The post ScaleOut Software Adds Google Cloud Support Across Products appeared first on ScaleOut Software.
]]>BELLEVUE, WASH. — June 15, 2023 — ScaleOut Software today announced that its product suite now includes Google Cloud support. Applications running in Google Cloud can take advantage of ScaleOut’s industry leading distributed cache and in-memory computing platform to scale their performance and run fast, data-parallel analysis on dynamic business data. The ScaleOut Product Suite is a comprehensive collection of production-proven software products, including In-Memory Database, StateServer, GeoServer, Digital Twin Streaming Service, StreamServer and more. This integration complements ScaleOut’s existing Amazon EC2 and Microsoft Azure Cloud support to provide comprehensive multi-cloud capabilities.
is a comprehensive collection of production-proven software products, including In-Memory Database, StateServer, GeoServer, Digital Twin Streaming Service, StreamServer and more. This integration complements ScaleOut’s existing Amazon EC2 and Microsoft Azure Cloud support to provide comprehensive multi-cloud capabilities.
“We are excited to add Google Cloud Platform support for hosting the ScaleOut Product Suite,” said Dr. William Bain, CEO of ScaleOut Software. “This support further broadens the public cloud options available to our customers for hosting our industry-leading distributed cache and in-memory analytics. Google’s impressive performance enables our distributed cache to deliver the full benefits of automatic throughput scaling to applications.”
Key benefits of ScaleOut’s support for the Google Cloud Platform include:
- Simplified Deployment and Management: Users can take advantage of the ScaleOut Management Console to deploy a distributed cache to Google Cloud using a step-by-step wizard and track its status.
- Automatic Clustering: Distributed caches comprising one or more virtual servers automatically create a single compute cluster to serve client requests with both scalability and high availability.
- Automatic Client Connectivity: Client applications running either within Google Cloud or from remote sites can automatically connect to all caching servers within a cluster just by specifying the cluster’s name.
- Elastic Performance: Using the management console, users can add or remove virtual servers from a distributed cache to meet the needs of application workloads. In addition, users can implement auto-scaling policies based on performance measures, such as memory usage.
Distributed caches, such as the ScaleOut Product Suite, allow applications to store fast-changing data, such as e-commerce shopping carts, stock prices, and streaming telemetry, in memory with low latency for rapid access and analysis. Built using a cluster of virtual or physical servers, these caches automatically scale access throughput and analytics to handle large workloads. In addition, they provide built-in high availability to ensure uninterrupted access if a server fails. They are ideal for hosting on cloud platforms, which offer highly elastic computing resources to their users without the need for capital investments.
For more information, please visit www.scaleoutsoftware.com and follow @ScaleOut_Inc on Twitter.
Additional Resources:
- ScaleOut Google Cloud Platform blog post
- ScaleOut Product Suite information
About ScaleOut Software
Founded in 2003, ScaleOut Software develops leading-edge software that delivers scalable, highly available, in-memory computing and streaming analytics technologies to a wide range of industries. ScaleOut Software’s in-memory computing platform enables operational intelligence by storing, updating, and analyzing fast-changing, live data so that businesses can capture perishable opportunities before the moment is lost. It has offices in Bellevue, Washington and Beaverton, Oregon.
Media Contact
Brendan Hughes
RH Strategic for ScaleOut Software
ScaleOutPR@rhstrategic.com
206-264-0246
The post ScaleOut Software Adds Google Cloud Support Across Products appeared first on ScaleOut Software.
]]>The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>
by Olivier Tritschler, Senior Software Engineer
Because of their ability to provide highly elastic computing resources, public clouds have become a highly attractive platform for hosting distributed caches, such as ScaleOut StateServer®. To complement its current offerings on Amazon AWS and Microsoft Azure, ScaleOut Software has just announced support for the Google Cloud Platform. Let’s take a look at some of the benefits of hosting distributed caches in the cloud and understand how we have worked to make both deployment and management as simple as possible.
