The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>
ScaleOut Software is excited to announce the release of ScaleOut In-Memory Database , which offers a new, highly scalable, clustered server platform for running Redis commands. This platform uses ScaleOut’s patented, quorum-based clustering technology to replace open-source Redis’s cluster implementation. It fully automates Redis cluster management while preserving the use of open-source Redis code to process commands. In doing so, ScaleOut In-Memory Database lets enterprise Redis users manage server clusters with much greater ease and lower both their acquisition and management costs (TCO) — while preserving a native execution environment for Redis applications. ScaleOut In-Memory Database runs on both Linux and Windows systems.
, which offers a new, highly scalable, clustered server platform for running Redis commands. This platform uses ScaleOut’s patented, quorum-based clustering technology to replace open-source Redis’s cluster implementation. It fully automates Redis cluster management while preserving the use of open-source Redis code to process commands. In doing so, ScaleOut In-Memory Database lets enterprise Redis users manage server clusters with much greater ease and lower both their acquisition and management costs (TCO) — while preserving a native execution environment for Redis applications. ScaleOut In-Memory Database runs on both Linux and Windows systems.
What sets ScaleOut’s cluster architecture apart
When ScaleOut Software first developed its clustering technology for scalable in-memory data storage in 2003, we had to tackle several technical challenges. We needed to:
- implement a scalable cluster membership,
- partition the in-memory data store across multiple servers,
- replicate updates with zero data loss (i.e., avoid eventual consistency), and
- maximize throughput with multi-threading on multicore servers.
We also realized that it was important not to expose all these complexities to users. The cluster had to be easy to manage, making a simple learning curve for system administrators. It was also vital to have a straightforward view of the data store for applications (that is, maintain location transparency and full consistency) so developers could target it easily.
Automated clustering
Our clustering architecture has many leading-edge automated clustering features. These include the ability to:
- self-organize multiple servers into a cluster,
- automatically partition data and distribute it across the cluster,
- load-balance stored data as servers are added or removed,
- automatically create and maintain replicas,
- detect server and network failures,
- recover from failures by promoting replicas to replace failed primary partitions, and
- “self-heal” by creating new replicas to replace lost ones.
Stability and consistency
The server cluster uses peer-to-peer algorithms to avoid single points of failure. Running on one or more servers, it maintains availability to applications even if all but one server fails. It uses a patented quorum algorithm to implement full (strong) consistency when updating stored data across multiple servers. Lastly, it executes multiple requests at once using a multi-threaded architecture.
Industry-leading ease of use
ScaleOut’s cluster architecture does all this without showing its inner workings to developers or system administrators. Developers see a single, reliable data store that happens to be distributed across multiple servers. System administrators see a set of servers on a single network subnet, each running a single service process.
Once the service is configured to select a specific subnet (if multiple NICs are in use), it joins the cluster with one click and is ready to take on its share of the workload. Building a server cluster is just a matter of adding servers (called “nodes” in Redis documentation):
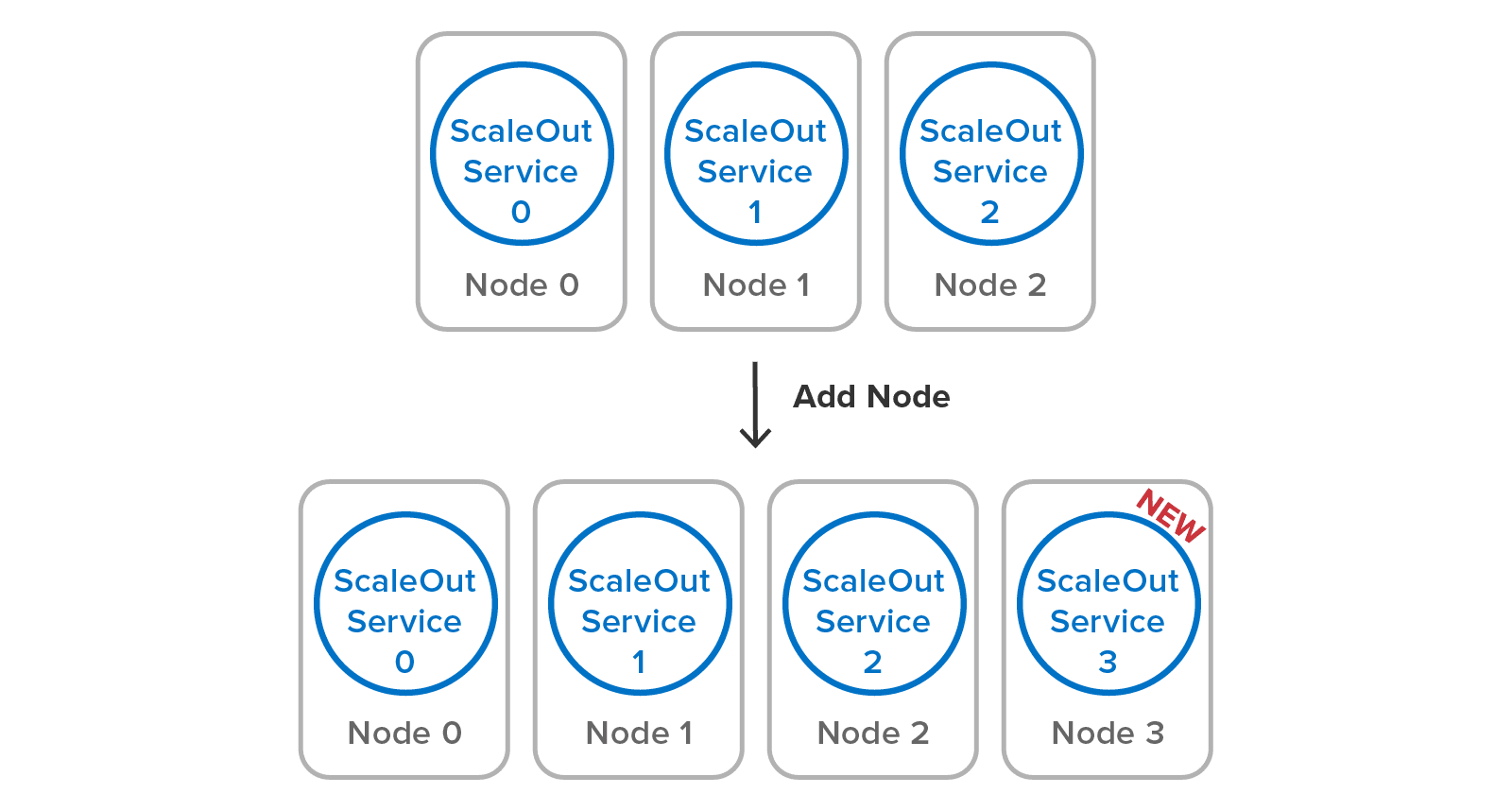 All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
All this automation minimizes the workload for system administrators, lowering costs and increasing uptime. Administrators are unaware of the cluster’s data partitioning mechanism and replica placement. They don’t need to intervene to recover and heal the data store if a server fails or becomes isolated. They also don’t need to spin up multiple service processes per node to extract more throughput from multicore servers.
Enter Redis
Open-source Redis was first created in 2009 for use on a single server, with clustering added in 2015. It has gained widespread popularity because of its rich set of data structures and commands. At the enterprise level, it has seen fast-growing adoption across many applications. As a result, the need to streamline cluster management procedures and increase data reliability for Redis users has become more urgent.
Introducing automated Redis clustering with ScaleOut In-Memory Database
We created ScaleOut In-Memory Database to meet this need. This product integrates open-source Redis code (version 6.2.5) that implements all the popular Redis data structures (strings, lists, sets, hashes, streams, and more) into ScaleOut’s automated cluster architecture and execution platform. Now, system administrators don’t need to manage Redis concepts like hashslots and shards. Instead, ScaleOut takes over these tasks using its built-in, fully automated mechanisms. Automated recovery and self-healing eliminate the need for manual intervention and increase uptime. What’s more, ScaleOut’s quorum-based updates replace Redis’s eventual consistency mechanism to deliver reliable data storage across servers. Applications can depend on the server cluster to survive a server failure without data loss, and the cluster remains available even if multiple servers fail.
To boost throughput and automatically make full use of all available processing cores, ScaleOut In-Memory Database integrates Redis command execution with its multi-threaded processing of client requests. Achieving this meant eliminating Redis’s native, single-threaded event-loop execution model without introducing a global lock that would constrain performance. The result is that each server in the cluster can run Redis commands simultaneously on all processing cores using a single service process.
Power with simplicity
We designed ScaleOut’s peer-to-peer cluster architecture to serve as the foundation for all user services. Hence, functions like clearing the database and backup/restore were built from the outset to run in parallel across all servers. This approach reduces the system administrator’s workload and delivers fast performance. To give Redis users the benefit of a fully parallel architecture, ScaleOut In-Memory Database provides a cluster-wide implementation of many Redis commands, such as PUBLISH and FLUSHALL.
