The post Video: Preventing Train Derailments with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
Introducing the latest ScaleOut Software video release: Preventing Train Derailments with Real-Time Digital Twins. Modern society relies on complex transportation networks to keep things moving smoothly, but when issues arise, the consequences can be substantial. In 2022 alone, over 1,100 train derailments in the US led to damages exceeding $100 million. Costs from the East Palestine, Ohio train derailment in February 2023 reached a staggering $803 million.
Many costly train derailments could potentially be prevented using a combination of existing infrastructure and new real-time digital twin technology. In this video, you’ll learn how real-time digital twins can revolutionize accident prevention for railroads by monitoring live data and taking action before derailments occur. See how digital twins can analyze data from existing trackside detectors simultaneously and determine when wheel bearings are likely to fail. Watch a simulation that illustrates how ScaleOut’s digital twins can predict problems and intervene to prevent accidents.
- Learn more about ScaleOut’s Digital Twin Streaming Service
- Subscribe to ScaleOut’s Youtube channel for more videos
The post Video: Preventing Train Derailments with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Watch: Founder and CEO William Bain Talks Real-Time Digital Twins with Techstrong TV appeared first on ScaleOut Software.
]]>Watch the video below:
- Learn more about ScaleOut’s Digital Twin Streaming Service
- Watch Dr. Bain’s previous interview with Techstrong TV
The post Watch: Founder and CEO William Bain Talks Real-Time Digital Twins with Techstrong TV appeared first on ScaleOut Software.
]]>The post New Article in Security Boulevard on Real-Time Cyber Threat Assessment appeared first on ScaleOut Software.
]]>
The post New Article in Security Boulevard on Real-Time Cyber Threat Assessment appeared first on ScaleOut Software.
]]>The post Building the Next Generation in Physical and Cyber Security with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
In-Memory Computing with Real-Time Digital Twins Offers the Intelligence, Responsiveness, Agility, and Scalability that Security and Safety Systems are Missing
Today’s physical and cyber security systems need to quickly detect and respond to unauthorized intrusions. However, these systems typically do not take advantage of in-memory computing techniques to help them immediately assess threats and generate alerts. In-memory computing with real-time digital twins offers a powerful new tool to address these challenges. Because these software components independently analyze telemetry from each data source and maintain dynamic contextual information, they can immediately spot unwanted intrusions and generate alerts. Let’s take a look at how they can add value.
Physical Security and Safety
Consider physical security with key card access control used by countless businesses and industries. Key card access control systems rely on database servers in the back office to authorize key cards for specific card readers and to log usage. As illustrated below, this information propagates to field access panels in the buildings to minimize delays in authorizing access. However, making changes usually requires manual database updates and may take minutes or longer to propagate throughout the system.
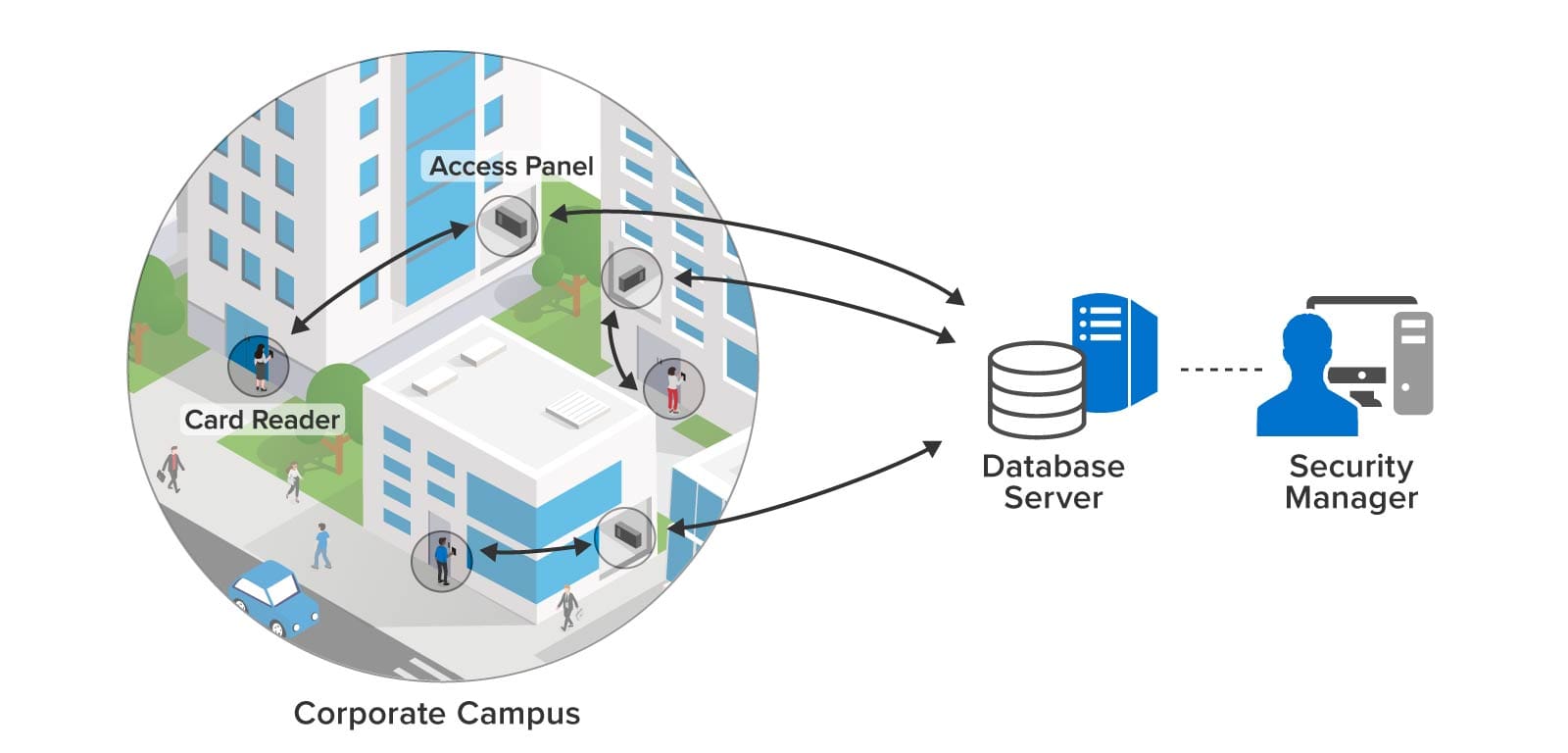
More importantly, subtle patterns of unauthorized access may escape the attention of security personnel and require a review of the logs to detect. For example, an employee who has given notice of resignation may unexpectedly visit buildings or laboratories that were not part of the employee’s known scope of work. Another employee might be put at risk by attempting to enter a hazardous laboratory without having completed the required training. An exit door might record an unusual pattern of entries outside of business hours. In all of these situations, quick detection and response could avoid unwanted intrusions or safety lapses.
To enable immediate alerting, real-time digital twins (RTDTs) can be used to track every key card and key card reader. Since each key card is associated with a specific employee, the RTDT can track that person’s individual authorization to access buildings, entry doors, laboratories, etc. It also can track employment status and level of training to help assess safety issues. This information can be immediately updated by sending a message to the RTDT whenever the employee’s status changes. With this contextual information, each RTDT can implement highly granular access permissions at the card readers while checking authorization within several milliseconds. It also can track the employee’s and entry point’s usage patterns to look for unusual situations that should be alerted.
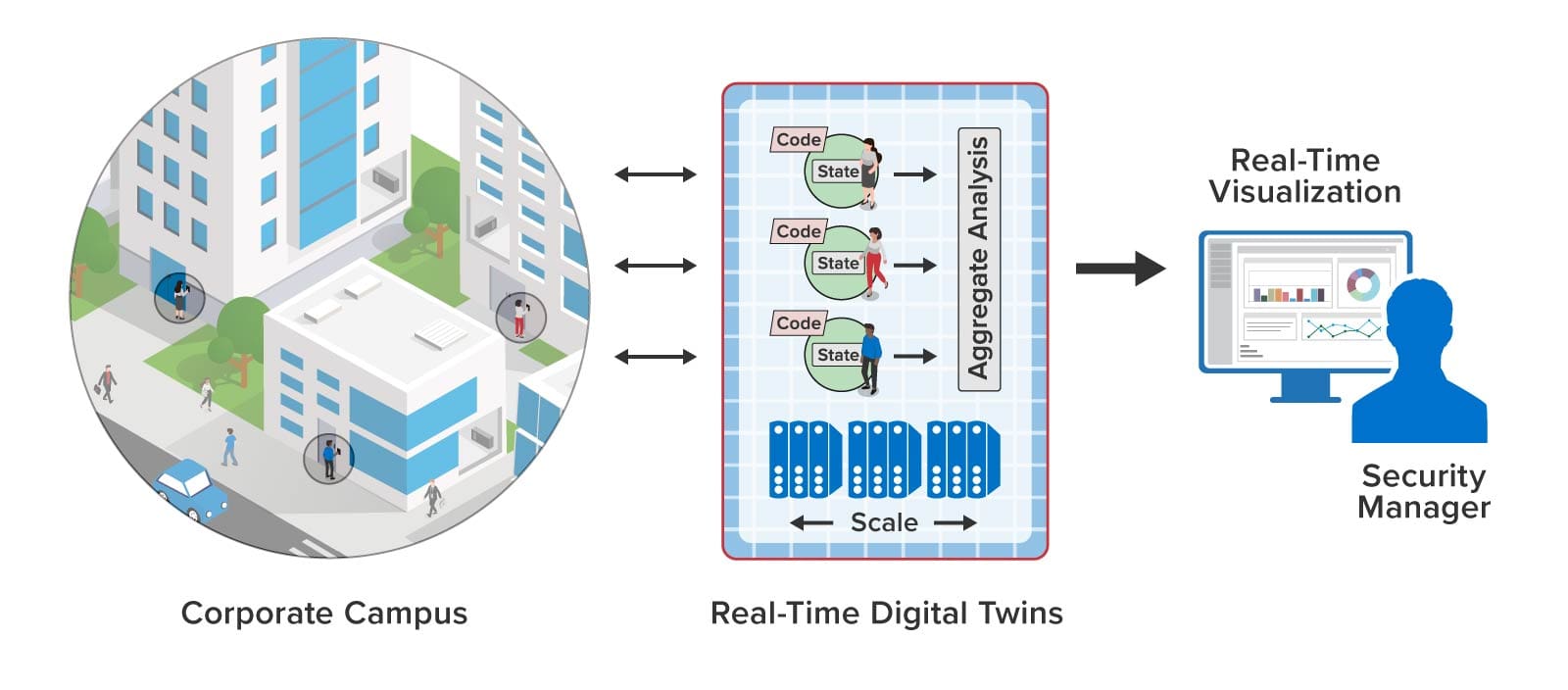
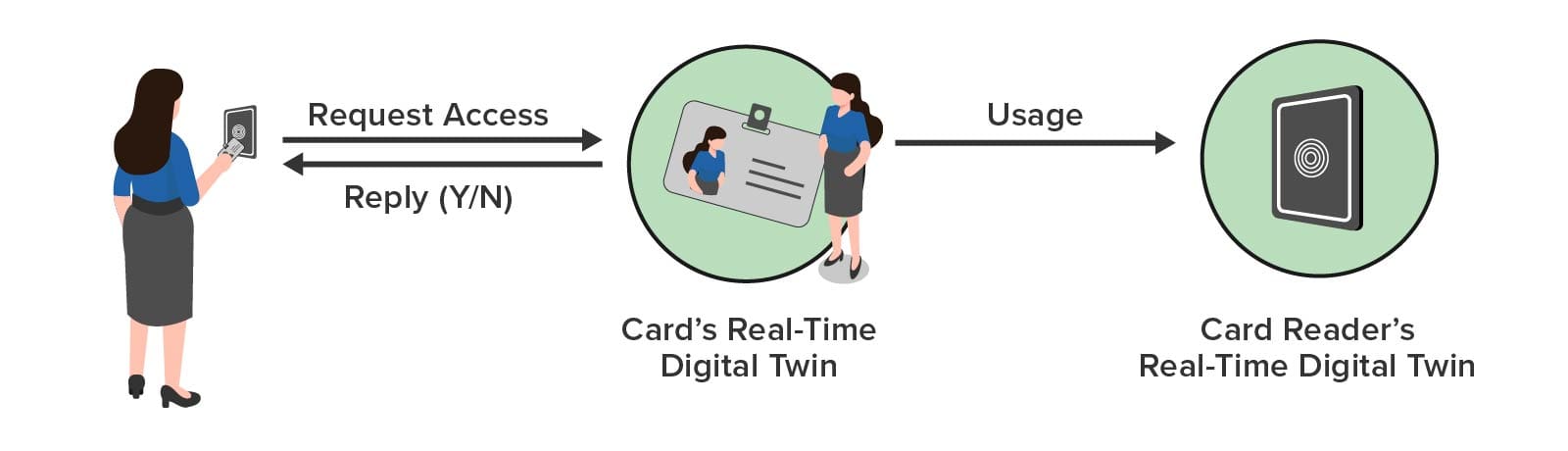
In a typical interaction, the key card reader sends a message to the employee’s key card RTDT with the reader’s identifier and time of day. After analyzing the request and tracking usage patterns, the key card RTDT responds with an authorization reply to the reader. The RTDT also sends a message to the reader’s RTDT to enable it to track usage and generate alerts as necessary, as illustrated below:
Cyber Security
Security information and event management (SIEM) software logs activities, such as user logins, failed attempts, and potentially malicious events so that security managers can detect and prevent or remediate possible intrusions. Typical SIEM software lets managers create and apply rules to event logs to extract information that should be alerted, such as identification of a chain of activity (“kill chain”) that leads to injection of malware or other malicious actions. Dashboards show managers raw telemetry, such as the number of potentially malicious events by region or events recorded over time. The forensic analysis of logs and display of large volumes of aggregated telemetry make it difficult for managers to spot and mitigate emerging kill chains, such as a chain of intrusions within a corporate infrastructure leading to an exploitation:
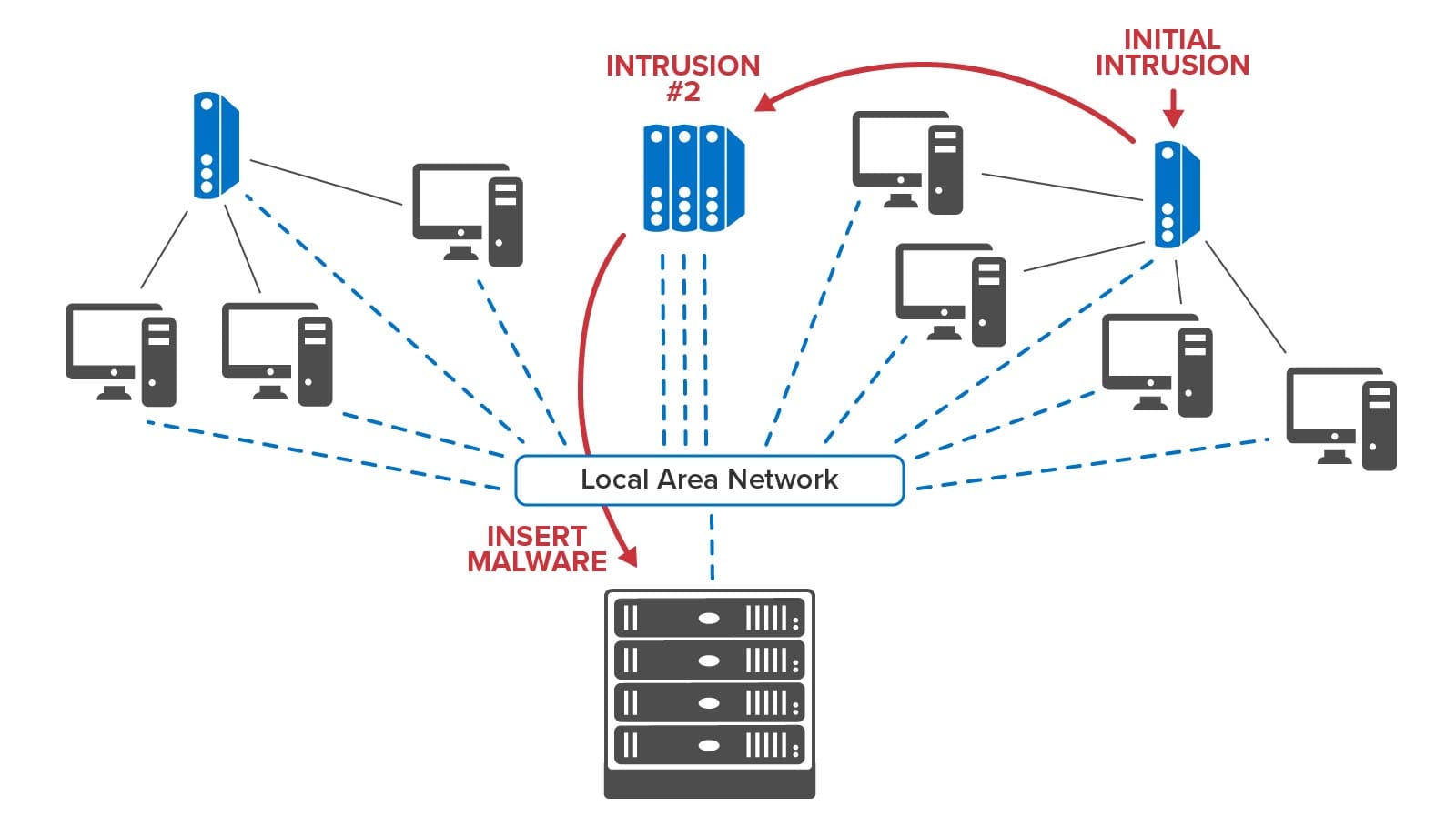
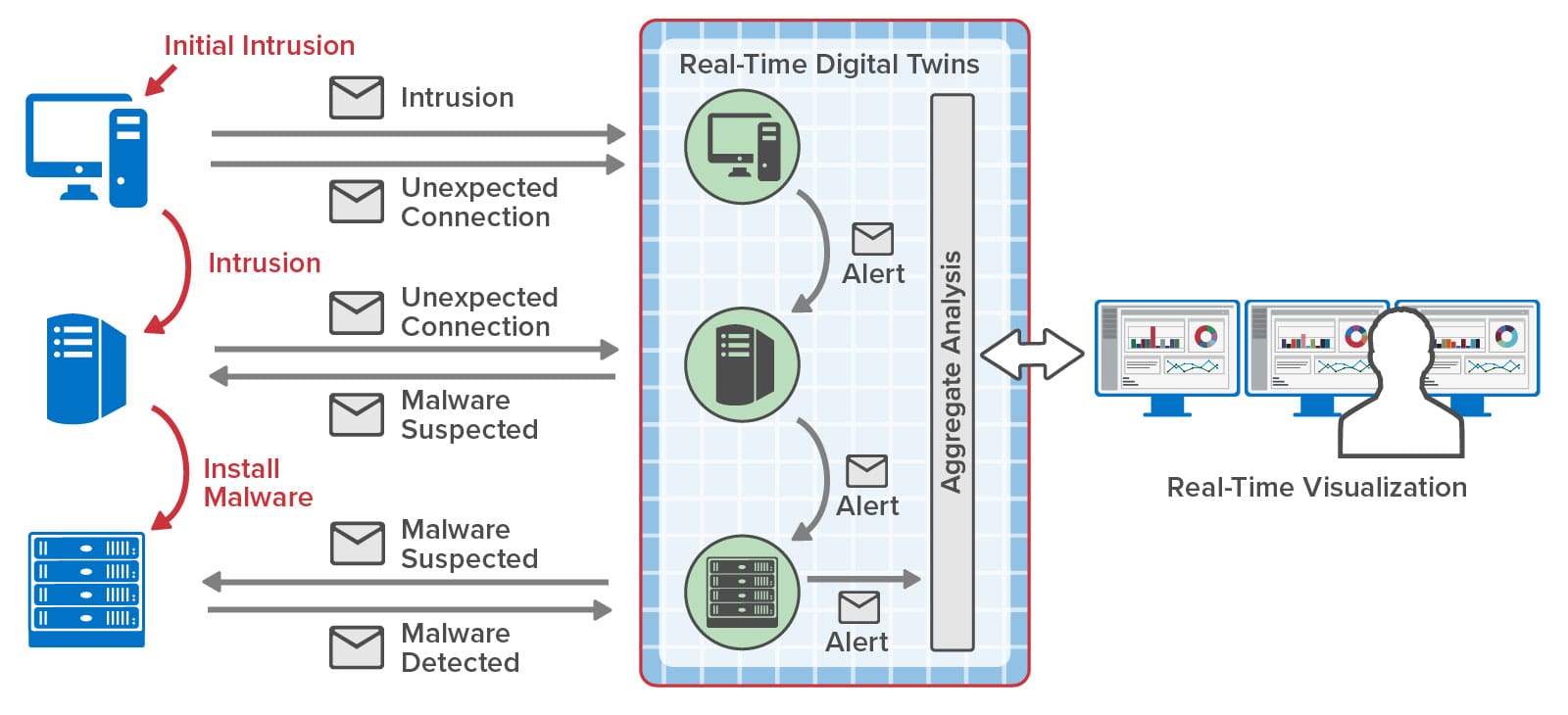
By hosting event tracking in memory with contextual information and by reacting within milliseconds to potential threats, RTDTs can help accelerate the detection and interruption of cyber kill chains. Many SIEM platforms maintain software agents distributed throughout an organization’s IT infrastructure to report suspicious events that could signal a possible intrusion. Instead of just feeding these events to a dashboard and to a log for analysis, they can also be reported to an RTDT for each agent. Each RTDT can immediately run a machine learning algorithm to classify activity and signal alerts when a threat is predicted. Moreover, if an agent’s event includes information about an outbound connection to another node in the network, the RTDT can send a message to that node’s RTDT to enrich its context and assist in detection of a potential kill chain. By dynamically sending messages to and among RTDTs that attempt to track the progression of an intruder within a network, RTDTs can build a real-time map of potential kill chains and possibly get ahead of the intruder to block threats.
