The post ScaleOut Software Releases Open-Source APIs for Digital Twins and Development Workbench appeared first on ScaleOut Software.
]]>BELLEVUE, WASH. — December 12 — ScaleOut Software today announces the first open-source release of its digital twin APIs and development workbench for its ScaleOut Digital Twins hosting platform. Digital twin APIs allow developers to build powerful applications for real-time monitoring and simulating large systems. The workbench enables fast development and testing of digital twin applications before deployment. To help accelerate the development of digital twin applications, ScaleOut Software is releasing these components as open source under the Apache 2.0 license.
hosting platform. Digital twin APIs allow developers to build powerful applications for real-time monitoring and simulating large systems. The workbench enables fast development and testing of digital twin applications before deployment. To help accelerate the development of digital twin applications, ScaleOut Software is releasing these components as open source under the Apache 2.0 license.
Going beyond product lifecycle management (PLM), which focuses on improving product design, digital twins enable important new capabilities for real-time monitoring and simulating systems with thousands of components. For example, they allow applications to analyze streaming data in real time instead of requiring offline batch analytics. They can also simulate large complex systems to improve design choices and decision making. Digital twins offer key benefits to data analysts and managers in a wide range of industries, including transportation, logistics, security, healthcare, disaster recovery, and financial services.
“We are excited to open source our digital twin APIs and new development workbench so that application developers can easily use digital twins to create a new generation of applications,” said Dr. William Bain, ScaleOut Software’s CEO and founder. “These freely accessible software components should simplify and accelerate the development of digital twin applications and encourage community participation.”
The ScaleOut Digital Twins platform uses highly scalable, in-memory computing technology to host thousands of digital twins for monitoring real-time data from IoT devices and other data sources, enabling real-time analytics that provides actionable results in seconds. The platform also runs large-scale simulations that aid in the design of complex systems, such as airline logistics and traffic control networks.
Application developers use ScaleOut’s open-source APIs to build digital twin models for deployment on the ScaleOut Digital Twins platform. They can now use the open-source workbench to test application code built using these APIs and gain immediate feedback that shortens the design cycle. Once tested, developers can deploy applications on the platform to run at scale with thousands of digital twins.
Key Features and Benefits for ScaleOut Software’s Digital Twin APIs and Workbench:
- Easily Build Digital Twin Models: ScaleOut’s open-source APIs enable developers to build digital twin models in Java or C#. These models serve as templates for creating digital twins. The APIs employ standard, object-oriented design principles to simplify development and avoid the use of specialized or platform-specific techniques.
- Easily Test Digital Twin Models: ScaleOut’s open-source workbench lets developers test their digital twin models for both real-time monitoring and simulation in the user’s native development and test environment. The workbench accelerates application development by avoiding the need to deploy models to the hosting platform during the development process.
- Greater Ease of Access and Flexibility: Because ScaleOut’s digital twin APIs and workbench are freely available as open-source components, developers can download them at no cost and immediately start building digital twin applications. These APIs can also serve as the basis for creating digital twins that run on other platforms and provide cross-platform compatibility.
- Enable High Performance: ScaleOut’s digital twin model simplifies hosting on scalable, in-memory computing platforms. In-memory hosting dramatically reduces latency when digital twins access state information or process messages for both real-time analytics and simulation. It also enables high processing rates that support the creation of thousands of digital twins.
For more information, please visit www.scaleoutdigitaltwins.com and follow @ScaleOut_Inc on Twitter.
Additional Resources:
- ScaleOut Open Source APIs and Workbench Blog Post
- ScaleOut Digital Twins Product Page
- GitHub Repositories for Java and C# Open-Source APIs
About ScaleOut Software
Founded in 2003, ScaleOut Software develops leading-edge software that delivers scalable, highly available, in-memory computing and streaming analytics technologies to a wide range of industries. ScaleOut Software’s in-memory computing platform enables operational intelligence by storing, updating, and analyzing fast-changing, live data so that businesses can capture perishable opportunities before the moment is lost. It has offices in Bellevue, Washington and Beaverton, Oregon.
Media Contact
Brendan Hughes
RH Strategic for ScaleOut Software
ScaleOutPR@rhstrategic.com
206-264-0246
The post ScaleOut Software Releases Open-Source APIs for Digital Twins and Development Workbench appeared first on ScaleOut Software.
]]>The post Preventing Train Derailments Using Digital Twins appeared first on ScaleOut Software.
]]>
Using Digital Twins to Track and Simulate Large Systems
For decades, digital twins have played a crucial role in the field of product lifecycle management (PLM), where they assist in the design and testing of many types of devices, from valves to jet engines. ScaleOut Software has pioneered the use of digital twin technology combined with in-memory computing to track the behavior of live systems with many components – such as vehicle fleets, IoT devices, and even people – to monitor status in real time and boost situational awareness for operational managers.
Now, both data analysts and system managers can also harness the power of digital twins to simulate the behaviors of complex systems with thousands of interacting entities. Digital twin simulations can provide invaluable information about complex interactions that are otherwise difficult to study. They can explore scenarios often found in live systems, informing decisions and helping to identify potential issues in the planning phase. They also empower professionals to validate real-time analytics prior to deployment and to make predictions that help manage live systems.
A Case Study: Rail Transportation Safety
Consider an important use case in transportation safety for the U.S. freight railway system. The U.S moves more than 1.6 billion tons of freight over 140,000 miles of track each year. In 2022, there were 1,164 train derailments that caused damage measured in the millions of dollars and cost multiple lives. For example, in February 2023, fifty freight cars derailed in East Palestine, Ohio in a widely publicized accident. How can digital twins help prevent similar emergencies?
Currently, track-side sensors detect mechanical issues that can cause derailments, such as severely overheated wheel bearings, and radio train engineers often too late to prevent an accident. In the Ohio event, the NTSB preliminary report described increasing temperatures reported by three rail-side “hot box” detectors before the accident occurred. The U.S. railway network places these detectors every few miles across the country:

Example of a hot box detector (BBT609 – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=25975512)
Hot box detectors capture the data needed to track increasing wheel bearing temperatures and predict impending derailments. However, safety systems need to harness this data more effectively to prevent these incidents. Digital twins can help.
Real-time analytics using digital twins can combine temperature information from multiple hot boxes to detect anomalies and take action faster, before small problems escalate into derailments. Cloud-hosted analytics can simultaneously track the entire rail network’s rolling stock using a scalable, in-memory computing platform, such as the ScaleOut Digital Twin Streaming Service, to host digital twins. They can continuously analyze patterns of temperature changes for each car’s wheel bearings, combine this with known information about the rail car, such as its maintenance history, and then assess the likelihood of failure and alert personnel within milliseconds. This use of contextual information also helps prevent false-positive alerts that create costly delays.
Using Digital Twin Simulations to Design and Test Real-Time Analytics
To help railway engineers develop and test new predictive analytics software, large-scale simulations can model the flow of information from the hundreds of thousands of freight cars that cross the U.S. each day, as well as the thousands of detectors placed along the tracks. These simulations can statistically simulate emerging wheel bearing issues to test how well real-time analytics software can detect impending failures before an accident occurs. Digital twins serve double duty here; they implement real-time analytics, and they model wheel bearing failures.
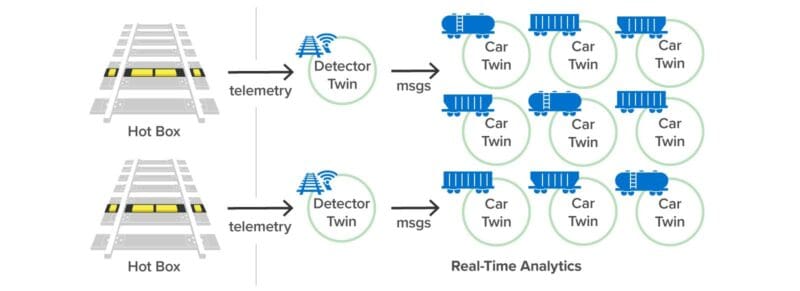
As a proof of concept, ScaleOut Software created a simulation of the U.S. freight rail system to evaluate how well digital twins can track wheel bearing temperatures from multiple hot box detectors and alert engineers to avoid derailments. The simulation runs as a discrete event simulation with digital twins exchanging messages in simulated time to model interactions.
Workload Generator
This workload generator creates 500-1000 simulated trains, each with 100 freight cars and 8 wheel bearings per car. The simulated trains travel on a hypothetical rail map that crisscrosses a hypothetical U.S. rail map with 107 routes between major U.S. cities:
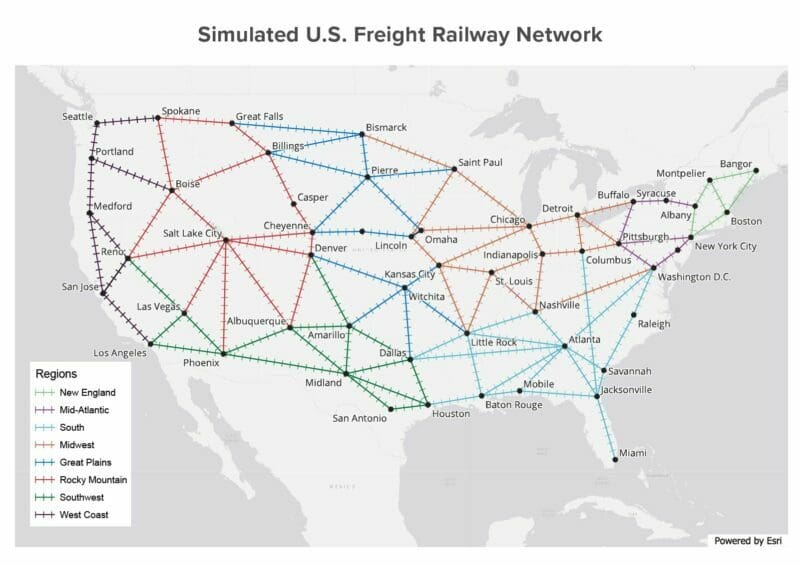
The simulated rail network places 3,800 hot box detectors approximately every 10 miles along the tracks. Each detector’s job is to report the wheel bearing temperatures for every freight car as a train passes it along the route, just as a real hot box detector would.
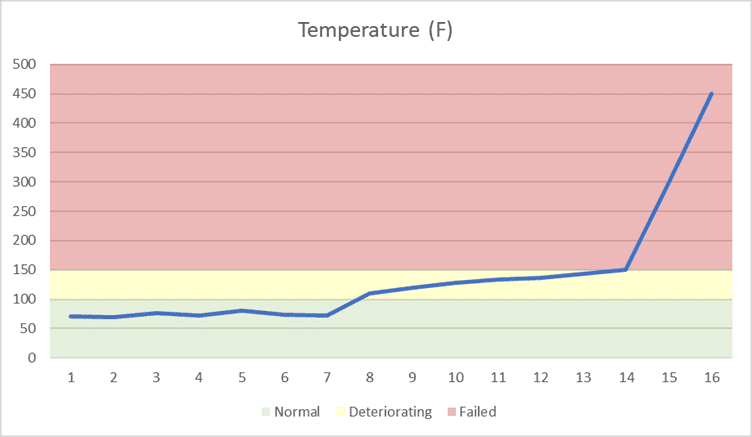
The simulation uses a separate digital twin model to implement trains and hot box detectors. (Each digital twin model has its own properties and algorithms.) A simulated train keeps track of its route, current position, speed, and freight cars. It also implements a probabilistic model of wheel bearing failures that cause a wheel bearing to enter a deteriorating state with a probability of 1:1M and then increase its temperature over time. As it passes a simulated detector, each train reports the temperature of all wheel bearings to the detector. After a deteriorating wheel bearing passes ten detectors, it increases to a 1:4 probability of entering a failed state with a rapid temperature rise. Once a bearing reaches 500 degrees Fahrenheit, the model considers it to have experienced a catastrophic failure, which corresponds to a fire or derailment.
Here is an example of a wheel bearing’s temperature profile as it passes detectors along the rails:
As simulated trains pass hot box detectors and report their wheel bearing temperatures, the detectors send a message to their corresponding real-time digital twins, which capture and analyze this telemetry.
The following diagram shows the simulation’s workload generator made up of digital twins:
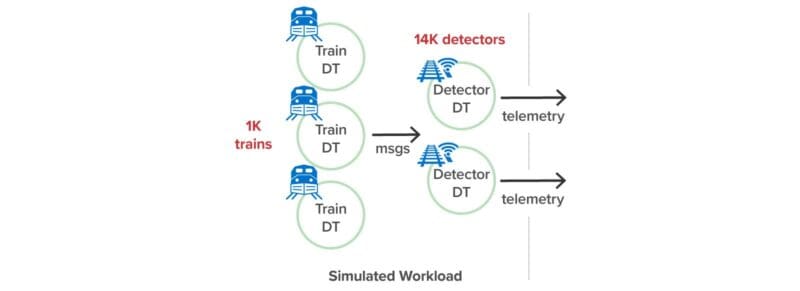
Real-Time Analytics
Digital twins also implement real-time analytics code for detecting wheel bearing failures. Once deployed in a data center for production use, they continuously track telemetry from real hot box detectors to look for possible wheel bearing failures and alert train engineers. In an actual deployment, existing hot box detectors would send messages over the cellular phone system to a cloud-based analytics service instead of just making radio broadcasts to nearby train personnel.
The analytics code uses two digital twin models, one for hot box detectors and another for individual train cars. The hot box detector twins receive telemetry messages from corresponding physical hot boxes along the tracks. Digital twins of train cars track telemetry and other relevant information about all the wheel bearings on each car. They build a picture over time of trends in wheel bearing temperatures reported by multiple detectors. They also can combine a temperature history with other contextual information, such as the type of wheel bearing and its service history, to best decide when a failure might be imminent.
In the simulation, train car digital twins just keep temperature histories for all wheel bearings and look for an upward trend over time. If a digital twin detects a potentially dangerous trend, it sends a message back to the simulated train, instructing it to stop.
To run the simulation, the workload generator sends messages to the real-time analytics: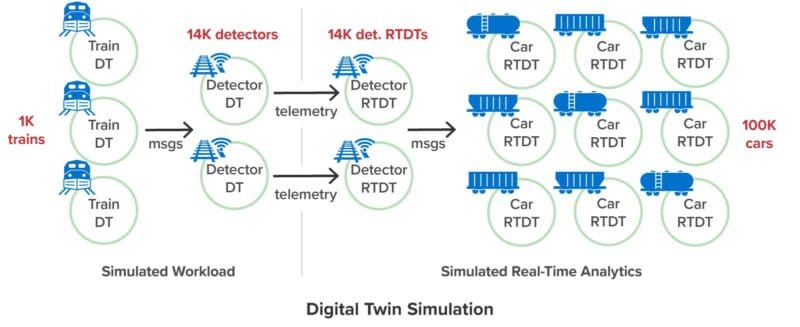
The same analytics twins can receive telemetry from actual hot box detectors after deployment:
Simulation Results
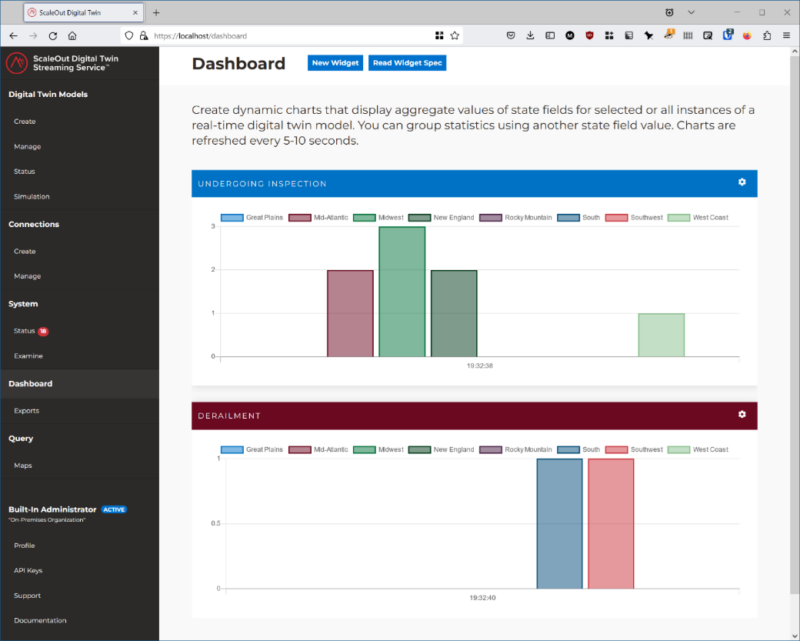
The simulation divides the U.S. rail network into regions. To check that trend analysis is working, we disable it in the south and southwest and compare it to other regions. The simulation shows that trend analysis catches all deteriorating bearings before they fail and cause derailments. Derailments only occur on routes not performing trend analysis.
The ScaleOut Digital Twin Streaming Service provides tools to visualize these results. The following dashboard widgets track the number of alerted trains by region that are undergoing inspection (because trend analysis detects an issue) along with the number of derailed trains. Note that derailments only occur in the regions with trend analysis disabled:
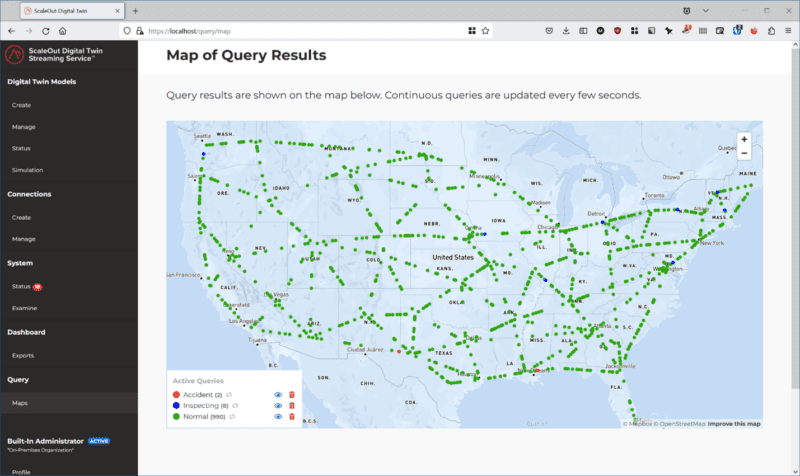
The following geospatial map of a continuous query shows the trains which are running normally in green, undergoing inspection in blue, and derailed in red. This map confirms that all derailed trains are located in the south and southwest regions and shows trains undergoing inspection in other regions:
Summing Up
The U.S. freight railways provide the backbone of the country’s freight transport system and must run with minimum disruptions. New technology like digital twins can take advantage of existing infrastructure to provide continuous monitoring that is missing today. Using scalable in-memory computing, digital twins can capture live telemetry throughout the rail system, analyze it in context, and create immediate alerts when needed. They can also implement simulations to model these issues and help planners evaluate real-time analytics software.
Beyond just watching wheel bearings, digital twins can track other areas of the rail system, such as rail intersections and switches, to further boost safety. With this technology, digital twins can help build next-generation safety systems to eliminate dangerous and costly derailments.
The post Preventing Train Derailments Using Digital Twins appeared first on ScaleOut Software.
]]>The post CEO William Bain Gives Talk for the Digital Twin Consortium appeared first on ScaleOut Software.
]]>In this talk, Dr. Bain described a new vision for digital twins that takes them beyond traditional applications to address challenges faced by managers of large systems with thousands or even millions of data sources. Digital twins can implement streaming analytics that continuously monitor these complex systems for emerging issues and help managers boost their situational awareness.
Numerous applications can benefit from this new use of digital twins. Examples described in the talk include tracking vehicle fleets and logistics networks, improving the safety of transportation systems, and assisting in disaster recovery.
ScaleOut Software’s in-memory computing technology makes it possible to simultaneously host thousands of digital twins and run both streaming analytics and simulations. The talk explains how this technology adds real-time aggregate analytics while lowering response times and scaling performance.
Download The Presentation Slides

- Learn more about the ScaleOut Digital Twin Streaming Service.
- Watch Dr. Bain’s previous digital twin talk.
The post CEO William Bain Gives Talk for the Digital Twin Consortium appeared first on ScaleOut Software.
]]>The post ScaleOut Software Adds Google Cloud Support Across Products appeared first on ScaleOut Software.
]]>BELLEVUE, WASH. — June 15, 2023 — ScaleOut Software today announced that its product suite now includes Google Cloud support. Applications running in Google Cloud can take advantage of ScaleOut’s industry leading distributed cache and in-memory computing platform to scale their performance and run fast, data-parallel analysis on dynamic business data. The ScaleOut Product Suite is a comprehensive collection of production-proven software products, including In-Memory Database, StateServer, GeoServer, Digital Twin Streaming Service, StreamServer and more. This integration complements ScaleOut’s existing Amazon EC2 and Microsoft Azure Cloud support to provide comprehensive multi-cloud capabilities.
“We are excited to add Google Cloud Platform support for hosting the ScaleOut Product Suite,” said Dr. William Bain, CEO of ScaleOut Software. “This support further broadens the public cloud options available to our customers for hosting our industry-leading distributed cache and in-memory analytics. Google’s impressive performance enables our distributed cache to deliver the full benefits of automatic throughput scaling to applications.”
Key benefits of ScaleOut’s support for the Google Cloud Platform include:
- Simplified Deployment and Management: Users can take advantage of the ScaleOut Management Console to deploy a distributed cache to Google Cloud using a step-by-step wizard and track its status.
- Automatic Clustering: Distributed caches comprising one or more virtual servers automatically create a single compute cluster to serve client requests with both scalability and high availability.
- Automatic Client Connectivity: Client applications running either within Google Cloud or from remote sites can automatically connect to all caching servers within a cluster just by specifying the cluster’s name.
- Elastic Performance: Using the management console, users can add or remove virtual servers from a distributed cache to meet the needs of application workloads. In addition, users can implement auto-scaling policies based on performance measures, such as memory usage.
Distributed caches, such as the ScaleOut Product Suite, allow applications to store fast-changing data, such as e-commerce shopping carts, stock prices, and streaming telemetry, in memory with low latency for rapid access and analysis. Built using a cluster of virtual or physical servers, these caches automatically scale access throughput and analytics to handle large workloads. In addition, they provide built-in high availability to ensure uninterrupted access if a server fails. They are ideal for hosting on cloud platforms, which offer highly elastic computing resources to their users without the need for capital investments.
For more information, please visit www.scaleoutsoftware.com and follow @ScaleOut_Inc on Twitter.
Additional Resources:
- ScaleOut Google Cloud Platform blog post
- ScaleOut Product Suite information
About ScaleOut Software
Founded in 2003, ScaleOut Software develops leading-edge software that delivers scalable, highly available, in-memory computing and streaming analytics technologies to a wide range of industries. ScaleOut Software’s in-memory computing platform enables operational intelligence by storing, updating, and analyzing fast-changing, live data so that businesses can capture perishable opportunities before the moment is lost. It has offices in Bellevue, Washington and Beaverton, Oregon.
Media Contact
Brendan Hughes
RH Strategic for ScaleOut Software
ScaleOutPR@rhstrategic.com
206-264-0246
The post ScaleOut Software Adds Google Cloud Support Across Products appeared first on ScaleOut Software.
]]>The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>
by Olivier Tritschler, Senior Software Engineer
Because of their ability to provide highly elastic computing resources, public clouds have become a highly attractive platform for hosting distributed caches, such as ScaleOut StateServer®. To complement its current offerings on Amazon AWS and Microsoft Azure, ScaleOut Software has just announced support for the Google Cloud Platform. Let’s take a look at some of the benefits of hosting distributed caches in the cloud and understand how we have worked to make both deployment and management as simple as possible.
Distributed Caching in the Cloud
Distributed caches, like ScaleOut StateServer, enhance a wide range of applications by offering shared, in-memory storage for fast-changing state information, such as shopping carts, financial transactions, geolocation data, etc. This data needs to be quickly updated and shared across all application servers, ensuring consistent tracking of user state regardless of the server handling a request. Distributed caches also offer a powerful computing platform for analyzing live data and generating immediate feedback or operational intelligence for applications.
Built using a cluster of virtual or physical servers, distributed caches automatically scale access throughput and analytics to handle large workloads. With their tightly integrated client-side caching, these caches typically provide faster access to fast-changing data than backing stores, such as blob stores and database servers. In addition, they incorporate redundant data storage and recovery techniques to provide built-in high availability and ensure uninterrupted access if a server fails.
To meet the needs of elastic applications, distributed caches must themselves be elastic. They are designed to transparently scale upwards or downwards by adding or removing servers as the workload varies. This is where the power of the cloud becomes clear.
Because cloud infrastructures provide inherent elasticity, they can benefit both applications and distributed caches. As more computing resources are needed to handle a growing workload, clouds can deploy additional virtual servers (also called cloud “instances”). Once a period of high demand subsides, resources can be dialed back to minimize cost without compromising quality of service. The flexibility of on-demand servers also avoids costly capital investments and reduces management costs.
Deploying ScaleOut’s Distributed Cache in the Google Cloud
A key challenge in using a distributed cache as part of a cloud-hosted application is to make it easy to deploy, manage, and access by the application. Distributed caches are typically deployed in the cloud as a cluster of virtual servers that scales as the workload demands. To keep it simple, a cloud-hosted application should just view a distributed cache as an abstract entity and not have to keep track of individual caching servers or which data they hold. The application does not want to be concerned with connecting N application instances to M caching servers, especially when N and M (as well as cloud IP addresses) vary over time. In particular, an application should not have to discover and track the IP addresses for the caching servers.
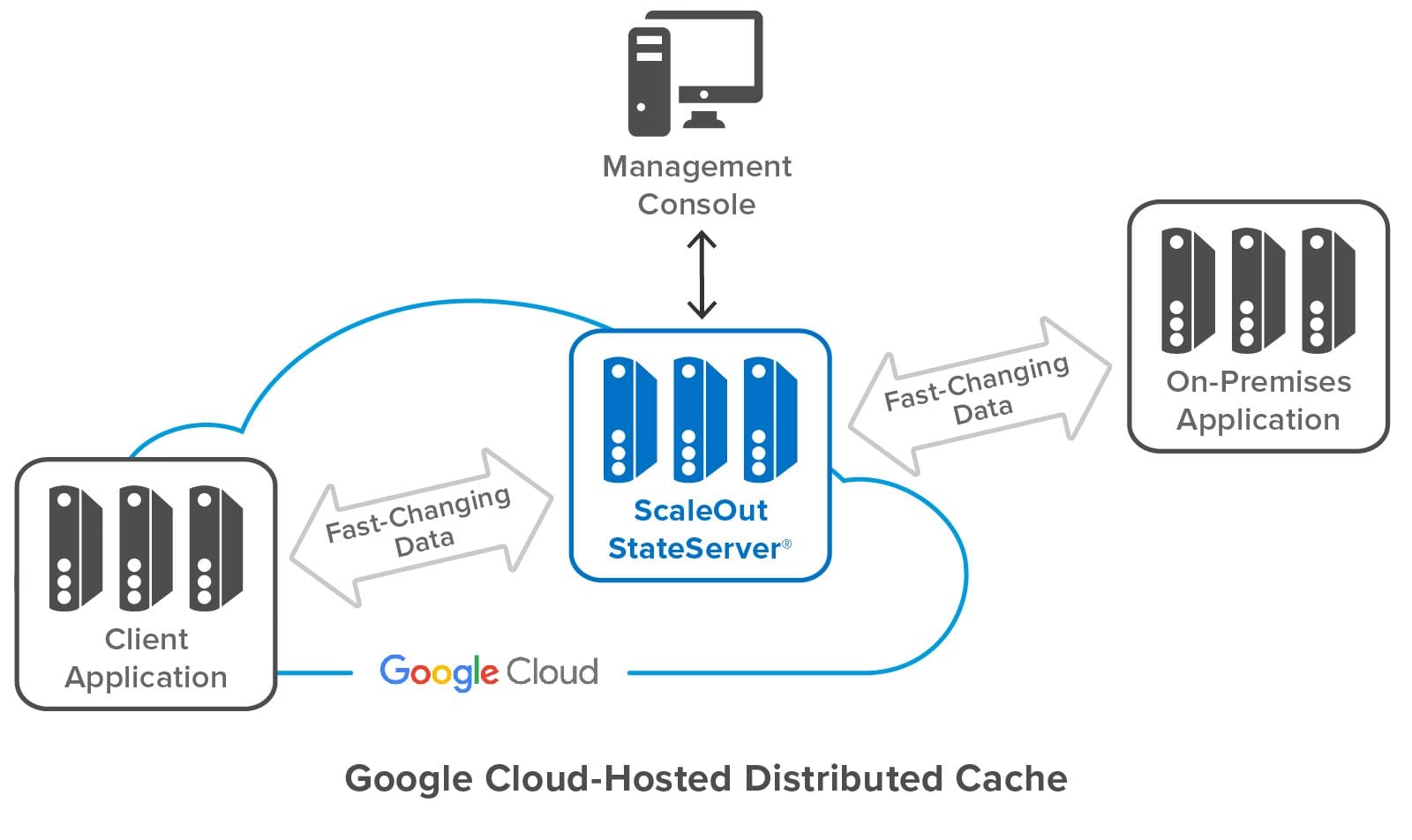
Even though a distributed cache comprises several servers, the simplest way to deploy and manage it in the cloud is to identify the cache as a single, coherent service. ScaleOut StateServer takes this approach by identifying a cloud-hosted distributed cache with a single “store” name combined with access credentials. This name becomes the basis for both managing the deployed servers and connecting applications to the cache. It lets applications connect to the caching cluster without needing to be aware of the IP addresses for the cluster’s virtual servers.
