The post CEO William Bain Gives Talk for the Digital Twin Consortium appeared first on ScaleOut Software.
]]>In this talk, Dr. Bain described a new vision for digital twins that takes them beyond traditional applications to address challenges faced by managers of large systems with thousands or even millions of data sources. Digital twins can implement streaming analytics that continuously monitor these complex systems for emerging issues and help managers boost their situational awareness.
Numerous applications can benefit from this new use of digital twins. Examples described in the talk include tracking vehicle fleets and logistics networks, improving the safety of transportation systems, and assisting in disaster recovery.
ScaleOut Software’s in-memory computing technology makes it possible to simultaneously host thousands of digital twins and run both streaming analytics and simulations. The talk explains how this technology adds real-time aggregate analytics while lowering response times and scaling performance.
Download The Presentation Slides

- Learn more about the ScaleOut Digital Twin Streaming Service
 .
. - Watch Dr. Bain’s previous digital twin talk.
The post CEO William Bain Gives Talk for the Digital Twin Consortium appeared first on ScaleOut Software.
]]>The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>
by Olivier Tritschler, Senior Software Engineer
Because of their ability to provide highly elastic computing resources, public clouds have become a highly attractive platform for hosting distributed caches, such as ScaleOut StateServer®. To complement its current offerings on Amazon AWS and Microsoft Azure, ScaleOut Software has just announced support for the Google Cloud Platform. Let’s take a look at some of the benefits of hosting distributed caches in the cloud and understand how we have worked to make both deployment and management as simple as possible.
Distributed Caching in the Cloud
Distributed caches, like ScaleOut StateServer, enhance a wide range of applications by offering shared, in-memory storage for fast-changing state information, such as shopping carts, financial transactions, geolocation data, etc. This data needs to be quickly updated and shared across all application servers, ensuring consistent tracking of user state regardless of the server handling a request. Distributed caches also offer a powerful computing platform for analyzing live data and generating immediate feedback or operational intelligence for applications.
Built using a cluster of virtual or physical servers, distributed caches automatically scale access throughput and analytics to handle large workloads. With their tightly integrated client-side caching, these caches typically provide faster access to fast-changing data than backing stores, such as blob stores and database servers. In addition, they incorporate redundant data storage and recovery techniques to provide built-in high availability and ensure uninterrupted access if a server fails.
To meet the needs of elastic applications, distributed caches must themselves be elastic. They are designed to transparently scale upwards or downwards by adding or removing servers as the workload varies. This is where the power of the cloud becomes clear.
Because cloud infrastructures provide inherent elasticity, they can benefit both applications and distributed caches. As more computing resources are needed to handle a growing workload, clouds can deploy additional virtual servers (also called cloud “instances”). Once a period of high demand subsides, resources can be dialed back to minimize cost without compromising quality of service. The flexibility of on-demand servers also avoids costly capital investments and reduces management costs.
Deploying ScaleOut’s Distributed Cache in the Google Cloud
A key challenge in using a distributed cache as part of a cloud-hosted application is to make it easy to deploy, manage, and access by the application. Distributed caches are typically deployed in the cloud as a cluster of virtual servers that scales as the workload demands. To keep it simple, a cloud-hosted application should just view a distributed cache as an abstract entity and not have to keep track of individual caching servers or which data they hold. The application does not want to be concerned with connecting N application instances to M caching servers, especially when N and M (as well as cloud IP addresses) vary over time. In particular, an application should not have to discover and track the IP addresses for the caching servers.
Even though a distributed cache comprises several servers, the simplest way to deploy and manage it in the cloud is to identify the cache as a single, coherent service. ScaleOut StateServer takes this approach by identifying a cloud-hosted distributed cache with a single “store” name combined with access credentials. This name becomes the basis for both managing the deployed servers and connecting applications to the cache. It lets applications connect to the caching cluster without needing to be aware of the IP addresses for the cluster’s virtual servers.
The following diagram shows a ScaleOut StateServer distributed cache deployed in Google Cloud. It shows both cloud-hosted and on-premises applications connected to the cache, as well as ScaleOut’s management console, which lets users deploy and manage the cache. Note that while the distributed cache and applications all contain multiple servers, applications and users can access the cache just by using its store name.
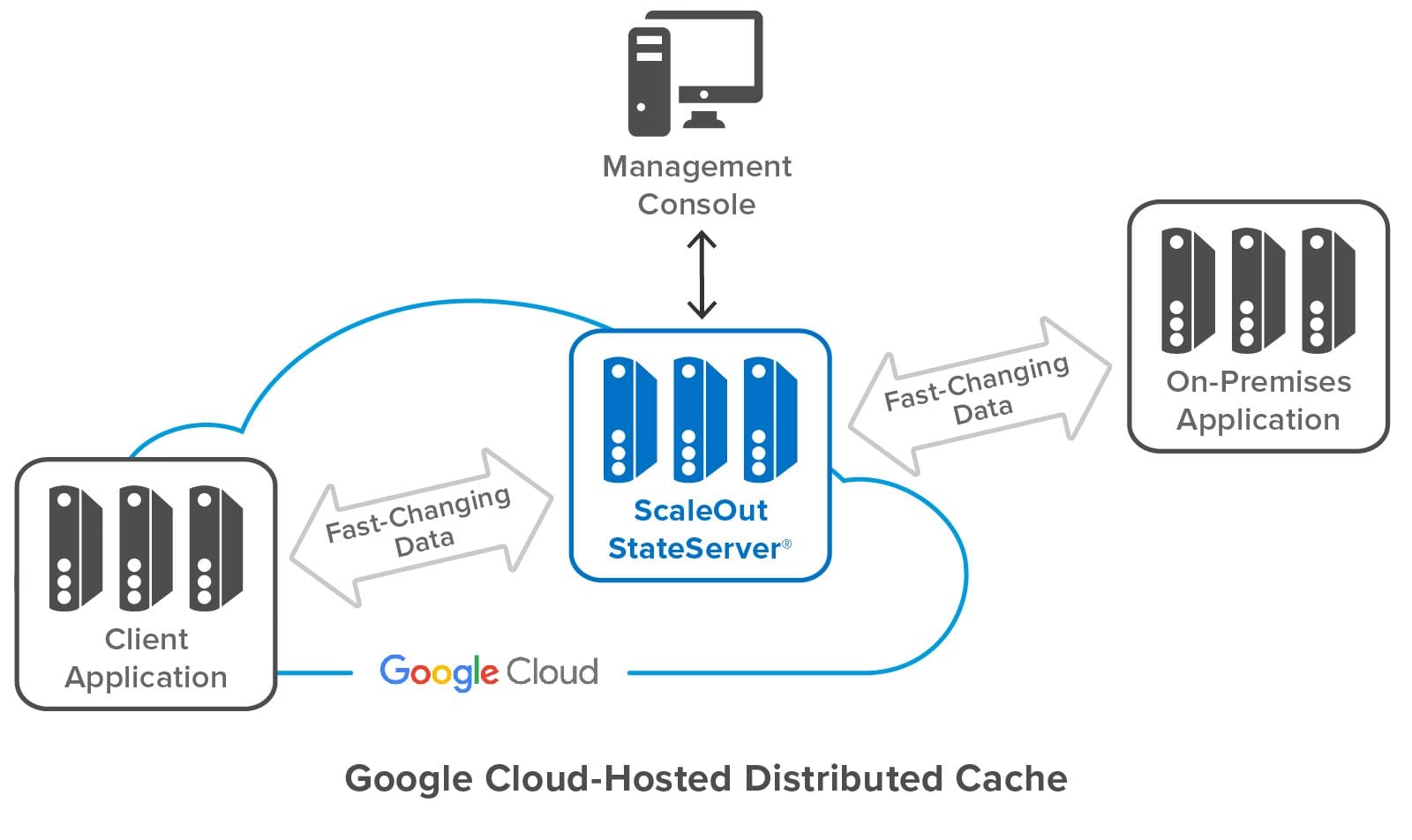
Building on the features developed for the integration of Amazon AWS and Microsoft Azure, the ScaleOut Management Console now lets users deploy and manage a cache in Google Cloud by just specifying a store name and initial number of servers, as well as other optional parameters. The console does the rest, interacting with Google Cloud to start up the distributed cache and configure its servers. To enable the servers to form a cluster, the console records metadata for all servers and identifies them as having the same store name.
Here’s a screenshot of the console wizard used for deploying ScaleOut StateServer in Google Cloud:
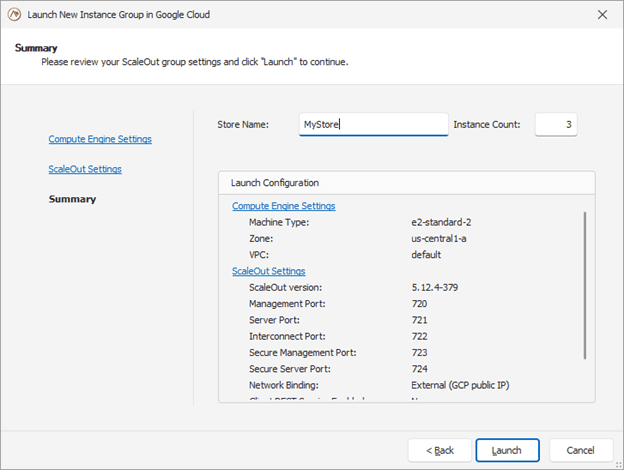
The management console provides centralized, on-premises management for initial deployment, status tracking, and adding or removing servers. It uses Google’s managed instance groups to host servers, and automated scripts use server metadata to guarantee that new servers automatically connect with an existing store. The managed instance groups used by ScaleOut also support defining auto-scaling options based on CPU/Memory usage metrics.
Instead of using the management console, users can also deploy ScaleOut StateServer to Google Cloud directly with Google’s Deployment Manager using optional templates and configuration files.
Simplifying Connectivity for Applications
On-premises applications typically connect each client instance to a distributed cache using a fixed list of IP addresses for the caching servers. This process works well on premises because the cache’s IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of a caching server.
To avoid this problem, ScaleOut StateServer lets client applications specify a store name and credentials to access a cloud-hosted distributed cache. ScaleOut’s client libraries internally use this store name to discover the IP addresses of caching servers from metadata stored in each server.
The following diagram shows a client application connecting to a ScaleOut StateServer distributed cache hosted in Google Cloud. ScaleOut’s client libraries make use of an internal software component called a “grid mapper” which acts as a bootstrap mechanism to find all servers belonging to a specified cache using its store name. The grid mapper accesses the metadata for the associated caching servers and returns their IP addresses back to the client library. The grid mapper handles any potential changes in IP addresses, such as servers being added or removed for scaling purposes.
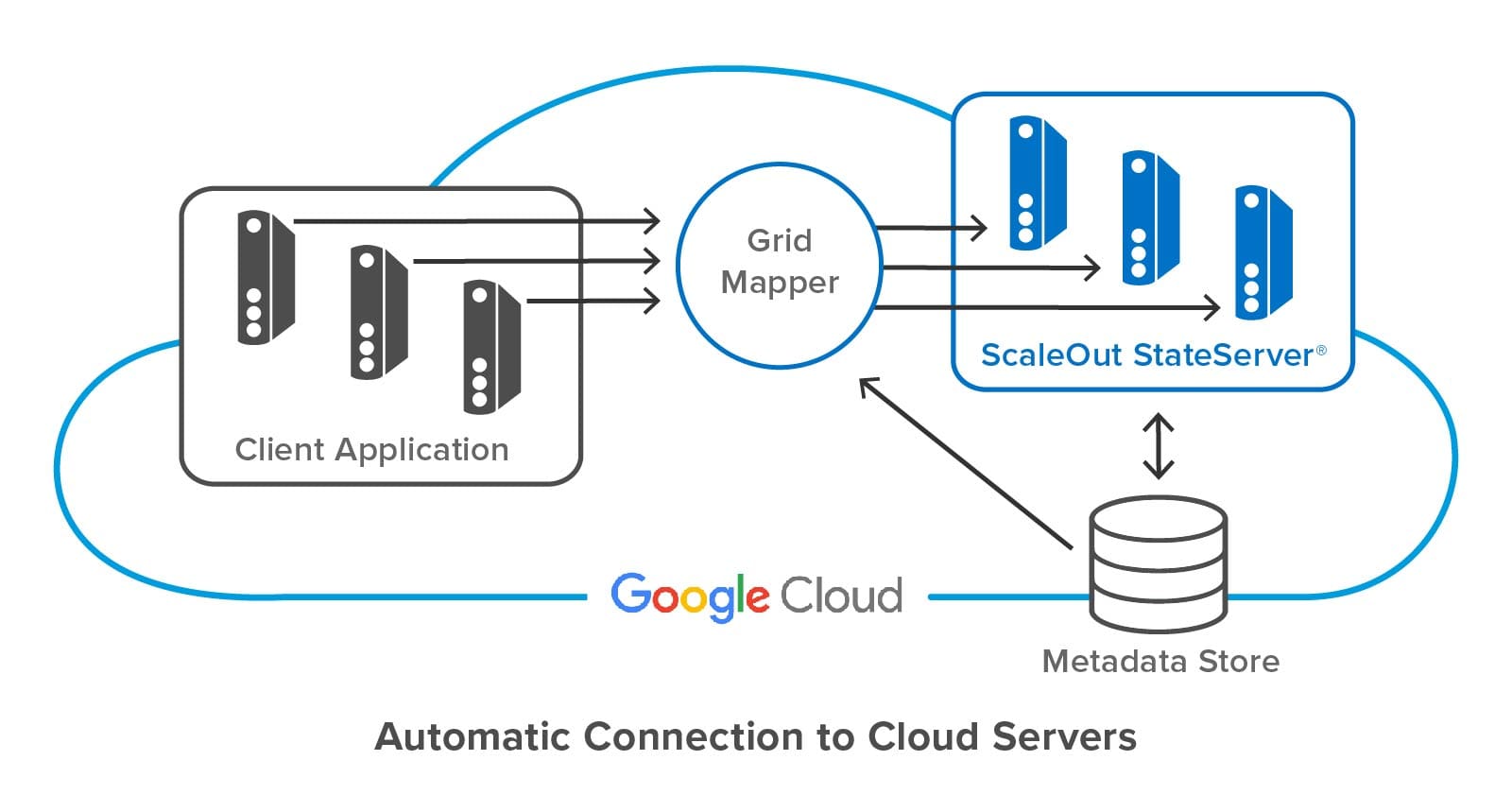
Summing up
Because they provide elastic computing resources and high performance, public clouds, such as Google Cloud, offer an excellent platform for hosting distributed caches. However, the ephemeral nature of their virtual servers introduces challenges for both deploying the cluster and connecting applications. Keeping deployment and management as simple as possible is essential to controlling operational costs. ScaleOut StateServer makes use of centralized management, server metadata, and automatic client connections to address these challenges. It ensures that applications derive the full benefits of the cloud’s elastic resources with maximum ease of use and minimum cost.
The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>
by Brandon Ripley, Senior Software Engineer
ScaleOut Software introduces a new Java client API for our distributed caching platform, ScaleOut StateServer®, that adds important new features for Java applications. It was designed with cloud-based deployments in mind, enabling clients to access ScaleOut in-memory data grids (IMDGs also called distributed caches) in multiple availability zones. It introduces the use of connection strings with DNS support for connecting Java clients to IMDGs, and it allows multiple, simultaneous connections to different caches. It also includes asynchronous APIs that add flexibility to application development.
You can download the JAR for the client API from ScaleOut’s Maven repository at https://repo.scaleoutsoftware.com. Simply connect your build tool to the repository and reference the API as a dependency to get started. The online User Guide can help you setup a project. Alternatively, you can download the JAR directly from the repo and then host the JAR with your build tool of choice. You can find an API reference here.
Let’s take a brief tour of the new Java APIs and look at an example using Docker for accessing multiple IMDGs.
A Quick Tour of the Java Client
The ScaleOut client API for Java lets client applications store and retrieve POJOs (plain old java objects) from a ScaleOut IMDG and provides an easy to use, fast, cloud-ready caching API. It can be used within any web application and is independent of any framework. This means that you can use the ScaleOut client API within your existing application architecture.
To simplify the developer experience, the API is logically divided into three primary packages:
Client Package
The client package houses the GridConnection class for connecting to a ScaleOut IMDG via a connection string. Each instance of GridConnection maintains a set of TCP connections to a ScaleOut cache and transparently handles retries, host failures, and load balancing.
The client package is also the place to register for event handling. ScaleOut servers can fire events for objects that are expiring and events for backing store operations (that is, read-through, refresh-ahead, write-behind, and erase-behind). The ServiceEvents class is used to register an event handler for events fired by the grid.
Caching Package
The caching package contains the strongly typed Cache<K,V> class that is used for all caching operations to store and retrieve POJOs of type V using a key of type K from a name space within the IMDG. All caching operations return a CacheResponse that details the result of the cache access.
For example, a successful access that adds a value to the cache using:
cache.add(key, value)
returns a CacheResponse with the status ObjectAdded, which can be obtained by calling the CacheResponse.getStatus() method. However, if the cache already contained an object for the key and the access was called again, CacheResponse.getStatus() would return ObjectAlreadyExists. (See the Javadoc for all possible responses.)
Query Package
The query package lets you perform queries to select objects from the IMDG. Queries are constructed using query filters created using the FilterFactory class. A filter can consist of a simple equality predicate, or it can combine multiple predicates to query with finer granularity.
Sample Applications
The following samples show how the ScaleOut Java client API can be used within a microservices architecture to access cached data and process events. The client API make it easy to develop modern web applications.
In these samples we will:
- Write an application that connects to two ScaleOut IMDGs to store and retrieve objects. (The two caches are configured to replicate data to each other using ScaleOut GeoServer®.)
- Write a second application that registers for and handles ScaleOut expiration events.
- Create four dockerfiles: the caching application, the expiration event handling application, and two ScaleOut IMDGs.
- Use the Docker compose command to spawn all four containers and run the two applications.
You can find the full samples, including the dockerfiles, on GitHub. Let’s look at the code for these two applications.
Accessing Multiple IMDGs
The first application’s goal is to verify ScaleOut GeoServer replication between two IMDGs. It first connects to the two IMDGs, creates an instance of Cache(K,V) for each IMDG, and then performs accesses.
The application connects to the grid using the GridConnection.connect() static method to instantiate a GridConnection object for each IMDG (named store1 and store2 here):
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
The next step is to create an instance of Cache(K,V) for each IMDG. Caches are instantiated with a GridConnection which associates the instance with a specific IMDG. This allows different instances to connect to different IMDGs.
The Java client API uses a builder pattern to instantiate caches. For applications using dependency injection, the immutable cache guarantees that the defaults we set at build time will stay consistent for the lifetime of the app. This is great for large applications with many caches as it guarantees there will be no unexpected modifications.
On the builder we can specify properties for defaults. Here is an example that sets an object timeout of fifteen seconds and a timeout type of Absolute (versus ResetOnUpdate or Sliding). The string “example” specifies the cache’s name space:
Cache<Integer, String> store1Cache = new CacheBuilder<Integer, String>(store1Connection, "example", Integer.class)
.objectTimeout(Duration.ofSeconds(15))
.timeoutType(TimeoutType.Absolute)
.build();
The Cache(K,V) class has multiple signatures for storing and retrieving objects from the IMDG. These signatures follow traditional Java naming semantics for distributed caching. For example, the add(key,value) method assumes that no key/value object mapping exists in the cache, whereas update(key,value) assumes than a key/value mapping exists in the cache.
This application uses the add method to insert an item into store1Cache and then checks the response for success. Here’s a code sample that adds two items to the cache:
CacheResponse<String, String> addResponse = store1Cache.add(“MyKey”, "SomeValue");
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
addResponse = store1Cache.add(“MyFavoriteKey”, "MyFavoriteValue");
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
The application’s goal is to verify that ScaleOut GeoServer replicates stored objects from the store1 IMDG to store2. It creates an instance of Cache(K,V) for the same namespace on store2 and then attempts to retrieve the object with the read API:
CacheResponse<String, String> readResponse = store2Cache.read(“Key”);
if(readResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
Registering for Events
This sample application demonstrates how an application can have fine grain control over which objects will be removed from the IMDG after a time interval elapses. With the object timeout and timeout-type properties established, objects added to the IMDG will be subject to expiration. When an object expires, the ScaleOut grid will fire an expiration event.
Our application can register to handle expiration events by supplying an instance of Cache(K,V) and an appropriate lambda (or implementing class) to the ServiceEvents static method. The following code removes all objects other than a cache entry mapping with the key, “MyFavoriteKey”:
ServiceEvents.setExpirationHandler(cache, new CacheEntryExpirationHandler<Integer, String>() {
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<Integer, String> cache, String key) {
System.out.println("ObjectExpired: " + key);
if(key.compareTo(“MyFavoriteKey”) == 0)
return CacheEntryDisposition.Save;
return CacheEntryDisposition.Remove;
}});
Running the Applications
We’ve created code snippets for connecting to a ScaleOut grid, creating a cache, and registering for ScaleOut expiration events. We can put all these pieces together to create the two applications with two Java classes called CacheRunner and CacheExpirationListener.
CacheRunner connects to two ScaleOut IMDGs that are setup for push replication using ScaleOut GeoServer. (This is handled by the infrastructure via the dockerfiles and not done in code.) It creates an instance of Cache(K,V) associated with one of the IMDG (called store1) that has a very small absolute timeout for each object and another instance for the other IMDG (called store2). It stores an object in store1 and then retrieves it from store2 to verify that the object was pushed from one IMDG to the other.
Here is the code for CacheRunner:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.caching.*;
import java.time.Duration;
public class CacheRunner {
public static void main(String[] args) throws CacheException, GridConnectException {
System.out.println("Connecting to store 1...");
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
System.out.println("Connecting to store 2...");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
.geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
.objectTimeout(Duration.ofSeconds(15))
.objectTimeoutType(TimeoutType.Absolute)
.build();
Cache<String, String> store2Cache = new CacheBuilder<String, String>(store2Connection, "sample", String.class)
.build();
System.out.println("Adding object to cache in store 1!");
CacheResponse<String, String> addResponse = store1Cache.add("MyKey", "MyValue");
System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
addResponse = store1Cache.add("MyFavoriteKey", "MyFavoriteValue");
System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
System.out.println("Reading object from cache in store 2!");
CacheResponse<String,String> readResponse = store2Cache.read("foo");
System.out.println("Object " + ((readResponse.getStatus() == RequestStatus.ObjectRetrieved ?