The following diagram illustrates the use of RTDTs to map the progression of incoming threats as they migrate among nodes of an organization’s infrastructure:
Summing Up
Physical and cyber security systems, as well as safety systems, require simultaneous, real-time assessment of numerous interactions in the context of allowed and expected usage patterns. Instead of relying on today’s offline computing techniques and forensic analysis to perform the bulk of the work, these systems can dramatically boost their effectiveness by employing next generation in-memory computing techniques, such as real-time digital twins. This software architecture offers a highly attractive combination of intelligence, agility, responsiveness, and scalability to meet the ever-increasing challenges faced by today’s security and safety systems.
The post Building the Next Generation in Physical and Cyber Security with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Real-Time Digital Twins Can Help Expedite Vaccine Distribution appeared first on ScaleOut Software.
]]>Agile In-Memory Software Can Track the Dynamic Rollout of Vaccine Distribution and Delivery to Quickly Spot Problems
Getting the COVID-19 crisis under control requires that we put in place an effective process for vaccine distribution so that the country can get to herd immunity as fast as possible. We are faced with quickly building a nationwide logistics network and standing up well more than 50,000 vaccination centers. Making all this work smoothly means that managers need accurate, up-to-the-minute information about all aspects of this operation, including:
- Where are all the vaccine shipments right now?
- What is the shortfall in vaccines at each center?
- How many people are waiting for vaccines at each center?
- How many qualified personnel are available at each center?
- Which centers have the most urgent needs and need immediate attention?
- Is vaccine distribution underserving certain regions or population groups?
Given the unique and highly dynamic nature of this challenge, we need software solutions that are agile enough to adapt to evolving needs and scalable enough to quickly handle a daunting amount of fast-changing data. Conventional, enterprise data architectures take months to develop and are complex to change. Is there a simpler, faster way to wrangle this data for crisis managers?
In-Memory Computing with Real Time Digital Twins: Fast and Agile
A software technology called in-memory computing has evolved over the last twenty years to grapple with the challenge of tracking and analyzing fast-changing data. Its two core competencies are speed and scalability. Widely used to track ecommerce shopping carts, financial transactions, airline flights and much more, in-memory computing can quickly store, retrieve, and analyze large volumes of live data. This powerful technology may also be just what we need to help tackle the challenge of vaccine distribution.
In the last two years, the concept of real-time digital twins has emerged to let in-memory computing track incoming data streams from hundreds of thousands of data sources, maintain pertinent information about each data source, and immediately alert when unusual conditions are detected. The power of this approach lies in its ability to simplify the problem for application developers. It encapsulates code that just focuses on analyzing messages from a single data source as they flow in, and it maintains an up-to-the second assessment of the data source’s status. Real-time digital twins are both easy to develop and easy to change as needs evolve. The in-memory computing system which hosts them typically runs as a cloud service (such as the ScaleOut Digital Twin Streaming Service) that transparently scales to handle as many data sources as needed.
Real-Time Digital Twins Can Help Expedite Vaccine Distribution
To track the distribution and delivery of COVID-19 vaccines, a real-time digital twin can be deployed for each shipment in transit and for each vaccination center. For shipments, the digital twins can track location, destination, and current condition on a second-by-second basis, allowing managers to instantly know where a shipment is and whether its viability is at risk, for example, due to a temperature change. For vaccination centers, real-time digital twins can track location, the supply of vaccines, current demand (number of recipients), availability of trained personnel to perform injections, and other parameters. Code in the digital twin continuously analyzes incoming messages to determine whether a problem exists or is likely to occur, and it alerts managers to urgent issues within a few milliseconds. This allows managers to keep track of which of the 50,000 centers need immediate assistance.
The following diagram illustrates the use of real-time digital twins to track thousands of vaccine shipments and vaccination centers. The red dotted lines depict message streams flowing from data sources located throughout the country over the Internet to their corresponding real-time digital twins hosted in the cloud service.
![]()
Let’s take a closer look at the real-time digital twin for a vaccination center. Using a simple web app, personnel at the vaccination center send periodic messages updating information about supplies, personnel, recipients, and wait times. The real time digital twin for this center records this data and then analyzes it for issues, such as a shortfall in supplies, lack of available personnel, or a surge in incoming recipients. It can then compute an assessment of the urgency for assistance (call it an alert level) which can be compared to other centers to identify which ones have the most urgent issues. If the alert level becomes sufficiently high, the analysis code can immediately notify managers. By analyzing incoming messages, real-time digital twins keep track of the latest status for all vaccination centers.
Here’s an illustration of a vaccination center sending messages to its real-time digital twin running in the cloud. It shows some of the state information that the twin maintains and the code which analyzes incoming messages as they arrive:
![]()
Aggregate Analytics Boost Situational Awareness
When dealing with thousands of dynamic data sources, managers can use real-time digital twins to serve as highly responsive watchdogs that continuously evaluate incoming information for changes that may need attention. This helps managers easily track thousands of data sources and focus on the most pressing concerns.
To further boost situational awareness, the in-memory computing platform can group and aggregate data held in the real-time digital twins every few seconds to help surface widespread changes that need strategic responses. For example, the average shortfall in vaccine doses for all centers in each region of the country can be aggregated to track where shortfalls may be occurring. This information can be visualized as shown in the chart below, which is updated every few seconds to provide managers with the most current view of the situation:
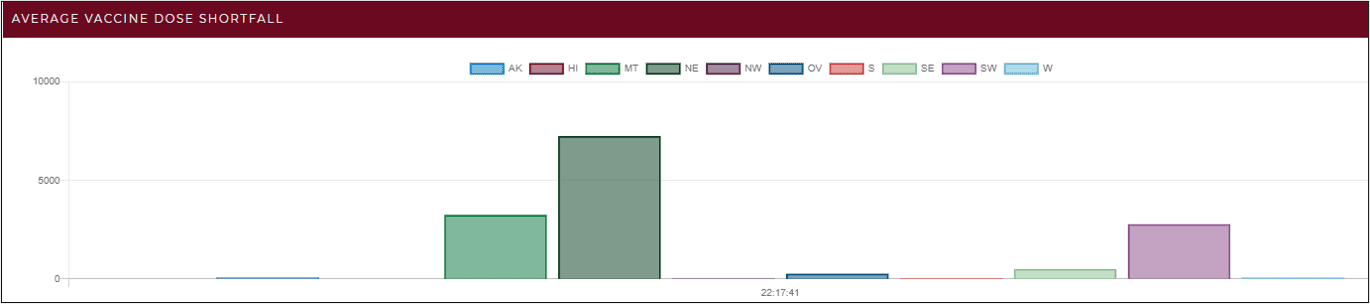
Likewise, this technique can be used to aggregate the average wait times for all vaccination centers by county. This can help determine where bottlenecks in vaccine delivery are occurring and enable mangers to render assistance by relocating personnel from less busy centers to overwhelmed ones.
Aggregate analytics of data maintained by real-time digital twins can also be used to track and validate the equitable distribution of vaccines. For example, it can aggregate information collected from each center about the demographics of vaccine recipients, such as age and ethnicity, and characteristics of the centers themselves, such as hospitals vs pharmacies and urban vs rural. This allows key real-time statistics to be tracked, such whether certain groups or regions are being underserved and whether hospitals have shorter wait times than pharmacies.
Summing Up
Without a doubt, distributing and delivering COVID-19 vaccines quickly and effectively over the next few months presents formidable challenges, namely:
- Ensuring that logistics managers get the critical information they need in a timely manner
- Avoiding the complexity and delay required to build custom information management systems that can provide this information
Because it is fast, scalable, and agile, in-memory computing technology with real-time digital twins can serve as a valuable tool for tracking the status of many thousands of vaccination centers and shipments. This innovative software infrastructure can quickly be programmed to analyze vital parameters and statistics in milliseconds and aggregate key data every few seconds. It offers managers a powerful and flexible means for helping ensure fast, efficient vaccine distribution and delivery.
The post Real-Time Digital Twins Can Help Expedite Vaccine Distribution appeared first on ScaleOut Software.
]]>The post ScaleOut Discusses Contact Tracing in The Record appeared first on ScaleOut Software.
]]>
Also read our Partner Perspective in the same issue, which explains how the Microsoft Azure cloud provides a powerful platform for hosting the ScaleOut Digital Twin Streaming Service and ensures high performance across a wide range of applications.
and ensures high performance across a wide range of applications.
The post ScaleOut Discusses Contact Tracing in The Record appeared first on ScaleOut Software.
]]>The post Founder & CEO William Bain Discusses Real-Time Digital Twins with TechStrong TV appeared first on ScaleOut Software.
]]>Watch the video here.

The post Founder & CEO William Bain Discusses Real-Time Digital Twins with TechStrong TV appeared first on ScaleOut Software.
]]>The post Using Real-Time Digital Twins for Corporate Contact Tracing appeared first on ScaleOut Software.
]]>
Until a COVID-19 vaccine is widely available, getting back to work means keeping a close watch for outbreaks and quickly containing them when they occur. While the prospects for accomplishing this within large companies seem daunting, tracking contacts between employees may be much easier than for the public at large. This blog post explains how a software application built with a new software construct called real-time digital twins makes this possible.
Tracking Employees Using Real-Time Digital Twins
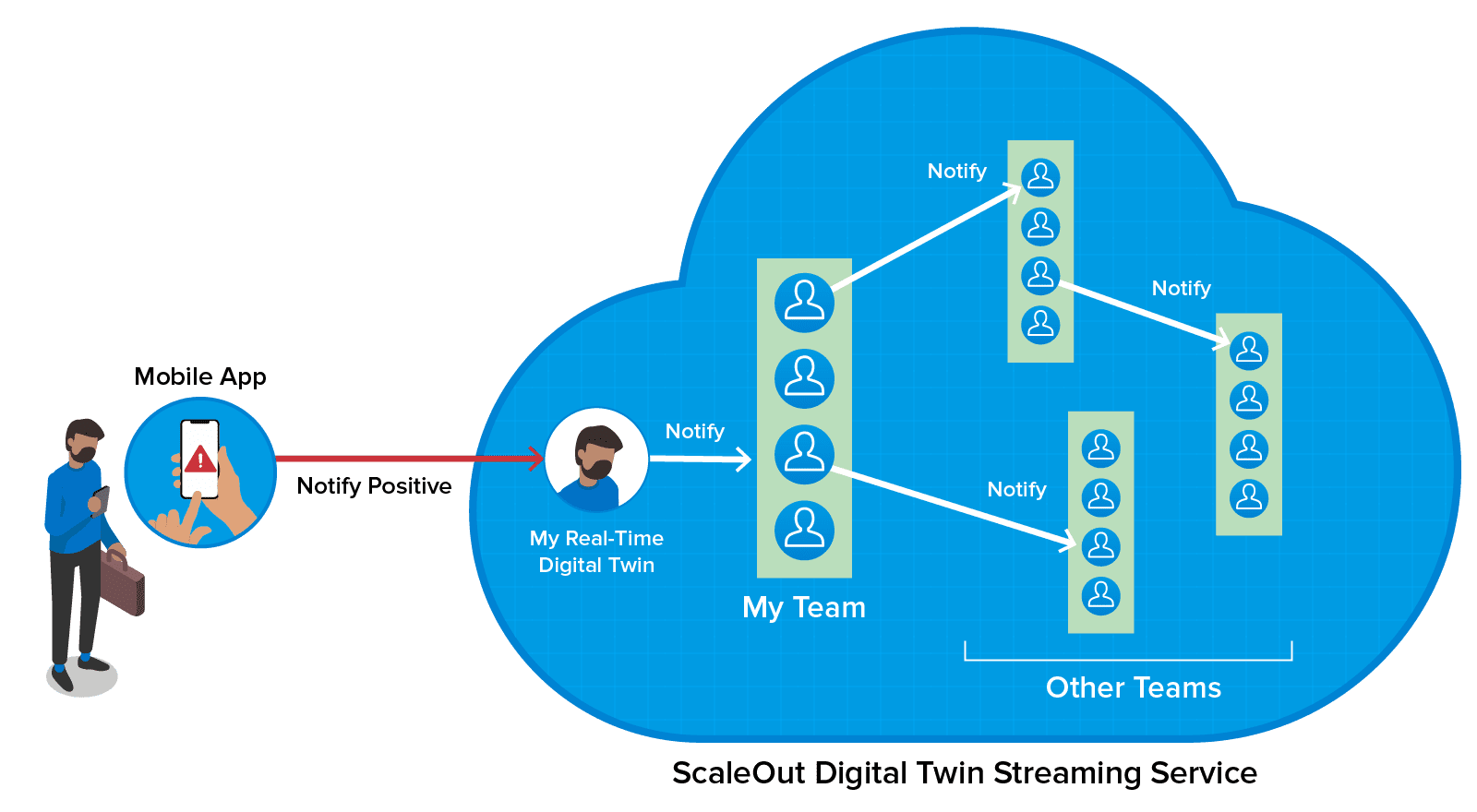
In an earlier blog post, we saw how real-time digital twins running in the ScaleOut Digital Twin Streaming Service can be used to track employees within a large company using a technique called “voluntary self-tracing.” In this post, we’ll take a closer look at its implementation in a demo application created by ScaleOut Software. We’ll also look at a companion mobile app that allows employees to log contacts with colleagues outside their immediate teams and to notify the company and their contacts if they test positive for COVID-19.
