The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>
by Olivier Tritschler, Senior Software Engineer
Because of their ability to provide highly elastic computing resources, public clouds have become a highly attractive platform for hosting distributed caches, such as ScaleOut StateServer®. To complement its current offerings on Amazon AWS and Microsoft Azure, ScaleOut Software has just announced support for the Google Cloud Platform. Let’s take a look at some of the benefits of hosting distributed caches in the cloud and understand how we have worked to make both deployment and management as simple as possible.
Distributed Caching in the Cloud
Distributed caches, like ScaleOut StateServer, enhance a wide range of applications by offering shared, in-memory storage for fast-changing state information, such as shopping carts, financial transactions, geolocation data, etc. This data needs to be quickly updated and shared across all application servers, ensuring consistent tracking of user state regardless of the server handling a request. Distributed caches also offer a powerful computing platform for analyzing live data and generating immediate feedback or operational intelligence for applications.
Built using a cluster of virtual or physical servers, distributed caches automatically scale access throughput and analytics to handle large workloads. With their tightly integrated client-side caching, these caches typically provide faster access to fast-changing data than backing stores, such as blob stores and database servers. In addition, they incorporate redundant data storage and recovery techniques to provide built-in high availability and ensure uninterrupted access if a server fails.
To meet the needs of elastic applications, distributed caches must themselves be elastic. They are designed to transparently scale upwards or downwards by adding or removing servers as the workload varies. This is where the power of the cloud becomes clear.
Because cloud infrastructures provide inherent elasticity, they can benefit both applications and distributed caches. As more computing resources are needed to handle a growing workload, clouds can deploy additional virtual servers (also called cloud “instances”). Once a period of high demand subsides, resources can be dialed back to minimize cost without compromising quality of service. The flexibility of on-demand servers also avoids costly capital investments and reduces management costs.
Deploying ScaleOut’s Distributed Cache in the Google Cloud
A key challenge in using a distributed cache as part of a cloud-hosted application is to make it easy to deploy, manage, and access by the application. Distributed caches are typically deployed in the cloud as a cluster of virtual servers that scales as the workload demands. To keep it simple, a cloud-hosted application should just view a distributed cache as an abstract entity and not have to keep track of individual caching servers or which data they hold. The application does not want to be concerned with connecting N application instances to M caching servers, especially when N and M (as well as cloud IP addresses) vary over time. In particular, an application should not have to discover and track the IP addresses for the caching servers.
Even though a distributed cache comprises several servers, the simplest way to deploy and manage it in the cloud is to identify the cache as a single, coherent service. ScaleOut StateServer takes this approach by identifying a cloud-hosted distributed cache with a single “store” name combined with access credentials. This name becomes the basis for both managing the deployed servers and connecting applications to the cache. It lets applications connect to the caching cluster without needing to be aware of the IP addresses for the cluster’s virtual servers.
The following diagram shows a ScaleOut StateServer distributed cache deployed in Google Cloud. It shows both cloud-hosted and on-premises applications connected to the cache, as well as ScaleOut’s management console, which lets users deploy and manage the cache. Note that while the distributed cache and applications all contain multiple servers, applications and users can access the cache just by using its store name.
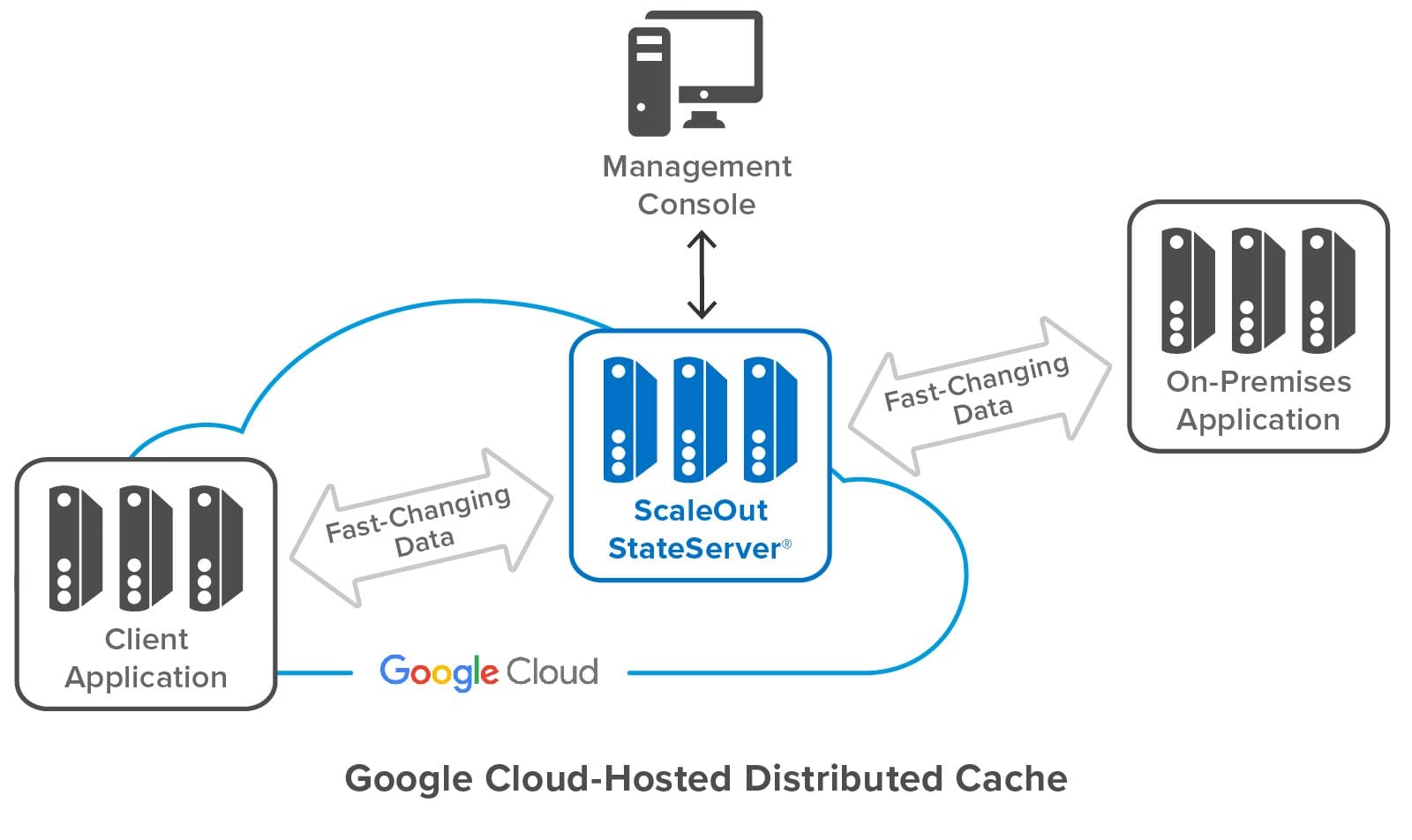
Building on the features developed for the integration of Amazon AWS and Microsoft Azure, the ScaleOut Management Console now lets users deploy and manage a cache in Google Cloud by just specifying a store name and initial number of servers, as well as other optional parameters. The console does the rest, interacting with Google Cloud to start up the distributed cache and configure its servers. To enable the servers to form a cluster, the console records metadata for all servers and identifies them as having the same store name.
Here’s a screenshot of the console wizard used for deploying ScaleOut StateServer in Google Cloud:
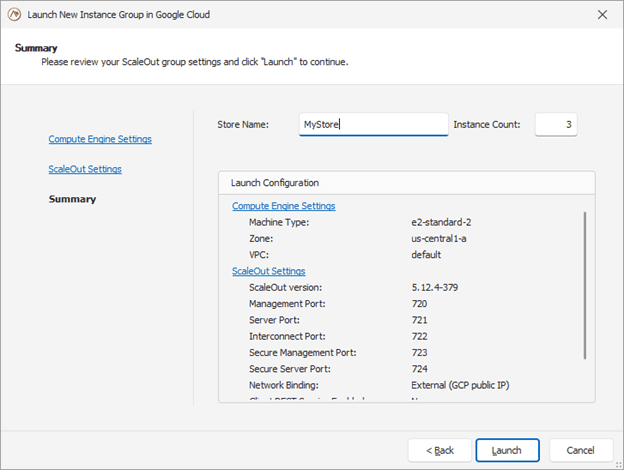
The management console provides centralized, on-premises management for initial deployment, status tracking, and adding or removing servers. It uses Google’s managed instance groups to host servers, and automated scripts use server metadata to guarantee that new servers automatically connect with an existing store. The managed instance groups used by ScaleOut also support defining auto-scaling options based on CPU/Memory usage metrics.
Instead of using the management console, users can also deploy ScaleOut StateServer to Google Cloud directly with Google’s Deployment Manager using optional templates and configuration files.
Simplifying Connectivity for Applications
On-premises applications typically connect each client instance to a distributed cache using a fixed list of IP addresses for the caching servers. This process works well on premises because the cache’s IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of a caching server.
To avoid this problem, ScaleOut StateServer lets client applications specify a store name and credentials to access a cloud-hosted distributed cache. ScaleOut’s client libraries internally use this store name to discover the IP addresses of caching servers from metadata stored in each server.