"retrieved" : "not retrieved.")) + " from cache in store 2.");
}
}
CacheExpirationListener connects to one ScaleOut IMDG, create an instance of Cache(K,V), and registers for expiration events. Here is its code:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.ServiceEvents;
import com.scaleout.client.ServiceEventsException;
import com.scaleout.client.caching.*;
import java.io.IOException;
import java.time.Duration;
import java.util.concurrent.CountDownLatch;
public class ExpirationListener {
public static void main(String[] args) throws ServiceEventsException, IOException, InterruptedException,
GridConnectException {
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
.geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
.objectTimeout(Duration.ofSeconds(15))
.objectTimeoutType(TimeoutType.Absolute)
.build();
ServiceEvents.setExpirationHandler(store1Cache, new CacheEntryExpirationHandler<String, String>() {
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<String, String> cache, String key) {
CacheEntryDisposition disposition = CacheEntryDisposition.NotHandled;
System.out.printf("Object (%s) expired\n", key);
if(key.equals("MyFavoriteKey"))
disposition = CacheEntryDisposition.Save;
else disposition = CacheEntryDisposition.Remove;
return disposition;
}
});
}
}
To run these applications, we’ll use the Docker compose command to build Docker containers. We will have 4 services, each defined in their own respective dockerfile, which are all provided and available on the GitHub repo. You can clone the repository and then run the deployment with the following command:
docker-compose -f ./docker-compose.yml up -d –build
Here is the expected output for CacheRunner:
Adding object to cache in store 1! Object added to cache in store 1. Object added to cache in store 1. Reading object from cache in store 2! Object retrieved. from cache in store 2.
Here is the output for ExpirationListener:
Connected to store1! Object (MyFavoriteKey) expired Object (MyKey) expired
Summing Up
The new ScaleOut client API for Java adds important features that support the development of modern web and cloud applications. Built-in support for connection strings enables simultaneous connections to multiple IMDGs using DNS entries. Full support for asynchronous accesses also assists in application development. Let us know what you think with your comments on our community forum.
The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>The post New Video: Automated Clustering for Redis appeared first on ScaleOut Software.
]]> (IMDB) automates Redis clustering so that you can add and remove servers with a single command — starting with just two servers. ScaleOut IMDB also ensures that the cluster implements strong consistency to keep stored data safe and IT costs low.
Subscribe to ScaleOut’s YouTube channel to see the latest explainer videos, interviews, tech talks and more!
The post New Video: Automated Clustering for Redis appeared first on ScaleOut Software.
]]>The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>
ScaleOut Software is excited to announce the release of ScaleOut In-Memory Database, which offers a new, highly scalable, clustered server platform for running Redis commands. This platform uses ScaleOut’s patented, quorum-based clustering technology to replace open-source Redis’s cluster implementation. It fully automates Redis cluster management while preserving the use of open-source Redis code to process commands. In doing so, ScaleOut In-Memory Database lets enterprise Redis users manage server clusters with much greater ease and lower both their acquisition and management costs (TCO) — while preserving a native execution environment for Redis applications. ScaleOut In-Memory Database runs on both Linux and Windows systems.
What sets ScaleOut’s cluster architecture apart
When ScaleOut Software first developed its clustering technology for scalable in-memory data storage in 2003, we had to tackle several technical challenges. We needed to:
- implement a scalable cluster membership,
- partition the in-memory data store across multiple servers,
- replicate updates with zero data loss (i.e., avoid eventual consistency), and
- maximize throughput with multi-threading on multicore servers.
We also realized that it was important not to expose all these complexities to users. The cluster had to be easy to manage, making a simple learning curve for system administrators. It was also vital to have a straightforward view of the data store for applications (that is, maintain location transparency and full consistency) so developers could target it easily.
Automated clustering
Our clustering architecture has many leading-edge automated clustering features. These include the ability to:
- self-organize multiple servers into a cluster,
- automatically partition data and distribute it across the cluster,
- load-balance stored data as servers are added or removed,
- automatically create and maintain replicas,
- detect server and network failures,
- recover from failures by promoting replicas to replace failed primary partitions, and
- “self-heal” by creating new replicas to replace lost ones.
Stability and consistency
The server cluster uses peer-to-peer algorithms to avoid single points of failure. Running on one or more servers, it maintains availability to applications even if all but one server fails. It uses a patented quorum algorithm to implement full (strong) consistency when updating stored data across multiple servers. Lastly, it executes multiple requests at once using a multi-threaded architecture.
Industry-leading ease of use
ScaleOut’s cluster architecture does all this without showing its inner workings to developers or system administrators. Developers see a single, reliable data store that happens to be distributed across multiple servers. System administrators see a set of servers on a single network subnet, each running a single service process.
Once the service is configured to select a specific subnet (if multiple NICs are in use), it joins the cluster with one click and is ready to take on its share of the workload. Building a server cluster is just a matter of adding servers (called “nodes” in Redis documentation):
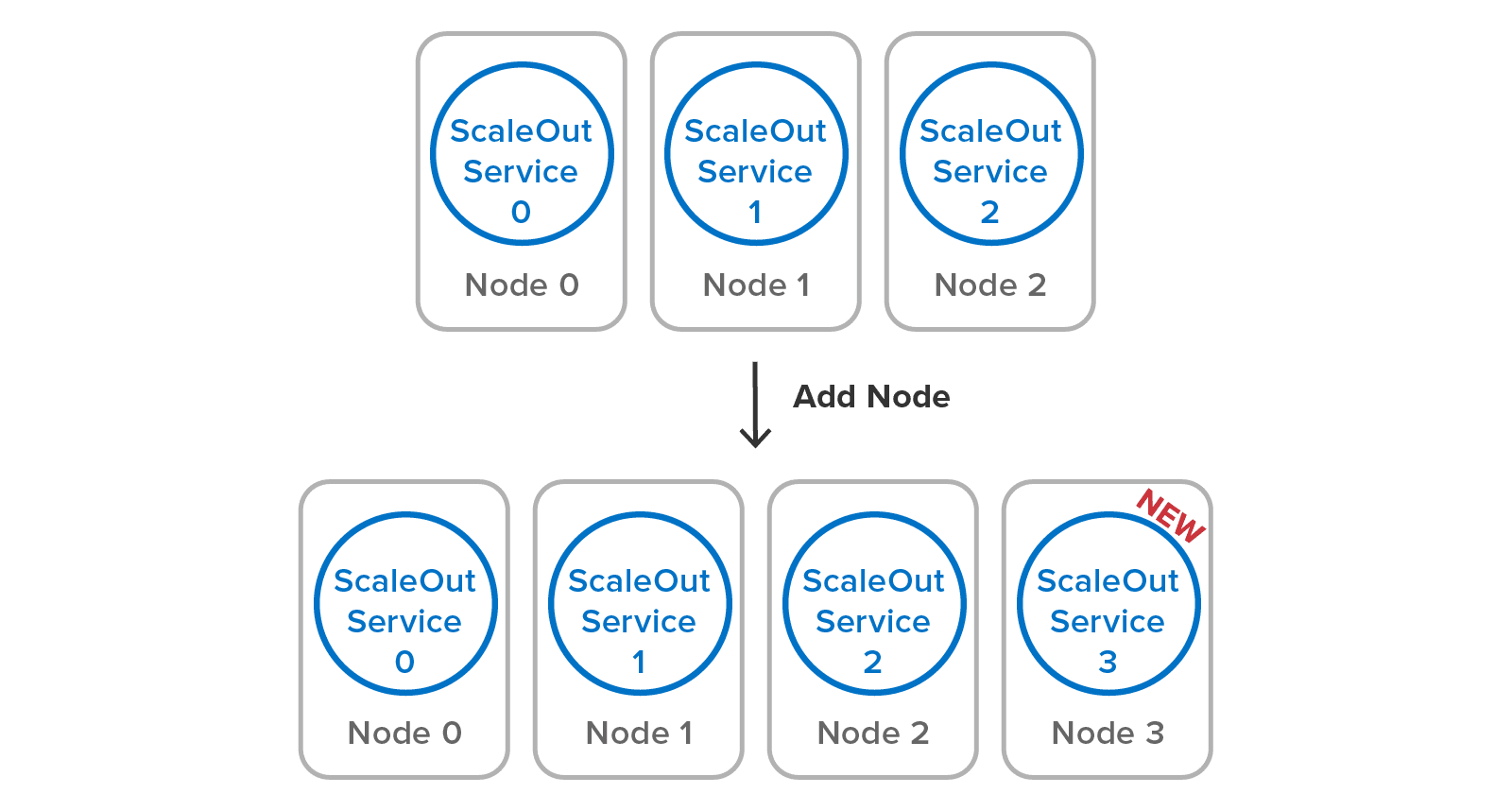 All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
Enter Redis
Open-source Redis was first created in 2009 for use on a single server, with clustering added in 2015. It has gained widespread popularity because of its rich set of data structures and commands. At the enterprise level, it has seen fast-growing adoption across many applications. As a result, the need to streamline cluster management procedures and increase data reliability for Redis users has become more urgent.
Introducing automated Redis clustering with ScaleOut In-Memory Database
We created ScaleOut In-Memory Database to meet this need. This product integrates open-source Redis code (version 6.2.5) that implements all the popular Redis data structures (strings, lists, sets, hashes, streams, and more) into ScaleOut’s automated cluster architecture and execution platform. Now, system administrators don’t need to manage Redis concepts like hashslots and shards. Instead, ScaleOut takes over these tasks using its built-in, fully automated mechanisms. Automated recovery and self-healing eliminate the need for manual intervention and increase uptime. What’s more, ScaleOut’s quorum-based updates replace Redis’s eventual consistency mechanism to deliver reliable data storage across servers. Applications can depend on the server cluster to survive a server failure without data loss, and the cluster remains available even if multiple servers fail.
To boost throughput and automatically make full use of all available processing cores, ScaleOut In-Memory Database integrates Redis command execution with its multi-threaded processing of client requests. Achieving this meant eliminating Redis’s native, single-threaded event-loop execution model without introducing a global lock that would constrain performance. The result is that each server in the cluster can run Redis commands simultaneously on all processing cores using a single service process.
Power with simplicity
We designed ScaleOut’s peer-to-peer cluster architecture to serve as the foundation for all user services. Hence, functions like clearing the database and backup/restore were built from the outset to run in parallel across all servers. This approach reduces the system administrator’s workload and delivers fast performance. To give Redis users the benefit of a fully parallel architecture, ScaleOut In-Memory Database provides a cluster-wide implementation of many Redis commands, such as PUBLISH and FLUSHALL.
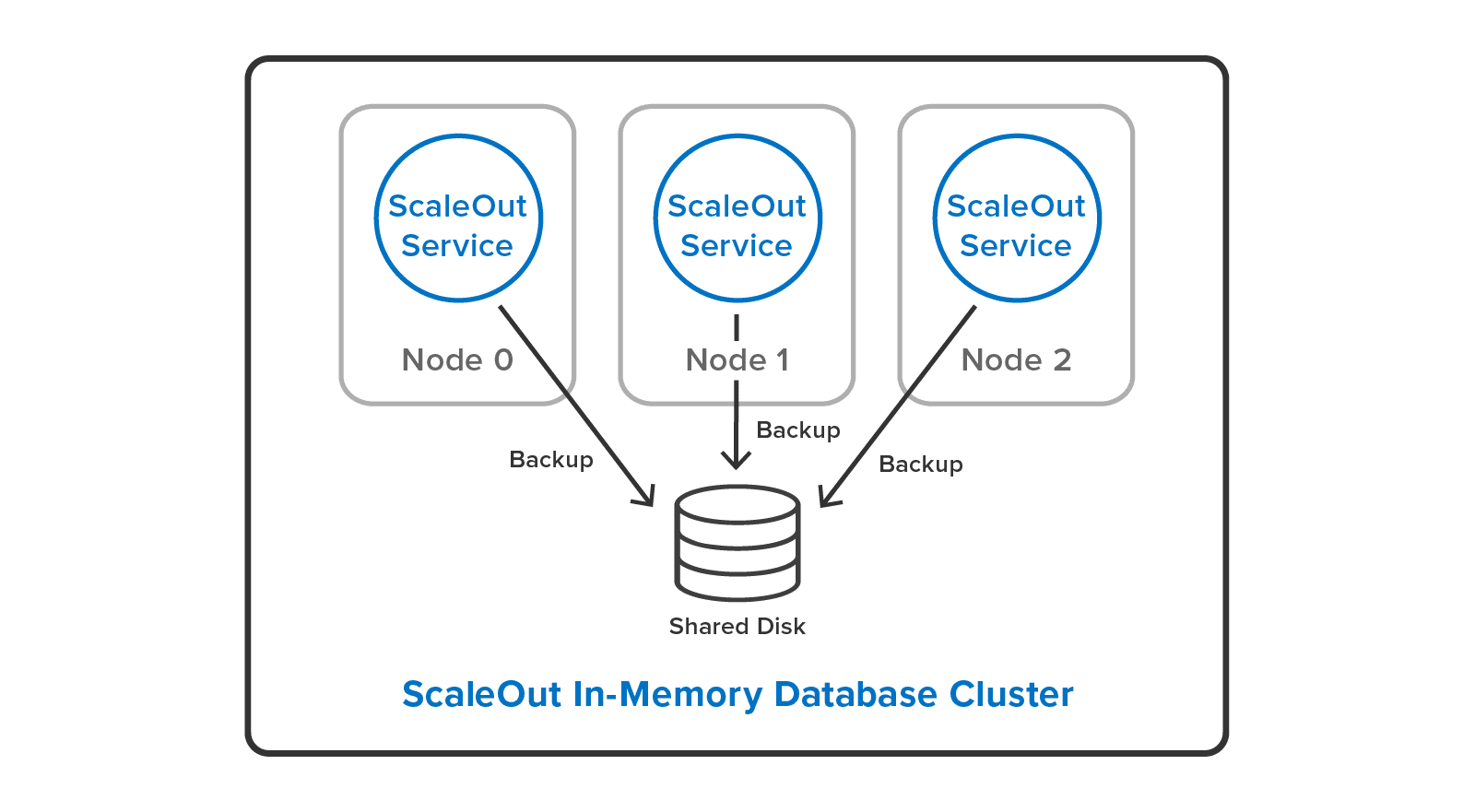
ScaleOut In-Memory Database also overcomes the single-server limitation of the Redis SAVE command. It provides a cluster-wide implementation of backup/restore using its built-in parallel backup/restore utility. This allows system administrators to backup all Redis objects with one click in ScaleOut’s management console, and it delivers parallel speedup by running simultaneously on all servers. The user can backup either to local disks:
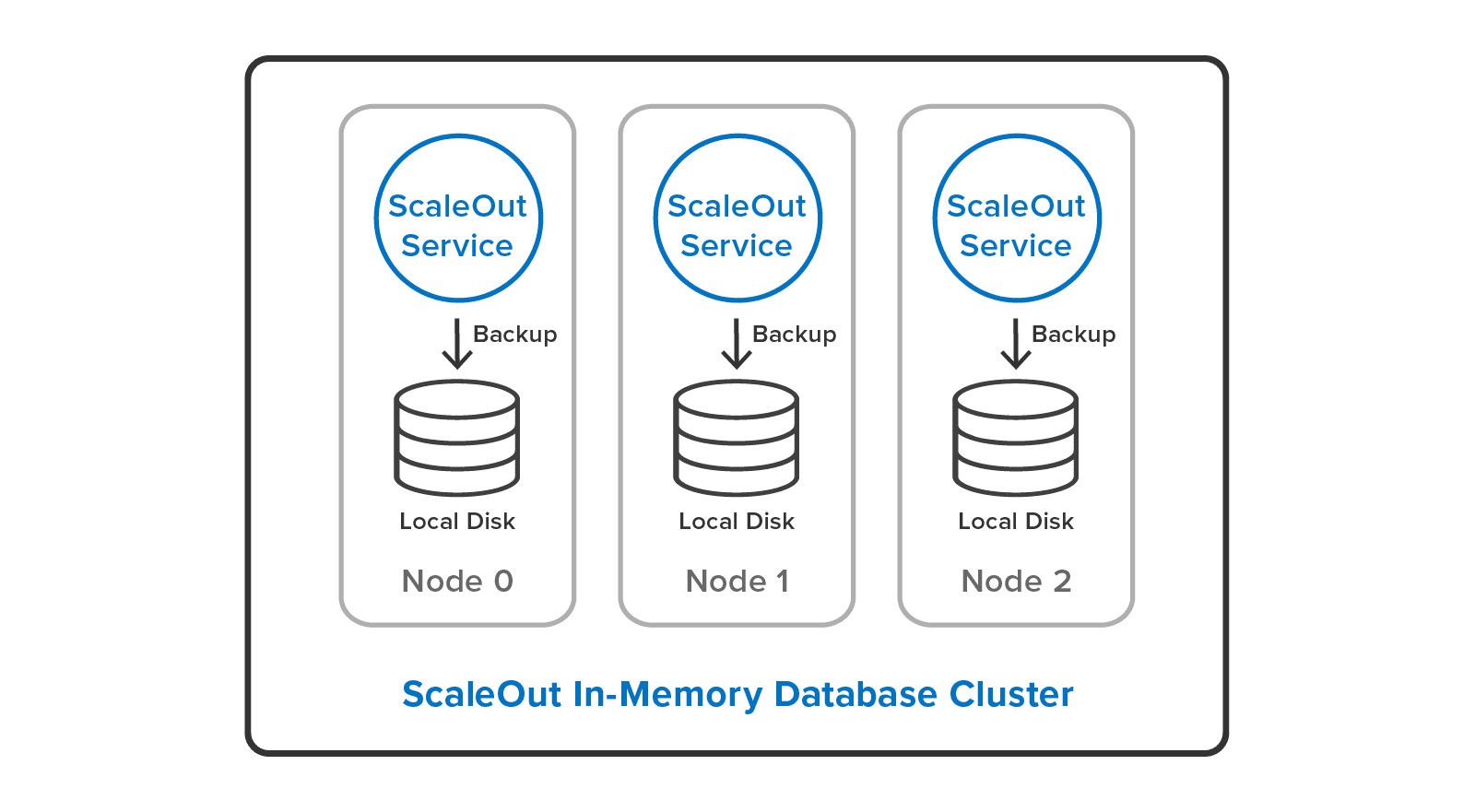
or to a single, shared disk:
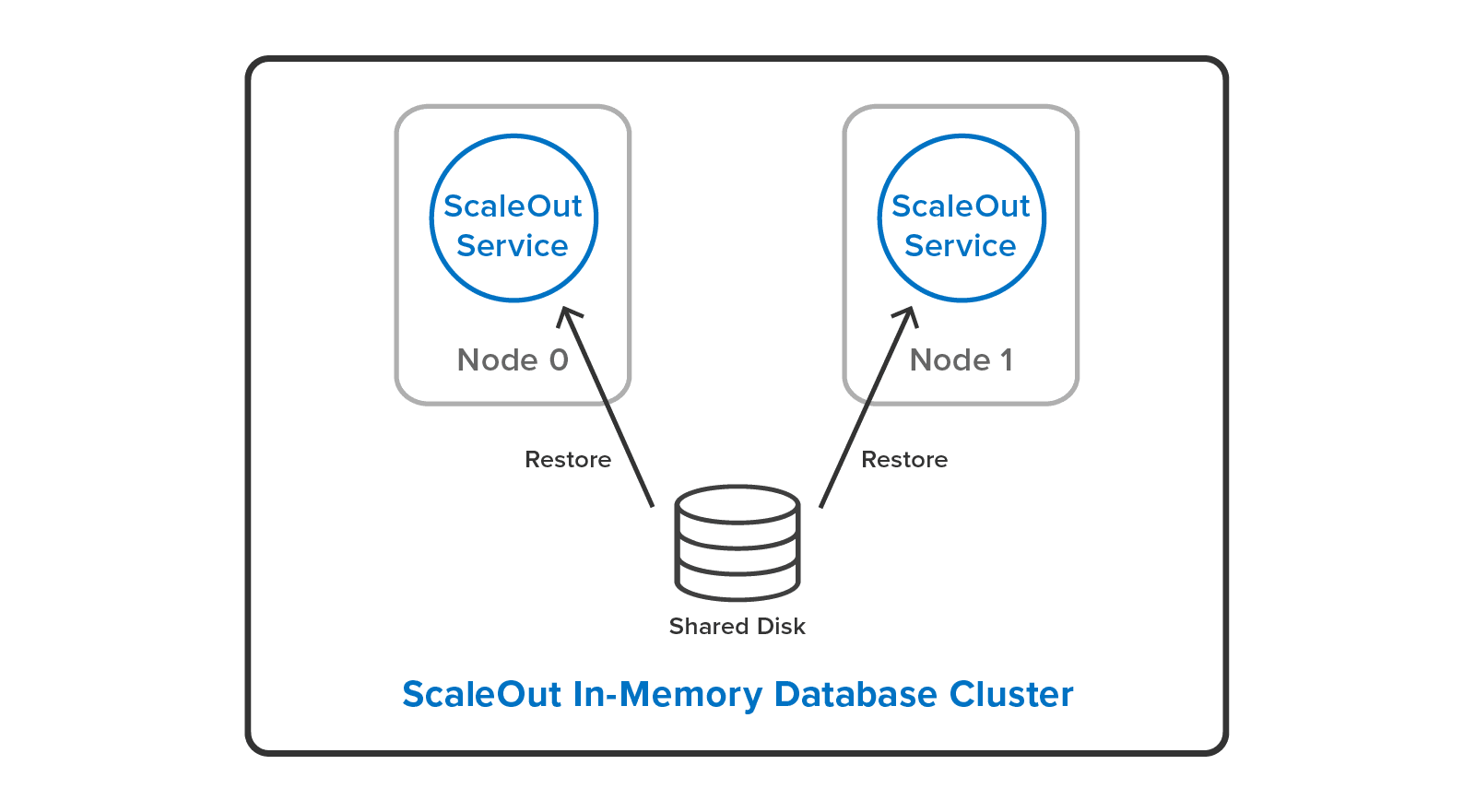
System administrators can cut down their workload by restoring backup files to a different cluster configuration than they used to make the backup. For example, it’s possible to restore a backup from a three-server cluster to a two-server cluster with a different hashslot mapping:
There’s a lot more in the new ScaleOut In-Memory Database than there’s room to discuss in depth here. For example, ScaleOut’s cluster stalls Redis command execution automatically when it moves hashslots between nodes for load-balancing, or when it performs recovery. This means clients always have a consistent view of the cluster. Also, the cluster stores Redis objects in their own ScaleOut namespace side-by-side with objects that ScaleOut’s native APIs manage. This lets users access the full power of ScaleOut’s in-memory computing features, including cluster-wide, data-parallel operations and stream processing with digital twins.