ScaleOut In-Memory Database also overcomes the single-server limitation of the Redis SAVE command. It provides a cluster-wide implementation of backup/restore using its built-in parallel backup/restore utility. This allows system administrators to backup all Redis objects with one click in ScaleOut’s management console, and it delivers parallel speedup by running simultaneously on all servers. The user can backup either to local disks:
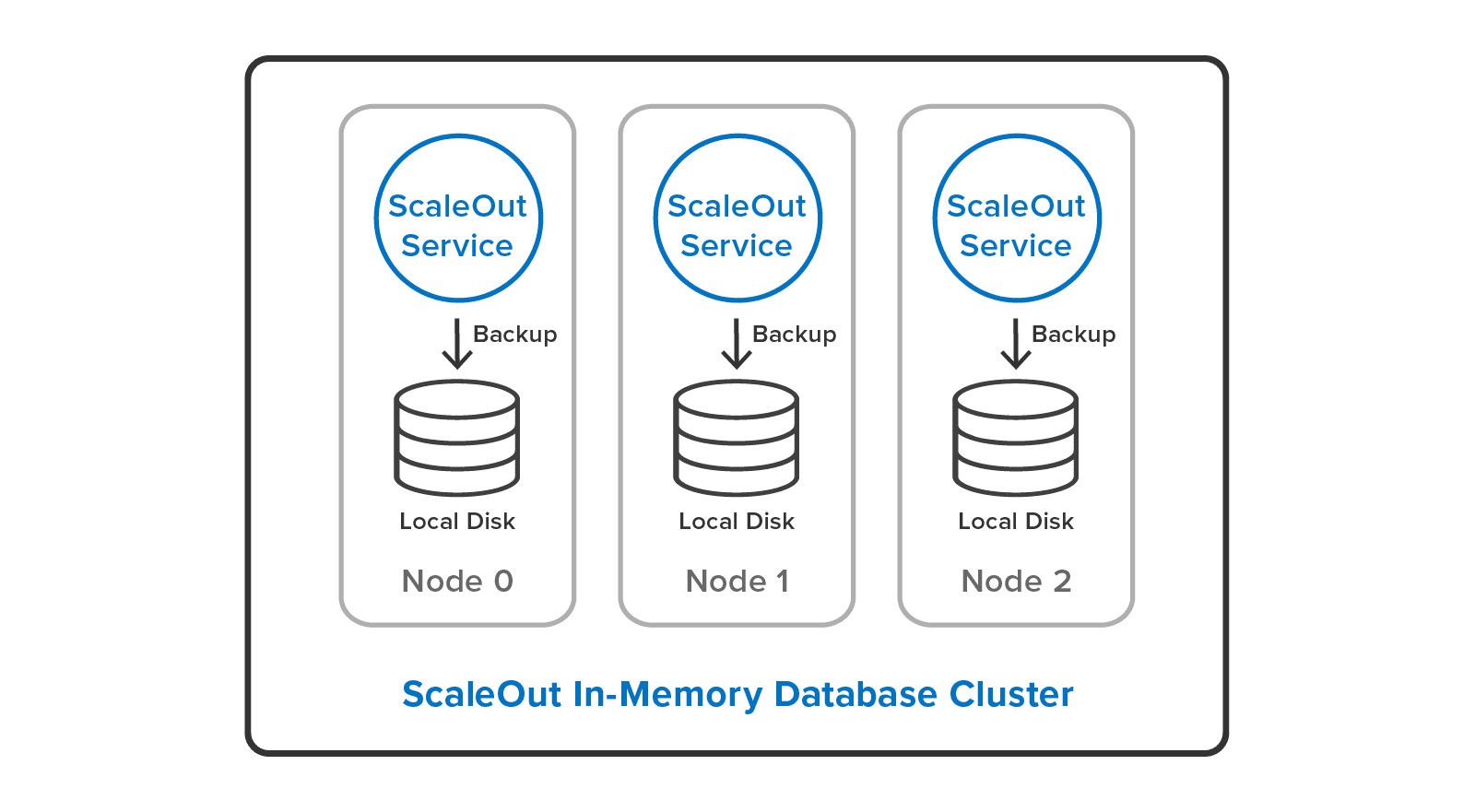
or to a single, shared disk:
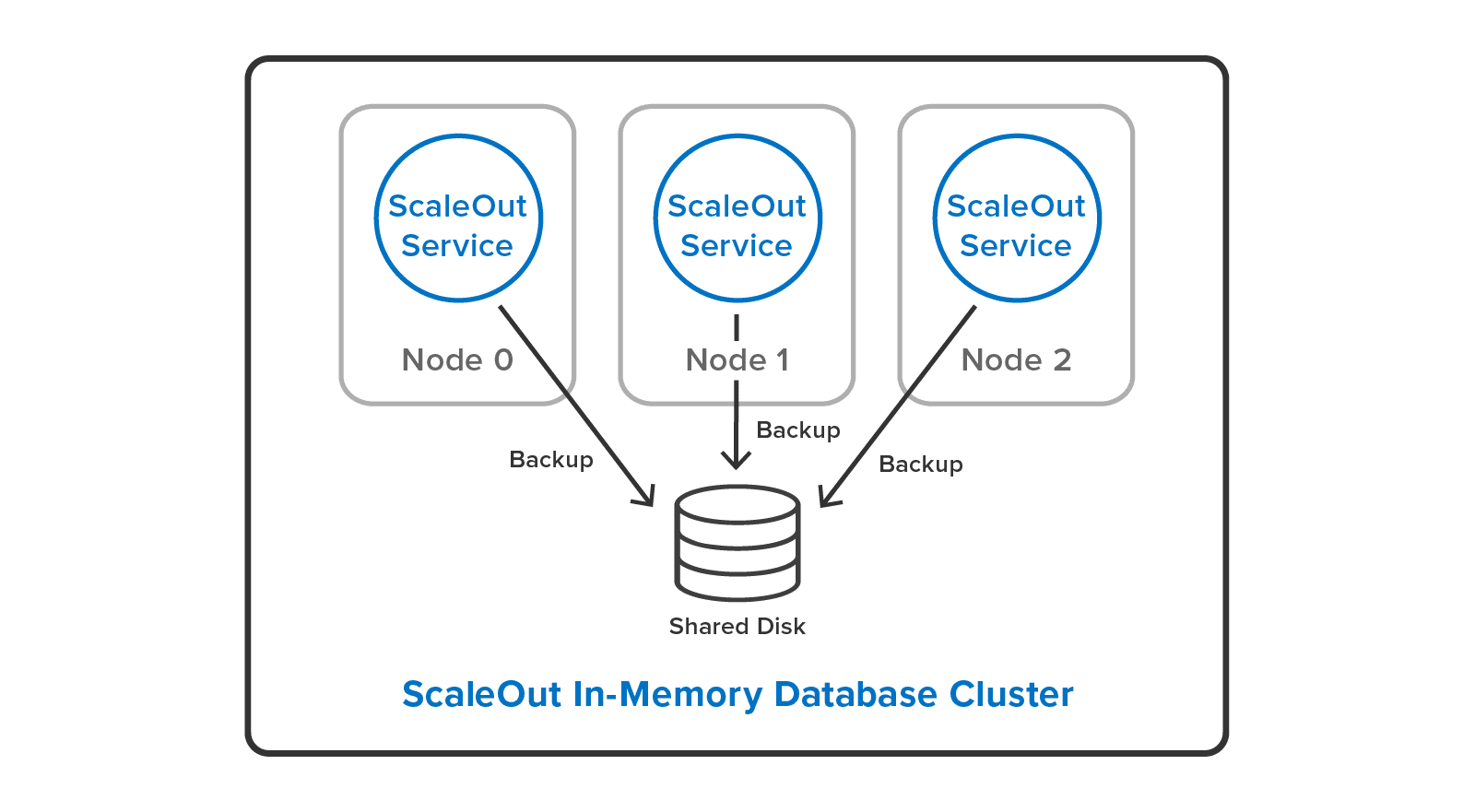
System administrators can cut down their workload by restoring backup files to a different cluster configuration than they used to make the backup. For example, it’s possible to restore a backup from a three-server cluster to a two-server cluster with a different hashslot mapping:
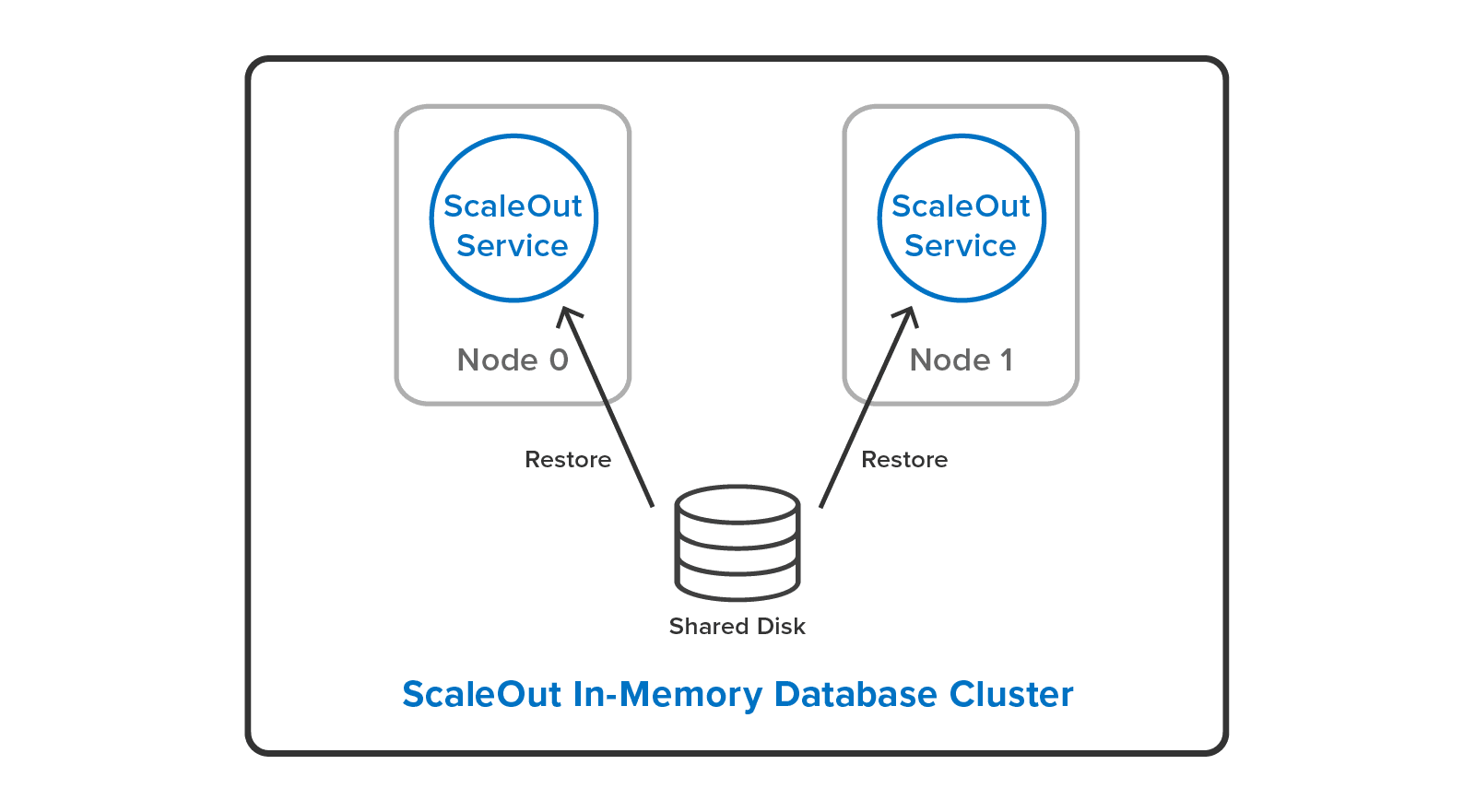
There’s a lot more in the new ScaleOut In-Memory Database than there’s room to discuss in depth here. For example, ScaleOut’s cluster stalls Redis command execution automatically when it moves hashslots between nodes for load-balancing, or when it performs recovery. This means clients always have a consistent view of the cluster. Also, the cluster stores Redis objects in their own ScaleOut namespace side-by-side with objects that ScaleOut’s native APIs manage. This lets users access the full power of ScaleOut’s in-memory computing features, including cluster-wide, data-parallel operations and stream processing with digital twins.
Summing Up
ScaleOut In-Memory Database makes scalable processing more convenient, reliable, and cost-effective for enterprise Redis users than ever before. By automating Redis cluster management, improving data reliability, and adding multi-threaded command execution, this product can significantly drive down the total cost of ownership for Redis deployments, even in comparison to commercial Redis alternatives. We invite you to check it out and see how it performs for you. We’d love to hear your feedback.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Announcing ScaleOut In-Memory Database: Automated Clustering for Redis Users appeared first on ScaleOut Software.
]]>The post Introducing A New Execution Platform for Redis Clients appeared first on ScaleOut Software.
]]>
The Challenge
Redis®* offers a compelling set of data structures that enhance the capabilities of a distributed cache beyond just storing serialized objects. Created in 2009 as a single-server store to assist in the design of a web server, Redis gives applications numerous useful options for organizing stored data, including sets, lists, and hashes. Cluster support was added later, and it introduced specialized concepts, like hashslots and master/replica shards, that system administrators must understand and manage. Along with its use of eventual consistency, this has created complexity that makes cluster management challenging while reducing flexibility in configurations.
In contrast, ScaleOut StateServer®, a distributed cache for serialized objects and first released in 2005, was designed from the ground up to run on a server cluster with automated load-balancing, data replication, and recovery while storing data with full consistency (i.e., sequential consistency) across replicas. It also executes client requests using all available processing cores for maximum throughput. These features dramatically simplify cluster management, especially for enterprise users, improve flexibility, and lower TCO. For example, unlike Redis, ScaleOut server clusters can seamlessly grow from a single to multiple servers, and system administrators do not need to manage hashslots or master/replica shards. See a recent blog post that discusses how ScaleOut StateServer simplifies cluster management in comparison to Redis.
ScaleOut Software recognized that running Redis commands on a ScaleOut StateServer cluster would offer Redis users the best of both worlds: familiar and rich data structures combined with significantly simpler cluster management and full data consistency. However, the ideal implementation would need to use Redis open-source code to execute Redis commands so that client commands would behave identically to open-source Redis clusters. The challenge is then to integrate Redis code into ScaleOut StateServer’s execution platform and take advantage of ScaleOut’s highly automated clustering features while eliminating the single-threaded constraints of Redis’s event-loop architecture.
Integrating Redis into ScaleOut StateServer
Released as a community preview, version 5.11 of ScaleOut StateServer introduces support for the most popular Redis data structures (strings, sets, lists, hashes, and sorted sets) plus publish/subscribe commands, transactions, and various utility commands (such as FLUSHDB and EXPIRE). Both Windows and Linux versions are available. This release uses open-source Redis version 6.2.5 to process Redis commands.
Redis clients connect to any ScaleOut StateServer server in a cluster using the standard RESP protocol. (A cluster can contain one or more servers.) Client libraries internally obtain the mapping of hashslots to servers using either the CLUSTER SLOTS or CLUSTER NODES commands and then direct Redis access requests to the appropriate ScaleOut server. To maximize throughput, each ScaleOut server processes incoming Redis commands on multiple threads using all available processor cores; there is no need to deploy multiple shards on each server for this purpose.