Distributed Caching in the Cloud
Distributed caches, like ScaleOut StateServer, enhance a wide range of applications by offering shared, in-memory storage for fast-changing state information, such as shopping carts, financial transactions, geolocation data, etc. This data needs to be quickly updated and shared across all application servers, ensuring consistent tracking of user state regardless of the server handling a request. Distributed caches also offer a powerful computing platform for analyzing live data and generating immediate feedback or operational intelligence for applications.
Built using a cluster of virtual or physical servers, distributed caches automatically scale access throughput and analytics to handle large workloads. With their tightly integrated client-side caching, these caches typically provide faster access to fast-changing data than backing stores, such as blob stores and database servers. In addition, they incorporate redundant data storage and recovery techniques to provide built-in high availability and ensure uninterrupted access if a server fails.
To meet the needs of elastic applications, distributed caches must themselves be elastic. They are designed to transparently scale upwards or downwards by adding or removing servers as the workload varies. This is where the power of the cloud becomes clear.
Because cloud infrastructures provide inherent elasticity, they can benefit both applications and distributed caches. As more computing resources are needed to handle a growing workload, clouds can deploy additional virtual servers (also called cloud “instances”). Once a period of high demand subsides, resources can be dialed back to minimize cost without compromising quality of service. The flexibility of on-demand servers also avoids costly capital investments and reduces management costs.
Deploying ScaleOut’s Distributed Cache in the Google Cloud
A key challenge in using a distributed cache as part of a cloud-hosted application is to make it easy to deploy, manage, and access by the application. Distributed caches are typically deployed in the cloud as a cluster of virtual servers that scales as the workload demands. To keep it simple, a cloud-hosted application should just view a distributed cache as an abstract entity and not have to keep track of individual caching servers or which data they hold. The application does not want to be concerned with connecting N application instances to M caching servers, especially when N and M (as well as cloud IP addresses) vary over time. In particular, an application should not have to discover and track the IP addresses for the caching servers.