Summing Up
ScaleOut In-Memory Database makes scalable processing more convenient, reliable, and cost-effective for enterprise Redis users than ever before. By automating Redis cluster management, improving data reliability, and adding multi-threaded command execution, this product can significantly drive down the total cost of ownership for Redis deployments, even in comparison to commercial Redis alternatives. We invite you to check it out and see how it performs for you. We’d love to hear your feedback.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>The post Introducing A New Execution Platform for Redis Clients appeared first on ScaleOut Software.
]]>
The Challenge
Redis®* offers a compelling set of data structures that enhance the capabilities of a distributed cache beyond just storing serialized objects. Created in 2009 as a single-server store to assist in the design of a web server, Redis gives applications numerous useful options for organizing stored data, including sets, lists, and hashes. Cluster support was added later, and it introduced specialized concepts, like hashslots and master/replica shards, that system administrators must understand and manage. Along with its use of eventual consistency, this has created complexity that makes cluster management challenging while reducing flexibility in configurations.
In contrast, ScaleOut StateServer®, a distributed cache for serialized objects and first released in 2005, was designed from the ground up to run on a server cluster with automated load-balancing, data replication, and recovery while storing data with full consistency (i.e., sequential consistency) across replicas. It also executes client requests using all available processing cores for maximum throughput. These features dramatically simplify cluster management, especially for enterprise users, improve flexibility, and lower TCO. For example, unlike Redis, ScaleOut server clusters can seamlessly grow from a single to multiple servers, and system administrators do not need to manage hashslots or master/replica shards. See a recent blog post that discusses how ScaleOut StateServer simplifies cluster management in comparison to Redis.
ScaleOut Software recognized that running Redis commands on a ScaleOut StateServer cluster would offer Redis users the best of both worlds: familiar and rich data structures combined with significantly simpler cluster management and full data consistency. However, the ideal implementation would need to use Redis open-source code to execute Redis commands so that client commands would behave identically to open-source Redis clusters. The challenge is then to integrate Redis code into ScaleOut StateServer’s execution platform and take advantage of ScaleOut’s highly automated clustering features while eliminating the single-threaded constraints of Redis’s event-loop architecture.
Integrating Redis into ScaleOut StateServer
Released as a community preview, version 5.11 of ScaleOut StateServer introduces support for the most popular Redis data structures (strings, sets, lists, hashes, and sorted sets) plus publish/subscribe commands, transactions, and various utility commands (such as FLUSHDB and EXPIRE). Both Windows and Linux versions are available. This release uses open-source Redis version 6.2.5 to process Redis commands.
Redis clients connect to any ScaleOut StateServer server in a cluster using the standard RESP protocol. (A cluster can contain one or more servers.) Client libraries internally obtain the mapping of hashslots to servers using either the CLUSTER SLOTS or CLUSTER NODES commands and then direct Redis access requests to the appropriate ScaleOut server. To maximize throughput, each ScaleOut server processes incoming Redis commands on multiple threads using all available processor cores; there is no need to deploy multiple shards on each server for this purpose.
The following diagram shows a set of Redis clients connecting to a ScaleOut StateServer cluster. Note that the complexities of hashslots and shards have been eliminated:
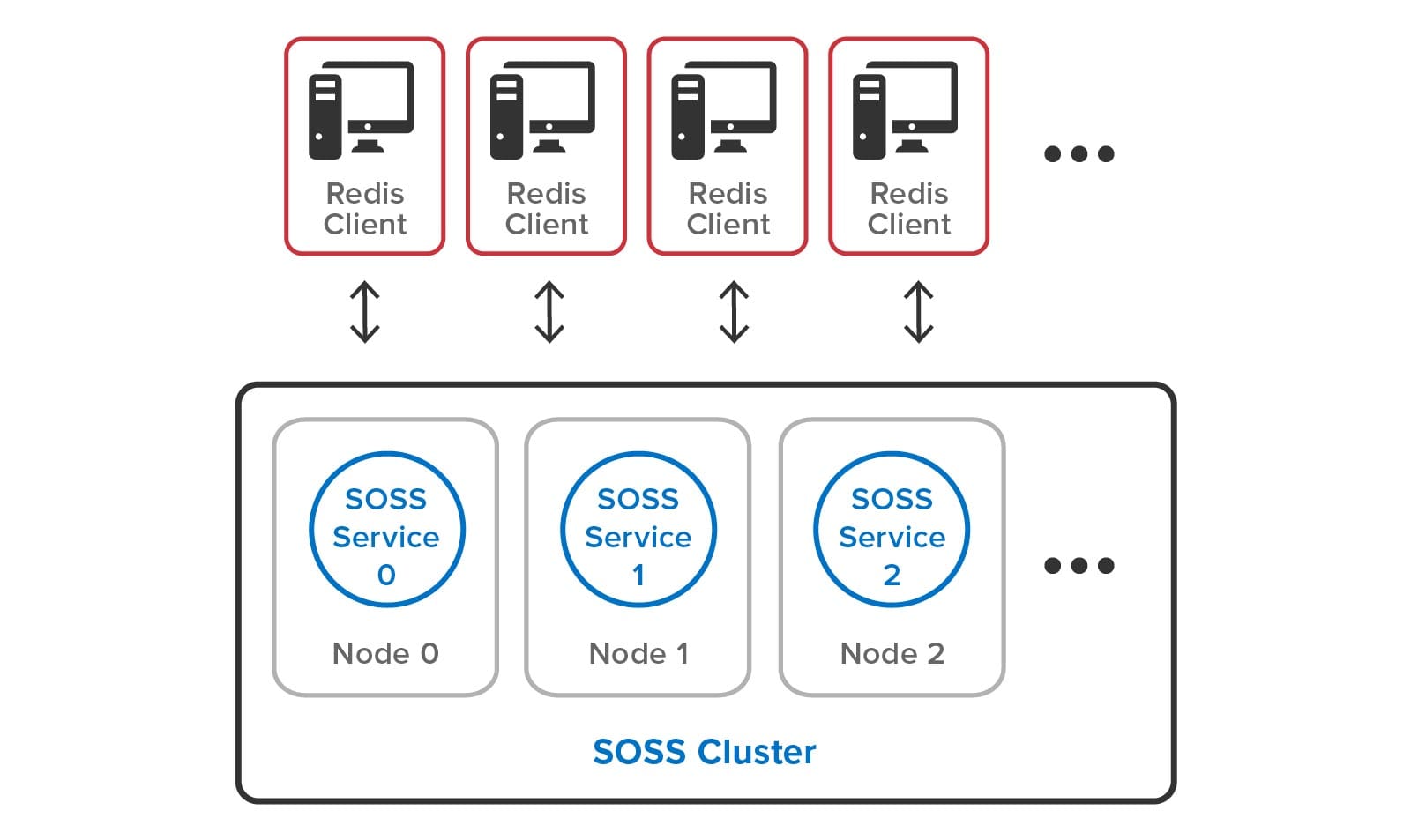
As the need for additional throughput grows, system administrators can simply join new servers to the cluster. ScaleOut StateServer automatically rebalances the hashslots across the cluster as servers are added or removed. It also delays execution of Redis commands during load-balancing (and recovery) to give clients a consistent picture of hashslot placement and avoid client exceptions. After a hashslot has fully migrated to a remote server, a requesting client is returned the Redis -MOVED indication so that it can redirect its request to the new server.
The following diagram illustrates how ScaleOut StateServer automatically manages hashslots. In this example, it migrates half of the hashslots to a second server that joins a cluster:
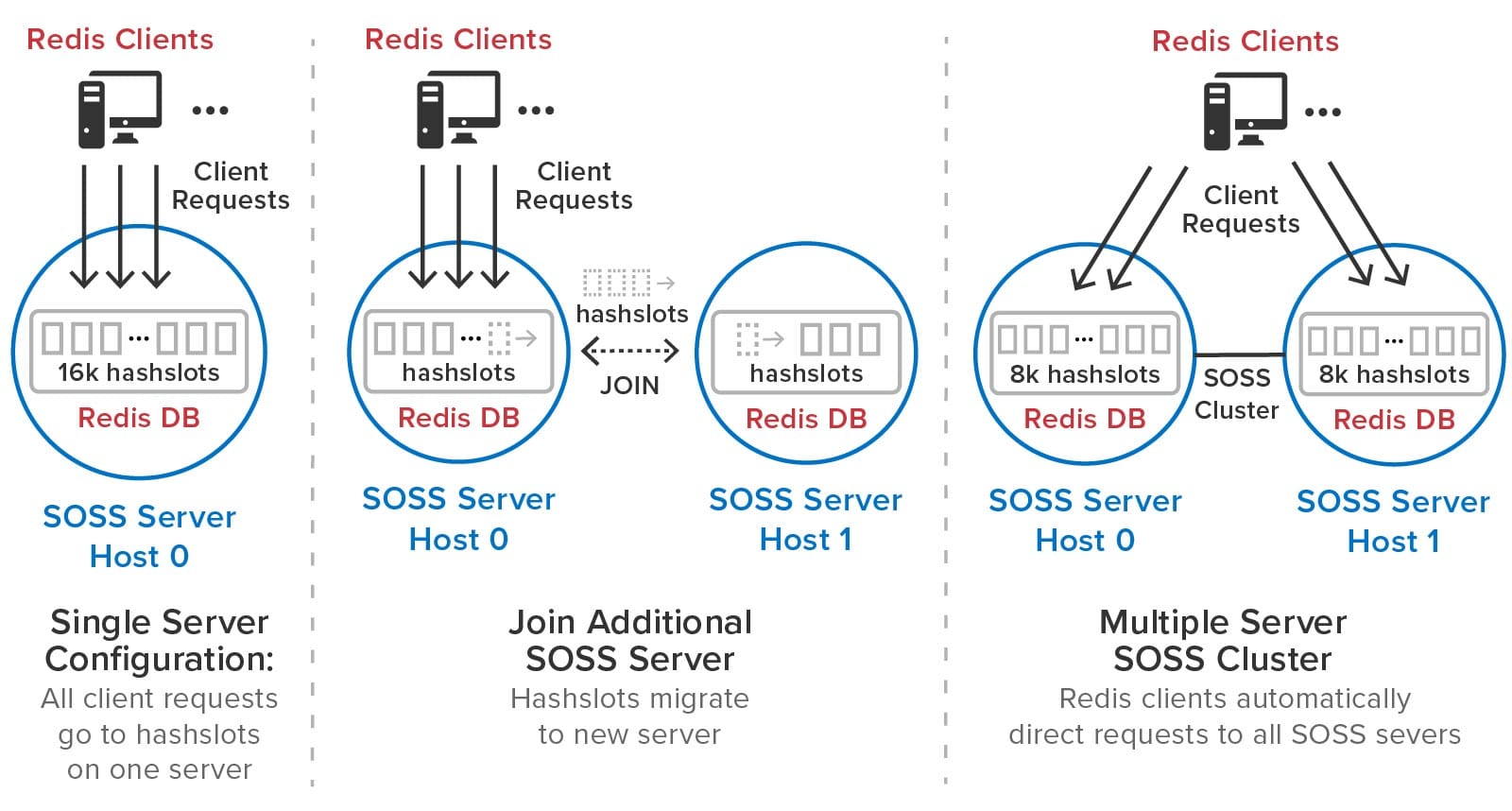
ScaleOut StateServer automatically creates replicas for all hashslots. There is no need for system administrators to manually create master and replica shards or move them from server to server during membership changes and recovery. ScaleOut StateServer automatically places replicas on different servers from their corresponding primary hashslots and migrates them as necessary during membership changes to ensure optimal load-balancing. If a server fails or has a network outage, ScaleOut StateServer automatically “self-heals” by promoting replicas to primaries and creating new replicas as necessary.
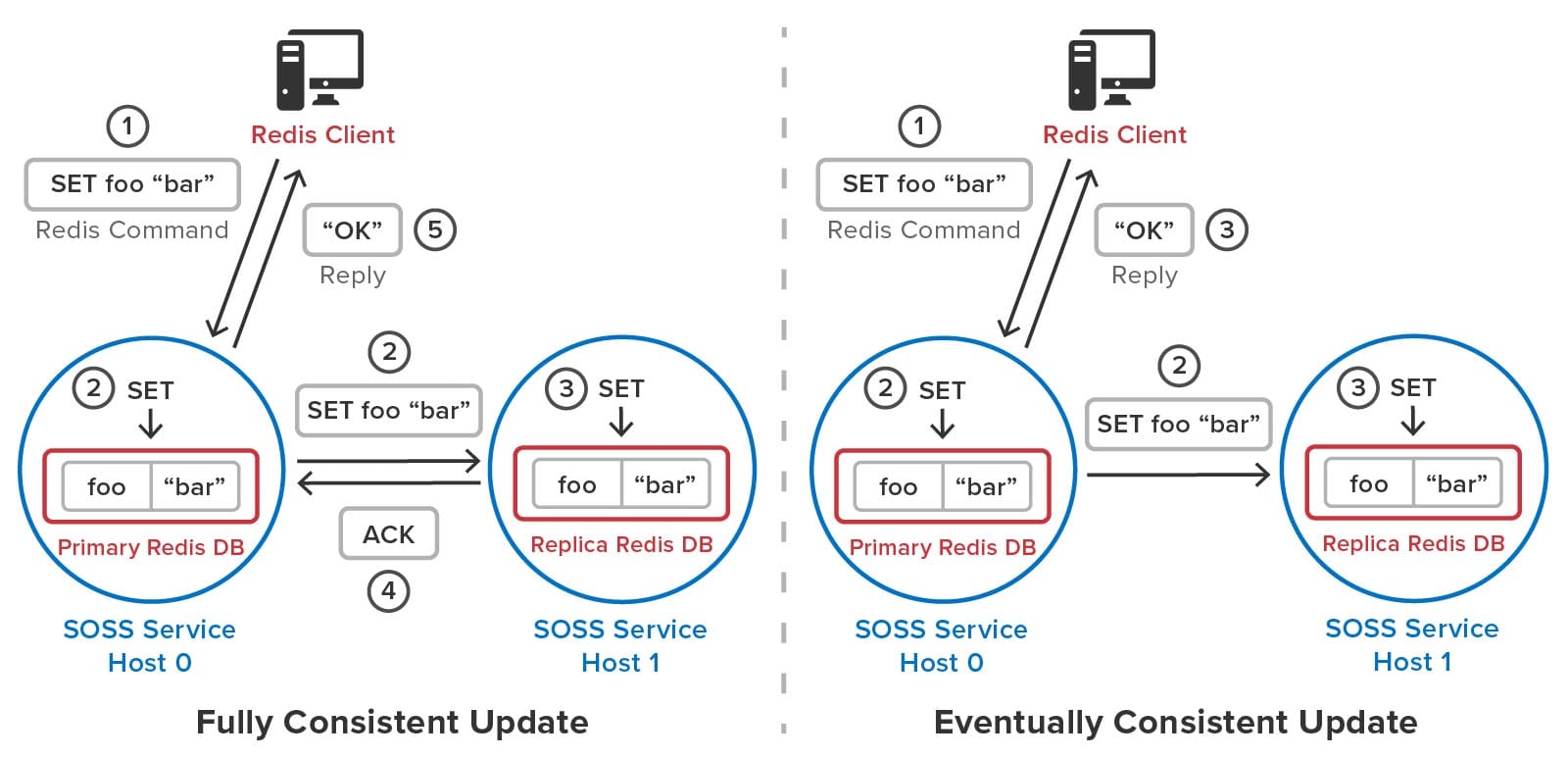
To avoid serving stale data to clients after recovery from an outage, ScaleOut StateServer uses a patented quorum algorithm to implement fully consistent updates to stored objects. In contrast, Redis uses an eventual consistency model for updating replicas. (To maximize throughput at the expense of data consistency, ScaleOut StateServer can optionally be configured for eventual consistency.) When a server receives a Redis command, it executes this command on a quorum containing the primary hashslot and replicas (one or two in the current implementation) prior to returning to the client. Transactions are processed in the same manner.
The following diagram compares the full and eventually consistent models for updating replicas and shows how they differ in behavior. A fully consistent update waits for the replica to be updated prior to returning to the client, whereas an eventually consistent update does not. If a primary server should fail prior to committing the replica’s update, the cluster could lose the update and serve stale data to clients.
Implementation Details
The following diagram shows how Redis open-source code has been integrated into ScaleOut StateServer:
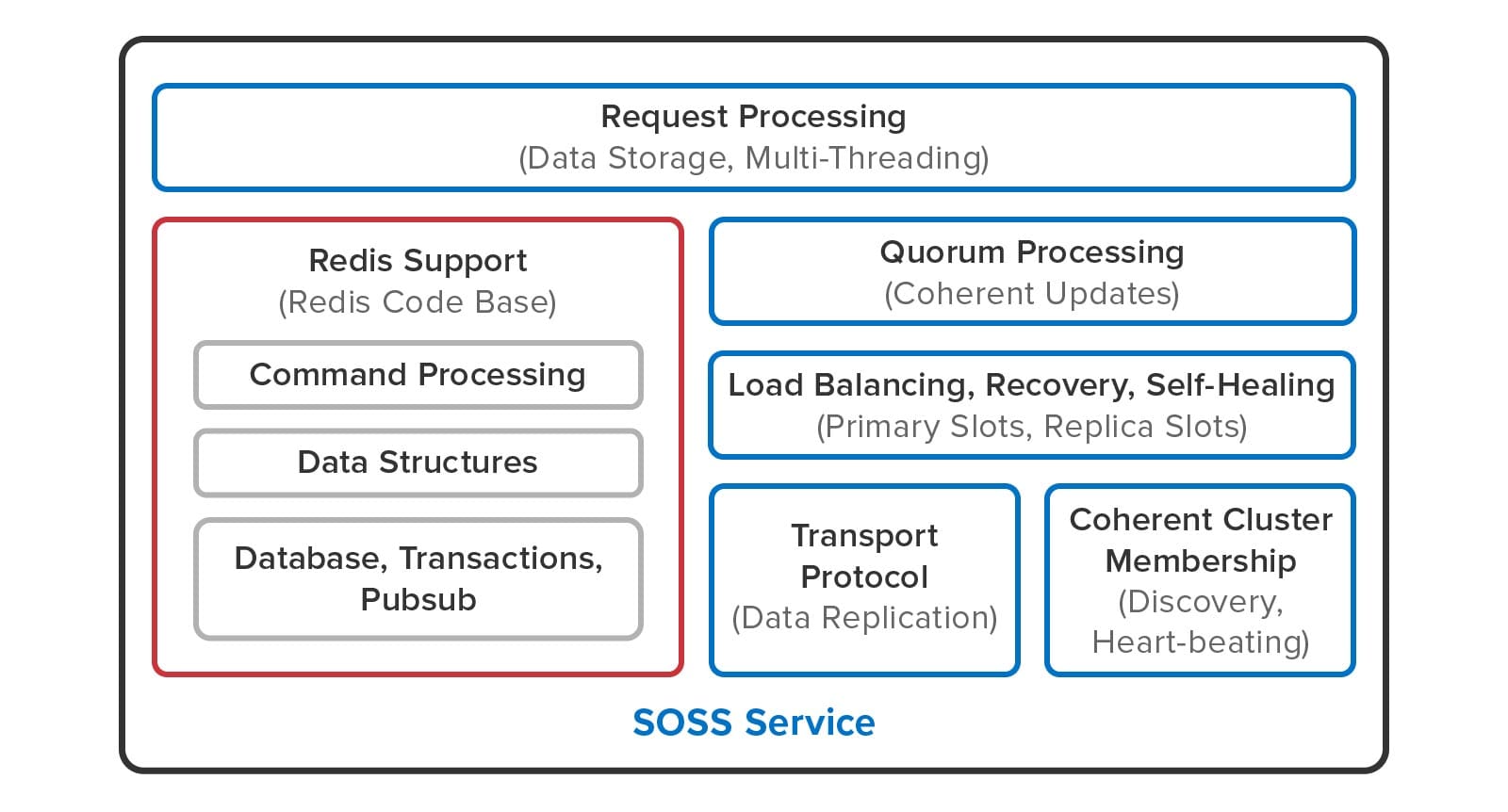
Redis open-source code (shown in the red box) implements command parsing and processing, the data structure commands, transactions, publish/subscribe commands, and blocking commands. ScaleOut StateServer takes over all clustering functions, including request processing, membership, quorum processing of updates, load-balancing, recovery, and self-healing. It also uses a proprietary transport protocol for server-to-server communication.