The demo application creates a memory-based real-time digital twin for each employee. Using information from the company’s organizational database, it populates each twin with the employee’s ID, team ID, department type, and location. The twin also keeps a list of the employee’s contacts within the organization (as well as community contacts, discussed below). This allows immediate colleagues and their contacts to be notified if an employee tests positive. The following diagram illustrates an employee’s real-time digital twin and the state data it holds; details about the contact tracing code are explained below:
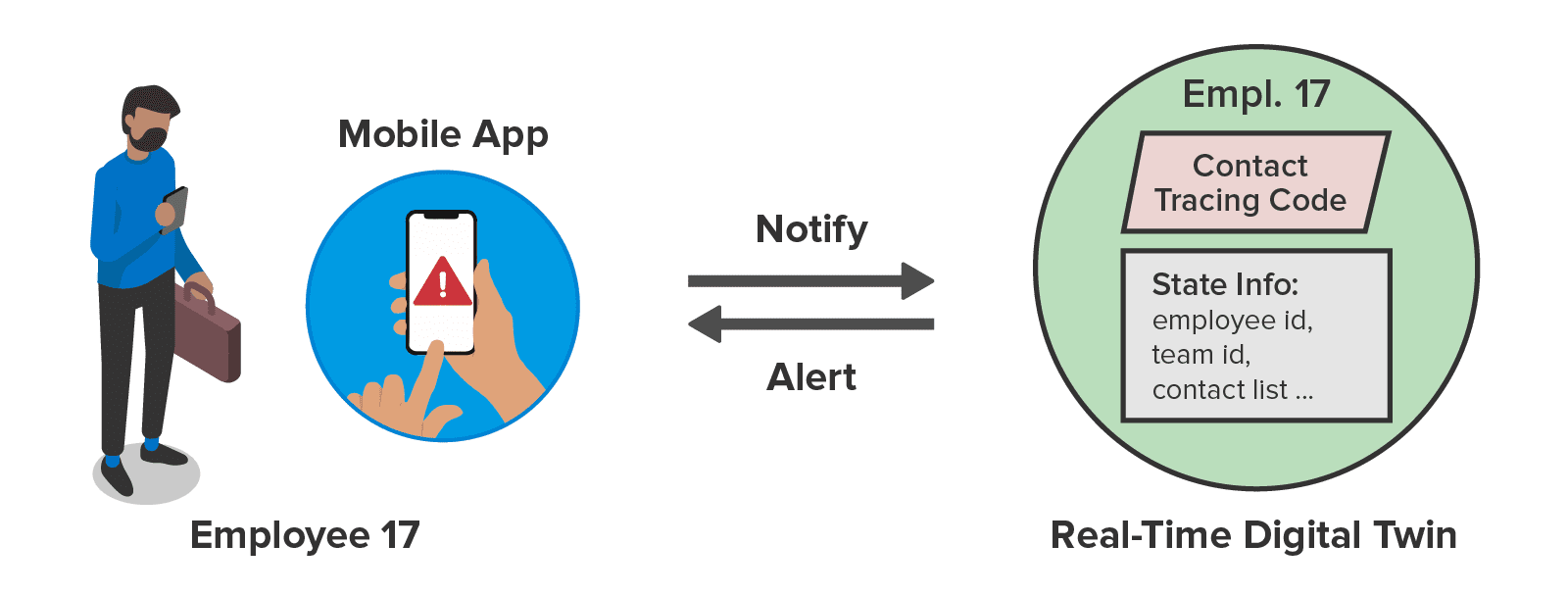
The twin automatically populates its contact list with the other members of the employee’s team, based on the expectation that team members are in daily contact. Using the mobile app, employees can log one-time and recurring contacts with colleagues in other teams, possibly at different office locations. In addition, they can log contacts outside the company, such as taxi rides, airline flights, and meals at restaurants, so that community members can be notified if an employee was exposed to COVID-19.
An employee can use the mobile app to notify their real-time digital twin of a positive test for COVID-19. Code running in the twin then sends messages to the real-time digital twins for all contacts in the employee’s list. These twins in turn send messages to their contacts, and so on, until the twins for all contacts have been notified. (The algorithm avoids unnecessary messages to team members and circular paths among twins.) The twin then sends a push notification to each affected employee through the mobile app, alerting them to the possible exposure and the number of intermediate contacts between themselves and the infected person. Because real-time digital twins are hosted in memory, all of this happens within seconds, enabling affected employees to immediately self-quarantine and obtain COVID-19 tests.
Here’s an illustration of the chain of contacts originating with an employee who reports testing positive. (Note that the outbound notifications from the twins to the employees’ mobile devices are not shown here.)
What’s in the Real-Time Digital Twin?
As illustrated in the first diagram, each real-time digital twin hosts two components, state data and a message-processing method. These are defined by the contact tracing application and can be written in C#, Java, or JavaScript. (C# was used for the demo application.) The state data is unique for each employee and contains the employee’s information and contact list, along with useful statistics, such as how often the employee has been alerted about a possible exposure. The message-processing method’s code is shared by all twins. It receives messages from the mobile app or from other twins (each corresponding to a single employee) and uses application-defined code to process these messages.
Messages from the mobile app can request to add or remove a contact from the list. For new contacts, they include parameters such as the employee ID of the contact and whether the contact will be recurring. (Users also can record contacts using calendar events.) Messages from the mobile app can also request the current contact list for display, signal that the employee has tested positive or negative, and request current notifications. Messages from other real-time digital twins signal that the corresponding employees have been exposed and provide additional information, such as the number of intermediate contacts and the location of the initial employee who tested positive.
The application’s message-processing code responds to these messages and implements the spanning-tree notification algorithm that alerts other twins on the contact list. The streaming service handles the rest, namely the details of message delivery, retrieval and updating of state information, and managing the execution platform.
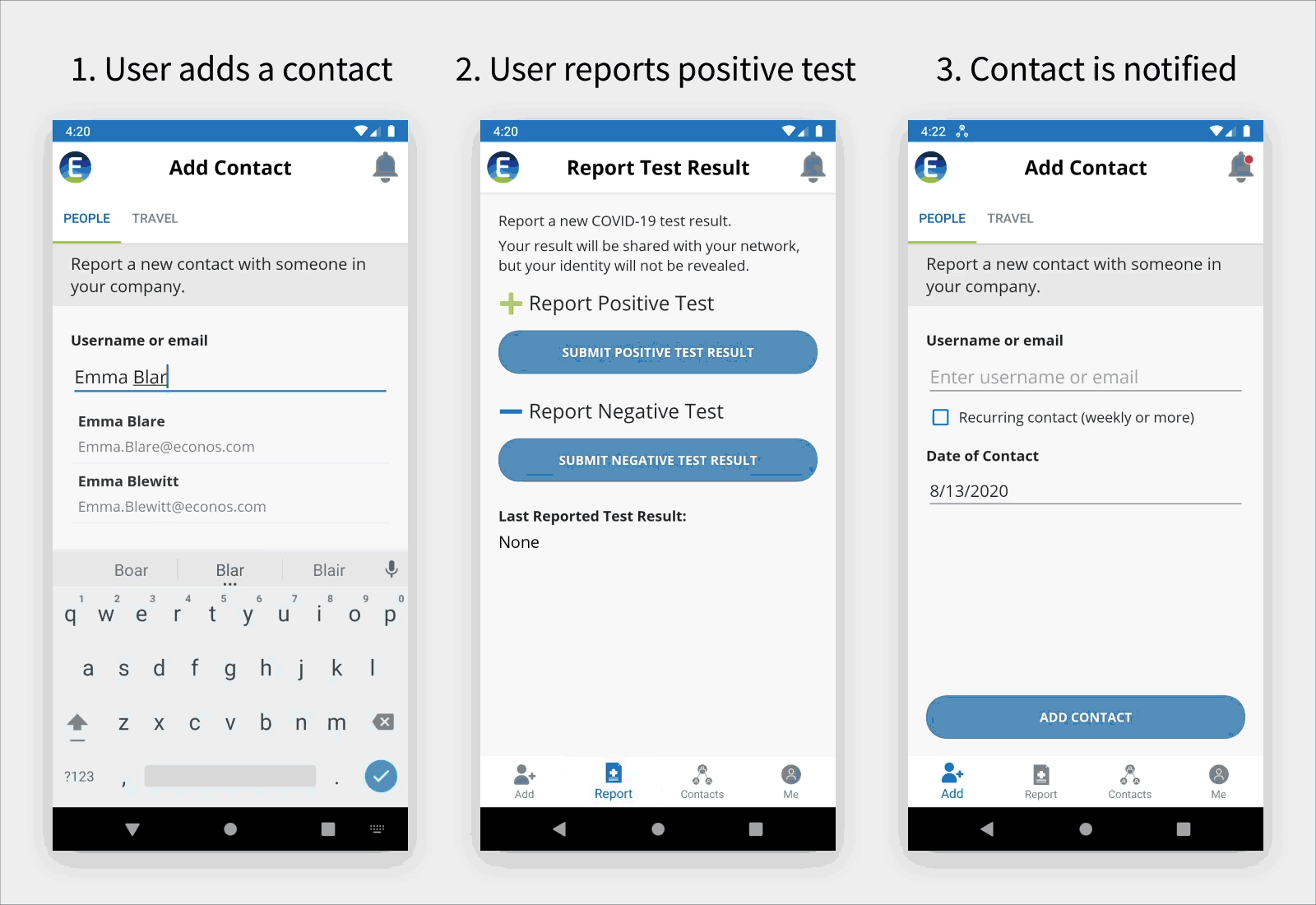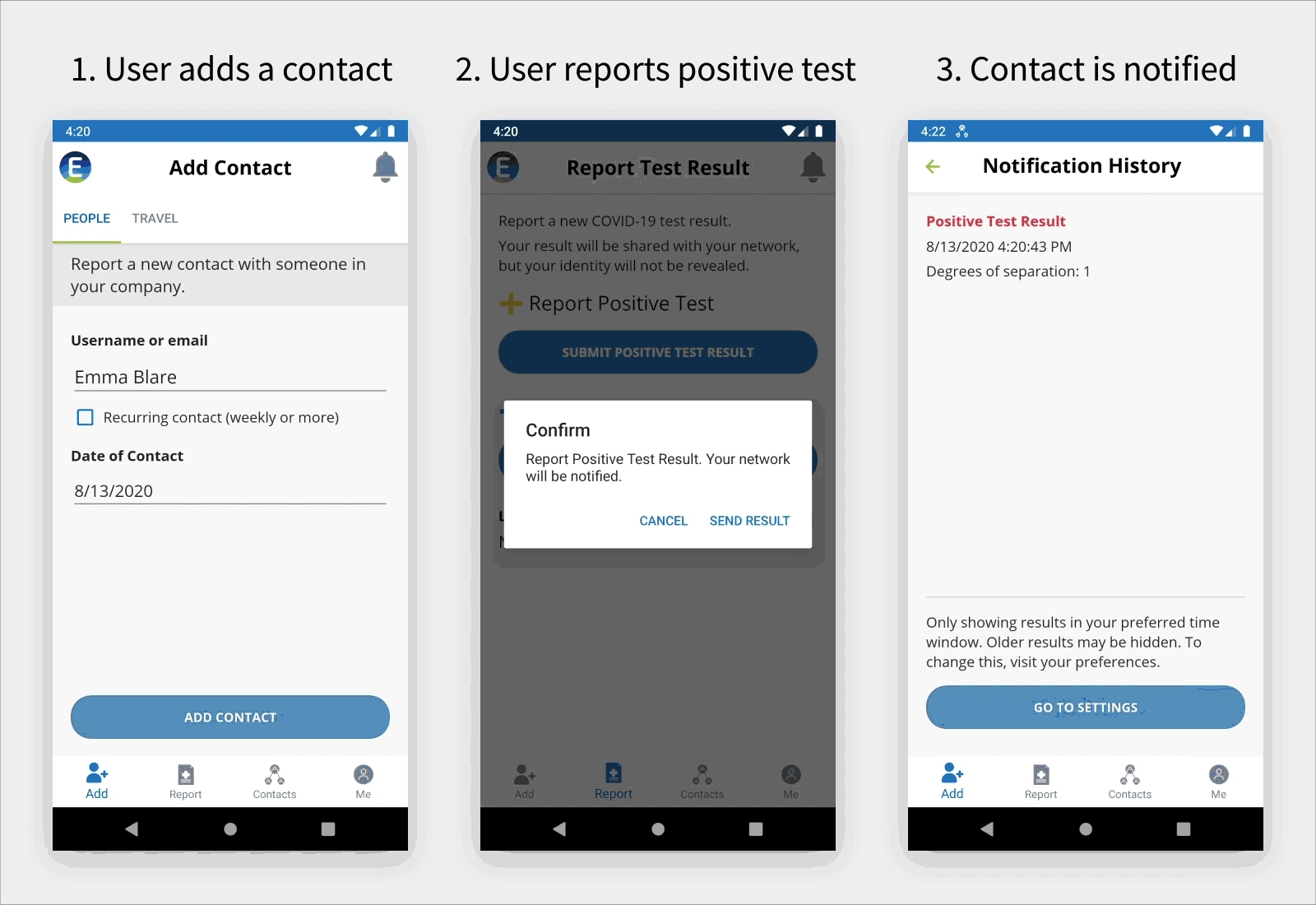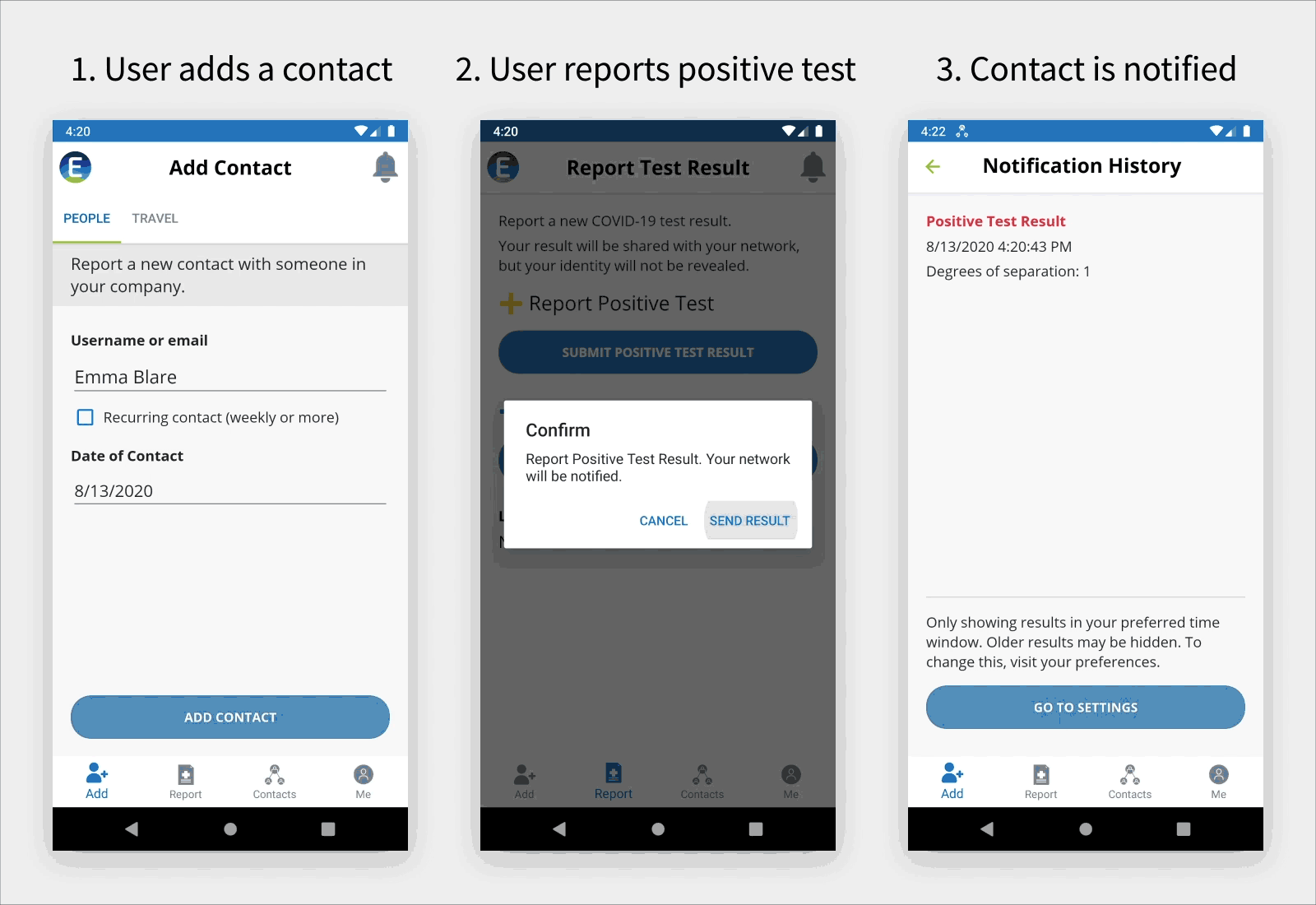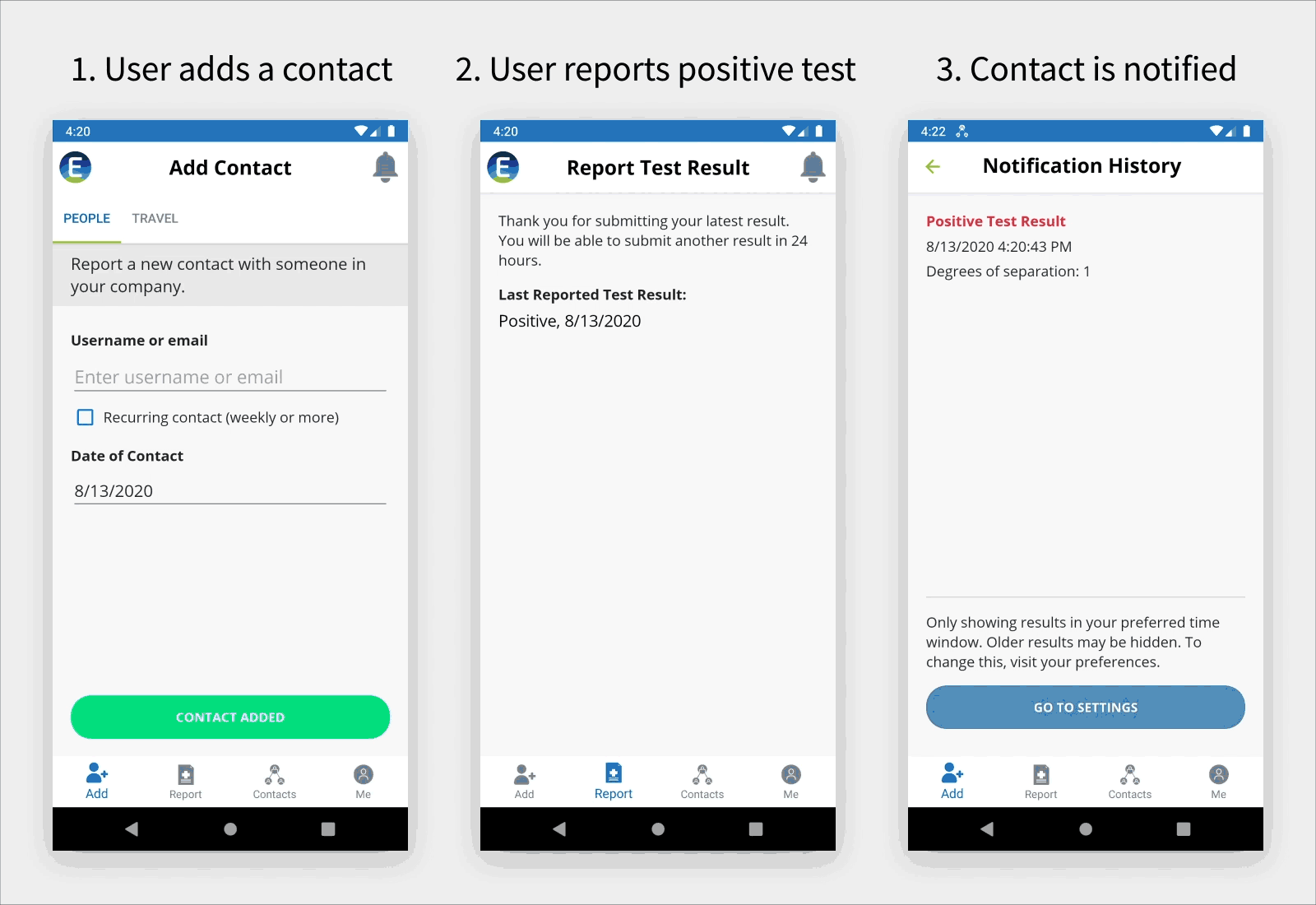
Using the Mobile App
The following animated diagram shows how an employee can add a contact with a company colleague outside of their immediate team or with a community contact during business travel (left screenshot). If the employee tests positive, the employee can use the mobile app to report this to the company (middle screenshot). All employees are then notified using the mobile app, as shown in the right screenshot. Community contacts are reported to managers who communicate with outside points of contact, such as airlines, taxi companies, and restaurants.