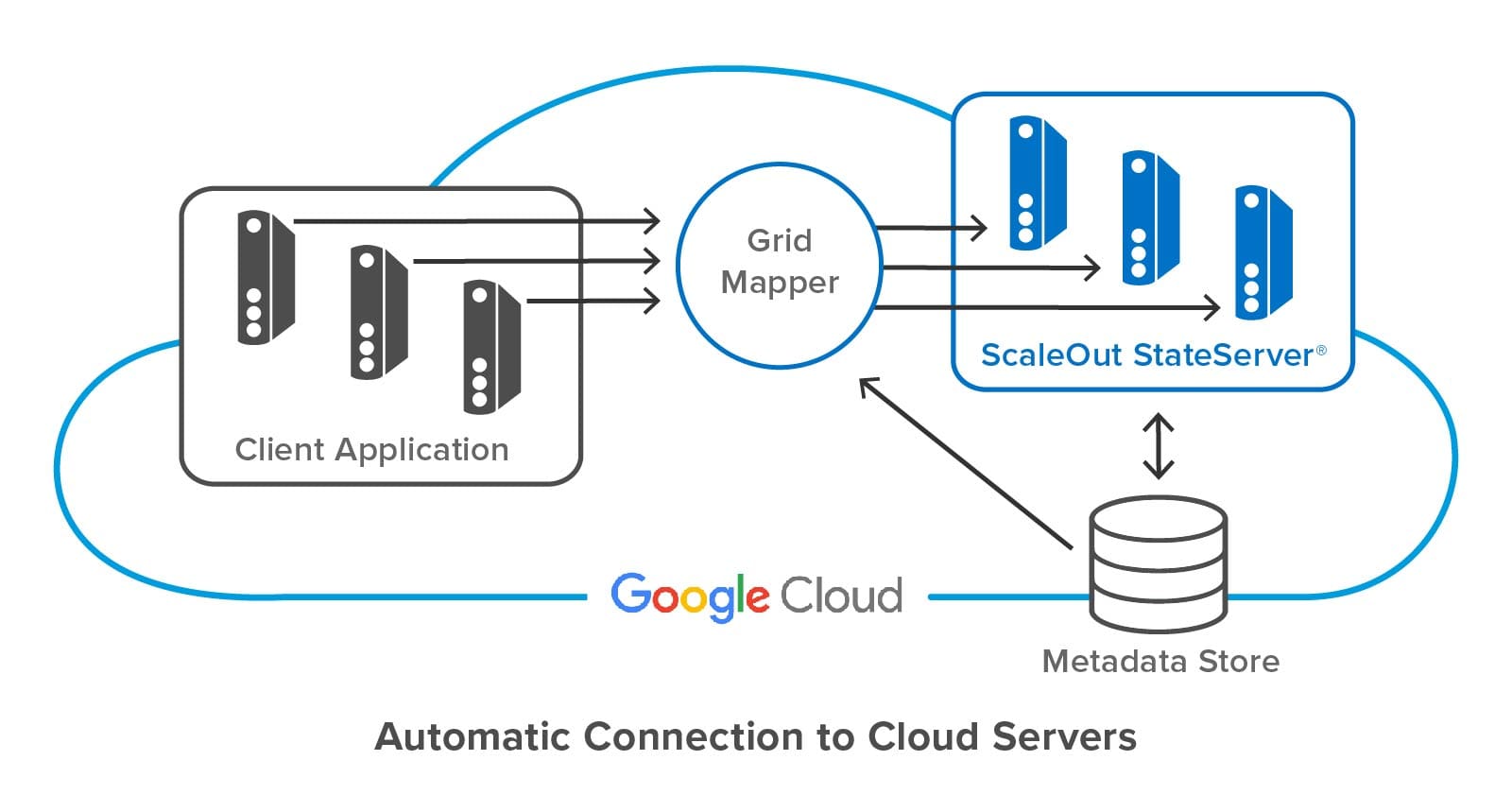
The following diagram shows a client application connecting to a ScaleOut StateServer distributed cache hosted in Google Cloud. ScaleOut’s client libraries make use of an internal software component called a “grid mapper” which acts as a bootstrap mechanism to find all servers belonging to a specified cache using its store name. The grid mapper accesses the metadata for the associated caching servers and returns their IP addresses back to the client library. The grid mapper handles any potential changes in IP addresses, such as servers being added or removed for scaling purposes.
Summing up
Because they provide elastic computing resources and high performance, public clouds, such as Google Cloud, offer an excellent platform for hosting distributed caches. However, the ephemeral nature of their virtual servers introduces challenges for both deploying the cluster and connecting applications. Keeping deployment and management as simple as possible is essential to controlling operational costs. ScaleOut StateServer makes use of centralized management, server metadata, and automatic client connections to address these challenges. It ensures that applications derive the full benefits of the cloud’s elastic resources with maximum ease of use and minimum cost.
The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>The post Machine Learning Supercharges Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
When tracking telemetry from a large number of IoT devices, it’s essential to quickly detect when something goes wrong. For example, a fleet of long-haul trucks needs to meet demanding schedules and can’t afford unexpected breakdowns as a fleet manager manages thousands of trucks on the road. With today’s IoT technology, these trucks can report their engine and cargo status every few seconds to cloud-hosted telematics software. How can this software sift through the flood of incoming messages to identify emerging issues and avoid costly failures? Can the power of machine learning be harnessed to provide predictive analytics that automates the task of finding problems that are otherwise very difficult to detect?
As described in earlier blog posts, real-time digital twins offer a powerful software architecture for tracking and analyzing IoT telemetry from large numbers of data sources. A real-time digital twin is a software component running within a fast, scalable in-memory computing platform, and it hosts analytics code and state information required to track a single data source, like a truck within a fleet. Thousands of real-time digital twins run together to track all of the data sources and enable highly granular real-time analysis of incoming telemetry. By building on the widely used digital twin concept, real-time digital twins simultaneously enhance real-time streaming analytics and simplify application design.
Incorporating machine learning techniques into real-time digital twins takes their power and simplicity to the next level. While analytics code can be written in popular programming languages, such as Java and C#, or even using a simplified rules engine, creating algorithms that ferret out emerging issues hidden within a stream of telemetry still can be challenging. In many cases, the algorithm itself may be unknown because the underlying processes which lead to device failures are not well understood. In these cases, a machine learning (ML) algorithm can be trained to recognize abnormal telemetry patterns by feeding it thousands of historic telemetry messages that have been classified as normal or abnormal. No manual analytics coding is required. After training and testing, the ML algorithm can then be put to work monitoring incoming telemetry and alerting when it observes suspected abnormal telemetry.
To enable ML algorithms to run within real-time digital twins, ScaleOut Software has integrated Microsoft’s popular machine learning library called ML.NET into its Azure-based ScaleOut Digital Twin Streaming Service . Using the ScaleOut Model Development Tool (formerly called the ScaleOut Rules Engine Development Tool), users can select, train, evaluate, deploy, and test ML algorithms within their real-time digital twin models. Once deployed, the ML algorithm runs independently for each data source, examining incoming telemetry within milliseconds after it arrives and logging abnormal events. The real-time digital twin also can be configured to generate alerts and send them to popular alerting providers, such as Splunk, Slack, and Pager Duty. In addition, business rules optionally can be used to further extend real-time analytics.
. Using the ScaleOut Model Development Tool (formerly called the ScaleOut Rules Engine Development Tool), users can select, train, evaluate, deploy, and test ML algorithms within their real-time digital twin models. Once deployed, the ML algorithm runs independently for each data source, examining incoming telemetry within milliseconds after it arrives and logging abnormal events. The real-time digital twin also can be configured to generate alerts and send them to popular alerting providers, such as Splunk, Slack, and Pager Duty. In addition, business rules optionally can be used to further extend real-time analytics.
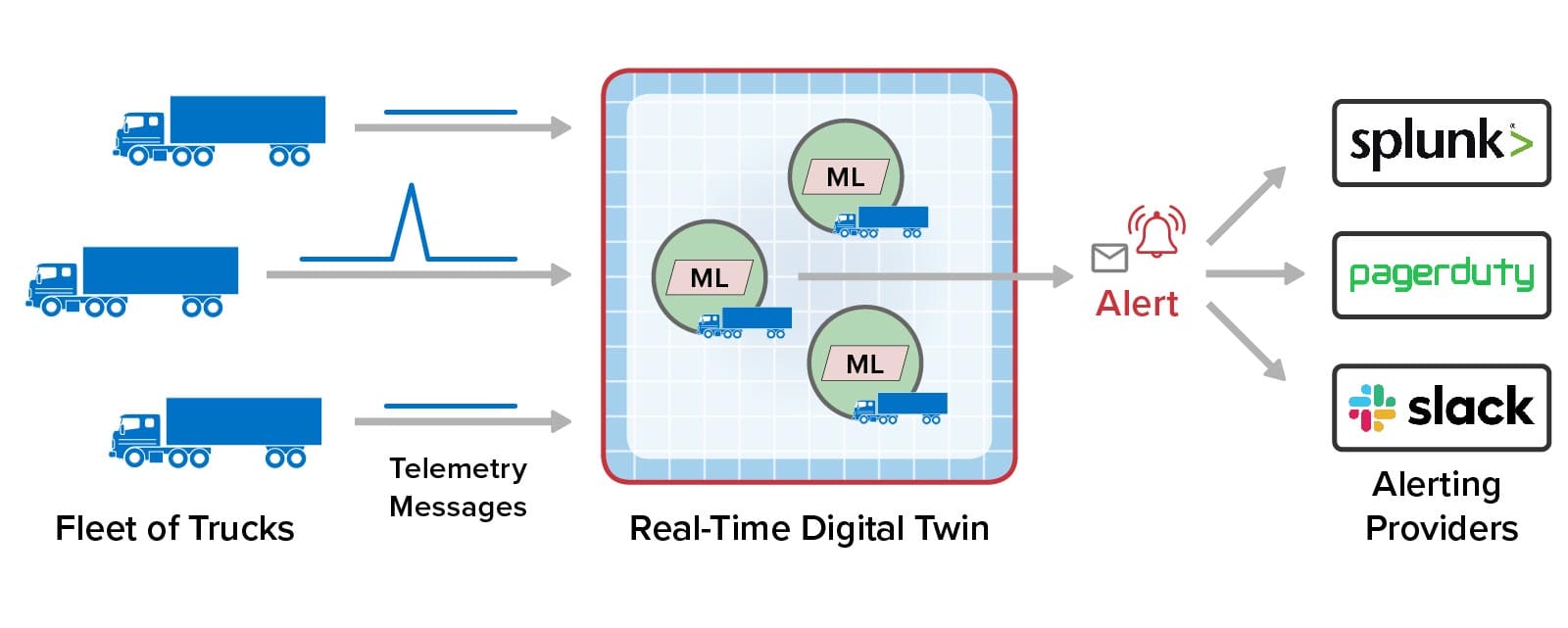
The following diagram illustrates the use of an ML algorithm to track engine and cargo parameters being monitored by a real-time digital twin hosting an ML algorithm for each truck in a fleet. When abnormal parameters are detected by the ML algorithm (as illustrated by the spike in the telemetry), the real-time digital twin records the incident and sends a message to the alerting provider:
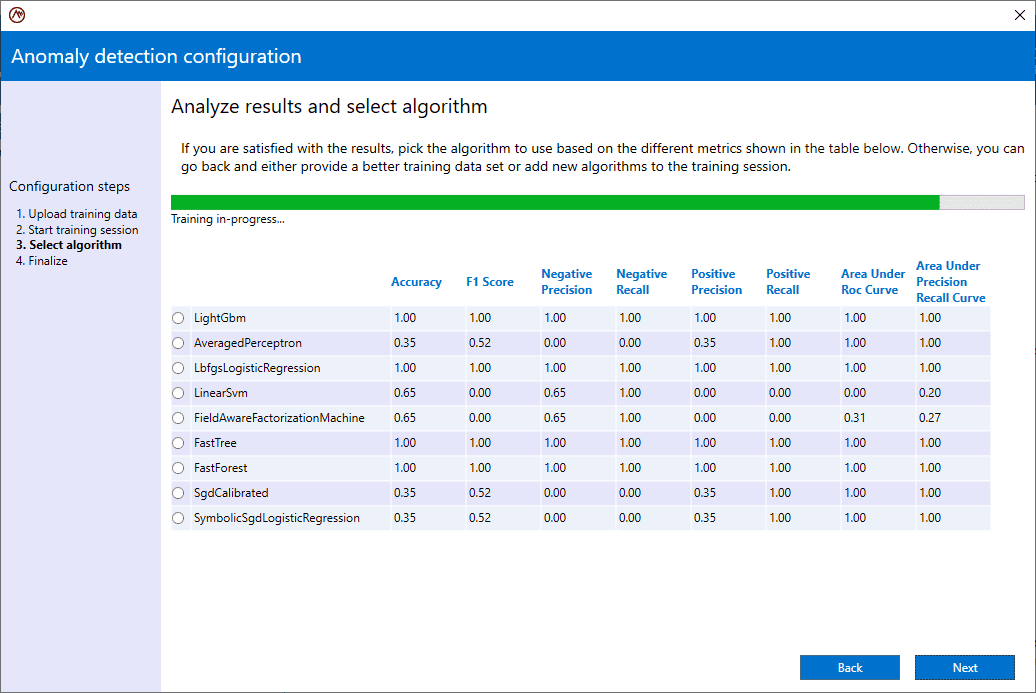
Training an ML algorithm to recognize abnormal telemetry just requires supplying a training set of historic data that has been classified as normal or abnormal. Using this training data, the ScaleOut Model Development Tool lets the user train and evaluate up to ten binary classification algorithms supplied by ML.NET using a technique called supervised learning. The user can then select the appropriate trained algorithm to deploy based on metrics for each algorithm generated during training and testing. (The algorithms are tested using a portion of the data supplied for training.)