As illustrated below, ScaleOut StateServer uses multi-threaded execution for Redis commands to take advantage of all processing cores and eliminate the need for multiple primary shards on each server. In contrast, Redis executes commands using an event loop that processes commands sequentially on a single processing core:
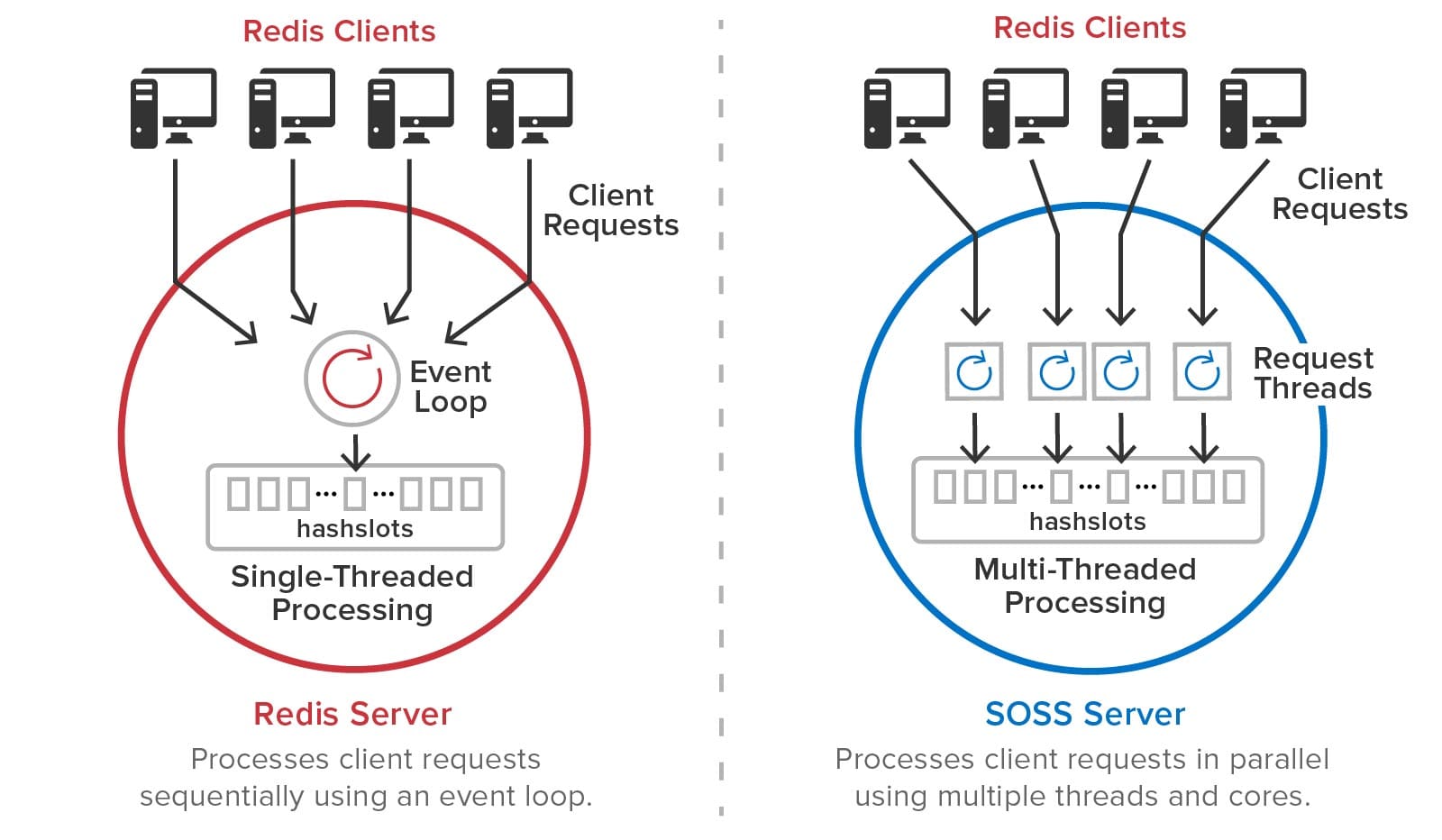
To accomplish this, ScaleOut StateServer has implemented a command scheduler that independently executes commands for each hashslot so that they can run in parallel without global locking.
What’s Missing?
The community preview release focuses on demonstrating support for Redis data structures, which represent the widely used core of Redis functionality. It does not include support for Redis streams, Lua scripting, modules, AOL/RDB persistence, ACLs, and Redis configuration files. In addition, many utility commands which are not required, such as cluster commands for manually moving hashslots, are not supported. Lastly, this version does not incorporate all of the performance enhancements in development for the production release.
Summing Up
ScaleOut’s new integration of Redis open-source code into ScaleOut StateServer was designed to bring powerful new capabilities to Redis users while ensuring native-Redis behavior for client applications. Targeted to meet the needs of enterprise users, it dramatically simplifies the management of Redis clusters by automating all cluster operations, and it ensures that fully consistent updates are performed by Redis commands. In addition, this integration runs alongside ScaleOut StateServer’s native APIs, which incorporate advanced features not available on open-source Redis clusters, such as data-parallel computing, streaming analytics, and coherent, wide-area data replication.
ScaleOut Software is excited to hear your feedback about the community preview and learn what additional features you would like to see in the upcoming production release. You can download ScaleOut StateServer, which incorporates the preview release, here for Linux or Windows and try it out now. Let us know what you think.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Introducing A New Execution Platform for Redis Clients appeared first on ScaleOut Software.
]]>The post Redis vs ScaleOut: What You Need to Know appeared first on ScaleOut Software.
]]>
ScaleOut’s Battle-Tested Clustering Technology Give It Key Advantages Over Redis®* in Ease of Use and Performance
By William L. Bain and Bryce C. Klinker
Breaking news: ScaleOut Software has announced a community preview of support for Redis clients in ScaleOut StateServer. Learn more here.
Distributed caching technology first hit the market in about 2001 with the introduction of Tangosol Coherence and has been evolving ever since. Designed to help applications scale performance by eliminating bottlenecks in accessing data, this distributed computing technology stores live, fast-changing data in memory across a cluster of inexpensive, commodity servers or virtual machines. The combination of fast, memory-based data storage and throughput scaling with multiple servers results in consistently fast access and update times for growing workloads, such as e-commerce, financial services, IoT device tracking, and other applications.
ScaleOut Software introduced its distributed caching product, ScaleOut StateServer® (SOSS), in 2005 and has made continuous enhancements over the last 16 years. While the single-server version of Redis was released in 2009 by Salvatore Sanfilippo, clustering support was first added in 2015. These two products embody highly different design goals. SOSS was designed as an integrated distributed caching architecture incorporating transparent throughput scaling and high availability using data replication with the goals of maximizing performance, ease of use, and portability across operating systems. In contrast, according to M. Russo, Redis was conceived as a single-server, data-structure store to improve the performance of a real-time data analytics product. (Beyond just storing strings or opaque objects, a data-structure store also implements various data types, such as lists and sorted sets.) Clustering was added to Redis’ single-server architecture after 4 years to provide a way to scale.
As background for the following discussion, it’s important to review some key concepts. Most distributed caches use a key/value storage model that identifies stored objects using string keys. To distribute objects across multiple servers in a cluster, a distributed cache typically maps keys to hash slots, each of which holds a subset of objects. The cache then distributes hash slots across the servers and moves them between servers as needed to balance the workload; this process is called sharding. A group of hash slots running on a single server (called a node here) can either be a primary or replica. Clients direct updates to the target hash slot on a primary node, which replicates the update to one or more replica nodes for high availability in case the primary node fails.
Ease of Use
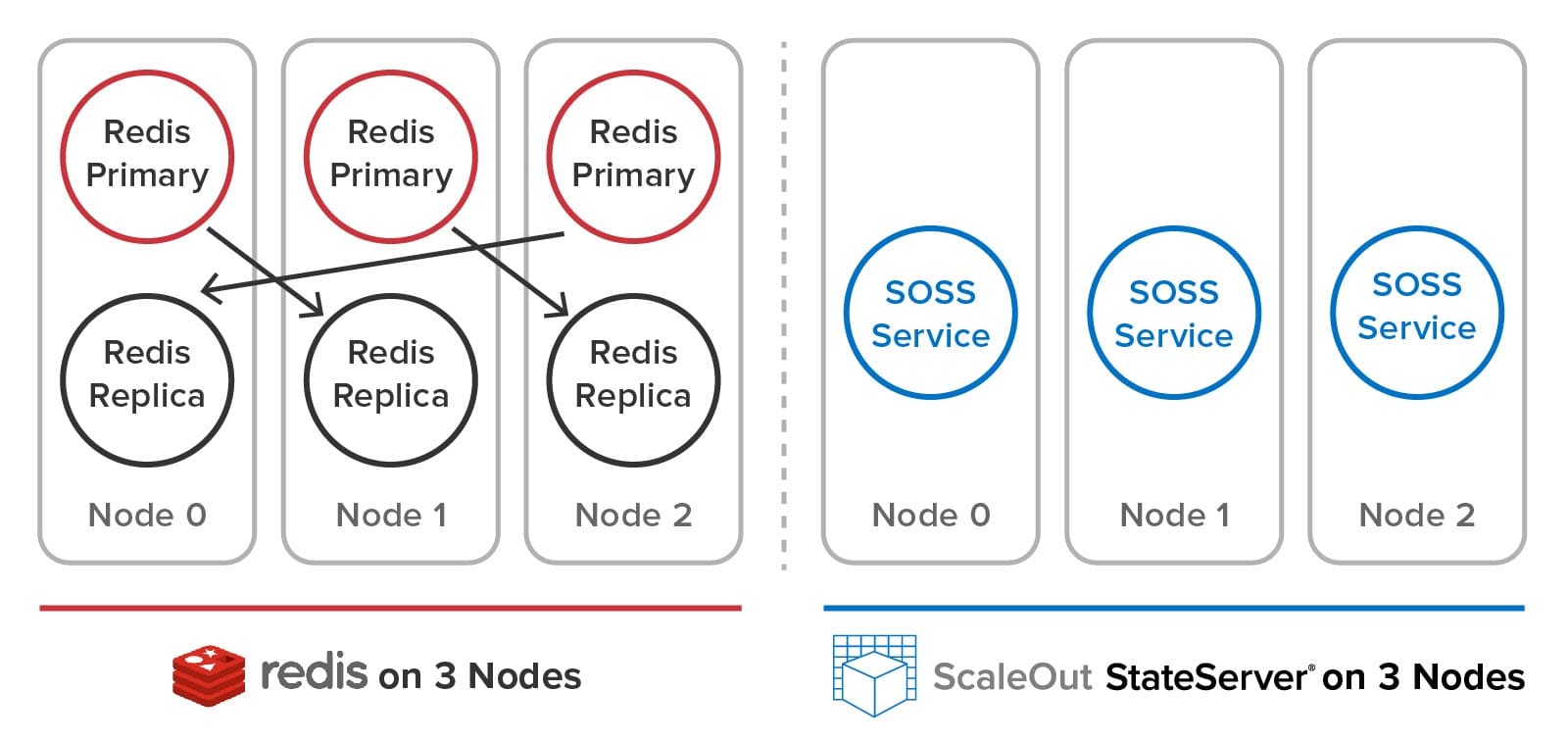
The differences in design goals of the two technologies have led to very different impacts on users. To maximize ease of use, SOSS automatically creates and manages hash slots for the user, including primaries and replicas. Using a built-in load-balancer, each service internally manages a subset of both primary and replica hash slots, as illustrated below. Users just create a single SOSS service process on every node, and these service processes discover each other and distribute the hash slots among themselves to balance the workload. They also automatically handle all aspects of recovery after a node fails.
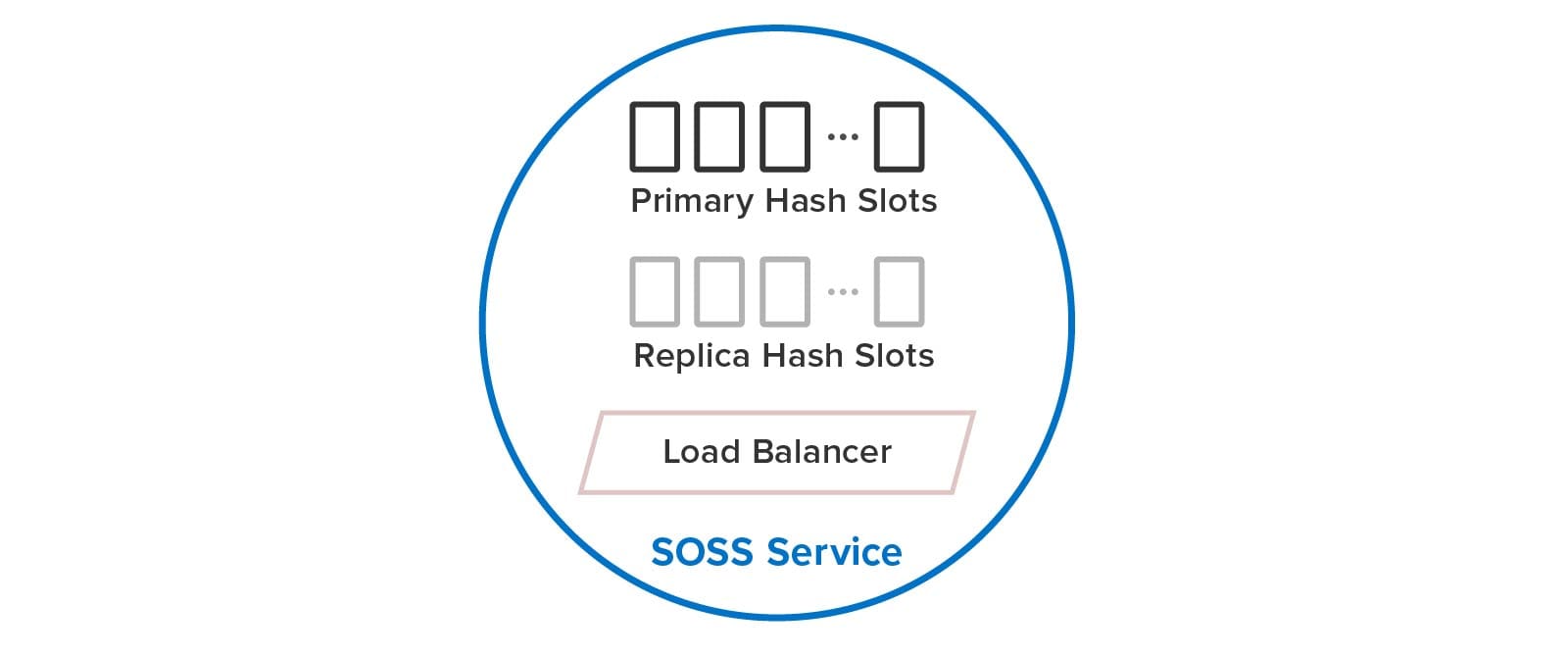
In contrast, Redis users create separate service processes on each node for primary and replica hash slots and must manually distribute the hash slots among the primaries. (Unlike SOSS, a 1-node or 2-node Redis cluster is not allowed.) As we will see below, users must perform a complex set of manual actions when adding and removing nodes and to heal and rebalance the cluster after a node fails. The following diagram illustrates the difference between Redis and SOSS in the user’s view of the cluster:
Adding a Node to the Cluster Using SOSS
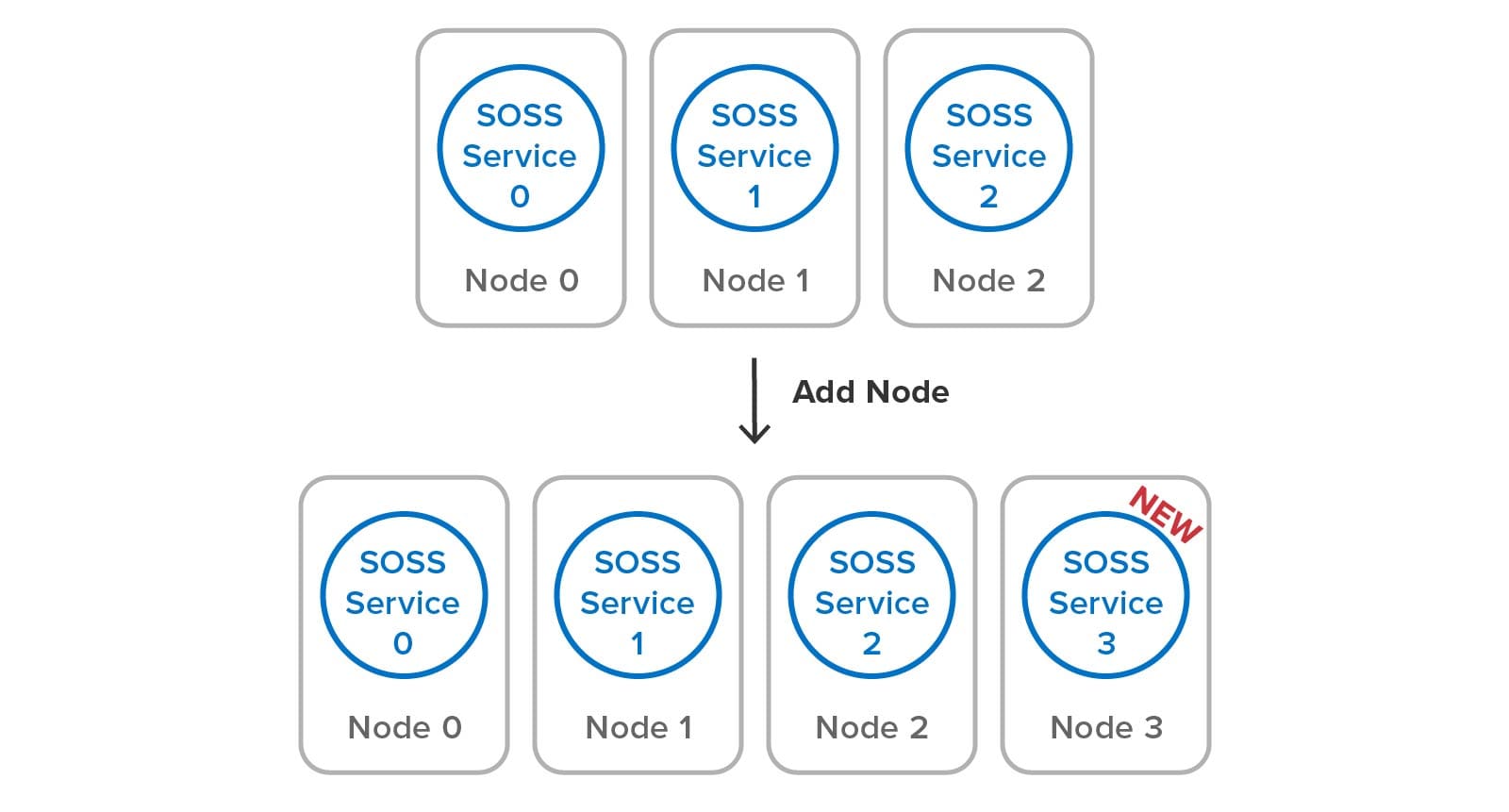
To illustrate how SOSS’s built-in mechanisms for managing hash slots, load-balancing, failure detection, and self-healing simplify cluster management, let’s look at the steps needed to add a node to the cluster. When using SOSS, the user just installs the service on a new node and clicks a button in the management console to join the cluster. Using multicast discovery (or optional host list if multicast is not available), the service process automatically receives primary and replica hash slots and starts handling its portion of the workload. The following diagram shows the addition of a fourth node to a cluster:
Adding a Node to the Cluster Using Redis
Because Redis requires the user to manage the creation of primary and replica service processes (sometimes called shards) and the management of hash slots, many more steps must be performed to add a node to the cluster. To accomplish this, the user runs administrative commands that create the new processes, connect the primaries and replicas, move the replicas as necessary, and reallocate the hash slots among the nodes. The required configuration changes are illustrated below:
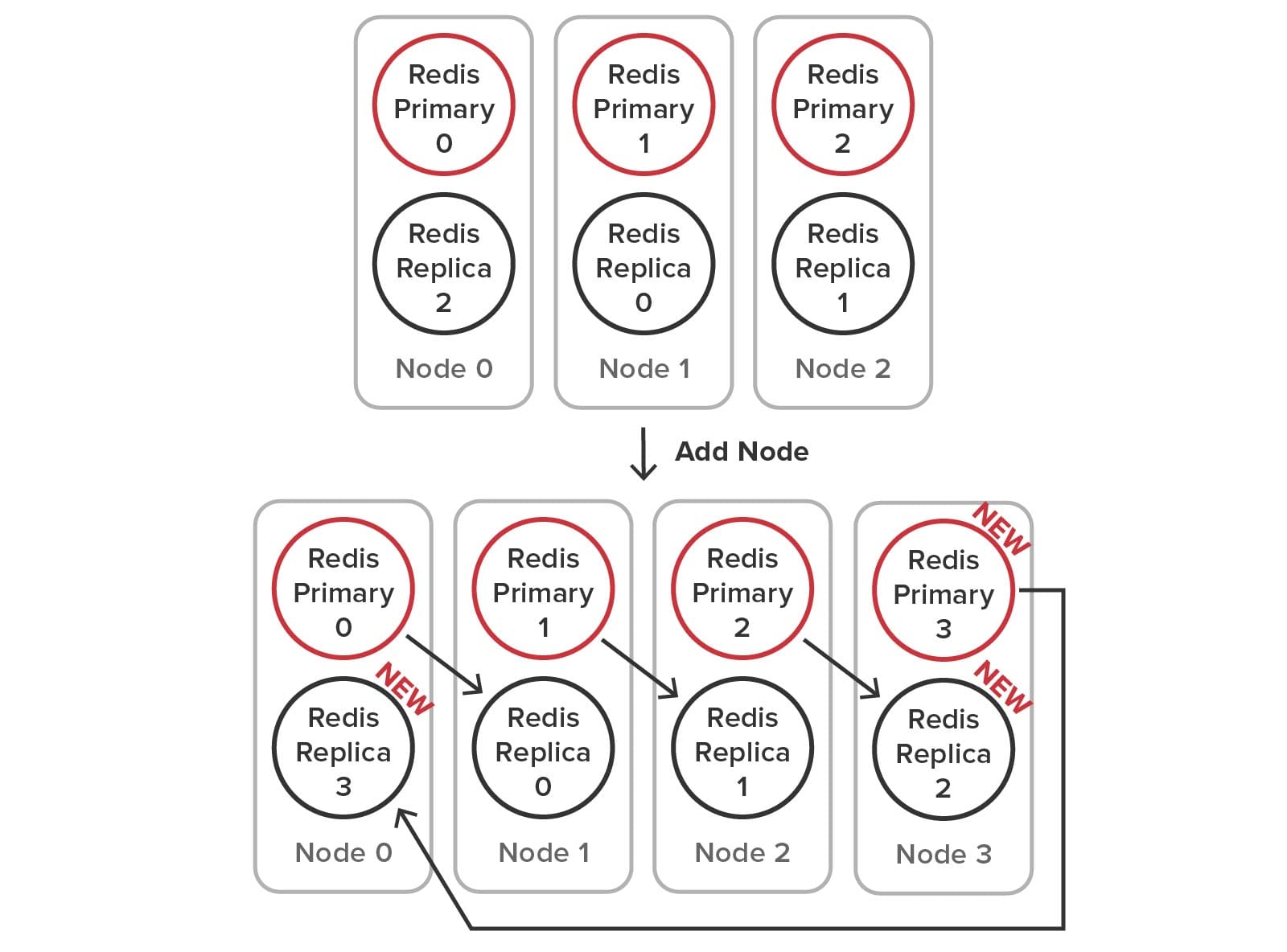
Here is an example of administrative steps required to make the configuration changes (using node 0’s IP and port as the bootstrap address for the new node):
// Start up a new replica redis-server instance on node 3 for primary 2:
redis-cli --cluster add-node host3Ip:replicaPort node0Ip:node0Port --cluster-slave
--cluster-master-id primary2NodeID
// Start up a new primary redis-server instance on node 3:
redis-cli --cluster add-node host3Ip:primaryPort existingIp:existingPort
// Connect to replica 2 on node 0 and modify it to replicate primary 3:
redis-cli -h replica2Ip -p -replica2Port > cluster replicate primary3NodeID
// Reshard the cluster by interactively moving hash slots from existing nodes to node 3:
redis-cli --cluster reshard existingIp:existingPort
> How many slots to move? 4096 //16384 / 4 = 4096
> What node to move slots to? primary3NodeID // (primary3NodeID returned by previous command)
> What nodes to move slots from? all
This process is complex, and it becomes more difficult to keep track of the distribution of hash slots with larger cluster memberships. Removing a node has comparable complexity.