The following diagram shows a ScaleOut StateServer distributed cache deployed in Google Cloud. It shows both cloud-hosted and on-premises applications connected to the cache, as well as ScaleOut’s management console, which lets users deploy and manage the cache. Note that while the distributed cache and applications all contain multiple servers, applications and users can access the cache just by using its store name.
Building on the features developed for the integration of Amazon AWS and Microsoft Azure, the ScaleOut Management Console now lets users deploy and manage a cache in Google Cloud by just specifying a store name and initial number of servers, as well as other optional parameters. The console does the rest, interacting with Google Cloud to start up the distributed cache and configure its servers. To enable the servers to form a cluster, the console records metadata for all servers and identifies them as having the same store name.
Here’s a screenshot of the console wizard used for deploying ScaleOut StateServer in Google Cloud:
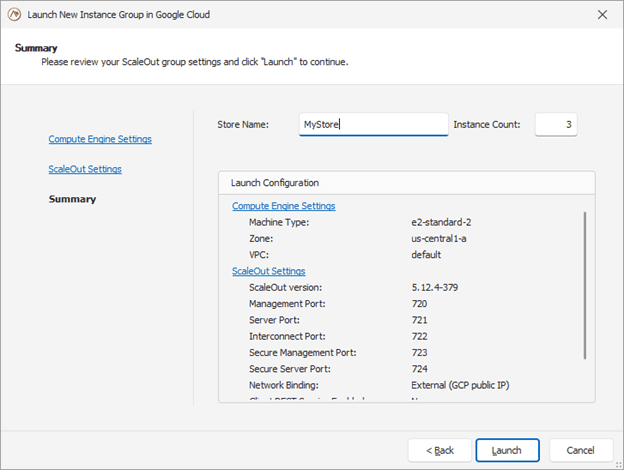
The management console provides centralized, on-premises management for initial deployment, status tracking, and adding or removing servers. It uses Google’s managed instance groups to host servers, and automated scripts use server metadata to guarantee that new servers automatically connect with an existing store. The managed instance groups used by ScaleOut also support defining auto-scaling options based on CPU/Memory usage metrics.
Instead of using the management console, users can also deploy ScaleOut StateServer to Google Cloud directly with Google’s Deployment Manager using optional templates and configuration files.
Simplifying Connectivity for Applications
On-premises applications typically connect each client instance to a distributed cache using a fixed list of IP addresses for the caching servers. This process works well on premises because the cache’s IP addresses typically are well known and static. However, it is impractical in the cloud since IP addresses change with each deployment or reboot of a caching server.
To avoid this problem, ScaleOut StateServer lets client applications specify a store name and credentials to access a cloud-hosted distributed cache. ScaleOut’s client libraries internally use this store name to discover the IP addresses of caching servers from metadata stored in each server.
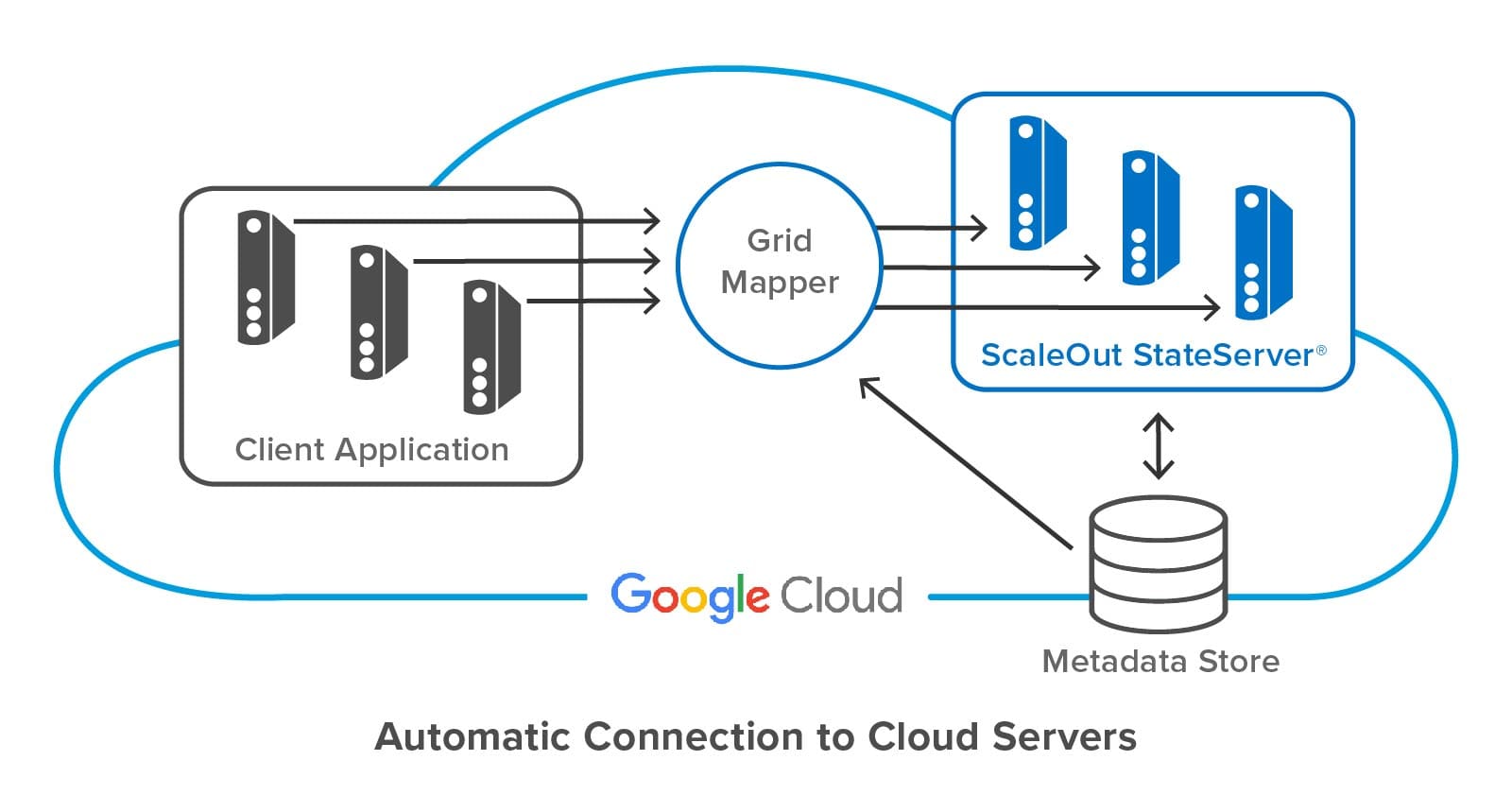
The following diagram shows a client application connecting to a ScaleOut StateServer distributed cache hosted in Google Cloud. ScaleOut’s client libraries make use of an internal software component called a “grid mapper” which acts as a bootstrap mechanism to find all servers belonging to a specified cache using its store name. The grid mapper accesses the metadata for the associated caching servers and returns their IP addresses back to the client library. The grid mapper handles any potential changes in IP addresses, such as servers being added or removed for scaling purposes.
Summing up
Because they provide elastic computing resources and high performance, public clouds, such as Google Cloud, offer an excellent platform for hosting distributed caches. However, the ephemeral nature of their virtual servers introduces challenges for both deploying the cluster and connecting applications. Keeping deployment and management as simple as possible is essential to controlling operational costs. ScaleOut StateServer makes use of centralized management, server metadata, and automatic client connections to address these challenges. It ensures that applications derive the full benefits of the cloud’s elastic resources with maximum ease of use and minimum cost.
The post Deploying ScaleOut’s Distributed Cache In Google Cloud appeared first on ScaleOut Software.
]]>The post Simulate at Scale with Digital Twins appeared first on ScaleOut Software.
]]>
Digital Twins Can Implement Both Streaming Analytics and Simulations
With the ScaleOut Digital Twin Streaming Service, the digital twin software model has proven its versatility well beyond its roots in product lifecycle management (PLM). This cloud-based service uses digital twins to implement streaming analytics and add important contextual information not possible with other stream-processing architectures. Because each digital twin can hold key information about an individual data source, it can enrich the analysis of incoming telemetry and extracts important, actionable insights without delay. Hosting digital twins on a scalable, in-memory computing platform enables the simultaneous tracking of thousands — or even millions — of data sources.
Owing to the digital twin’s object-oriented design, many diverse applications can take advantage of its powerful but easy-to-use software architecture. For example, telematics applications use digital twins to track telemetry from every vehicle in a fleet and immediately identify issues, such as lost or erratic drivers or emerging mechanical problems. Airlines can use digital twins to track the progress of passengers throughout an itinerary and respond to delays and cancellations with proactive remedies that smooth operations and reduce stress. Other applications abound, including health informatics, financial services, logistics, cybersecurity, IoT, smart cities, and crime prevention.
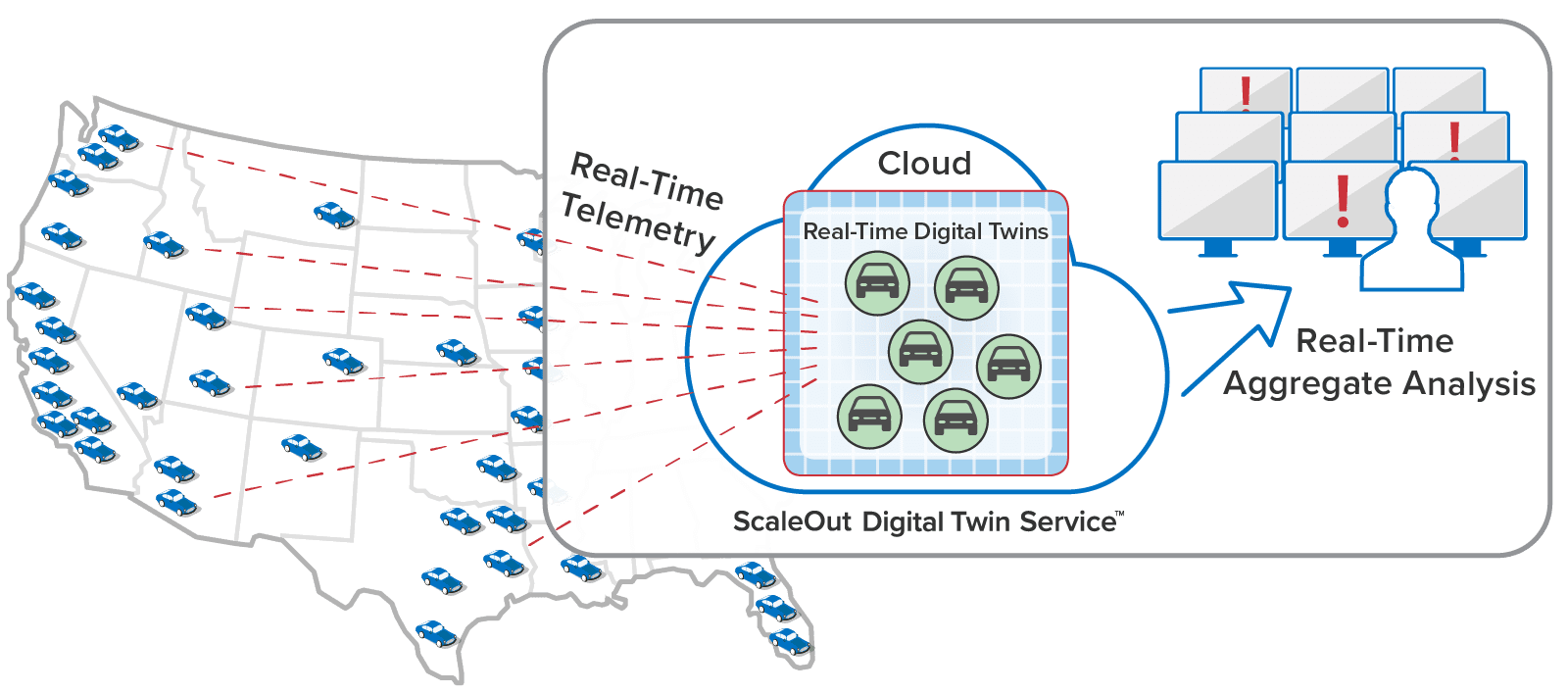
Here’s an example of a telematics application that tracks a large fleet of vehicles. Each vehicle has a corresponding digital twin analyzing telemetry from the vehicle in real time:
Applications like these need to simultaneously track the dynamic behavior of numerous data sources, such as IoT devices, to identify issues (or opportunities) as quickly as possible and give systems managers the best possible situational awareness. To either validate streaming analytics code for a complex physical system or model its behavior, it is useful to simulate the devices and the telemetry that they generate. The ScaleOut Digital Twin Streaming Service now enables digital twins to simplify both tasks.
Use Digital Twins to Simulate a Workload for Streaming Analytics
Digital twins can implement a workload generator that generates telemetry used in validating streaming analytics code. Each digital twin models the behavior of a physical data source, such as a vehicle in fleet, and the messages it sends and receives. When running in simulation, thousands of digital twins can then generate realistic telemetry for all data sources and feed streaming analytics, such as a telematics application, designed to track and analyze its behavior. In fact, the streaming service enables digital twins to implement both the workload generator and the streaming analytics. Once the analytics code has been validated in this manner, developers can then deploy it to track a live system.
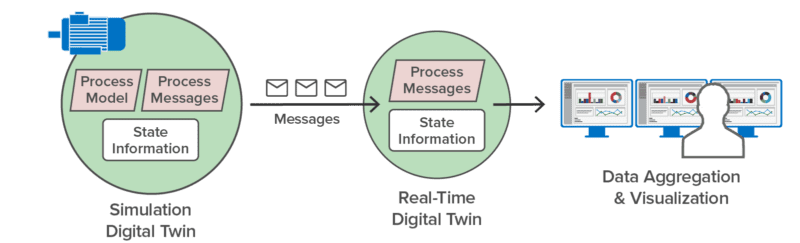
Here’s an example of using a digital twin to simulate the operations of a pump and the telemetry (such as the pump’s temperature and RPM) that it generates. Running in simulation, this simulated pump sends telemetry messages to a corresponding real-time digital twin that analyzes the telemetry to predict impending issues:
Once the simulation has validated the analytics, the real-time digital twin can be deployed to analyze telemetry from an actual pump:
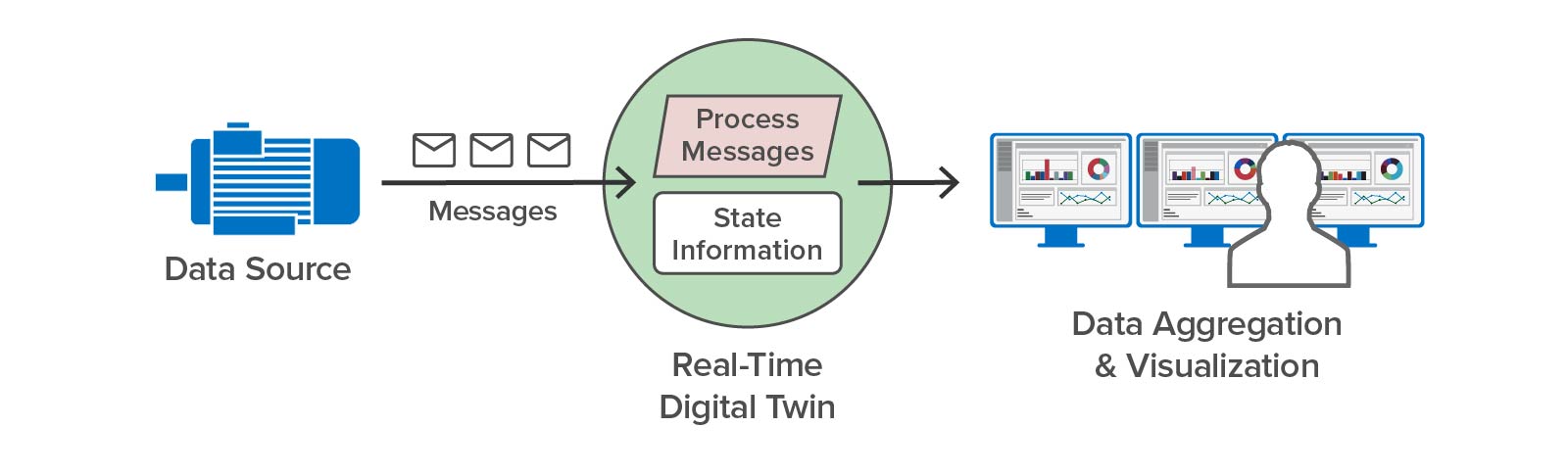
This example illustrates how digital twins can both simulate devices and provide streaming analytics for a live system.
Using digital twins to build a workload generator enables investigation of a wide range of scenarios that might be encountered in typical, real-world use. Developers can implement parameterizable, stateful models of physical data sources and then vary these parameters in simulation to evaluate the ability of streaming analytics to analyze and respond in various situations. For example, digital twins could simulate perimeter devices detecting security intrusions in a large infrastructure to help evaluate how well streaming analytics can identify and classify threats. In addition, the streaming service can capture and record live telemetry and later replay it in simulation.
Use Digital Twins to Simulate a Large System with Many Entities
In addition to using digital twins for analyzing telemetry, the ScaleOut Digital Twin Streaming Service enables digital twins to implement time-driven simulations that model large groups of interacting physical entities. Digital twins can model individual entities within a large system, such as airline passengers, aircraft, airport gates, and air traffic sectors in a comprehensive airline model. These digital twins maintain state information about the physical entities they represent, and they can run code at each time step in the simulation model’s execution to update digital twin state over time. These digital twins also can exchange messages that model interactions.
For example, an airline tracking system can use simulation to model numerous types of weather delays and system outages (such as ground stops) to see how their system manages passenger needs. As the simulation model evolves over time, simulated aircraft can model flight delays and send messages to simulated passengers that react by updating their itineraries. Here is a depiction of an airline tracking simulation:
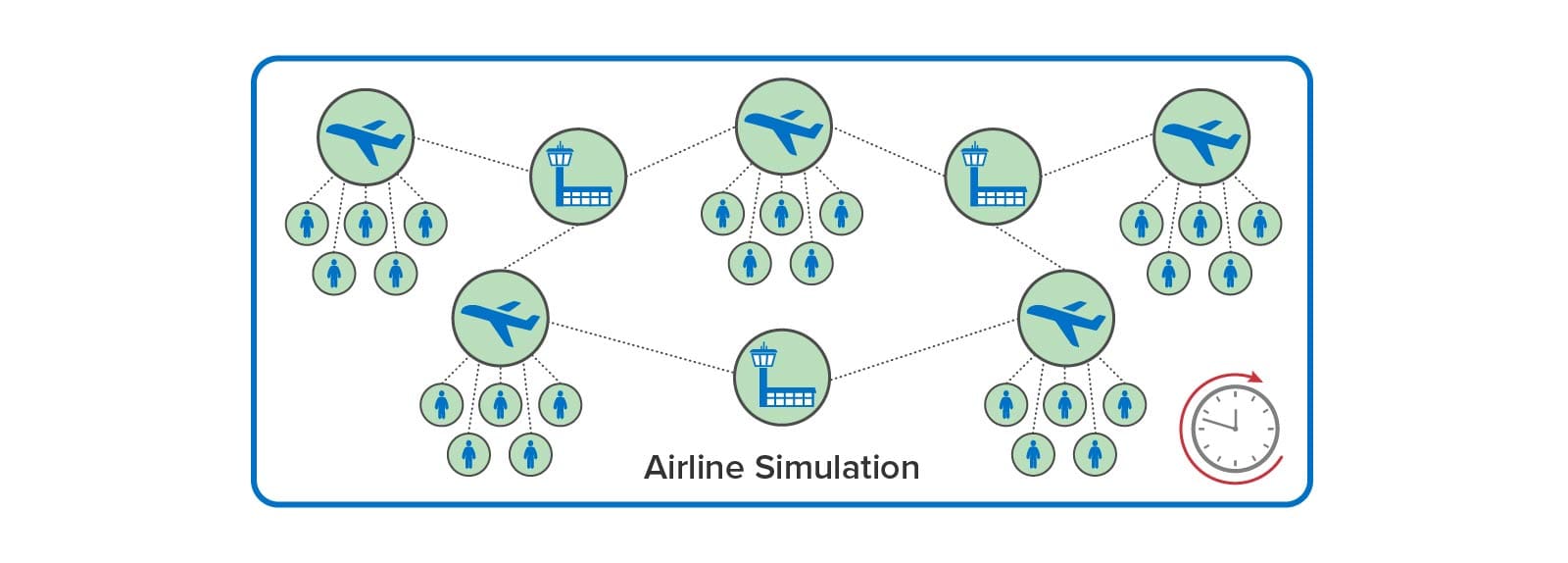
In contrast to the use of digital twins for PLM, which typically embody a complex design within a single digital twin model, the ScaleOut Digital Twin Streaming Service enables large numbers of physical entities and their interactions to be simulated. By doing this, simulations can model intricate behaviors that evolve over time and reveal important insights during system design and optimization. They also can be fed live data and run faster than real time as a tool for making predictions that assist decision-making by managers (such as airline dispatchers).
Scalable, In-Memory Computing Makes It Possible
Digital twins offer a compelling software architecture for implementing time-driven simulations with thousands of entities. In a typical implementation, developers create multiple digital twin models to describe the state information and simulation code representing various physical entities, such as trucks, cargo, and warehouses in a telematics simulation. They create instances of these digital twin models (simply called digital twins) to implement all of the entities being simulated, and the streaming service runs their code at each time step being simulated. During each time step, digital twins can exchange messages that represent simulated interactions between physical entities.
The ScaleOut Digital Twin Streaming Service uses scalable, in-memory computing technology to provide the speed and memory capacity needed to run large simulations with many entities. It stores digital twins in memory and automatically distributes them across a cluster of servers that hosts a simulation. At each time step, each server runs the simulation code for a subset of the digital twins and determines the next time step that the simulation needs to run. The streaming service orchestrates the simulation’s progress on the cluster and advances simulation time at a rate selected by the user.
In this manner, the streaming service can harness as many servers as it needs to host a large simulation and run it with maximum throughput. As illustrated below, the service’s in-memory computing platform can add new servers while a simulation is running, and it can transparently handle server outages should they occur. Users need only focus on building digital twin models and deploying them to the streaming service.
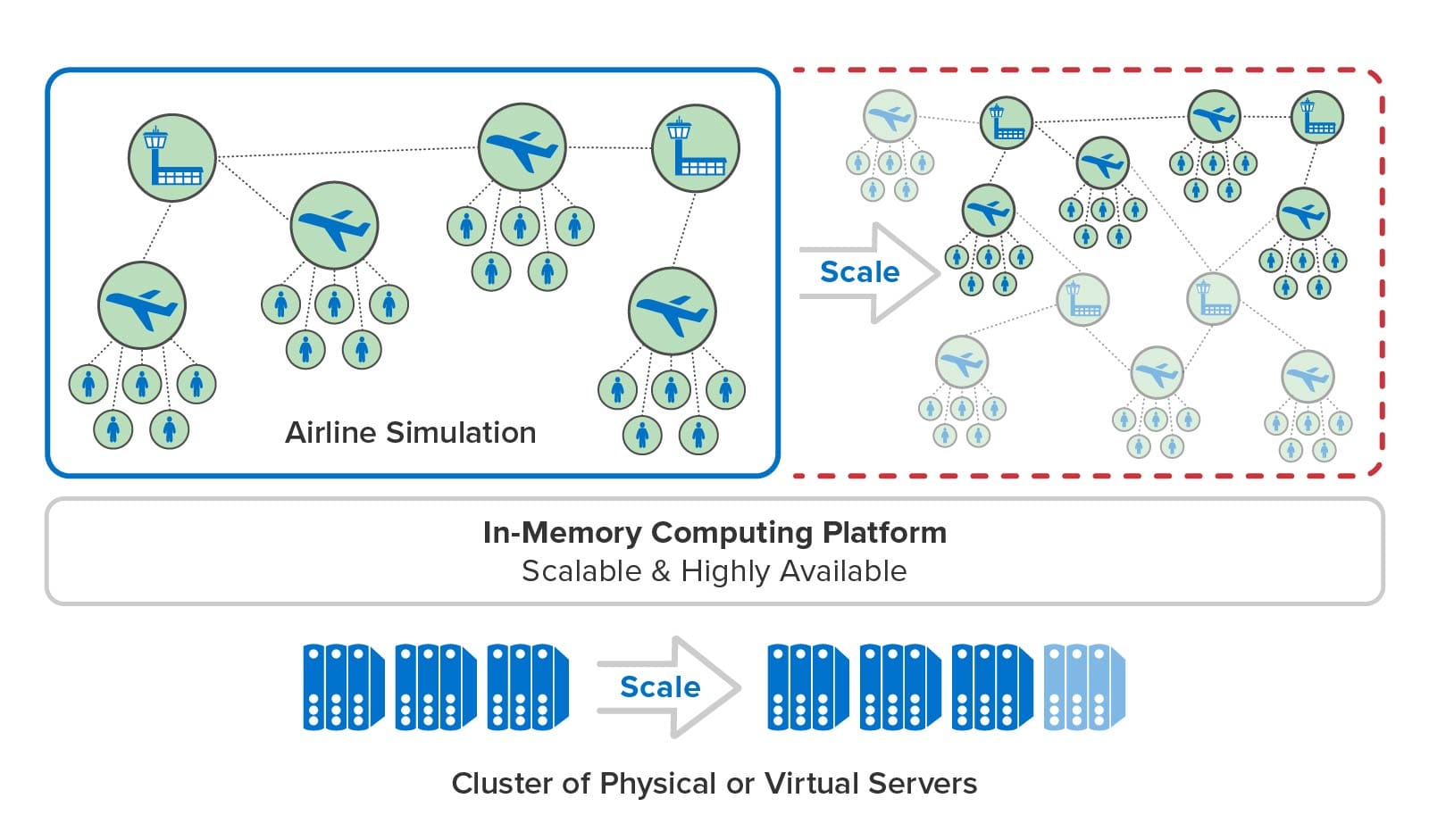
The Next Generation of Simulation with Digital Twins
Digital twins have historically been employed as a tool for simulating increasingly detailed behavior of a complex physical entity, like a jet engine. The ScaleOut Digital Twin Streaming Service takes digital twins in a new direction: simulation of large systems. Its highly scalable, in-memory computing architecture enables it to easily simulate many thousands of entities and their interactions. This provides a powerful new tool for extracting insights about complex systems that today’s managers must operate at peak efficiency. Its analytics and predictive capabilities promise to offer a high return on investment in many industries.