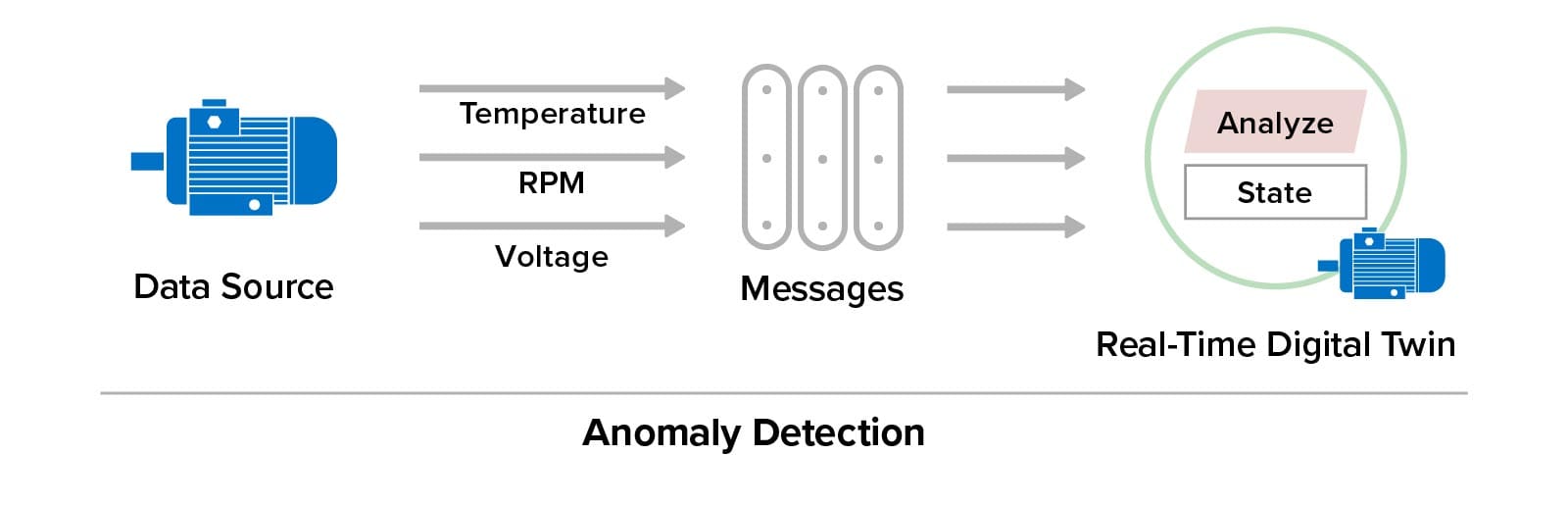
For example, consider an electric motor which periodically supplies three parameters (temperature, RPM, and voltage) to its real-time digital twin for monitoring by an ML algorithm to detect anomalies and generate alerts when they occur:
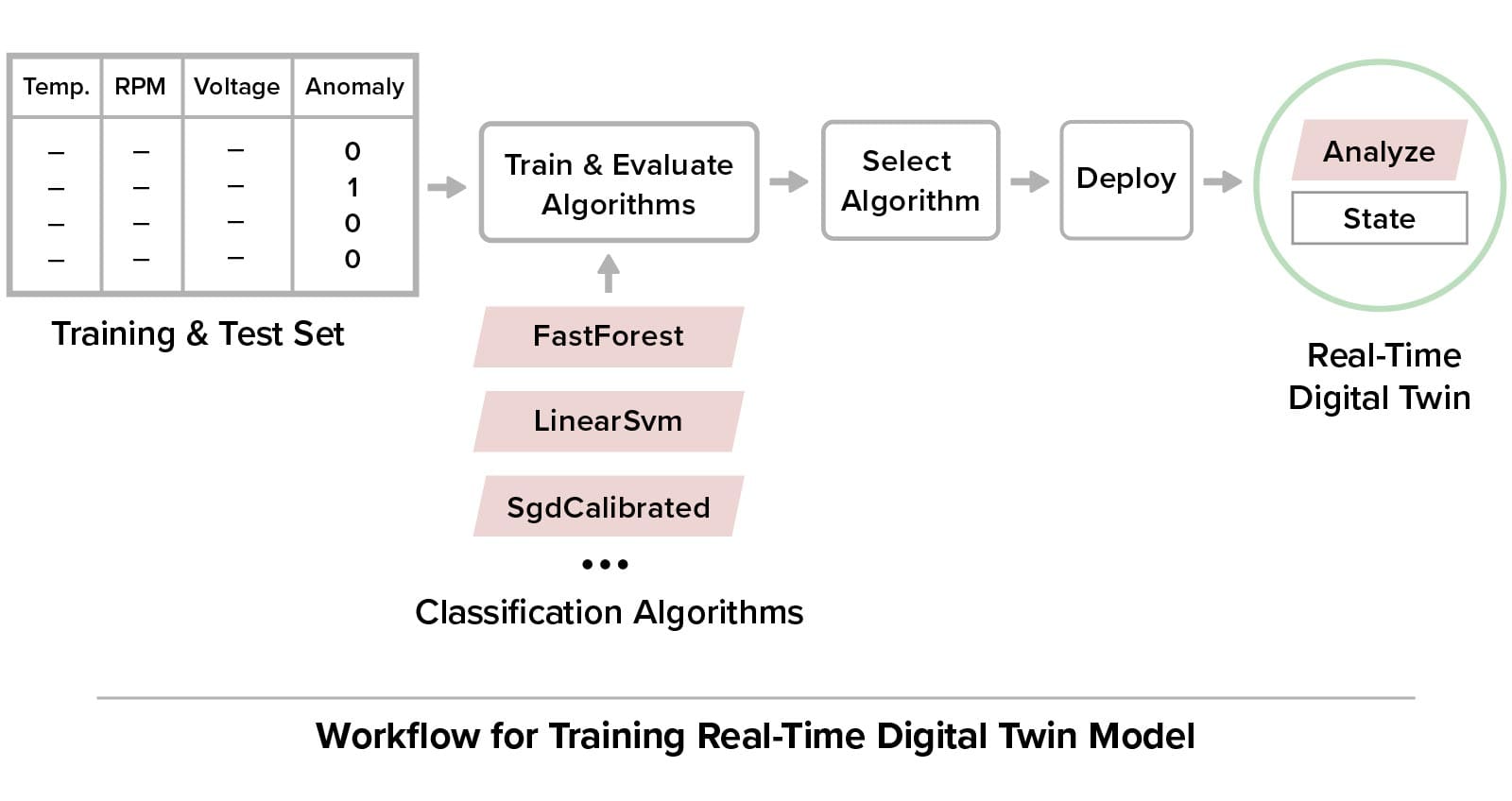
Training the real-time digital twin’s ML model follows the workflow illustrated below:
Here’s a screenshot of the ScaleOut Model Development Tool that shows the training of selected ML.NET algorithms for evaluation by the user:
The output of this process is a real-time digital twin model which can be deployed to the streaming service. As each motor reports its telemetry to the streaming service, a unique real-time digital twin “instance” (a software object) is created to track that motor’s telemetry using the ML algorithm.
In addition to supervised learning, ML.NET provides an algorithm (called an adaptive kernel density estimation algorithm) for spike detection, which detects rapid changes in telemetry for a single parameter. The ScaleOut Model Development Tool lets users add spike detection for selected parameters using this algorithm. In addition, it is often useful to detect unusual but subtle changes in a parameter’s telemetry over time. For example, if the temperature for an electric motor is expected to remain constant, it would be useful to detect a slow rise in temperature that might otherwise go unobserved. To address this need, the tool lets users make use of a ScaleOut-developed, linear regression algorithm that detects and reports inflection points in the telemetry for a single parameter. These two techniques for tracking changes in a telemetry parameter are illustrated below:
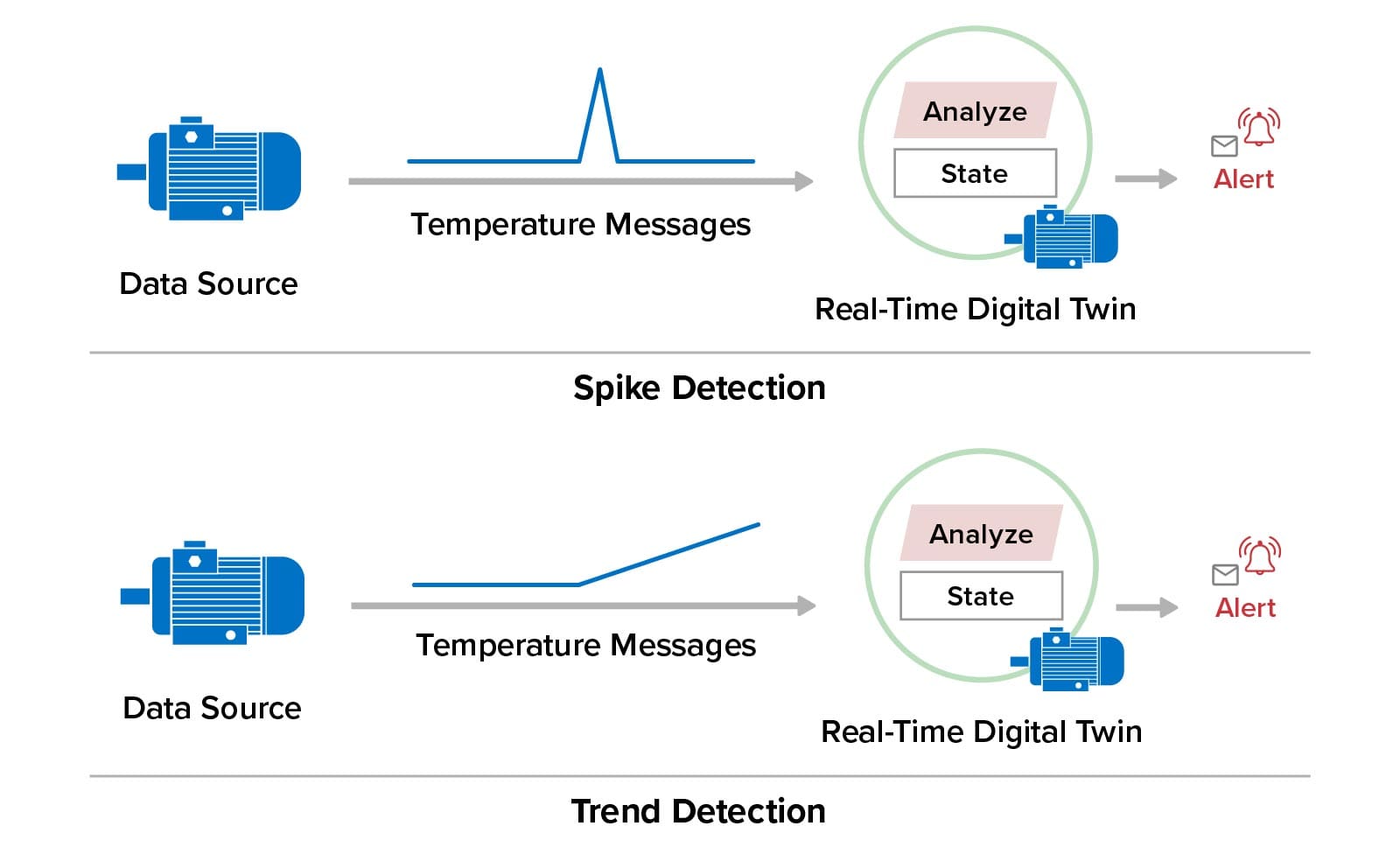
Summing Up
Machine learning provides important real-time insights that enhance situational awareness and enable fast, effective responses. They often can provide useful analytics for complex datasets that cannot be analyzed with hand-coded algorithms. Their usefulness and rate of adoption is quickly growing. Using the ScaleOut Model Development Tool, real-time digital twins now can easily be enhanced to automatically analyze incoming telemetry messages with machine learning techniques that take full advantage of Microsoft’s ML.NET library. The integration of machine learning with real-time digital twins enables thousands of data streams to be automatically and independently analyzed in real-time with fast, scalable performance. Best of all, no coding is required, enabling fast, easy model development. By combining ML with real-time digital twins, the ScaleOut Digital Twin Streaming Service adds important new capabilities for real-time streaming analytics that supercharge the Azure IoT ecosystem.