Using Aggregate Statistics to Spot Outbreaks
The streaming service has the built-in capability to aggregate state data from all real-time digital twins. The service then displays the results in charts which are recalculated every few seconds. These charts enable managers to identify emerging issues, such as an outbreak within a specific department or site. With this information, they can take immediate steps to contain the outbreak and minimize the number of affected employees.
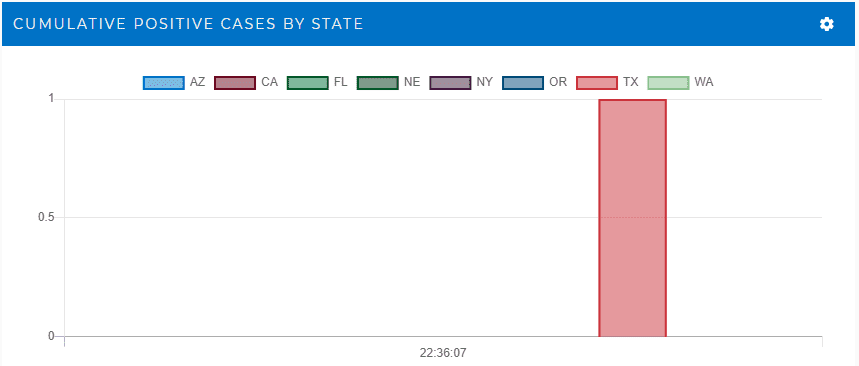
To illustrate the value of aggregate statistics in boosting situational awareness, consider a hypothetical company with 30,000 employees and offices in several states across the U.S. Suppose an employee at the Texas site suddenly tests positive. This could be immediately alerted to managers with the following chart generated and continuously updated by the streaming service, which shows all employees who have tested positive:
Within a few seconds, the real-time digital twins notify all points of contact. Updates to state data are immediately aggregated in another chart that shows the sites where employees have been notified of a positive contact and the number of employees affected at each site:
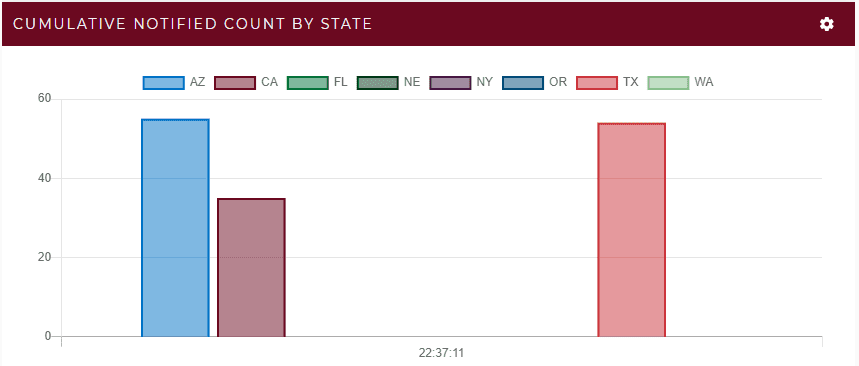
This chart shows that about 140 employees in three states were notified and possibly exposed directly or indirectly. All of these employees are then immediately quarantined to contain the possible spread of COVID-19. After an investigation by company managers, it is determined that the employee had business travel to Arizona and met with a team that subsequently had business travel to California. Instead of taking hours or days to uncover the scope of a COVID-19 exposure, contact tracing using real-time digital twins alerts managers within seconds.
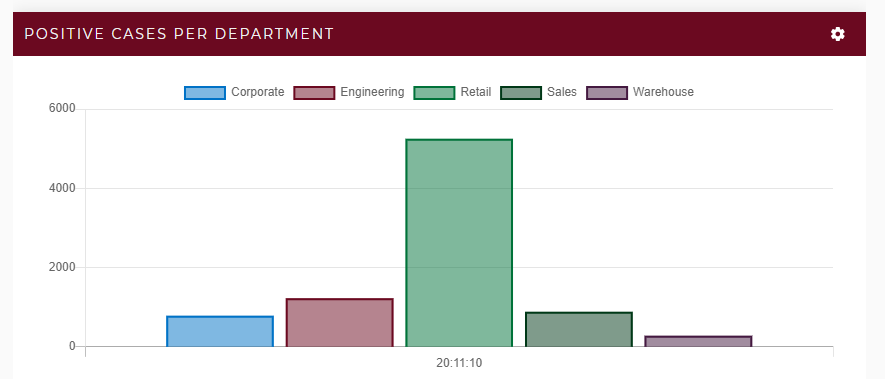
The real-time digital twins can collect additional useful statistics for visualization by the streaming service. Another chart can show the average number of intermediate contacts for all notified employees, which is an indication of how widely employees have been interacting across teams. If this becomes an issue (as it is in the above example), managers can implement policies to further isolate teams. As shown below, a chart can also show the number of notified employees by department so that managers can determine whether certain departments, such as retail outlets, need stricter policies to limit exposure to COVID-19 from outside contacts.
The Benefits of an Integrated Streaming Service
This contact tracing application demonstrates the power of real-time digital twins to enable fast application development with compelling benefits. Because the amount of application code is small, real-time digital twins can be quickly written and tested. (See a recent blog post which describes how to simplify debugging and testing using a mock environment prior to deployment in the cloud.) They also can be easily modified and updated.
The ScaleOut Digital Twin Streaming Service provides the execution platform so that the application code does not have to deal with message distribution, state saving, performance scaling, and high availability. It also includes support for real-time aggregate analytics and visualization integrated with the real-time digital twin model to maximize ease of use.
Compare this approach to the complexity of building out an application server farm, database, analytics application, and visualization to accomplish the same goals at higher cost and lower performance. Cobbling together these diverse technologies would require several skill sets, lengthy development time, and higher operational costs.
Summing Up
This demo contact tracing application was designed to show how companies can take advantage of their organizational structures to track contacts among employees and quickly notify all affected employees when an individual tests positive for COVID-19. By responding quickly to an exposure with immediate, comprehensive information about its extent within the company (and with community contacts), managers can limit the exposure’s impact. The application also shows how the real-time digital twin model enables a quick, agile implementation which can be easily adapted to the specific needs of a wide range of companies.
Please contact us at ScaleOut Software to learn more about this demo application for limiting the impact of COVID-19 and other ways real-time digital twins can help your company monitor and respond to fast-changing events.
The post Using Real-Time Digital Twins for Corporate Contact Tracing appeared first on ScaleOut Software.
]]>The post New Article in Toolbox on Using Real-Time Digital Twins for Emergency Response appeared first on ScaleOut Software.
]]>
The post New Article in Toolbox on Using Real-Time Digital Twins for Emergency Response appeared first on ScaleOut Software.
]]>The post Why Use “Real-Time Digital Twins” for Streaming Analytics? appeared first on ScaleOut Software.
]]>
What Problems Does Streaming Analytics Solve?
To understand why we need real-time digital twins for streaming analytics, we first need to look at what problems are tackled by popular streaming platforms. Most if not all platforms focus on mining the data within an incoming message stream for patterns of interest. For example, consider a web-based ad-serving platform that selects ads for users and logs messages containing a timestamp, user ID, and ad ID every time an ad is displayed. A streaming analytics platform might count all the ads for each unique ad ID in the latest five-minute window and repeat this every minute to give a running indication of which ads are trending.
Based on technology from the Trill research project, the Microsoft Stream Analytics platform offers an elegant and powerful platform for implementing applications like this. It views the incoming stream of messages as a columnar database with the column representing a time-ordered history of messages. It then lets users create SQL-like queries with extensions for time-windowing to perform data selection and aggregation within a time window, and it does this at high speed to keep up with incoming data streams.
Other streaming analytic platforms, such as open-source Apache Storm, Flink, and Beam and commercial implementations such as Hazelcast Jet, let applications pass an incoming data stream through a pipeline (or directed graph) of processing steps to extract information of interest, aggregate it over time windows, and create alerts when specific conditions are met. For example, these execution pipelines could process a stock market feed to compute the average stock price for all equities over the previous hour and trigger an alert if an equity moves up or down by a certain percentage. Another application tracking telemetry from gas meters could likewise trigger an alert if any meter’s flow rate deviates from its expected value, which might indicate a leak.
What’s key about these stream-processing applications is that they focus on examining and aggregating properties of data communicated in the stream. Other than by observing data in the stream, they do not track the dynamic state of the data sources themselves, and they don’t make inferences about the behavior of the data sources, either individually or in aggregate. So, the streaming analytics platform for the ad server doesn’t know why each user was served certain ads, and the market-tracking application does not know why each equity either maintained its stock price or deviated materially from it. Without knowing the why, it’s much harder to take the most effective action when an interesting situation develops. That’s where real-time digital twins can help.
The Need for Real-Time Digital Twins
Real-time digital twins shift the application’s focus from the incoming data stream to the dynamically evolving state of the data sources. For each individual data source, they let the application incorporate dynamic information about that data source in the analysis of incoming messages, and the application can also update this state over time. The net effect is that the application can develop a significantly deeper understanding about the data source so that it can take effective action when needed. This cannot be achieved by just looking at data within the incoming message stream.
For example, the ad-serving application can use a real-time digital twin for each user to track shopping history and preferences, measure the effectiveness of ads, and guide ad selection. The stock market application can use a real-time digital twin for each company to track financial information, executive changes, and news releases that explain why its stock price starts moving and filter out trades that don’t fit desired criteria.
Also, because real-time digital twins maintain dynamic information about each data source, applications can aggregate this highly curated data instead of just aggregating data in the data stream. This gives users deeper insights into the overall state of all data sources and boosts “situational awareness” that is hard to maintain by just looking at the message stream.
An Example
Consider a trucking fleet that manages thousands of long-haul trucks on routes throughout the U.S. Each truck periodically sends telemetry messages about its location, speed, engine parameters, and cargo status (for example, trailer temperature) to a real-time monitoring application at a central location. With traditional streaming analytics, personnel can detect changes in these parameters, but they can’t assess their significance to take effective, individualized action for each truck. Is a truck stopped because it’s at a rest stop or because it has stalled? Is an out-of-spec engine parameter expected because the engine is scheduled for service or does it indicate that a new issue is emerging? Has the driver been on the road too long? Does the driver appear to be lost or entering a potentially hazardous area?
The use of real-time digital twins provides the context needed for the application to answer these questions as it analyzes incoming messages from each truck. For example, it can keep track of the truck’s route, schedule, cargo, mechanical and service history, and information about the driver. Using this information, it can alert drivers to impending problems, such as road blockages, delays or emerging mechanical issues. It can assist lost drivers, alert them to erratic driving or the need for rest stops, and help when changing conditions require route updates.
The following diagram shows a truck communicating with its associated real-time digital twin. (The parallelogram represents application code.) Because the twin holds unique contextual data for each truck, analysis code for incoming messages can provide highly focused feedback that goes well beyond what is possible with traditional streaming analytics:
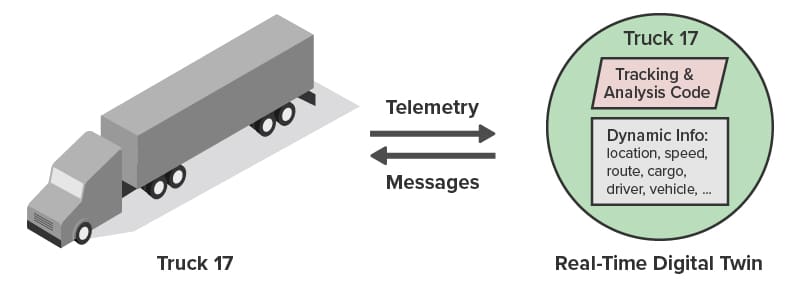
As illustrated below, the ScaleOut Digital Twin Streaming Service runs as a cloud-hosted service in the Microsoft Azure cloud to provide streaming analytics using real-time digital twins. It can exchange messages with thousands of trucks across the U.S., maintain a real-time digital twin for each truck, and direct messages from that truck to its corresponding twin. It simplifies application code, which only needs to process messages from a given truck and has immediate access to dynamic, contextual information that enhances the analysis. The result is better feedback to drivers and enhanced overall situational awareness for the fleet.
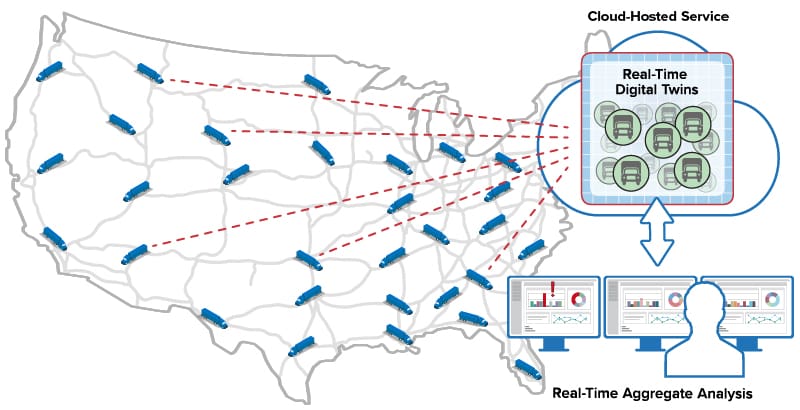
Lower Complexity and Higher Performance
While the functionality implemented by real-time digital twins can be replicated with ad hoc solutions that combine application servers, databases, offline analytics, and visualization, they would require vastly more code, a diverse combination of skill sets, and longer development cycles. They also would encounter performance bottlenecks that require careful analysis to measure and resolve. The real-time digital twin model running on ScaleOut Software’s integrated execution platform sidesteps these obstacles.
Scaling performance to maintain high throughput creates an interesting challenge for traditional streaming analytics platforms because the work performed by their task pipelines does not naturally map to a set of processing cores within multiple servers. Each pipeline stage must be accelerated with parallel execution, and some stages require longer processing time than others, creating bottlenecks in the pipeline.
In contrast, real-time digital twins naturally create a uniformly large set of tasks that can be evenly distributed across servers. To minimize network overhead, this mapping follows the distribution of in-memory objects within ScaleOut’s in-memory data grid, which holds the state information for each twin. This enables the processing of real-time digital twins to scale transparently without adding complexity to either applications or the platform.
