The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>
by Olivier Tritschler, Senior Software Engineer
Because of their ability to provide highly elastic computing resources, public clouds have become a highly attractive platform for hosting distributed caches, such as ScaleOut StateServer®. To complement its current offerings on Amazon AWS and Microsoft Azure, ScaleOut Software has just announced support for the Google Cloud Platform. Let’s take a look at some of the benefits of hosting distributed caches in the cloud and understand how we have worked to make both deployment and management as simple as possible.
Distributed Caching in the Cloud
Distributed caches, like ScaleOut StateServer, enhance a wide range of applications by offering shared, in-memory storage for fast-changing state information, such as shopping carts, financial transactions, geolocation data, etc. This data needs to be quickly updated and shared across all application servers, ensuring consistent tracking of user state regardless of the server handling a request. Distributed caches also offer a powerful computing platform for analyzing live data and generating immediate feedback or operational intelligence for applications.
Built using a cluster of virtual or physical servers, distributed caches automatically scale access throughput and analytics to handle large workloads. With their tightly integrated client-side caching, these caches typically provide faster access to fast-changing data than backing stores, such as blob stores and database servers. In addition, they incorporate redundant data storage and recovery techniques to provide built-in high availability and ensure uninterrupted access if a server fails.
To meet the needs of elastic applications, distributed caches must themselves be elastic. They are designed to transparently scale upwards or downwards by adding or removing servers as the workload varies. This is where the power of the cloud becomes clear.
Because cloud infrastructures provide inherent elasticity, they can benefit both applications and distributed caches. As more computing resources are needed to handle a growing workload, clouds can deploy additional virtual servers (also called cloud “instances”). Once a period of high demand subsides, resources can be dialed back to minimize cost without compromising quality of service. The flexibility of on-demand servers also avoids costly capital investments and reduces management costs.
Deploying ScaleOut’s Distributed Cache in the Google Cloud
A key challenge in using a distributed cache as part of a cloud-hosted application is to make it easy to deploy, manage, and access by the application. Distributed caches are typically deployed in the cloud as a cluster of virtual servers that scales as the workload demands. To keep it simple, a cloud-hosted application should just view a distributed cache as an abstract entity and not have to keep track of individual caching servers or which data they hold. The application does not want to be concerned with connecting N application instances to M caching servers, especially when N and M (as well as cloud IP addresses) vary over time. In particular, an application should not have to discover and track the IP addresses for the caching servers.