Recovering After a Node Fails (SOSS and Redis)
SOSS’s service processes automatically detect and recover from the loss of a node. They use built-in, scalable, peer-to-peer heart-beating to detect missing node(s) and create a new, coherent cluster membership. Next, they promote replica hash slots to primaries on the surviving nodes, create new replicas for self-healing, and rebalance the workload across the nodes.
Redis does not implement a coherent cluster membership and does not provide automatic self-healing and recovery. Each Redis node sends heartbeat messages to random other nodes to detect possible failures, and the cluster uses a gossip mechanism to declare that a node has failed. After that, its replica on a different node promotes itself to a primary so that the hash slots remain available, but Redis does not self-heal by creating a new replica for the hash slots. Also, it does not automatically redistribute the hash slots across the nodes to rebalance the workload. These tasks are left to the system administrator, who needs to sort out the needed configuration changes and implement them to restore a fully redundant, balanced cluster.
Performance Comparison
The different design choices between SOSS and Redis also lead to semantic and performance differences. To maximize ease of use for application developers, SOSS maintains all stored data with full consistency (to be more precise, sequential consistency), ensuring that it only serves the latest updates and never loses data after the failure of a single server (or two servers if multiple replicas are used). This design choice targets enterprise applications that need to ensure that the distributed cache always returns the correct data. To implement data replication across multiple replicas with the highest possible performance, SOSS uses a patented quorum algorithm.
In contrast, Redis employs an eventual consistency model with asynchronous replication. In general, this choice enables higher throughput because updates do not have to wait for replication to complete before responding to the user. It also enables potentially higher read throughput by serving reads from replicas even if they are not guaranteed to serve the latest updates.
Given these two design choices, it’s valuable to compare the throughput of the two distributed caches as nodes are added and the workload is simultaneously increased, as illustrated below. This technique evaluates how well the caches can scale their throughput by adding nodes to handle increasing workload; linear throughput scaling ensures consistently fast response times. (For a discussion of throughput scaling in distributed systems, see Gustafson’s Law.).
To perform an apples-to-apples throughput comparison of Redis 6.2 and SOSS 5.10, SOSS was configured to use eventual consistency (“EC”) when updating replicas. The performance of SOSS with full consistency (“FC”) was also measured. Tests were run for 3, 4, and 6 node clusters in AWS on m5.xlarge instances with 4 cores@2.5 Ghz, and 16GB RAM. The clients ran read/update pairs on 100K objects of sizes 2KB and 20KB to represent a typical web workload with a 1:1 read/update ratio. The results are as follows:
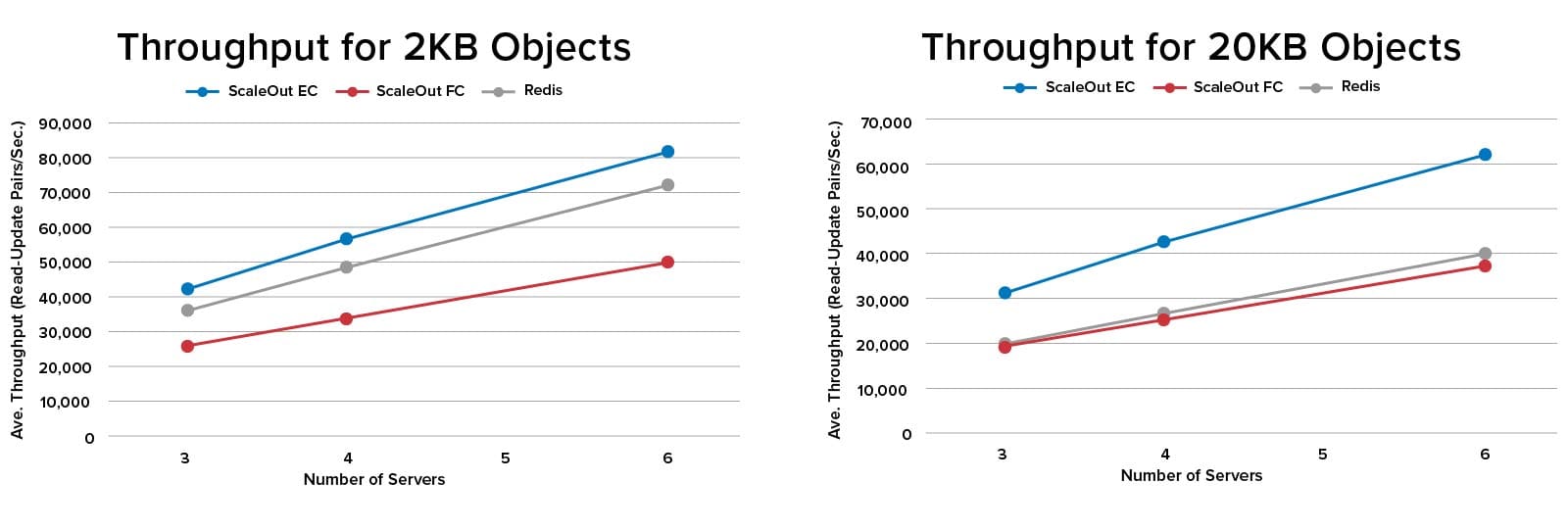
SOSS provided consistently higher throughput than Redis when eventual consistency was used to perform updates (the blue and gray lines in the charts). Running SOSS with full consistency (the red lines) resulted in lower throughput, as expected, since updates have to be committed at the replica before responding to the client instead of being performed asynchronously. However, both Redis and SOSS with full consistency delivered close to the same throughput for 20KB objects. This may be due to benefits of SOSS’s client-side caching, which eliminated unnecessary data transfers during reads.
Summing Up
Our comparison of SOSS and Redis shows the benefits of ScaleOut’s integrated clustering architecture. A key design goal for SOSS was to simplify the user’s workload by providing a unified, location-transparent data cache with built-in, fully automatic load-balancing and high availability. By hiding the inner workings of hash slots, heart-beating, replica placement, load-balancing, and self-healing, the application developer and systems administrator can focus on simply using the distributed cache instead of configuring its implementation. In our view, Redis’s approach of exposing these complex mechanisms to the user significantly steepens the learning curve and increases the user’s workload.
It might come as a surprise to learn that in the above benchmark testing, SOSS maintained a consistent performance advantage. We attribute this to ScaleOut’s approach of designing an integrated cluster architecture from the outset instead of adding clustering to a single server data store, as Redis did. This approach enabled design freedom at every step to eliminate distributed bottlenecks, and it led to extensive use of multithreading and internal data sharding within each service process to extract maximum performance from multi-core servers.
Lastly, SOSS demonstrates that the CAP theorem doesn’t really prevent the use of full consistency when building a scalable, distributed cache. For many enterprise applications, which demand data integrity at all times, this may be the better choice.
Learn more about how ScaleOut StateServer compares to Redis.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Redis vs ScaleOut: What You Need to Know appeared first on ScaleOut Software.
]]>The post ScaleOut Software Announces the Availability of ScaleOut GeoServer® Pro appeared first on ScaleOut Software.
]]>BELLEVUE, Wash – November 17, 2020 – ScaleOut Software today announced ScaleOut GeoServer® Pro, a new software product release that integrates site-to-site data replication with fully coherent data access for its battle-tested ScaleOut StateServer® in-memory data grid (IMDG) and distributed cache. This release extends the company’s ScaleOut GeoServer® DR product, which provides asynchronous, site-to-site data replication to protect against site-wide failures and currently is in production use.
For more than fifteen years, ScaleOut StateServer has set the standard for high performance reliability and industry-leading ease of use at hundreds of enterprise sites around the world. The product stores fast-changing data in a wide variety of applications, including ecommerce, financial services, online learning, airline reservations, gaming and much more.
“With the release of ScaleOut GeoServer Pro, we are excited to offer our customers breakthrough capabilities for multi-site storage of their fast-changing data,” said Dr. William L. Bain, founder and CEO of ScaleOut Software. “Now they can take advantage of our industry-leading technology that replicates data across sites to protect against data center failures while making fully coordinated use of the sites.”
By harnessing ScaleOut GeoServer Pro, users can now take in-memory data storage and distributed caching to the next level with an integrated solution for disaster recovery and synchronized data access across multiple sites. This technology enables applications to both protect against site-wide failures and to maintain a consistent view of data stored at all data centers.
Key ScaleOut GeoServer Pro Benefits:
ScaleOut GeoServer Pro enables organizations to store, access and protect fast-changing data at multiple sites, while maintaining a consistent view of the data at all times. The technology ensures that critical data is always accessible and synchronized across locations.
- Transparent Replication Across Data Centers: Applications can automatically replicate all stored data across multiple data centers for continuous availability in case a data center fails. This includes replicating in-memory data across different cloud regions, while automatically coordinating access to data stored at these sites.
- Integrated, Synchronized Data Access: ScaleOut GeoServer Pro introduces optional, synchronized access to replicated data across multiple data centers. This enables applications that distribute workloads across data centers to maintain a straightforward, unified view of stored data. For example, web applications which use a global load balancer to share user data held in two data centers can now use both data centers in an “active-active” configuration.
- Automatic Recovery from WAN Failures: In the event of a WAN failure between data centers, applications can independently access data at each data center. When WAN connectivity is re-established, ScaleOut GeoServer Pro automatically resolves inconsistencies in stored data due to duplicate updates during the WAN outage known as a “split-brain” condition.
- Maximize Application Performance: To maximize overall performance, ScaleOut GeoServer Pro’s caches offer flexible coherency policies so that applications can select the appropriate combination of coherency and access latency according to data usage. This avoids unnecessary WAN data usage and associated delays.
Additional Resources:
For more information about ScaleOut GeoServer Pro, please visit:
- ScaleOut GeoServer Pro announcement blog post
- ScaleOut GeoServer Pro product page
About ScaleOut Software
Founded in 2003, ScaleOut Software develops leading-edge software that delivers scalable, highly available, in-memory computing and streaming analytics technologies to a wide range of industries. ScaleOut Software’s in-memory computing platform enables operational intelligence by storing, updating, and analyzing fast-changing, live data so that businesses can capture perishable opportunities before the moment is lost. It has offices in Bellevue, Washington and Beaverton, Oregon.
For more information, please visit www.scaleoutsoftware.com and follow @scaleout_inc
###
Contact:
RH Strategic for ScaleOut Software
The post ScaleOut Software Announces the Availability of ScaleOut GeoServer® Pro appeared first on ScaleOut Software.
]]>The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>
Web applications, such as ecommerce sites and financial services, often need to replicate fast-changing, in-memory data across multiple data centers or cloud regions. As part of an overall strategy for disaster recovery, cross-site data replication ensures that mission-critical data is continuously available, even if one site goes offline.
Many applications need to use two (and sometimes more) sites in an “active-active” manner, distributing the workload across the sites. Here are some real-world applications we have seen. Ecommerce applications need to maintain shopping carts at multiple sites and distribute the workload from their shoppers with a global load-balancer. Cell phone providers need to keep their lists of available mobile numbers consistent across sites as individual stores allocate them. Conference-management companies need to keep attendee lists and schedules consistent at conference sites and their central data center.
Let’s take a closer look at an ecommerce site using a global load-balancer to distribute incoming web requests to multiple sites. This approach lets the web application take advantage of the processing power at multiple sites during normal operations. However, it creates the challenge of coordinating access to in-memory objects which are replicated across two or more sites. This can add substantial complexity if handled by the application.
Here’s an example of an ecommerce site using a global load-balancer to distribute incoming web requests across two sites, each of which hosts shopping carts within an in-memory data grid (also called a distributed cache), such as ScaleOut StateServer®. A web shopper might select a pair of shoes and place them in the shopping cart followed by selecting a tennis racket. As shown in the following diagram, the global load-balancer sends the first request to site 1 and the second request to site 2 in this example:
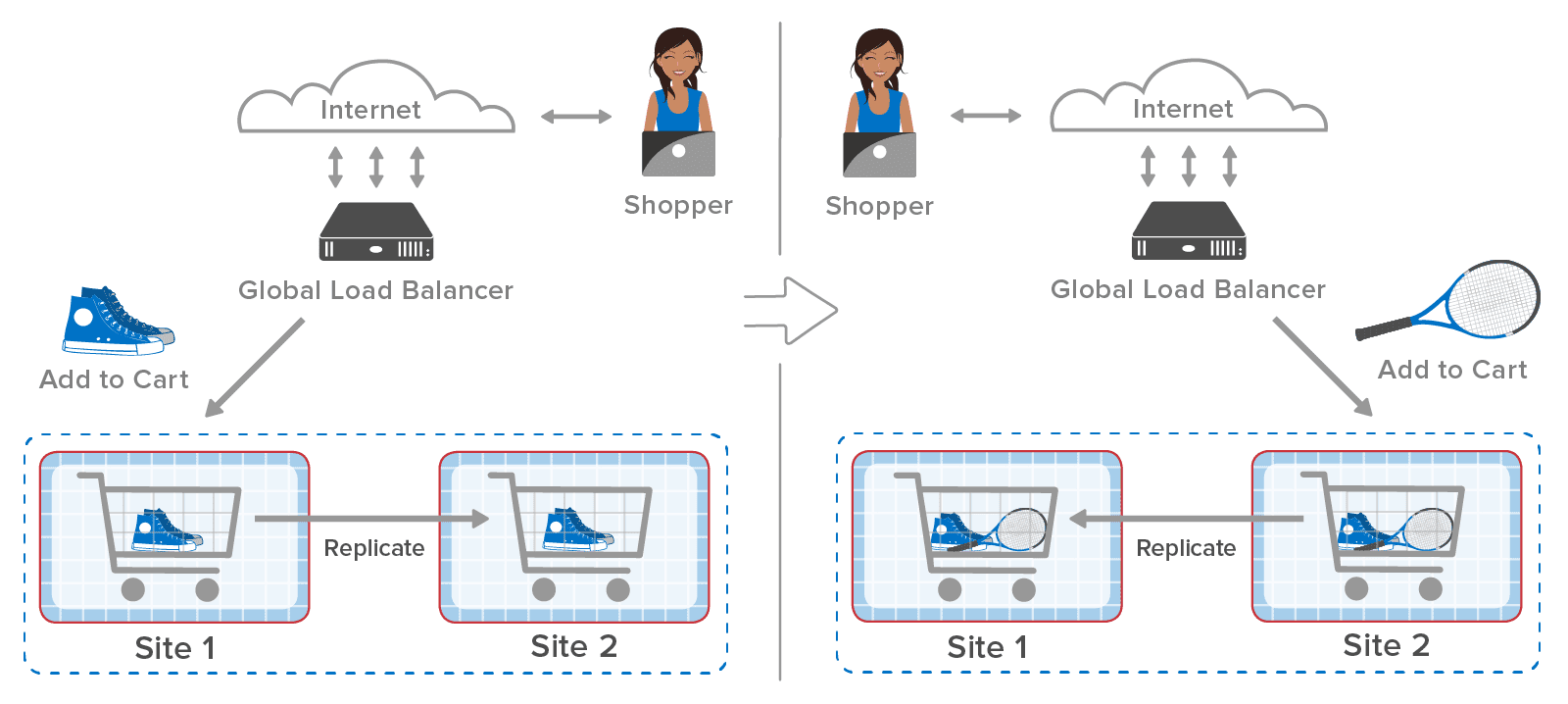
After the first request completes, the in-memory data grid at site 1 replicates the cart to site 2. The global load-balancer then sends the second request to site 2, which adds the tennis racket to the cart. Finally, site 2 replicates the changes back to site 1 so that both sites have the latest copy of the shopping cart.