Read more about the ScaleOut Model Development Tool.
The post Machine Learning Supercharges Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>
Web applications, such as ecommerce sites and financial services, often need to replicate fast-changing, in-memory data across multiple data centers or cloud regions. As part of an overall strategy for disaster recovery, cross-site data replication ensures that mission-critical data is continuously available, even if one site goes offline.
Many applications need to use two (and sometimes more) sites in an “active-active” manner, distributing the workload across the sites. Here are some real-world applications we have seen. Ecommerce applications need to maintain shopping carts at multiple sites and distribute the workload from their shoppers with a global load-balancer. Cell phone providers need to keep their lists of available mobile numbers consistent across sites as individual stores allocate them. Conference-management companies need to keep attendee lists and schedules consistent at conference sites and their central data center.
Let’s take a closer look at an ecommerce site using a global load-balancer to distribute incoming web requests to multiple sites. This approach lets the web application take advantage of the processing power at multiple sites during normal operations. However, it creates the challenge of coordinating access to in-memory objects which are replicated across two or more sites. This can add substantial complexity if handled by the application.
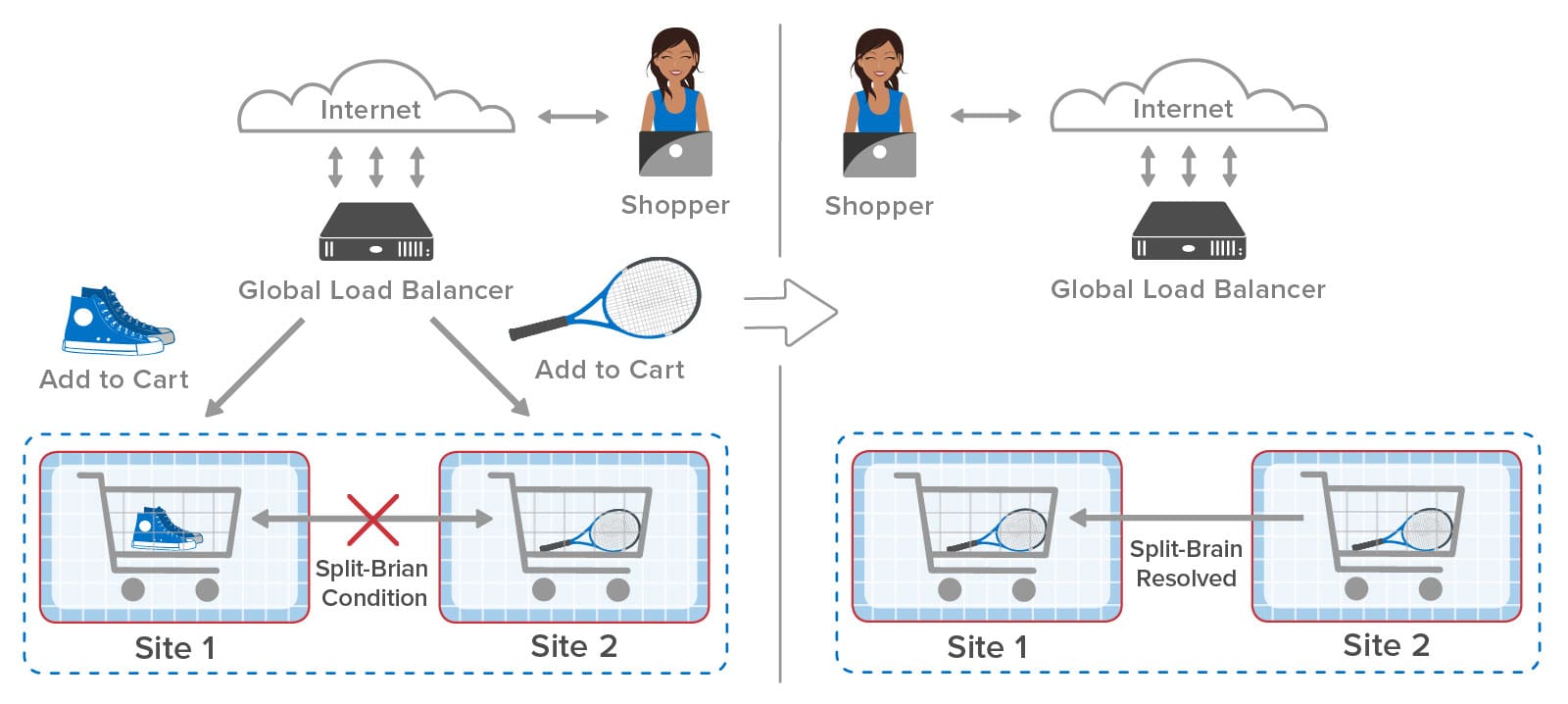
Here’s an example of an ecommerce site using a global load-balancer to distribute incoming web requests across two sites, each of which hosts shopping carts within an in-memory data grid (also called a distributed cache), such as ScaleOut StateServer®. A web shopper might select a pair of shoes and place them in the shopping cart followed by selecting a tennis racket. As shown in the following diagram, the global load-balancer sends the first request to site 1 and the second request to site 2 in this example:
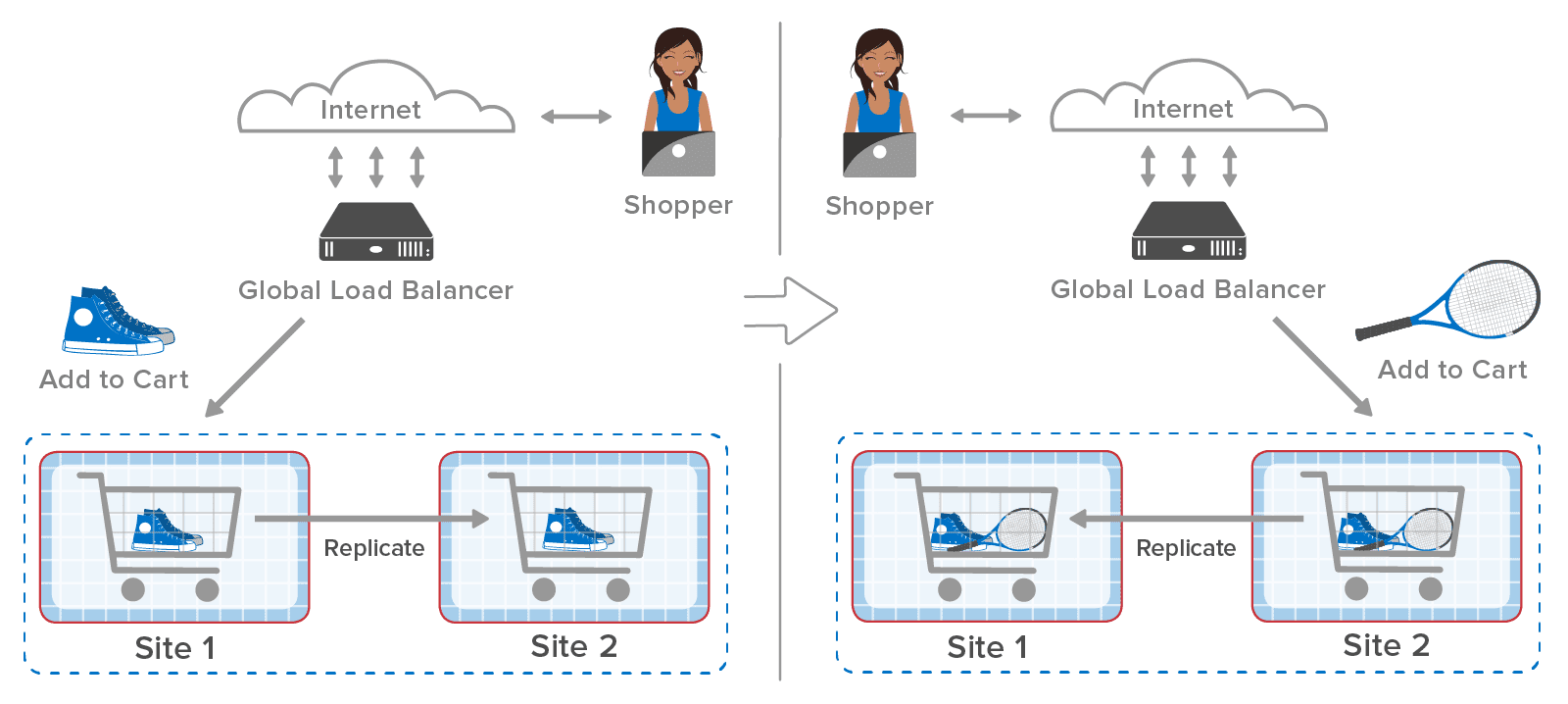
After the first request completes, the in-memory data grid at site 1 replicates the cart to site 2. The global load-balancer then sends the second request to site 2, which adds the tennis racket to the cart. Finally, site 2 replicates the changes back to site 1 so that both sites have the latest copy of the shopping cart.