Even though a distributed cache comprises several servers, the simplest way to deploy and manage it in the cloud is to identify the cache as a single, coherent service. ScaleOut StateServer takes this approach by identifying a cloud-hosted distributed cache with a single “store” name combined with access credentials. This name becomes the basis for both managing the deployed servers and connecting applications to the cache. It lets applications connect to the caching cluster without needing to be aware of the IP addresses for the cluster’s virtual servers.
The following diagram shows a ScaleOut StateServer distributed cache deployed in Google Cloud. It shows both cloud-hosted and on-premises applications connected to the cache, as well as ScaleOut’s management console, which lets users deploy and manage the cache. Note that while the distributed cache and applications all contain multiple servers, applications and users can access the cache just by using its store name.
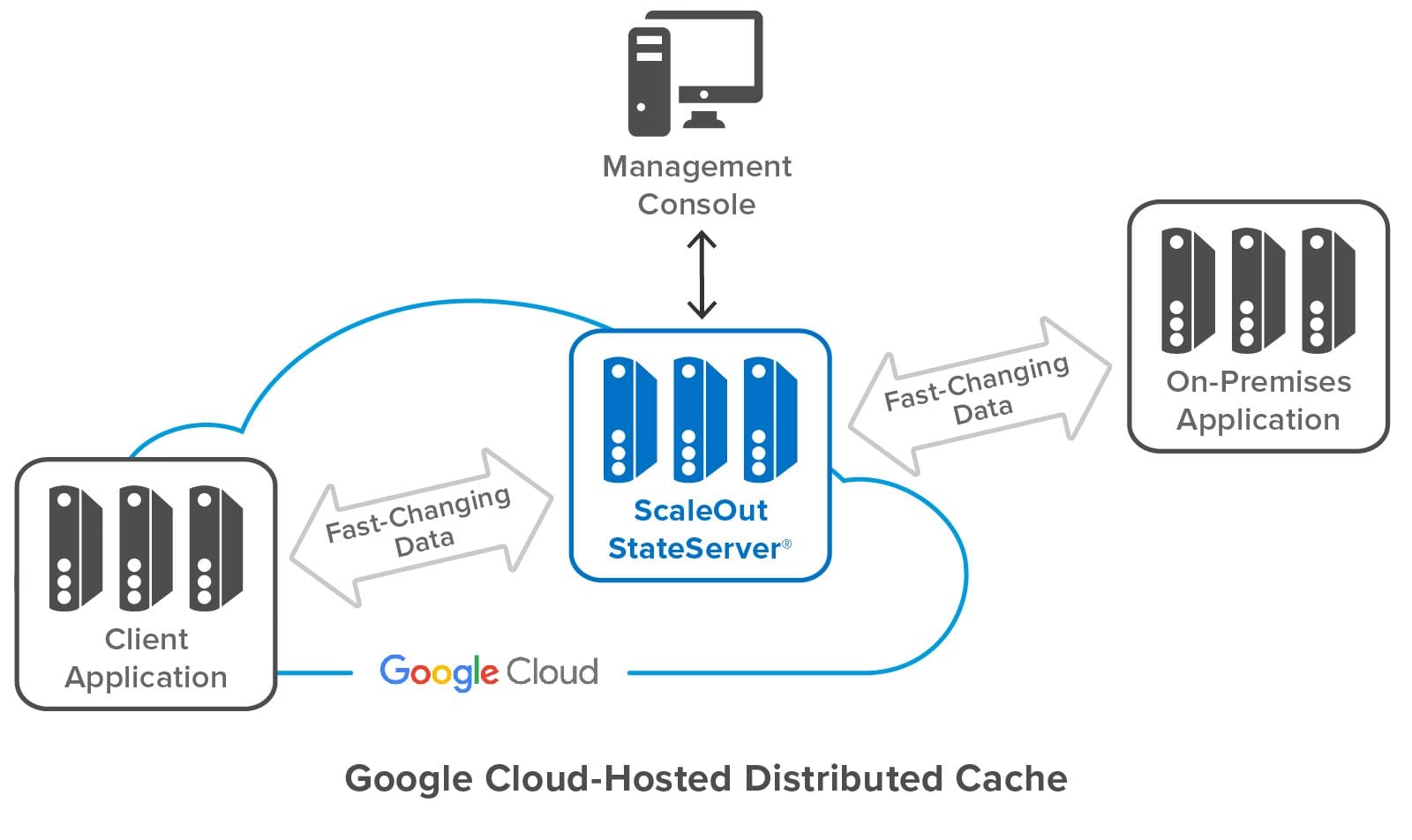
Building on the features developed for the integration of Amazon AWS and Microsoft Azure, the ScaleOut Management Console now lets users deploy and manage a cache in Google Cloud by just specifying a store name and initial number of servers, as well as other optional parameters. The console does the rest, interacting with Google Cloud to start up the distributed cache and configure its servers. To enable the servers to form a cluster, the console records metadata for all servers and identifies them as having the same store name.
Here’s a screenshot of the console wizard used for deploying ScaleOut StateServer in Google Cloud:
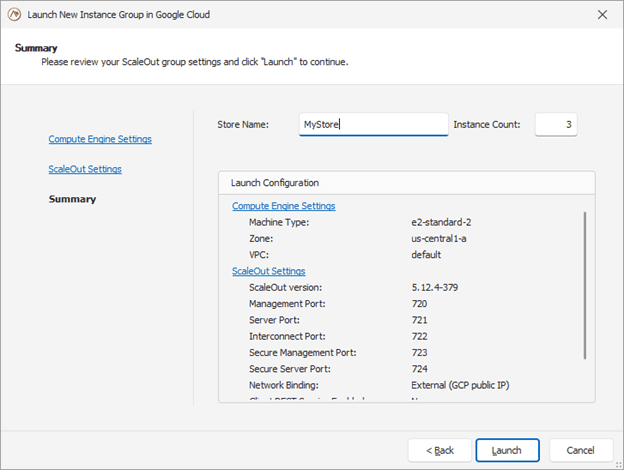
The management console provides centralized, on-premises management for initial deployment, status tracking, and adding or removing servers. It uses Google’s managed instance groups to host servers, and automated scripts use server metadata to guarantee that new servers automatically connect with an existing store. The managed instance groups used by ScaleOut also support defining auto-scaling options based on CPU/Memory usage metrics.
Instead of using the management console, users can also deploy ScaleOut StateServer to Google Cloud directly with Google’s Deployment Manager using optional templates and configuration files.
Simplifying Connectivity for Applications
On-premises applications typically connect each client instance to a distributed cache using a fixed list of IP addresses for the caching servers. This process works well on premises because the cache’s IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of a caching server.
To avoid this problem, ScaleOut StateServer lets client applications specify a store name and credentials to access a cloud-hosted distributed cache. ScaleOut’s client libraries internally use this store name to discover the IP addresses of caching servers from metadata stored in each server.