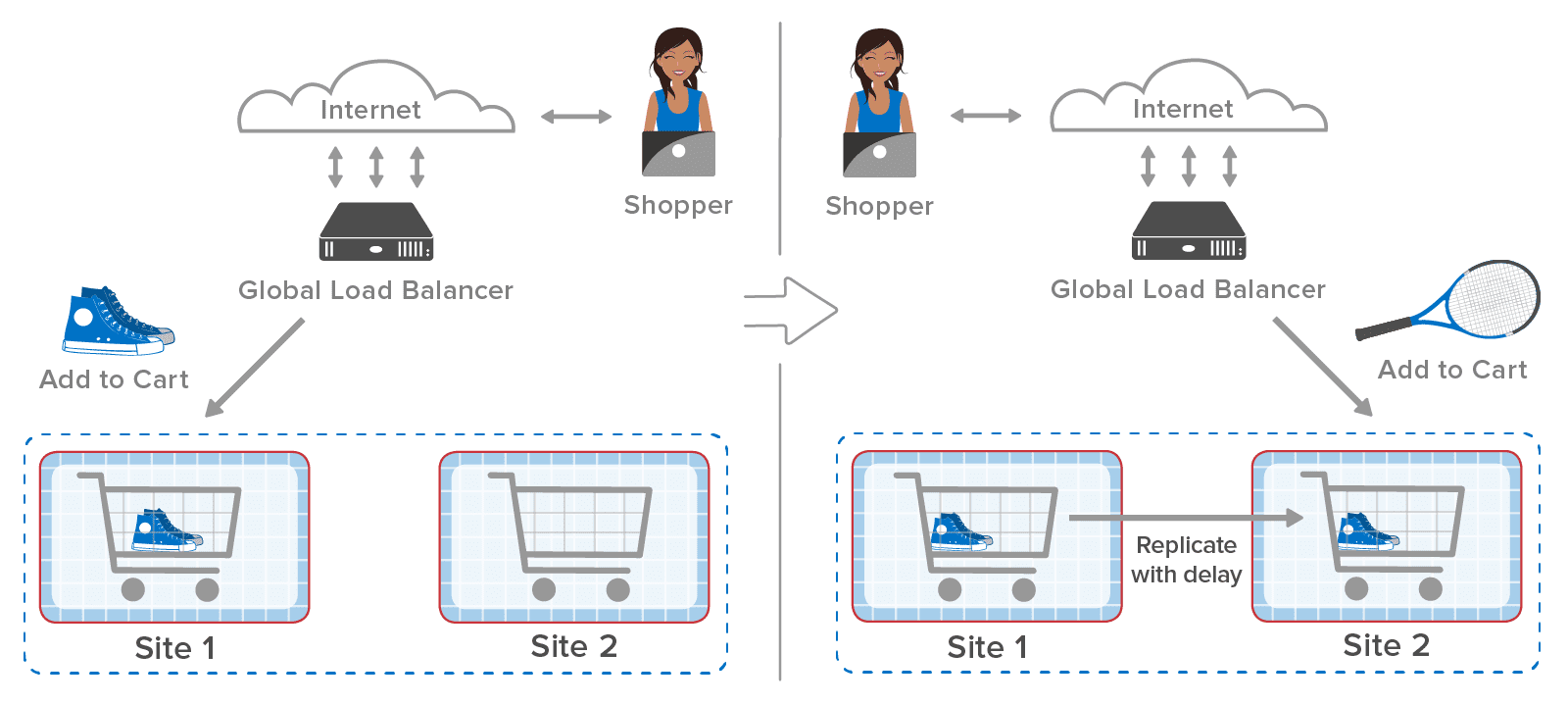
What happens if replication from site 1 to site 2 is slightly delayed? After site 2 puts the tennis racket in the cart, the incoming replicated update arrives and overwrites the cart. This causes both sites to lose the update at site 2, and the shopper will undoubtedly be annoyed to find that the tennis racket is missing from the cart:
The solution to this problem is to have the web applications at both sites synchronize updates to the shopping carts. This ensures that only one site at a time updates the shopping cart and that each site always sees the latest version of the in-memory object. Using ScaleOut GeoServer Pro, applications can use standard object-locking APIs for this purpose, just as they would to coordinate object access within a single in-memory data grid:
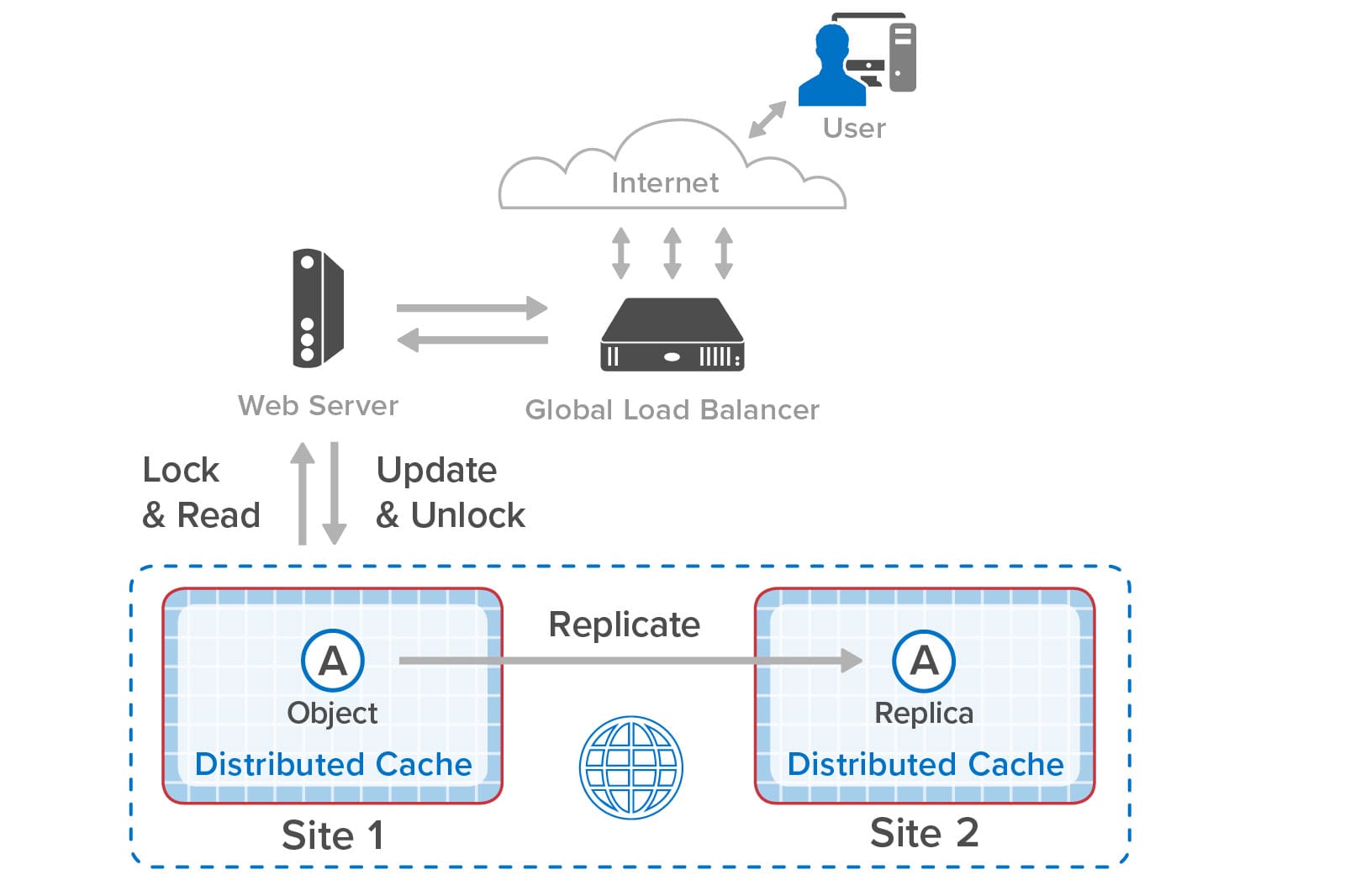
After the web application on site 1 updates and unlocks object A (the shopping cart in our example), site 1 replicates the update to site 2. When the global load-balancer sends the next request to site 2, the web application on that site 2 also locks and reads the object, updates it, and then unlocks it:
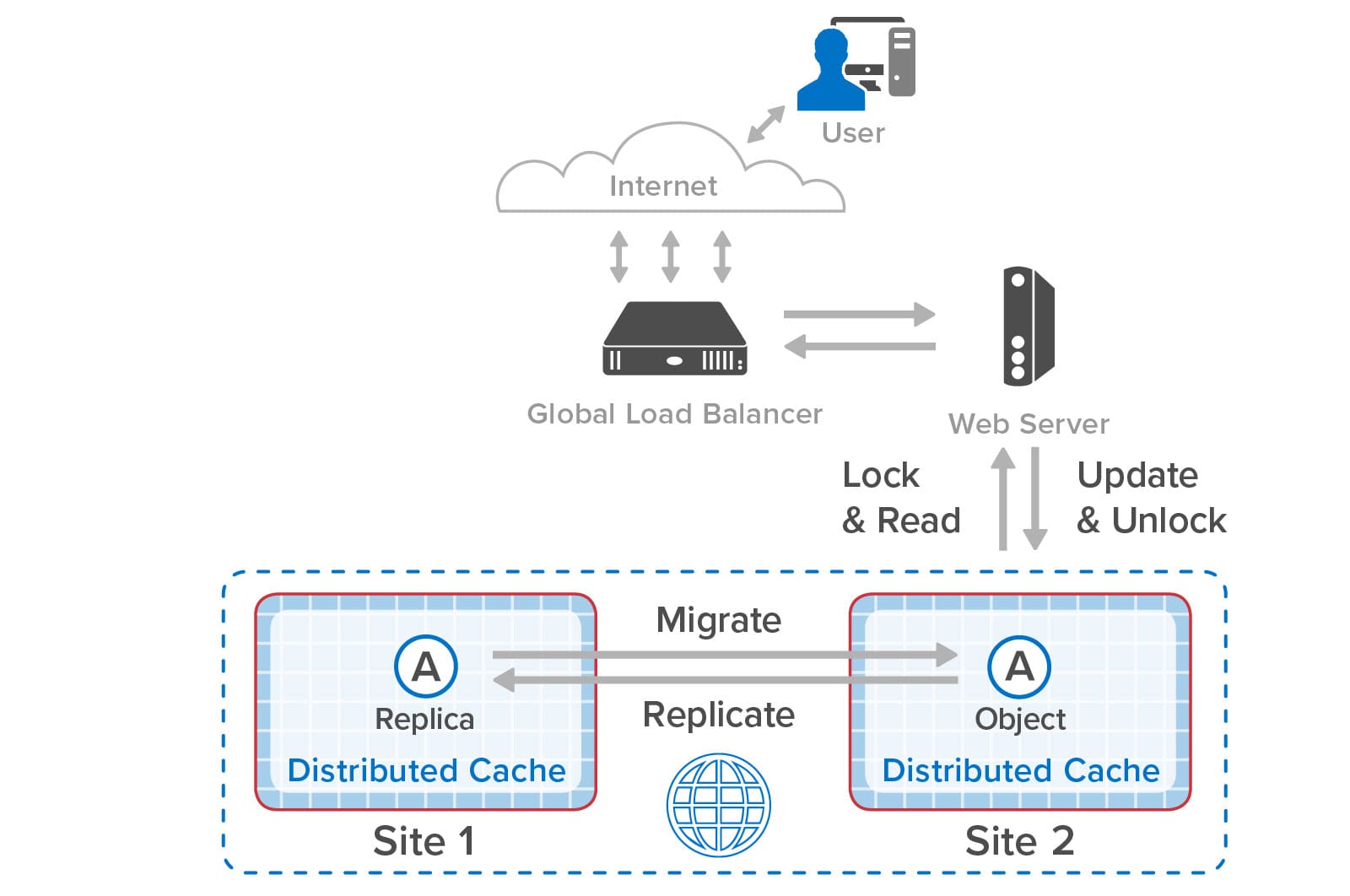
When the object is locked on site 2, ScaleOut GeoServer Pro makes sure that the application sees the latest version of the object. It does so by migrating ownership of the object to site 2 and checking that it has the latest version. Although this requires a round trip to site 1, once a site gains ownership, all further accesses are local until the other site again attempts to lock the object and request ownership. If the global load-balancer avoids ping-ponging between sites with every web request, the latency to lock an object remains low.
Should the wide area network (WAN) connecting the two sites fail, or if the remote site goes offline, the two sites can operate independently; this is called “split brain” mode in distributed systems. They detect the WAN failure and automatically promote local replica objects as needed to gain ownership when requesting a lock. This enables uninterrupted operations that make use of object replicas held at each site. By combining object replication with synchronized access, applications enjoy the full benefits of synchronized object access across sites during normal operations and uninterrupted access during WAN or site outages:
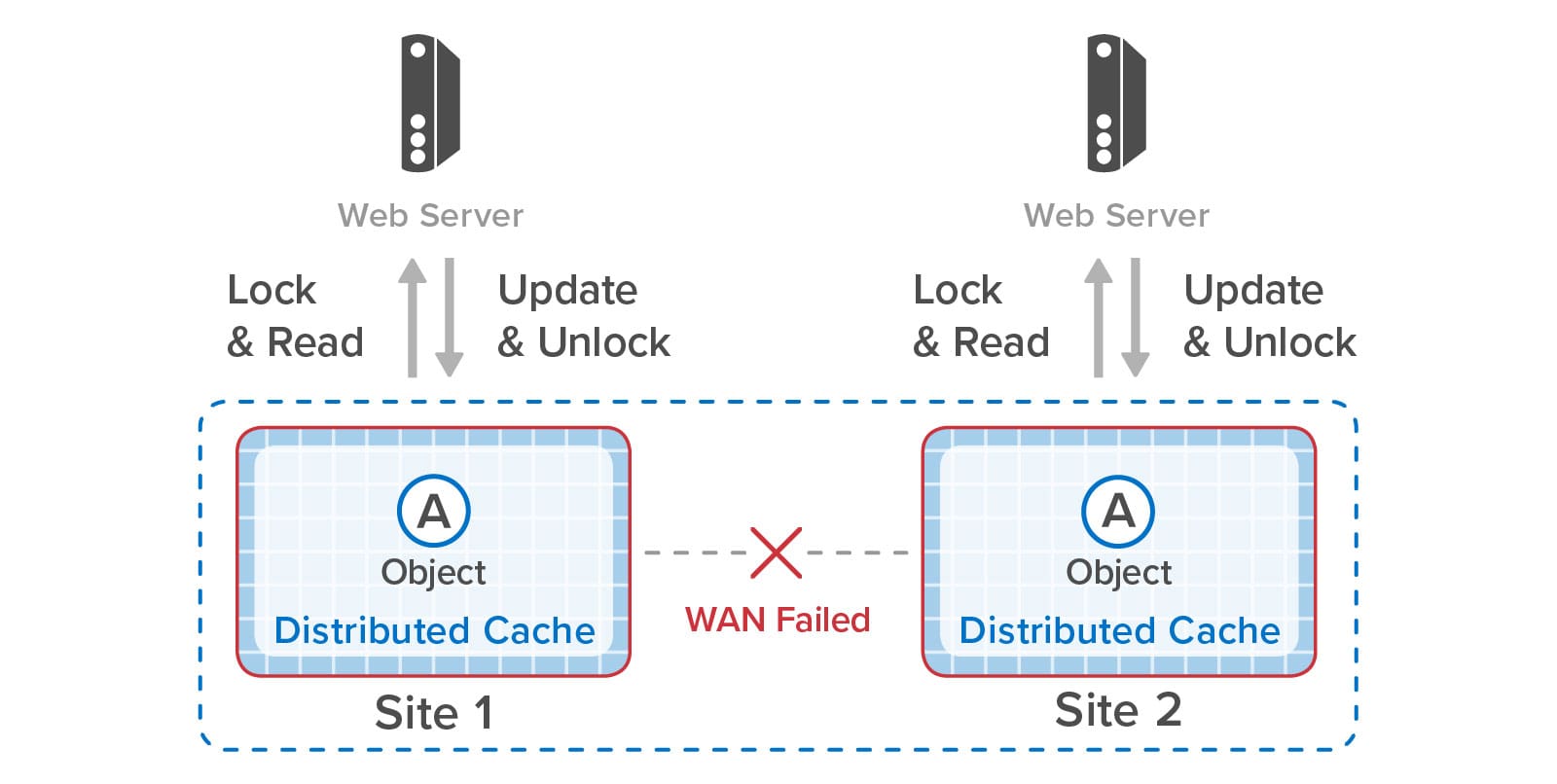
A key challenge created by split-brain mode is how to restore normal operations after an outage has been corrected. For example, the following diagram shows the two sites in our shopping example operating independently during a WAN outage that occurs between the two web requests. Site 1 adds the shoes to its shopping cart but is unable to replicate that update to site 2. The web application on site 2 then places the tennis racket in its shopping cart:
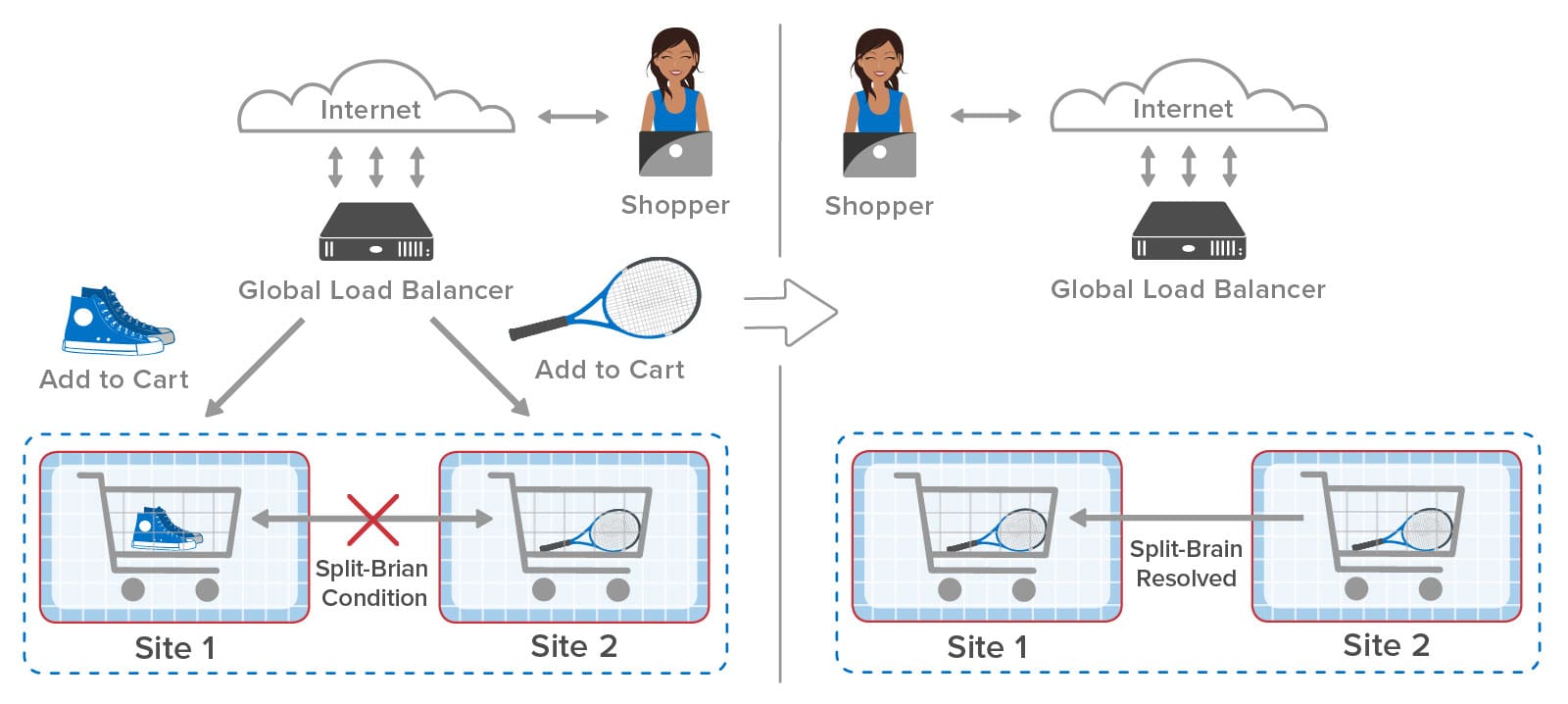
After the WAN is restored, the two sites have to resolve the differences in the contents of their copies of stored objects. Unless the application uses special, conflict-free data types that can be merged (and this is rare for most applications), a heuristic needs to be used to resolve conflicts. ScaleOut GeoServer Pro automatically resolves conflicts for each pair of object copies by selecting the copy with the latest update time or randomly picking one of the copies if the update times are the same. So in this case, both sites are updated with the version of the shopping cart holding the tennis racket. (This will be another source of annoyance for our shopper, but at least the ecommerce site survived a WAN outage without interruption.)
ScaleOut GeoServer Pro resolves split-brain conflicts as it detects them when updates are performed and then are successfully replicated across the WAN. It also has to resolve the fact that both sites now think they own the same object, and it handles this by randomly picking a site to retain ownership. As the two sites attempt to lock and read the object, ownership will then automatically migrate to the site where it’s needed.
One more key benefit of ScaleOut GeoServer Pro is that it lets applications efficiently access objects that have slowly changing contents (such as product descriptions, schedules, and portfolio lists) without making repeated WAN accesses. Sites that are configured for bi-directional replication have immediate access to replicas when just reading but not updating remote objects. Other sites can be configured to maintain local copies of remote objects (called “proxies”) that can periodically poll for updates using a configurable timeout. This minimizes WAN accesses while allowing applications to track changes in objects stored at remote sites.
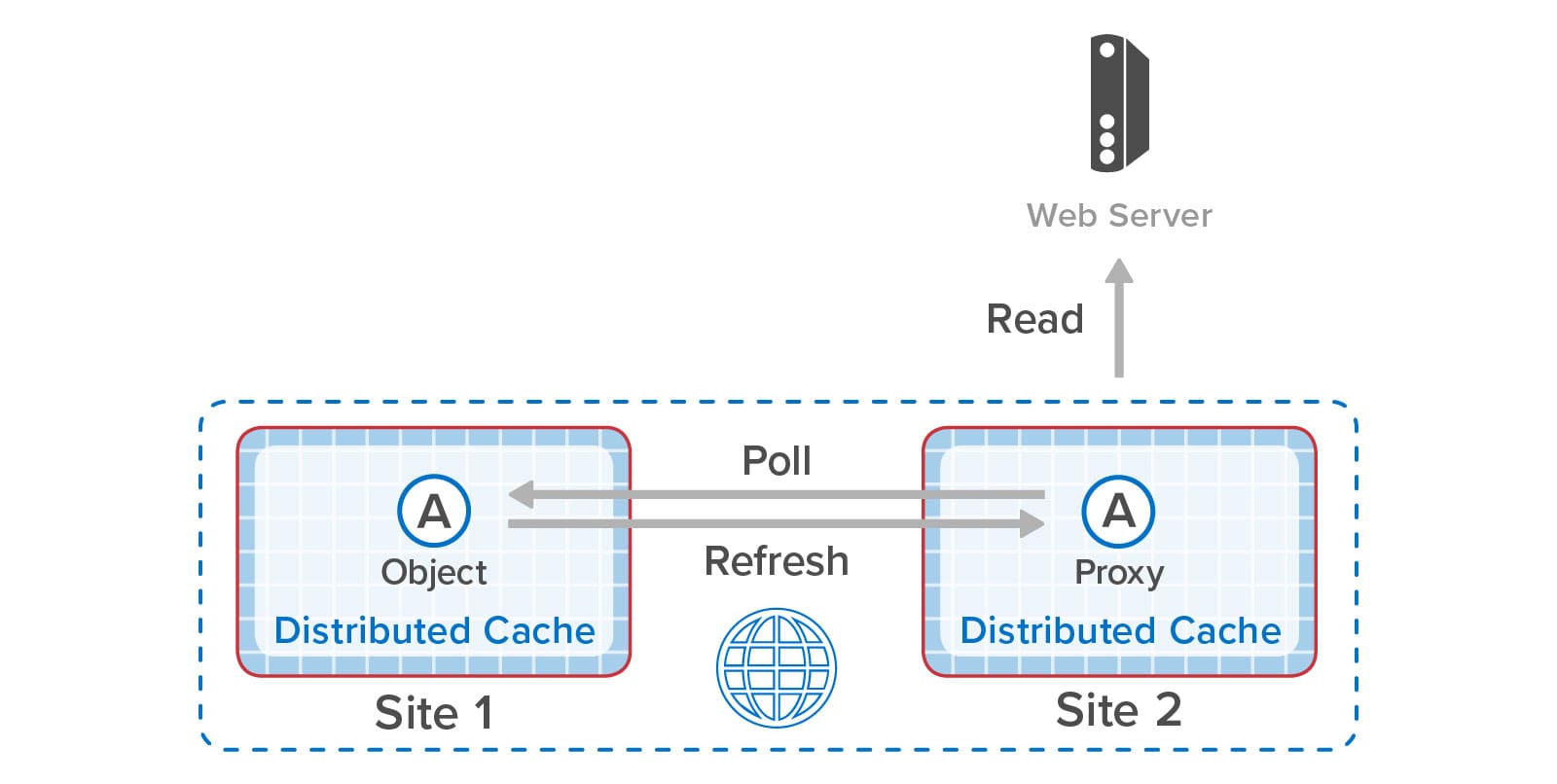
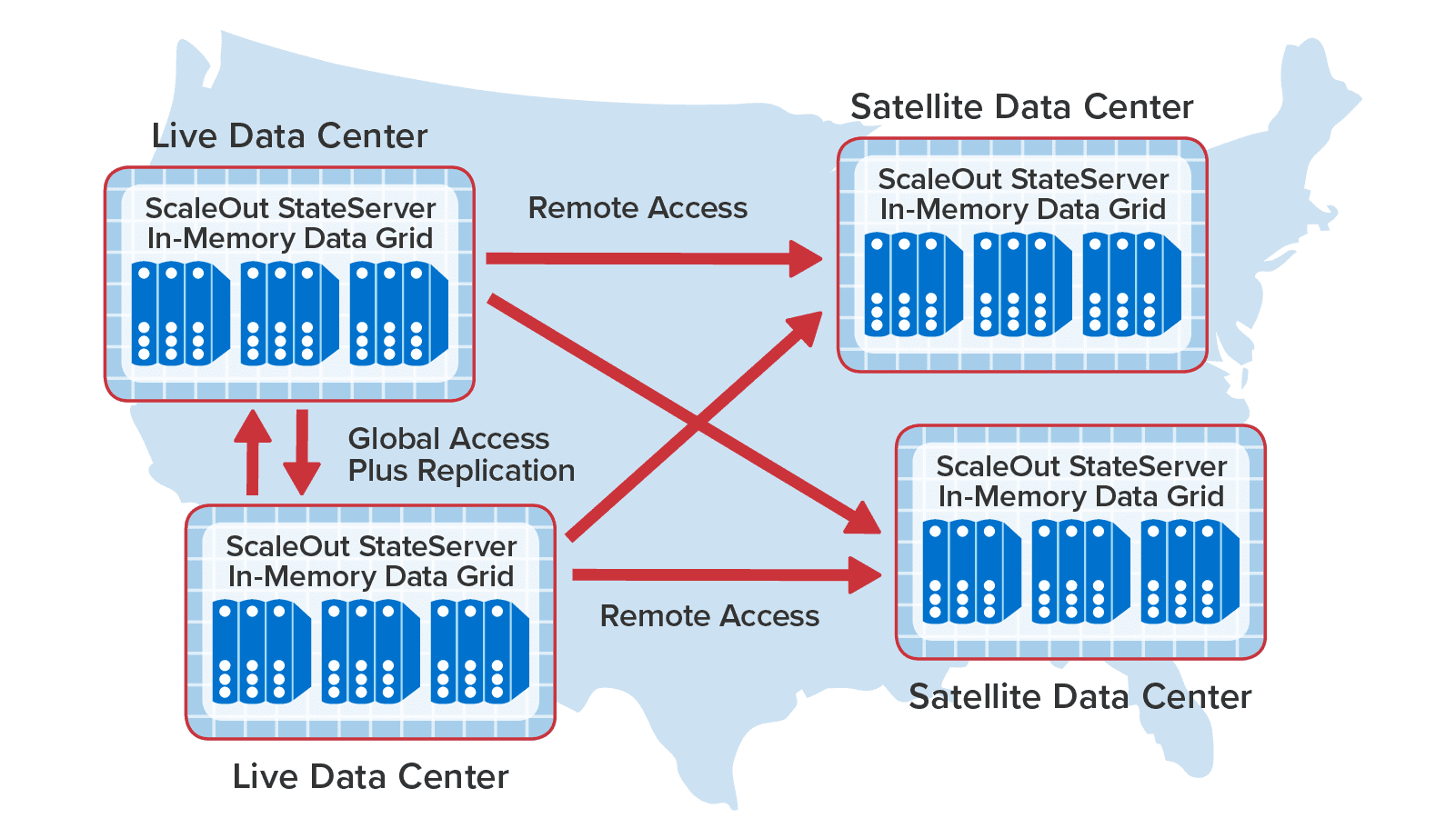
To illustrate how all of these features can work together, the following diagram shows two sites on the west coast of the U.S. configured for bi-directional replication and synchronized access along with additional “satellite” sites in other states that are periodically polling to read data held in the “live” data centers:
With its advanced capabilities for combining data replication with synchronized access, ScaleOut GeoServer Pro takes a leadership position among commercial in-memory data grids by enabling applications to seamlessly access and update objects replicated across data centers. This solves a long-standing challenge for applications that actively maintain mission-critical data at multiple sites and further extends the power of in-memory data grids to manage fast-changing business data.