The post Simulate at Scale with Digital Twins appeared first on ScaleOut Software.
]]>The post ScaleOut Software Adds Simulation Capabilities to its Digital Twin Streaming Service appeared first on ScaleOut Software.
]]>BELLEVUE, WASH. — February 21, 2023 — ScaleOut Software today announces new device modeling and simulation capabilities for its ScaleOut Digital Twin Streaming Service. These capabilities extend the service’s ability to perform real-time analytics at scale using digital twins to track devices and other real-world data sources. Users can now simulate the behavior of these data sources using digital twins prior to deployment as a tool to evaluate design choices and improve decision-making. This offers several benefits to data analysts and managers in a wide range of industries, including telematics, logistics, security, healthcare, crime prevention, and financial services.
Going beyond product lifecycle management (PLM), which focuses on improving product design, ScaleOut Software’s new simulation capabilities using digital twins also can assist in developing real-time analytics applications. The streaming service now enables digital twins to both generate and analyze telemetry. For example, developers can model a fleet of trucks with digital twins that send telemetry to additional digital twins which implement real-time analytics for tracking the fleet, identifying issues, and evaluating performance. The streaming service also can record telemetry from live devices and replay it in simulation to assist in performing offline analytics.
“We are excited to extend the capabilities of our streaming service to harness digital twins for both simulation and real-time analytics,” said Dr. William Bain, ScaleOut Software’s CEO and founder. “By hosting digital twins using our highly scalable, in-memory computing technology, we enable our customers to simulate large systems with complex interactions and gain insights not previously possible.”
Managers can also use ScaleOut Software’s simulation capabilities to model thousands of interacting data sources and predict likely outcomes faster than real time. For example, they can model the effect of delays for an airline’s flight schedule within a multi-hour, forward-looking window to predict and mitigate impacts on passengers caused by weather and equipment issues. This predictive capability can assist in decision-making during real-time operations.
Key Features and Benefits for ScaleOut Software’s Digital Twin Simulations:
- Build Simulations at Scale: Now developers can construct simulations that model thousands of devices and other data sources. Fast, in-memory computing ensures high throughput and seamless scaling during simulations with built-in high availability.
- Model with Digital Twins: Developers can harness the popular digital twin model to describe various physical entities using a powerful but easy-to-use, object-oriented representation of each device or data source. The ScaleOut Digital Twin Builder Toolkit lets developers construct digital twin models in both Java and C#.
- Combine Modeling and Analytics: The ScaleOut Digital Twin Streaming Service now helps managers use digital twins to both analyze telemetry from real-world data sources and to model those data sources. This simplifies the creation of workload generators for evaluating real-time analytics. The platform also allows a single digital twin instance to both simulate a data source’s behavior and analyze its telemetry.
- Capture and Replay Live Telemetry: The streaming service can capture telemetry from live data sources and replay it in simulation. This capability streamlines workload generation for simulations and enables offline analysis of live scenarios.
- Make Predictions with Simulation: The streaming service can configure simulations to run faster than real-time. This aids decision-making for operational managers by enabling simulations to predict future events based on parameterizable scenarios.
For more information, please visit www.scaleoutsoftware.com and follow @ScaleOut_Inc on Twitter.
Additional Resources:
- ScaleOut Digital Twin simulations blog post
- ScaleOut Digital Twin Streaming Service product page
About ScaleOut Software
Founded in 2003, ScaleOut Software develops leading-edge software that delivers scalable, highly available, in-memory computing and streaming analytics technologies to a wide range of industries. ScaleOut Software’s in-memory computing platform enables operational intelligence by storing, updating, and analyzing fast-changing, live data so that businesses can capture perishable opportunities before the moment is lost. It has offices in Bellevue, Washington and Beaverton, Oregon.
Media Contact
Brendan Hughes
RH Strategic for ScaleOut Software
ScaleOutPR@rhstrategic.com
206-264-0246
The post ScaleOut Software Adds Simulation Capabilities to its Digital Twin Streaming Service appeared first on ScaleOut Software.
]]>The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>
by Brandon Ripley, Senior Software Engineer
ScaleOut Software introduces a new Java client API for our distributed caching platform, ScaleOut StateServer®, that adds important new features for Java applications. It was designed with cloud-based deployments in mind, enabling clients to access ScaleOut in-memory data grids (IMDGs also called distributed caches) in multiple availability zones. It introduces the use of connection strings with DNS support for connecting Java clients to IMDGs, and it allows multiple, simultaneous connections to different caches. It also includes asynchronous APIs that add flexibility to application development.
You can download the JAR for the client API from ScaleOut’s Maven repository at https://repo.scaleoutsoftware.com. Simply connect your build tool to the repository and reference the API as a dependency to get started. The online User Guide can help you setup a project. Alternatively, you can download the JAR directly from the repo and then host the JAR with your build tool of choice. You can find an API reference here.
Let’s take a brief tour of the new Java APIs and look at an example using Docker for accessing multiple IMDGs.
A Quick Tour of the Java Client
The ScaleOut client API for Java lets client applications store and retrieve POJOs (plain old java objects) from a ScaleOut IMDG and provides an easy to use, fast, cloud-ready caching API. It can be used within any web application and is independent of any framework. This means that you can use the ScaleOut client API within your existing application architecture.
To simplify the developer experience, the API is logically divided into three primary packages:
Client Package
The client package houses the GridConnection class for connecting to a ScaleOut IMDG via a connection string. Each instance of GridConnection maintains a set of TCP connections to a ScaleOut cache and transparently handles retries, host failures, and load balancing.
The client package is also the place to register for event handling. ScaleOut servers can fire events for objects that are expiring and events for backing store operations (that is, read-through, refresh-ahead, write-behind, and erase-behind). The ServiceEvents class is used to register an event handler for events fired by the grid.
Caching Package
The caching package contains the strongly typed Cache<K,V> class that is used for all caching operations to store and retrieve POJOs of type V using a key of type K from a name space within the IMDG. All caching operations return a CacheResponse that details the result of the cache access.
For example, a successful access that adds a value to the cache using:
cache.add(key, value)
returns a CacheResponse with the status ObjectAdded, which can be obtained by calling the CacheResponse.getStatus() method. However, if the cache already contained an object for the key and the access was called again, CacheResponse.getStatus() would return ObjectAlreadyExists. (See the Javadoc for all possible responses.)
Query Package
The query package lets you perform queries to select objects from the IMDG. Queries are constructed using query filters created using the FilterFactory class. A filter can consist of a simple equality predicate, or it can combine multiple predicates to query with finer granularity.
Sample Applications
The following samples show how the ScaleOut Java client API can be used within a microservices architecture to access cached data and process events. The client API make it easy to develop modern web applications.
In these samples we will:
- Write an application that connects to two ScaleOut IMDGs to store and retrieve objects. (The two caches are configured to replicate data to each other using ScaleOut GeoServer®.)
- Write a second application that registers for and handles ScaleOut expiration events.
- Create four dockerfiles: the caching application, the expiration event handling application, and two ScaleOut IMDGs.
- Use the Docker compose command to spawn all four containers and run the two applications.
You can find the full samples, including the dockerfiles, on GitHub. Let’s look at the code for these two applications.
Accessing Multiple IMDGs
The first application’s goal is to verify ScaleOut GeoServer replication between two IMDGs. It first connects to the two IMDGs, creates an instance of Cache(K,V) for each IMDG, and then performs accesses.
The application connects to the grid using the GridConnection.connect() static method to instantiate a GridConnection object for each IMDG (named store1 and store2 here):
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
The next step is to create an instance of Cache(K,V) for each IMDG. Caches are instantiated with a GridConnection which associates the instance with a specific IMDG. This allows different instances to connect to different IMDGs.
The Java client API uses a builder pattern to instantiate caches. For applications using dependency injection, the immutable cache guarantees that the defaults we set at build time will stay consistent for the lifetime of the app. This is great for large applications with many caches as it guarantees there will be no unexpected modifications.
On the builder we can specify properties for defaults. Here is an example that sets an object timeout of fifteen seconds and a timeout type of Absolute (versus ResetOnUpdate or Sliding). The string “example” specifies the cache’s name space:
Cache<Integer, String> store1Cache = new CacheBuilder<Integer, String>(store1Connection, "example", Integer.class)
.objectTimeout(Duration.ofSeconds(15))
.timeoutType(TimeoutType.Absolute)
.build();
The Cache(K,V) class has multiple signatures for storing and retrieving objects from the IMDG. These signatures follow traditional Java naming semantics for distributed caching. For example, the add(key,value) method assumes that no key/value object mapping exists in the cache, whereas update(key,value) assumes than a key/value mapping exists in the cache.
This application uses the add method to insert an item into store1Cache and then checks the response for success. Here’s a code sample that adds two items to the cache:
CacheResponse<String, String> addResponse = store1Cache.add(“MyKey”, "SomeValue");
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
addResponse = store1Cache.add(“MyFavoriteKey”, "MyFavoriteValue");
if(addResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
The application’s goal is to verify that ScaleOut GeoServer replicates stored objects from the store1 IMDG to store2. It creates an instance of Cache(K,V) for the same namespace on store2 and then attempts to retrieve the object with the read API:
CacheResponse<String, String> readResponse = store2Cache.read(“Key”);
if(readResponse.getStatus() != RequestStatus.ObjectAdded)
System.out.println("Unexpected request status " + response.getStatus());
Registering for Events
This sample application demonstrates how an application can have fine grain control over which objects will be removed from the IMDG after a time interval elapses. With the object timeout and timeout-type properties established, objects added to the IMDG will be subject to expiration. When an object expires, the ScaleOut grid will fire an expiration event.
Our application can register to handle expiration events by supplying an instance of Cache(K,V) and an appropriate lambda (or implementing class) to the ServiceEvents static method. The following code removes all objects other than a cache entry mapping with the key, “MyFavoriteKey”:
ServiceEvents.setExpirationHandler(cache, new CacheEntryExpirationHandler<Integer, String>() {
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<Integer, String> cache, String key) {
System.out.println("ObjectExpired: " + key);
if(key.compareTo(“MyFavoriteKey”) == 0)
return CacheEntryDisposition.Save;
return CacheEntryDisposition.Remove;
}});
Running the Applications
We’ve created code snippets for connecting to a ScaleOut grid, creating a cache, and registering for ScaleOut expiration events. We can put all these pieces together to create the two applications with two Java classes called CacheRunner and CacheExpirationListener.
CacheRunner connects to two ScaleOut IMDGs that are setup for push replication using ScaleOut GeoServer. (This is handled by the infrastructure via the dockerfiles and not done in code.) It creates an instance of Cache(K,V) associated with one of the IMDG (called store1) that has a very small absolute timeout for each object and another instance for the other IMDG (called store2). It stores an object in store1 and then retrieves it from store2 to verify that the object was pushed from one IMDG to the other.
Here is the code for CacheRunner:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.caching.*;
import java.time.Duration;
public class CacheRunner {
public static void main(String[] args) throws CacheException, GridConnectException {
System.out.println("Connecting to store 1...");
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
System.out.println("Connecting to store 2...");
GridConnection store2Connection = GridConnection.connect("bootstrapGateways=store2:3721");
Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
.geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
.objectTimeout(Duration.ofSeconds(15))
.objectTimeoutType(TimeoutType.Absolute)
.build();
Cache<String, String> store2Cache = new CacheBuilder<String, String>(store2Connection, "sample", String.class)
.build();
System.out.println("Adding object to cache in store 1!");
CacheResponse<String, String> addResponse = store1Cache.add("MyKey", "MyValue");
System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
addResponse = store1Cache.add("MyFavoriteKey", "MyFavoriteValue");
System.out.println("Object " + ((addResponse.getStatus() == RequestStatus.ObjectAdded ? "added" : "not added."))
+ " to cache in store 1.");
System.out.println("Reading object from cache in store 2!");
CacheResponse<String,String> readResponse = store2Cache.read("foo");
System.out.println("Object " + ((readResponse.getStatus() == RequestStatus.ObjectRetrieved ?
"retrieved" : "not retrieved.")) + " from cache in store 2.");
}
}
CacheExpirationListener connects to one ScaleOut IMDG, create an instance of Cache(K,V), and registers for expiration events. Here is its code:
package com.scaleout.caching.sample;
import com.scaleout.client.GridConnectException;
import com.scaleout.client.GridConnection;
import com.scaleout.client.ServiceEvents;
import com.scaleout.client.ServiceEventsException;
import com.scaleout.client.caching.*;
import java.io.IOException;
import java.time.Duration;
import java.util.concurrent.CountDownLatch;
public class ExpirationListener {
public static void main(String[] args) throws ServiceEventsException, IOException, InterruptedException,
GridConnectException {
GridConnection store1Connection = GridConnection.connect("bootstrapGateways=store1:2721");
Cache<String, String> store1Cache = new CacheBuilder<String, String>(store1Connection, "sample", String.class)
.geoServerPushPolicy(GeoServerPushPolicy.AllowReplication)
.objectTimeout(Duration.ofSeconds(15))
.objectTimeoutType(TimeoutType.Absolute)
.build();
ServiceEvents.setExpirationHandler(store1Cache, new CacheEntryExpirationHandler<String, String>() {
@Override
public CacheEntryDisposition handleExpirationEvent(Cache<String, String> cache, String key) {
CacheEntryDisposition disposition = CacheEntryDisposition.NotHandled;
System.out.printf("Object (%s) expired\n", key);
if(key.equals("MyFavoriteKey"))
disposition = CacheEntryDisposition.Save;
else disposition = CacheEntryDisposition.Remove;
return disposition;
}
});
}
}
To run these applications, we’ll use the Docker compose command to build Docker containers. We will have 4 services, each defined in their own respective dockerfile, which are all provided and available on the GitHub repo. You can clone the repository and then run the deployment with the following command:
docker-compose -f ./docker-compose.yml up -d –build
Here is the expected output for CacheRunner:
Adding object to cache in store 1! Object added to cache in store 1. Object added to cache in store 1. Reading object from cache in store 2! Object retrieved. from cache in store 2.
Here is the output for ExpirationListener:
Connected to store1! Object (MyFavoriteKey) expired Object (MyKey) expired
Summing Up
The new ScaleOut client API for Java adds important features that support the development of modern web and cloud applications. Built-in support for connection strings enables simultaneous connections to multiple IMDGs using DNS entries. Full support for asynchronous accesses also assists in application development. Let us know what you think with your comments on our community forum.
The post Introducing a New ScaleOut Java Client API appeared first on ScaleOut Software.
]]>The post New Digital Twin Features for Real-World Applications appeared first on ScaleOut Software.
]]>
Using Digital Twins for Streaming Analytics
In the two years since we initially released the ScaleOut Digital Twin Streaming Service, we have applied the digital twin model to numerous use cases, including security alerting, telematics, contact tracing, logistics, device tracking, industrial sensor monitoring, cloned license plate detection, and airline system tracking. Constructing applications for these use cases has demonstrated the power of the digital twin model in creating streaming analytics that track large numbers of data sources.
The process of building digital twin applications allowed us to surface both the strengths and shortcomings of our APIs. This has led to a series of new features which enhance the core platform. For example, we created a rules engine for implementing the logic within a digital twin so that new models can be created without the need for programming expertise. We then added machine learning to digital twin models using Microsoft’s ML.NET library. This enables digital twins to look for patterns in telemetry that are difficult to define with code. More recently, we integrated our digital twin model with Microsoft’s Azure Digital Twins to accelerate real-time processing using our in-memory computing technology while providing new visualization and persistence capabilities for digital twins.
With the newly announced version 2, we are adding important new capabilities for real-time analytics to our digital twin APIs. Let’s take a look at some of these new features.
New Support for .NET 6
Version 2 expands the target platforms for C#-based digital twin models by supporting .NET 6. With our goal to make the ScaleOut Digital Twin Streaming Service’s feature set and visualization tools uniformly available in the cloud and on-premises, we recognized that we needed to move beyond support for .NET Framework, which can only be deployed on Windows. By adding .NET 6, we can take advantage of its portability across both Windows and Linux. Now C#, Java, JavaScript, and rules-based digital twin models can be deployed on all platforms:
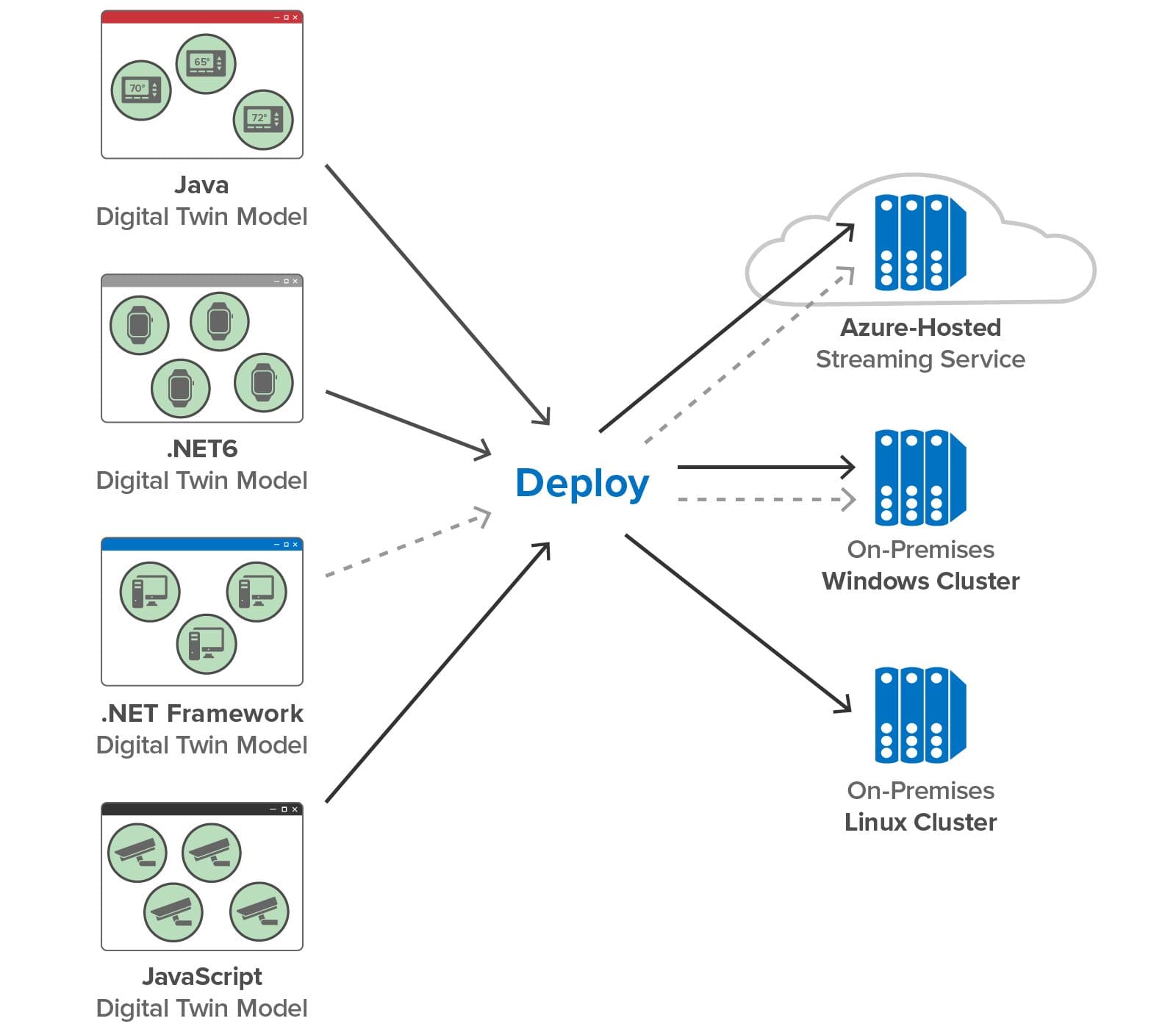
(As illustrated with the dotted lines above, we continue to support .NET Framework on Windows and in the Azure cloud.)
To take maximum advantage of .NET 6, we also re-implemented our Azure cloud service and key portions of the back-end infrastructure in .NET 6. This provides better performance and flexibility for future upgrades.
Digital Twin Timers
Using our APIs, digital twins can run analytics code to process incoming messages from their corresponding data sources. In developing a proof-of-concept application for an industrial safety application, we learned that they also need to be able to create timers and run code when the timers expire. This enables digital twins to detect when their data sources fail or become erratic in sending messages.
For example, consider a digital application that tracks periodic telemetry from a collection of building thermostats. Each digital twin looks for abnormal temperature excursions that indicate the need to alert personnel. In addition, a digital twin must determine if its thermostat has failed and is no longer sending periodic temperature readings. By setting a timer and restarting it after each message is received, the digital twin can signal an alert if excessive time elapses between incoming messages:
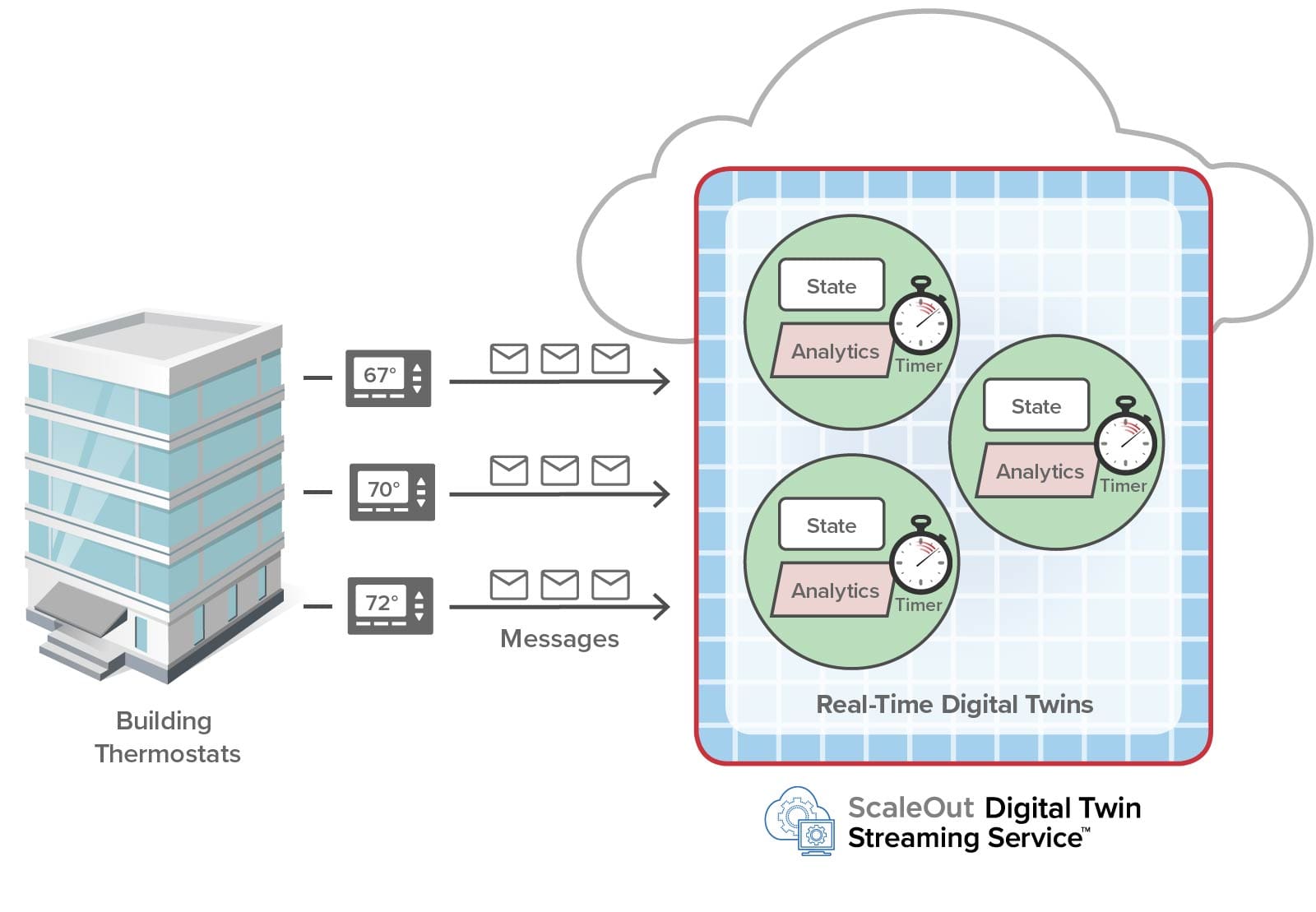
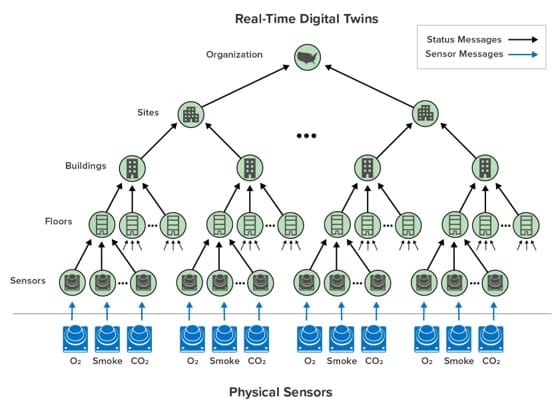
In the actual industrial safety application we built, buildings throughout a site had numerous smoke and gas sensors. Digital twins for the sensors incorporated timers to detect failed sensors. As shown below, they periodically forwarded their status to a hierarchy of digital twins arranged as shown below from the lowest level upwards. The digital twins represented floors within buildings, buildings within a site, sites within the organization, and the overall organization itself. At each level, status information was aggregated to gives personnel immediate information about where problems were occurring. The role of timers was critical in maintaining a complete picture of the organization’s status.
Aggregate Initialization
When we first implemented our digital twin platform, we designed it to automatically create a digital twin instance when the first message from an unknown data source arrives. (The platform determines which type of digital twin to create from the message’s contents.) This technique simplifies deployment by avoiding the need to explicitly create digital twin instances. The user simply develops and deploys a digital twin model, for example, for a gas sensor, and the platform creates a digital twin for each sensor that sends a message to the platform.
In many cases, it’s useful to create digital twin instances when deploying a model instead of waiting for messages to arrive. For example, both demo applications and simulations need to explicitly create digital twins since there are no actual physical devices. Also, applications with model hierarchies (like the example above) may need to create instances to fill out the hierarchy and start reporting at deployment time.