The following diagram shows a set of Redis clients connecting to a ScaleOut StateServer cluster. Note that the complexities of hashslots and shards have been eliminated:
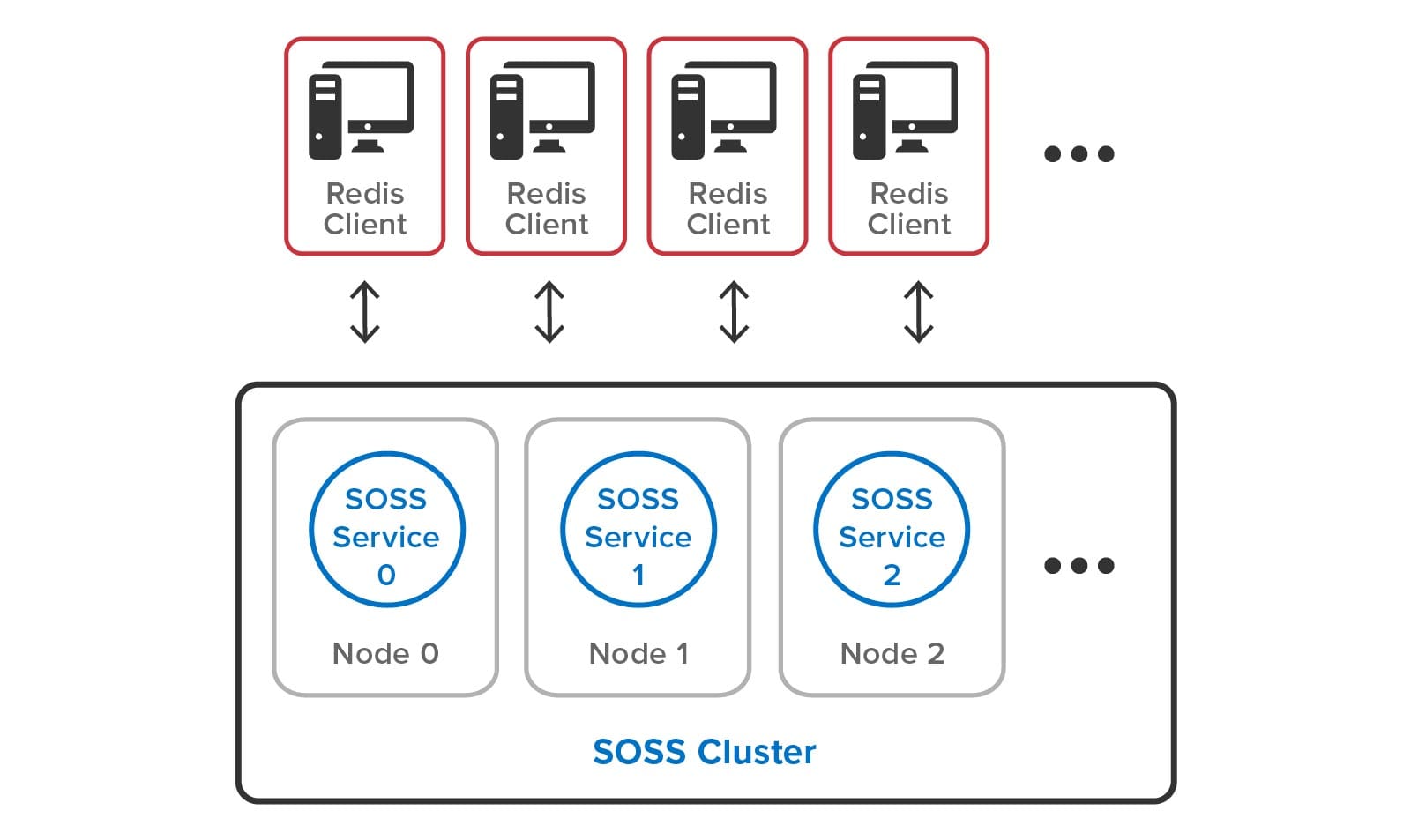
As the need for additional throughput grows, system administrators can simply join new servers to the cluster. ScaleOut StateServer automatically rebalances the hashslots across the cluster as servers are added or removed. It also delays execution of Redis commands during load-balancing (and recovery) to give clients a consistent picture of hashslot placement and avoid client exceptions. After a hashslot has fully migrated to a remote server, a requesting client is returned the Redis -MOVED indication so that it can redirect its request to the new server.
The following diagram illustrates how ScaleOut StateServer automatically manages hashslots. In this example, it migrates half of the hashslots to a second server that joins a cluster:
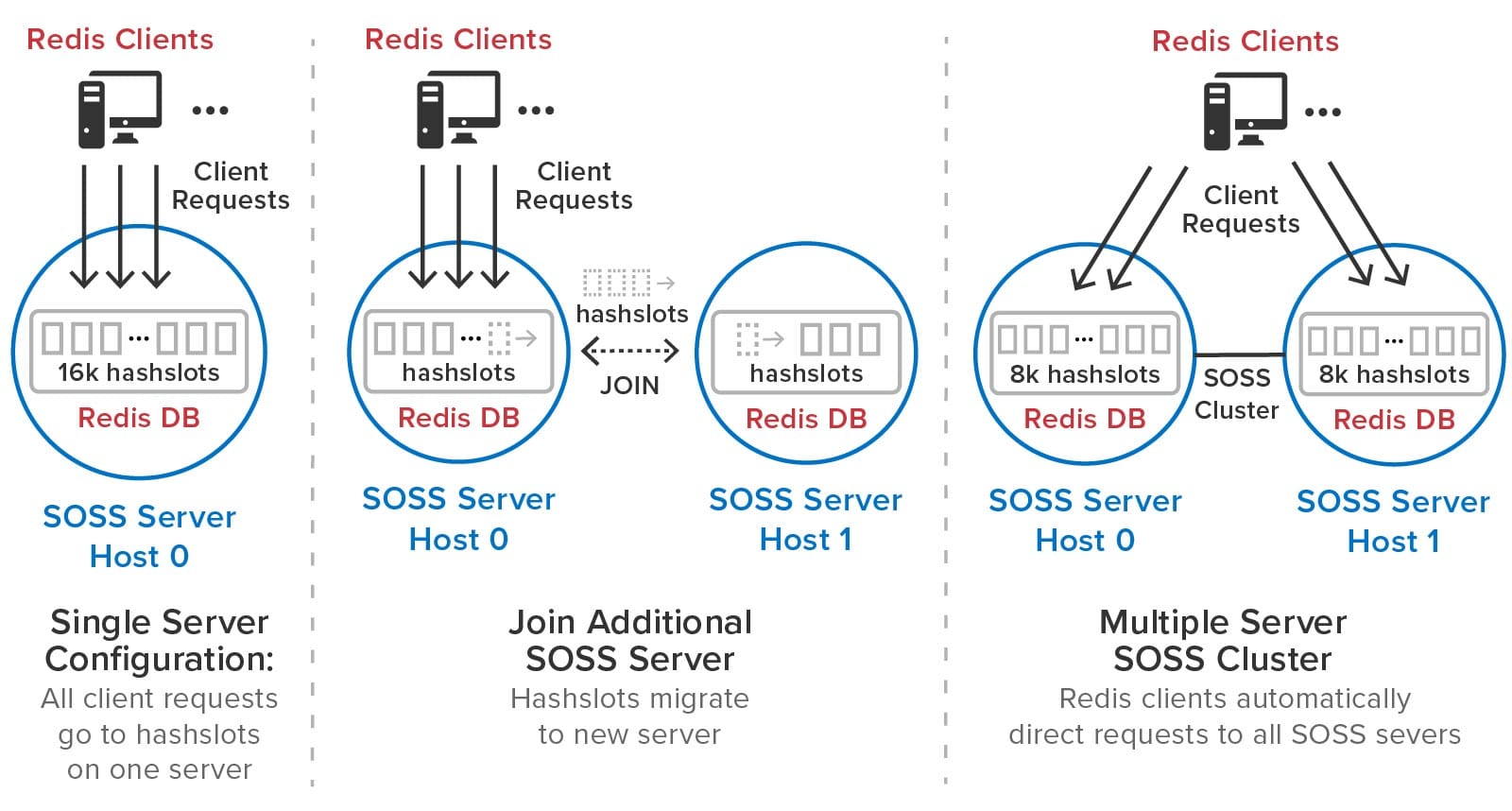
ScaleOut StateServer automatically creates replicas for all hashslots. There is no need for system administrators to manually create master and replica shards or move them from server to server during membership changes and recovery. ScaleOut StateServer automatically places replicas on different servers from their corresponding primary hashslots and migrates them as necessary during membership changes to ensure optimal load-balancing. If a server fails or has a network outage, ScaleOut StateServer automatically “self-heals” by promoting replicas to primaries and creating new replicas as necessary.
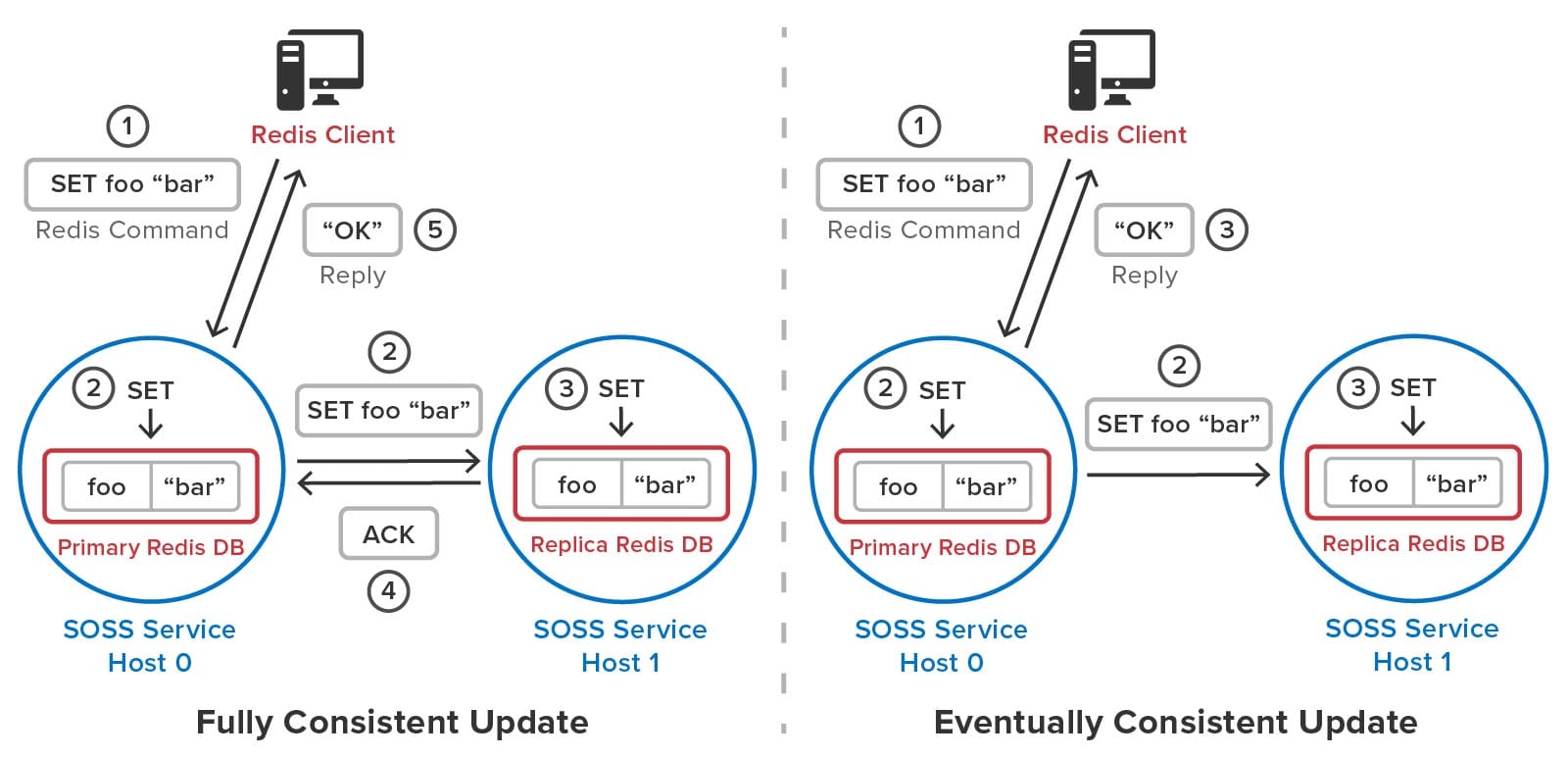
To avoid serving stale data to clients after recovery from an outage, ScaleOut StateServer uses a patented quorum algorithm to implement fully consistent updates to stored objects. In contrast, Redis uses an eventual consistency model for updating replicas. (To maximize throughput at the expense of data consistency, ScaleOut StateServer can optionally be configured for eventual consistency.) When a server receives a Redis command, it executes this command on a quorum containing the primary hashslot and replicas (one or two in the current implementation) prior to returning to the client. Transactions are processed in the same manner.
The following diagram compares the full and eventually consistent models for updating replicas and shows how they differ in behavior. A fully consistent update waits for the replica to be updated prior to returning to the client, whereas an eventually consistent update does not. If a primary server should fail prior to committing the replica’s update, the cluster could lose the update and serve stale data to clients.