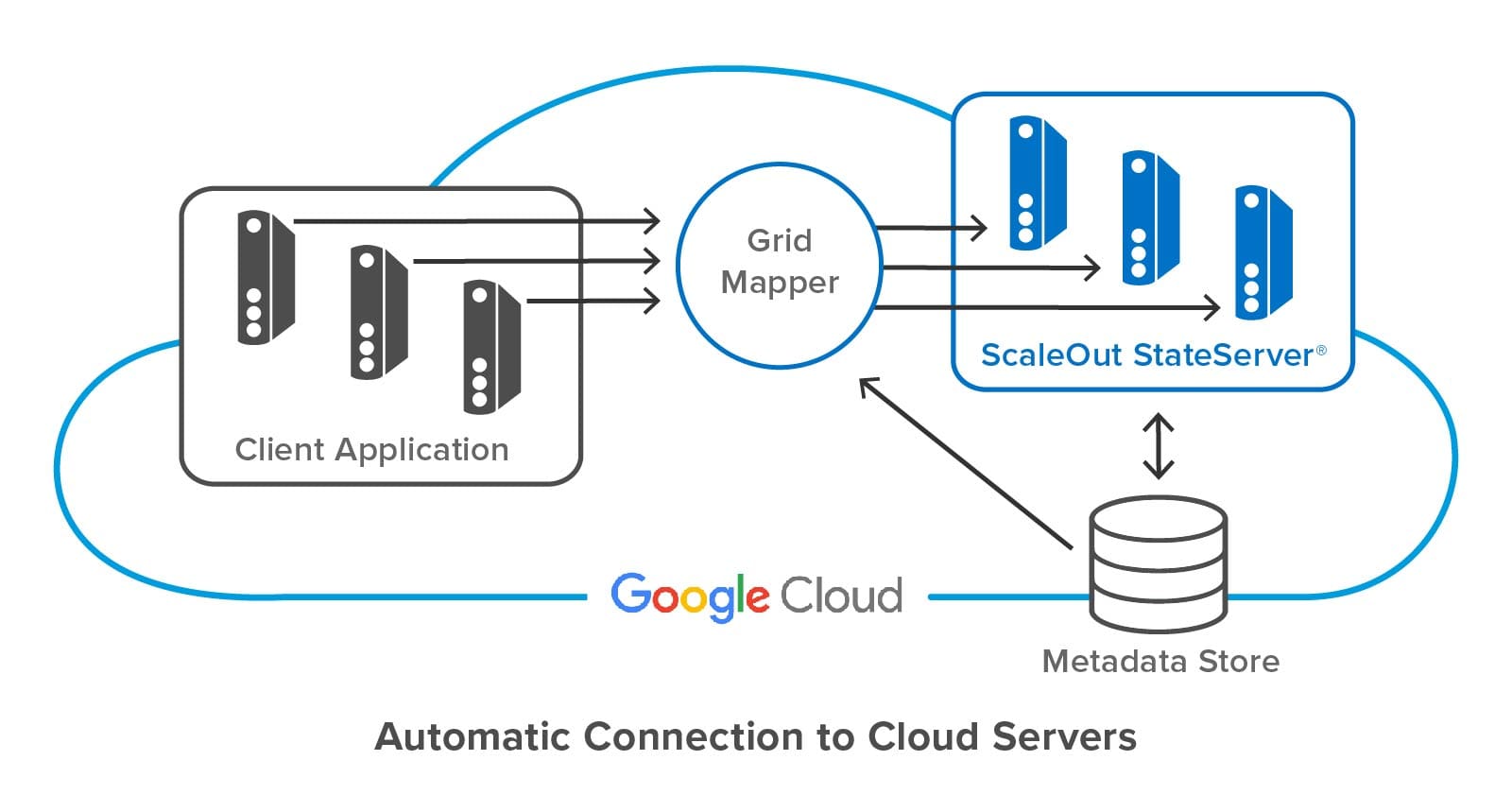
The following diagram shows a client application connecting to a ScaleOut StateServer distributed cache hosted in Google Cloud. ScaleOut’s client libraries make use of an internal software component called a “grid mapper” which acts as a bootstrap mechanism to find all servers belonging to a specified cache using its store name. The grid mapper accesses the metadata for the associated caching servers and returns their IP addresses back to the client library. The grid mapper handles any potential changes in IP addresses, such as servers being added or removed for scaling purposes.