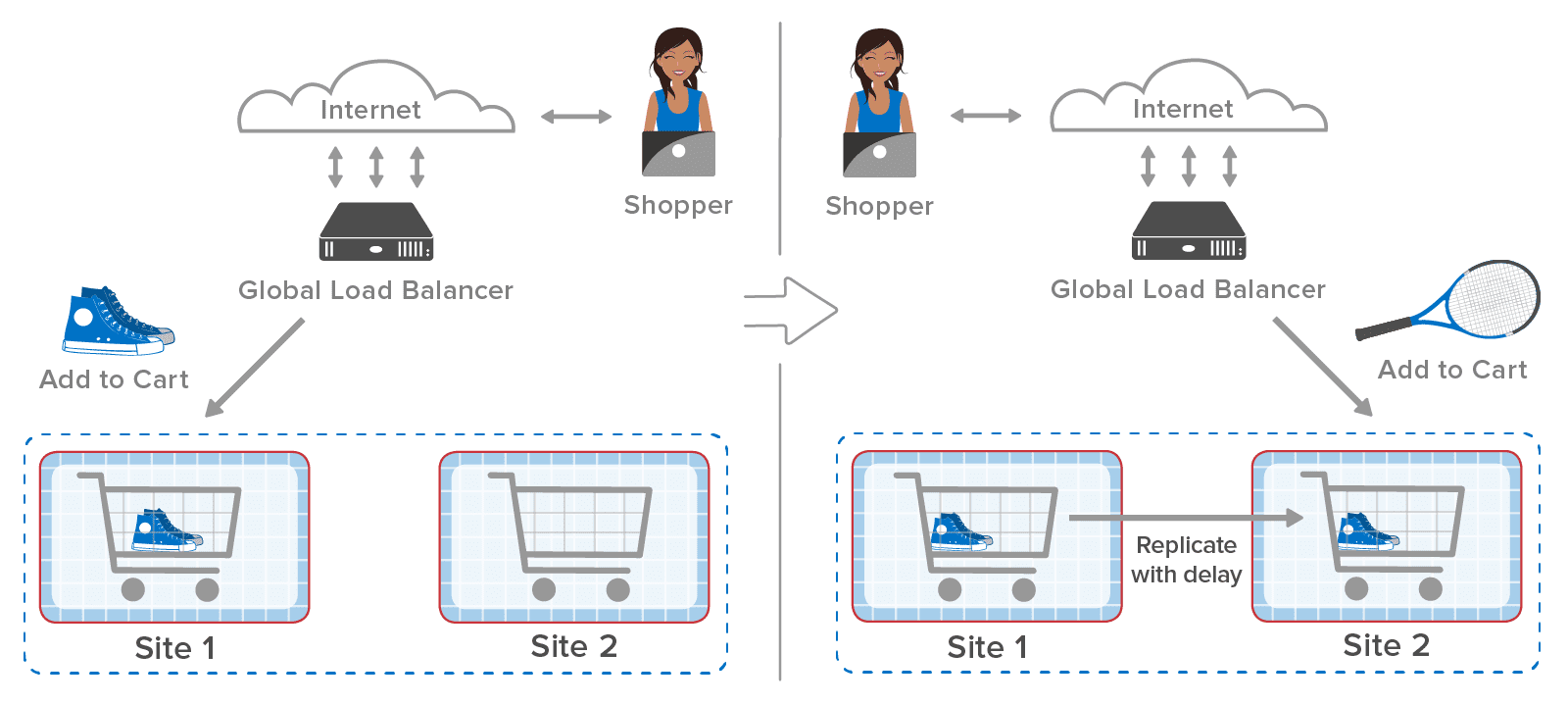
What happens if replication from site 1 to site 2 is slightly delayed? After site 2 puts the tennis racket in the cart, the incoming replicated update arrives and overwrites the cart. This causes both sites to lose the update at site 2, and the shopper will undoubtedly be annoyed to find that the tennis racket is missing from the cart:
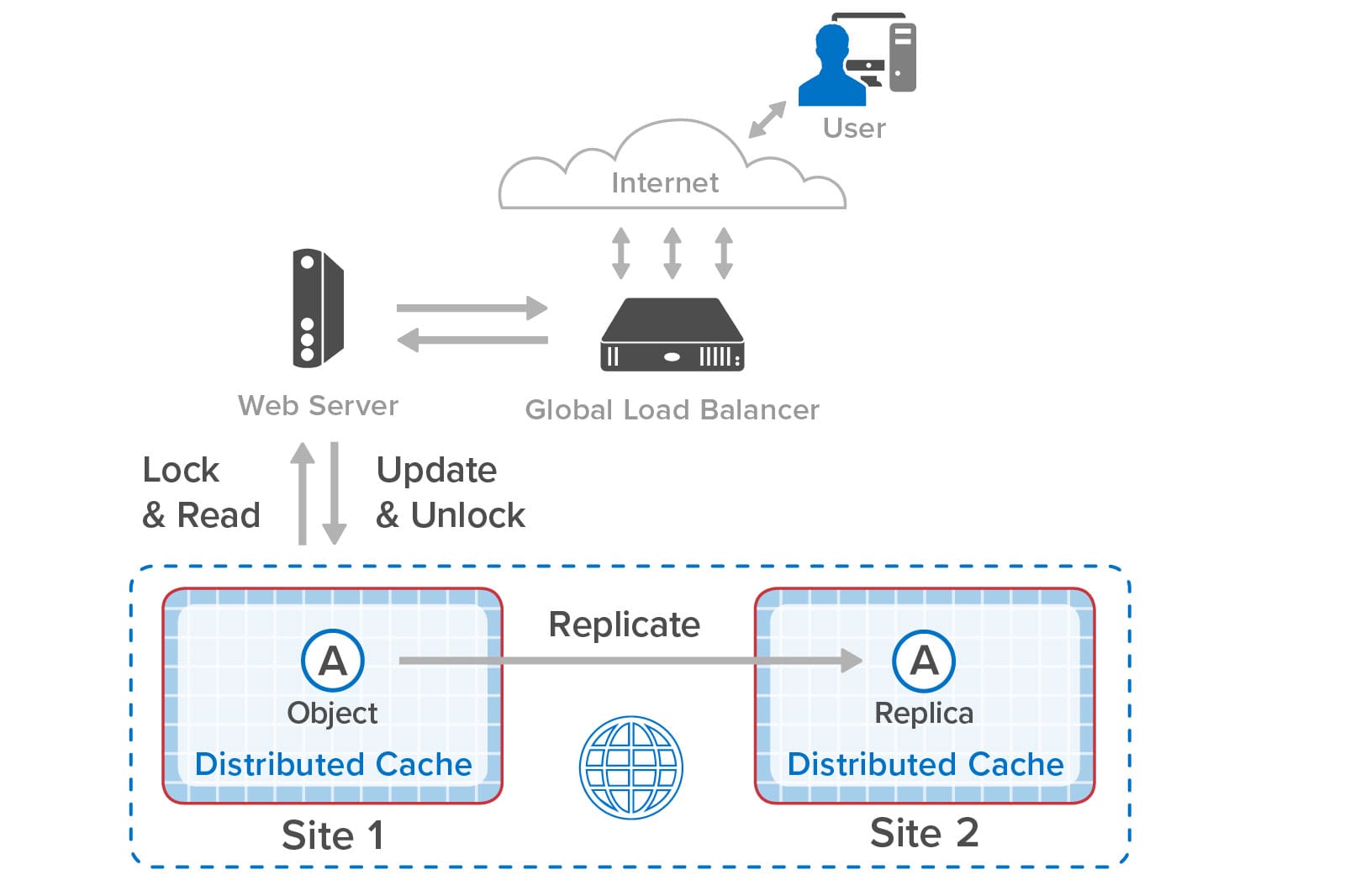
The solution to this problem is to have the web applications at both sites synchronize updates to the shopping carts. This ensures that only one site at a time updates the shopping cart and that each site always sees the latest version of the in-memory object. Using ScaleOut GeoServer Pro, applications can use standard object-locking APIs for this purpose, just as they would to coordinate object access within a single in-memory data grid:
After the web application on site 1 updates and unlocks object A (the shopping cart in our example), site 1 replicates the update to site 2. When the global load-balancer sends the next request to site 2, the web application on that site 2 also locks and reads the object, updates it, and then unlocks it:
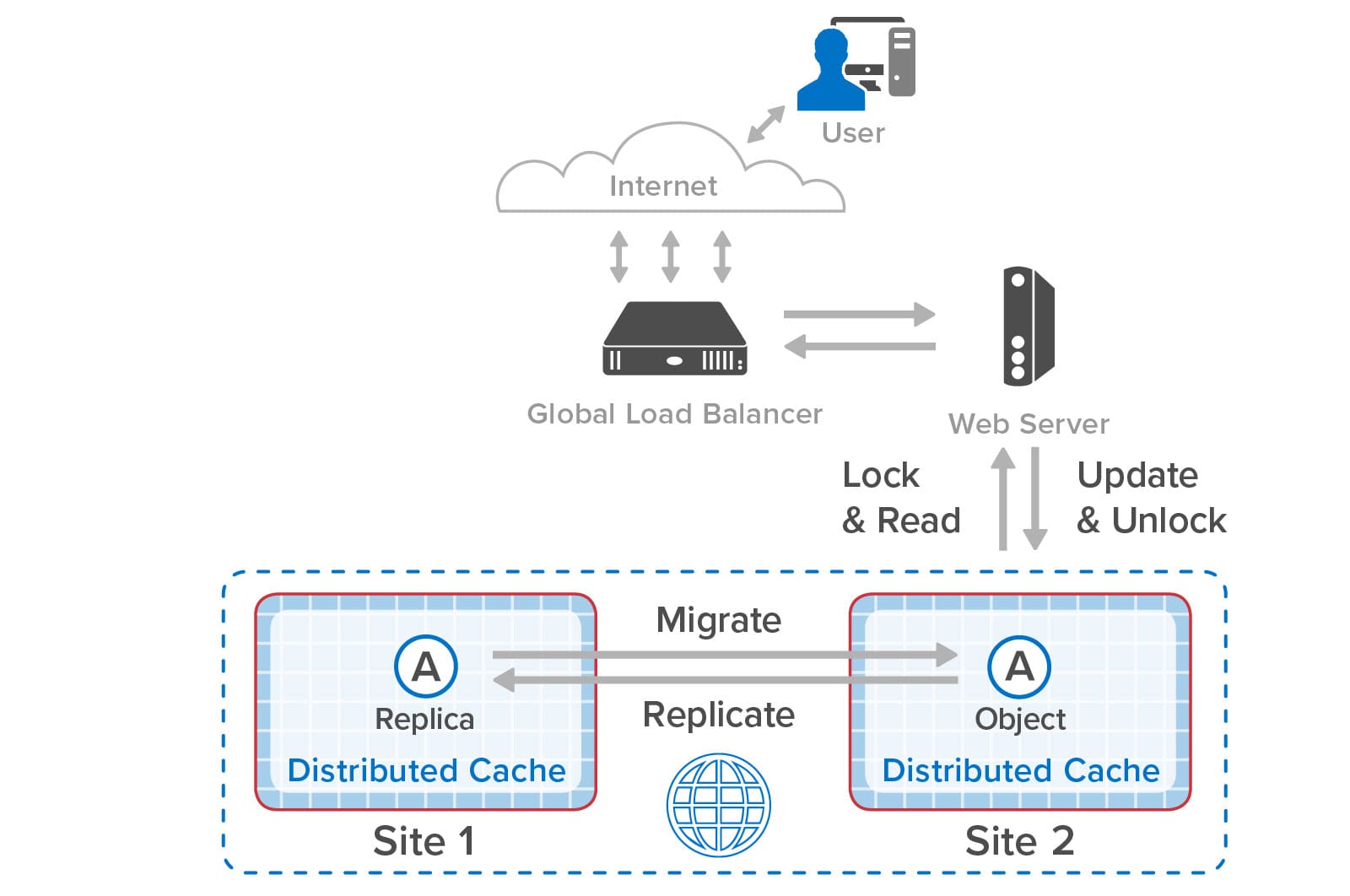
When the object is locked on site 2, ScaleOut GeoServer Pro makes sure that the application sees the latest version of the object. It does so by migrating ownership of the object to site 2 and checking that it has the latest version. Although this requires a round trip to site 1, once a site gains ownership, all further accesses are local until the other site again attempts to lock the object and request ownership. If the global load-balancer avoids ping-ponging between sites with every web request, the latency to lock an object remains low.