Implementation Details
The following diagram shows how Redis open-source code has been integrated into ScaleOut StateServer:
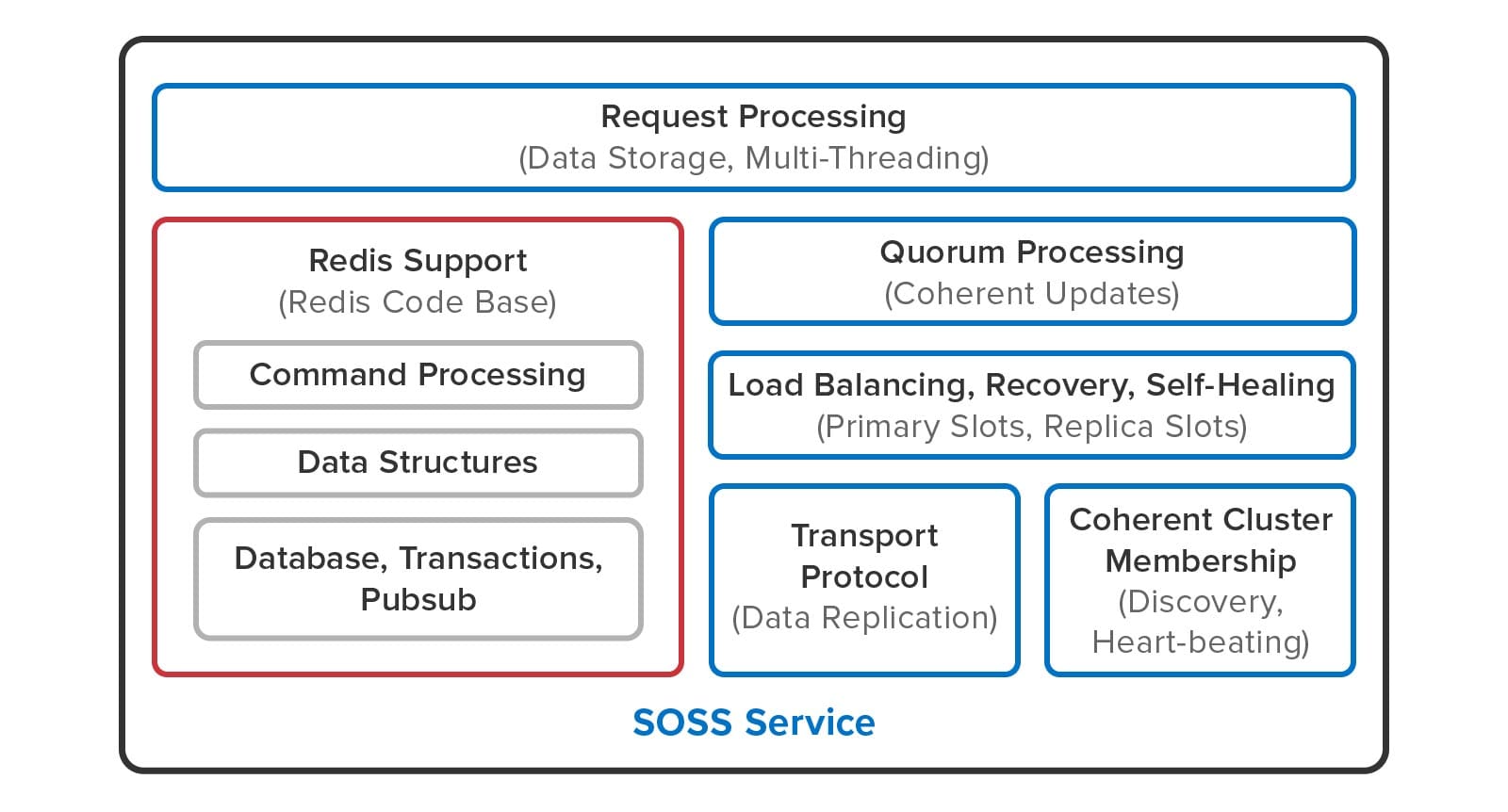
Redis open-source code (shown in the red box) implements command parsing and processing, the data structure commands, transactions, publish/subscribe commands, and blocking commands. ScaleOut StateServer takes over all clustering functions, including request processing, membership, quorum processing of updates, load-balancing, recovery, and self-healing. It also uses a proprietary transport protocol for server-to-server communication.
As illustrated below, ScaleOut StateServer uses multi-threaded execution for Redis commands to take advantage of all processing cores and eliminate the need for multiple primary shards on each server. In contrast, Redis executes commands using an event loop that processes commands sequentially on a single processing core:
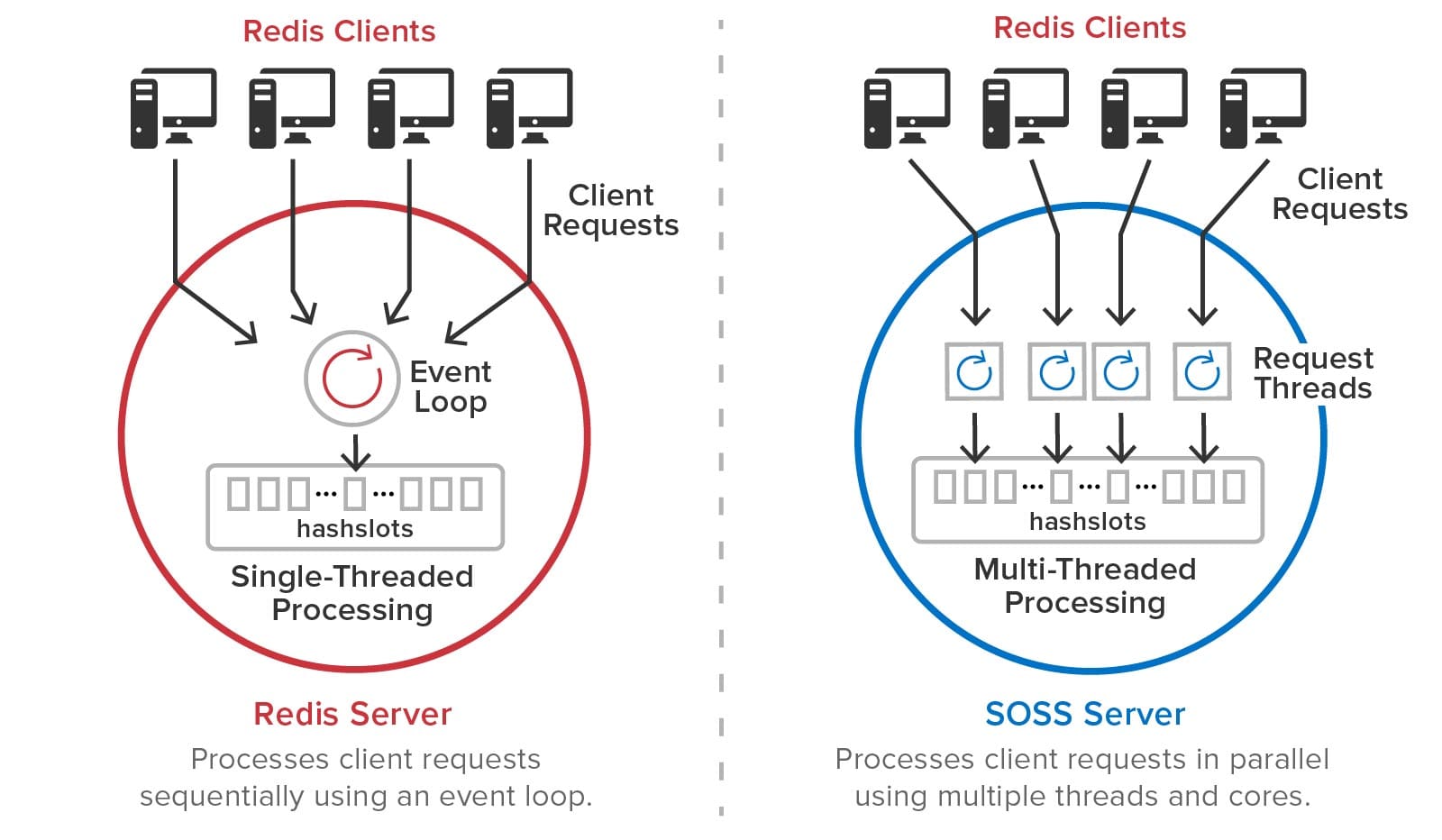
To accomplish this, ScaleOut StateServer has implemented a command scheduler that independently executes commands for each hashslot so that they can run in parallel without global locking.
What’s Missing?
The community preview release focuses on demonstrating support for Redis data structures, which represent the widely used core of Redis functionality. It does not include support for Redis streams, Lua scripting, modules, AOL/RDB persistence, ACLs, and Redis configuration files. In addition, many utility commands which are not required, such as cluster commands for manually moving hashslots, are not supported. Lastly, this version does not incorporate all of the performance enhancements in development for the production release.
Summing Up
ScaleOut’s new integration of Redis open-source code into ScaleOut StateServer was designed to bring powerful new capabilities to Redis users while ensuring native-Redis behavior for client applications. Targeted to meet the needs of enterprise users, it dramatically simplifies the management of Redis clusters by automating all cluster operations, and it ensures that fully consistent updates are performed by Redis commands. In addition, this integration runs alongside ScaleOut StateServer’s native APIs, which incorporate advanced features not available on open-source Redis clusters, such as data-parallel computing, streaming analytics, and coherent, wide-area data replication.
ScaleOut Software is excited to hear your feedback about the community preview and learn what additional features you would like to see in the upcoming production release. You can download ScaleOut StateServer, which incorporates the preview release, here for Linux or Windows and try it out now. Let us know what you think.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Introducing A New Execution Platform for Redis Clients appeared first on ScaleOut Software.
]]>The post Unlocking New Capabilities for Azure Digital Twins with Real-Time Analytics appeared first on ScaleOut Software.
]]>
The Need for Real-Time Analytics with Digital Twins
In countless applications that track live systems, real-time analytics plays a key role in identifying problems (or finding opportunities) and responding fast enough to make a difference. Consider a software telematics application that tracks a nationwide fleet of trucks to ensure timely deliveries. Dispatchers receive telemetry from trucks every few seconds detailing location, speed, lateral acceleration, engine parameters, and cargo viability. In a classic needle-and-haystack scenario, dispatchers must continuously sift through telemetry from thousands of trucks to spot issues, such as lost or fatigued drivers, engines requiring maintenance, or unreliable cargo refrigeration. They must intervene quickly to keep the supply chain running smoothly. Real-time analytics can help dispatchers tackle this seemingly impossible task by automatically sifting through telemetry as it arrives, analyzing it for anomalies needing attention, and alerting dispatchers when conditions warrant.
By using a process of divide and conquer, digital twins can dramatically simplify the construction of applications that implement real-time analytics for telematics or other applications. A digital twin for each truck can track that truck’s parameters (for example, maintenance and driver history) and its dynamic state (location, speed, engine and cargo condition, etc.). The digital twin can analyze telemetry from the truck to update this state information and generate alerts when needed. It can encapsulate analytics code or use machine learning techniques to look for anomalies. Running simultaneously, thousands of digital twins can track all the trucks in a fleet to keep dispatchers informed while reducing their workload.
Applying the digital twin model to real-time analytics expands its range of uses from its traditional home in product lifecycle management and infrastructure tracking to managing time-critical, live systems with many data sources. Examples include preventive maintenance, health-device tracking, logistics, physical and cyber security, IoT for smart cities, ecommerce shopping, financial services, and many others. But how can we integrate real-time analytics with digital twins and ensure high performance combined with straightforward application development?
Message Processing with Azure Digital Twins
Microsoft’s Azure Digital Twins provides a compelling platform for creating digital twin models with a rich set of features for describing their contents, including properties, components, inheritance, and more. The Azure Digital Twins Explorer GUI tool lets users view digital twin models and instances, as well as their relationships.