Even though a distributed cache comprises several servers, the simplest way to deploy and manage it in the cloud is to identify the cache as a single, coherent service. ScaleOut StateServer takes this approach by identifying a cloud-hosted distributed cache with a single “store” name combined with access credentials. This name becomes the basis for both managing the deployed servers and connecting applications to the cache. It lets applications connect to the caching cluster without needing to be aware of the IP addresses for the cluster’s virtual servers.
The following diagram shows a ScaleOut StateServer distributed cache deployed in Google Cloud. It shows both cloud-hosted and on-premises applications connected to the cache, as well as ScaleOut’s management console, which lets users deploy and manage the cache. Note that while the distributed cache and applications all contain multiple servers, applications and users can access the cache just by using its store name.
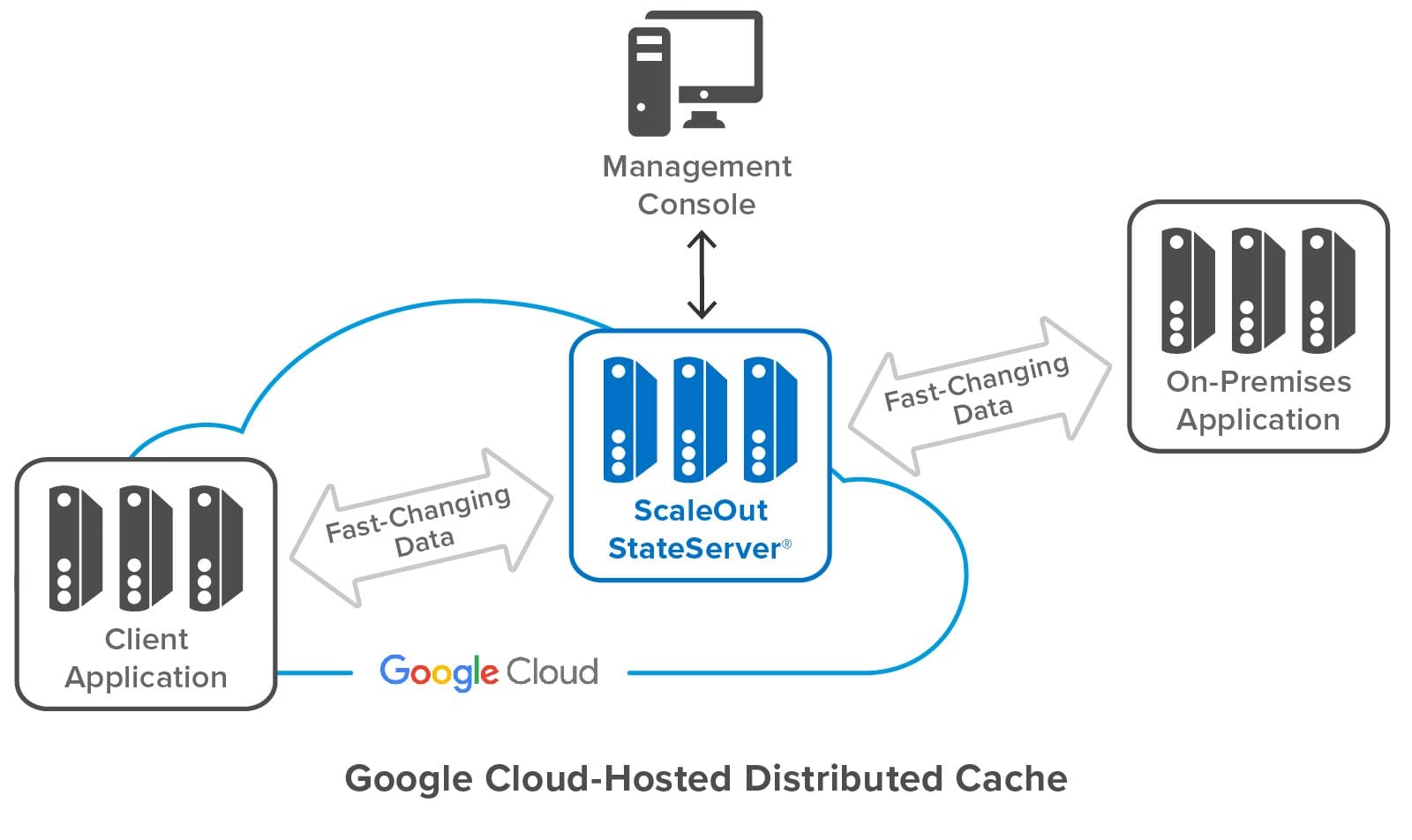
Building on the features developed for the integration of Amazon AWS and Microsoft Azure, the ScaleOut Management Console now lets users deploy and manage a cache in Google Cloud by just specifying a store name and initial number of servers, as well as other optional parameters. The console does the rest, interacting with Google Cloud to start up the distributed cache and configure its servers. To enable the servers to form a cluster, the console records metadata for all servers and identifies them as having the same store name.
Here’s a screenshot of the console wizard used for deploying ScaleOut StateServer in Google Cloud:
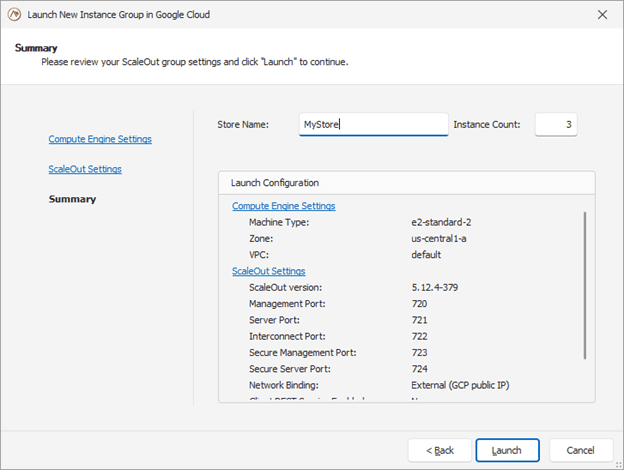
The management console provides centralized, on-premises management for initial deployment, status tracking, and adding or removing servers. It uses Google’s managed instance groups to host servers, and automated scripts use server metadata to guarantee that new servers automatically connect with an existing store. The managed instance groups used by ScaleOut also support defining auto-scaling options based on CPU/Memory usage metrics.
Instead of using the management console, users can also deploy ScaleOut StateServer to Google Cloud directly with Google’s Deployment Manager using optional templates and configuration files.