Summing Up
Why use real-time digital twins? They solve an important challenge for streaming analytics that is not addressed by other, “pipeline-oriented” platforms, namely, to simultaneously track the state of thousands of data sources. They use contextual information unique to each data source to help interpret incoming messages, analyze their importance, and generate feedback and alerts tailored to that data source.
Traditional streaming analytics finds patterns and trends in the data stream. Real-time digital twins identify and react to important state changes in the data sources themselves. As a result, applications can achieve better situational awareness than previously possible. This new way of implementing streaming analytics can be used in a wide range of applications. We invite you to take a closer look.
The post Why Use “Real-Time Digital Twins” for Streaming Analytics? appeared first on ScaleOut Software.
]]>The post Voluntary Contact Self-Tracing for Companies appeared first on ScaleOut Software.
]]>
How Voluntary Self-Tracing Helps
In a previous blog post, we explored how voluntary contact self-tracing can assist other contact tracing techniques in alerting people who may have been exposed to the COVID-19 virus. This technique enables participants to log interactions with others so that they can discover if they are in a chain of contacts originating with someone, often a stranger, who subsequently tests positive for the virus. These contacts could include friends at a barbeque, grocery checkers, hairdressers, restaurant waitstaff, taxi drivers, or other interactions.
In contrast to highly publicized, proximity-based contact tracing by using mobile devices, voluntary self-tracing avoids security and privacy issues that have threatened widespread adoption. It also adds human judgment to the process so that the chain of contacts captures only potentially risky interactions. This is accomplished in advance of a positive test, enabling immediate notifications when the need arises.
Voluntary self-tracing offers huge value in connecting strangers who otherwise would not be notified about the need for testing without arduous manual contact tracing. However, it imposes the burden that everyone participates in a common tracing system and consistently makes the effort to log interactions. While this might restrict its appeal for public use, it could be readily adopted by companies, which have well-known, slowly changing populations and established working relationships and protocols.
Helping Companies Get Back to Work
Consider a company that has multiple departments distributed across several locations. As employees come back to work, they typically interact closely with colleagues in the same department. If anyone in the department tests positive for COVID-19, it’s likely that all of these colleagues have been exposed and need to get tested. In addition, employees occasionally interact with colleagues in other departments, both at the same site and at remote sites. These interactions also need to be tracked to contain exposure within the organization, as illustrated in the following diagram:
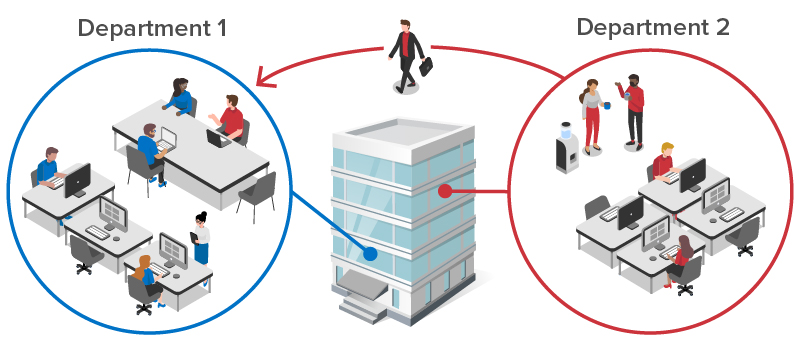
Voluntary contact self-tracing can handle the most common scenarios by using the company’s employee database to automatically connect colleagues who work in the same department and interact daily. Employees need only manually log contacts they make with employees in other departments. These interactions are relatively infrequent and tracked for a limited period of time (typically two weeks). This approach streamlines the work required to track contacts, while enabling the company to immediately identify all employees who need to be notified, tested, and possibly isolated after one person tests positive.
In addition, employees can manually track information about contacts they make while on business travel, such as during airline flights, taxi rides, and meals at restaurants. That way, when an employee tests positive, these external contacts can be immediately alerted of possible exposure. This enables companies to assist their communities in contact tracing and help contain the spread of COVID-19.

Enabling Technology: In-Memory Computing
Many large companies have tens of thousands of employees and need to perform fast, efficient contact tracing. They require both immediate notifications and up-to-the-moment statistics that identify emerging trends, such as hot spots at one of their offices. To make this possible, a technology called in-memory computing can be used to track contacts and immediately alert all affected employees (and community touchpoints, such as restaurants) when anyone tests positive and alerts the system. Using a mobile app connected to a cloud service, it creates and maintains a dynamic web of contacts that evolves as interactions occur and time passes.
For example, when an employee tests positive and alerts the system, all colleagues in the same department are quickly notified, as are employees in other departments with whom interactions have occurred. The contact tracing system follows the chain of contacts across departments at all locations within the company. It also notifies community contacts, such as airlines and taxi companies, of possible exposures so that they can take the appropriate action.
Within the cloud service, the in-memory computing system maintains a software-based real-time digital twin for each employee. This software twin records and maintains all contacts for the employee, as well as all community contacts. It also removes non-recurring contacts after sufficient time passes and exposure is no longer likely. When an employee tests positive, the mobile app notifies the corresponding real-time digital twin in the cloud. This sets off the chain of communication that alerts all connected twins to the exposure and notifies their real-world counterparts.
Maximizing Situational Awareness
Real-time digital twins contain a wealth of dynamic, up-to-the-minute information that can be tapped to help managers maintain situational awareness about rapidly evolving exposures and ongoing progress to contain them. In-memory computing technology can aggregate this data and visually present the results to help immediately spot outbreaks and identify significant problem areas. For example, the following chart, which can be updated every few seconds, shows the number of employees who have just tested positive at each site within a company:
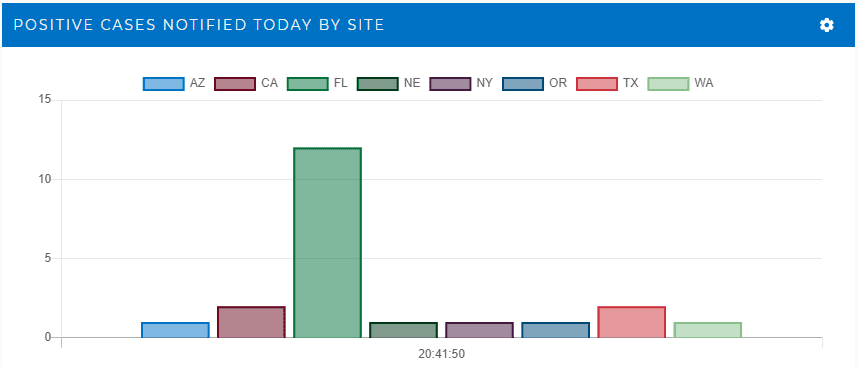
The chart shows a jump in cases for employees at the Florida site. Managers can then investigate the source of the outbreak by department at this site:
Not surprisingly, most cases are occurring in the Retail department, most likely because of its large number of interactions with customers, and this department needs to take additional steps to limit exposure. With real-time aggregate analytics, managers can also track other important indicators, such as the number of employees and sites affected by an outbreak, the average number of interconnected contacts, and the percentage of affected employees who have received notifications and taken action.
Getting Back to Work Safely
As companies strive to restore to a normal working environment, managers recognize the need to carefully track the occurrence of COVID-19 in the workplace and minimize its propagation throughout an organization. Immediately notifying and isolating all affected employees helps to limit the size of an outbreak, while analyzing the sources and evolution of incidents assists managers in the moment and as they develop new policies and strategies. With its ability to track and analyze fast-changing data in real time, in-memory computing technology offers a powerful and flexible toolset for contact tracing, helping employees get back to work safely.
The post Voluntary Contact Self-Tracing for Companies appeared first on ScaleOut Software.
]]>The post Using Real-Time Digital Twins for Aggregate Analytics appeared first on ScaleOut Software.
]]>thousands of data sources.
When analyzing telemetry from a large population of data sources, such as a fleet of rental cars or IoT devices in “smart cities” deployments, it’s difficult if not impossible for conventional streaming analytics platforms to track the behavior of each individual data source and derive actionable information in real time. Instead, most applications just sift through the telemetry for patterns that might indicate exceptional conditions and forward the bulk of incoming messages to a data lake for offline scrubbing with a big data tool such as Spark.
Maintain State Information for Each Data Source
An innovative new software technique called “real-time digital twins” leverages in-memory computing technology to turn the Lambda model for streaming analytics on its head and enable each data source to be independently tracked and responded to in real time. A real-time digital twin is a software object that encapsulates dynamic state information for each data source combined with application-specific code for processing incoming messages from that data source. This state information gives the code the context it needs to assess the incoming telemetry and generate useful feedback within 1-3 milliseconds.
For example, suppose an application analyzes heart rate, blood pressure, oxygen saturation, and other telemetry from thousands of people wearing smart watches or medical devices. By holding information about each user’s demographics, medical history, medications, detected anomalies, and current activity, real-time digital twins can intelligently assess this telemetry while updating their state information to further refine their feedback to each person. Beyond just helping real-time digital twins respond more effectively in the moment, maintaining context improves feedback over time.
Use State Information for Aggregate Analytics
State information held within real-time digital twins also provides a repository of significant data that can be analyzed in aggregate to spot important trends. With in-memory computing, aggregate analysis can be performed continuously every few seconds instead of waiting for offline analytics in a data lake. In this usage, relevant state information is computed for each data source and updated as telemetry flows in. It is then repeatedly extracted from all real-time digital twins and aggregated to highlight emerging patterns or issues that may need attention. This provides a powerful tool for maximizing overall situational awareness.
Consider an emergency monitoring system during the COVID-19 crisis that tracks the need for supplies across the nation’s 6,100+ hospitals and attempts to quickly respond when a critical shortage emerges. Let’s assume all hospitals send messages every few minutes to this system running in a central command center. These messages provide updates on various types and amounts of shortages (for example, of PPE, ventilators, and medicines) that the hospitals need to quickly rectify. Using state information, a real-time digital twin for each hospital can both track and evaluate these shortages as they evolve. It can look at key indicators, such as the relative importance of each supply type and the rate at which the shortages are increasing, to create a dynamic measure of urgency that the hospital receive attention from the command center. All of this data is continuously updated within the real-time digital twin as messages arrive to give personnel the latest status.
Aggregate analysis can then compare this data across all hospitals by region to identify which regions have the greatest immediate need and track how fast and where overall needs are evolving. Personnel can then query state information within the real-time digital twins to quickly determine which specific hospitals should receive supplies and what specific supplies should be immediately delivered to them. Using real-time digital twins, all of this can be accomplished in seconds or minutes.
This analysis flow is illustrated in the following diagram:
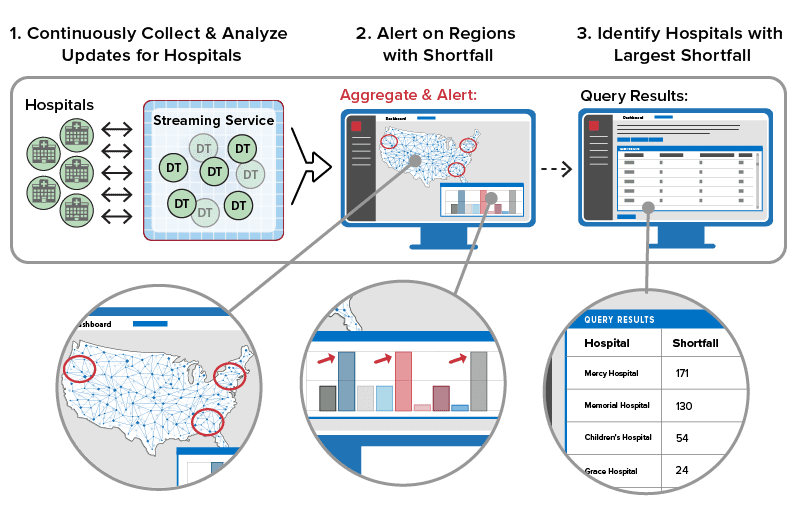
As this example shows, real-time digital twins provide both a real-time filter and aggregator of the data stream from each data source to create dynamic information that is continuously extracted for aggregate analysis. Real-time digital twins also track detailed information about the data source that can be queried to provide a complete understanding of evolving conditions and enable appropriate action.
Numerous Applications Need Real-Time Monitoring
This new paradigm for streaming analytics can be applied to numerous applications. For example, it can be used in security applications to assess and filter incoming telemetry (such as likely false positives) from intrusion sensors and create an overall likelihood of a genuine threat from a given location within a large physical or cyber system. Aggregate analysis combined with queries can quickly evaluate the overall threat profile, pinpoint the source(s), and track how the threat is changing over time. This information enables personnel to assess the strategic nature of the threat and take the most effective action.
Likewise, disaster-recovery applications can use real-time digital twins to track assets needed to respond to emergencies, such as hurricanes and forest fires. Fleets of rental cars or trucks can use real-time digital twins to track vehicles and quickly identify issues, such as lost drivers or breakdowns. IoT applications can use real-time digital twins to implement predictive analytics for mission-critical devices, such as medical refrigerators. The list goes on.
Summing Up: Do More in Real Time
Conventional streaming analytics only attempt to perform superficial analysis of aggregated data streams and defer the bulk of analysis to offline processing. Because of their ability to maintain dynamic, application-specific information about each data source, real-time digital twins offer breathtaking new capabilities to track thousands of data sources in real time, provide intelligent feedback, and combine this with immediate, highly focused aggregate analysis. By harnessing the scalable power of in-memory computing, real-time digital twins are poised to usher in a new era in streaming analytics.
We invite you to learn more about the ScaleOut Digital Twin Streaming Service, which is available for evaluation and production use today.
The post Using Real-Time Digital Twins for Aggregate Analytics appeared first on ScaleOut Software.
]]>The post Voluntary & Anonymous Contact “Self”-Tracing at Scale appeared first on ScaleOut Software.
]]>A New Approach: Log Our Own Contacts in Advance
As we all know, getting people back to work will require testing and contact tracing. The latter will need armies of people to track down all contacts of each person who tests positive for coronavirus. Leading software companies are building mobile apps to log the places we have been and determine possible contacts. However, these apps will be complex by relying on Bluetooth wireless technology to detect proximity, and they raise concerns regarding both accuracy and privacy. Experts have stated that humans need to be in the loop for contact tracing to be effective. Maybe there’s a hybrid approach that offers promise in the near term.
What if we could easily and anonymously let people keep track of encounters as they occur that they judge to be potentially risky, such as with work colleagues, merchants, neighbors, and friends? As people log these contacts using aliases for privacy, cloud software could build a web of connections, often connecting strangers through intermediaries. Later, when a person tests positive, he or she could notify this software. It then could follow the breadcrumbs and anonymously alert via text message or email all people who recently came into contact and should be tested and/or self-isolated.
Here’s an example. When a grocery checker with the alias “flash88” tests positive for COVID-19, he can anonymously alert a chain of people who are connected by direct or intermediate contacts who have logged significant, recent encounters, such as haircuts or backyard barbeques:
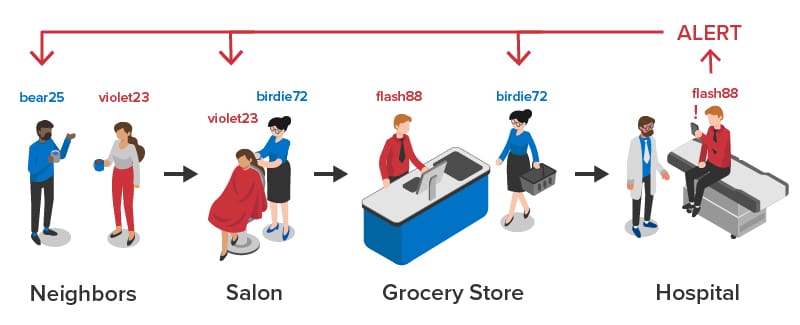
Although voluntarily “self-tracing” our contacts would require proactive effort for each of us to log individual encounters, it could be done quickly and simply by just entering a person’s anonymous alias into a mobile app or web page. Most people likely would choose to do this only for lengthy interactions, such as with colleagues working closely together, friends at a barbeque, or perhaps a hairdresser or server at a restaurant. Location information could be included if permitted. What emerges from countless individual actions is a massive, continuously evolving web of contacts that can be immediately called upon for alerting when anyone tests positive.
For self-tracing to be effective, people who come into mutual contact need to register aliases and contact information (email or mobile number) with the software. As each person encounters a potentially risky contact and logs that contact’s alias, the system builds a record of the contact just for the period of time that risk of infection is possible, possibly two weeks. Regular work contacts could automatically be refreshed on a schedule.
The power of self-tracing is its ability to give us automatic, immediate — and anonymous — notification of exposure risk from a chain of contacts. While this tool does not replace standard contact tracing, it can add important value in its simplicity, timeliness, and incorporation of human judgment. As an alternative to more complicated and invasive Bluetooth-based contact tracing software, it could help accelerate the return to work for colleagues and businesses while offloading some of the work for contact tracers.
Advanced Capabilities
Beyond just tracking contacts, cloud-hosted software can keep track of important statistics, such as when and where (if permitted) a person tested positive or was alerted and how many in a chain separate a person from the source of an alert. Real-time analytics can continuously evaluate this data to immediately identify important trends, such as the locations where an unusually large number of alerts are occurring. This allows personnel to quickly respond and institute a self-isolation protocol where necessary.
Real-time analytics also can generate other useful statistics, such as the average chain length that results in co-infection and the percentage of connected people who actually become co-infected. If anonymous demographics are maintained and submitted by users, statistics can be computed by gender, age, and other parameters useful to healthcare professionals.