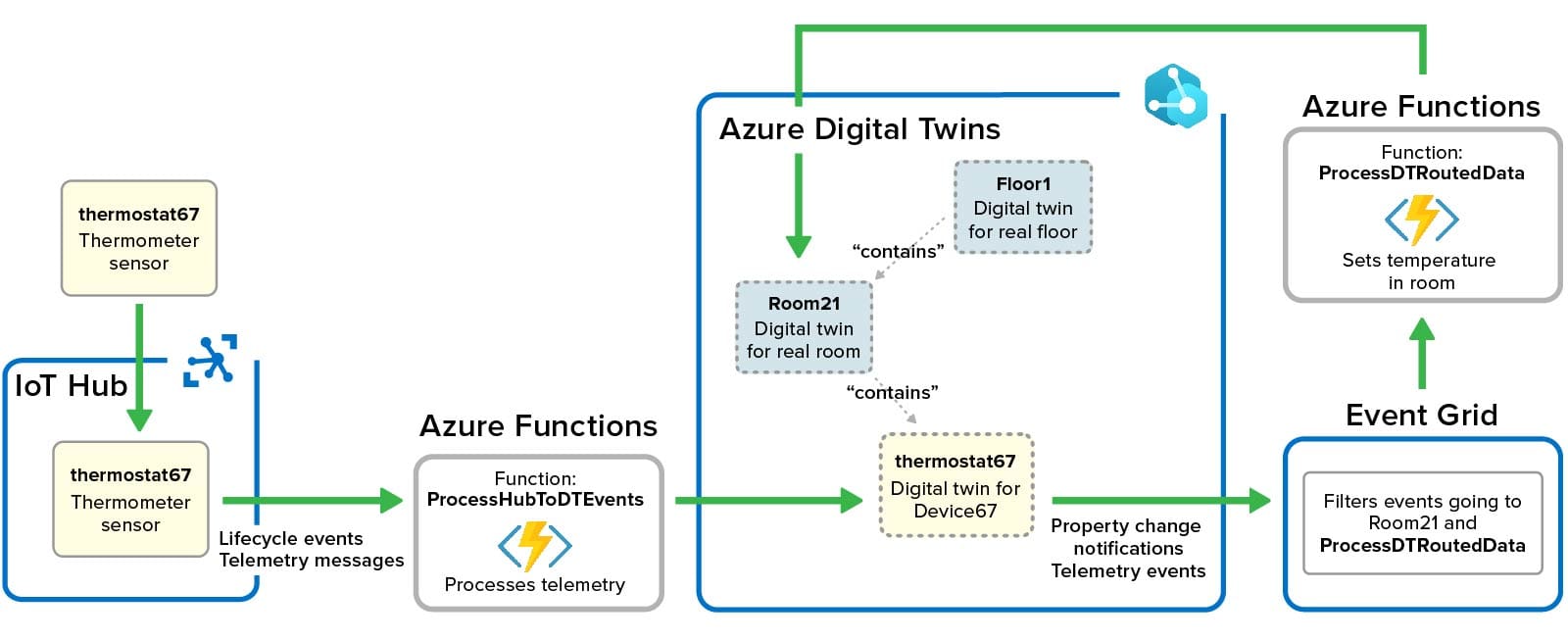
Azure digital twins can host dynamic properties that track the current state of physical data sources. Users can create serverless functions using Azure Functions to ingest messages generated by data sources and delivered to digital twins via Azure IoT Hub (or other message hubs). These functions update the properties of Azure digital twins using APIs provided for this purpose. Here’s a redrawn tutorial example that shows how Azure functions can process messages from a thermostat and update both its digital twin and a parent digital twin that models the room in which the thermostat is located. Note that the first Azure function’s update triggers the Azure Event Grid to run a second function that updates the room’s property:
The challenge in using serverless functions to process messages and perform real-time analytics is that they add overhead and complexity. By their nature, serverless functions are stateless and must obtain their state from external services; this adds latency. In addition, they are subject to scheduling and authentication overheads on each invocation, and this adds delays that limit scalability. The use of multiple serverless functions and associated mechanisms, such as Event Grid topics and routes, also adds complexity in developing analytics code.
Adding Real-Time Analytics Using In-Memory Computing
Integrating an in-memory computing platform with the Azure Digital Twins infrastructure addresses both of the challenges. This technology runs on a cluster of virtual servers and hosts application-defined software objects in memory for fast access along with a software-based compute engine that can run application-defined methods with extremely low latency. By storing each Azure digital twin instance’s properties in memory and routing incoming messages to an in-memory method for processing, both latency and complexity can be dramatically reduced, and real-time analytics can be scaled to handle thousands or even millions of data sources.
ScaleOut Software’s newly announced Azure Digital Twins Integration does just this. It integrates the ScaleOut Digital Twin Streaming Service, an in-memory computing platform running on Microsoft Azure (or on premises), with the Azure Digital Twins service to provide real-time streaming analytics. It accelerates message processing using in-memory computing to ensure fast, scalable performance while simultaneously streamlining the programming model.
The ScaleOut Azure Digital Twins Integration creates a component within an Azure Digital Twin model in which it hosts “real-time” properties for each digital twin instance of the model. These properties track dynamic changes to the instance’s physical data source and provide context for real-time analytics.
To implement real-time analytics code, application developers create a message-processing method for an Azure digital twin model. This method can be written in C# or Java, using an intuitive rules-based language, or by configuring machine learning (ML) algorithms implemented by Microsoft’s ML.NET library. It makes use of each instance’s real-time properties, which it stores in a memory-based object called a real-time digital twin, and the in-memory compute engine automatically persists these properties in the Azure digital twin instance.
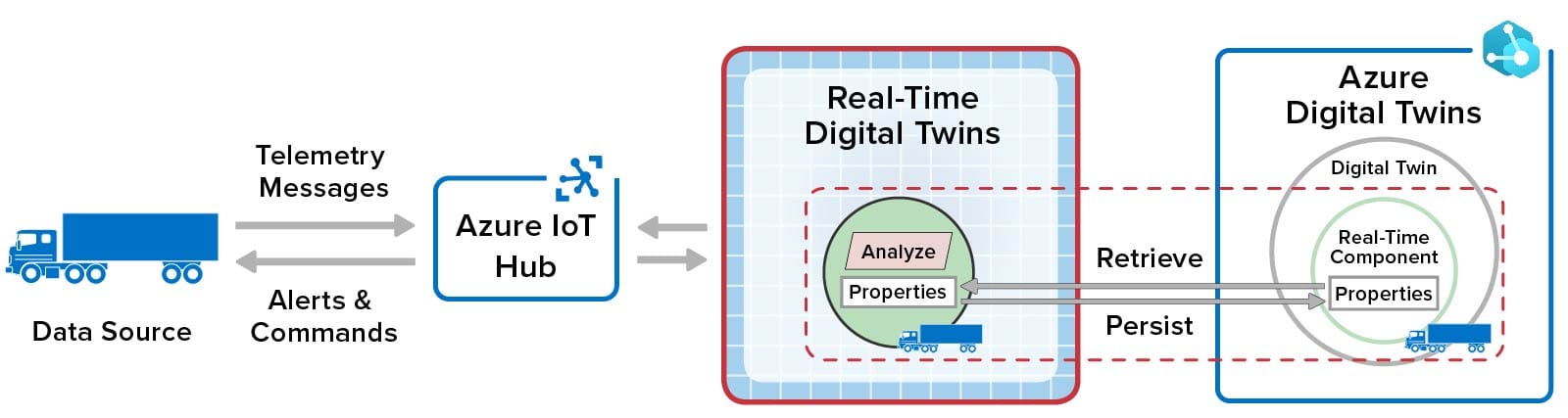
Here’s a diagram that illustrates how real-time digital twins integrate with Azure digital twins to provide real-time streaming analytics:
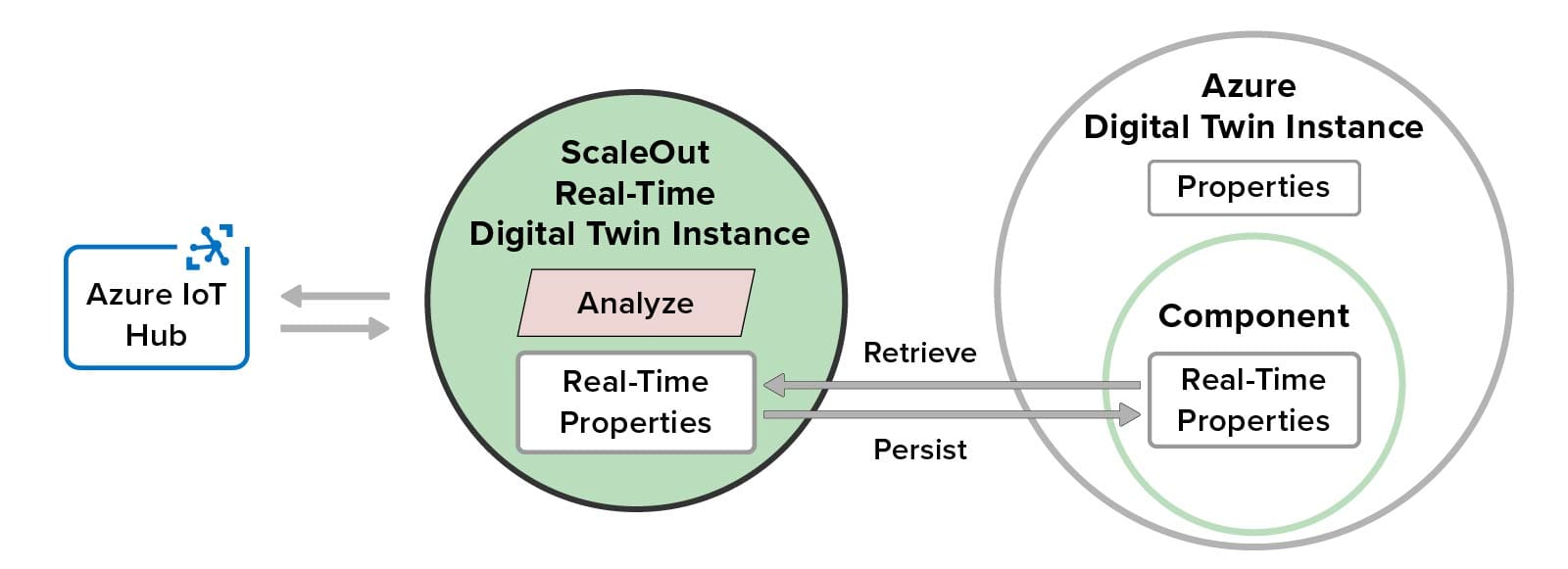
This diagram shows how each real-time digital twin instance maintains in-memory properties, which it retrieves when deployed, and automatically persists these properties in its corresponding Azure digital twin instance. The real-time digital twin connects to Azure IoT Hub or other message source to receive and then analyze incoming messages from its corresponding data source. Fast, in-memory processing provides sub-millisecond access to real-time properties and completes message processing with minimal latency. It also avoids repeated authentication delays every time a message is processed by authenticating once with the Azure Digital Twins service at startup.
All real-time analytics performed during message processing can run within a single in-memory method that has full access to the digital twin instance’s properties. This code also can access and update properties in other Azure digital twin instances. These features simplify design by avoiding the need to split functionality across multiple serverless functions and by providing a straightforward, object-oriented design framework with advanced, built-in capabilities, such as ML.
To further accelerate development, ScaleOut provides tools that automatically generate Azure digital twin model definitions for real-time properties. These model definitions can be used either to create new digital twin models or to add a real-time component to an existing model. Users just need to upload the model definitions to the Azure Digital Twins service.