Simplifying Connectivity for Applications
On-premises applications typically connect each client instance to a distributed cache using a fixed list of IP addresses for the caching servers. This process works well on premises because the cache’s IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of a caching server.
To avoid this problem, ScaleOut StateServer lets client applications specify a store name and credentials to access a cloud-hosted distributed cache. ScaleOut’s client libraries internally use this store name to discover the IP addresses of caching servers from metadata stored in each server.
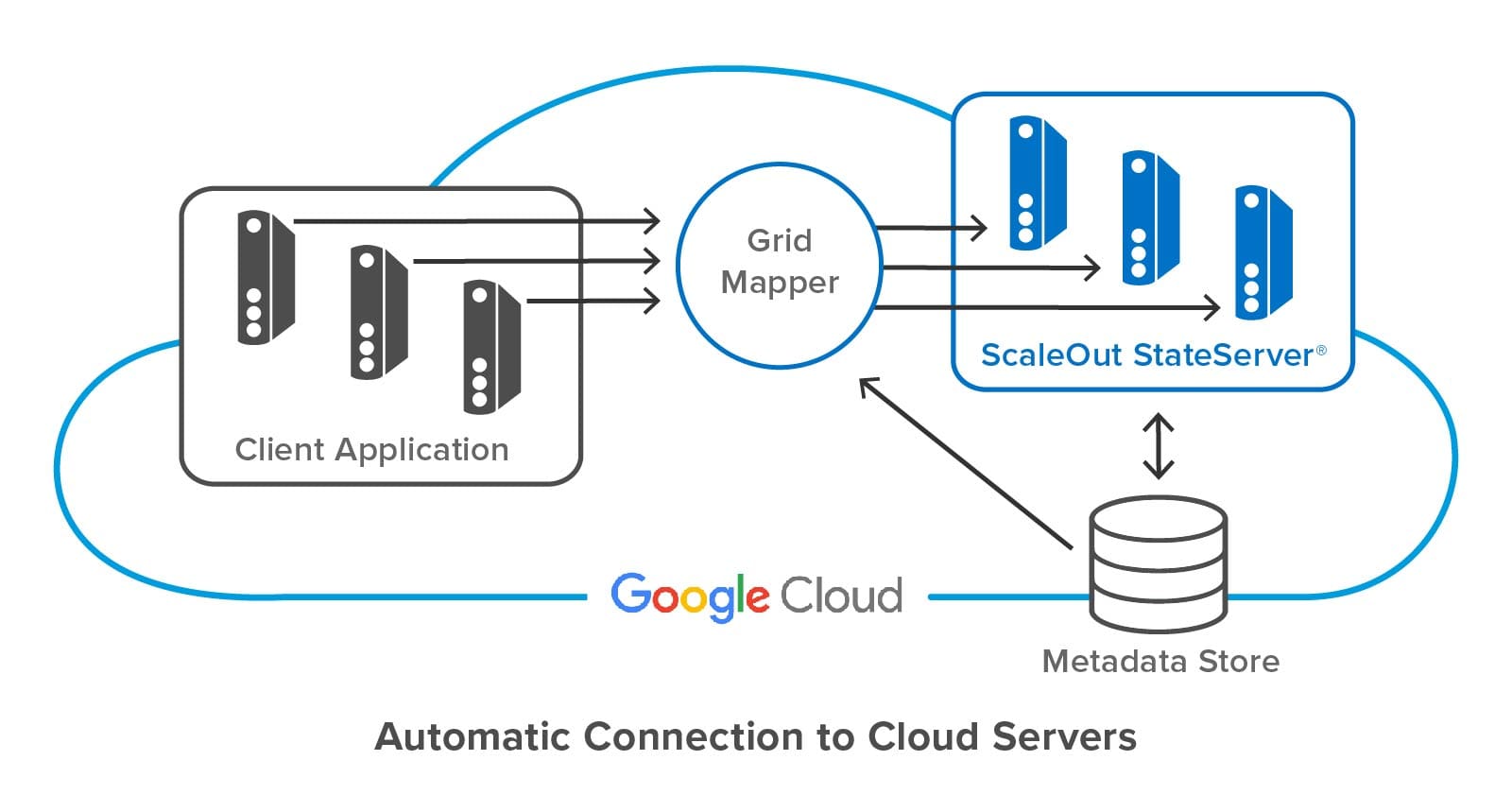
The following diagram shows a client application connecting to a ScaleOut StateServer distributed cache hosted in Google Cloud. ScaleOut’s client libraries make use of an internal software component called a “grid mapper” which acts as a bootstrap mechanism to find all servers belonging to a specified cache using its store name. The grid mapper accesses the metadata for the associated caching servers and returns their IP addresses back to the client library. The grid mapper handles any potential changes in IP addresses, such as servers being added or removed for scaling purposes.