The Tech: In-Memory Cloud Computing Makes Self-Tracing Fast and Scalable
Cloud-hosted software technology called in-memory computing makes this contact tracing technique fast, scalable and quickly deployable. (It also can be used to assist other contact tracing efforts and for asset tracking.) While simultaneously tracking contacts for millions of people, this software can alert all related contacts in a matter of seconds after notification, and it can send out many thousands of alerts every second.
When a person tests positive and notifies the software, a cloud-based system uses the record of contacts kept with each person to send out alerts, and it follows these records from contact to contact until all mutually connected people have been alerted. In addition, human contact tracers could take advantage of this network (if permitted by users) to aid in their investigations.
ScaleOut Software has developed an in-memory, cloud-hosted software technology called real-time digital twins which make hosting this application easy, fast, and flexible. As illustrated below, cloud software can maintain a real-time digital twin for each user being tracked in the system to keep dynamic data for both alerting and real-time analytics. In addition to processing alerts, this software continuously extracts dynamic data from the real-time digital twins and analyzes it every few seconds. This makes it possible to generate and visualize the statistics described above in real time. Using real-time digital twins enables an application like this to be implemented within just a few days instead of weeks or months.
Note: To the extent possible, ScaleOut Software will make its cloud-based ScaleOut Digital Twin Streaming Service available free of charge (except for fees from the cloud provider) for public institutions needing help tracking data to assist in the COVID19 crisis.
Summing Up
Anonymous, voluntary, contact self-tracing has the potential to fill an important gap as a hybrid approach between manual contact tracing and complex, fully automated, location-based technologies. In work settings, it could be especially useful in protecting colleagues and customers. It offers a powerful tool to help contain the spread of COVID19, maximize situational awareness for healthcare workers and contact tracers, and minimize risks from exposure for all of us.
The post Voluntary & Anonymous Contact “Self”-Tracing at Scale appeared first on ScaleOut Software.
]]>The post Track Thousands of Assets in a Time of Crisis Using Real-Time Digital Twins appeared first on ScaleOut Software.
]]>What are real-time digital twins and why are they useful here?
A “real-time digital twin” is a software concept that can track the key parameters for an individual asset, such as a box of masks or a ventilator, and update these parameters in milliseconds as messages flow in from personnel in the field (or directly from smart devices). For example, the parameters for a ventilator could include its identifier, make and model, current location, status (in use, in storage, broken), time in use, technical issues and repairs, and contact information. The real-time digital twin software tracks and updates this information using incoming messages whenever significant events affecting the ventilator occur, such as when it moves from place to place, is put in use, becomes available, encounters a mechanical issue, has an expected repair time, etc. This software can simultaneously perform these actions for hundreds of thousands of ventilators to keep this vital logistical information instantly available for real-time analysis.
With up-to-date information for all ventilators immediately at hand, analysts can ask questions like:
- “Where are all the available ventilators at this moment?”
- “Show me a list of currently available or soon to be available ventilators in my county right now.”
- “What is the average time that ventilators have been in use per patient for each state?
- “Which hospital in a given state has the most unused ventilators?”
- “How many ventilators currently are in repair by make?”
These questions can be answered using the latest data as it streams in from the field. Within seconds, the software performs aggregate analysis of this data for all real-time digital twins. By avoiding the need to create or connect to complex databases and ship data to offline analytics systems, it can provide timely answers quickly and easily.
Besides just tracking assets, real-time digital twins also can track needs. For example, real-time digital twins of hospitals can track quantities of needed supplies in addition to supplies of assets on hand. This allows quick answers to questions such as:
- “Show me the percentage shortfall in ventilators by state.”
- “Which hospitals in a state currently have more than a 25% shortfall (or excess) in ventilators?”
Unlike powerful big data platforms which focus on deep and often lengthy analysis to make future projections, what real-time digital twins offer is timeliness in obtaining quick answers to pressing questions using the most current data. This allows decision makers to maximize their situational awareness in rapidly evolving situations.
Of course, keeping data up to date relies on the ability to send messages to the software hosting real-time digital twins whenever a significant event occurs, such as when a ventilator is taken out of storage or activated for a patient. Field personnel with mobile devices can send these messages over the Internet to the cloud service. It also might be possible for smart devices like ventilators to send their own messages automatically when activated and deactivated or if a problem occurs.
The following diagram illustrates how real-time digital twins running in a cloud service can receive messages from thousands of physical data sources across the country:
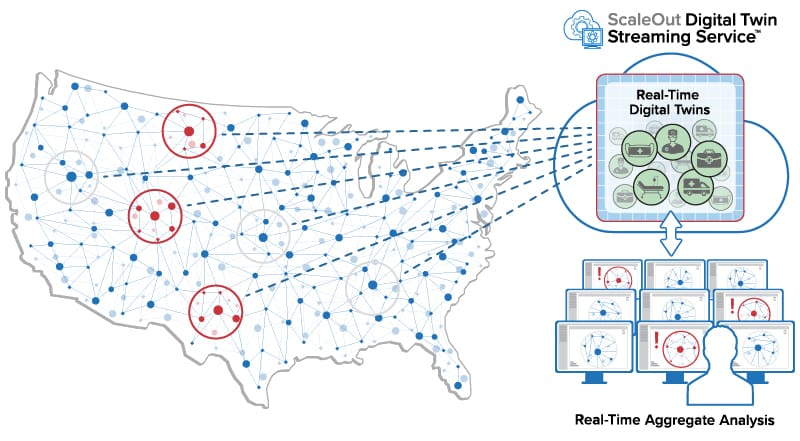
How Do Real-Time Digital Twins Work?
What gives real-time digital twins their agility compared to complex, enterprise-based data management systems is their simplicity. A real-time digital twin consists of two components: a software object describing the properties of the physical asset being tracked and a software method (that is, code) which describes how to update these properties when an incoming message arrives. This method also can analyze changes in the properties and send an alert when conditions warrant.
Consider a simple example in which a message arrives signaling that a ventilator has been activated for a patient. The software method receives the message and then records the activation time in a property within the associated object. When the ventilator is deactivated, the method can both record the time and update a running average of usage time for each patient. This allows analysts to ask, for example, “What is the average time in use for all ventilators by state?” which could serve as indication of increased severity of cases in some states.
Because of this extremely simple software formulation, real-time digital twins can be created and enhanced quickly and easily. For example, if analysts observe that several ventilators are being marked as failed, they could add properties to track the type of failure and the average time to repair.
The power of real-time digital twin approach lies in the use of a scalable, in-memory computing system which can host thousands (or even millions) of twins to track very large numbers of assets in real time. The computing system also has the ability to perform aggregate analytics in seconds on the continuously evolving data held in the twins. This enables analysts to obtain immediate results with the very latest information and make decisions within minutes.
In this time of crisis, it’s likely the case that the technology of real-time digital twins has arrived at the right time to help our overtaxed medical professionals.
Note: To the extent possible, ScaleOut Software will make its cloud-based ScaleOut Digital Twin Streaming Service available free of charge (except for fees from the cloud provider) for institutions needing help tracking data to assist in the COVID19 crisis.
The post Track Thousands of Assets in a Time of Crisis Using Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Real-Time Digital Twins: A New Approach to Streaming Analytics appeared first on ScaleOut Software.
]]>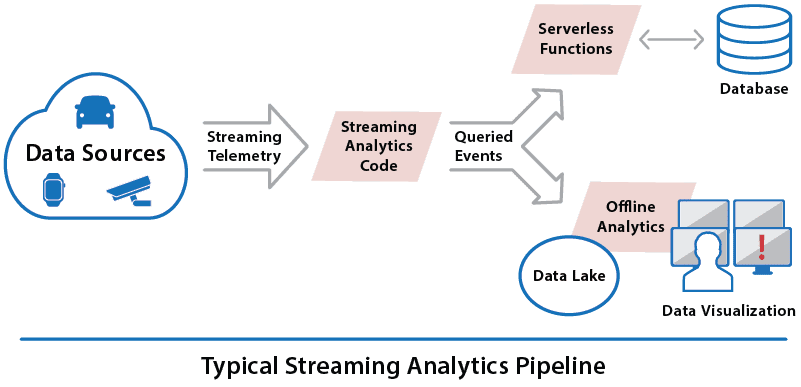
A conventional pipeline combines telemetry from all data sources into a single stream which is queried by the user’s streaming analytics application. This code often takes the form of a set of SQL queries (extended with time-windowing semantics) running continuously to select interesting events from the stream. These query results are then forwarded to a data lake for offline analytics using tools such as Spark and for data visualization. Query results also might be forwarded to cloud-based serverless functions to trigger alerts or other actions in conjunction with access to a database or blob store.
These techniques are highly effective for analyzing telemetry in aggregate to identify unusual situations which might require action. For example, if the telemetry is tracking a fleet of rental cars, a query could report all cars by make and model that have reported a mechanical problem more than once over the last 24 hours so that follow-up inquiries can be made. In another application, if the telemetry stream contains key-clicks from an e-commerce clothing site, a query might count how many times a garment of a given type or brand was viewed in the last hour so that a flash sale can be started.
A key limitation of this approach is that it is difficult to separately track and analyze the behavior of each individual data source, especially when they number in the thousands or more. It’s simply not practical to create a unique query tailored for each data source. Fine-grained analysis by data source must be relegated to offline processing in the data lake, making it impossible to craft individualized, real-time responses to the data sources.
For example, a rental car company might want to alert a driver if she/he strays from an allowed region or appears to be lost or repeatedly speeding. An e-commerce company might want to offer a shopper a specific product based on analyzing the click-stream in real time with knowledge of the shopper’s brand preferences and demographics. These individualized actions are impractical using the conventional tools of real-time streaming analytics.
However, real-time digital twins easily bring these capabilities within reach. Take a look at how the streaming pipeline differs when using real-time digital twins:
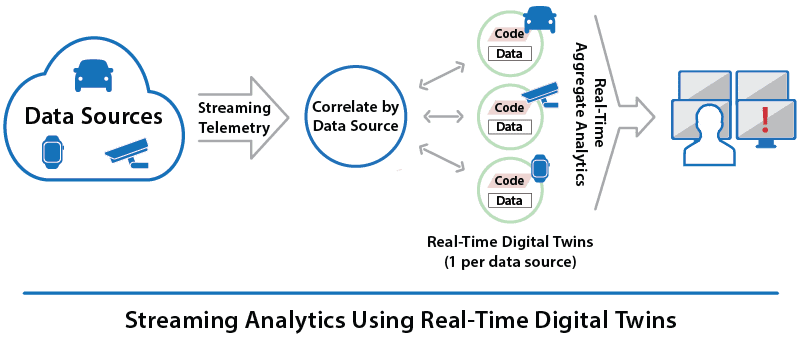
The first important difference to note is that the execution platform automatically correlates telemetry events by data source. This avoids the need for the application to select events by data source using queries (which is impractical in any case when using a conventional pipeline with many data sources). The second difference is that real-time digital twins maintain immediately accessible (in-memory) state information for each data source which is used by message-processing code to analyze incoming events from that data source. This enables straightforward application code to immediately react to telemetry information in the context of knowledge about the history and state of each data source.
For example, the rental car application can keep each driver’s contract, location history, and the car’s known mechanical issues and service history within the corresponding digital twin for immediate reference to help detect whether an alert is needed. Likewise, the e-commerce application can keep each shopper’s recent product searches along with brand preferences and demographics in her/his digital twin, enabling timely suggestions targeted to each shopper.
The power of real-time digital twins lies in their ability to make fine-grained analysis and responses possible in real time for thousands of data sources. They are made possible by scalable, in-memory computing technology hosted on clusters of cloud-based servers. This provides the fast response times and scalable throughput needed to support many thousands of data sources.
Lastly, real-time digital twins open the door to real-time aggregate analytics that analyze state data across all instances to spot emerging patterns and trends. Instead of waiting for the data lake to provide insights, aggregate analytics on real-time digital twins can immediately surface patterns of interest, maximizing situational awareness and assisting in the creation of response strategies.
With aggregate analytics, the rental car company can identify regions with unusual delays due to weather or highway blockages and then alert the appropriate drivers to suggest alternative routes. The e-commerce company can spot hot-selling products perhaps due to social media events and respond to ensure that inventory is made available.
Real-time digital twins create exciting new capabilities that were not previously possible with conventional techniques. You can find detailed information about ScaleOut Software’s cloud service for real-time digital twins here.
The post Real-Time Digital Twins: A New Approach to Streaming Analytics appeared first on ScaleOut Software.
]]>The post The Power of an In-Memory Data Grid for Hosting Digital Twin Models appeared first on ScaleOut Software.
]]>The secret to the power of the digital twin model is its focus on organizing real-time data by the data source to which it corresponds. What this means is that all event messages from each data source are correlated into a time-ordered collection, which is associated with both dynamic state information and historical knowledge of that data source. This gives the stream-processing application a rich context for analyzing event messages and determining what actions need to be taken in real time.
For example, consider an application which tracks a rental car fleet to look for drivers who are lost or driving recklessly. This application can use the digital twin model to correlate real-time telemetry (e.g., location, speed) for each car in the fleet and combine that with data about the driver’s contract, safety record with the rental car company, and possibly driving history. Instead of just examining the latest incoming events, the application now has much more information instantly available to judge when and whether to signal an alert.
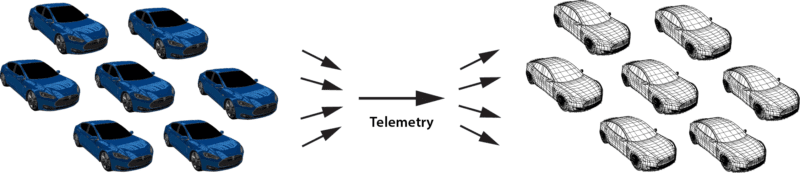
When implementing a stateful stream-processing application using the digital twin model, an object-oriented approach offers obvious leverage in managing the data and event processing associated with this model. For each type of data source, the developer can create a data type (object “class”) which describes the event collection, real-time state data, and analysis code to be executed when a new event message arrives. Instances of this data type then can be created for each unique data source as its digital twin for stream-processing. Here is a depiction of a digital twin object and its associated methods:
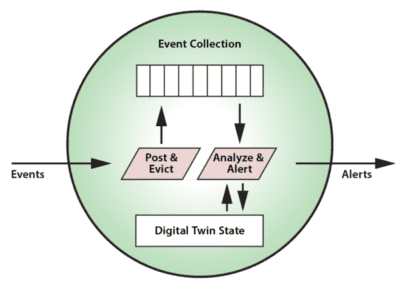
This object-oriented approach makes an in-memory data grid (IMDG) with integrated in-memory computing, (e.g., ScaleOut StreamServer) an excellent stream-processing platform for real-time digital twin models. IMDGs have a long history dating back almost two decades. They were originally created as middleware software to host large populations of fast-changing data objects, such as ecommerce session-state and shopping carts, in memory instead of database servers, thereby speeding up access. An IMDG implements a software-based, key-value store of serialized objects that spans a cluster of commodity servers (or cloud instances). Its architecture provides cost-effective scalability and high availability, while hiding the complexity of distributed in-memory storage from the applications which use them. It also can take full advantage of a cluster’s computing power to run application code within the IMDG — where the data lives — to maximize performance and avoid network bottlenecks.
Using an example from financial services, the following diagram illustrates an application’s logical view of an IMDG as a collection of objects (stock sectors in this case) and its physical implementation as in-memory storage spanning a cluster of servers:
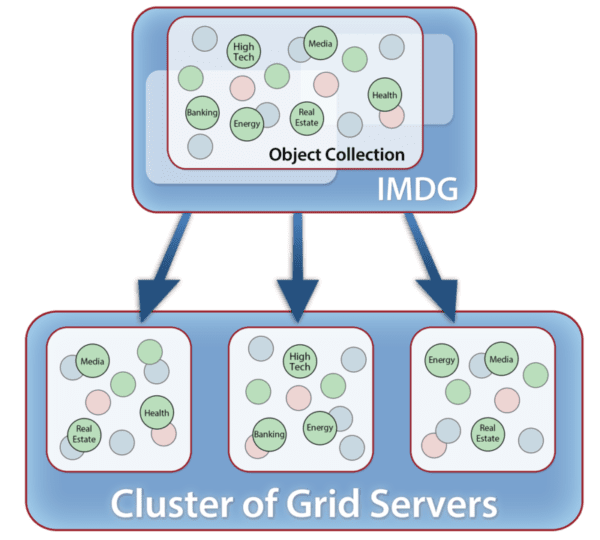
It should now be clear why IMDGs offer a great way to host digital twin models and perform stateful-stream processing. An IMDG can store instances of a digital twin model and scale its storage capacity and event-processing throughput by adding servers to hold many thousands of instances as needed for all the data sources. The grid’s key-value storage model automatically correlates incoming event messages for the corresponding digital twin instance based on the data source’s identifying key. When the grid delivers an event to its digital twin, it then runs the model’s application code for event ingestion, analysis, and alerting in real time.
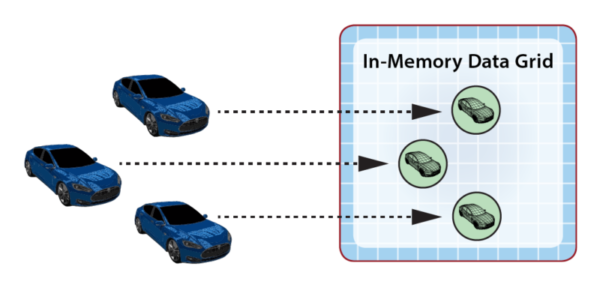
As an example, the following diagram illustrates the use of an IMDG to host digital twin objects for rental cars. The arrows indicate that the IMDG directs events from each car to its corresponding digital twin for event-processing.