Here’s how the tutorial example for the thermostat would be implemented using ScaleOut’s Azure Digital Twins Integration:
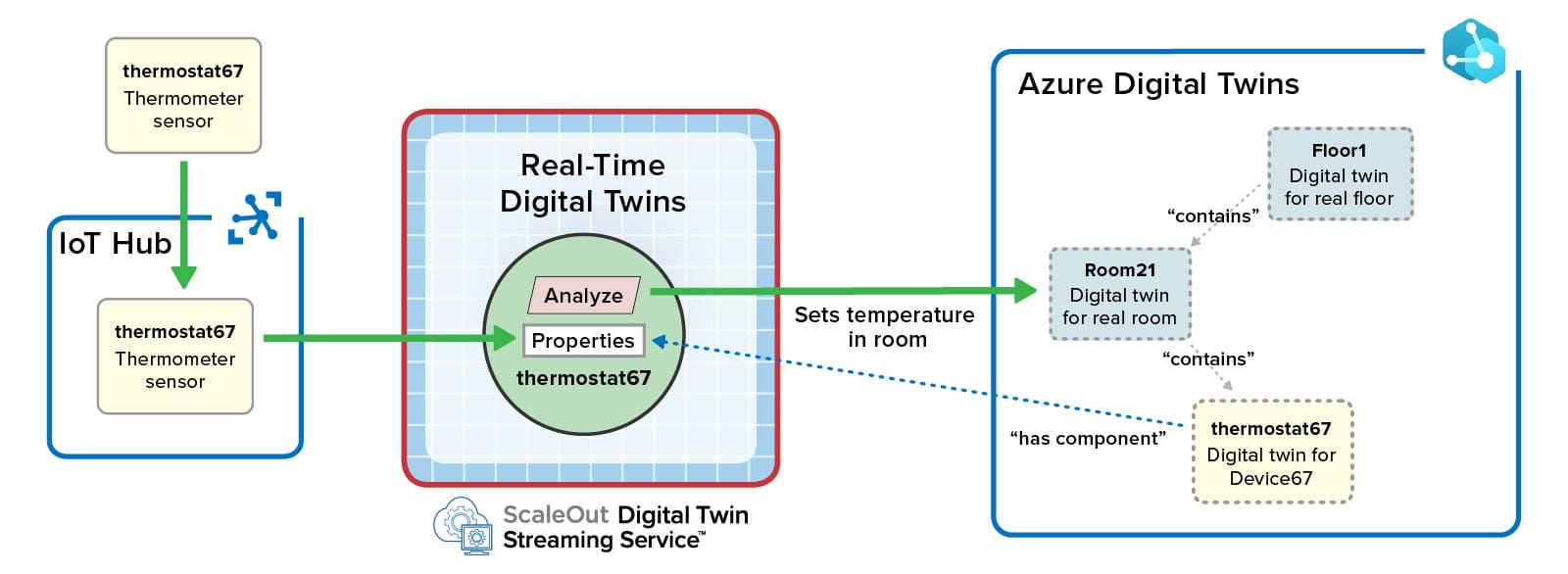 Note that the ScaleOut Digital Twins Streaming Service takes responsibility for ingesting messages from Azure IoT Hub and for invoking analytics code for the data source’s incoming messages. Multiple, pipelined connections with Azure IoT Hub ensure high throughput. Also note that the two serverless functions and use of Event Grid have been eliminated since the in-memory method handles both message processing and updates to the parent object (Room 21).
Note that the ScaleOut Digital Twins Streaming Service takes responsibility for ingesting messages from Azure IoT Hub and for invoking analytics code for the data source’s incoming messages. Multiple, pipelined connections with Azure IoT Hub ensure high throughput. Also note that the two serverless functions and use of Event Grid have been eliminated since the in-memory method handles both message processing and updates to the parent object (Room 21).
Combining the ScaleOut Digital Twin Streaming Service with Azure Digital Twins gives users the power of in-memory computing for real-time analytics while leveraging the full spectrum of Azure services and tools, as illustrated below for the thermostat example:
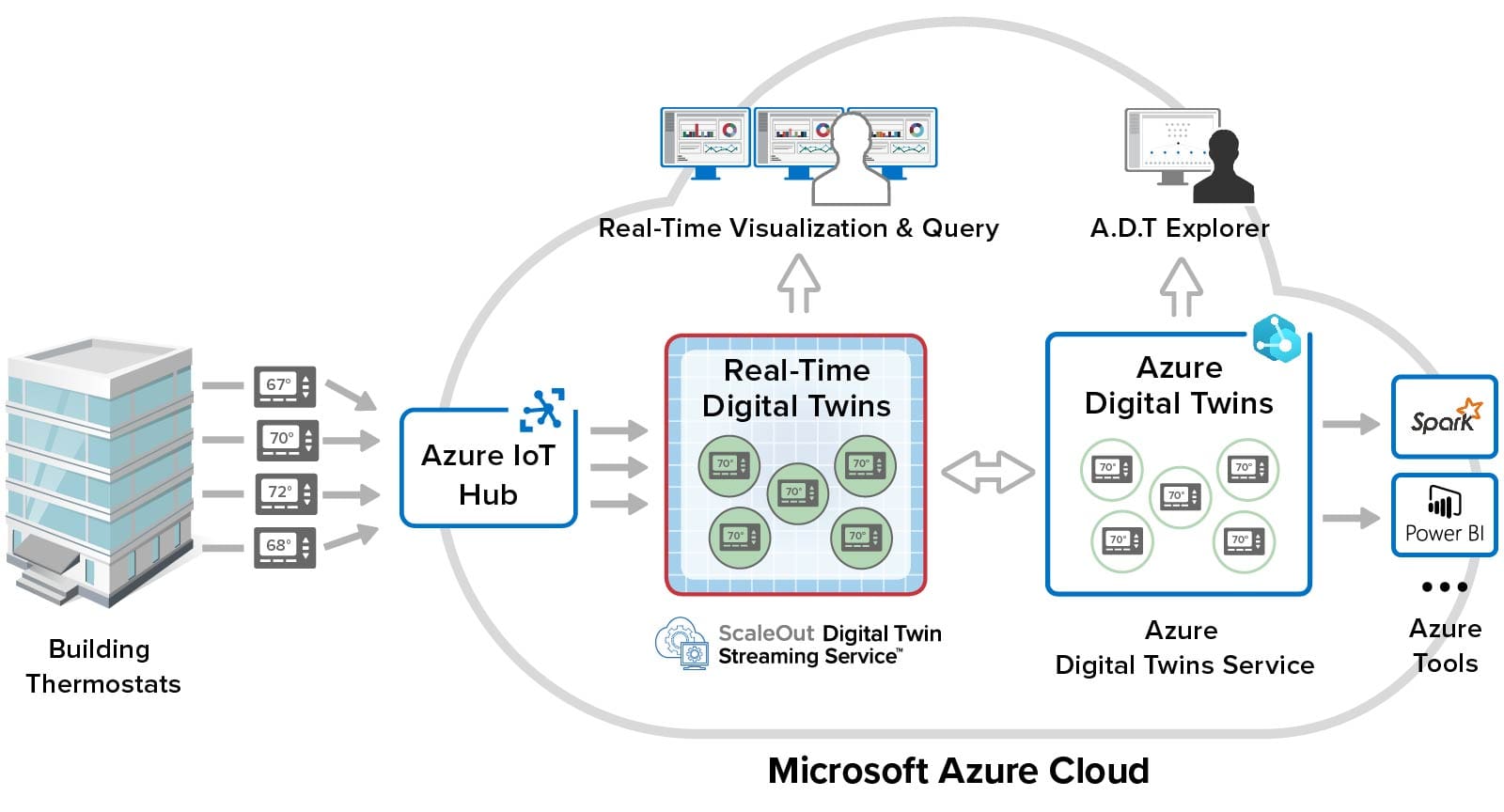
Users can view real-time properties with the Azure Digital Twins Explorer tool and track changes due to message processing. They also can take advantage of Azure’s ecosystem of big data analytics tools like Spark to perform batch processing. ScaleOut’s real-time data aggregation, continuous query, and visualization tools for real-time properties enable second-by-second tracking of live systems that boosts situational awareness for users.
Example of Real-Time Analytics with Azure Digital Twins
Incorporating real-time analytics using ScaleOut’s Azure Digital Twins Integration unlocks a wide array of applications for Azure Digital Twins. For example, here’s how the telematics software application discussed above could be implemented:
Each truck has a corresponding Azure digital twin which tracks its properties including a subset of real-time properties held in a component of each instance. When telemetry messages flow in to Azure IoT Hub, they are processed and analyzed by ScaleOut’s in-memory computing platform using a real-time digital twin that holds a truck’s real-time properties in memory for fast access and a message-processing method that analyzes telemetry changes, updates properties, and signals alerts when needed.
Real-time analytics can run ML algorithms that continuously examine telemetry, such as engine parameters, to detect anomalies and signal alerts. Digital twin analytics, combined with data aggregation and visualization powered by the in-memory platform, enable dispatchers to quickly spot emerging issues and take corrective action in a timely manner.
Summing Up
Digital twins offer a powerful means to model and visualize a population of physical devices. Adding real-time analytics to digital twins extends their reach into live, production systems that perform time-sensitive functions. By enabling managers to continuously examine telemetry from thousands or even millions of data sources and immediately identify emerging issues, they can avoid costly problems and capture elusive opportunities.
Azure Digital Twins has emerged as a compelling platform for hosting digital twin models. With the integration of in-memory computing technology using the ScaleOut Digital Twin Streaming Service, Azure Digital Twins gains the ability to analyze incoming telemetry with low latency, high scalability, and a straightforward development model. The combination of these two technologies has the potential to unlock a wide range of important new use cases for digital twins.
The post Unlocking New Capabilities for Azure Digital Twins with Real-Time Analytics appeared first on ScaleOut Software.
]]>The post Redis vs ScaleOut: What You Need to Know appeared first on ScaleOut Software.
]]>
ScaleOut’s Battle-Tested Clustering Technology Give It Key Advantages Over Redis®* in Ease of Use and Performance
By William L. Bain and Bryce C. Klinker
Breaking news: ScaleOut Software has announced a community preview of support for Redis clients in ScaleOut StateServer. Learn more here.
Distributed caching technology first hit the market in about 2001 with the introduction of Tangosol Coherence and has been evolving ever since. Designed to help applications scale performance by eliminating bottlenecks in accessing data, this distributed computing technology stores live, fast-changing data in memory across a cluster of inexpensive, commodity servers or virtual machines. The combination of fast, memory-based data storage and throughput scaling with multiple servers results in consistently fast access and update times for growing workloads, such as e-commerce, financial services, IoT device tracking, and other applications.
ScaleOut Software introduced its distributed caching product, ScaleOut StateServer® (SOSS), in 2005 and has made continuous enhancements over the last 16 years. While the single-server version of Redis was released in 2009 by Salvatore Sanfilippo, clustering support was first added in 2015. These two products embody highly different design goals. SOSS was designed as an integrated distributed caching architecture incorporating transparent throughput scaling and high availability using data replication with the goals of maximizing performance, ease of use, and portability across operating systems. In contrast, according to M. Russo, Redis was conceived as a single-server, data-structure store to improve the performance of a real-time data analytics product. (Beyond just storing strings or opaque objects, a data-structure store also implements various data types, such as lists and sorted sets.) Clustering was added to Redis’ single-server architecture after 4 years to provide a way to scale.
As background for the following discussion, it’s important to review some key concepts. Most distributed caches use a key/value storage model that identifies stored objects using string keys. To distribute objects across multiple servers in a cluster, a distributed cache typically maps keys to hash slots, each of which holds a subset of objects. The cache then distributes hash slots across the servers and moves them between servers as needed to balance the workload; this process is called sharding. A group of hash slots running on a single server (called a node here) can either be a primary or replica. Clients direct updates to the target hash slot on a primary node, which replicates the update to one or more replica nodes for high availability in case the primary node fails.
Ease of Use
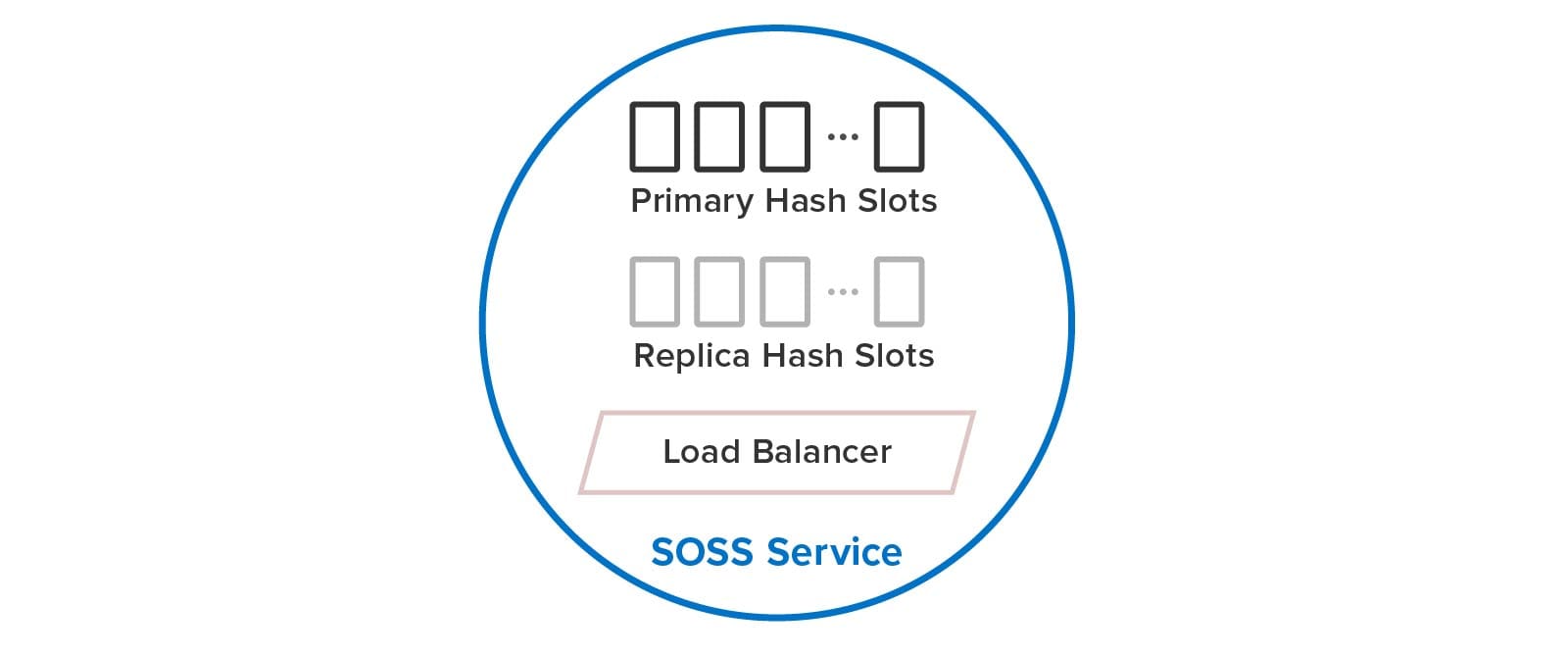
The differences in design goals of the two technologies have led to very different impacts on users. To maximize ease of use, SOSS automatically creates and manages hash slots for the user, including primaries and replicas. Using a built-in load-balancer, each service internally manages a subset of both primary and replica hash slots, as illustrated below. Users just create a single SOSS service process on every node, and these service processes discover each other and distribute the hash slots among themselves to balance the workload. They also automatically handle all aspects of recovery after a node fails.