Summing up
Because they provide elastic computing resources and high performance, public clouds, such as Google Cloud, offer an excellent platform for hosting distributed caches. However, the ephemeral nature of their virtual servers introduces challenges for both deploying the cluster and connecting applications. Keeping deployment and management as simple as possible is essential to controlling operational costs. ScaleOut StateServer makes use of centralized management, server metadata, and automatic client connections to address these challenges. It ensures that applications derive the full benefits of the cloud’s elastic resources with maximum ease of use and minimum cost.
The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>The post Simulate at Scale with Digital Twins appeared first on ScaleOut Software.
]]>
Digital Twins Can Implement Both Streaming Analytics and Simulations
With the ScaleOut Digital Twin Streaming Service , the digital twin software model has proven its versatility well beyond its roots in product lifecycle management (PLM). This cloud-based service uses digital twins to implement streaming analytics and add important contextual information not possible with other stream-processing architectures. Because each digital twin can hold key information about an individual data source, it can enrich the analysis of incoming telemetry and extracts important, actionable insights without delay. Hosting digital twins on a scalable, in-memory computing platform enables the simultaneous tracking of thousands — or even millions — of data sources.
, the digital twin software model has proven its versatility well beyond its roots in product lifecycle management (PLM). This cloud-based service uses digital twins to implement streaming analytics and add important contextual information not possible with other stream-processing architectures. Because each digital twin can hold key information about an individual data source, it can enrich the analysis of incoming telemetry and extracts important, actionable insights without delay. Hosting digital twins on a scalable, in-memory computing platform enables the simultaneous tracking of thousands — or even millions — of data sources.