Summing up
Because they provide elastic computing resources and high performance, public clouds, such as Google Cloud, offer an excellent platform for hosting distributed caches. However, the ephemeral nature of their virtual servers introduces challenges for both deploying the cluster and connecting applications. Keeping deployment and management as simple as possible is essential to controlling operational costs. ScaleOut StateServer makes use of centralized management, server metadata, and automatic client connections to address these challenges. It ensures that applications derive the full benefits of the cloud’s elastic resources with maximum ease of use and minimum cost.
The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>The post Announcing the ScaleOut Digital Twin Streaming Service™ appeared first on ScaleOut Software.
]]>, and it’s now available for production use. Sign up to use the service here.
A major challenge for stream-processing applications that track numerous data sources in real time is to analyze telemetry relevant to each specific data source and combine this with dynamic, contextual information about the data source to enable immediate action when necessary. For example, heart-rate telemetry from a smart watch cannot be effectively evaluated in isolation. Instead, it needs to be combined with knowledge of each person’s age, health, medications, and activity to determine when an alert should be generated.
A second and equally daunting challenge for live systems is to maintain real-time situational awareness about the state of all data sources so that strategic responses can be implemented, especially when a rapid sequence of events is unfolding. Whether it’s a rental car fleet with 100K vehicles on the road or a power grid with 40K nodes subject to outages, system managers need to quickly identify the scope of emerging problems and rapidly focus resources where most needed.
Traditional platforms for streaming analytics attempt to look at the entire telemetry pipeline using techniques such as SQL query to uncover and act on patterns of interest. But this approach is complex and leads to superficial analysis in real time, forcing telemetry to be logged into a data lake for later analysis using Spark or other tools. How do you trigger an alert to the wearer of a smart watch at the exact moment that the combination of telemetry fluctuations and knowledge about the individual’s health indicate that an alert is needed?
The key to creating straightforward stream-processing applications that can deal with these challenges lies in a software concept called the “real-time digital twin model.” Borrowed from its use in the field of product life-cycle management, real-time digital twins host application code that analyzes incoming telemetry (event messages) from each individual data source and maintains dynamically evolving information about the data source. This approach refactors and simplifies application code (which can be written in standard Java, C#, or JavaScript) to just focus on a single data source, introspect deeply, and better predict important events.