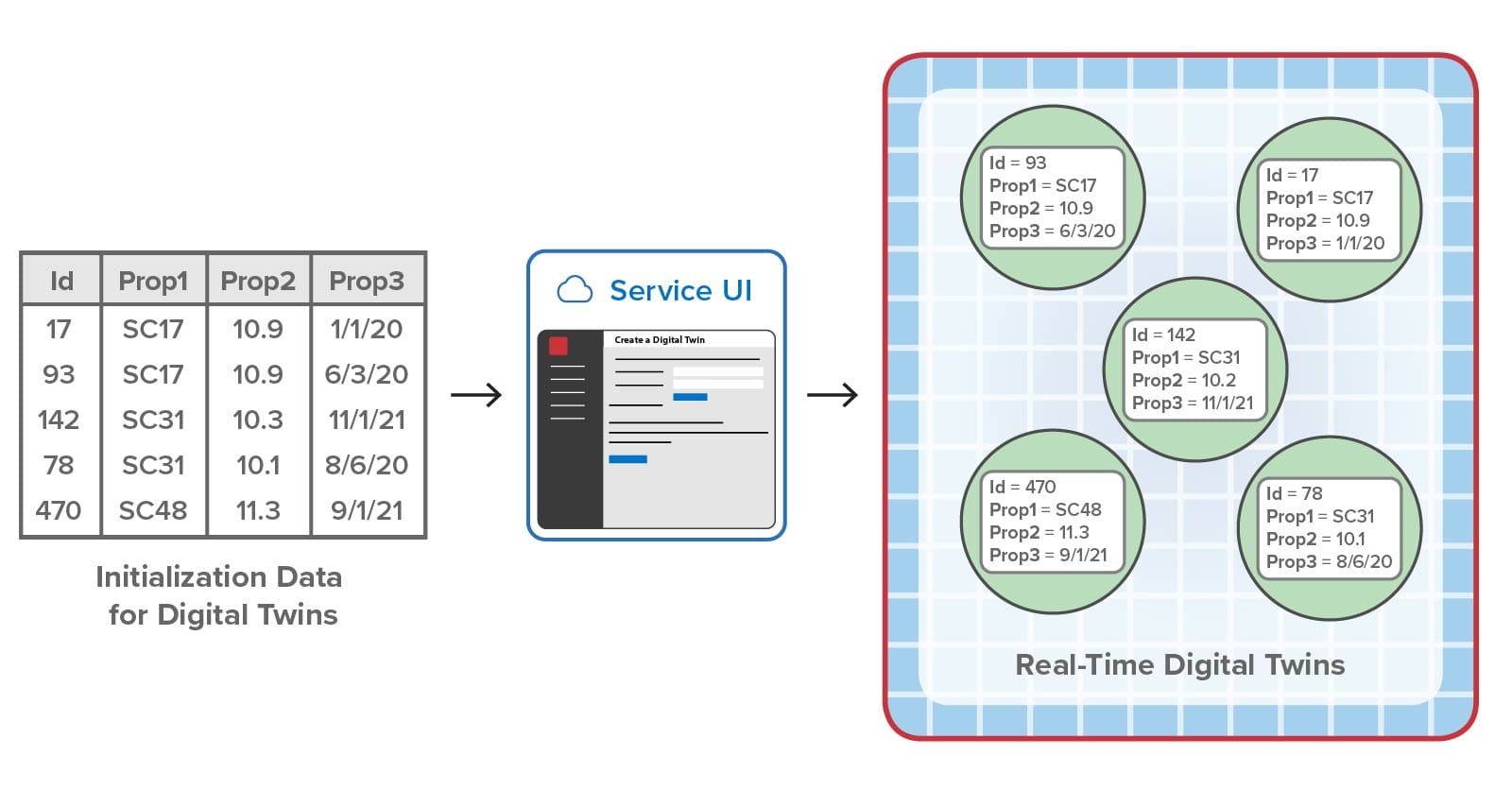
To address these needs, version 2 lets users supply a csv file when deploying a digital twin model. This csv file lists all digital twin instances and the initial values for each instance’s properties. The platform then creates the corresponding digital twin instances and sets the initial values.
Here’s an example that shows how a csv file generated from a spreadsheet can be deployed to the streaming service via the UI to initialize five digital twin instances. Note that the spreadsheet’s first row has the names of the properties to be set:
Summing Up
After more than two years of experience in building real-world applications with digital twins, we have confirmed the power of using digital twins for streaming analytics. Because digital twins bring together state information, telemetry, and application logic for each physical device, they enable deep introspection that tracks behavior and surfaces issues using a simple, highly efficient programming model. They also allow applications to focus on analytics code and defer the challenges of data visualization and throughput scaling to the streaming service.
With version 2, we have added important new capabilities to our implementation of the digital twin model and to the underlying platform. These features have been driven by emerging requirements that surfaced during application development. This matches our design philosophy of starting with a simple, coherent model and carefully enhancing it as new learnings are made.
Interestingly, our development work has consistently shown the value of using simulation to demonstrate the capabilities of the digital twin model for streaming analytics. The new features in version 2 enhance our ability to build simulations, and we expect to add more support for simulation in upcoming releases. Stay tuned.
The post New Digital Twin Features for Real-World Applications appeared first on ScaleOut Software.
]]>The post New Video Interview by the Digital Twin Consortium appeared first on ScaleOut Software.
]]>In this video, Bill explains how digital twins can make use of object-oriented programming techniques and in-memory computing to implement real-time analytics at scale. These combined technologies can enable a wide range of live applications to track thousands of data sources, identify issues, and respond in the moment. Target applications include IoT, telematics, logistics, disaster management, health-device tracking, energy management, cyber and physical security, and fraud detection.

ScaleOut Software offers an in-memory, digital twin platform designed to provide real-time analytics for applications with many data sources. The ScaleOut Digital Twin Streaming Service runs as an Azure-based cloud service and on-premises for developing and running object-oriented digital twin models written in C#, Java, and JavaScript. It includes a comprehensive UI for managing digital twins, aggregating and querying their dynamic state, and visualizing real-time trends.
The post New Video Interview by the Digital Twin Consortium appeared first on ScaleOut Software.
]]>The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>
ScaleOut Software is excited to announce the release of ScaleOut In-Memory Database, which offers a new, highly scalable, clustered server platform for running Redis commands. This platform uses ScaleOut’s patented, quorum-based clustering technology to replace open-source Redis’s cluster implementation. It fully automates Redis cluster management while preserving the use of open-source Redis code to process commands. In doing so, ScaleOut In-Memory Database lets enterprise Redis users manage server clusters with much greater ease and lower both their acquisition and management costs (TCO) — while preserving a native execution environment for Redis applications. ScaleOut In-Memory Database runs on both Linux and Windows systems.
What sets ScaleOut’s cluster architecture apart
When ScaleOut Software first developed its clustering technology for scalable in-memory data storage in 2003, we had to tackle several technical challenges. We needed to:
- implement a scalable cluster membership,
- partition the in-memory data store across multiple servers,
- replicate updates with zero data loss (i.e., avoid eventual consistency), and
- maximize throughput with multi-threading on multicore servers.
We also realized that it was important not to expose all these complexities to users. The cluster had to be easy to manage, making a simple learning curve for system administrators. It was also vital to have a straightforward view of the data store for applications (that is, maintain location transparency and full consistency) so developers could target it easily.
Automated clustering
Our clustering architecture has many leading-edge automated clustering features. These include the ability to:
- self-organize multiple servers into a cluster,
- automatically partition data and distribute it across the cluster,
- load-balance stored data as servers are added or removed,
- automatically create and maintain replicas,
- detect server and network failures,
- recover from failures by promoting replicas to replace failed primary partitions, and
- “self-heal” by creating new replicas to replace lost ones.
Stability and consistency
The server cluster uses peer-to-peer algorithms to avoid single points of failure. Running on one or more servers, it maintains availability to applications even if all but one server fails. It uses a patented quorum algorithm to implement full (strong) consistency when updating stored data across multiple servers. Lastly, it executes multiple requests at once using a multi-threaded architecture.
Industry-leading ease of use
ScaleOut’s cluster architecture does all this without showing its inner workings to developers or system administrators. Developers see a single, reliable data store that happens to be distributed across multiple servers. System administrators see a set of servers on a single network subnet, each running a single service process.
Once the service is configured to select a specific subnet (if multiple NICs are in use), it joins the cluster with one click and is ready to take on its share of the workload. Building a server cluster is just a matter of adding servers (called “nodes” in Redis documentation):
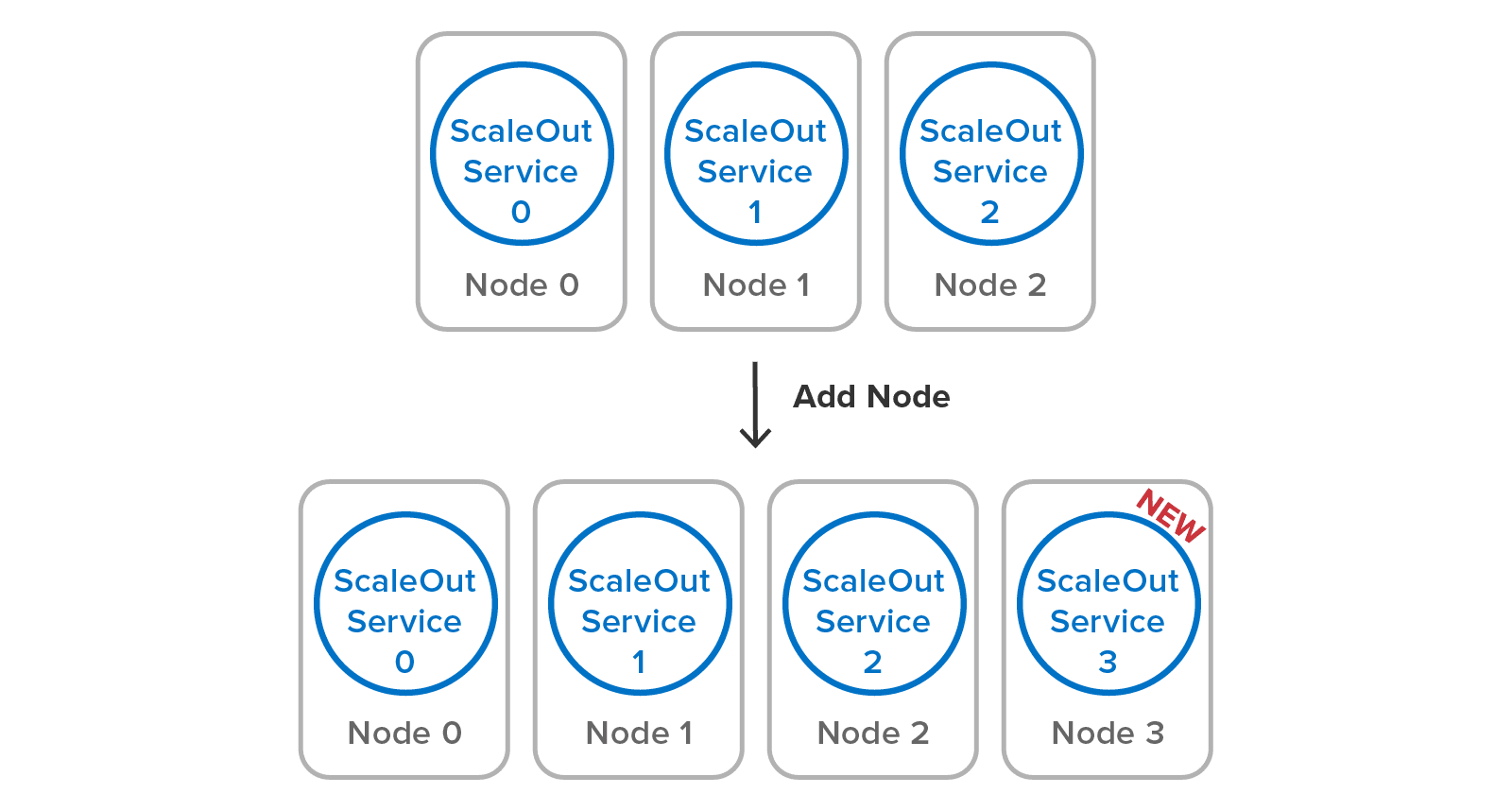 All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
Enter Redis
Open-source Redis was first created in 2009 for use on a single server, with clustering added in 2015. It has gained widespread popularity because of its rich set of data structures and commands. At the enterprise level, it has seen fast-growing adoption across many applications. As a result, the need to streamline cluster management procedures and increase data reliability for Redis users has become more urgent.
Introducing automated Redis clustering with ScaleOut In-Memory Database
We created ScaleOut In-Memory Database to meet this need. This product integrates open-source Redis code (version 6.2.5) that implements all the popular Redis data structures (strings, lists, sets, hashes, streams, and more) into ScaleOut’s automated cluster architecture and execution platform. Now, system administrators don’t need to manage Redis concepts like hashslots and shards. Instead, ScaleOut takes over these tasks using its built-in, fully automated mechanisms. Automated recovery and self-healing eliminate the need for manual intervention and increase uptime. What’s more, ScaleOut’s quorum-based updates replace Redis’s eventual consistency mechanism to deliver reliable data storage across servers. Applications can depend on the server cluster to survive a server failure without data loss, and the cluster remains available even if multiple servers fail.
To boost throughput and automatically make full use of all available processing cores, ScaleOut In-Memory Database integrates Redis command execution with its multi-threaded processing of client requests. Achieving this meant eliminating Redis’s native, single-threaded event-loop execution model without introducing a global lock that would constrain performance. The result is that each server in the cluster can run Redis commands simultaneously on all processing cores using a single service process.
Power with simplicity
We designed ScaleOut’s peer-to-peer cluster architecture to serve as the foundation for all user services. Hence, functions like clearing the database and backup/restore were built from the outset to run in parallel across all servers. This approach reduces the system administrator’s workload and delivers fast performance. To give Redis users the benefit of a fully parallel architecture, ScaleOut In-Memory Database provides a cluster-wide implementation of many Redis commands, such as PUBLISH and FLUSHALL.
ScaleOut In-Memory Database also overcomes the single-server limitation of the Redis SAVE command. It provides a cluster-wide implementation of backup/restore using its built-in parallel backup/restore utility. This allows system administrators to backup all Redis objects with one click in ScaleOut’s management console, and it delivers parallel speedup by running simultaneously on all servers. The user can backup either to local disks:
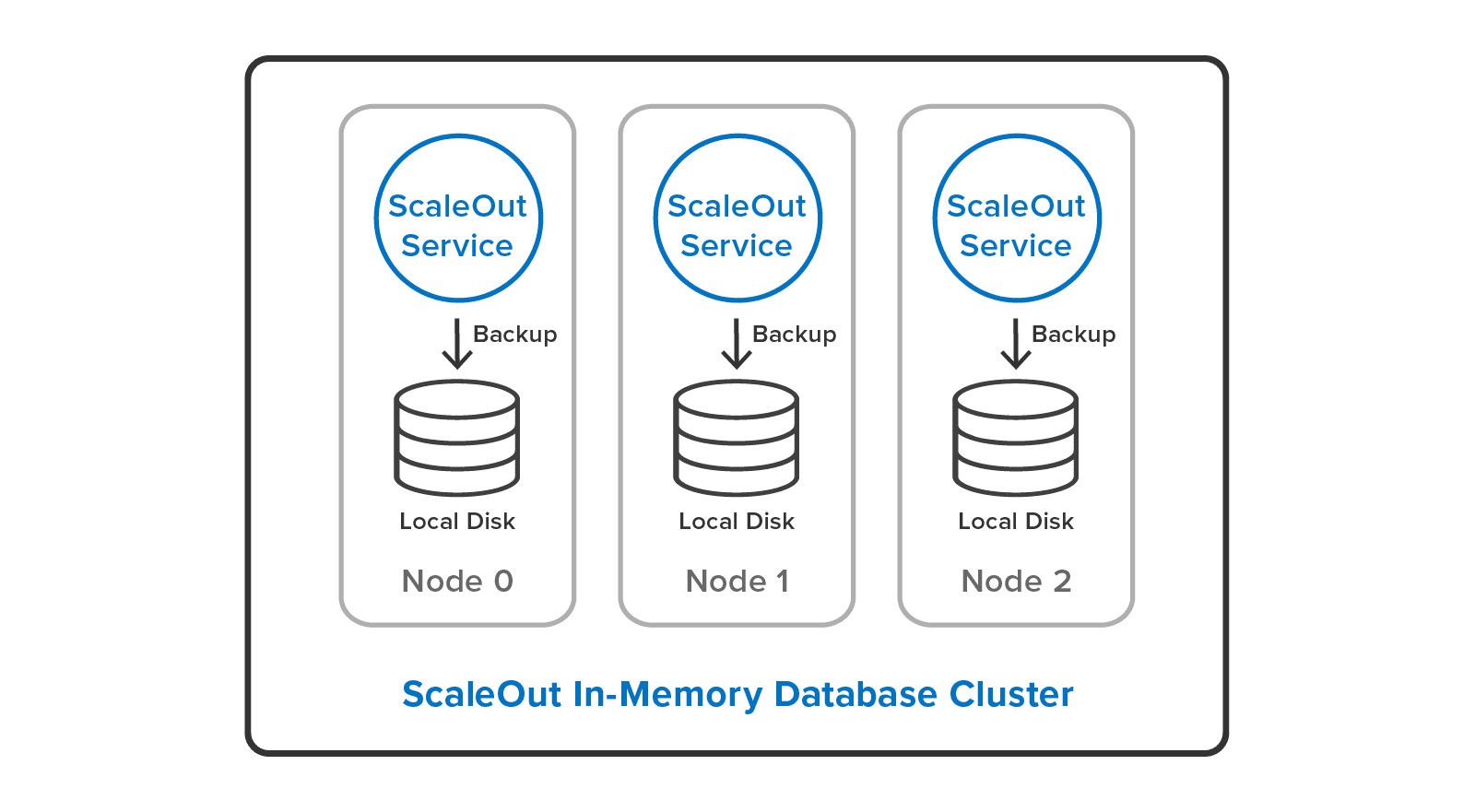
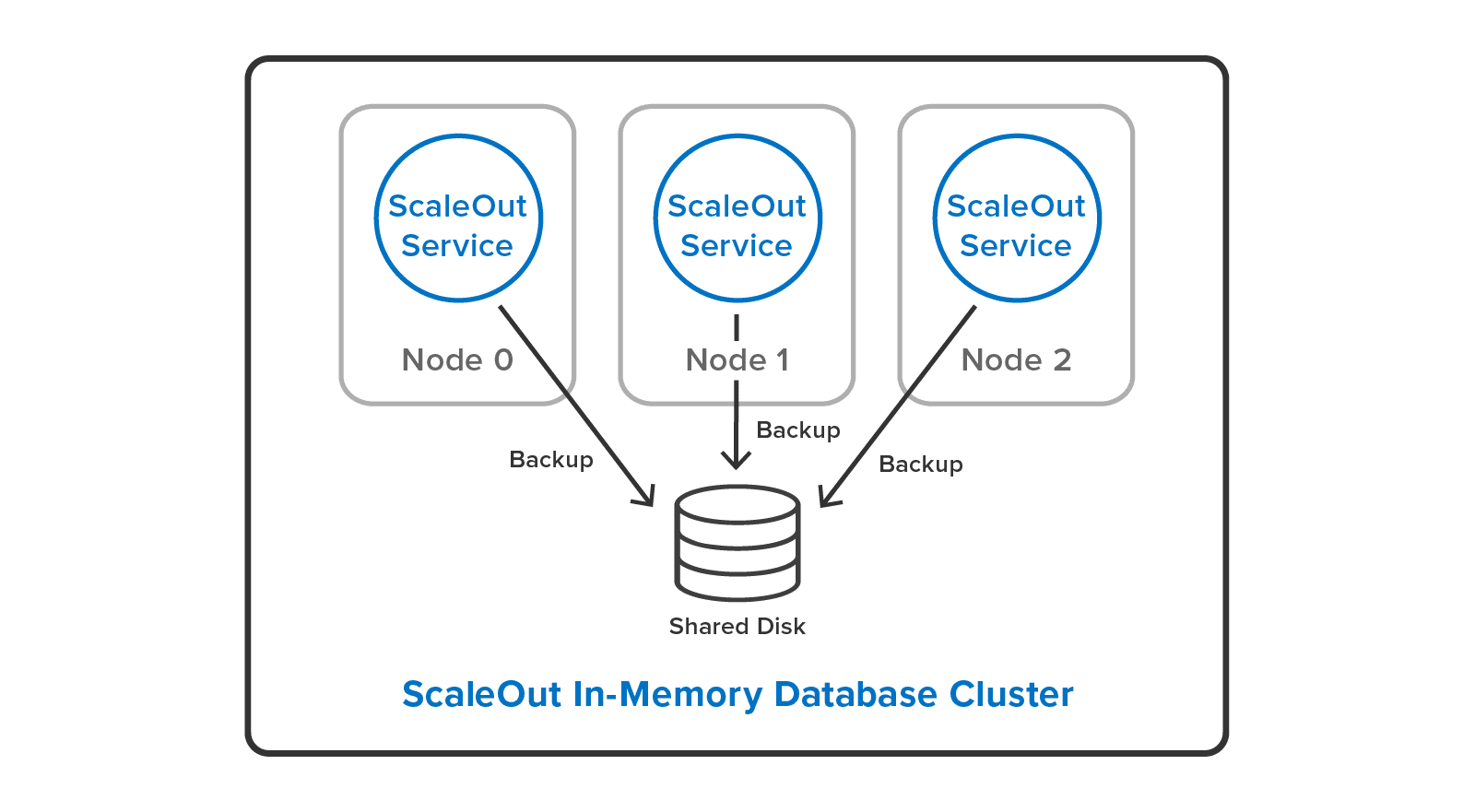
or to a single, shared disk:
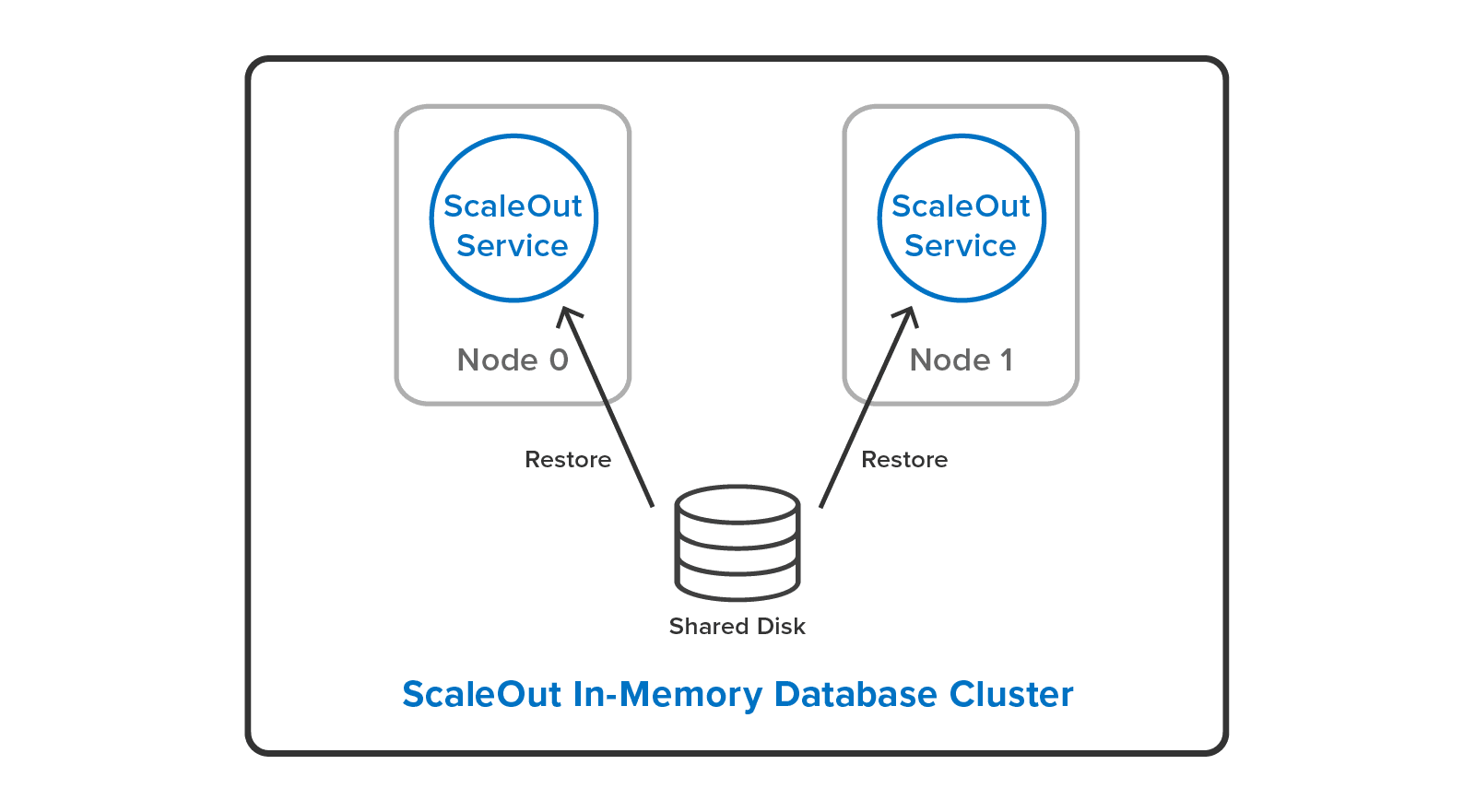
System administrators can cut down their workload by restoring backup files to a different cluster configuration than they used to make the backup. For example, it’s possible to restore a backup from a three-server cluster to a two-server cluster with a different hashslot mapping:
There’s a lot more in the new ScaleOut In-Memory Database than there’s room to discuss in depth here. For example, ScaleOut’s cluster stalls Redis command execution automatically when it moves hashslots between nodes for load-balancing, or when it performs recovery. This means clients always have a consistent view of the cluster. Also, the cluster stores Redis objects in their own ScaleOut namespace side-by-side with objects that ScaleOut’s native APIs manage. This lets users access the full power of ScaleOut’s in-memory computing features, including cluster-wide, data-parallel operations and stream processing with digital twins.
Summing Up
ScaleOut In-Memory Database makes scalable processing more convenient, reliable, and cost-effective for enterprise Redis users than ever before. By automating Redis cluster management, improving data reliability, and adding multi-threaded command execution, this product can significantly drive down the total cost of ownership for Redis deployments, even in comparison to commercial Redis alternatives. We invite you to check it out and see how it performs for you. We’d love to hear your feedback.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>The post Unlocking New Capabilities for Azure Digital Twins with Real-Time Analytics appeared first on ScaleOut Software.
]]>
The Need for Real-Time Analytics with Digital Twins
In countless applications that track live systems, real-time analytics plays a key role in identifying problems (or finding opportunities) and responding fast enough to make a difference. Consider a software telematics application that tracks a nationwide fleet of trucks to ensure timely deliveries. Dispatchers receive telemetry from trucks every few seconds detailing location, speed, lateral acceleration, engine parameters, and cargo viability. In a classic needle-and-haystack scenario, dispatchers must continuously sift through telemetry from thousands of trucks to spot issues, such as lost or fatigued drivers, engines requiring maintenance, or unreliable cargo refrigeration. They must intervene quickly to keep the supply chain running smoothly. Real-time analytics can help dispatchers tackle this seemingly impossible task by automatically sifting through telemetry as it arrives, analyzing it for anomalies needing attention, and alerting dispatchers when conditions warrant.
By using a process of divide and conquer, digital twins can dramatically simplify the construction of applications that implement real-time analytics for telematics or other applications. A digital twin for each truck can track that truck’s parameters (for example, maintenance and driver history) and its dynamic state (location, speed, engine and cargo condition, etc.). The digital twin can analyze telemetry from the truck to update this state information and generate alerts when needed. It can encapsulate analytics code or use machine learning techniques to look for anomalies. Running simultaneously, thousands of digital twins can track all the trucks in a fleet to keep dispatchers informed while reducing their workload.
Applying the digital twin model to real-time analytics expands its range of uses from its traditional home in product lifecycle management and infrastructure tracking to managing time-critical, live systems with many data sources. Examples include preventive maintenance, health-device tracking, logistics, physical and cyber security, IoT for smart cities, ecommerce shopping, financial services, and many others. But how can we integrate real-time analytics with digital twins and ensure high performance combined with straightforward application development?
Message Processing with Azure Digital Twins
Microsoft’s Azure Digital Twins provides a compelling platform for creating digital twin models with a rich set of features for describing their contents, including properties, components, inheritance, and more. The Azure Digital Twins Explorer GUI tool lets users view digital twin models and instances, as well as their relationships.