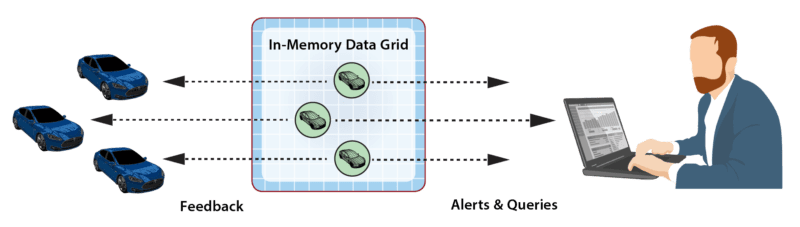
As part of event-processing, digital twins can create alerts for human attention and/or feedback directed at the corresponding data source. In addition, the collection of digital twin objects stored in the IMDG can be queried or analyzed using data-parallel techniques (e.g., MapReduce) to extract important aggregate patterns and trends. For example, the rental car application could alert managers when a driver repeatedly exceeds the speed limit according to criteria specific to the driver’s age and driving history. It also could allow a manager to query the status of a specific car or compute the maximum excessive speeding for all cars in a specified region. These data flows are illustrated in the following diagram:
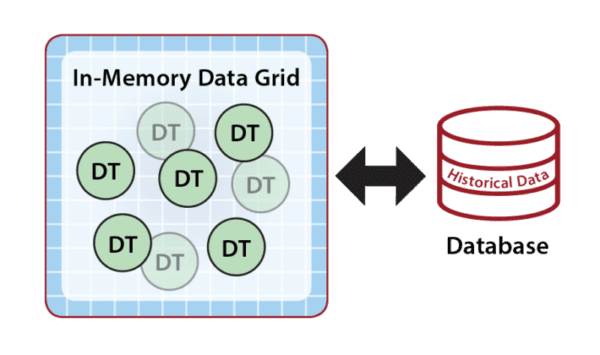
Because they are hosted in memory, digital twin models can react very quickly to incoming events, and the IMDG can scale by adding servers to keep event processing times fast even when the number of instances (objects) and/or event rates become very large. Although the in-memory state of a digital twin is restricted to the event and state data needed for real-time processing, the application can reference historical data from external database servers to broaden its context, as shown below. For example, the rental car application could access driving history only when incoming telemetry indicates a need for it. It also could store past events in a database for archival purposes.
What makes an IMDG an excellent fit for stateful stream-processing is its ability to transparently host both the state information and application code within a fast, highly scalable, in-memory computing platform and then automatically direct incoming events to their respective digital twin instances within the grid for processing. These two key capabilities, namely correlating events by data sources and analyzing these events within the context of the digital twin’s real-time state information, give applications powerful new tools and create an exciting new way to think about stateful stream-processing.
The post The Power of an In-Memory Data Grid for Hosting Digital Twin Models appeared first on ScaleOut Software.
]]>The post Using In-Memory Data Grids for ETL on Streaming Data appeared first on ScaleOut Software.
]]>
Using ETL to Feed the Data Warehouse
A key challenge for any data warehouse is to supply data to it in a format that can be readily ingested and analyzed, and this is the role of the well-known process called “extract-transform-load” (ETL). In the case of Hadoop, this usually means extracting data from external sources and transforming them into a form that can be stored in HDFS for use by MapReduce applications. When incoming data arrives as collections of files, it’s a straightforward matter either to just copy them into HDFS or to periodically run a batch MapReduce application which reads in the files, transforms the data as needed, and outputs it to HDFS.
Consider a company that sends end-of-day reports from its field offices to the data warehouse for aggregate analysis. The data warehouse can start up a MapReduce application after the last report has been uploaded to read from an external file system, reorganize it, and then output the results to HDFS. For example, this application might use the keys output from the mappers to join data for various fields (such as, revenue, volume, etc.) across all offices so that the reducers can output this data to HDFS by field instead of by office.
Implementing ETL using MapReduce offers several advantages. It makes use of the data warehouse’s parallel infrastructure to quickly process the data on a cluster of servers. It also leverages the development team’s skill sets in developing MapReduce applications to minimize overall cost. Lastly, it avoids the need to deploy a variety of technologies, which creates unnecessary complexity and headaches for system administrators.
The Challenge: Real-Time ETL
Running ETL using a batch MapReduce job works fine for static data, such as file-based, end-of-day reports. But what about streaming data that continuously flows into the data warehouse? For example, consider an e-commerce website that accepts orders which flow to the data warehouse for analysis to identify patterns and issues. The website generates a continuous stream of orders which must be stored as HDFS files by an ETL processing step, as illustrated by the following diagram:
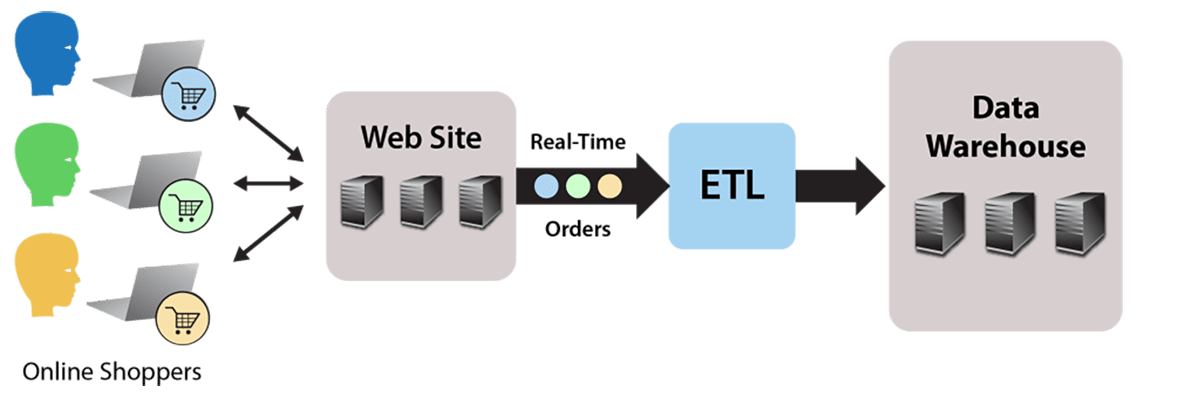
The simplest possible approach to this problem is to store the incoming orders as individual files in HDFS. Of course, this does not allow for any data translation prior to saving the files in the data warehouse. Also, this creates many file I/O operations both when loading HDFS and later when reading large numbers of small files during each analysis.
A better solution would be to run a MapReduce application that reads the input stream and outputs to HDFS. This enables the translation step to reorganize and consolidate the data as necessary and to efficiently output it to HDFS. By using standard MapReduce instead of another stream processing platform, such as Spark or Storm, the skill sets already employed for the data warehouse can be used instead of requiring a different software stack to perform ETL.
However, the data warehouse’s batch-oriented MapReduce execution environment incurs high scheduling latency (typically 15 seconds or longer) that makes it unsuitable for processing an incoming data stream. Furthermore, this MapReduce application would need to run continuously, tying up resources that were intended for data analysis, not ongoing ETL.
The Solution: Offload to an In-Memory Data Grid Running MapReduce
The streaming ETL challenge can be met by deploying an in-memory data grid with an integrated MapReduce engine, such as ScaleOut hServer, to capture the data stream in real time, perform ETL, and offload the data warehouse. Let’s take a look at how this works.
IMDGs host data in memory and distribute it across a cluster of commodity servers. Using an object-oriented data storage model, they provide APIs for storing, accessing, and updating data objects in well under a millisecond (depending on the size of the object). This enables operational systems to use IMDGs for storing fast-changing, “live” data, such as the data warehouse’s incoming order stream.
An IMDG provides an ideal repository for the data stream, buffering orders as objects within the grid and running the ETL application using built-in MapReduce (more on that below). The IMDG matches the arrival rate of the incoming data stream by adding servers as needed to its cluster, ensuring that both storage capacity and update throughput scale linearly while keeping update times fast. Also, the IMDG maintains high availability using data replication so that if a server fails, the IMDG can continue to handle update requests without delay.
Because IMDGs store data in memory distributed across a cluster of servers, they can easily perform data-parallel computations on stored data, such as the ETL function needed by the data warehouse; they simply make use of the cluster’s processing power to analyze data “in place,” that is, without the need to migrate it to other servers. This enables IMDGs to complete ETL fast (possibly in less than a second) with minimal overhead.
Some IMDGs, such as ScaleOut hServer, can execute standard Hadoop MapReduce applications (i.e., applications which are fully code-compatible with Apache Hadoop), allowing these applications to access in-memory data from the grid and output to HDFS. This enables the ETL function to be deployed as a conventional MapReduce application within the IMDG. The application extracts orders from the grid’s memory, transforms them as required for storage in the data warehouse, and then outputs them to HDFS using standard MapReduce techniques, as illustrated in the following diagram:
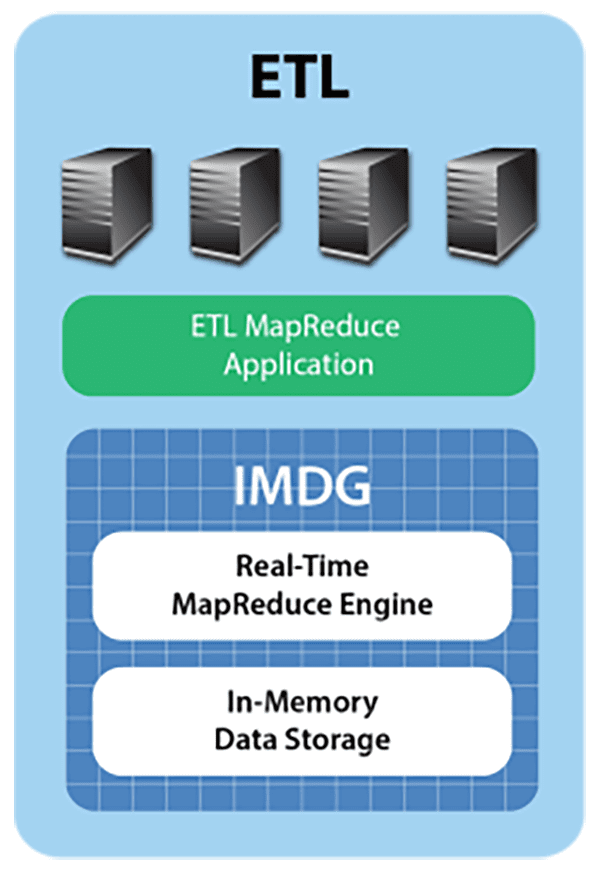
Ensuring Continuous Processing
The use of an IMDG offloads the data warehouse, allowing the MapReduce application performing ETL to run continuously. It also dramatically reduces the latency required to start up each iteration from 15+ seconds to a few milliseconds. Buffering orders in memory while simultaneously migrating them to HDFS ensures that ETL processing seamlessly keeps up with the incoming data stream.
To show how continuous processing can be achieved, the following diagram depicts the use of a “double buffering” strategy to perform ETL processing. IMDGs organize collections of objects within name spaces that can be identified and used as input to a MapReduce application. In this case, while incoming orders are added to one name space, which serves as an input buffer, the MapReduce application extracts orders from a second name space that was previously filled; it then organizes them into an appropriate format and outputs the data to HDFS. Upon completion, the extracted orders are cleared from the associated name space, the name spaces are switched, and the MapReduce application is restarted on the other name space:
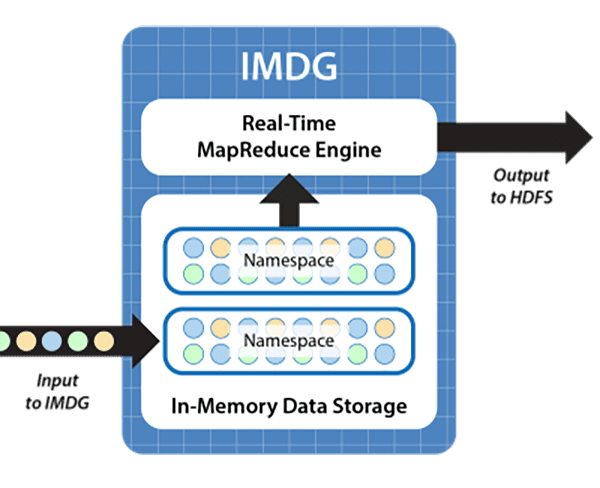
This technique uses the memory of the IMDG to allow orders to flow smoothly into the IMDG while processing by the MapReduce ETL application is ongoing. It requires that sufficient memory be available in the IMDG to buffer incoming order objects during the processing time of the application. Because the IMDG can scale memory capacity by adding servers and because the IMDG fast start-up and data-parallel execution minimize the ETL application’s processing time, continuous processing of incoming orders is ensured.
Summing Up
Hadoop’s powerful analytics capabilities are rapidly making it the centerpiece of next-generation data warehouses. The ability of IMDGs to implement ETL for streaming data enables them to serve as a vital component of these infrastructures. IMDGs which can run MapReduce applications provide the threefold benefits of meeting the low latency requirements for ingesting streaming data, offloading the data warehouse’s execution environment, and leveraging existing Hadoop skills. ETL on streaming data is yet another example of real-time analytics and a prime application for IMDGs.
Perhaps most exciting is that hosting ETL in an IMDG’s real-time analytics engine opens the door to analyzing the order stream (or a clickstream) in real time and generating instant feedback for web users. Over time, the ETL function can evolve to perform real-time analysis, provide guidance, and thereby drive incremental sales. The IMDG’s analytics engine forms a bridge from the data warehouse to customers, helping push the benefits of data analytics to the point of sale where it can have maximum impact.
The post Using In-Memory Data Grids for ETL on Streaming Data appeared first on ScaleOut Software.
]]>The post Transforming Retail with Real-Time Analytics appeared first on ScaleOut Software.
]]>Operational Systems Need In-Memory Data Grids
Operational systems typically manage fast-changing client data that constantly streams in for processing by business logic, which updates existing state information and initiates appropriate responses. Some responses provide feedback to clients and others commit changes to persistent storage. For example, an e-commerce system receives requests to view products from web browsers, displays requested products and offers, and sends requested information back to clients. It also receives orders from clients, which it commits to permanent storage, and then it sends out messages to other systems to process these orders.
In-memory data grids (IMDGs) have been used for several years within operational systems to ensure fast responses and to scale throughput as workloads grow. In-memory data grids enable the execution of business logic to scale out across a cluster of servers while holding fast-changing application state in memory accessible to all servers. Memory-based data storage helps minimize response times, and servers can add CPU capacity to handle incremental growth in the workload.
For example, an in-memory data grid can hold session state and shopping carts for an e-commerce web farm, enabling all web servers to quickly and seamlessly access this data as they handle incoming browser requests (which are distributed by an IP load-balancer to web servers):
In-Memory Computing: The Engine of Real-Time Analytics
The next step for operational systems is to add real-time analytics, and the easiest way to insert real-time analytics into an operational system is to integrate it with the system’s business logic using an IMDG. By adding real-time analytics to an in-memory data grid, it becomes instantly available to analyze fast-changing data flowing through the system and produce immediate results:
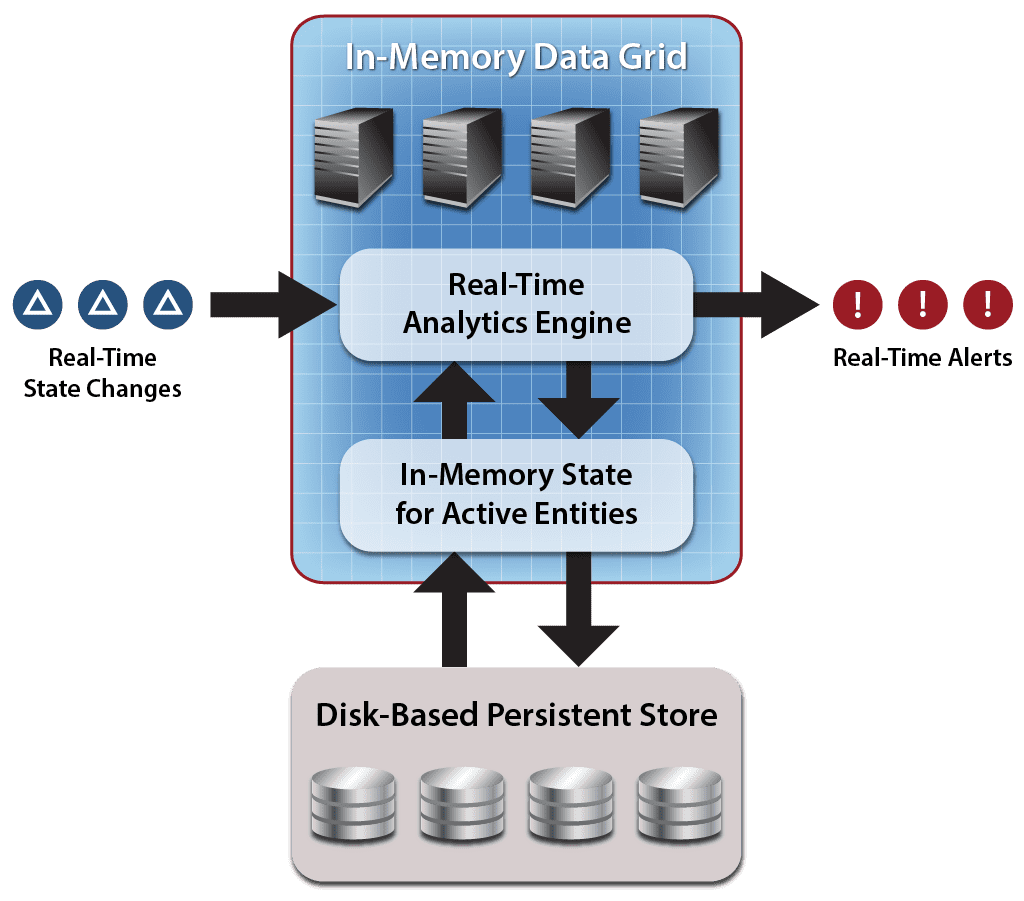
As we have explored in previous blogs, the key to fast response times for real-time analytics is data-parallel programming, that is, examining many data items in parallel using a single algorithm. This approach has two major strengths: (a) it enables the algorithm to be distributed across the grid’s cluster of servers for fast execution, and (b) it avoids moving data between servers for processing. The net result is that large, memory-based data sets can be quickly analyzed to generate timely responses.