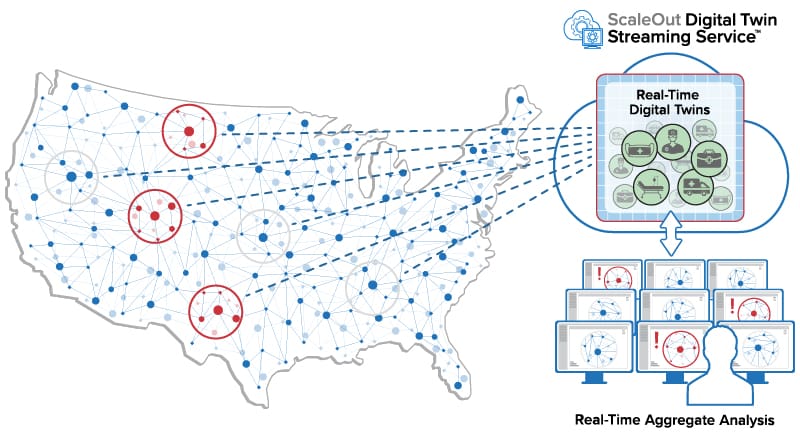
The following diagram illustrates how the ScaleOut Digital Twin Streaming Service hosts real-time digital twins that receive telemetry from individual data sources and send responses, including commands and alerts:
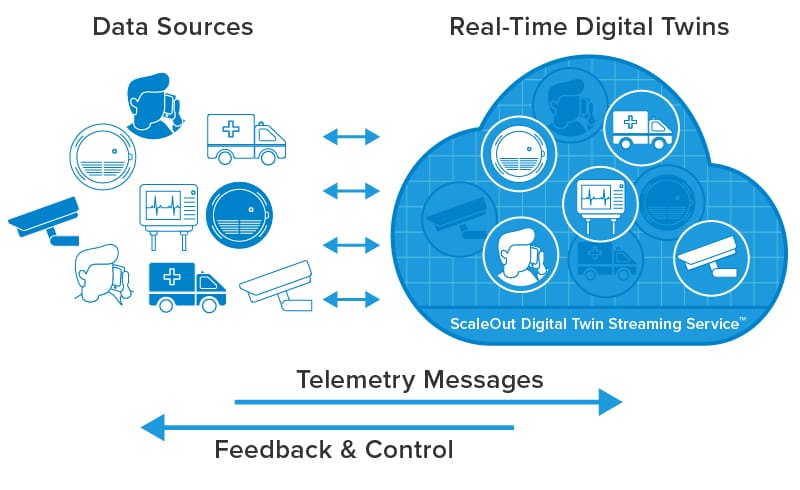
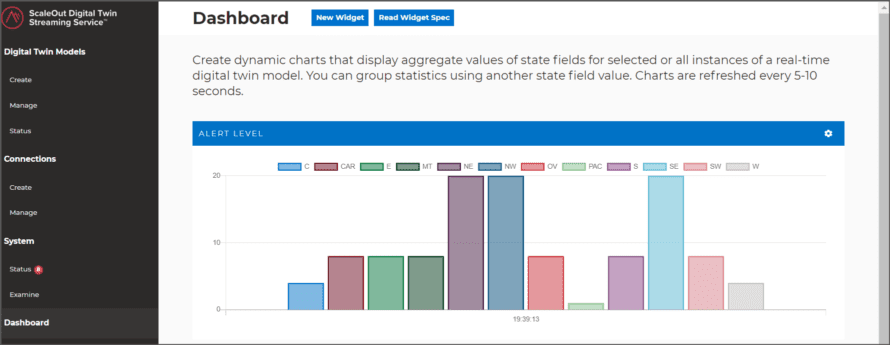
Because real-time digital twins maintain and dynamically update key information about each data source, aggregate analytics — essentially, continuous queries — can continuously look for patterns in this curated data instead of in just the raw telemetry. This enables immediate, focused insights that enhance situational awareness. For example, the streaming service can generate a bar chart every few seconds to aggregate and highlight alerts by region generated by examining properties of real-time digital twins for thousands of data sources:
The ScaleOut Digital Twin Streaming Service plugs into popular event hubs, such as Azure IoT Hub, AWS IoT Core, and Kafka, to extract event messages and forward them to real-time digital twin instances, one for each data source. It then triggers application code to process the messages and gives it immediate access to memory-based contextual information for the data source. Application code can generate alerts, command devices, update the contextual information, and read or update databases as needed. This code can be thought of as similar to a serverless function with the major distinction that it is automatically supplied contextual information and does not have to maintain it in an external data store.
This highly scalable cloud service is designed to simultaneously and cost-effectively track telemetry from millions of data sources and provide real-time feedback in milliseconds while simultaneously performing continuous, aggregate analytics every few seconds. A powerful UI enables fast deployment of real-time digital twin models created using the ScaleOut Digital Twin Builder software toolkit. The UI lets users build graphical widgets which create and chart aggregate statistics. Under the floor, a powerful in-memory data grid with an integrated compute engine transparently ensures fast, predictable performance.
