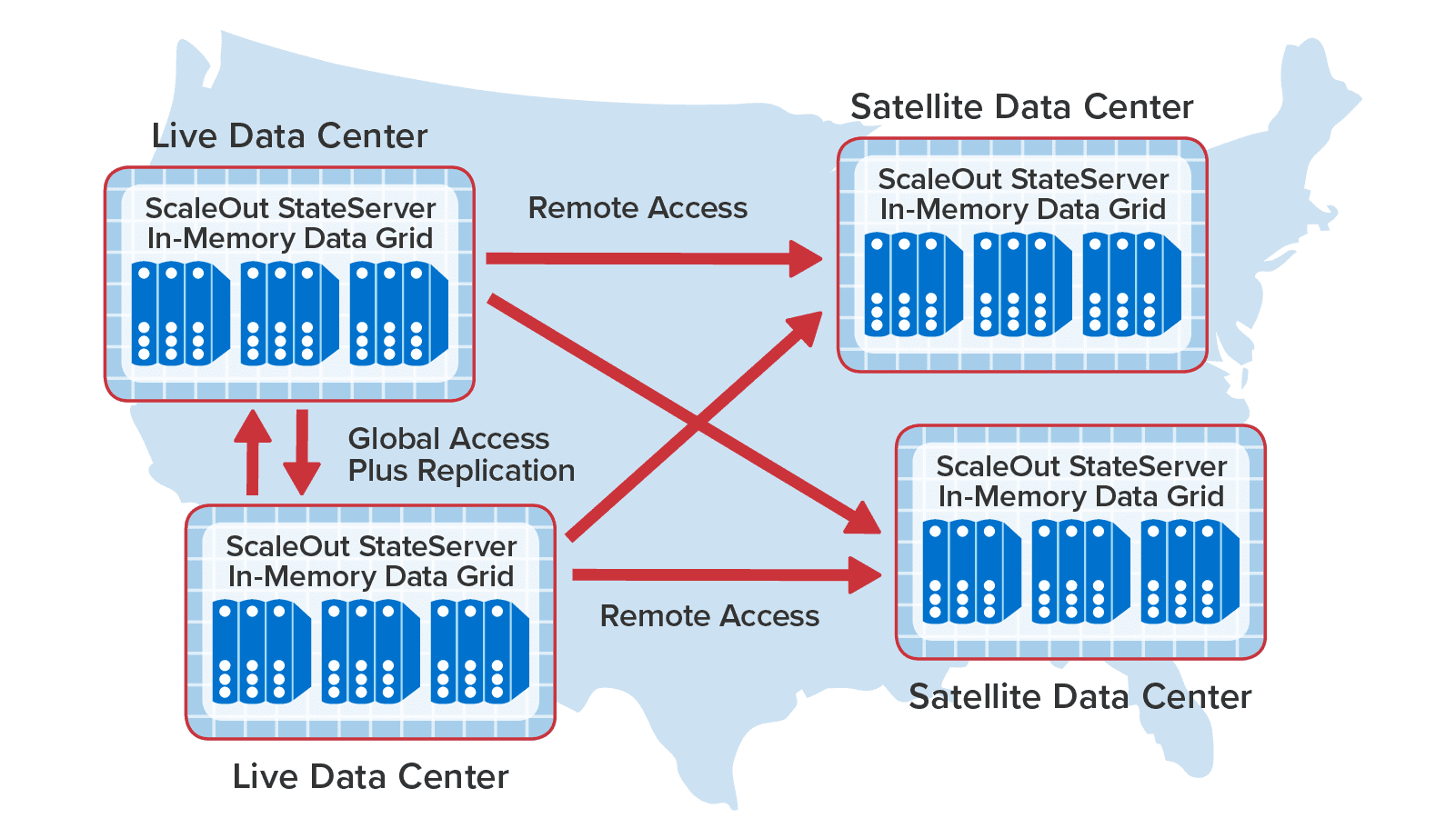
With its advanced capabilities for combining data replication with synchronized access, ScaleOut GeoServer Pro takes a leadership position among commercial in-memory data grids by enabling applications to seamlessly access and update objects replicated across data centers. This solves a long-standing challenge for applications that actively maintain mission-critical data at multiple sites and further extends the power of in-memory data grids to manage fast-changing business data.
The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>