Should the wide area network (WAN) connecting the two sites fail, or if the remote site goes offline, the two sites can operate independently; this is called “split brain” mode in distributed systems. They detect the WAN failure and automatically promote local replica objects as needed to gain ownership when requesting a lock. This enables uninterrupted operations that make use of object replicas held at each site. By combining object replication with synchronized access, applications enjoy the full benefits of synchronized object access across sites during normal operations and uninterrupted access during WAN or site outages:
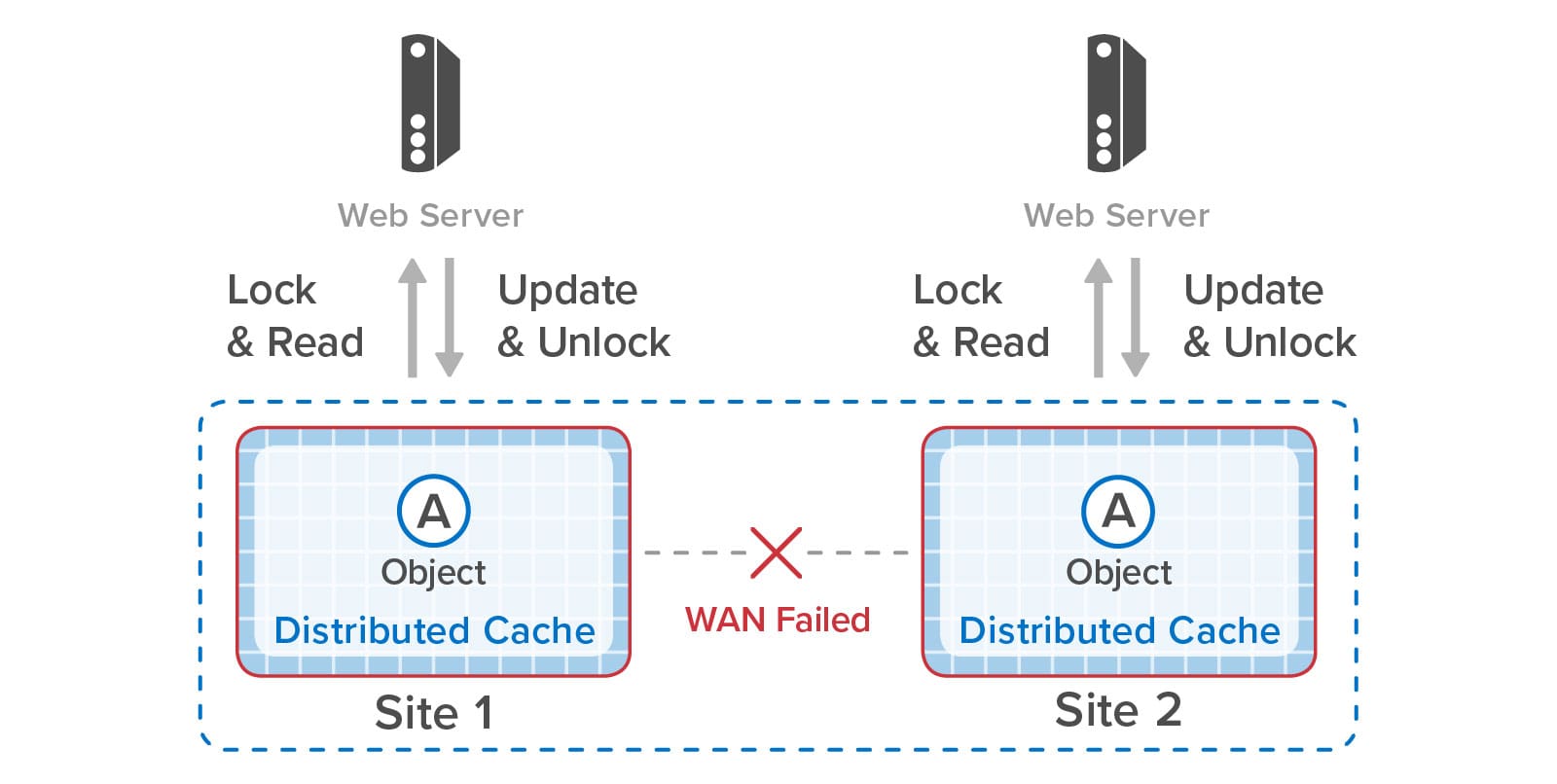
A key challenge created by split-brain mode is how to restore normal operations after an outage has been corrected. For example, the following diagram shows the two sites in our shopping example operating independently during a WAN outage that occurs between the two web requests. Site 1 adds the shoes to its shopping cart but is unable to replicate that update to site 2. The web application on site 2 then places the tennis racket in its shopping cart:
After the WAN is restored, the two sites have to resolve the differences in the contents of their copies of stored objects. Unless the application uses special, conflict-free data types that can be merged (and this is rare for most applications), a heuristic needs to be used to resolve conflicts. ScaleOut GeoServer Pro automatically resolves conflicts for each pair of object copies by selecting the copy with the latest update time or randomly picking one of the copies if the update times are the same. So in this case, both sites are updated with the version of the shopping cart holding the tennis racket. (This will be another source of annoyance for our shopper, but at least the ecommerce site survived a WAN outage without interruption.)
ScaleOut GeoServer Pro resolves split-brain conflicts as it detects them when updates are performed and then are successfully replicated across the WAN. It also has to resolve the fact that both sites now think they own the same object, and it handles this by randomly picking a site to retain ownership. As the two sites attempt to lock and read the object, ownership will then automatically migrate to the site where it’s needed.
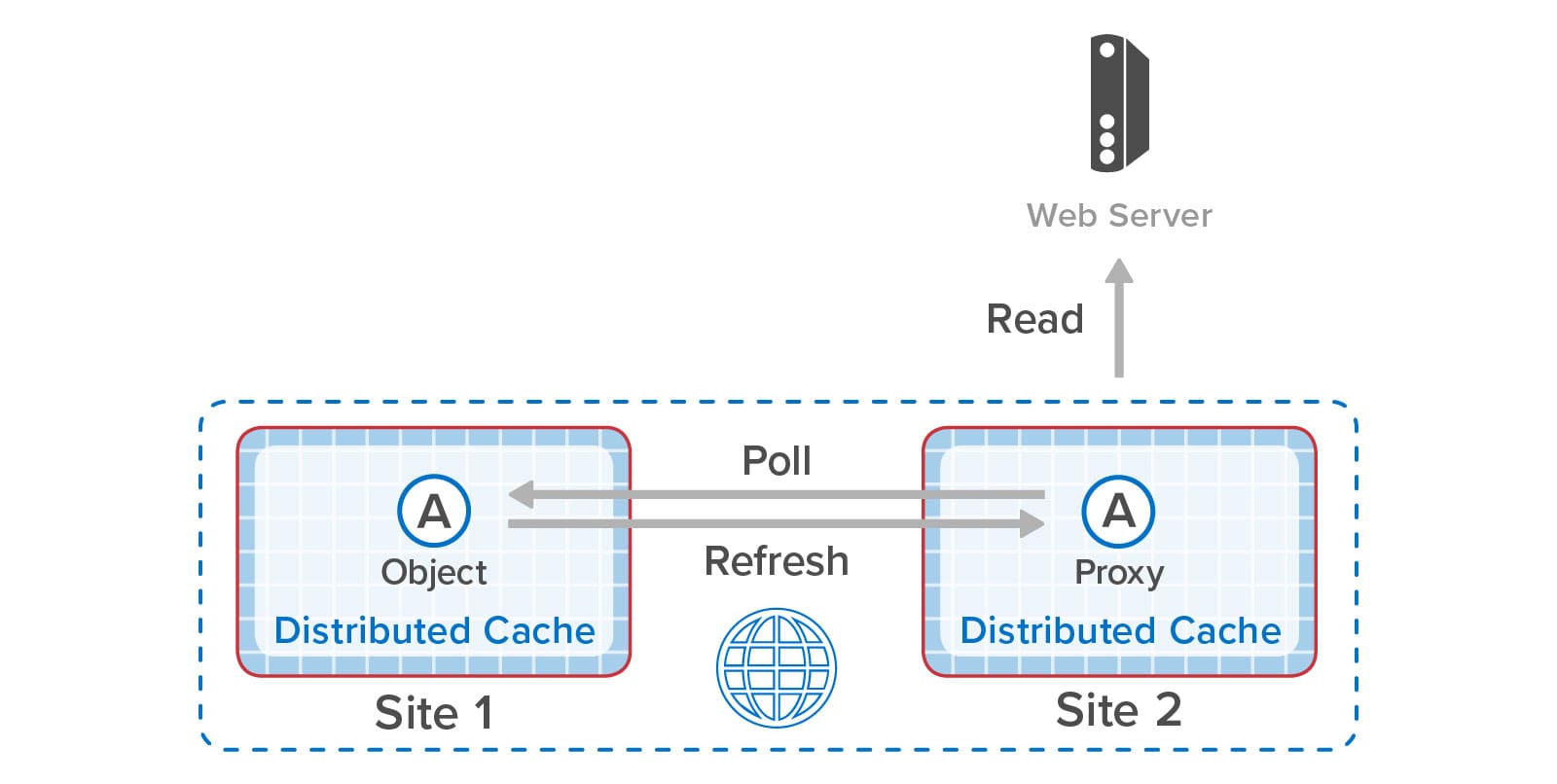
One more key benefit of ScaleOut GeoServer Pro is that it lets applications efficiently access objects that have slowly changing contents (such as product descriptions, schedules, and portfolio lists) without making repeated WAN accesses. Sites that are configured for bi-directional replication have immediate access to replicas when just reading but not updating remote objects. Other sites can be configured to maintain local copies of remote objects (called “proxies”) that can periodically poll for updates using a configurable timeout. This minimizes WAN accesses while allowing applications to track changes in objects stored at remote sites.