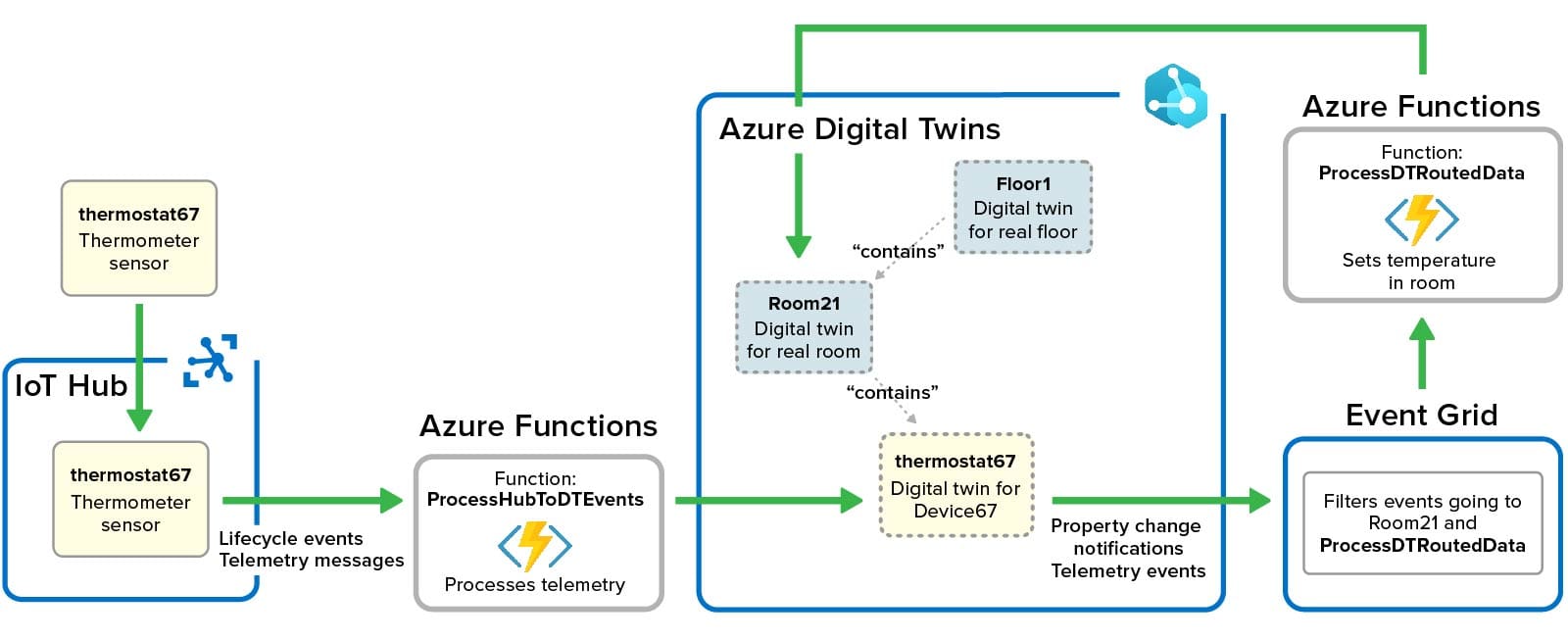
Azure digital twins can host dynamic properties that track the current state of physical data sources. Users can create serverless functions using Azure Functions to ingest messages generated by data sources and delivered to digital twins via Azure IoT Hub (or other message hubs). These functions update the properties of Azure digital twins using APIs provided for this purpose. Here’s a redrawn tutorial example that shows how Azure functions can process messages from a thermostat and update both its digital twin and a parent digital twin that models the room in which the thermostat is located. Note that the first Azure function’s update triggers the Azure Event Grid to run a second function that updates the room’s property:
The challenge in using serverless functions to process messages and perform real-time analytics is that they add overhead and complexity. By their nature, serverless functions are stateless and must obtain their state from external services; this adds latency. In addition, they are subject to scheduling and authentication overheads on each invocation, and this adds delays that limit scalability. The use of multiple serverless functions and associated mechanisms, such as Event Grid topics and routes, also adds complexity in developing analytics code.
Adding Real-Time Analytics Using In-Memory Computing
Integrating an in-memory computing platform with the Azure Digital Twins infrastructure addresses both of the challenges. This technology runs on a cluster of virtual servers and hosts application-defined software objects in memory for fast access along with a software-based compute engine that can run application-defined methods with extremely low latency. By storing each Azure digital twin instance’s properties in memory and routing incoming messages to an in-memory method for processing, both latency and complexity can be dramatically reduced, and real-time analytics can be scaled to handle thousands or even millions of data sources.
ScaleOut Software’s newly announced Azure Digital Twins Integration does just this. It integrates the ScaleOut Digital Twin Streaming Service, an in-memory computing platform running on Microsoft Azure (or on premises), with the Azure Digital Twins service to provide real-time streaming analytics. It accelerates message processing using in-memory computing to ensure fast, scalable performance while simultaneously streamlining the programming model.
The ScaleOut Azure Digital Twins Integration creates a component within an Azure Digital Twin model in which it hosts “real-time” properties for each digital twin instance of the model. These properties track dynamic changes to the instance’s physical data source and provide context for real-time analytics.
To implement real-time analytics code, application developers create a message-processing method for an Azure digital twin model. This method can be written in C# or Java, using an intuitive rules-based language, or by configuring machine learning (ML) algorithms implemented by Microsoft’s ML.NET library. It makes use of each instance’s real-time properties, which it stores in a memory-based object called a real-time digital twin, and the in-memory compute engine automatically persists these properties in the Azure digital twin instance.
Here’s a diagram that illustrates how real-time digital twins integrate with Azure digital twins to provide real-time streaming analytics:
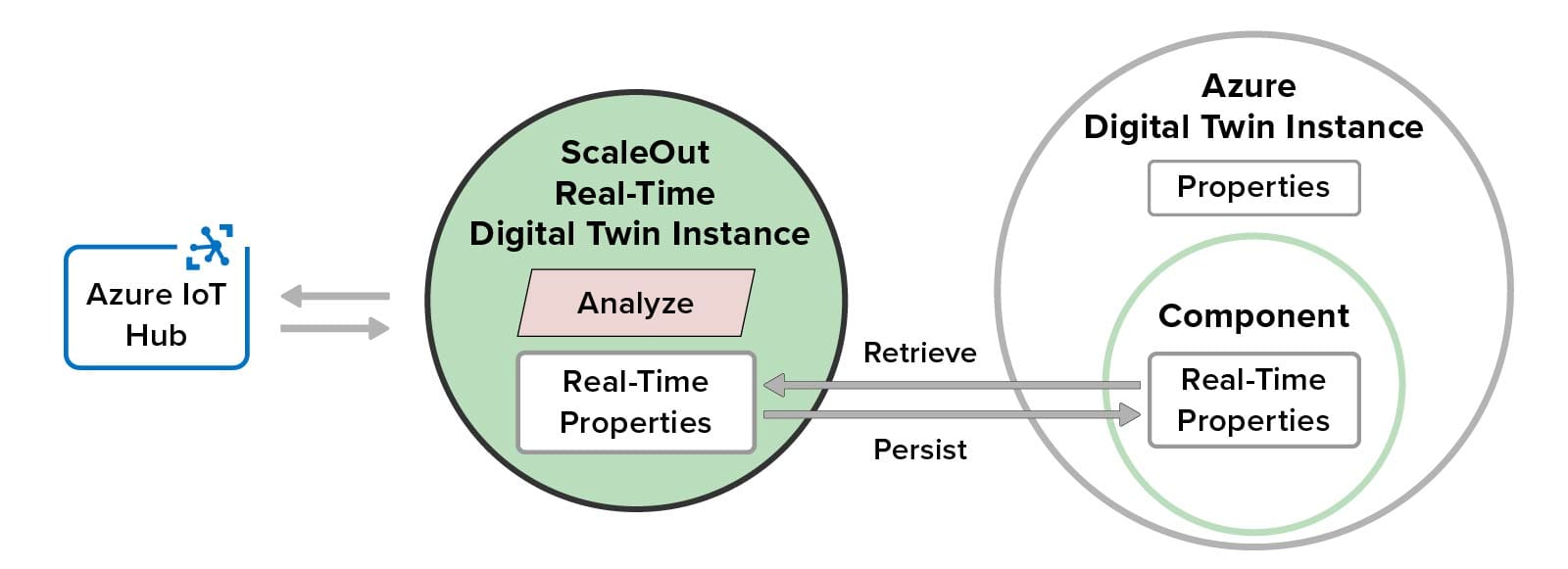
This diagram shows how each real-time digital twin instance maintains in-memory properties, which it retrieves when deployed, and automatically persists these properties in its corresponding Azure digital twin instance. The real-time digital twin connects to Azure IoT Hub or other message source to receive and then analyze incoming messages from its corresponding data source. Fast, in-memory processing provides sub-millisecond access to real-time properties and completes message processing with minimal latency. It also avoids repeated authentication delays every time a message is processed by authenticating once with the Azure Digital Twins service at startup.
All real-time analytics performed during message processing can run within a single in-memory method that has full access to the digital twin instance’s properties. This code also can access and update properties in other Azure digital twin instances. These features simplify design by avoiding the need to split functionality across multiple serverless functions and by providing a straightforward, object-oriented design framework with advanced, built-in capabilities, such as ML.
To further accelerate development, ScaleOut provides tools that automatically generate Azure digital twin model definitions for real-time properties. These model definitions can be used either to create new digital twin models or to add a real-time component to an existing model. Users just need to upload the model definitions to the Azure Digital Twins service.
Here’s how the tutorial example for the thermostat would be implemented using ScaleOut’s Azure Digital Twins Integration:
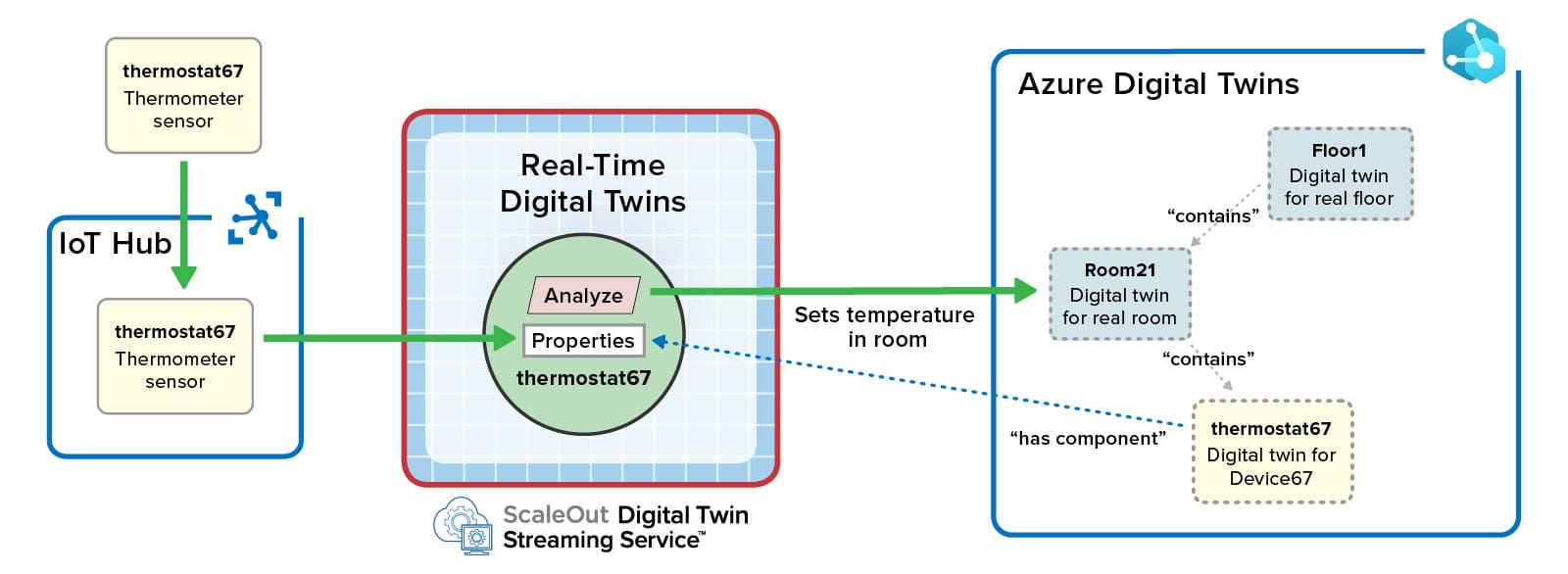 Note that the ScaleOut Digital Twins Streaming Service takes responsibility for ingesting messages from Azure IoT Hub and for invoking analytics code for the data source’s incoming messages. Multiple, pipelined connections with Azure IoT Hub ensure high throughput. Also note that the two serverless functions and use of Event Grid have been eliminated since the in-memory method handles both message processing and updates to the parent object (Room 21).
Note that the ScaleOut Digital Twins Streaming Service takes responsibility for ingesting messages from Azure IoT Hub and for invoking analytics code for the data source’s incoming messages. Multiple, pipelined connections with Azure IoT Hub ensure high throughput. Also note that the two serverless functions and use of Event Grid have been eliminated since the in-memory method handles both message processing and updates to the parent object (Room 21).
Combining the ScaleOut Digital Twin Streaming Service with Azure Digital Twins gives users the power of in-memory computing for real-time analytics while leveraging the full spectrum of Azure services and tools, as illustrated below for the thermostat example:
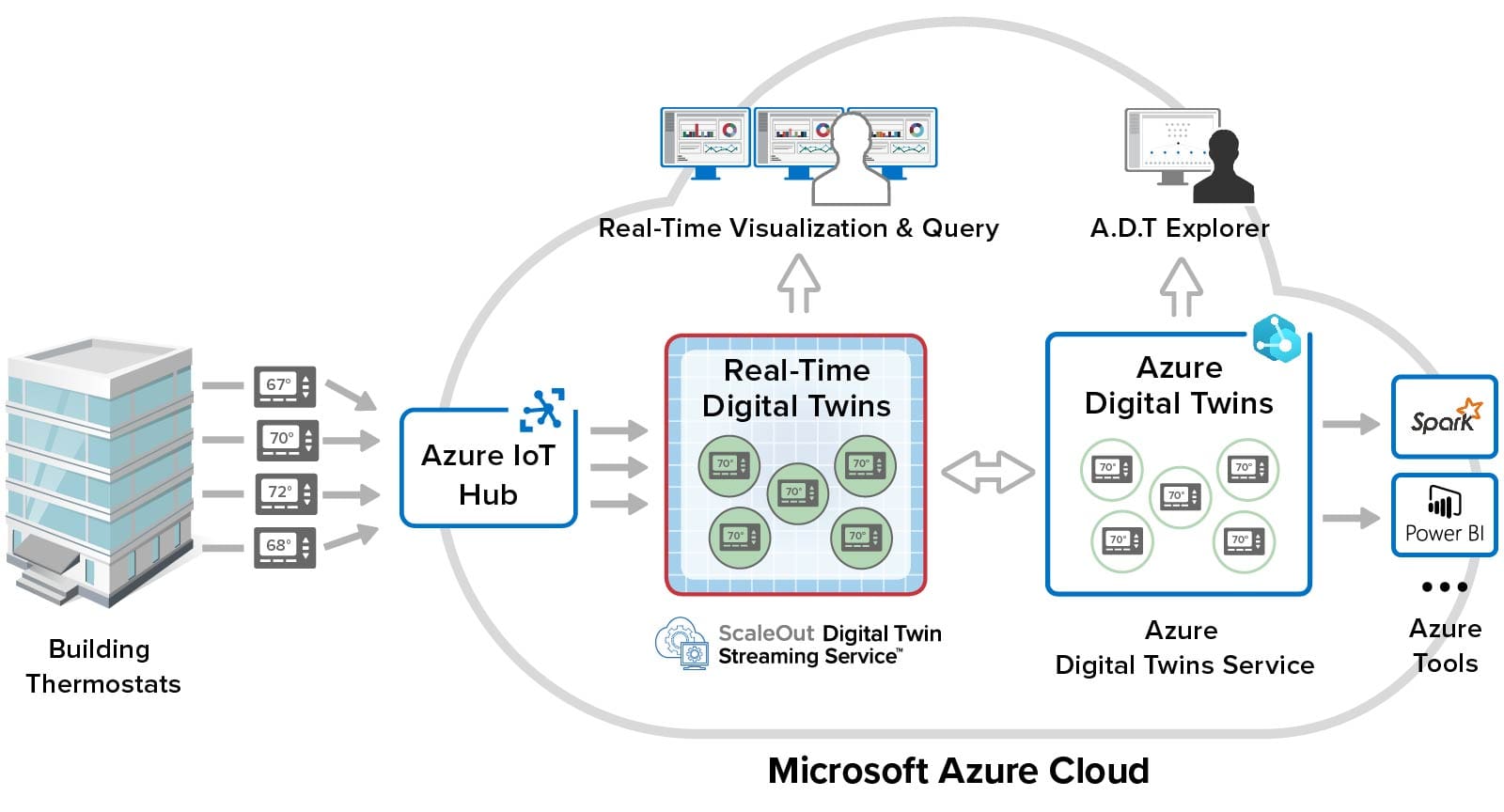
Users can view real-time properties with the Azure Digital Twins Explorer tool and track changes due to message processing. They also can take advantage of Azure’s ecosystem of big data analytics tools like Spark to perform batch processing. ScaleOut’s real-time data aggregation, continuous query, and visualization tools for real-time properties enable second-by-second tracking of live systems that boosts situational awareness for users.
Example of Real-Time Analytics with Azure Digital Twins
Incorporating real-time analytics using ScaleOut’s Azure Digital Twins Integration unlocks a wide array of applications for Azure Digital Twins. For example, here’s how the telematics software application discussed above could be implemented:
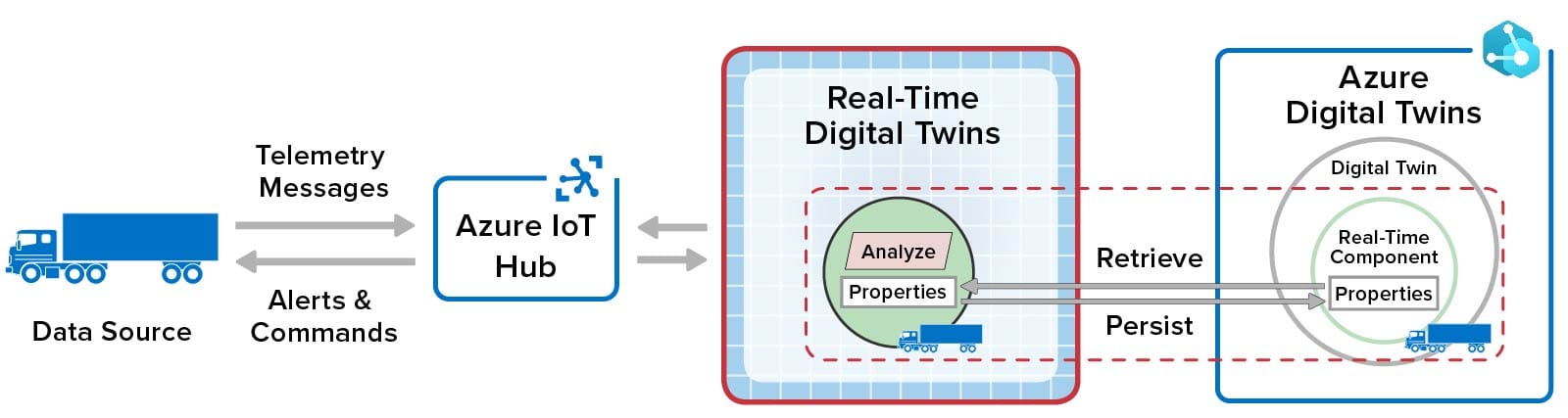
Each truck has a corresponding Azure digital twin which tracks its properties including a subset of real-time properties held in a component of each instance. When telemetry messages flow in to Azure IoT Hub, they are processed and analyzed by ScaleOut’s in-memory computing platform using a real-time digital twin that holds a truck’s real-time properties in memory for fast access and a message-processing method that analyzes telemetry changes, updates properties, and signals alerts when needed.
Real-time analytics can run ML algorithms that continuously examine telemetry, such as engine parameters, to detect anomalies and signal alerts. Digital twin analytics, combined with data aggregation and visualization powered by the in-memory platform, enable dispatchers to quickly spot emerging issues and take corrective action in a timely manner.
Summing Up
Digital twins offer a powerful means to model and visualize a population of physical devices. Adding real-time analytics to digital twins extends their reach into live, production systems that perform time-sensitive functions. By enabling managers to continuously examine telemetry from thousands or even millions of data sources and immediately identify emerging issues, they can avoid costly problems and capture elusive opportunities.
Azure Digital Twins has emerged as a compelling platform for hosting digital twin models. With the integration of in-memory computing technology using the ScaleOut Digital Twin Streaming Service, Azure Digital Twins gains the ability to analyze incoming telemetry with low latency, high scalability, and a straightforward development model. The combination of these two technologies has the potential to unlock a wide range of important new use cases for digital twins.
The post Unlocking New Capabilities for Azure Digital Twins with Real-Time Analytics appeared first on ScaleOut Software.
]]>The post Machine Learning Supercharges Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
When tracking telemetry from a large number of IoT devices, it’s essential to quickly detect when something goes wrong. For example, a fleet of long-haul trucks needs to meet demanding schedules and can’t afford unexpected breakdowns as a fleet manager manages thousands of trucks on the road. With today’s IoT technology, these trucks can report their engine and cargo status every few seconds to cloud-hosted telematics software. How can this software sift through the flood of incoming messages to identify emerging issues and avoid costly failures? Can the power of machine learning be harnessed to provide predictive analytics that automates the task of finding problems that are otherwise very difficult to detect?
As described in earlier blog posts, real-time digital twins offer a powerful software architecture for tracking and analyzing IoT telemetry from large numbers of data sources. A real-time digital twin is a software component running within a fast, scalable in-memory computing platform, and it hosts analytics code and state information required to track a single data source, like a truck within a fleet. Thousands of real-time digital twins run together to track all of the data sources and enable highly granular real-time analysis of incoming telemetry. By building on the widely used digital twin concept, real-time digital twins simultaneously enhance real-time streaming analytics and simplify application design.
Incorporating machine learning techniques into real-time digital twins takes their power and simplicity to the next level. While analytics code can be written in popular programming languages, such as Java and C#, or even using a simplified rules engine, creating algorithms that ferret out emerging issues hidden within a stream of telemetry still can be challenging. In many cases, the algorithm itself may be unknown because the underlying processes which lead to device failures are not well understood. In these cases, a machine learning (ML) algorithm can be trained to recognize abnormal telemetry patterns by feeding it thousands of historic telemetry messages that have been classified as normal or abnormal. No manual analytics coding is required. After training and testing, the ML algorithm can then be put to work monitoring incoming telemetry and alerting when it observes suspected abnormal telemetry.
To enable ML algorithms to run within real-time digital twins, ScaleOut Software has integrated Microsoft’s popular machine learning library called ML.NET into its Azure-based ScaleOut Digital Twin Streaming Service. Using the ScaleOut Model Development Tool (formerly called the ScaleOut Rules Engine Development Tool), users can select, train, evaluate, deploy, and test ML algorithms within their real-time digital twin models. Once deployed, the ML algorithm runs independently for each data source, examining incoming telemetry within milliseconds after it arrives and logging abnormal events. The real-time digital twin also can be configured to generate alerts and send them to popular alerting providers, such as Splunk, Slack, and Pager Duty. In addition, business rules optionally can be used to further extend real-time analytics.
The following diagram illustrates the use of an ML algorithm to track engine and cargo parameters being monitored by a real-time digital twin hosting an ML algorithm for each truck in a fleet. When abnormal parameters are detected by the ML algorithm (as illustrated by the spike in the telemetry), the real-time digital twin records the incident and sends a message to the alerting provider:
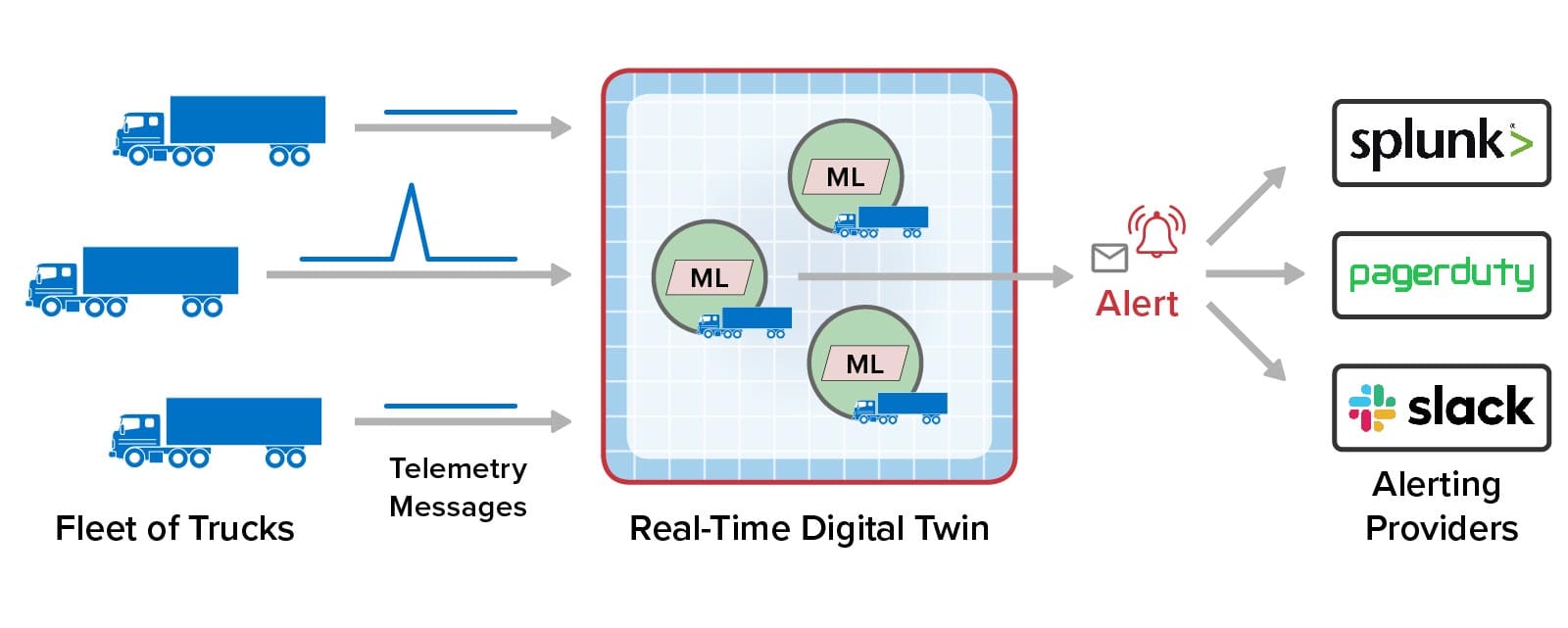
Training an ML algorithm to recognize abnormal telemetry just requires supplying a training set of historic data that has been classified as normal or abnormal. Using this training data, the ScaleOut Model Development Tool lets the user train and evaluate up to ten binary classification algorithms supplied by ML.NET using a technique called supervised learning. The user can then select the appropriate trained algorithm to deploy based on metrics for each algorithm generated during training and testing. (The algorithms are tested using a portion of the data supplied for training.)