Given the current COVID-19 crisis, here’s a use case in which the streaming service can assist in prioritizing the distribution of critical medical supplies to the nation’s hospitals. Hospitals distributed across the United States can send status updates to the cloud service regarding their shortfall of supplies such as ventilators and personal protective equipment. Within milliseconds, a dedicated real-time digital twin instance for each hospital can analyze incoming messages to track and evaluate the need for supplies, determine the hospital’s overall shortfall, and assess the urgency for immediate action, as depicted below:
The streaming service can then simultaneously analyze these results across the population of digital twin instances to determine in seconds which regions are exhibiting the most critical shortfall. This alerts logistics managers, who can then query the digital twins to identify specific hospitals and implement a strategic response:
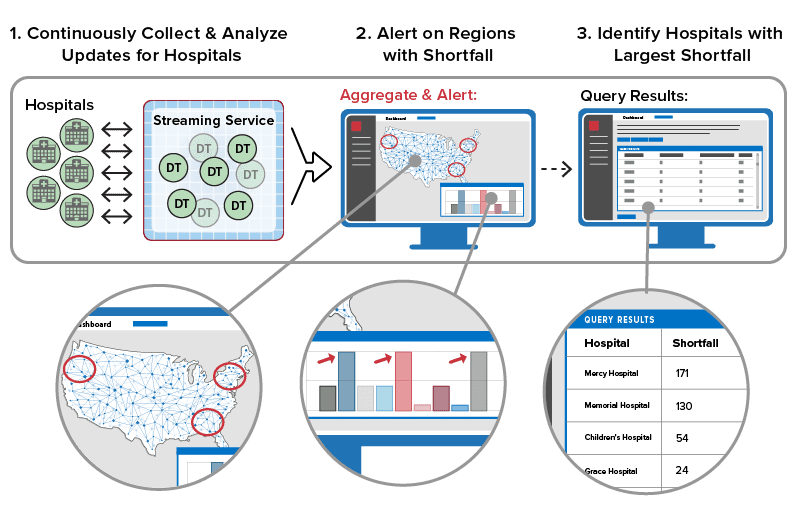
The real-time digital twin approach creates a breakthrough for application developers that both simplifies application development and enhances introspection. It’s ideal for a wide range of applications, including real-time intelligent monitoring (the example above), Industrial Internet of Things (IIoT), logistics, security and disaster recovery, e-commerce recommendations, financial services, and much more. The ScaleOut Digital Twin Streaming Service is available now. We invite interested users to contact us here to learn more.
The post Announcing the ScaleOut Digital Twin Streaming Service™ appeared first on ScaleOut Software.
]]>The post What’s New in ScaleOut StateServer® Version 5.1 appeared first on ScaleOut Software.
]]>New C++ APIs
We introduced ScaleOut StateServer® almost exactly nine years ago and have worked continuously since then to add features requested by our customers and boost the product’s performance. Version 5.1 contains several exciting new capabilities, led by our introduction of C++ APIs. Our goal was to make these C++ APIs as easy to use as possible. So the first decision was to make them open source. This allows developers to build the APIs for a variety of compilers starting with GCC 4.4 (circa 2009) and newer. To strike a balance that allows support for the older compilers used on some enterprise-grade distributions of Linux, some newer C++11 features were not used, and the APIs use the widely-available Boost C++ libraries instead. (Releases of Boost going back to version 1.41 have been verified to work.) So, for example, rather than returning a std::shared_ptr to a retrieved object, the API returns a boost::shared_ptr. The C++ APIs are also available for Windows developers; we ship pre-built libraries for Visual Studio 2013 users in the release.
The next big challenge with the C++ APIs was how to handle data serialization, which is needed to store objects within an out-of-process, in-memory data grid (IMDG). We first introduced C# APIs in 2005, and then added Java APIs in 2008. Unlike C++, both of these languages have built-in serializers; ScaleOut StateServer uses these serializers by default to keep application development as simple for the user as possible. Looking at other IMDGs in the market, we did not want to go down the same path of requiring the use of serialization APIs provided by the IMDG vendor (us in this case). So we chose to offer integrated support for the popular Google Protocol Buffer encoding standard (with optional indexing of annotated fields to support parallel query) and also provide an extensible API mechanism that allows users to build custom serializers.