Owing to the digital twin’s object-oriented design, many diverse applications can take advantage of its powerful but easy-to-use software architecture. For example, telematics applications use digital twins to track telemetry from every vehicle in a fleet and immediately identify issues, such as lost or erratic drivers or emerging mechanical problems. Airlines can use digital twins to track the progress of passengers throughout an itinerary and respond to delays and cancellations with proactive remedies that smooth operations and reduce stress. Other applications abound, including health informatics, financial services, logistics, cybersecurity, IoT, smart cities, and crime prevention.
Here’s an example of a telematics application that tracks a large fleet of vehicles. Each vehicle has a corresponding digital twin analyzing telemetry from the vehicle in real time:
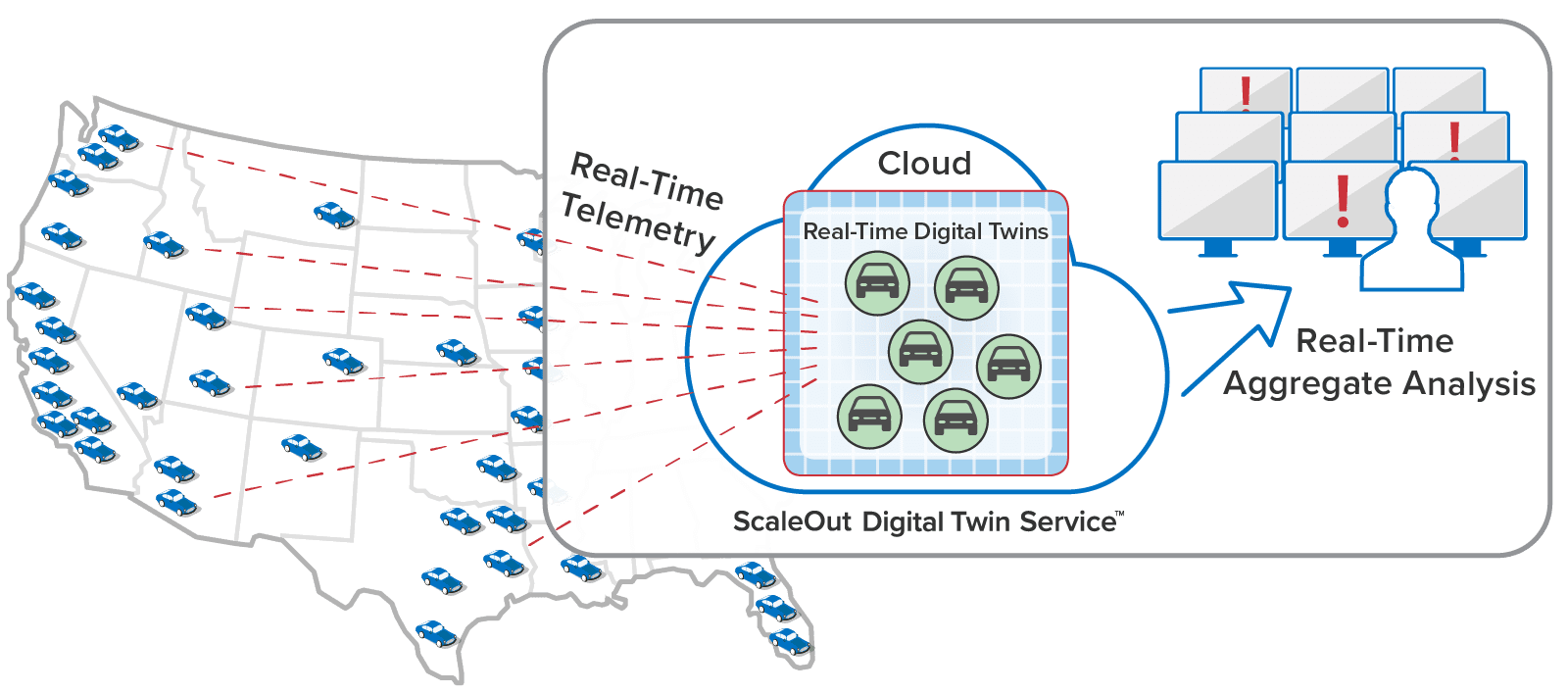
Applications like these need to simultaneously track the dynamic behavior of numerous data sources, such as IoT devices, to identify issues (or opportunities) as quickly as possible and give systems managers the best possible situational awareness. To either validate streaming analytics code for a complex physical system or model its behavior, it is useful to simulate the devices and the telemetry that they generate. The ScaleOut Digital Twin Streaming Service now enables digital twins to simplify both tasks.
Use Digital Twins to Simulate a Workload for Streaming Analytics
Digital twins can implement a workload generator that generates telemetry used in validating streaming analytics code. Each digital twin models the behavior of a physical data source, such as a vehicle in fleet, and the messages it sends and receives. When running in simulation, thousands of digital twins can then generate realistic telemetry for all data sources and feed streaming analytics, such as a telematics application, designed to track and analyze its behavior. In fact, the streaming service enables digital twins to implement both the workload generator and the streaming analytics. Once the analytics code has been validated in this manner, developers can then deploy it to track a live system.
Here’s an example of using a digital twin to simulate the operations of a pump and the telemetry (such as the pump’s temperature and RPM) that it generates. Running in simulation, this simulated pump sends telemetry messages to a corresponding real-time digital twin that analyzes the telemetry to predict impending issues:
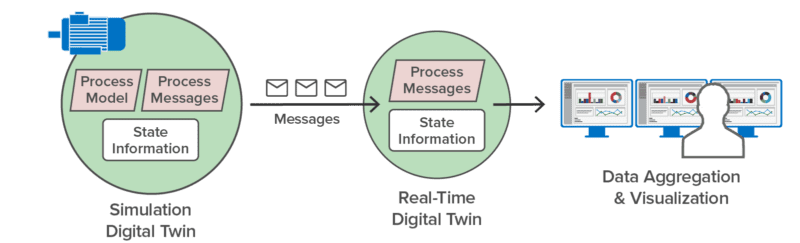
Once the simulation has validated the analytics, the real-time digital twin can be deployed to analyze telemetry from an actual pump:
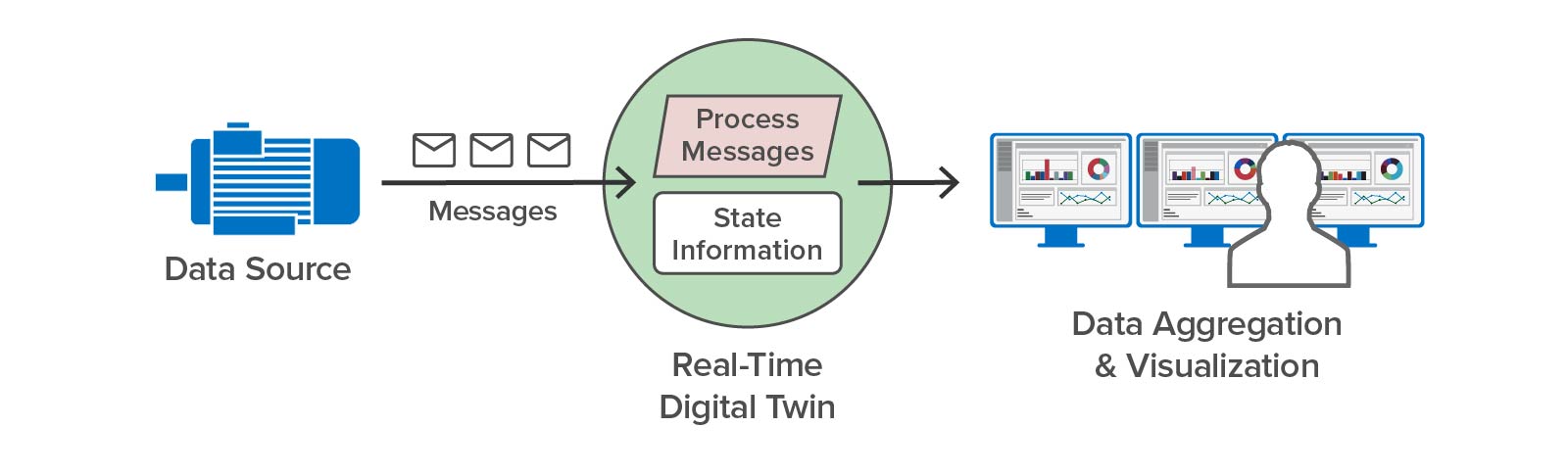
This example illustrates how digital twins can both simulate devices and provide streaming analytics for a live system.