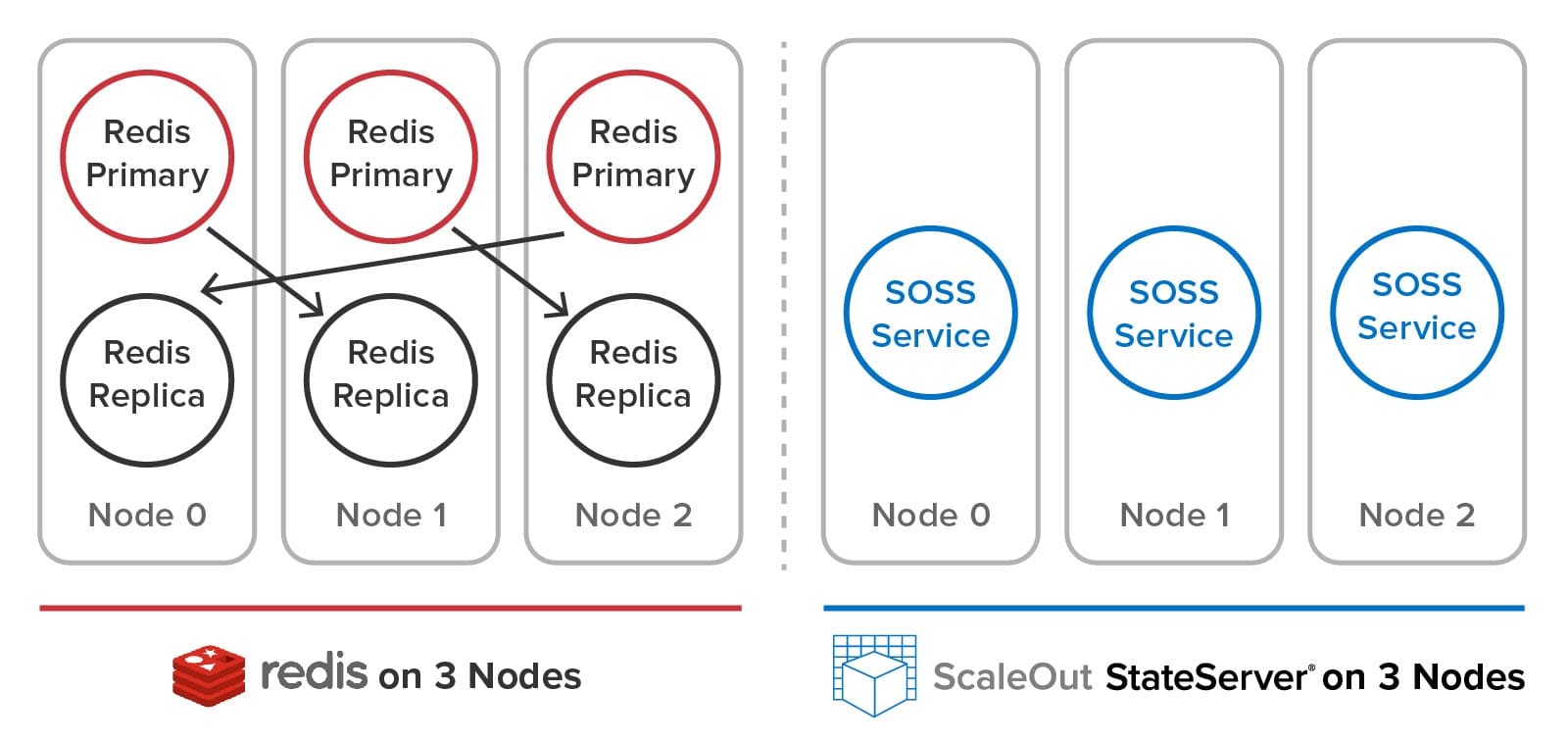
In contrast, Redis users create separate service processes on each node for primary and replica hash slots and must manually distribute the hash slots among the primaries. (Unlike SOSS, a 1-node or 2-node Redis cluster is not allowed.) As we will see below, users must perform a complex set of manual actions when adding and removing nodes and to heal and rebalance the cluster after a node fails. The following diagram illustrates the difference between Redis and SOSS in the user’s view of the cluster:
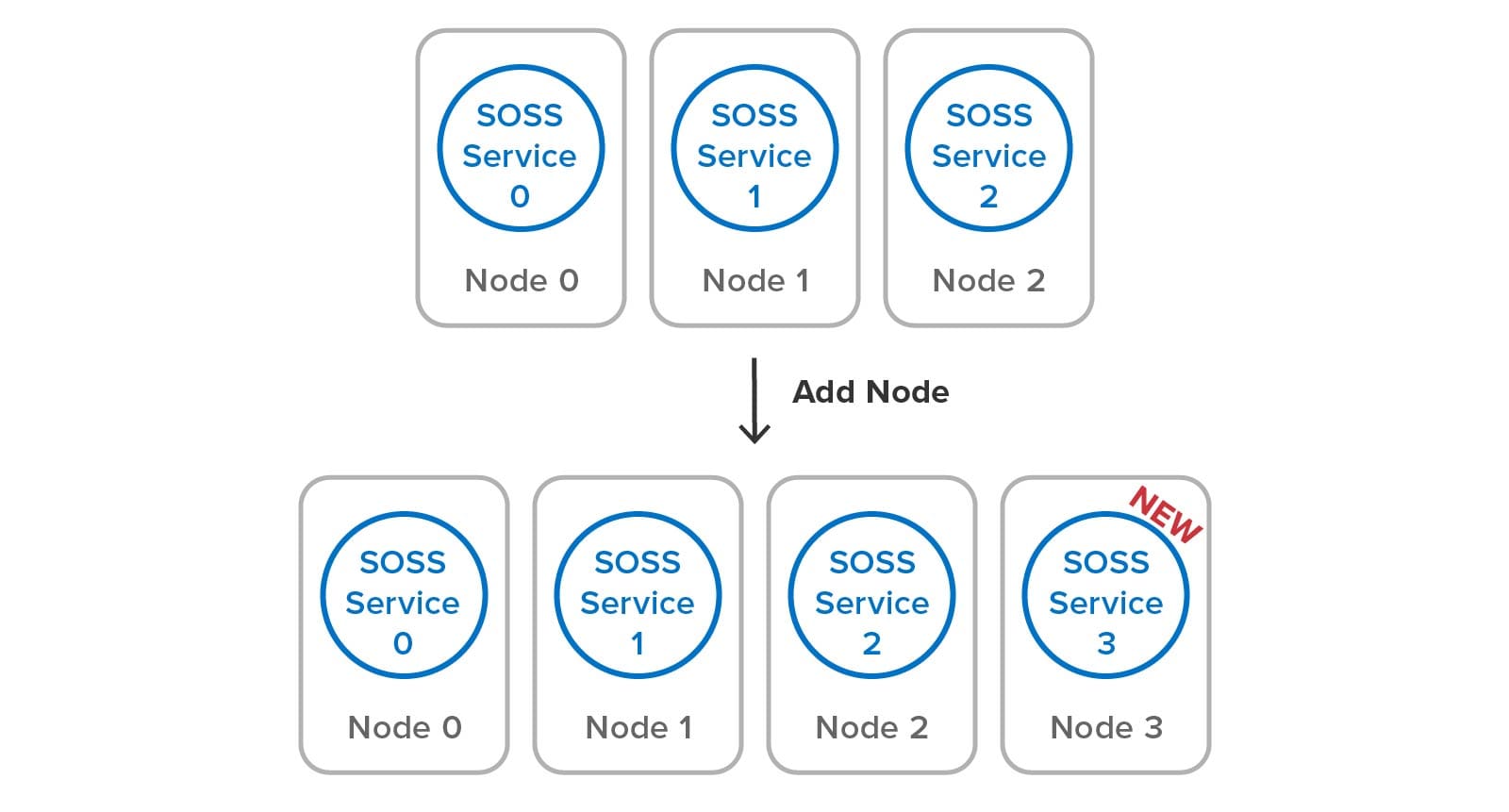
Adding a Node to the Cluster Using SOSS
To illustrate how SOSS’s built-in mechanisms for managing hash slots, load-balancing, failure detection, and self-healing simplify cluster management, let’s look at the steps needed to add a node to the cluster. When using SOSS, the user just installs the service on a new node and clicks a button in the management console to join the cluster. Using multicast discovery (or optional host list if multicast is not available), the service process automatically receives primary and replica hash slots and starts handling its portion of the workload. The following diagram shows the addition of a fourth node to a cluster:
Adding a Node to the Cluster Using Redis
Because Redis requires the user to manage the creation of primary and replica service processes (sometimes called shards) and the management of hash slots, many more steps must be performed to add a node to the cluster. To accomplish this, the user runs administrative commands that create the new processes, connect the primaries and replicas, move the replicas as necessary, and reallocate the hash slots among the nodes. The required configuration changes are illustrated below:
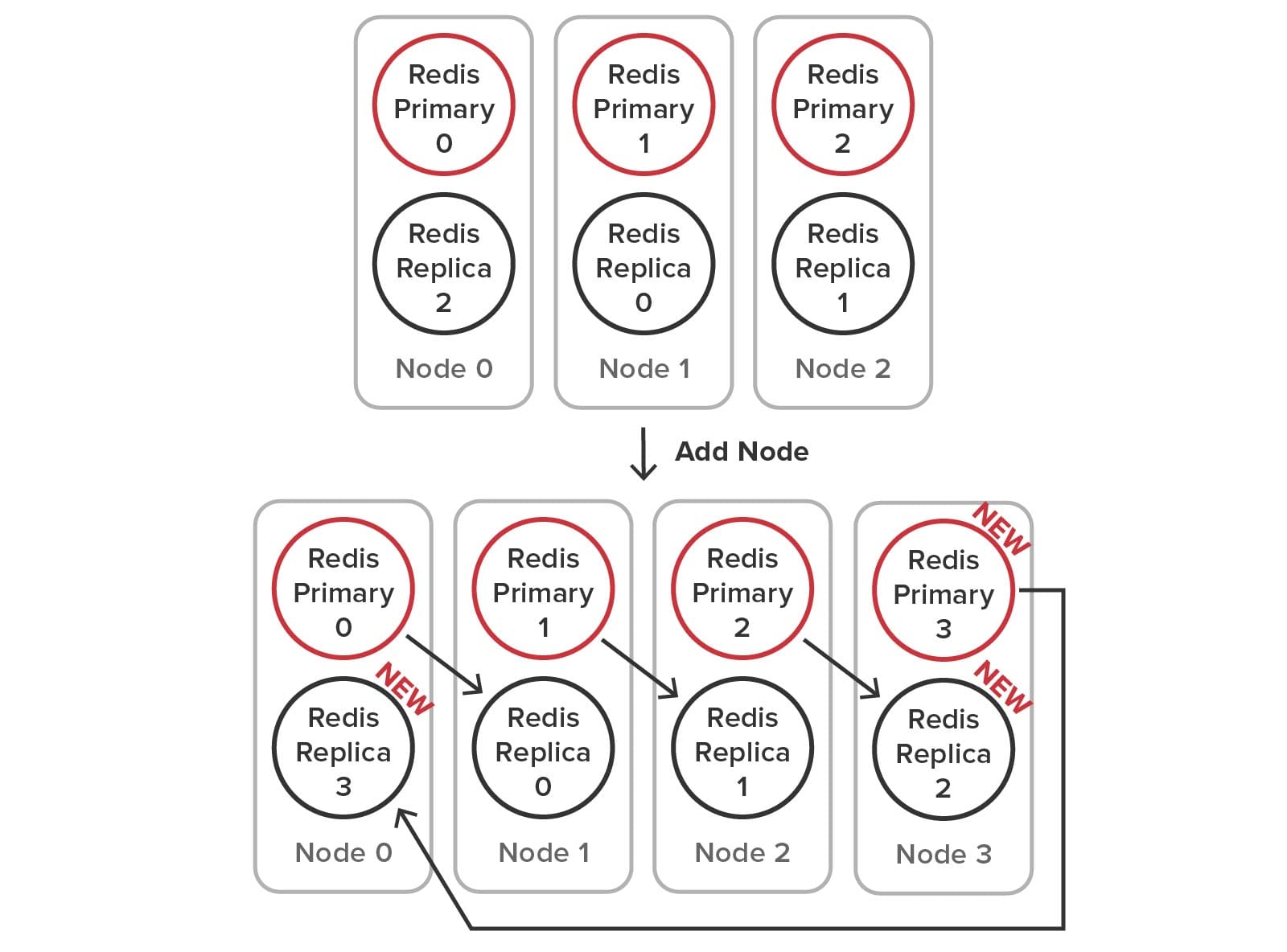
Here is an example of administrative steps required to make the configuration changes (using node 0’s IP and port as the bootstrap address for the new node):
// Start up a new replica redis-server instance on node 3 for primary 2:
redis-cli --cluster add-node host3Ip:replicaPort node0Ip:node0Port --cluster-slave
--cluster-master-id primary2NodeID
// Start up a new primary redis-server instance on node 3:
redis-cli --cluster add-node host3Ip:primaryPort existingIp:existingPort
// Connect to replica 2 on node 0 and modify it to replicate primary 3:
redis-cli -h replica2Ip -p -replica2Port > cluster replicate primary3NodeID
// Reshard the cluster by interactively moving hash slots from existing nodes to node 3:
redis-cli --cluster reshard existingIp:existingPort
> How many slots to move? 4096 //16384 / 4 = 4096
> What node to move slots to? primary3NodeID // (primary3NodeID returned by previous command)
> What nodes to move slots from? all
This process is complex, and it becomes more difficult to keep track of the distribution of hash slots with larger cluster memberships. Removing a node has comparable complexity.