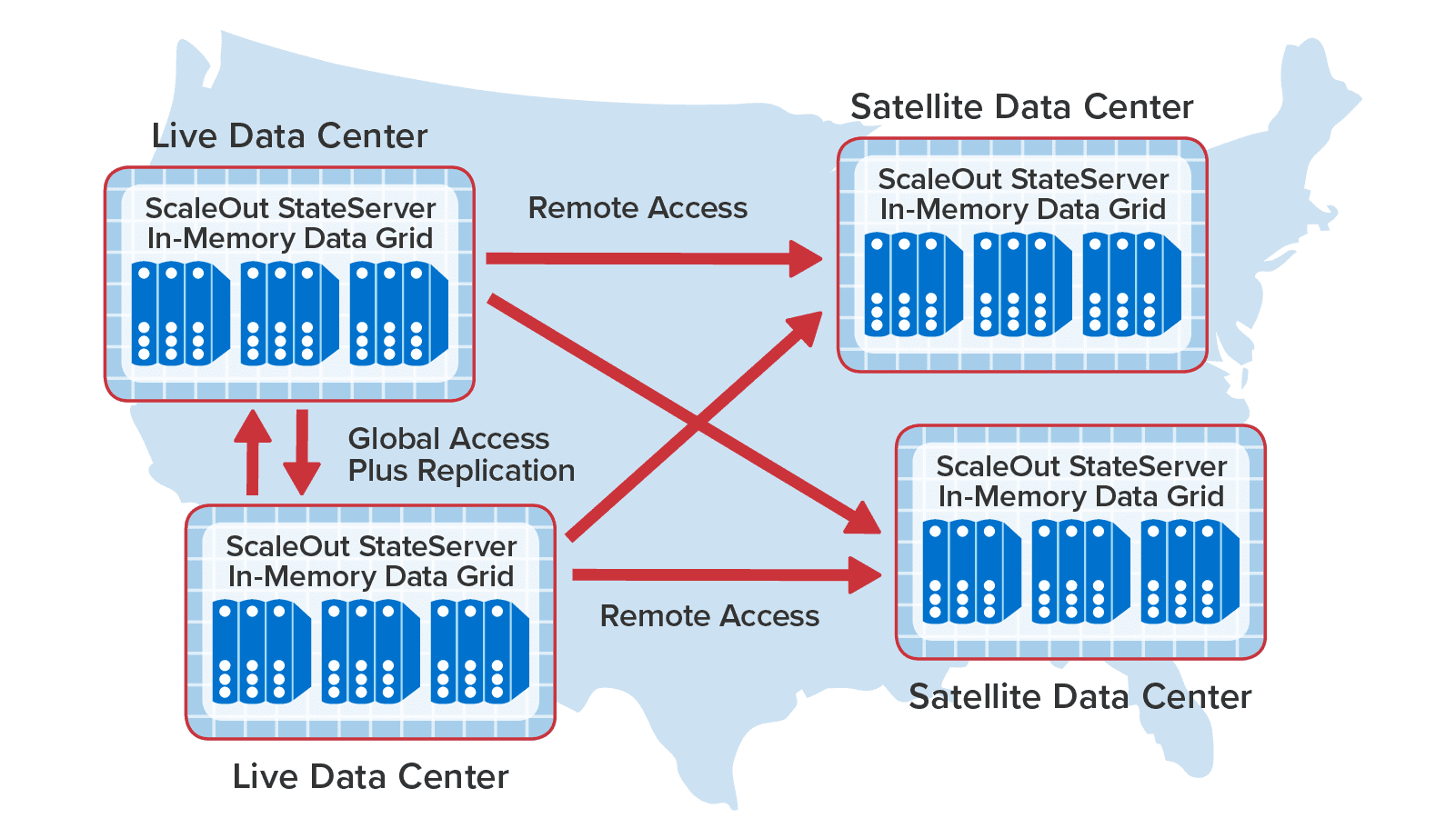
To illustrate how all of these features can work together, the following diagram shows two sites on the west coast of the U.S. configured for bi-directional replication and synchronized access along with additional “satellite” sites in other states that are periodically polling to read data held in the “live” data centers:
With its advanced capabilities for combining data replication with synchronized access, ScaleOut GeoServer Pro takes a leadership position among commercial in-memory data grids by enabling applications to seamlessly access and update objects replicated across data centers. This solves a long-standing challenge for applications that actively maintain mission-critical data at multiple sites and further extends the power of in-memory data grids to manage fast-changing business data.
The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times. For more than two decades, the answer to this challenge has proven to be a technology called in-memory computing.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers. Assuming bottlenecks are avoided, this enables transparent throughput scaling that matches an increase in workload, which in turn keeps response times low for users. It can also take advantage of the elastic computing resources available in cloud infrastructures to quickly and cost-effectively scale throughput to meet changes in demand.
Harnessing the power of in-memory computing requires software platforms that can make in-memory computing’s scalability readily available to applications using APIs while hiding the complexity of its implementation. Emerging in the early 2000s, the first such platforms provided distributed caching on clustered servers with straightforward APIs for storing and retrieving in-memory objects. When first introduced, distributed caching offered a breakthrough for applications by storing fast-changing data in memory on a server cluster for consistently fast response times, while simultaneously offloading database servers that would otherwise become bottlenecked. For example, ecommerce applications adopted distributed caching to store session-state, shopping carts, product descriptions, and other data that shoppers need to be able to access quickly.
Software platforms for distributed caching, such as ScaleOut StateServer®, which was introduced in 2005, hide internal mechanisms for cluster membership, throughput scaling, and high availability to take full advantage of the cluster’s scalable memory without adding complexity to applications. They transparently distribute stored objects across the cluster’s servers and ensure that data is not lost if a server or network component fails.
As distributed caching has evolved over the last two decades, additional mechanisms for in-memory computing have been incorporated to take advantage of the computing power available in the server cluster. Parallel query enables stored objects on all servers to be scanned simultaneously to retrieve objects with desired properties. Data-parallel computing analyzes objects on the server cluster to extract and report patterns of interest; it scales much better than parallel query by avoiding network bottlenecks and by using the cluster’s computing resources.
Most recently, stream-processing has been implemented with in-memory computing to simultaneously analyze telemetry from thousands or even millions of data sources and track dynamic state information for each data source. ScaleOut Software’s real-time digital twin model provides straightforward APIs for implementing stream-processing applications within its ScaleOut Digital Twin Streaming Service, an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins. Each step in the evolution has built on the previous one to add new capabilities that take advantage of the scalable computing power and fast data access that in-memory computing enables.
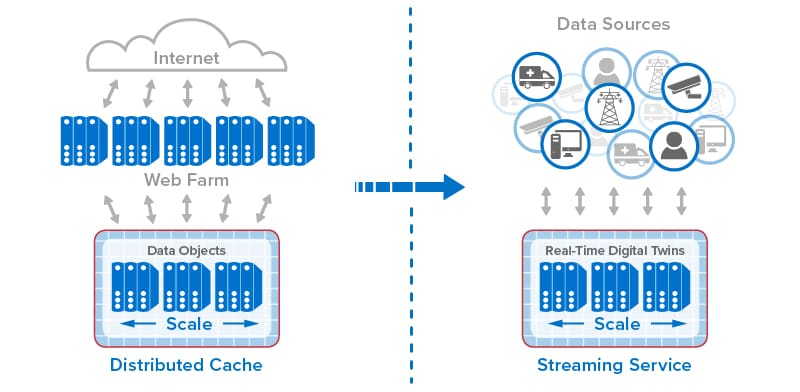
For ecommerce applications, this evolution has created new capabilities that dramatically improve the experience for online shoppers. Instead of just passively hosting session-state and shopping carts, online applications now can mine shopping carts for dynamic trends to evaluate the effectiveness of product descriptions and marketing programs (such as flash sales). They can also employ real-time digital twins or similar techniques to track each shopper’s behavior and make recommendations. By analyzing a click-stream of product selections in the context of knowledge of a shopper’s preferences and demographics, an ecommerce site can make highly focused recommendations to assist the shopper.
For example, one of ScaleOut Software’s customers recently upgraded from just using distributed caching to scale its ecommerce application. This customer now incorporates stream-processing capabilities using ScaleOut StreamServer® to capture click-streams and score users so that its web site can make more effective real-time offers.
The following diagram illustrates how the evolution of in-memory computing has enhanced the online experience for ecommerce shoppers by providing in-the-moment suggestions:
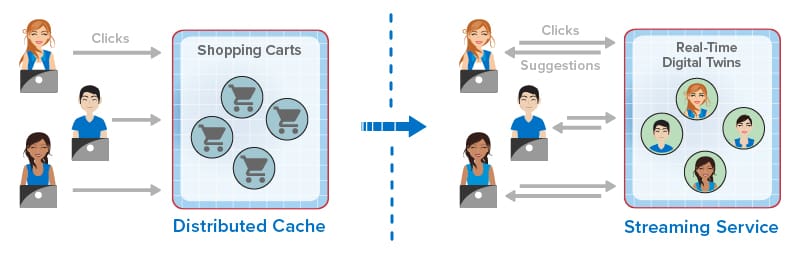
Starting with its development for parallel supercomputing in the late 1990s and evolving into its latest form as a cloud-based service, in-memory computing has offered powerful, software based APIs for building applications that serve large populations of users and data sources. It has helped assure that these applications deliver predictably fast performance and scale to meet the demands of growing workloads. In the next few years, we should continued innovation from in-memory computing to help ecommerce and other applications maintain their competitive edge.
The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>The post Real-Time Digital Twins: A New Approach to Streaming Analytics appeared first on ScaleOut Software.
]]>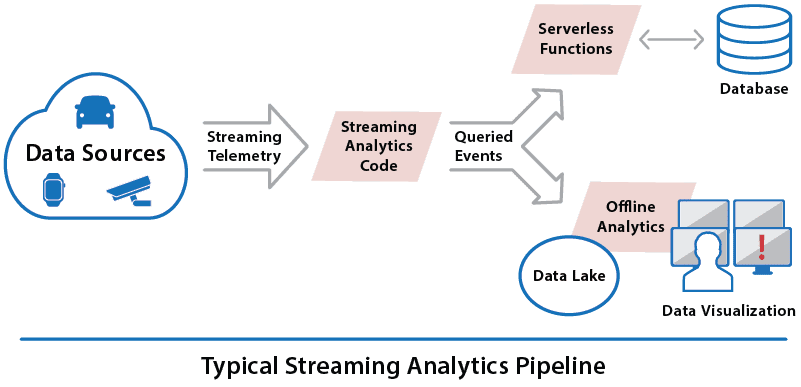
A conventional pipeline combines telemetry from all data sources into a single stream which is queried by the user’s streaming analytics application. This code often takes the form of a set of SQL queries (extended with time-windowing semantics) running continuously to select interesting events from the stream. These query results are then forwarded to a data lake for offline analytics using tools such as Spark and for data visualization. Query results also might be forwarded to cloud-based serverless functions to trigger alerts or other actions in conjunction with access to a database or blob store.