Using digital twins to build a workload generator enables investigation of a wide range of scenarios that might be encountered in typical, real-world use. Developers can implement parameterizable, stateful models of physical data sources and then vary these parameters in simulation to evaluate the ability of streaming analytics to analyze and respond in various situations. For example, digital twins could simulate perimeter devices detecting security intrusions in a large infrastructure to help evaluate how well streaming analytics can identify and classify threats. In addition, the streaming service can capture and record live telemetry and later replay it in simulation.
Use Digital Twins to Simulate a Large System with Many Entities
In addition to using digital twins for analyzing telemetry, the ScaleOut Digital Twin Streaming Service enables digital twins to implement time-driven simulations that model large groups of interacting physical entities. Digital twins can model individual entities within a large system, such as airline passengers, aircraft, airport gates, and air traffic sectors in a comprehensive airline model. These digital twins maintain state information about the physical entities they represent, and they can run code at each time step in the simulation model’s execution to update digital twin state over time. These digital twins also can exchange messages that model interactions.
For example, an airline tracking system can use simulation to model numerous types of weather delays and system outages (such as ground stops) to see how their system manages passenger needs. As the simulation model evolves over time, simulated aircraft can model flight delays and send messages to simulated passengers that react by updating their itineraries. Here is a depiction of an airline tracking simulation:
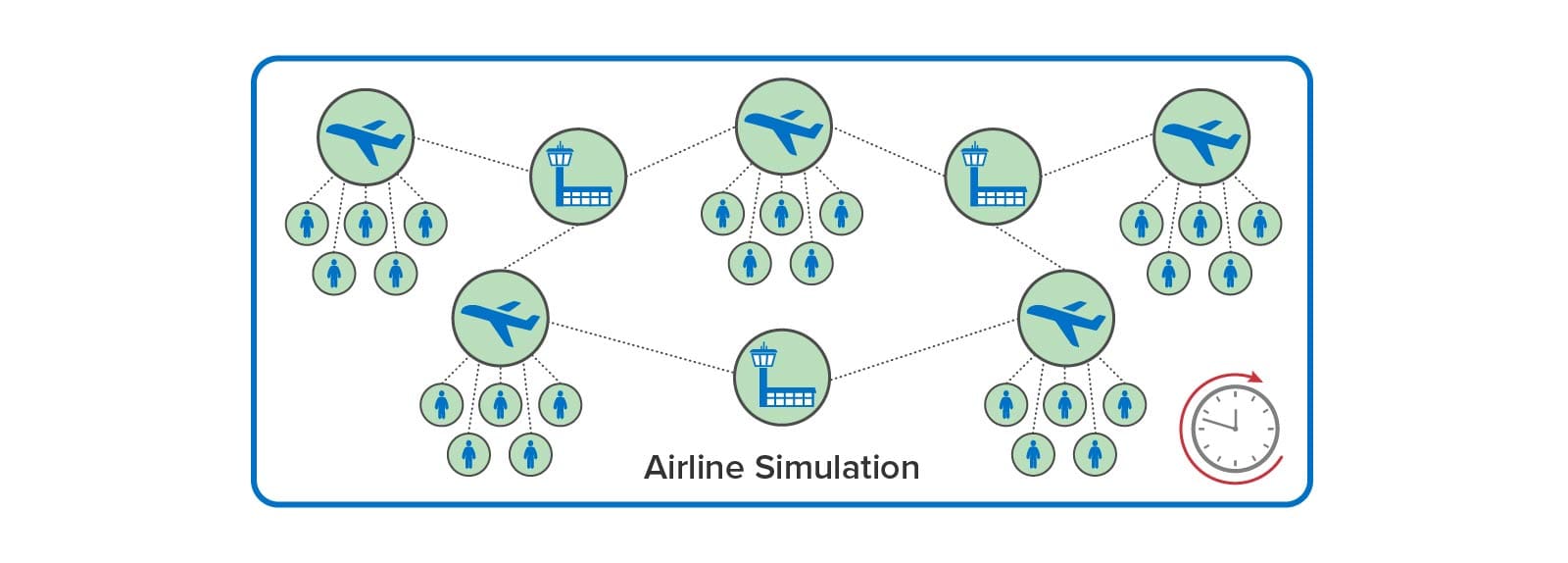
In contrast to the use of digital twins for PLM, which typically embody a complex design within a single digital twin model, the ScaleOut Digital Twin Streaming Service enables large numbers of physical entities and their interactions to be simulated. By doing this, simulations can model intricate behaviors that evolve over time and reveal important insights during system design and optimization. They also can be fed live data and run faster than real time as a tool for making predictions that assist decision-making by managers (such as airline dispatchers).