The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>The post Founder & CEO William Bain Discusses Real-Time Digital Twins with TechStrong TV appeared first on ScaleOut Software.
]]>Watch the video here.

The post Founder & CEO William Bain Discusses Real-Time Digital Twins with TechStrong TV appeared first on ScaleOut Software.
]]>The post The Power of Integrated Analytics Within an IMDG appeared first on ScaleOut Software.
]]>
In-Memory Data Grids for Fast-Changing Data
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. Typical uses include storing session-state and ecommerce shopping carts, product descriptions, airline reservations, financial portfolios, news stories, online learning data, and many others.
From its inception, the design philosophy behind ScaleOut StateServer has been to simultaneously maximize both performance and ease of use. Because IMDGs have complex internal mechanisms, they need to automate them as much as possible so that the developer can just focus on application concerns and not on the inner workings of the IMDG. For this reason, the product incorporates features such as automatic discovery of servers, transparent load-balancing when servers are added to the cluster or removed, automatic data replication for high availability with transparent placement of replicas, quorum-based updating of replicas to ensure consistency, integrated client libraries, and coherent client-side caching. The net effect is that applications maintain a straightforward view of the IMDG as a unified key/value store for serialized application objects.
The Challenges with Parallel Queries
Although IMDGs are optimized for key-based access, applications often need to retrieve groups of objects with matching properties. For example, if an application is storing shopping carts, it might be useful to find all shopping carts with a total value that exceeds a specified threshold so that these shoppers can be given special attention. To this end, ScaleOut StateServer incorporates a property-based, distributed query API that returns a collection of matching objects. To simplify development for .NET applications, it uses Microsoft’s language integrated query (LINQ) to specify queries. (Java applications use a similar mechanism.)
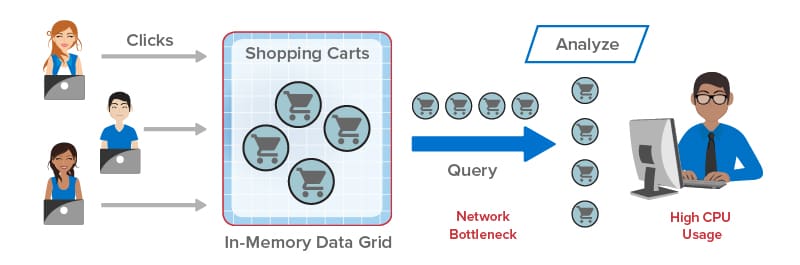
Queries in an IMDG can create interesting performance challenges. Because IMDGs have highly scalable storage capacity, they can easily return large numbers of matching objects to the client application, and this leads to network bottlenecks transferring large amounts of data from the IMDG back to the client. Once all objects are delivered, the client is then faced with the task of analyzing potentially huge numbers of objects. This can saturate the client’s CPU and delay responses, as illustrated in the following diagram:
ScaleOut StateServer Pro: Integrated Data Analytics
To address these challenges, ScaleOut Software has introduced ScaleOut StateServer Pro, an advanced version of ScaleOut StateServer that integrates data analytics within the IMDG. Instead of querying objects from the IMDG and analyzing them in the client, applications can now simply run this analysis within the IMDG itself using APIs available in ScaleOut StateServer Pro. Because all the work is performed with the IMDG, this has the two-fold advantage of offloading both the network and the client’s CPU. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
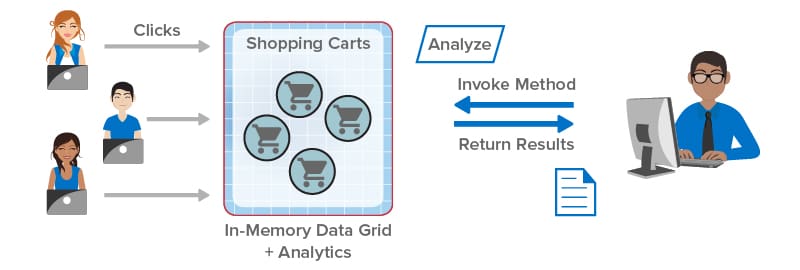
Take a look at how integrated data analytics can help client applications. In the following illustration, the client library sends the application’s analysis method (“Analyze”) to the IMDG for execution in parallel on all shopping carts selected by a query. The results are combined within the IMDG and returned to the application:
Keeping with the design philosophy of maximizing both performance and ease of use, ScaleOut StateServer Pro lets developers easily construct data analytics by specifying an object-oriented method that analyzes each matching object selected by a query and a second method for combining the results. In .NET applications, this data-parallel execution structure can be described using a distributed version of Microsoft’s popular Parallel.ForEach API, which ScaleOut StateServer Pro integrates with LINQ query. Application code is automatically shipped by the client library to the IMDG for execution and runs fully in parallel across all servers for maximum performance.
Consider the above example of querying shopping carts exceeding a threshold value. Suppose the application’s goal is to periodically analyze high value shopping carts to make upsell offers based on the contents of each cart. Instead of querying the IMDG and returning thousands of shopping carts to the client, the application can implement a method which analyzes these carts within the IMDG to determine which carts should receive upsell offers (and possibly determine which upsell offers to make). This analysis runs in parallel within the IMDG and then returns its results to the client for further action. This dramatically reduces the workload on the network and client, and it ensures consistently high performance.
Summing Up: Extracting Maximum Value from an IMDG
Since their inception, IMDGs have to a large extent been underutilized by viewing them as passive key/value stores. Because they are actually designed as a data-parallel execution platform, they can do much more than just store and serve memory-hosted, live data. They also can perform analysis quickly and efficiently — where the data lives.
Taking full advantage of this powerful capability requires just a shift in thinking about where application work should be performed. In many cases, it’s a much better choice to analyze data within the IMDG instead of transferring it to the client for analysis. ScaleOut StateServer Pro makes it easy to do just that, and it delivers fast, scalable performance. Now developers can finally extract full value from their IMDGs.
The post The Power of Integrated Analytics Within an IMDG appeared first on ScaleOut Software.
]]>The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times. For more than two decades, the answer to this challenge has proven to be a technology called in-memory computing.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers. Assuming bottlenecks are avoided, this enables transparent throughput scaling that matches an increase in workload, which in turn keeps response times low for users. It can also take advantage of the elastic computing resources available in cloud infrastructures to quickly and cost-effectively scale throughput to meet changes in demand.
Harnessing the power of in-memory computing requires software platforms that can make in-memory computing’s scalability readily available to applications using APIs while hiding the complexity of its implementation. Emerging in the early 2000s, the first such platforms provided distributed caching on clustered servers with straightforward APIs for storing and retrieving in-memory objects. When first introduced, distributed caching offered a breakthrough for applications by storing fast-changing data in memory on a server cluster for consistently fast response times, while simultaneously offloading database servers that would otherwise become bottlenecked. For example, ecommerce applications adopted distributed caching to store session-state, shopping carts, product descriptions, and other data that shoppers need to be able to access quickly.
Software platforms for distributed caching, such as ScaleOut StateServer®, which was introduced in 2005, hide internal mechanisms for cluster membership, throughput scaling, and high availability to take full advantage of the cluster’s scalable memory without adding complexity to applications. They transparently distribute stored objects across the cluster’s servers and ensure that data is not lost if a server or network component fails.
As distributed caching has evolved over the last two decades, additional mechanisms for in-memory computing have been incorporated to take advantage of the computing power available in the server cluster. Parallel query enables stored objects on all servers to be scanned simultaneously to retrieve objects with desired properties. Data-parallel computing analyzes objects on the server cluster to extract and report patterns of interest; it scales much better than parallel query by avoiding network bottlenecks and by using the cluster’s computing resources.
Most recently, stream-processing has been implemented with in-memory computing to simultaneously analyze telemetry from thousands or even millions of data sources and track dynamic state information for each data source. ScaleOut Software’s real-time digital twin model provides straightforward APIs for implementing stream-processing applications within its ScaleOut Digital Twin Streaming Service, an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins. Each step in the evolution has built on the previous one to add new capabilities that take advantage of the scalable computing power and fast data access that in-memory computing enables.
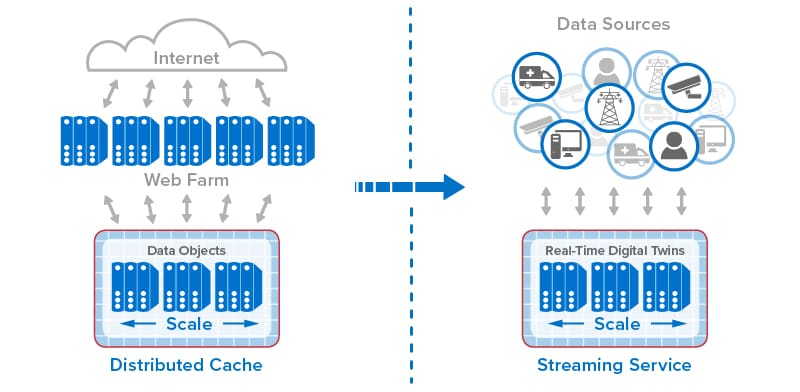
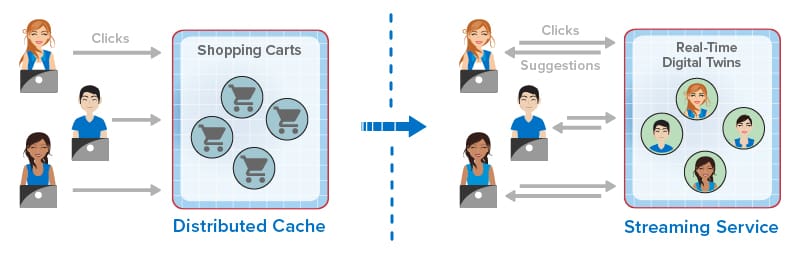
For ecommerce applications, this evolution has created new capabilities that dramatically improve the experience for online shoppers. Instead of just passively hosting session-state and shopping carts, online applications now can mine shopping carts for dynamic trends to evaluate the effectiveness of product descriptions and marketing programs (such as flash sales). They can also employ real-time digital twins or similar techniques to track each shopper’s behavior and make recommendations. By analyzing a click-stream of product selections in the context of knowledge of a shopper’s preferences and demographics, an ecommerce site can make highly focused recommendations to assist the shopper.
For example, one of ScaleOut Software’s customers recently upgraded from just using distributed caching to scale its ecommerce application. This customer now incorporates stream-processing capabilities using ScaleOut StreamServer® to capture click-streams and score users so that its web site can make more effective real-time offers.
The following diagram illustrates how the evolution of in-memory computing has enhanced the online experience for ecommerce shoppers by providing in-the-moment suggestions:
Starting with its development for parallel supercomputing in the late 1990s and evolving into its latest form as a cloud-based service, in-memory computing has offered powerful, software based APIs for building applications that serve large populations of users and data sources. It has helped assure that these applications deliver predictably fast performance and scale to meet the demands of growing workloads. In the next few years, we should continued innovation from in-memory computing to help ecommerce and other applications maintain their competitive edge.
The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>The post Use Distributed Caching to Accelerate Online Web Sites appeared first on ScaleOut Software.
]]>In this time of extremely high online usage, web sites and services have quickly become overloaded, clogged trying to manage high volumes of fast-changing data. Most sites maintain a wide variety of this data, including information about logged-in users, e-commerce shopping carts, requested product specifications, or records of partially completed transactions. Maintaining rapidly changing data in back-end databases creates bottlenecks that impact responsiveness. In addition, repeatedly accessing back-end databases to serve up popular items, such as product descriptions and news stories, also adds to the bottleneck.
The Solution: Distributed Caching
The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. This speeds up accesses and updates while offloading back-end database servers. Also called in-memory data grids, distributed caches, such as ScaleOut StateServer®, use server farms to both scale storage capacity and accelerate access throughput, thereby maintaining fast data access at all times.
The following diagram illustrates how a distributed cache can store fast-changing data to accelerate online performance and offload a back-end database server:
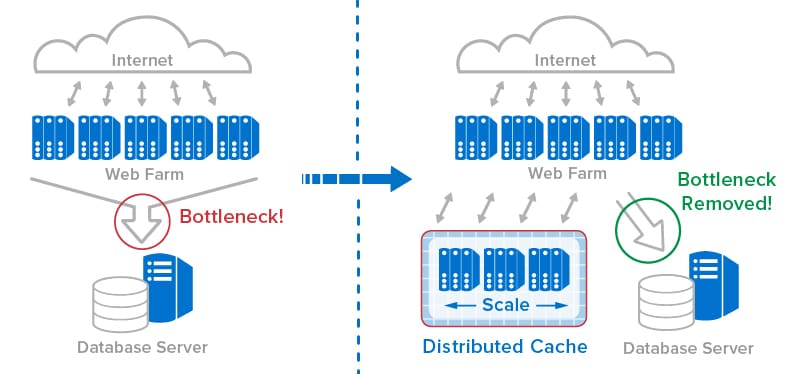
The Technology Behind Distributed Caching
It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches. To be reliable and easy to use, distributed caches need to incorporate technology that provides important attributes, including ease of integration, location transparency, transparent scaling, and high availability with strong consistency. Let’s take a look at some of these capabilities.
To make distributed caches easy to use and keep them fast, they typically employ a “NoSQL” key/value access model and store values as serialized objects. This enables web applications to store, retrieve, and update instances of their application-defined objects (for example, shopping carts) using a simple key, such as a user’s unique identifier. This object-oriented approach allows distributed caches to be viewed as more of an extension of an application’s in-memory data storage than as a separate storage tier.
That said, a web application needs to interact with a distributed cache as a unified whole. It’s just too difficult for the application to keep track of which server within a distributed cache holds a given data object. For this reason, distributed caches handle all the bookkeeping required to keep track of where objects are stored. Applications simply present a key to the distributed cache, and the cache’s client library finds the object, regardless of which server holds it.
It’s also the distributed cache’s responsibility to distribute access requests across its farm of servers and scale throughput as servers are added. Linear scaling keeps access times low as the workload increases. Distributed caches typically use partitioning techniques to accomplish this. ScaleOut StateServer further integrates the cache’s partitioning with its client libraries so that scaling is both transparent to applications and automatic. When a server is added, the cache quietly rebalances the workload across all caching servers and makes the client libraries aware of the changes.
To enable their use in mission-critical applications, distributed caches need to be highly available, that is, to ensure that both stored data and access to the distributed cache can survive the failure of one of the servers. To accomplish this, distributed caches typically store each object on two (or more) servers. If a server fails, the cache detects this, removes the server from the farm, and then restores the redundancy of data storage in case another failure occurs.
When there are multiple copies of an object stored on different servers, it’s important to keep them consistent. Otherwise, stale data due to a missed update could inadvertently be returned to an application after a server fails. Unlike some distributed caches which use a simpler, “eventual” consistency model prone to this problem, ScaleOut StateServer uses a patented, quorum-based technique which ensures that all stored data is fully consistent.
There’s More: Parallel Query and Computing
Because a distributed cache stores memory-based objects on a farm of servers, it can harness the CPU power of the server farm to analyze stored data much faster than would be possible on a single server. For example, instead of just accessing individual objects using keys, it can query the servers in parallel to find all objects with specified properties. With ScaleOut StateServer, applications can use standard query mechanisms, such as Microsoft LINQ, to create parallel queries executed by the distributed cache.
Although they are powerful, parallel queries can overload both a requesting client and the network by returning a large number of query results. In many cases, it makes more sense to let the distributed cache perform the client’s work within the cache itself. ScaleOut StateServer provides an API called Parallel Method Invocation (and also a variant of .NET’s Parallel.ForEach called Distributed ForEach) which lets a client application ship code to the cache that processes the results of a parallel query and then returns merged results back to the client. Moving code to where the data lives accelerates processing while minimizing network usage.
Distributed Caches Can Help Now
Online web sites and services are now more vital than ever to keeping our daily activities moving forward. Since almost all large web sites use server farms to handle growing workloads, it’s no surprise that server farms can also offer a powerful and cost-effective hardware platform for hosting a site’s fast-changing data. Distributed caches harness the power of server farms to handle this important task and remove database bottlenecks. Also, with integrated parallel query and computing, distributed caches can now do much more to offload a site’s workload. This might be a good time to take a fresh look at the power of distributed caching.
The post Use Distributed Caching to Accelerate Online Web Sites appeared first on ScaleOut Software.
]]>The post Use Parallel Analysis – Not Parallel Query – for Fast Data Access and Scalable Computing Power appeared first on ScaleOut Software.
]]>To help ensure fast data access and scalability, IMDGs usually employ a straightforward key/value storage model. This model works well for storing large, object-oriented collections of business-logic state, such as the examples listed above. Each object is stored in the grid as a serialized version of the application’s in-memory counterpart and is accessed with a unique key defined within a namespace (as shown in the diagram below). (Namespaces typically hold objects of a single, language-defined type.) In contrast to relational, graph-oriented, and other more complex storage models, key/value stores usually deliver faster data access because key lookups can be quickly completed with low overhead.
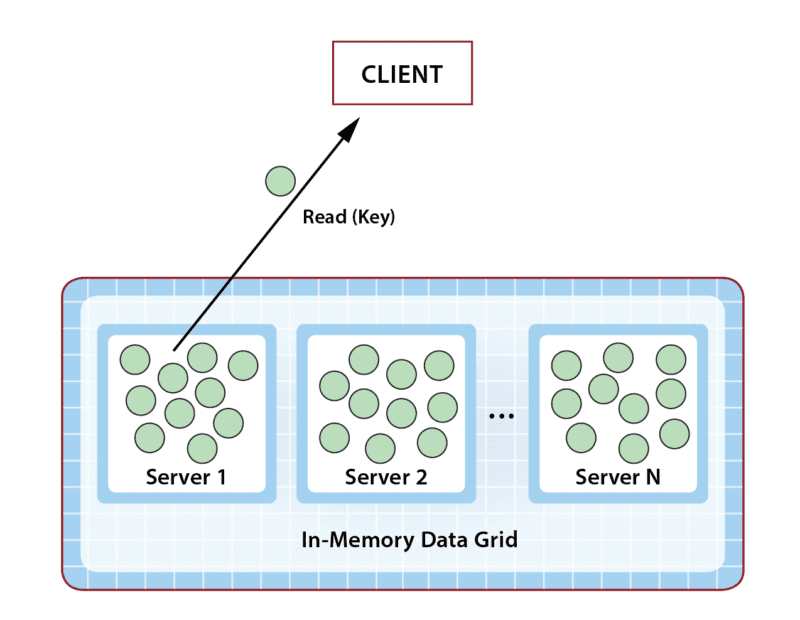
Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database. For example, it can be used to host short-lived business logic state used to prepare transactions. Offloading the database boosts performance, reduces bottlenecks, and lowers costs.