Some IMDGs, such as ScaleOut Analytics Server, offer an integrated real-time analytics engine that automatically ships analytics code to all grid servers and then executes the code in parallel on a specified collection of data stored within the IMDG. This simplifies the task of embedding real-time analytics within an operational system and ensures high performance.
Real-time analytics also can be constructed using the Hadoop MapReduce programming model, which offers a very popular data-parallel design pattern. ScaleOut hServer hosts Hadoop MapReduce applications using its real-time analytics engine and eliminates the overheads of task scheduling and data motion usually associated with Hadoop, thereby opening the door to using MapReduce in operational systems.
Adding Real-Time Analytics to an E-Commerce System
Let’s look at how real-time analytics can be integrated into an e-commerce system. In addition to sending basic page requests to the system from clients browsing a website, the browser also can be instrumented to send detailed information about which products customers are examining and the time they are spending on each product. Combining all of this information, the system can build a history of site usage for each customer and collect a set of preferences for that customer. To support a large population of customers, customer information can be persisted in a database or NoSQL store and then brought into the IMDG when the customer starts browsing.
As illustrated in the following diagram, real-time analytics can continuously examine all active customers in parallel to identify special offers that are appropriate for the customer based on a combination of his/her preferences, shopping history, and current browsing behavior. By analyzing access patterns, the site also can determine if a customer is having difficulty finding products or services and suggest remedies. Inactive customers can be flagged and sent emails to remind them to complete purchases in their shopping carts. In addition, common patterns across customers can be identified and used to steer strategic decisions influenced by buying trends.
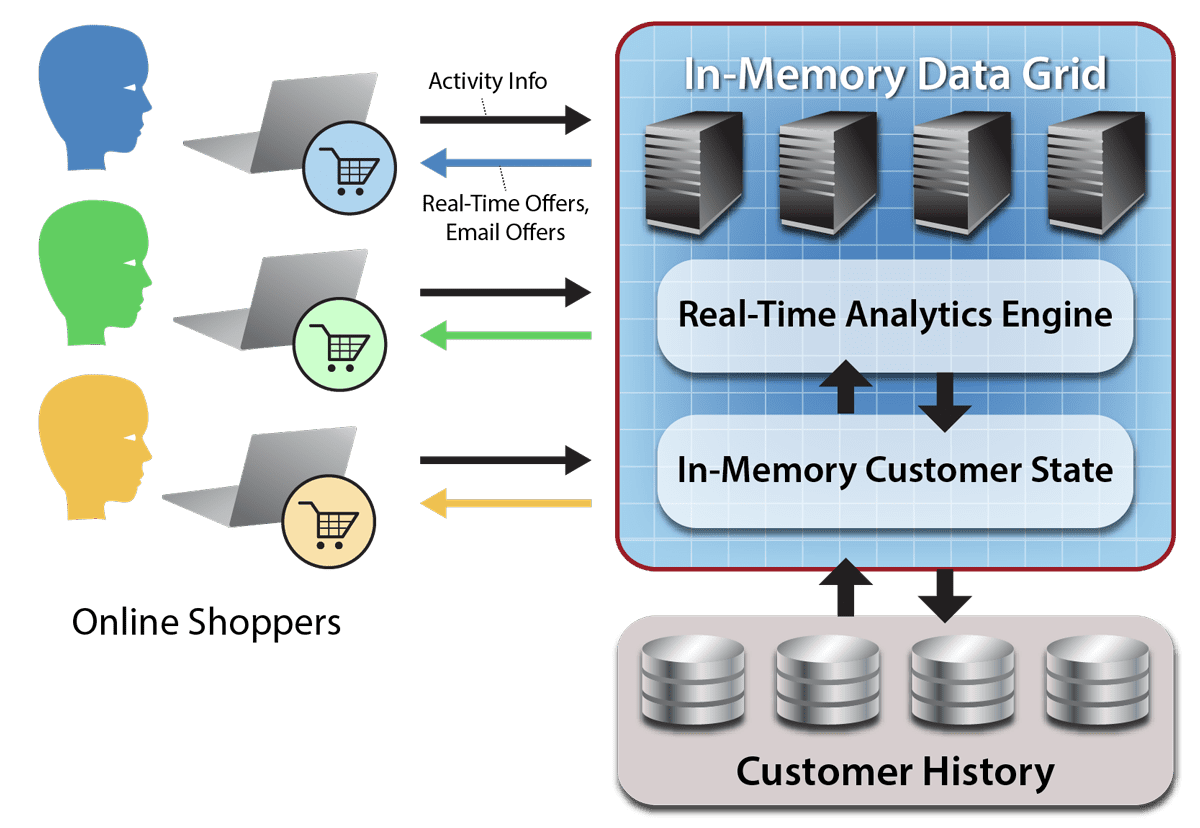
Using Real-Time Analytics in a Brick and Mortar Retail Store
As e-commerce has gained increasing dominance with the shopping public, brick and mortar stores have responded by personalizing the shopping experience. High end retailers are now beginning to send real-time information from the point of sale to back-office servers for analysis in order to provide immediate feedback to sales staff. This enables the retailer to dramatically enhance the shopping experience.
For example, opt-in customers can identify themselves to sales staff on arrival so that their preferences and history can be used to help suggest products of interest. Products can be tracked with RFID tags to alert the sales staff when an active customer’s size is not present on the sales floor and must be retrieved from the stockroom (preferably before the customer requests it). These tags also can identify which products are being taken from the shelves or racks so that buying trends can be tracked. This also helps the store determine which products are repeatedly left in the changing rooms and not purchased, increasing the store’s buying power with the manufacturer. These are some of the many potential uses for real-time analytics in brick and mortar retail.
As the following diagram illustrates, IMDGs with integrated real-time analytics provide a fast and highly scalable platform for hosting customer information and analytics algorithms used by brick and mortar stores. Streams of information regarding customer activity and product motion can be fed to an IMDG to update in-memory state information for customers and products. Using data-parallel execution, analytics algorithms can continuously analyze this in-memory state and generate alerts for the sales staff which are delivered to point of sale terminals or tablets.
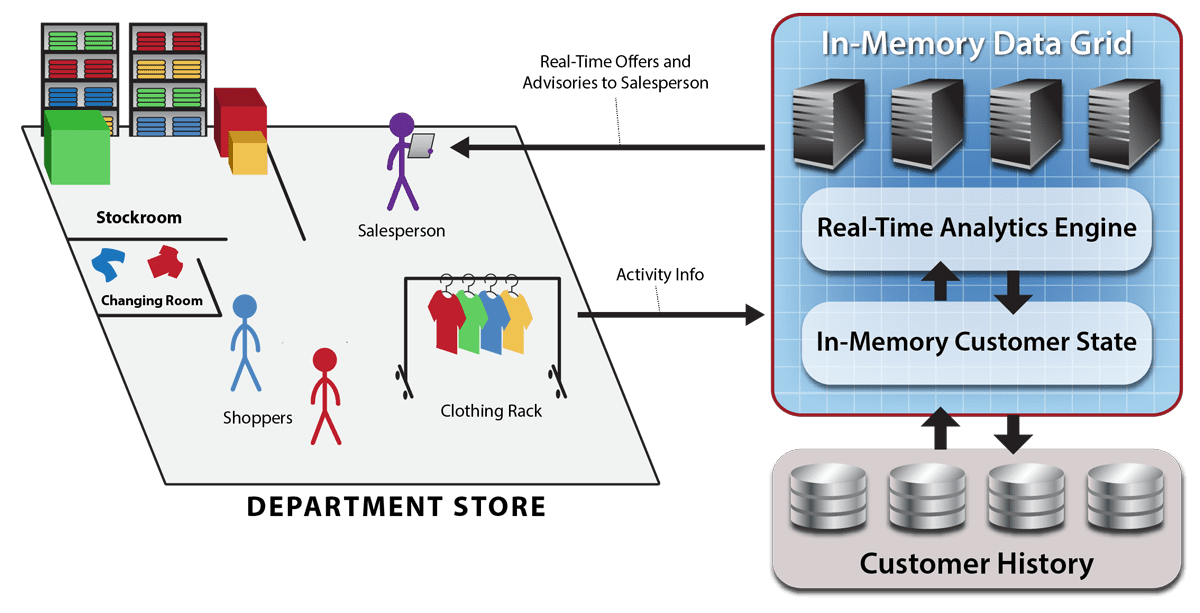
Summing Up
These examples show the power of real-time analytics to enhance operational systems which manage retail purchases, whether online or in brick and mortar stores. By hosting real-time analytics within an IMDG, these systems easily can host customer and product information which is repeatedly updated by streams of activity data. Unlike pure streaming systems, IMDGs can integrate these two types of information to provide a more complete picture of customer activity, leading to a deeper understanding of behavior, preferences, and customer needs. Lastly, IMDGs which host data-parallel analytics algorithms can deliver fast results, avoiding the batch processing overheads of conventional analytics systems, while ensuring scalable performance to handle growing workloads.
The post Transforming Retail with Real-Time Analytics appeared first on ScaleOut Software.
]]>The post Creating Data-Parallel Computations for Real-Time Analytics appeared first on ScaleOut Software.
]]>The Starting Point: Domain Decomposition
Going back to the 1980s, application developers realized that determining how to partition data so that each portion can be analyzed in parallel, a technique often called “domain decomposition,” is the fundamental design decision in data-parallel programming. Once this is accomplished, the domain can be parceled out among the servers within a computational cluster, and the analysis can proceed in parallel on all servers. The cluster speeds up the computation and also allows more servers to be added as the workload (i.e., the domain) grows in size.
The key to domain decomposition is determining which data within the state of an application to use as the domain for parallel analysis. In many cases, the domain is easy to identify, especially when the application is analyzing a physical entity. For example, in an earlier blog we saw how a climate simulation divides the atmosphere, land, and ocean into a grid of boxes which are analyzed independently at each time interval. Likewise, structural mechanics and fluid dynamics typically use grids that model physical systems.
The process of domain decomposition can be more challenging for applications whose data sets can be partitioned in different ways. Consider the hedge fund example above. Do we analyze the data by partitioning the stock symbols across the servers and then analyzing all strategies which hold a given stock? Alternatively, should we partition the strategies and analyze all positions within the strategy? Is there still another domain decomposition?
Minimize Data Motion: An Example in Financial Services
The best approach to choose usually is dictated by the need to minimize data motion. If a given decomposition induces data motion at each analysis step, this can kill performance while saturating the network. For example, if the hedge fund analysis partitions stock symbols, it would need to query all strategies affected by the stock symbol to obtain information needed to perform the analysis, and this requires substantial data motion for each stock symbol. (This assumes that the strategies as well as the stock symbols – and, in general, all data sets – are distributed across the cluster of servers performing the data-parallel computation, as is the case for data sets stored within an in-memory data grid (IMDG).
Instead, the computation could partition the strategies across the servers and analyze all strategies in parallel. In this case, it would need to query the latest stock prices for all positions within each strategy; this also induces data motion. In either case, if the strategies and stock prices are stored in separate data sets, unacceptable data motion will be incurred by the data-parallel computation.
However, if the stock prices for all relevant positions are kept up to date within the strategies instead of storing this data elsewhere, no data motion is needed to perform the data-parallel analysis, and maximum performance is achieved. Bearing in mind that multiple strategies maintain positions in a given stock, how can we efficiently update the strategies as price changes flow in from a market feed? The answer lies in leveraging data-parallel computation to both analyze and update the strategies. We can distribute a snapshot of price changes to all strategies at the start of each analysis and use this information to update each strategy’s positions prior to performing the analysis. This easily can be accomplished by tracking all price changes since the last analysis step and efficiently distributing them to the servers as part of the invocation mechanism for the analysis.
The following diagram illustrates how an IMDG can host a set of strategies and perform parallel analysis on the strategies while updating them with a live market feed containing snapshots of price changes. The analysis produces a stream of alerts to the trader (or to an automated trading system) for strategies that need rebalancing. In ScaleOut Analytics Server, the data parallel analysis can be implemented using a feature called parallel method invocation (PMI):
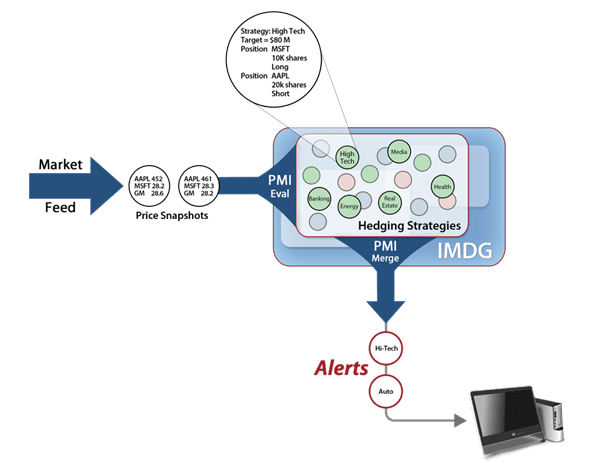
The net effect is that the hedge fund in real time can update its strategies and obtain alerts regarding positions that require rebalancing based on current market conditions. Take a look at this demo of a proof of concept implementation for 2K strategies tracking and analyzing a total of 40K positions using a cluster of four servers. This demo was implemented using a real-time Hadoop MapReduce engine implemented within ScaleOut hServer and delivered alerts within about 330 milliseconds (instead of more than 15 seconds for standard Hadoop).
Another Example: Inventory Reconciliation in E-Commerce
Consider another example of an e-commerce application that needs to reconcile orders and inventory in real time to avoid a shortfall in inventory. Orders flow into the system for a set of products (“SKUs”), and inventory changes flow into the system from several sources: orders to outside vendors are placed, products arrive at the warehouse, orders from customers are filled, defects are detected, etc. Especially with perishable goods, it’s vital to precisely track order commitments so that orders can be accurately filled (and customers stay happy).
Several different domain decompositions for reconciling orders to inventory could be used. Do we partition based on the orders, the inventory changes, or on some other basis? If we reconcile based on pending orders, we have to query the inventory changes for all items within each order, inducing substantial, performance-killing data motion. Likewise, if we partition the inventory changes, we have to query all orders that include a given inventory item, again inducing data motion.
To solve this problem, we can collect pending orders and inventory changes within their common SKUs and then use the SKUs to form a domain decomposition. As orders come into the system, we update the SKUs for all items within each order to track those orders. Likewise, as inventory changes flow in, we update the SKUs to maintain the latest inventory updates. This continuous process updates the SKUs on a real-time basis in a manner analogous to an ongoing database join operation. Now, a data-parallel analysis of the SKUs can reconcile all relevant orders and inventory changes for that SKU without causing data motion. This enables the cluster to perform a reconciliation across all SKUs in seconds instead of minutes.
The following diagram illustrates an IMDG hosting a collection of data representing SKUs that are being updated by incoming orders and inventory changes. The IMDG performs data-parallel reconciliation (“Eval”) of the SKUs and combines the results (“Merge”) while operations are ongoing:
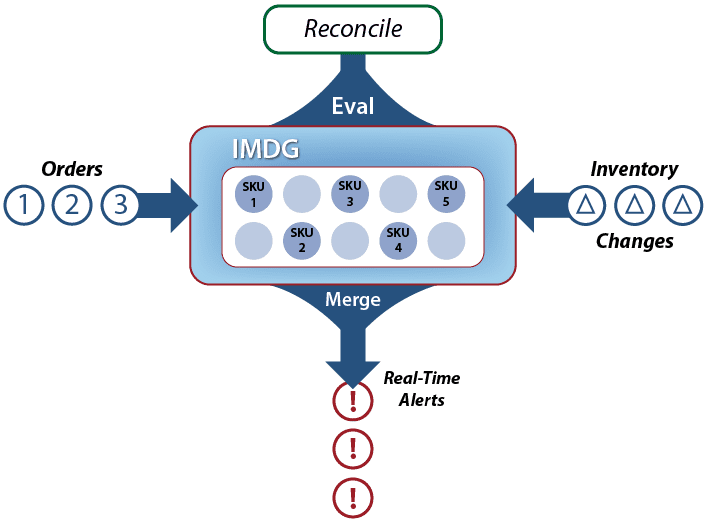
Note that in this example, we do not use the data-parallel invocation mechanism to perform updates to the application’s state as we did with the hedge fund example. Instead, individual order and inventory updates flow into the application on a continuous basis, and the data-parallel analysis is performed on the state information as it changes. In both cases, the integration of data-parallel analysis within an operational system handling live data demonstrates the value of real-time analytics: analysis results are continuously generated and fed back to the system to optimize its ongoing operations.
Using an IMDG to Host a Data-Parallel Application
Lastly, note that an IMDG serves as an ideal host for both the application’s state and the data-parallel analysis. By storing data in memory and distributing it across a cluster of servers, it can keep up with continuous updates and scale to handle growing workloads (while maintaining high availability) just by adding servers. And it can perform data-parallel analysis on domains of data distributed across the servers, leveraging the IMDG’s automatic load-balancing and avoiding data motion across the network during the analysis.
Interestingly, the object-oriented programming model supported by IMDGs helps us to structure, distribute, identify, query, and analyze domains that we construct for real time analysis. We will explore that in an upcoming blog.
The post Creating Data-Parallel Computations for Real-Time Analytics appeared first on ScaleOut Software.
]]>