Scalable, In-Memory Computing Makes It Possible
Digital twins offer a compelling software architecture for implementing time-driven simulations with thousands of entities. In a typical implementation, developers create multiple digital twin models to describe the state information and simulation code representing various physical entities, such as trucks, cargo, and warehouses in a telematics simulation. They create instances of these digital twin models (simply called digital twins) to implement all of the entities being simulated, and the streaming service runs their code at each time step being simulated. During each time step, digital twins can exchange messages that represent simulated interactions between physical entities.
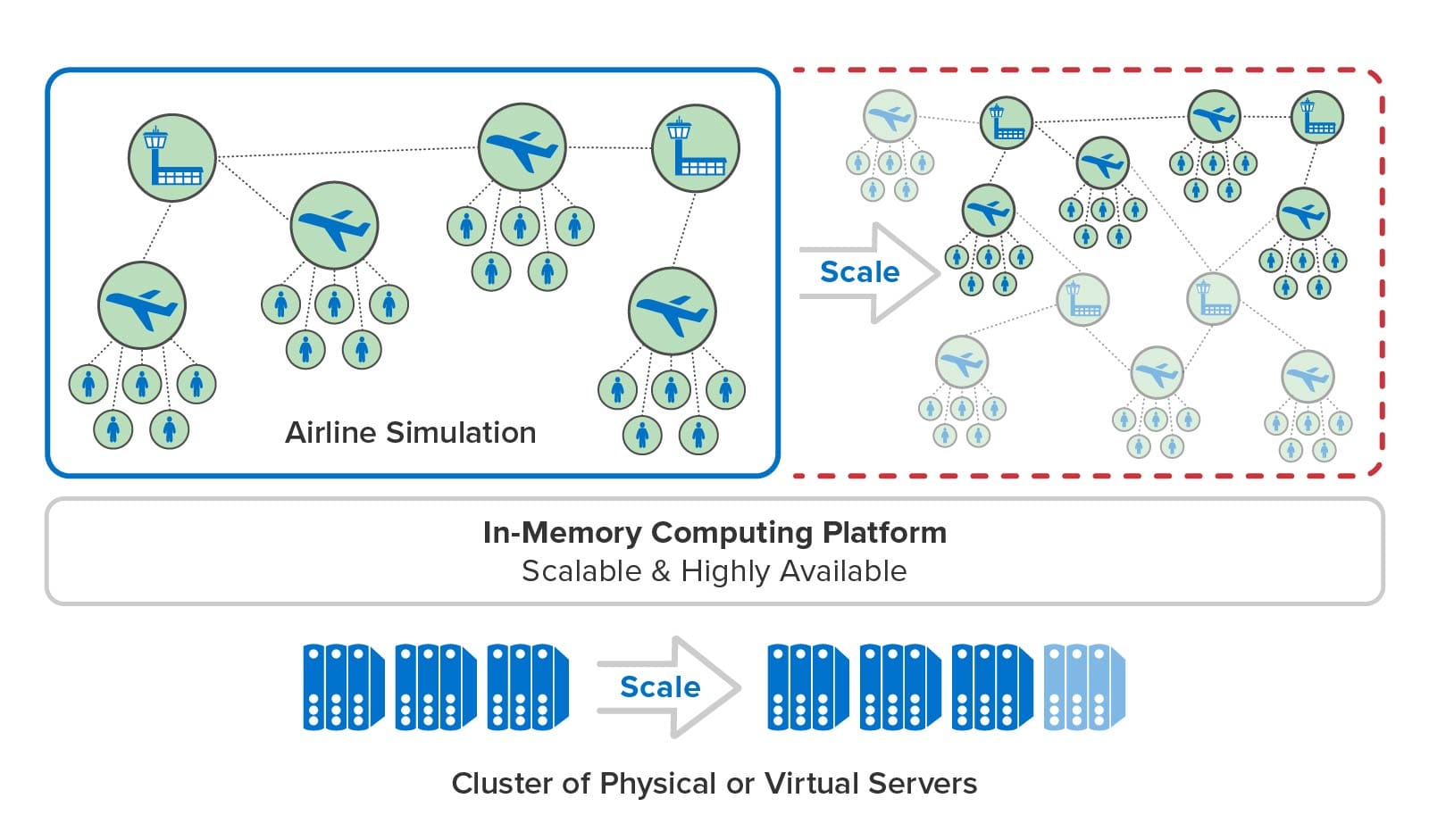
The ScaleOut Digital Twin Streaming Service uses scalable, in-memory computing technology to provide the speed and memory capacity needed to run large simulations with many entities. It stores digital twins in memory and automatically distributes them across a cluster of servers that hosts a simulation. At each time step, each server runs the simulation code for a subset of the digital twins and determines the next time step that the simulation needs to run. The streaming service orchestrates the simulation’s progress on the cluster and advances simulation time at a rate selected by the user.