Replicating Data to the Cloud
With version 5.1, we also extended support for data replication and remote access to IMDGs hosted in public clouds using our ScaleOut GeoServer® product. This product lets users connect a local IMDG to one or more remote IMDGs so that data can be replicated off-site in case of a site-wide failure; it also allows transparent access to data stored at remote sites using the IMDG’s APIs for local data access. With this release, remote IMDGs hosted in Amazon Web Services or Windows Azure can be accessed by ScaleOut GeoServer (and by client applications) with full support for secure connections using SSL.
The challenge with accessing cloud-based IMDGs is that it is clumsy to bootstrap connectivity using IP addresses, as is standard practice for on-premise grids, since these IP addresses are highly dynamic. To solve this problem, we created a simple mechanism (first introduced in version 5.0 for remote clients) which binds clients and remote IMDGs to a cloud-hosted IMDG using a simple combination of account credentials and a “store” name. We then retrieve cloud-based metadata to automatically identify and configure the current IP addresses and ports for the client or remote IMDG. The net effect is that configuring ScaleOut GeoServer to access a cloud-hosted IMDG is simple and secure.
Real-Time Hadoop MapReduce for Windows
With 5.1, we also rolled out the Windows version of our ScaleOut hServer® product, which lets developers create and run Hadoop MapReduce applications on grid-based data. This enables analysis of “live”, fast-changing data held within the IMDG, and it also delivers real-time results in milliseconds to a few seconds (instead of the minutes to hours required by standard, open source Hadoop distributions). Now users can run ScaleOut hServer on both Linux and Windows. We also added support for the Cloudera CDH4 Hadoop APIs to supplement support for the Apache Hadoop 1.X APIs.
Eliminating Network Bottlenecks
Some of the most exciting enhancements in version 5.1 deal with the internal architecture of ScaleOut’s IMDG. Over the last nine years, we have watched advances in CPU, memory, and networking technology. Unfortunately, these advances occur at different times and put stress in varying parts of the IMDG’s architecture. Today’s IMDGs often are deployed on clusters of servers each with 32 GB memory or higher (instead of 2 GB, which was common in 2005) and 8 or more i7 or Xeon cores. However, network bandwidth has only jumped 10X to 1 Gbps from 100 Mbps since 2005, while 10 Gbps Ethernet and Infiniband await widespread adoption in clusters of commodity servers. The net effect is that IMDG applications can easily saturate a gigabit network as servers are added to the cluster, especially when large objects are stored.
To help address this, we have streamlined the IMDG’s internal transport protocol used for load-balancing to boost its effective throughput by as much as 5X. This allows load-balancing to complete much faster after a server is added or removed from the IMDG.
Detecting Failures in Virtualized Environments
Another big technology change we have seen over the last nine years is the migration to virtualized environments; many if not most of our customer deployments are now hosted on virtual servers. Because it’s all too easy to overload the underlying physical servers with too many VMs, we often see intermittent network or processing delays caused by maxing out the CPU and NIC and sometimes by paging grid-hosted memory. These transient delays make it difficult to build a reliable heart-beating mechanism to recognize and recover from server or network outages (by looking for missing heartbeat messages between servers). Version 5.0 incorporated an adaptive heart-beating mechanism that responded to intermittent delays but could be spoofed by the unpredictable behavior of virtualized systems.
We now have fully revised this mechanism with new heuristics that more effectively identify and ignore these transient delays. ScaleOut StateServer measures the network for a full 24 hours before tightening its parameters for treating a heartbeat delay as a real outage, and it fully re-measures the network after a failure is detected. (Because it’s important to handle real outages quickly, allowed heartbeat delays must be kept as short as possible.) Our tests show that this approach minimizes service interruptions caused by erratic delays endemic to virtualized environments. However, it’s important to note that because of its heuristic nature, heart-beating can interpret communication delays as server failures.
We hope this tour of version 5.1 has helped illustrate our ongoing goals to maximize both ease of use and application performance, two core objectives of our IMDG and analytics technology. Please let us know your thoughts and comments.
The post What’s New in ScaleOut StateServer® Version 5.1 appeared first on ScaleOut Software.
]]>