When used as a cache, developers often view an IMDG with a database mindset and access grid data using traditional, database-oriented techniques, such as SQL query, instead of key-based lookup. For example, an object describing a customer might be retrieved by querying the customer’s last name instead of performing a key-based lookup of the customer’s unique account number. That’s where performance problems can begin.
When used in an IMDG, a typical query seeks to access a set of objects matching specific properties. Just as a relational database queries a table by attributes, an IMDG queries a distributed, in-memory, object collection by matching class-based properties. In both cases, many results may match a query and be returned to the requesting client. When used sparingly, IMDG queries work quite well. However, when applications rely on query as the primary access model, access throughput can be seriously degraded, and overall application performance can suffer in two ways.
First, unlike key-based access, which is directed to a specific grid server to retrieve an object, a query requires the participation of all grid servers. This enables the IMDG to find all matching objects, which potentially reside on multiple servers within the distributed store. So the overhead to perform a query requires O(N) overhead on a cluster of N grid servers, while a key lookup only requires O(1) overhead. Since an IMDG typically has many clients simultaneously making access requests, the combined overhead for many parallel queries can quickly grow. For this reason, query should be avoided when a key lookup will suffice.
A bigger problem with query is that when it matches many results, a large amount of data may need to be returned over the network to the requesting client for processing, as illustrated below. This can quickly saturate the network (and bog down the client). When you consider that an IMDG can easily host terabytes of data distributed across several servers, it’s not surprising to see a single query return 10s of megabytes (MB) of results. A gigabit network can only move about a peak of 128MB/sec (although delays can start increasing at about half that), so large queries can (and often do) overload the network. And after a query returns the requested objects to the client for processing, the client must then wade through them all, potentially creating another bottleneck on the client.
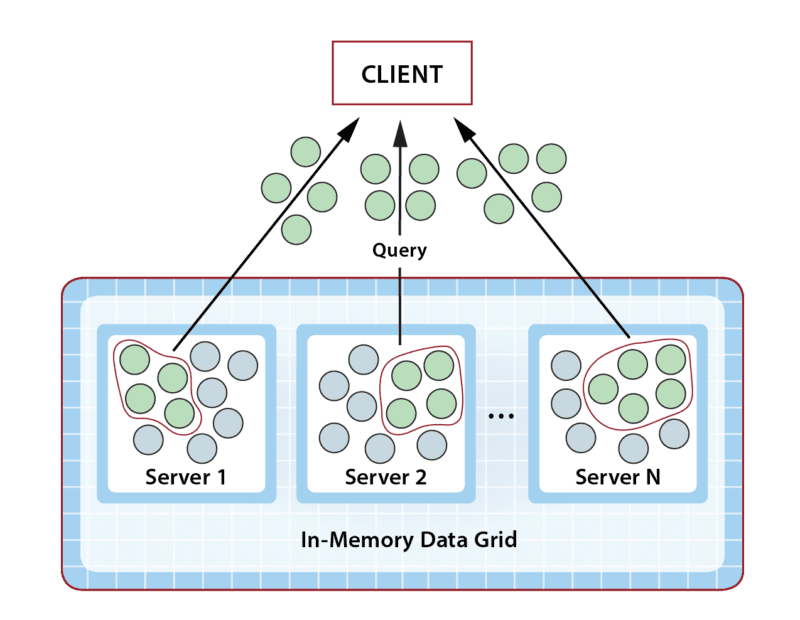
What’s interesting about this dilemma is that the IMDG’s apparent weakness is actually its key strength. It’s all in how the application looks at the problem to be solved. Instead of querying the grid, what if we just moved this work from the client into the grid and performed it there? This would enable the application to avoid bottlenecks and harness the IMDG’s scalable computing power to boost performance.
The technique is called data-parallel computing, and many IMDGs (like ScaleOut StateServer Pro®) provide APIs that make it easy to use in languages like Java, C#, and C++. In its simplest form, the application ships off a class-defined method (call it “Eval”) to execute in the grid along with a query specification, and the IMDG distributes the work across all of its servers, querying each server locally and then running the application’s method on the selected objects. The application optionally can define a second method (call it “Merge”) to combine the results and return them back to the client. Running a method in the grid can be compared to executing a stored procedure in a database. The following diagram illustrates this concept:
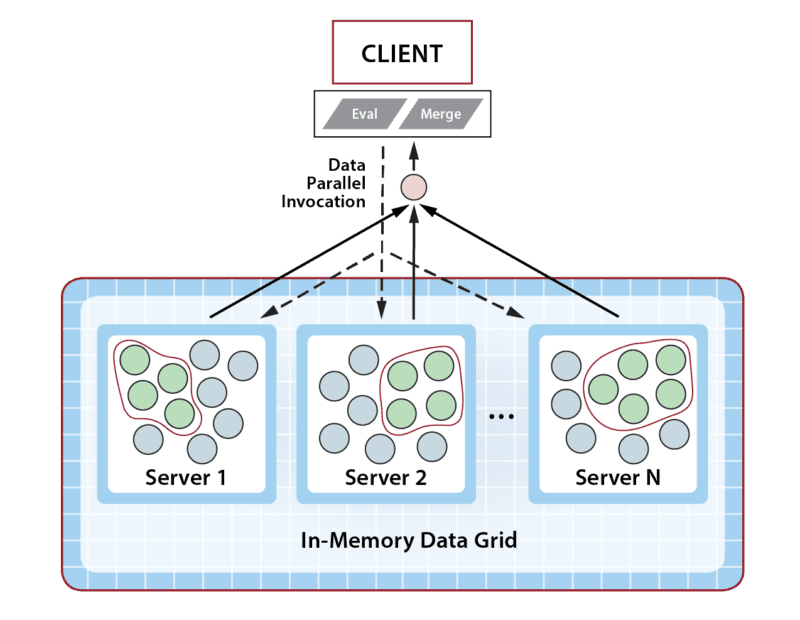
Using data-parallel computing instead of parallel query gives an application two big wins. First, moving the code to the data dramatically reduces the amount of data transferred over the network since the results of the computation are usually dramatically smaller than the size of the original query results. Second, the grid’s scalable computing power reduces execution time while avoiding a bottleneck in the client. This scales the application’s throughput as the size of the workload increases.
We have seen this computing model’s utility in countless applications. Consider, for example, a hedge fund storing portfolios of stocks in an IMDG as objects, where each portfolio tracks a given market sector (high tech, energy, healthcare, etc.). When the stock exchange’s ticker feed updates a stock price, the hedge fund needs to evaluate all corresponding portfolios to see if rebalancing is needed. The obvious way to implement this is to query the grid for all portfolios containing the updated stock and then analyze them in the client. However, this requires large amounts of data to cross the network and creates lots of work for the client. Instead, the client can simply kick off a data-parallel computation in the grid on all portfolios that contain the stock and let the grid perform this work quickly (and scalably). Using this technique, a hedge fund was able to see the time for rebalancing drop from several minutes to less than half a second.
Although it often masquerades as a distributed cache, an IMDG actually is a scalable, in-memory computing platform – not that different from a parallel supercomputer running on commodity hardware. With a small change in mindset, developers easily can harness its computing power to eliminate bottlenecks and reap big dividends in performance.
The post Use Parallel Analysis – Not Parallel Query – for Fast Data Access and Scalable Computing Power appeared first on ScaleOut Software.
]]>The post AppFabric Caching: What Now? appeared first on ScaleOut Software.
]]>Eighteen months ago we posted a blog on the performance and feature shortcomings of Microsoft’s Windows Server AppFabric (WSAF) Caching. Since then much has transpired. Microsoft announced earlier this year it will be ending support for Windows Server AppFabric 1.1 by April 2017. AppFabric Caching users now have to determine the right next step in migrating to an alternative distributed cache.
Recommended alternatives found lacking
With its “mobile first, cloud first” strategy, it appears that Microsoft is pushing customers to its Microsoft Azure cloud platform by recommending that “all Microsoft AppFabric customers using Cache to move to Microsoft Azure Redis Cache.” However, for many customers it is not yet practical to move to Azure, and a fully supported, on-premise solution is required for their distributed cache. Microsoft’s recommendation that customers move to Redis is both controversial and misleading since the Redis open source community does not recommend running on Windows.
Further, Redis is an in-memory database which works well on a single server but lacks many of the scalability and high-availability features of a mature, fully featured in-memory data grid, let alone real-time analytics and computing capabilities. This leaves customers with an uncertain and commercially unsupported future when migrating their on-premise, .NET compatible, distributed cache away from AppFabric Caching.
A better alternative
Luckily, ScaleOut Software has been loyally serving the .NET developer community with an industry-leading in-memory data grid for over a decade. ScaleOut’s architectural design philosophy focuses on delivering high performance with maximum ease-of-use. It employs a single, coherent architecture for integrating scalability and high availability; this architecture is transparently leveraged in all aspects of its in-memory data grid. We call this “scalable, highly available everything” — the platform goes beyond linear performance scaling for accessing grid objects and uses a common architecture for all features such as distributed locking, event processing, load-balancing, geographic replication, parallel computation and backup/restore.
The key benefits and advantages that set ScaleOut StateServer® apart from its industry peers are:
Peer-to-peer architecture:
- ScaleOut StateServer uses a peer-to-peer architecture to avoid single points of failure and maximize ease of use. It avoids the need for a centralized configuration store (which is a single point of failure) by automatically replicating its configuration files on every cluster host. System administrators do not need to create and manage a configuration store; this is automatically handled by ScaleOut StateServer.
- ScaleOut StateServer’s peer-to-peer architecture allows servers to be easily added and removed from the membership. Servers automatically form a new membership and rebalance the workload as needed. The membership self-heals after a server failure, restoring redundancy for high availability and redistributing the workload as necessary.
Ease-of-use:
- ScaleOut StateServer’s acclaimed ease-of-use ensures that installation is extremely simple with minimum configuration steps. Unlike AppFabric Caching, it doesn’t require a highly qualified Windows system administrator to navigate the process of installing and configuring a distributed cache.
- ScaleOut StateServer’s centralized, GUI-based management console dramatically simplifies management and provides important capabilities, such as cluster-wide control, dynamic performance charting alerts, and a grid heat-map. Holistic visualization delivers at-a-glance monitoring, which is not possible with PowerShell and other text-based scripting approaches.
- ScaleOut Object Browser enables detailed introspection on the contents of the distributed cache, including access to values for object properties.
Extended functionality:
ScaleOut StateServer (and its product extensions) go far beyond AppFabric Caching’s basic capabilities and add important functionality, including:
- Distributed, property-based query using Microsoft LINQ
- Numerous API extensions, such as support for object dependencies and sliding timeouts
- Powerful object browser to directly browse data stored in the grid
- Scalable event handling
- Data-parallel computation, including the world’s first C# MapReduce
- Extensible support for building server-based data structures
- WAN-based data replication and synchronized, global data access
- Integrated support for public clouds, including Amazon AWS and Microsoft Azure
Furthermore, unlike Redis and some of the other open-source alternatives, ScaleOut StateServer is fully commercially supported by ScaleOut Software for use on Windows (or Linux).
Replacement and migration options
Customers have two paths to choose from when planning their migration off of AppFabric Caching to ScaleOut Software’s distributed cache: retain source-code compatibility for their existing legacy applications or migrate their applications to fully take advantage of native ScaleOut APIs.
Source-code compatible library
The ScaleOut Windows Server AppFabric (WSAF) Caching Compatibility Library is a source-code compatible, drop-in replacement for Microsoft AppFabric Caching APIs. This allows existing customer applications using AppFabric to preserve the legacy AppFabric Caching API semantics and switch to ScaleOut StateServer without making any code changes and use familiar PowerShell commands to manage the distributed cache. This library ships as part of ScaleOut StateServer release 5.4 and later, as described in the WSAF Caching Compatibility Library Reference.
Native ScaleOut APIs
Customers also can rewrite their applications to use ScaleOut StateServer’s native APIs, which allows applications to take full advantage of the extended functionality mentioned above. Using a hybrid approach, native ScaleOut StateServer APIs can be used alongside AppFabric APIs. We have developed a detailed technical AppFabric Caching migration guide to help developers through this process.
Using the WSAF Caching Compatibility Library
The WSAF Caching Compatibility Library is easy to integrate into applications that use AppFabric Caching’s APIs. Here is an outline of the required steps:
- Add the compatibility library’s assembly (soss_wsaf_compat.dll) as a reference to the project. This assembly can be found in the ScaleOut StateServer installation folder (typically C:\Program Files\ScaleOut_Software\StateServer) in the Compat\WSAF_Caching folder.
- Change the “using Microsoft.ApplicationServer.Caching;” statements in the source files to “using Soss.Compat.WSAF;”.
- Recompile the project to start using the WSAF Caching Compatibility Library.
For More Information
More information about all the AppFabric Caching replacement and migration resources available can be found at www.scaleoutsoftware.com/appfabric, including a valuable offer for former AppFabric Caching users. We hope that the power of our platform as both a replacement and an upgrade from Microsoft’s WSAF Caching has captured your interest. Regardless if you run on-premise or in the cloud, it may be the right next step for your application.
The post AppFabric Caching: What Now? appeared first on ScaleOut Software.
]]>The post AppFabric Caching: Retry Later appeared first on ScaleOut Software.
]]>Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers. In addition to looking at performance differences, we also want to compare ScaleOut StateServer (SOSS) to AppFabric on qualitative measures, such as features, ease of installation, and management.
Testing Scale-Up Performance
Well, performance comparisons aren’t so easy since the AppFabric license agreement states: “You may not disclose the results of any benchmark tests of the software to any third party without Microsoft’s prior written approval.” So our comments will be confined to what testing we felt was valuable and how well SOSS performed.
In a recent customer engagement, the application needed to load 10M objects into each server of the IMDG’s cluster to make full use of high-end servers with 60GB memory capacity. Measuring object creation and access rates on a single server is a good test of the IMDG’s memory management and multithreading, and this is an area in which we have made several performance optimizations. Using a workload of random object sizes varying from 200B to 2KB, SOSS was able to load 2 million objects in 59.2 seconds and then sustain 18K read/update pairs per second to random objects. That’s actually quite fast. (We invite you to test AppFabric’s performance; contact us if you need a test application.)
We also looked at load-balancing and recovery times for this workload of 2M objects when adding a server to a 2-server cluster, removing the third server, and also just killing the third server. This measures how well the IMDG’s servers use multithreading to maximize network bandwidth during load-balancing, and it also evaluates failure detection and recovery algorithms. These are areas in which we have invested heavily to take advantage of 10 Gbps (and faster) networks and to handle intermittent network delays inherent in virtual server infrastructures. While handling an access load of 6K read/update pairs per second, SOSS was measured to complete load-balancing in less than 35 seconds for joins and leaves and also to complete recovery and restore full throughput in this amount of time after a server failure.
Unwanted Client Exceptions from AppFabric
We were surprised to discover that AppFabric throws exceptions to the client application during load-balancing and recovery and due to security issues, as described in other blog posts. During load-balancing, the client gets the following exception when accessing the cache:
ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later. (One or more specified cache servers are unavailable, which could be caused by busy network or servers. …)
You’ll also see a “Please retry later” exception (forever!) if the client runs with insufficient security authorization; we had to run the client as administrator to avoid problems without a much deeper investigation. The client also throws these exceptions during “graceful” host shutdowns and during recovery.
To keep application development as straightforward as possible, SOSS handles all exceptions that occur during membership changes and load-balancing, automatically retrying requests within the server as necessary. This avoids exposing the application to the details of the IMDG’s internal operations unless the IMDG is completely unreachable.
A Few Words on Design Philosophy: Keep It Simple
Our experience with customers consistently reinforces the need to keep middleware software as easy to install and use as possible, especially given that it is deployed as distributed software running on a cluster of servers. This philosophy manifests itself in all areas, including installation, application development, and cluster management. We believe that installing our software should be as straightforward as we can make it, requiring minimal knowledge of the host operating system and the fewest possible explicit configuration settings.
AppFabric caching does not share this design approach and requires the configuration of numerous components, including security policies, SQL Server or a network file share with the appropriate permissions, “lead” hosts, etc. Also, a long list of PowerShell commands for managing the cache must be learned and correctly used. Running AppFabric caching in production typically requires the use of a domain and is deeply tied into the Windows Server infrastructure. As expected, AppFabric requires the comprehensive knowledge of a Windows system administrator to install and manage.
In our testing, the net result was about a half-day investment in time on our part (and some frustration) getting AppFabric up and running. After spending an hour trying to join multiple cluster hosts in a Windows workgroup, we switched to using a domain controller to make this work; it just wasn’t worth the time to sort out the incorrect configuration settings. Head scratching was required in several other areas before our AppFabric cluster showed signs of life.
GUI Based Management Is Crucial for Distributed Software
A major source of frustration with AppFabric is its use of PowerShell commands to manage the cache cluster. It’s easy to forget that distributed software is running on multiple servers which need to be orchestrated as a group, and that’s hard to do with a sequence of shell commands because you can’t track the state of the cluster at a glance. It’s much easier to manage a cluster with a graphical user interface (GUI) which shows the status of all hosts and alerts you to dynamic situations, such as high usage, load-balancing, or network outages.
To take full advantage of the GUI approach, SOSS uses a Windows-based management console with intuitive controls that make management of the IMDG simple and easy to learn. The console also adds advanced visualization features, such as integrated performance charts and tabular usage charts, a “heat” map showing the availability and dynamic state of all regions within the distributed store, and an object browser that lets you see stored objects and examine both their metadata and contents.
The following screenshots illustrate SOSS’s performance charting and heat map. Note that the status of the IMDG and all cluster hosts is instantly visible in the tree list at the left:
Because the GUI management console receives periodic updates from all cluster hosts, it stays tightly integrated with the cluster and dynamically updates the latest status. In contrast, the use of shell commands just gives you a snapshot of the state of the cluster at one instant in time. We also have observed that these results quickly can become out of sync with what client applications are actually experiencing. For example, a shell command can report that the cluster is in an unknown state when in fact the client is successfully completing access requests. (In AppFabric, be prepared to wait for several seconds for management commands to time out when a cluster host goes into an unknown state.)
Use Fully Peer-to-Peer Design for Simplicity and High Availability
AppFabric uses a single store, either a file share or SQL Server, to hold the cluster’s configuration, which adds complexity to installation and creates a single point of failure. Although SQL Server can be clustered, this adds even more cost than just using a single server. To avoid these problems, SOSS automatically replicates its configuration files on every cluster host to maximize availability with a fully peer-to-peer implementation. This approach also keeps the user from having to deal with managing a configuration store.
The peer-to-peer issue arises again in AppFabric’s requiring a majority of lead hosts (presumably) to reconfigure the cluster after a membership change. Because some hosts are lead hosts and others are not, an AppFabric caching cluster will go down even when hosts are healthy. Moreover, the administrator has to understand and ensure that a majority hosts quorum of lead hosts exists, and the number of lead hosts varies with cluster size. For example, a small cluster of up to 20 hosts might use 3 lead hosts, requiring two hosts to form a quorum. If 2 of the 3 lead hosts go down, the cluster will go down even if there are 18 healthy hosts.
With ScaleOut, you don’t need to know what the word “quorum” means. SOSS sidesteps these issues by using a fully peer-to-peer membership so that all hosts can participate in constructing the cluster membership. (SOSS makes use of a ScaleOut Software patent which eliminates the need for a majority hosts quorum by building a logical quorum on a uniform set of servers.) This means that SOSS can avoid the use of lead hosts and maintains service as long as any host survives. System administrators view all cluster hosts as peers and do not have to be aware of SOSS’s internal mechanisms for implementing the cluster membership.
Distributed Cache or In-Memory Data Grid?
It’s actually not clear to us whether AppFabric’s design philosophy regarding high availability is more closely aligned with “best effort” distributed caches like memcached or with mission-critical in-memory data grids like SOSS and others. Data replication is turned off by default and is explicitly set on a namespace-by-namespace basis using management commands. (High availability apparently is not available on Windows Server 2008R2 Standard Edition and requires Enterprise Edition, which can cost about $2,800 more per server, or you must upgrade to Windows Server 2012.) Also, since data is hosted in managed code, access delays due to garbage collection (as well as the exceptions noted above) are to be expected. (Microsoft recommends not storing more than 16GB in a cache host to avoid GC pauses.) Lastly, AppFabric’s client cache is not kept coherent with the distributed cache, and so the client cache cannot be used for transactional data.
In contrast, SOSS automatically replicates all stored objects on multiple hosts to maintain high availability at all times. Likewise, it uses an unmanaged heap for stored data to keep access times as predictable as possible and avoid GC pauses. It also keeps all client caches coherent with the IMDG so that multi-threaded code running on the cluster can coordinate access to transactional data using the well understood sequential consistency model.
In Summary: Design for Ease of Use and High Performance
It was tempting to write this blog post as a feature comparison between AppFabric and SOSS. It’s clear that, as a full in-memory data grid, SOSS — unlike AppFabric — incorporates many features that go well beyond distributed caching. For example, SOSS lets applications query stored data by property using Microsoft’s own LINQ, and ScaleOut Analytics Server (SOAS) can perform data-parallel analysis of queried objects using application code that SOAS automatically deploys on the cluster. ScaleOut hServer takes analytics a step further by hosting full Hadoop MapReduce on the IMDG.
That said, since AppFabric is targeted at distributed caching, we felt that AppFabric users likely are more focused on issues regarding deployment, performance, and availability. Beyond just evaluating how well products like AppFabric and SOSS extract performance from scale-up, it’s also important to examine how they stack up in their overall role of providing scalable, highly available in-memory storage.
When looking at other design approaches, we feel that ScaleOut’s philosophy of easy-to-use, fully peer-to-peer design with GUI-based management provides important dividends by simplifying deployment and maximizing visibility, while driving high performance and availability. Not surprisingly, all of this lowers the total cost of ownership, which — as we have seen — even for “free” software is never zero.
The post AppFabric Caching: Retry Later appeared first on ScaleOut Software.
]]>