In this manner, the streaming service can harness as many servers as it needs to host a large simulation and run it with maximum throughput. As illustrated below, the service’s in-memory computing platform can add new servers while a simulation is running, and it can transparently handle server outages should they occur. Users need only focus on building digital twin models and deploying them to the streaming service.
The Next Generation of Simulation with Digital Twins
Digital twins have historically been employed as a tool for simulating increasingly detailed behavior of a complex physical entity, like a jet engine. The ScaleOut Digital Twin Streaming Service takes digital twins in a new direction: simulation of large systems. Its highly scalable, in-memory computing architecture enables it to easily simulate many thousands of entities and their interactions. This provides a powerful new tool for extracting insights about complex systems that today’s managers must operate at peak efficiency. Its analytics and predictive capabilities promise to offer a high return on investment in many industries.
The post Simulate at Scale with Digital Twins appeared first on ScaleOut Software.
]]>The post Steve Smith Review: Simplify Redis Clustering with ScaleOut IMDB appeared first on ScaleOut Software.
]]>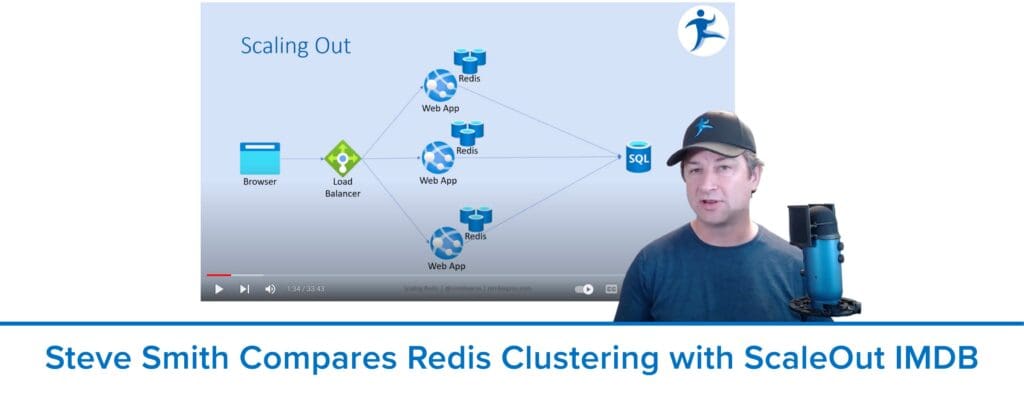
Check out the blog post and video from distinguished software architect and .NET guru Steve “ardalis” Smith on the challenges of scaling single-server Redis and how ScaleOut In-Memory Database tackles them with fully automated cluster technology to avoid complex manual configuration steps.
Steve Smith is a well-known entrepreneur and software developer. He is passionate about building quality software and spreading his knowledge through training workshops, speaking at developer conferences, and sharing his experience on his blog and podcast. Steve Smith has also been recognized as a Microsoft MVP for over ten consecutive years.
The post Steve Smith Review: Simplify Redis Clustering with ScaleOut IMDB appeared first on ScaleOut Software.
]]>The post New Video: Automated Clustering for Redis appeared first on ScaleOut Software.
]]> (IMDB) automates Redis clustering so that you can add and remove servers with a single command — starting with just two servers. ScaleOut IMDB also ensures that the cluster implements strong consistency to keep stored data safe and IT costs low.
Subscribe to ScaleOut’s YouTube channel to see the latest explainer videos, interviews, tech talks and more!
The post New Video: Automated Clustering for Redis appeared first on ScaleOut Software.
]]>