These techniques are highly effective for analyzing telemetry in aggregate to identify unusual situations which might require action. For example, if the telemetry is tracking a fleet of rental cars, a query could report all cars by make and model that have reported a mechanical problem more than once over the last 24 hours so that follow-up inquiries can be made. In another application, if the telemetry stream contains key-clicks from an e-commerce clothing site, a query might count how many times a garment of a given type or brand was viewed in the last hour so that a flash sale can be started.
A key limitation of this approach is that it is difficult to separately track and analyze the behavior of each individual data source, especially when they number in the thousands or more. It’s simply not practical to create a unique query tailored for each data source. Fine-grained analysis by data source must be relegated to offline processing in the data lake, making it impossible to craft individualized, real-time responses to the data sources.
For example, a rental car company might want to alert a driver if she/he strays from an allowed region or appears to be lost or repeatedly speeding. An e-commerce company might want to offer a shopper a specific product based on analyzing the click-stream in real time with knowledge of the shopper’s brand preferences and demographics. These individualized actions are impractical using the conventional tools of real-time streaming analytics.
However, real-time digital twins easily bring these capabilities within reach. Take a look at how the streaming pipeline differs when using real-time digital twins:
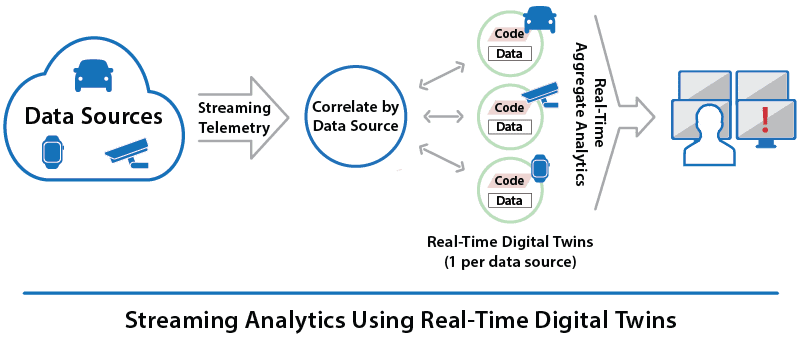
The first important difference to note is that the execution platform automatically correlates telemetry events by data source. This avoids the need for the application to select events by data source using queries (which is impractical in any case when using a conventional pipeline with many data sources). The second difference is that real-time digital twins maintain immediately accessible (in-memory) state information for each data source which is used by message-processing code to analyze incoming events from that data source. This enables straightforward application code to immediately react to telemetry information in the context of knowledge about the history and state of each data source.
For example, the rental car application can keep each driver’s contract, location history, and the car’s known mechanical issues and service history within the corresponding digital twin for immediate reference to help detect whether an alert is needed. Likewise, the e-commerce application can keep each shopper’s recent product searches along with brand preferences and demographics in her/his digital twin, enabling timely suggestions targeted to each shopper.
The power of real-time digital twins lies in their ability to make fine-grained analysis and responses possible in real time for thousands of data sources. They are made possible by scalable, in-memory computing technology hosted on clusters of cloud-based servers. This provides the fast response times and scalable throughput needed to support many thousands of data sources.
Lastly, real-time digital twins open the door to real-time aggregate analytics that analyze state data across all instances to spot emerging patterns and trends. Instead of waiting for the data lake to provide insights, aggregate analytics on real-time digital twins can immediately surface patterns of interest, maximizing situational awareness and assisting in the creation of response strategies.
With aggregate analytics, the rental car company can identify regions with unusual delays due to weather or highway blockages and then alert the appropriate drivers to suggest alternative routes. The e-commerce company can spot hot-selling products perhaps due to social media events and respond to ensure that inventory is made available.
Real-time digital twins create exciting new capabilities that were not previously possible with conventional techniques. You can find detailed information about ScaleOut Software’s cloud service for real-time digital twins here.
The post Real-Time Digital Twins: A New Approach to Streaming Analytics appeared first on ScaleOut Software.
]]>The post How to Easily Deploy an IMDG in the Cloud appeared first on ScaleOut Software.
]]>IMDGs Help Scale Applications
In-memory data grids (IMDGs) add tremendous value to this scenario by providing a sharable, in-memory repository for an application’s fast-changing state information, such as shopping carts, financial transactions, pending orders, geolocation information, machine state, etc. This information tends to be rapidly updated and often needs to be shared across all application servers. For example, when external requests from a web user are directed to different web servers, the user’s state has to be tracked independent of which server is handling the request.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. They also offer a powerful computing platform for analyzing live data as it changes and generating immediate feedback or “operational intelligence;” for example, see this blog post describing the use of real-time analytics in a retail application.
The Need to Keep It Simple
A key challenge in using an IMDG as part of a cloud-hosted application is to easily deploy, access, and manage the IMDG. To meet the needs of an elastic application, an IMDG must be designed to transparently scale its throughput by adding virtual servers and then automatically rebalance its in-memory storage to keep the workload evenly distributed. Likewise, it must be easy to remove IMDG servers when the workload decreases and creates excess capacity.
Like the applications they serve, IMDGs are deployed as a cluster of cloud-hosted virtual servers that scales as the workload demands. This scaling may differ from the application in the number of virtual servers required to handle the workload. To keep it simple, a cloud-hosted application should just view the IMDG as an abstract entity and not be concerned with individual IMDG servers or the data they hold. The application does not want to be concerned with connecting N application instances to M IMDG servers, especially when N and M (as well as cloud IP addresses) vary over time.
Deploying an IMDG in the Cloud
Even though an IMDG comprises several servers, the simplest way to deploy and manage an IMDG in the cloud is to identify it as a single, coherent service. ScaleOut StateServer® (and ScaleOut Analytics Server®, which includes features for operational intelligence) take this approach by naming a cloud-hosted IMDG with a single “store” name combined with access credentials. This name becomes the basis both for managing the deployed servers and for connecting applications to the IMDG.
For example, ScaleOut StateServer’s management console lets users deploy and manage an IMDG in both Amazon EC2 and Windows Azure by specifying a store name and the initial number of servers, as well as other optional parameters. The console does the rest, interacting with the cloud provider to accomplish several tasks, including starting up the IMDG, configuring its servers so that they can see each other, and recording metadata in the cloud needed to manage the deployment. For example, here’s the console wizard for deploying an IMDG in Amazon EC2:
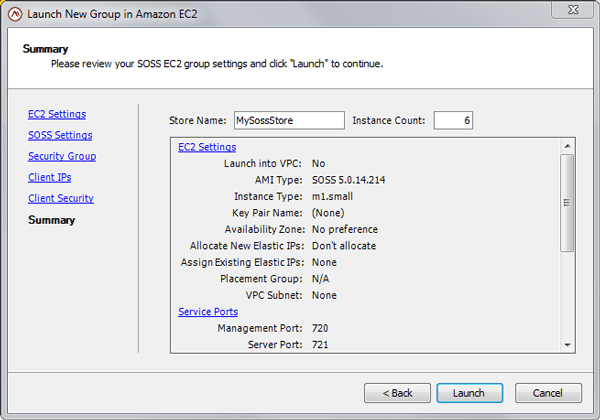
When the IMDG’s servers start up, they make use of metadata to find and connect to each other and to form a single, scalable, peer-to-peer service. ScaleOut StateServer uses different techniques on EC2 and Azure to make use of available metadata support. Also, the ScaleOut management console lets users specify various security parameters appropriate to the various cloud providers (e.g., security groups and VPC in EC2 and firewall settings in Azure), and the start-up process configures these parameters for all IMDG servers.
The management console also lets users add (or remove) instances as necessary to handle changes in the workload. The IMDG automatically redistributes the workload across the servers as the membership changes.
Easily Hooking Up an Application to the IMDG
The power of managing an IMDG using a single store name becomes apparent when connecting instances of a cloud-based application to the IMDG. On-premise applications typically connect each client instance to an IMDG using a list of IP addresses corresponding to available IMDG servers. This process works well on premise because IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of an IMDG server.
The solution to this problem is to let the application access the IMDG solely by its store name and cloud access credentials and have the IMDG find the servers. The store name and credentials are stored in a configuration file on each application instance with the access credentials fully encrypted. At startup time, the IMDG’s client library reads the configuration file and then uses previously stored metadata in the cloud to find the IMDG’s servers and connect to them. Note that this technique works well with both unencrypted and encrypted connections.
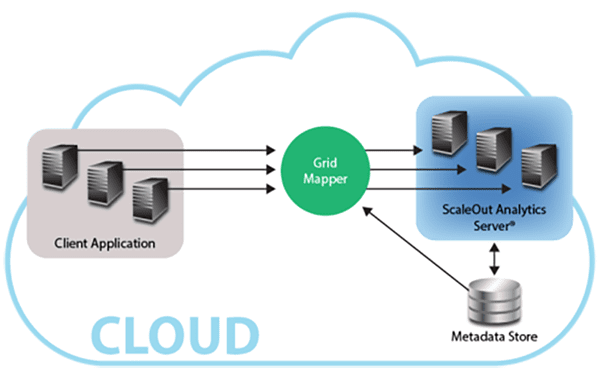
The following diagram illustrates how application instances automatically connect to the IMDG’s servers using the client library’s “grid mapper” software, which retrieves cloud-based metadata to make connections to ScaleOut Analytics Server:
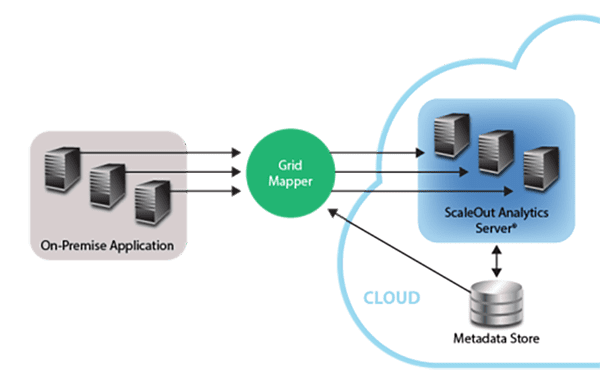
The application need not be running in the cloud. The same mechanism also allows an on-premise application to access a cloud-based IMDG. It also allows an on-premise IMDG to replicate its data to a cloud-based IMDG or connect to a cloud-based IMDG to form a virtual IMDG spanning both sites. (These features are provided in the ScaleOut GeoServer® product.) The following diagram illustrates connecting an on-premise application to a cloud-based IMDG:
Summing Up
As more and more server-side applications migrate to the cloud to take advantage of its elasticity, the power of IMDGs to unlock scalable performance and operational intelligence becomes increasingly compelling. Keeping IMDG deployment as simple as possible is critical to unlock the potential of this combined solution. Leveraging cloud-based metadata to automate the configuration process lets the application ignore the details of the IMDG’s infrastructure and easily access its scalable storage and computing power.
The post How to Easily Deploy an IMDG in the Cloud appeared first on ScaleOut Software.
]]>