For example, consider an electric motor which periodically supplies three parameters (temperature, RPM, and voltage) to its real-time digital twin for monitoring by an ML algorithm to detect anomalies and generate alerts when they occur:
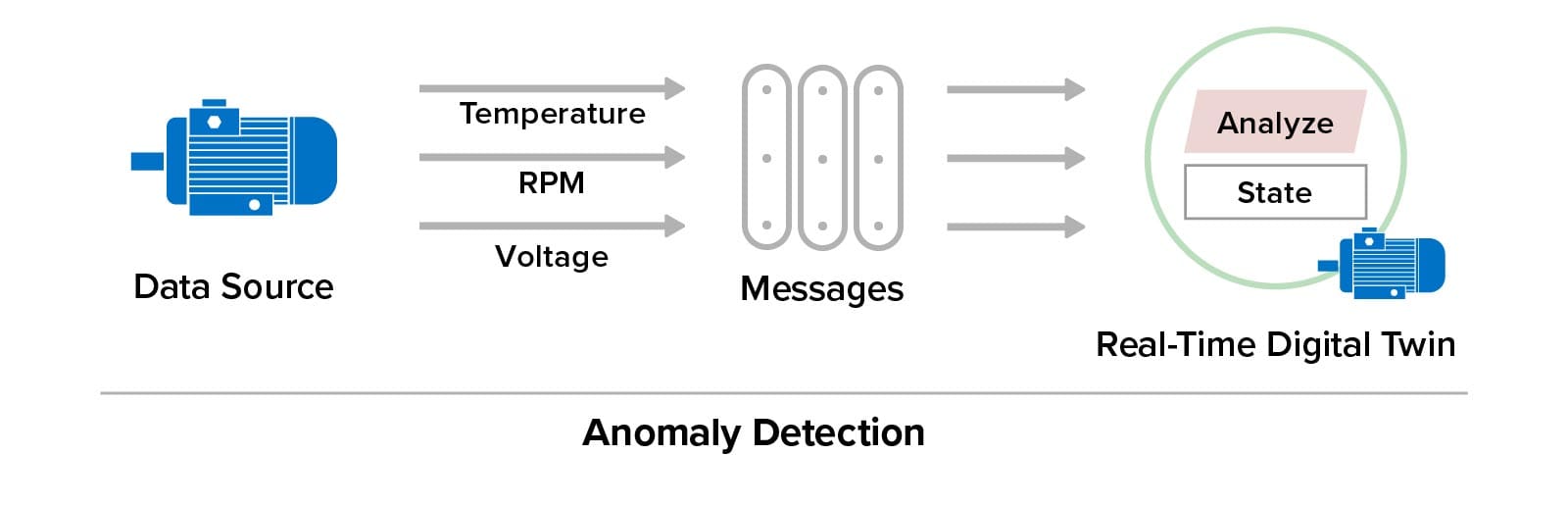
Training the real-time digital twin’s ML model follows the workflow illustrated below:
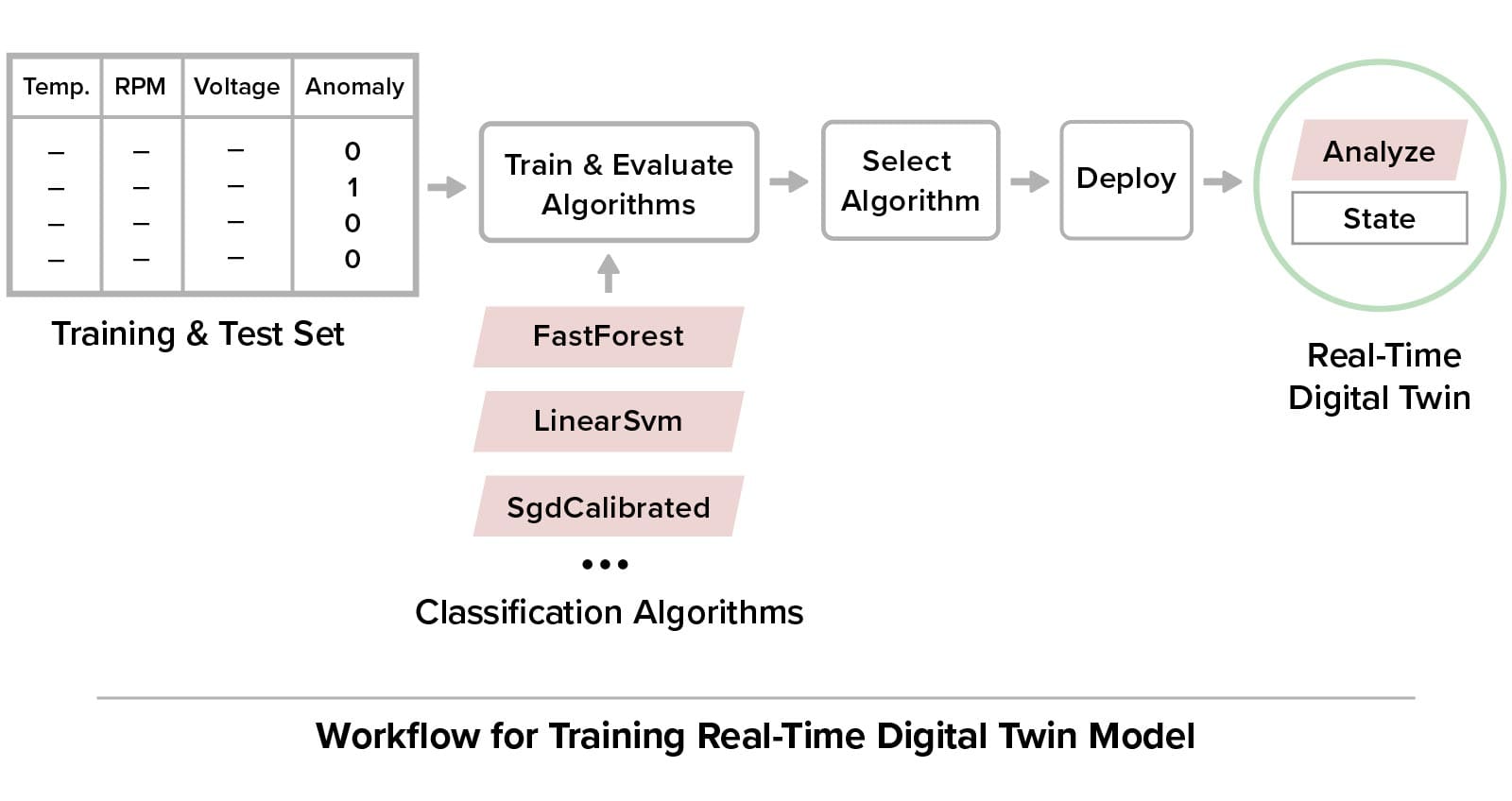
Here’s a screenshot of the ScaleOut Model Development Tool that shows the training of selected ML.NET algorithms for evaluation by the user:
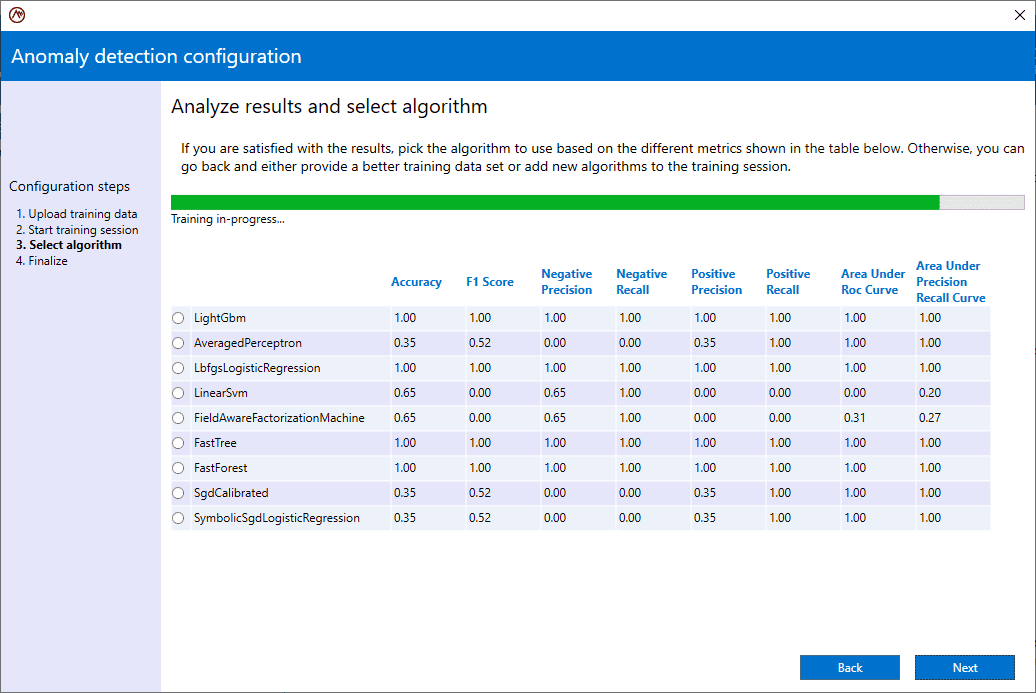
The output of this process is a real-time digital twin model which can be deployed to the streaming service. As each motor reports its telemetry to the streaming service, a unique real-time digital twin “instance” (a software object) is created to track that motor’s telemetry using the ML algorithm.
In addition to supervised learning, ML.NET provides an algorithm (called an adaptive kernel density estimation algorithm) for spike detection, which detects rapid changes in telemetry for a single parameter. The ScaleOut Model Development Tool lets users add spike detection for selected parameters using this algorithm. In addition, it is often useful to detect unusual but subtle changes in a parameter’s telemetry over time. For example, if the temperature for an electric motor is expected to remain constant, it would be useful to detect a slow rise in temperature that might otherwise go unobserved. To address this need, the tool lets users make use of a ScaleOut-developed, linear regression algorithm that detects and reports inflection points in the telemetry for a single parameter. These two techniques for tracking changes in a telemetry parameter are illustrated below:
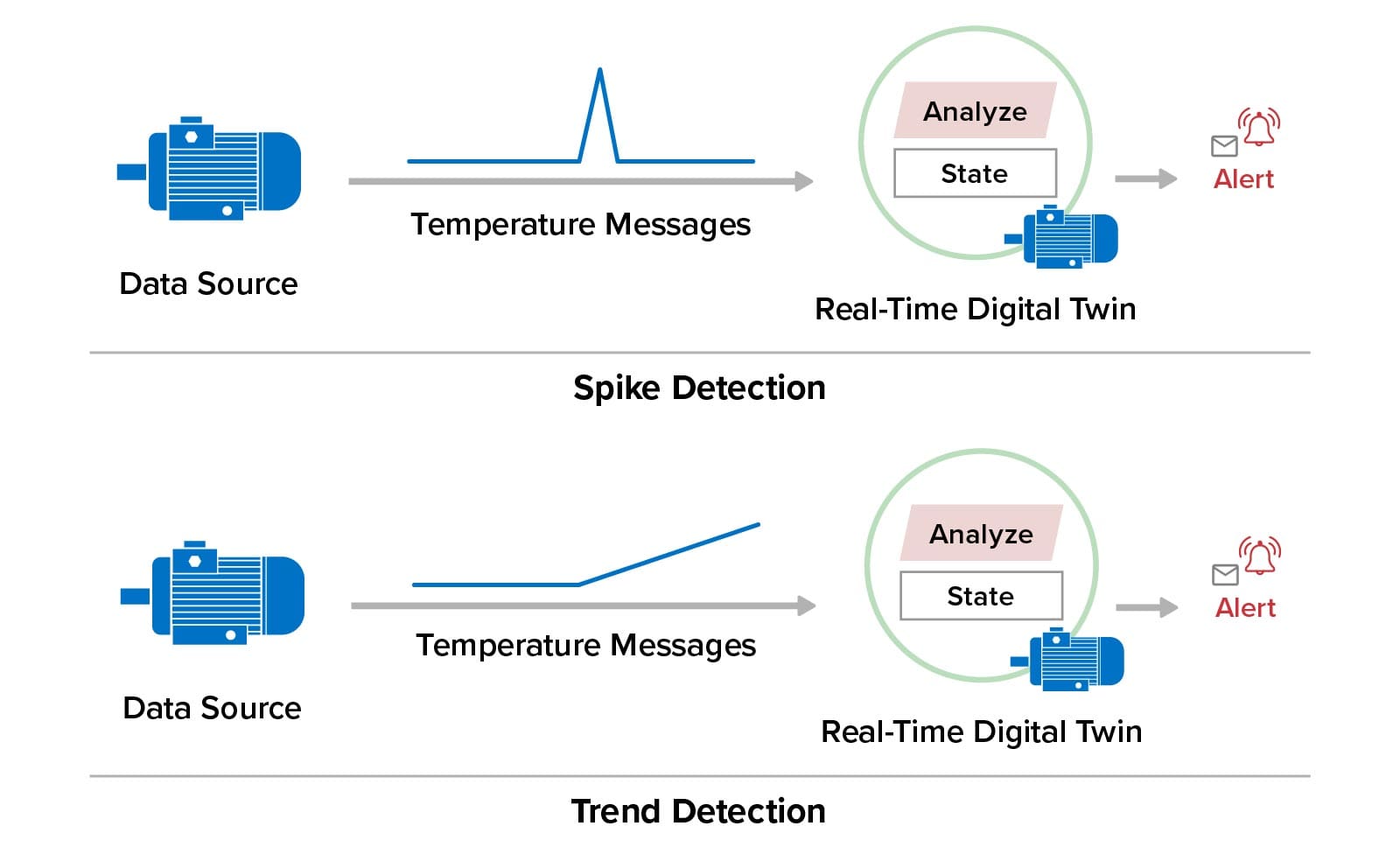
Summing Up
Machine learning provides important real-time insights that enhance situational awareness and enable fast, effective responses. They often can provide useful analytics for complex datasets that cannot be analyzed with hand-coded algorithms. Their usefulness and rate of adoption is quickly growing. Using the ScaleOut Model Development Tool, real-time digital twins now can easily be enhanced to automatically analyze incoming telemetry messages with machine learning techniques that take full advantage of Microsoft’s ML.NET library. The integration of machine learning with real-time digital twins enables thousands of data streams to be automatically and independently analyzed in real-time with fast, scalable performance. Best of all, no coding is required, enabling fast, easy model development. By combining ML with real-time digital twins, the ScaleOut Digital Twin Streaming Service adds important new capabilities for real-time streaming analytics that supercharge the Azure IoT ecosystem.
Read more about the ScaleOut Model Development Tool.
The post Machine Learning Supercharges Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Redis vs ScaleOut: What You Need to Know appeared first on ScaleOut Software.
]]>
ScaleOut’s Battle-Tested Clustering Technology Give It Key Advantages Over Redis®* in Ease of Use and Performance
By William L. Bain and Bryce C. Klinker
Breaking news: ScaleOut Software has announced a community preview of support for Redis clients in ScaleOut StateServer. Learn more here.
Distributed caching technology first hit the market in about 2001 with the introduction of Tangosol Coherence and has been evolving ever since. Designed to help applications scale performance by eliminating bottlenecks in accessing data, this distributed computing technology stores live, fast-changing data in memory across a cluster of inexpensive, commodity servers or virtual machines. The combination of fast, memory-based data storage and throughput scaling with multiple servers results in consistently fast access and update times for growing workloads, such as e-commerce, financial services, IoT device tracking, and other applications.
ScaleOut Software introduced its distributed caching product, ScaleOut StateServer® (SOSS), in 2005 and has made continuous enhancements over the last 16 years. While the single-server version of Redis was released in 2009 by Salvatore Sanfilippo, clustering support was first added in 2015. These two products embody highly different design goals. SOSS was designed as an integrated distributed caching architecture incorporating transparent throughput scaling and high availability using data replication with the goals of maximizing performance, ease of use, and portability across operating systems. In contrast, according to M. Russo, Redis was conceived as a single-server, data-structure store to improve the performance of a real-time data analytics product. (Beyond just storing strings or opaque objects, a data-structure store also implements various data types, such as lists and sorted sets.) Clustering was added to Redis’ single-server architecture after 4 years to provide a way to scale.
As background for the following discussion, it’s important to review some key concepts. Most distributed caches use a key/value storage model that identifies stored objects using string keys. To distribute objects across multiple servers in a cluster, a distributed cache typically maps keys to hash slots, each of which holds a subset of objects. The cache then distributes hash slots across the servers and moves them between servers as needed to balance the workload; this process is called sharding. A group of hash slots running on a single server (called a node here) can either be a primary or replica. Clients direct updates to the target hash slot on a primary node, which replicates the update to one or more replica nodes for high availability in case the primary node fails.
Ease of Use
The differences in design goals of the two technologies have led to very different impacts on users. To maximize ease of use, SOSS automatically creates and manages hash slots for the user, including primaries and replicas. Using a built-in load-balancer, each service internally manages a subset of both primary and replica hash slots, as illustrated below. Users just create a single SOSS service process on every node, and these service processes discover each other and distribute the hash slots among themselves to balance the workload. They also automatically handle all aspects of recovery after a node fails.
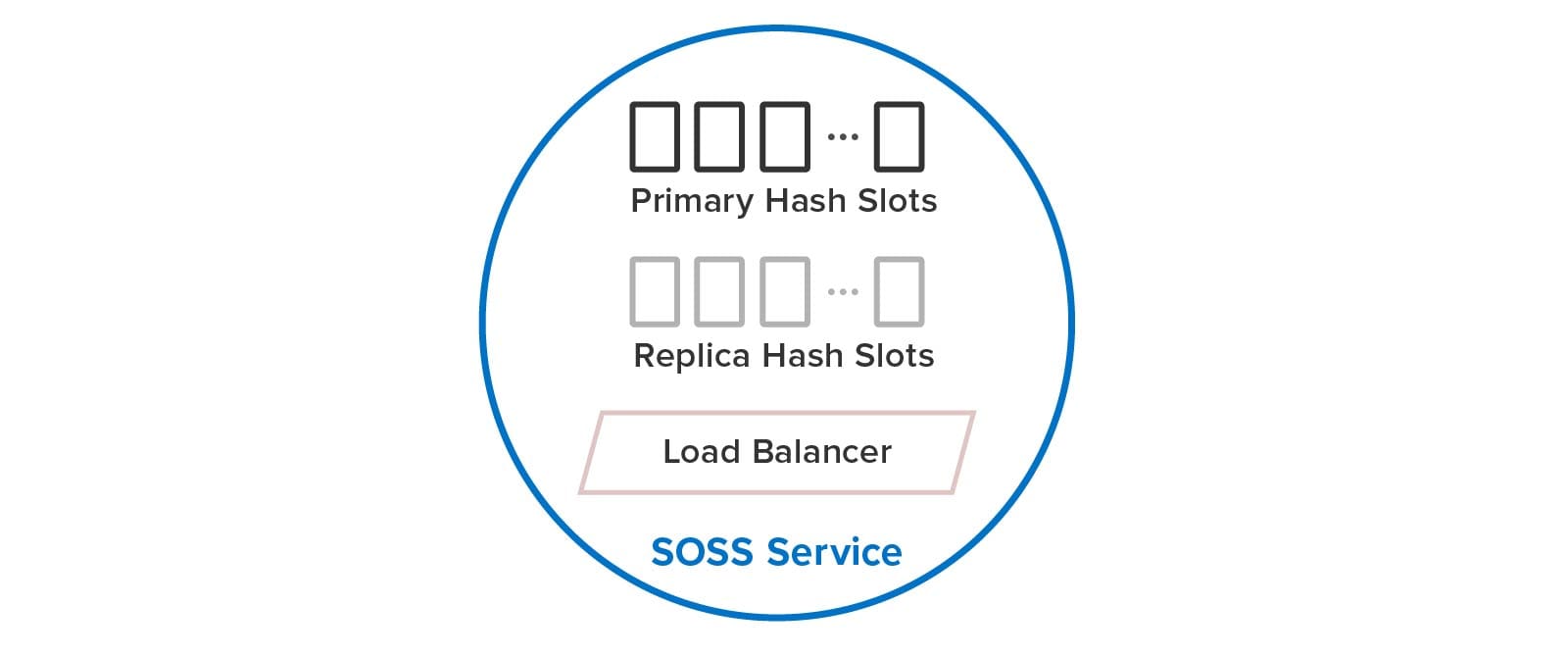
In contrast, Redis users create separate service processes on each node for primary and replica hash slots and must manually distribute the hash slots among the primaries. (Unlike SOSS, a 1-node or 2-node Redis cluster is not allowed.) As we will see below, users must perform a complex set of manual actions when adding and removing nodes and to heal and rebalance the cluster after a node fails. The following diagram illustrates the difference between Redis and SOSS in the user’s view of the cluster:
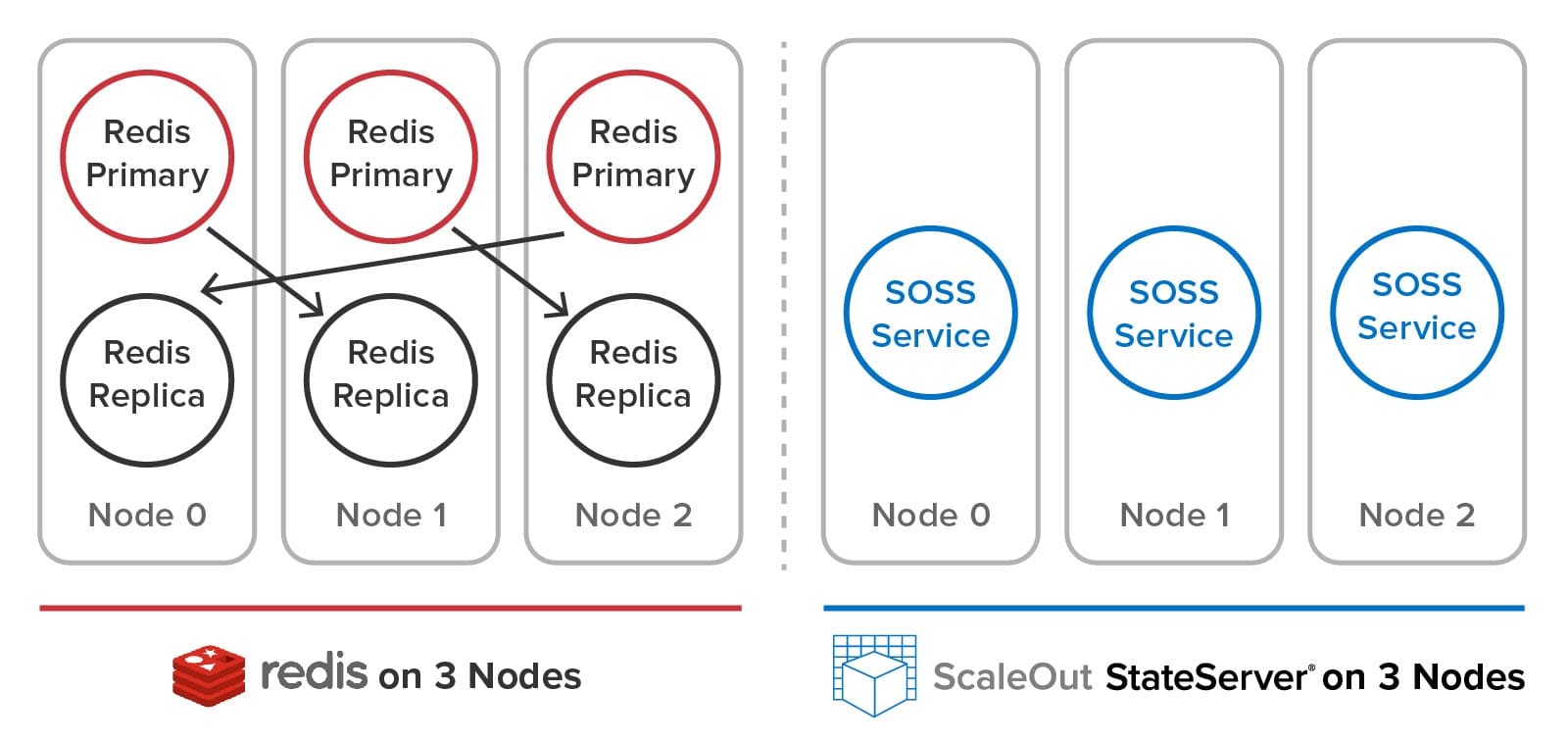
Adding a Node to the Cluster Using SOSS
To illustrate how SOSS’s built-in mechanisms for managing hash slots, load-balancing, failure detection, and self-healing simplify cluster management, let’s look at the steps needed to add a node to the cluster. When using SOSS, the user just installs the service on a new node and clicks a button in the management console to join the cluster. Using multicast discovery (or optional host list if multicast is not available), the service process automatically receives primary and replica hash slots and starts handling its portion of the workload. The following diagram shows the addition of a fourth node to a cluster:
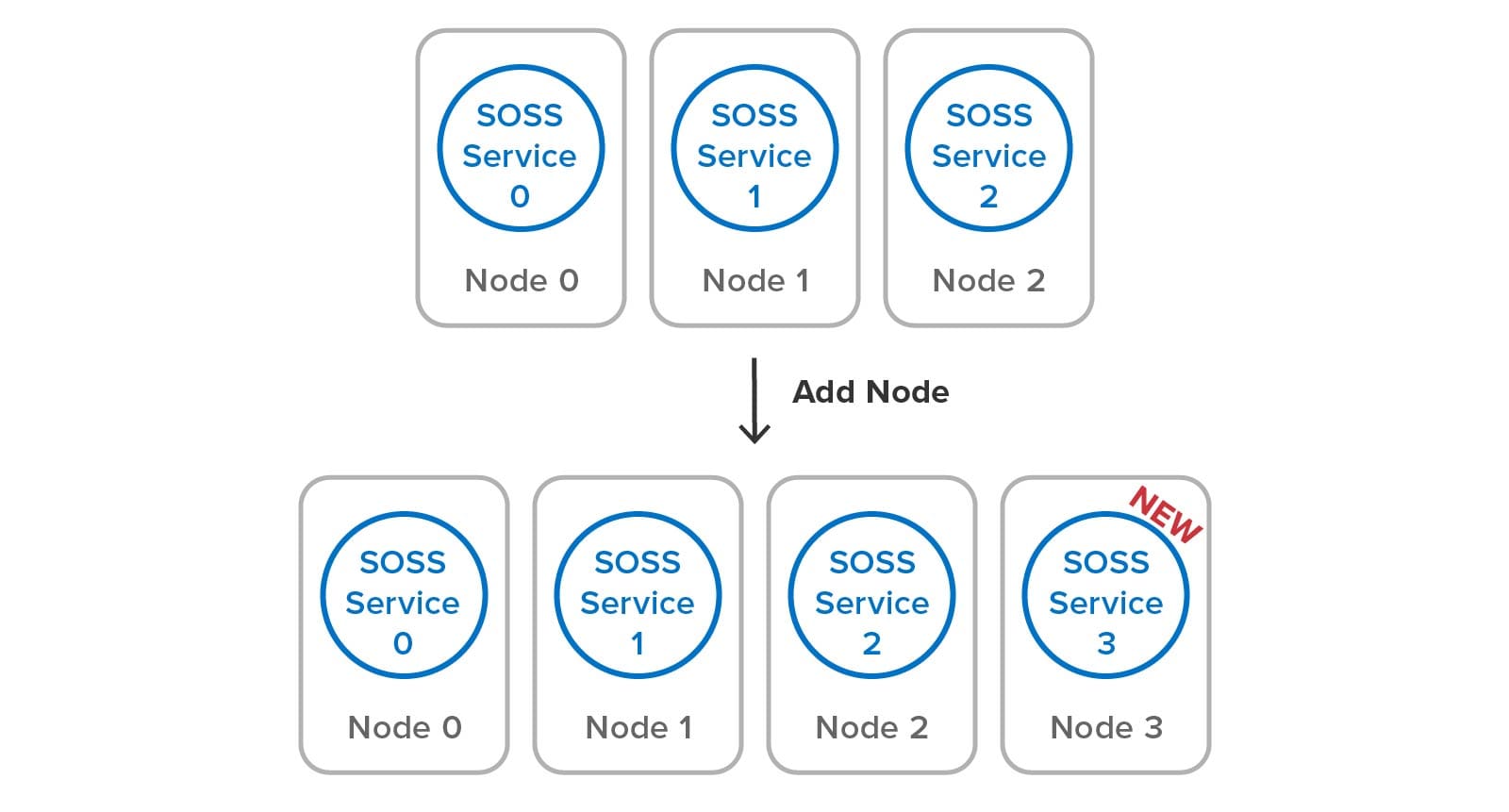
Adding a Node to the Cluster Using Redis
Because Redis requires the user to manage the creation of primary and replica service processes (sometimes called shards) and the management of hash slots, many more steps must be performed to add a node to the cluster. To accomplish this, the user runs administrative commands that create the new processes, connect the primaries and replicas, move the replicas as necessary, and reallocate the hash slots among the nodes. The required configuration changes are illustrated below:
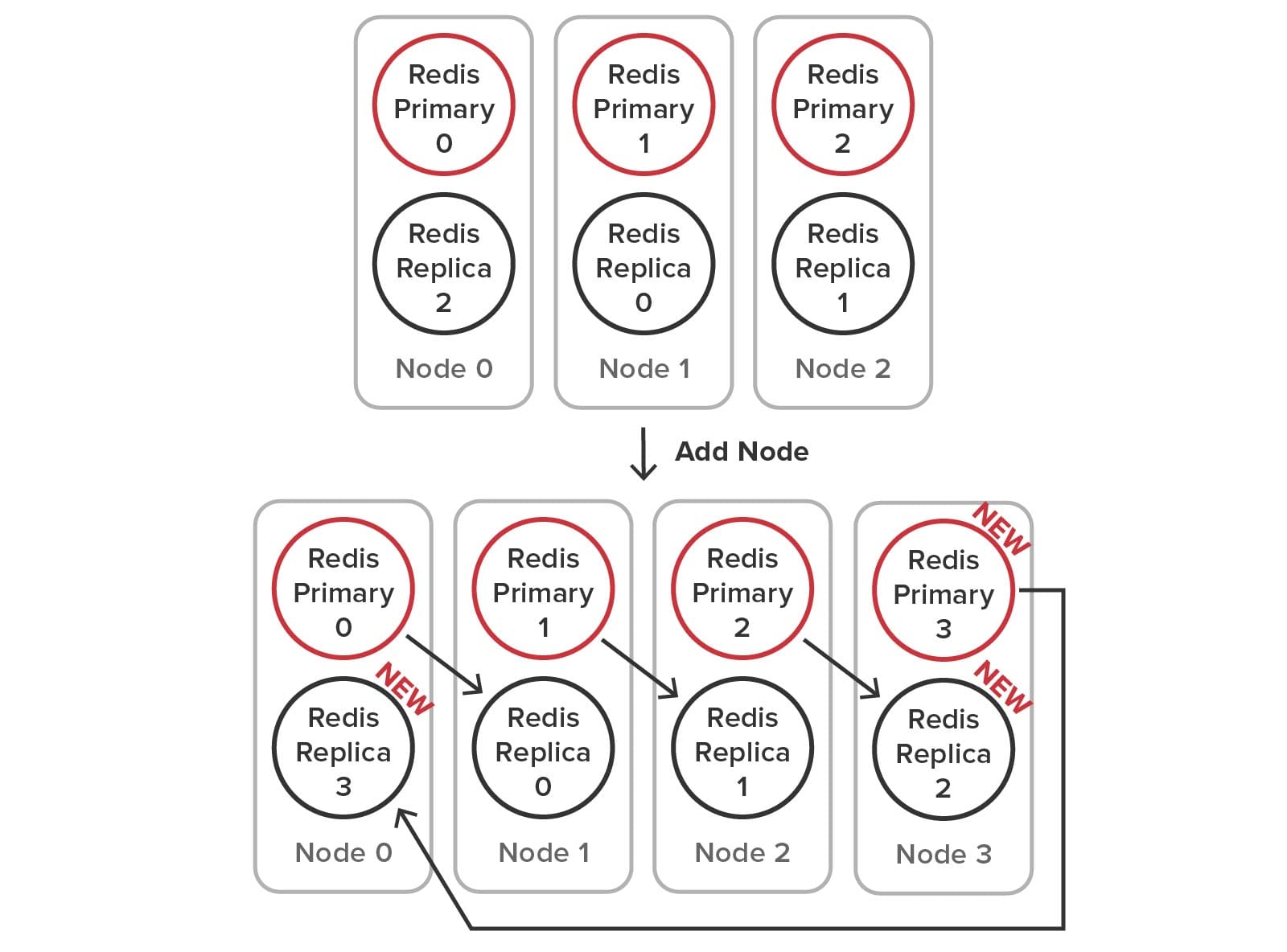
Here is an example of administrative steps required to make the configuration changes (using node 0’s IP and port as the bootstrap address for the new node):
// Start up a new replica redis-server instance on node 3 for primary 2:
redis-cli --cluster add-node host3Ip:replicaPort node0Ip:node0Port --cluster-slave
--cluster-master-id primary2NodeID
// Start up a new primary redis-server instance on node 3:
redis-cli --cluster add-node host3Ip:primaryPort existingIp:existingPort
// Connect to replica 2 on node 0 and modify it to replicate primary 3:
redis-cli -h replica2Ip -p -replica2Port > cluster replicate primary3NodeID
// Reshard the cluster by interactively moving hash slots from existing nodes to node 3:
redis-cli --cluster reshard existingIp:existingPort
> How many slots to move? 4096 //16384 / 4 = 4096
> What node to move slots to? primary3NodeID // (primary3NodeID returned by previous command)
> What nodes to move slots from? all
This process is complex, and it becomes more difficult to keep track of the distribution of hash slots with larger cluster memberships. Removing a node has comparable complexity.
Recovering After a Node Fails (SOSS and Redis)
SOSS’s service processes automatically detect and recover from the loss of a node. They use built-in, scalable, peer-to-peer heart-beating to detect missing node(s) and create a new, coherent cluster membership. Next, they promote replica hash slots to primaries on the surviving nodes, create new replicas for self-healing, and rebalance the workload across the nodes.
Redis does not implement a coherent cluster membership and does not provide automatic self-healing and recovery. Each Redis node sends heartbeat messages to random other nodes to detect possible failures, and the cluster uses a gossip mechanism to declare that a node has failed. After that, its replica on a different node promotes itself to a primary so that the hash slots remain available, but Redis does not self-heal by creating a new replica for the hash slots. Also, it does not automatically redistribute the hash slots across the nodes to rebalance the workload. These tasks are left to the system administrator, who needs to sort out the needed configuration changes and implement them to restore a fully redundant, balanced cluster.
Performance Comparison
The different design choices between SOSS and Redis also lead to semantic and performance differences. To maximize ease of use for application developers, SOSS maintains all stored data with full consistency (to be more precise, sequential consistency), ensuring that it only serves the latest updates and never loses data after the failure of a single server (or two servers if multiple replicas are used). This design choice targets enterprise applications that need to ensure that the distributed cache always returns the correct data. To implement data replication across multiple replicas with the highest possible performance, SOSS uses a patented quorum algorithm.
In contrast, Redis employs an eventual consistency model with asynchronous replication. In general, this choice enables higher throughput because updates do not have to wait for replication to complete before responding to the user. It also enables potentially higher read throughput by serving reads from replicas even if they are not guaranteed to serve the latest updates.
Given these two design choices, it’s valuable to compare the throughput of the two distributed caches as nodes are added and the workload is simultaneously increased, as illustrated below. This technique evaluates how well the caches can scale their throughput by adding nodes to handle increasing workload; linear throughput scaling ensures consistently fast response times. (For a discussion of throughput scaling in distributed systems, see Gustafson’s Law.).
To perform an apples-to-apples throughput comparison of Redis 6.2 and SOSS 5.10, SOSS was configured to use eventual consistency (“EC”) when updating replicas. The performance of SOSS with full consistency (“FC”) was also measured. Tests were run for 3, 4, and 6 node clusters in AWS on m5.xlarge instances with 4 cores@2.5 Ghz, and 16GB RAM. The clients ran read/update pairs on 100K objects of sizes 2KB and 20KB to represent a typical web workload with a 1:1 read/update ratio. The results are as follows:
SOSS provided consistently higher throughput than Redis when eventual consistency was used to perform updates (the blue and gray lines in the charts). Running SOSS with full consistency (the red lines) resulted in lower throughput, as expected, since updates have to be committed at the replica before responding to the client instead of being performed asynchronously. However, both Redis and SOSS with full consistency delivered close to the same throughput for 20KB objects. This may be due to benefits of SOSS’s client-side caching, which eliminated unnecessary data transfers during reads.
Summing Up
Our comparison of SOSS and Redis shows the benefits of ScaleOut’s integrated clustering architecture. A key design goal for SOSS was to simplify the user’s workload by providing a unified, location-transparent data cache with built-in, fully automatic load-balancing and high availability. By hiding the inner workings of hash slots, heart-beating, replica placement, load-balancing, and self-healing, the application developer and systems administrator can focus on simply using the distributed cache instead of configuring its implementation. In our view, Redis’s approach of exposing these complex mechanisms to the user significantly steepens the learning curve and increases the user’s workload.
It might come as a surprise to learn that in the above benchmark testing, SOSS maintained a consistent performance advantage. We attribute this to ScaleOut’s approach of designing an integrated cluster architecture from the outset instead of adding clustering to a single server data store, as Redis did. This approach enabled design freedom at every step to eliminate distributed bottlenecks, and it led to extensive use of multithreading and internal data sharding within each service process to extract maximum performance from multi-core servers.
Lastly, SOSS demonstrates that the CAP theorem doesn’t really prevent the use of full consistency when building a scalable, distributed cache. For many enterprise applications, which demand data integrity at all times, this may be the better choice.
Learn more about how ScaleOut StateServer compares to Redis.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Redis vs ScaleOut: What You Need to Know appeared first on ScaleOut Software.
]]>The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
]]>Real-Time Device Tracking with In-Memory Computing Can Fill an Important Gap in Today’s Streaming Analytics Platforms
We are increasingly surrounded by intelligent IoT devices, which have become an essential part of our lives and an integral component of business and industrial infrastructures. Smart watches report biometrics like blood pressure and heartrate; sensor hubs on long-haul trucks and delivery vehicles report telemetry about location, engine and cargo health, and driver behavior; sensors in smart cities report traffic flow and unusual sounds; card-key access devices in companies track entries and exits within businesses and factories; cyber agents probe for unusual behavior in large network infrastructures. The list goes on.
The Limitations of Today’s Streaming Analytics
How are we managing the torrent of telemetry that flows into analytics systems from these devices? Today’s streaming analytics architectures are not equipped to make sense of this rapidly changing information and react to it as it arrives. The best they can usually do in real-time using general purpose tools is to filter and look for patterns of interest. The heavy lifting is deferred to the back office. The following diagram illustrates a typical workflow. Incoming data is saved into data storage (historian database or log store) for query by operational managers who must attempt to find the highest priority issues that require their attention. This data is also periodically uploaded to a data lake for offline batch analysis that calculates key statistics and looks for big trends that can help optimize operations.
![]()
What’s missing in this picture? This architecture does not apply computing resources to track the myriad data sources sending telemetry and continuously look for issues and opportunities that need immediate responses. For example, if a health tracking device indicates that a specific person with known health condition and medications is likely to have an impending medical issue, this person needs to be alerted within seconds. If temperature-sensitive cargo in a long haul truck is about to be impacted by an erratic refrigeration system with known erratic behavior and repair history, the driver needs to be informed immediately. If a cyber network agent has observed an unusual pattern of failed login attempts, it needs to alert downstream network nodes (servers and routers) to block the kill chain in a potential attack.
A New Approach: Real-Time Device Tracking
To address these challenges and countless others like them, we need autonomous, deep introspection on incoming data as it arrives and immediate responses. The technology that can do this is called in-memory computing. What makes in-memory computing unique and powerful is its two-fold ability to host fast-changing data in memory and run analytics code within a few milliseconds after new data arrives. It can do this simultaneously for millions of devices. Unlike manual or automatic log queries, in-memory computing can continuously run analytics code on all incoming data and instantly find issues. And it can maintain contextual information about every data source (like the medical history of a device wearer or the maintenance history of a refrigeration system) and keep it immediately at hand to enhance the analysis. While offline, big data analytics can provide deep introspection, they produce answers in minutes or hours instead of milliseconds, so they can’t match the timeliness of in-memory computing on live data.
The following diagram illustrates the addition of real-time device tracking with in-memory computing to a conventional analytics system. Note that it runs alongside existing components. It adds the ability to continuously examine incoming telemetry and generate both feedback to the data sources (usually, devices) and alerts for personnel in milliseconds:
![]()
In-Memory Computing with Real-Time Digital Twins
Let’s take a closer look at today’s conventional streaming analytics architectures, which can be hosted in the cloud or on-premises. As shown in the following diagram, a typical analytics system receives messages from a message hub, such as Kafka, which buffers incoming messages from the data sources until they can be processed. Most analytics systems have event dashboards and perform rudimentary real-time processing, which may include filtering an aggregated incoming message stream and extracting patterns of interest. These real-time components then deliver messages to data storage, which can include a historian database for logging and query and a data lake for offline, batch processing using big data tools such as Spark:
![]()
Conventional streaming analytics systems run either manual queries or automated, log-based queries to identify actionable events. Since big data analyses can take minutes or hours to run, they are typically used to look for big trends, like the fuel efficiency and on-time delivery rate of a trucking fleet, instead of emerging issues that need immediate attention. These limitations create an opportunity for real-time device tracking to fill the gap.
As shown in the following diagram, an in-memory computing system performing real-time device tracking can run alongside the other components of a conventional streaming analytics solution and provide autonomous introspection of the data streams from each device. Hosted on a cluster of physical or virtual servers, it maintains memory-based state information about the history and dynamically evolving state of every data source. As messages flow in, the in-memory compute cluster examines and analyzes them separately for each data source using application-defined analytics code. This code makes use of the device’s state information to help identify emerging issues and trigger alerts or feedback to the device. In-memory computing has the speed and scalability needed to generate responses within milliseconds, and it can evaluate and report aggregate trends every few seconds.
![]()
Because in-memory computing can store contextual data and process messages separately for each data source, it can organize application code using a software-based digital twin for each device, as illustrated in the diagram above. Instead of using the digital twin concept to model the inner workings of the device, a real-time digital twin tracks the device’s evolving state coupled with its parameters and history to detect and predict issues needing immediate attention. This provides an object-oriented mechanism that simplifies the construction of real-time application code that needs to evaluate incoming messages in the context of the device’s dynamic state. For example, it enables a medical application to determine the importance of a change in heart rate for a device wearer based on the individual’s current activity, age, medications, and medical history.
Summing Up
The complex web of communicating devices that surrounds us needs intelligent, real-time device tracking to extract its full benefits. Conventional streaming analytics architectures have not kept up with the growing demands of IoT. With its combination of fast data storage, low-latency processing and ease of use, in-memory computing can fill the gap while complementing the benefits provided by historian databases and data lakes. It can add the immediate feedback that IoT applications need and boost situational awareness to a new level, finally enabling IoT to deliver on its promises.
The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
]]>The post Adding New Capabilities for Real-Time Analytics to Azure IoT appeared first on ScaleOut Software.
]]>
The population of intelligent IoT devices is exploding, and they are generating more telemetry than ever. Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processing IoT telemetry, from its arrival in the cloud through its storage in databases and data lakes. Acting as a switchboard for incoming and outgoing messages, Azure IoT Hub forms the core of these capabilities. It provides support for a range of message protocols, buffering, and scalable message distribution to downstream services. These services include:
- Azure Event Grid for routing incoming events to a variety of handlers, including serverless functions, webhooks, storage queues, and other services
- Azure IoT Central for managing devices, visualizing incoming telemetry on a dashboard, triggering alerts, and integrating with line-of-business applications
- Azure Stream Analytics for simultaneously analyzing aggregated telemetry streams using extended SQL queries to extract patterns that can be fed to workflows, including alerts, serverless functions, and data storage with offline processing
- Azure Time Series Insights for storing time-series data and then exploring, modeling, and querying it to gain insights, such as identifying anomalies and trends, with a rich set of analytics tools
- Azure Digital Twins for creating a graphical representation of the assets within an organization using the Digital Twin Definition Language, processing events, and visualizing entity graphs to display and query status
While Azure IoT offers a wide variety of services, it focuses on visualizing entities and events, extracting insights from telemetry streams with queries, and migrating events to storage for more intensive offline analysis. What’s missing is continuous, real-time introspection on the dynamic state of IoT devices to predict and immediately react to significant changes in their state. These capabilities are vitally important to extract the full potential of real-time intelligent monitoring.
For example, here are some scenarios in which stateful, real-time introspection can create important insights. Telemetry from each truck in a fleet of thousands can provide numerous parameters about the driver (such as repeated lateral accelerations at the end of a long shift) that might indicate the need for a dispatcher to intervene. A health tracking device might indicate a combination of signals (blood pressure, blood oxygen, heart rate, etc.) that indicate an emerging medical issue for an individual with a known medical history and current medications. A security sensor in a key-card access system might indicate an unusual pattern of building entries for an employee who has given notice of resignation.
In all of these examples, the event-processing system needs to be able to independently analyze events for each data source (IoT device) within milliseconds, and it needs immediate access to dynamic, contextual information about the data source that it can use to perform real-time predictive analytics. In short, what’s needed is a scalable, in-memory computing platform connected directly to Azure IoT Hub which can ingest and process event messages separately for each data source using memory-based state information maintained for that data source.
The ScaleOut Digital Twin Streaming Service provides precisely these capabilities. It does this by leveraging the digital twin concept (not to be confused with Azure Digital Twins) to create an in-memory software object for every data source that it is tracking. This object, called a real-time digital twin, holds dynamic state information about the data source and is made available to the application’s event handling code, which runs within 1-2 milliseconds whenever an incoming event is received. Application developers write event handling code in C#, Java, JavaScript, or using a rules engine; this code encapsulates application logic, such as a predictive analytics or machine learning algorithm. Once the real-time digital twin’s model (that is, its state data and event handling code) has been created, the developer can use an intuitive UI to deploy it to the streaming service and connect to Azure IoT Hub.
As shown in the following diagram, ScaleOut’s streaming service connects to Azure IoT Hub, runs alongside other Azure IoT services, and provides unique capabilities that enhance the overall Azure IoT ecosystem:
ScaleOut’s streaming service handles all the details of message delivery, data management, code orchestration, and scalable execution. This makes developing streaming analytics code for real-time digital twins fast and easy. The application developer just focuses on writing a single method to process incoming messages, run application-specific analytics, update state information about the data source, and generate alerts as needed. The optional rules engine further simplifies the development process with a UI for specifying state data and a sequential list of business rules for describing analytics code.
How are the streaming service’s real-time digital twins different from Azure digital twins? Both services leverage the digital twin concept by providing a software entity for each IoT device that can track the parameters and state of the device. What’s different is the streaming service’s focus on real-time analytics and its use of an in-memory computing platform integrated with Azure IoT Hub to ensure the lowest possible latency and high scalability. Azure digital twins serve a different purpose. They are intended to maintain a graphical representation of an organization’s entities for management and querying current status; they are not designed to implement real-time analytics using application-defined algorithms.
The following diagram illustrates the integration of ScaleOut’s streaming service with Azure IoT Hub to provide fast, scalable event handling with low-latency access to memory-based state for all data sources. It shows how real-time digital twins are distributed across multiple virtual servers organized into an in-memory computing cluster connected to Azure IoT Hub. The streaming service uses multiple message queues in Azure IoT Hub to scale message delivery and event processing:
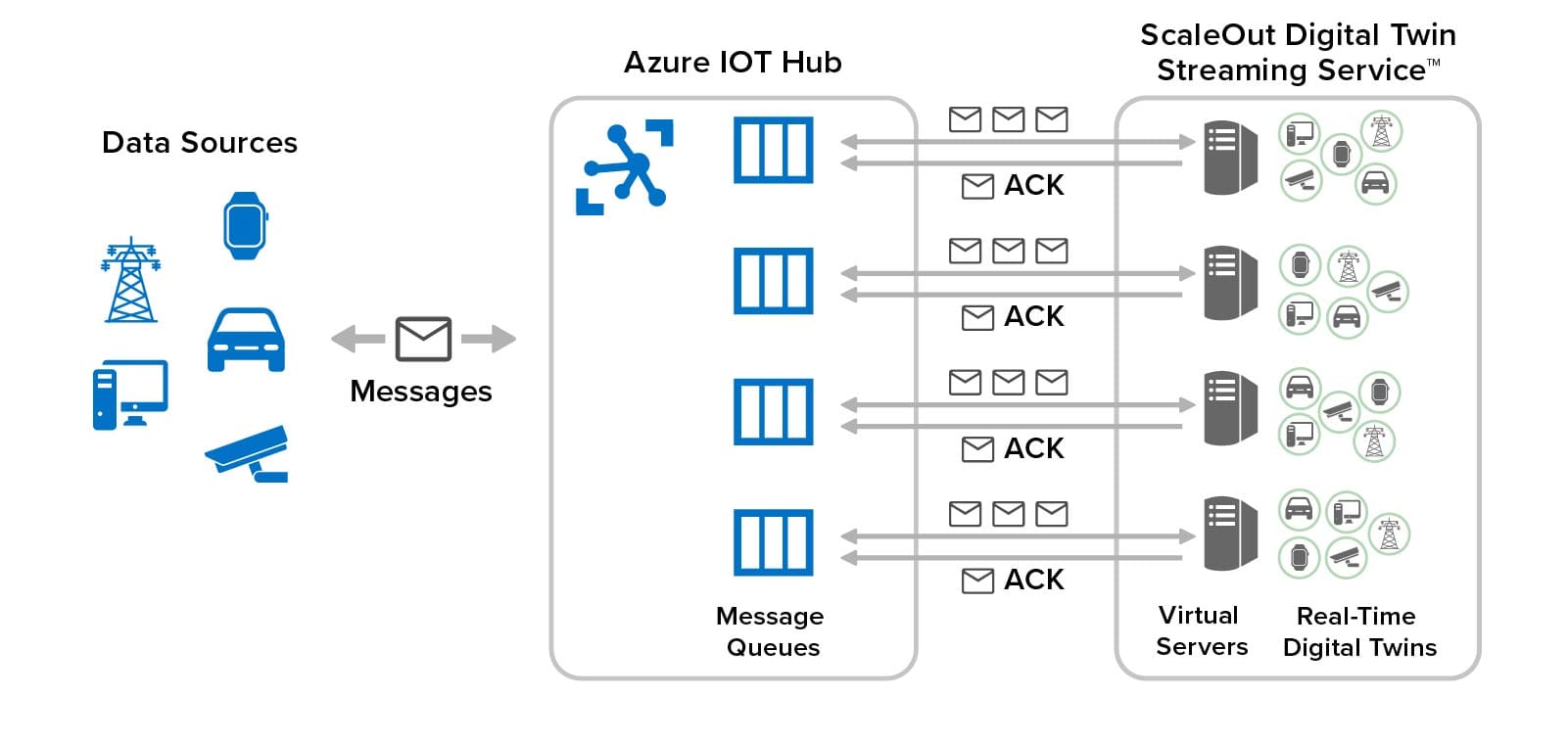
As IoT devices proliferate and become more intelligent, it’s vital that our cloud-based event-processing systems be able to perform continuous and deep introspection in real time. This enables applications to react quickly, effectively, and autonomously to emerging challenges, such as to security threats and safety issues, as well as to new opportunities, such as real-time ecommerce recommendations. While there is an essential role for query and offline analytics to optimize IoT services, the need for highly granular, real-time analytics continues to grow. ScaleOut’s Digital Twin Streaming Service is designed to meet this need as an integral part of the Azure IoT ecosystem.
To learn more about using the ScaleOut’s Digital Twin Streaming Service in the Microsoft Azure cloud, visit the Azure Marketplace here.
The post Adding New Capabilities for Real-Time Analytics to Azure IoT appeared first on ScaleOut Software.
]]>The post New Article in Security Boulevard on Real-Time Cyber Threat Assessment appeared first on ScaleOut Software.
]]>
The post New Article in Security Boulevard on Real-Time Cyber Threat Assessment appeared first on ScaleOut Software.
]]>The post New Article in RT Insights on Tracking Vaccine Distribution with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
The post New Article in RT Insights on Tracking Vaccine Distribution with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Building the Next Generation in Physical and Cyber Security with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
In-Memory Computing with Real-Time Digital Twins Offers the Intelligence, Responsiveness, Agility, and Scalability that Security and Safety Systems are Missing
Today’s physical and cyber security systems need to quickly detect and respond to unauthorized intrusions. However, these systems typically do not take advantage of in-memory computing techniques to help them immediately assess threats and generate alerts. In-memory computing with real-time digital twins offers a powerful new tool to address these challenges. Because these software components independently analyze telemetry from each data source and maintain dynamic contextual information, they can immediately spot unwanted intrusions and generate alerts. Let’s take a look at how they can add value.
Physical Security and Safety
Consider physical security with key card access control used by countless businesses and industries. Key card access control systems rely on database servers in the back office to authorize key cards for specific card readers and to log usage. As illustrated below, this information propagates to field access panels in the buildings to minimize delays in authorizing access. However, making changes usually requires manual database updates and may take minutes or longer to propagate throughout the system.
More importantly, subtle patterns of unauthorized access may escape the attention of security personnel and require a review of the logs to detect. For example, an employee who has given notice of resignation may unexpectedly visit buildings or laboratories that were not part of the employee’s known scope of work. Another employee might be put at risk by attempting to enter a hazardous laboratory without having completed the required training. An exit door might record an unusual pattern of entries outside of business hours. In all of these situations, quick detection and response could avoid unwanted intrusions or safety lapses.
To enable immediate alerting, real-time digital twins (RTDTs) can be used to track every key card and key card reader. Since each key card is associated with a specific employee, the RTDT can track that person’s individual authorization to access buildings, entry doors, laboratories, etc. It also can track employment status and level of training to help assess safety issues. This information can be immediately updated by sending a message to the RTDT whenever the employee’s status changes. With this contextual information, each RTDT can implement highly granular access permissions at the card readers while checking authorization within several milliseconds. It also can track the employee’s and entry point’s usage patterns to look for unusual situations that should be alerted.
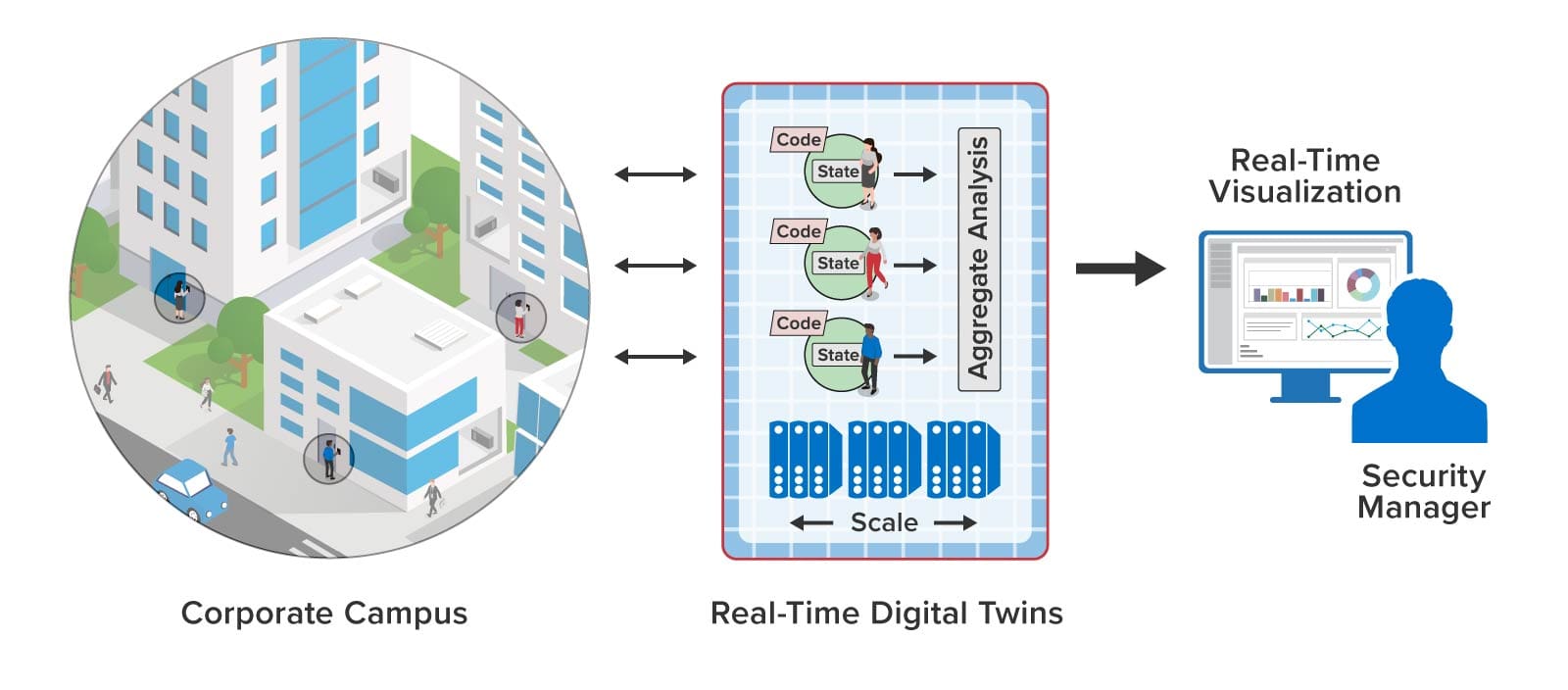
In a typical interaction, the key card reader sends a message to the employee’s key card RTDT with the reader’s identifier and time of day. After analyzing the request and tracking usage patterns, the key card RTDT responds with an authorization reply to the reader. The RTDT also sends a message to the reader’s RTDT to enable it to track usage and generate alerts as necessary, as illustrated below:
Cyber Security
Security information and event management (SIEM) software logs activities, such as user logins, failed attempts, and potentially malicious events so that security managers can detect and prevent or remediate possible intrusions. Typical SIEM software lets managers create and apply rules to event logs to extract information that should be alerted, such as identification of a chain of activity (“kill chain”) that leads to injection of malware or other malicious actions. Dashboards show managers raw telemetry, such as the number of potentially malicious events by region or events recorded over time. The forensic analysis of logs and display of large volumes of aggregated telemetry make it difficult for managers to spot and mitigate emerging kill chains, such as a chain of intrusions within a corporate infrastructure leading to an exploitation:
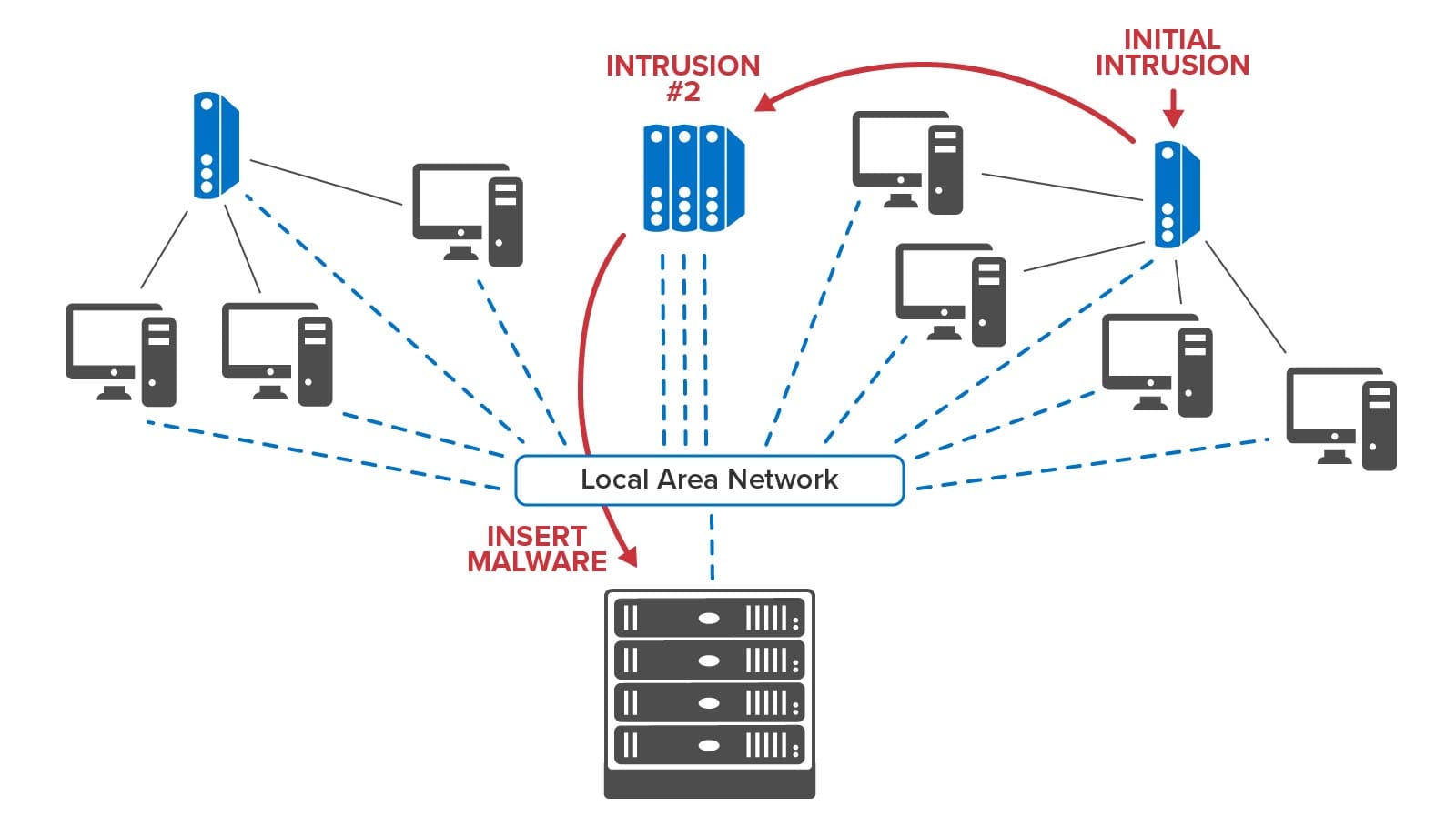
By hosting event tracking in memory with contextual information and by reacting within milliseconds to potential threats, RTDTs can help accelerate the detection and interruption of cyber kill chains. Many SIEM platforms maintain software agents distributed throughout an organization’s IT infrastructure to report suspicious events that could signal a possible intrusion. Instead of just feeding these events to a dashboard and to a log for analysis, they can also be reported to an RTDT for each agent. Each RTDT can immediately run a machine learning algorithm to classify activity and signal alerts when a threat is predicted. Moreover, if an agent’s event includes information about an outbound connection to another node in the network, the RTDT can send a message to that node’s RTDT to enrich its context and assist in detection of a potential kill chain. By dynamically sending messages to and among RTDTs that attempt to track the progression of an intruder within a network, RTDTs can build a real-time map of potential kill chains and possibly get ahead of the intruder to block threats.
The following diagram illustrates the use of RTDTs to map the progression of incoming threats as they migrate among nodes of an organization’s infrastructure:
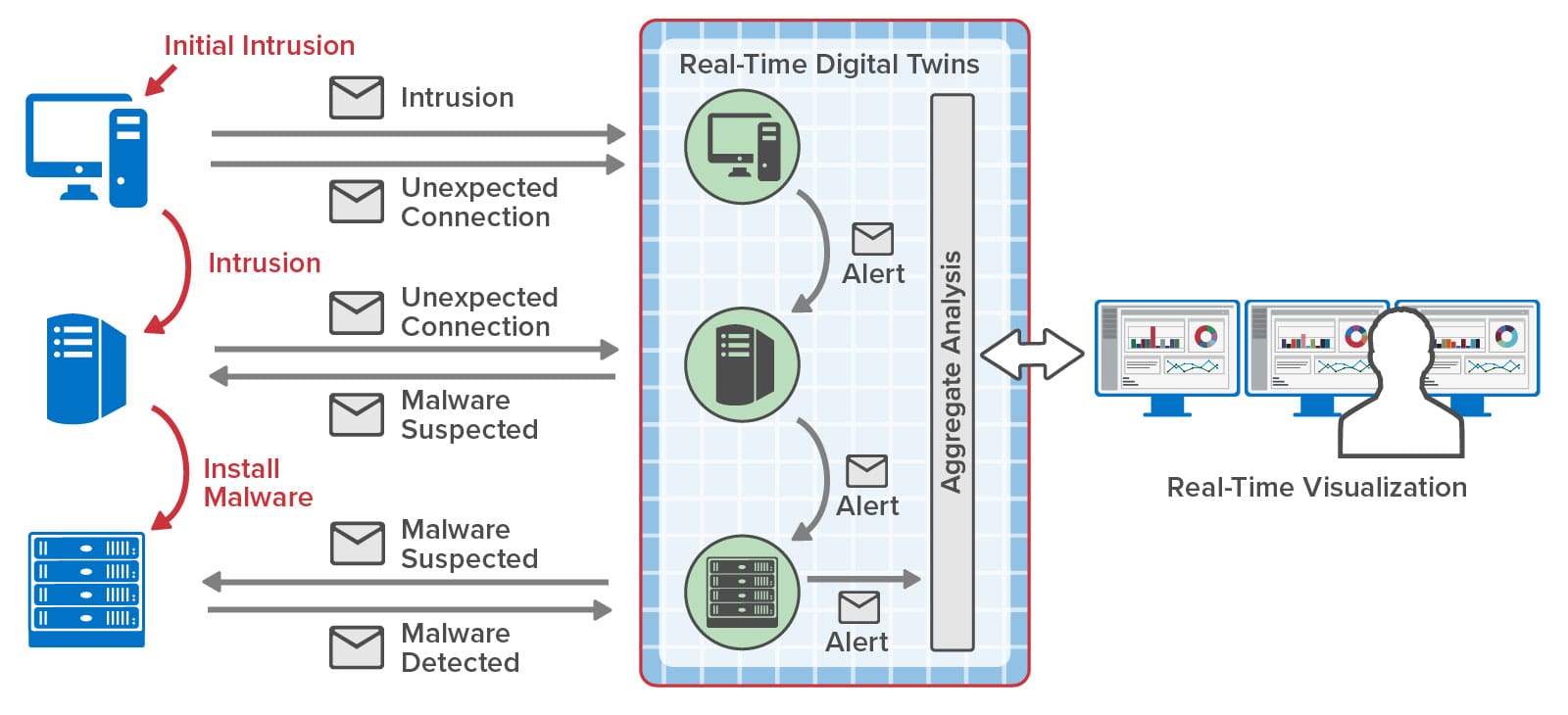
Summing Up
Physical and cyber security systems, as well as safety systems, require simultaneous, real-time assessment of numerous interactions in the context of allowed and expected usage patterns. Instead of relying on today’s offline computing techniques and forensic analysis to perform the bulk of the work, these systems can dramatically boost their effectiveness by employing next generation in-memory computing techniques, such as real-time digital twins. This software architecture offers a highly attractive combination of intelligence, agility, responsiveness, and scalability to meet the ever-increasing challenges faced by today’s security and safety systems.
The post Building the Next Generation in Physical and Cyber Security with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Introducing Geospatial Mapping for Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
The goal of real-time streaming analytics is to get answers fast. Mission-critical applications that manage large numbers of live data sources need to quickly sift through incoming telemetry, assess dynamic changes, and immediately pinpoint emerging issues that need attention. Examples abound: a telematics application tracking a fleet of vehicles, a vaccine distribution system managing the delivery of thousands of shipments, a security or safety application analyzing entry points in a large infrastructure (physical or cyber), a healthcare application tracking medical telemetry from a population of wearable devices, a financial services application watching wire transfers and looking for potential fraud — the list goes on. In all these cases, when a problem occurs (or an opportunity emerges), managers need answers now.
Conventional streaming analytics platforms are unable to separate messages from each data source and analyze them as they flow in. Instead, they ingest and store telemetry from all data sources, attempt a preliminary search for interesting patterns in the aggregated data stream, and defer detailed analysis to offline batch processing. As a result, they are unable to introspect on the dynamic, evolving state of each data source and immediately alert on emerging issues, such as the impending failure of a truck engine, an unusual pattern of entries and exits to a secure building, or a potentially dangerous pattern of telemetry for a patient with a known medical condition.
In-memory computing with software components called real-time digital twins overcomes these obstacles and enables continuous analysis of incoming telemetry for each data source with contextual information that deepens introspection. While processing each message in a few milliseconds, this technology automatically scales to simultaneously handle thousands of data sources. It also can aggregate and visualize the results of analysis every few seconds so that managers can graphically track the state of a complex live system and quickly pinpoint issues.
The ScaleOut Digital Twin Streaming Service is an Azure-based cloud service that uses real-time digital twins to perform continuous data ingestion, analysis by data source, aggregation, and visualization, as illustrated below. What’s key about this approach is that the system visualizes state information that results from real-time analysis — not raw telemetry flowing in from data sources. This gives managers curated data that intelligently focuses on the key problem areas (or opportunities). For example, instead of looking at fluctuating oil temperature, telematics dispatchers see the results of predictive analytics. There’s not enough time for managers to examine all the raw data, and not enough time to wait for batch processing to complete. Maintaining situational awareness requires real-time introspection for each data source, and real-time digital twins provide it.
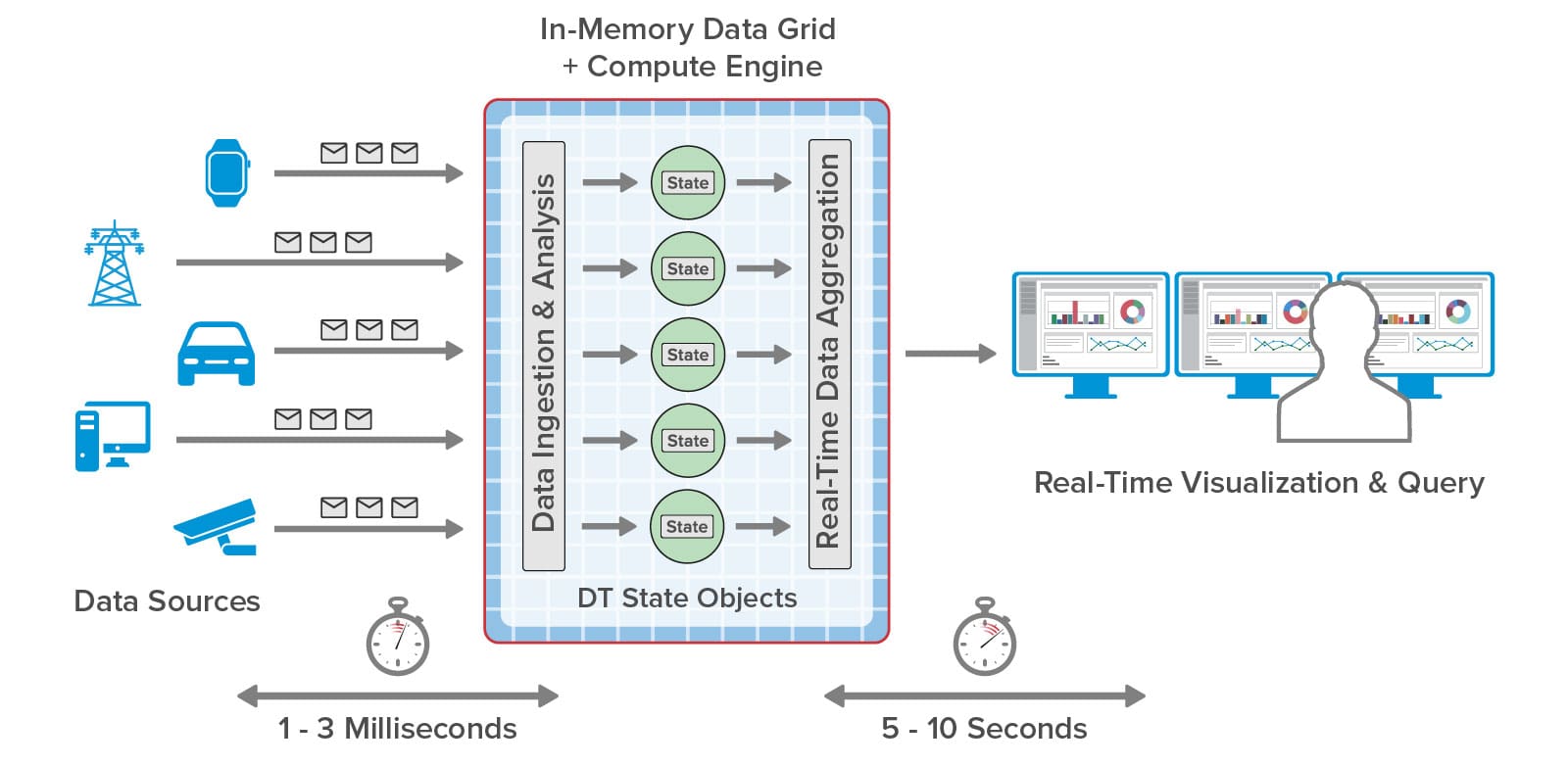
In the ScaleOut Digital Twin Streaming Service, real-time data visualization can take the form of charts and tables. Dynamic charts effectively display the results of aggregate analytics that combine data from all real-time digital twins to show emerging patterns, such as the regions of the country with the largest delivery delays for a vaccine distribution system. This gives a comprehensive view that helps managers maintain the “big picture.” To pinpoint precisely which data sources need attention, users can query analytics results for all real-time digital twins and see the results in a table. This enables managers to ask questions like “Which vaccination centers in Washington state are experiencing delivery delays in excess of 1 hour and have seen more than 100 people awaiting vaccinations at least three times today?” With this information, managers can immediately determine where vaccine shipments should be delivered first.
With the latest release, the streaming service now offers geospatial mapping of query results combined with continuous queries that refresh the map every few seconds. For example, using this cloud service, a telematics system for a trucking fleet can continuously display the locations of specific trucks which have issues (the red dots on the map) in addition to watching aggregate statistics:
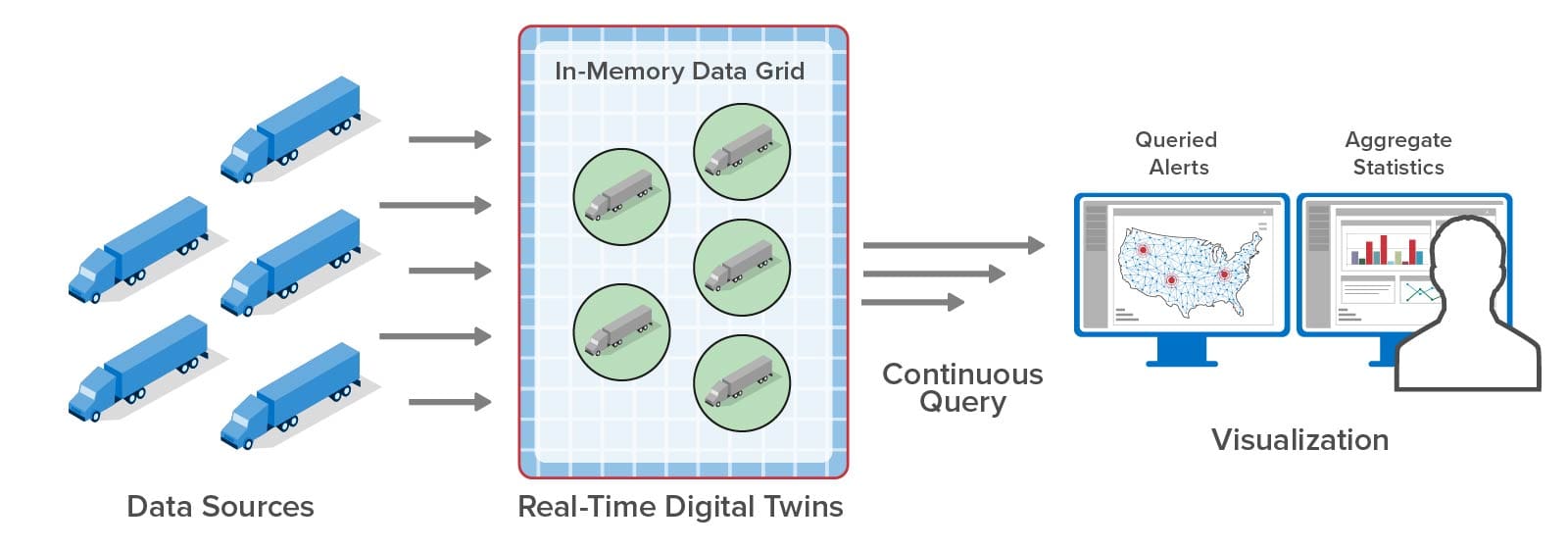
For applications like this, a mapped view of query results offers valuable insights about the locations where issues are emerging that would otherwise be more difficult to obtain from a tabular view. Note that the queried data shows the results of real-time analytics which are continuously updated as messages arrive and are processed. For example, instead of displaying the latest oil temperature from a truck, the query reports the results of a predictive analytics algorithm that makes use of several state variables maintained by the real-time digital twin. This declutters the dispatcher’s view so that only alertable conditions are highlighted and demand attention:
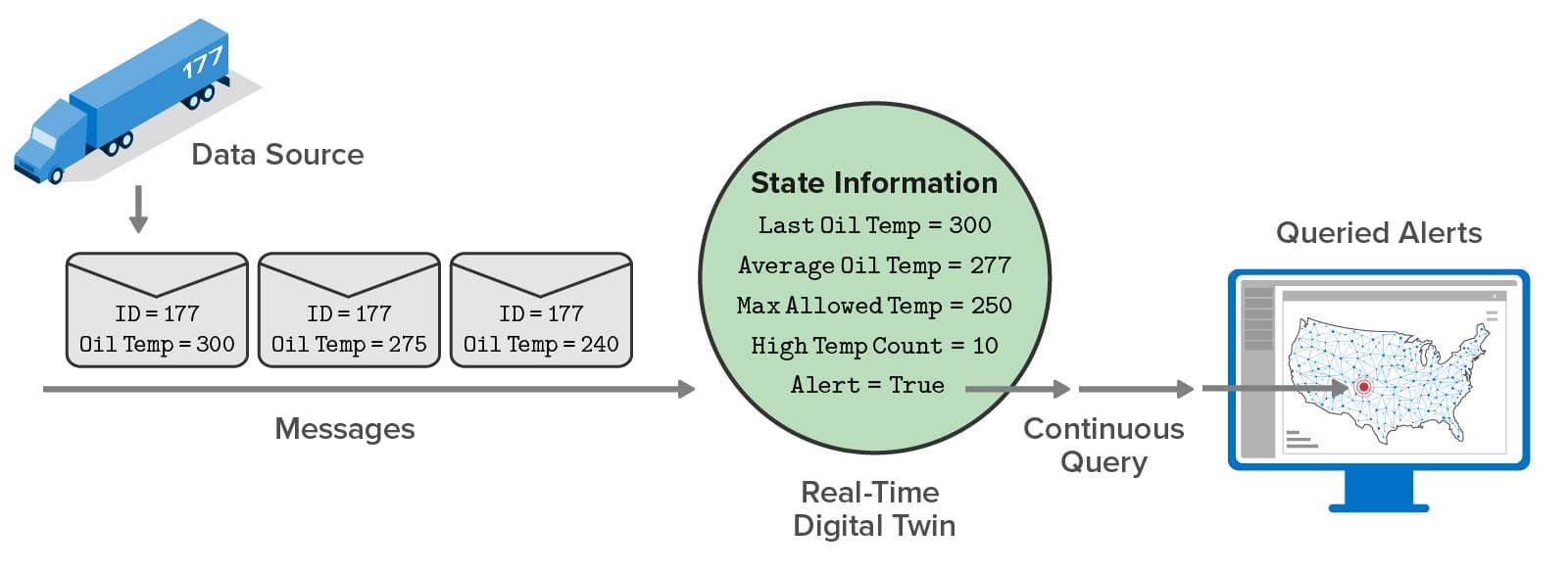
The following image shows an example of actual map output for a hypothetical security application that tracks possible intrusions within a nationwide power grid. The goal of the real-time digital twins is to assess telemetry from each of 20K control points in the power grid’s network, filter out false-positives and known issues, and produce a quantitative assessment of the threat (“alert level”). Continuous queries map the results of this assessment so that managers can immediately spot a real threat, understand its scope, and take action to isolate it. The map shows the results of results three continuous queries: high alerts requiring action, medium alerts that just need watching, and offline nodes (with the output suppressed here):
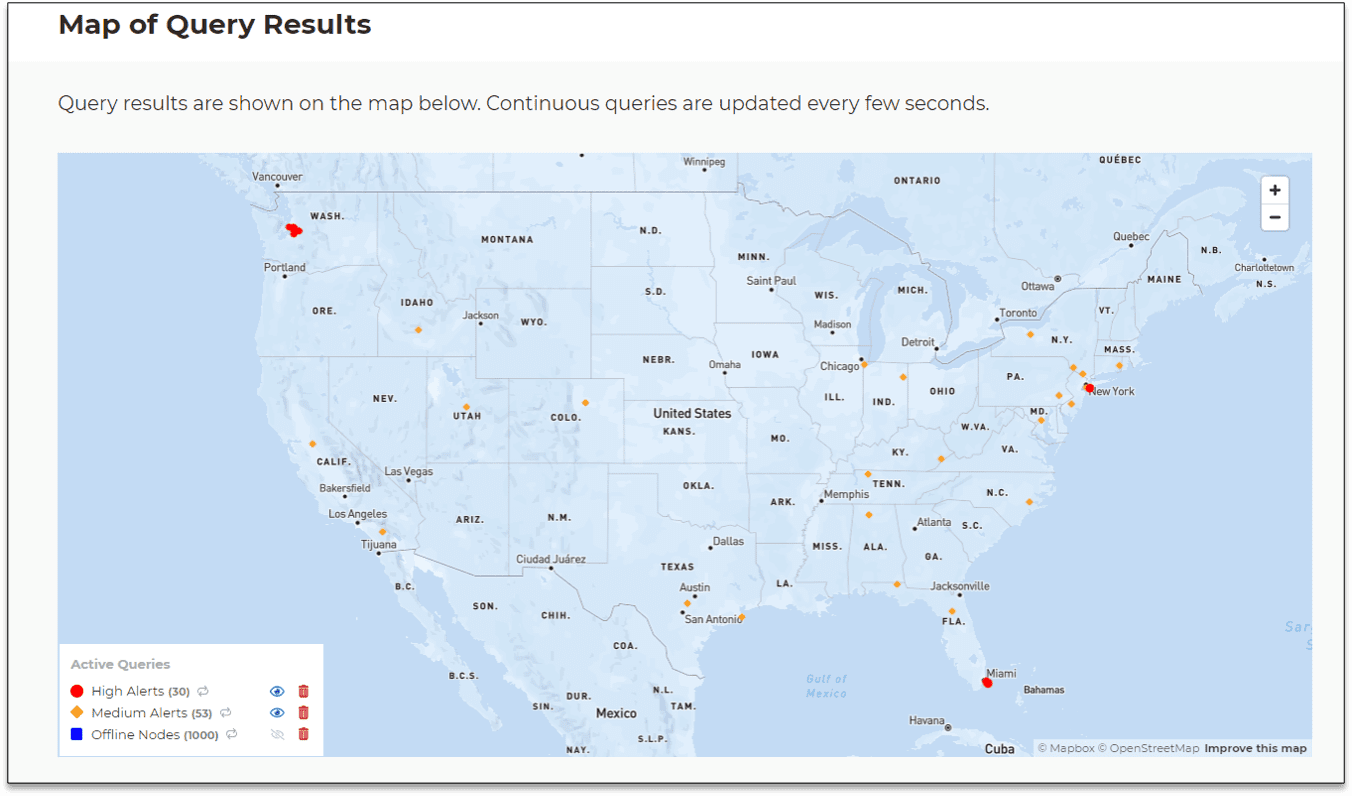
In this scenario a high alert has suddenly appeared in the grid at three locations (Seattle, New York, and Miami) indicating a serious, coordinated attack on the network. By zooming in and hovering over dots in the graph, users can display the detailed query results for each corresponding data source. Within seconds, managers have immediate, actionable information about threat assessments and can quickly visualize the locations and scope of specific threats.
In applications like these and many others, the power of in-memory computing with real-time digital twins gives managers a new means to digest real-time telemetry from thousands of data sources, combine it with contextual information that enhances the analysis, and then immediately visualize the results. This powerful technology boosts situational awareness and helps guide responses much better and faster than was previously possible.
The post Introducing Geospatial Mapping for Real-Time Digital Twins appeared first on ScaleOut Software.
]]>