Recovering After a Node Fails (SOSS and Redis)
SOSS’s service processes automatically detect and recover from the loss of a node. They use built-in, scalable, peer-to-peer heart-beating to detect missing node(s) and create a new, coherent cluster membership. Next, they promote replica hash slots to primaries on the surviving nodes, create new replicas for self-healing, and rebalance the workload across the nodes.
Redis does not implement a coherent cluster membership and does not provide automatic self-healing and recovery. Each Redis node sends heartbeat messages to random other nodes to detect possible failures, and the cluster uses a gossip mechanism to declare that a node has failed. After that, its replica on a different node promotes itself to a primary so that the hash slots remain available, but Redis does not self-heal by creating a new replica for the hash slots. Also, it does not automatically redistribute the hash slots across the nodes to rebalance the workload. These tasks are left to the system administrator, who needs to sort out the needed configuration changes and implement them to restore a fully redundant, balanced cluster.
Performance Comparison
The different design choices between SOSS and Redis also lead to semantic and performance differences. To maximize ease of use for application developers, SOSS maintains all stored data with full consistency (to be more precise, sequential consistency), ensuring that it only serves the latest updates and never loses data after the failure of a single server (or two servers if multiple replicas are used). This design choice targets enterprise applications that need to ensure that the distributed cache always returns the correct data. To implement data replication across multiple replicas with the highest possible performance, SOSS uses a patented quorum algorithm.
In contrast, Redis employs an eventual consistency model with asynchronous replication. In general, this choice enables higher throughput because updates do not have to wait for replication to complete before responding to the user. It also enables potentially higher read throughput by serving reads from replicas even if they are not guaranteed to serve the latest updates.
Given these two design choices, it’s valuable to compare the throughput of the two distributed caches as nodes are added and the workload is simultaneously increased, as illustrated below. This technique evaluates how well the caches can scale their throughput by adding nodes to handle increasing workload; linear throughput scaling ensures consistently fast response times. (For a discussion of throughput scaling in distributed systems, see Gustafson’s Law.).
To perform an apples-to-apples throughput comparison of Redis 6.2 and SOSS 5.10, SOSS was configured to use eventual consistency (“EC”) when updating replicas. The performance of SOSS with full consistency (“FC”) was also measured. Tests were run for 3, 4, and 6 node clusters in AWS on m5.xlarge instances with 4 cores@2.5 Ghz, and 16GB RAM. The clients ran read/update pairs on 100K objects of sizes 2KB and 20KB to represent a typical web workload with a 1:1 read/update ratio. The results are as follows:
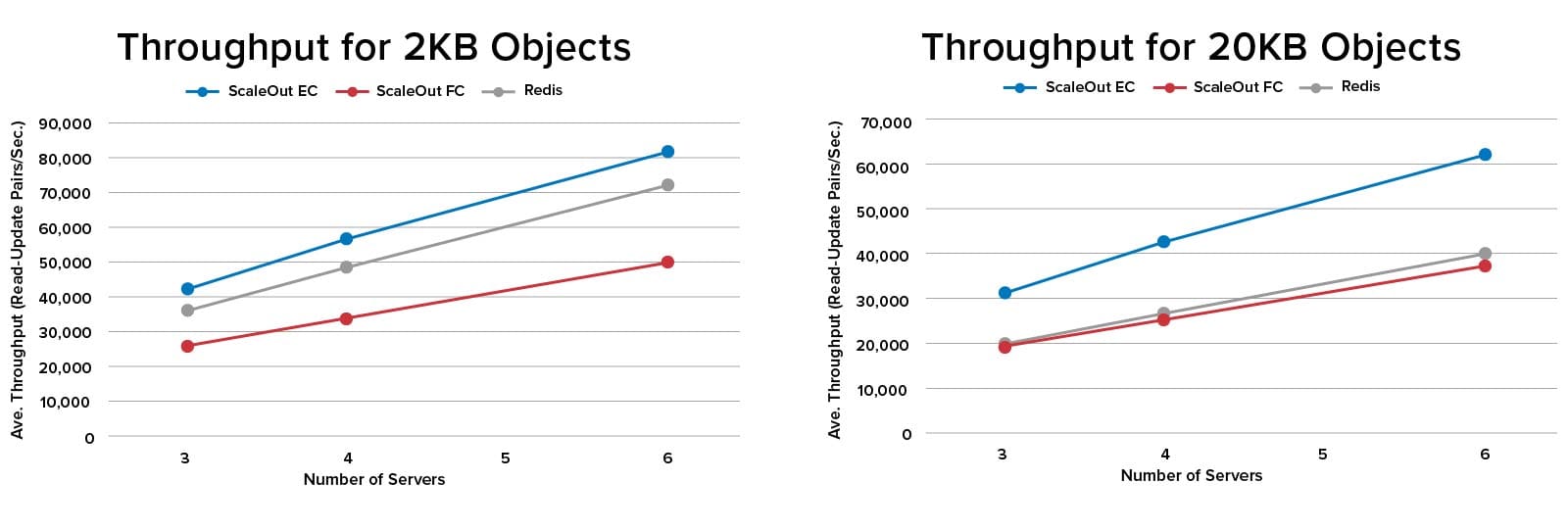
SOSS provided consistently higher throughput than Redis when eventual consistency was used to perform updates (the blue and gray lines in the charts). Running SOSS with full consistency (the red lines) resulted in lower throughput, as expected, since updates have to be committed at the replica before responding to the client instead of being performed asynchronously. However, both Redis and SOSS with full consistency delivered close to the same throughput for 20KB objects. This may be due to benefits of SOSS’s client-side caching, which eliminated unnecessary data transfers during reads.
Summing Up
Our comparison of SOSS and Redis shows the benefits of ScaleOut’s integrated clustering architecture. A key design goal for SOSS was to simplify the user’s workload by providing a unified, location-transparent data cache with built-in, fully automatic load-balancing and high availability. By hiding the inner workings of hash slots, heart-beating, replica placement, load-balancing, and self-healing, the application developer and systems administrator can focus on simply using the distributed cache instead of configuring its implementation. In our view, Redis’s approach of exposing these complex mechanisms to the user significantly steepens the learning curve and increases the user’s workload.
It might come as a surprise to learn that in the above benchmark testing, SOSS maintained a consistent performance advantage. We attribute this to ScaleOut’s approach of designing an integrated cluster architecture from the outset instead of adding clustering to a single server data store, as Redis did. This approach enabled design freedom at every step to eliminate distributed bottlenecks, and it led to extensive use of multithreading and internal data sharding within each service process to extract maximum performance from multi-core servers.
Lastly, SOSS demonstrates that the CAP theorem doesn’t really prevent the use of full consistency when building a scalable, distributed cache. For many enterprise applications, which demand data integrity at all times, this may be the better choice.
Learn more about how ScaleOut StateServer compares to Redis.
*Redis is a registered trademark of Redis Ltd. and the Redis box logo is a mark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleOut Software is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleOut Software.
The post Redis vs ScaleOut: What You Need to Know appeared first on ScaleOut Software.
]]>The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
]]>Real-Time Device Tracking with In-Memory Computing Can Fill an Important Gap in Today’s Streaming Analytics Platforms
We are increasingly surrounded by intelligent IoT devices, which have become an essential part of our lives and an integral component of business and industrial infrastructures. Smart watches report biometrics like blood pressure and heartrate; sensor hubs on long-haul trucks and delivery vehicles report telemetry about location, engine and cargo health, and driver behavior; sensors in smart cities report traffic flow and unusual sounds; card-key access devices in companies track entries and exits within businesses and factories; cyber agents probe for unusual behavior in large network infrastructures. The list goes on.
The Limitations of Today’s Streaming Analytics
How are we managing the torrent of telemetry that flows into analytics systems from these devices? Today’s streaming analytics architectures are not equipped to make sense of this rapidly changing information and react to it as it arrives. The best they can usually do in real-time using general purpose tools is to filter and look for patterns of interest. The heavy lifting is deferred to the back office. The following diagram illustrates a typical workflow. Incoming data is saved into data storage (historian database or log store) for query by operational managers who must attempt to find the highest priority issues that require their attention. This data is also periodically uploaded to a data lake for offline batch analysis that calculates key statistics and looks for big trends that can help optimize operations.
![]()
What’s missing in this picture? This architecture does not apply computing resources to track the myriad data sources sending telemetry and continuously look for issues and opportunities that need immediate responses. For example, if a health tracking device indicates that a specific person with known health condition and medications is likely to have an impending medical issue, this person needs to be alerted within seconds. If temperature-sensitive cargo in a long haul truck is about to be impacted by an erratic refrigeration system with known erratic behavior and repair history, the driver needs to be informed immediately. If a cyber network agent has observed an unusual pattern of failed login attempts, it needs to alert downstream network nodes (servers and routers) to block the kill chain in a potential attack.
A New Approach: Real-Time Device Tracking
To address these challenges and countless others like them, we need autonomous, deep introspection on incoming data as it arrives and immediate responses. The technology that can do this is called in-memory computing. What makes in-memory computing unique and powerful is its two-fold ability to host fast-changing data in memory and run analytics code within a few milliseconds after new data arrives. It can do this simultaneously for millions of devices. Unlike manual or automatic log queries, in-memory computing can continuously run analytics code on all incoming data and instantly find issues. And it can maintain contextual information about every data source (like the medical history of a device wearer or the maintenance history of a refrigeration system) and keep it immediately at hand to enhance the analysis. While offline, big data analytics can provide deep introspection, they produce answers in minutes or hours instead of milliseconds, so they can’t match the timeliness of in-memory computing on live data.
The following diagram illustrates the addition of real-time device tracking with in-memory computing to a conventional analytics system. Note that it runs alongside existing components. It adds the ability to continuously examine incoming telemetry and generate both feedback to the data sources (usually, devices) and alerts for personnel in milliseconds:
![]()
In-Memory Computing with Real-Time Digital Twins
Let’s take a closer look at today’s conventional streaming analytics architectures, which can be hosted in the cloud or on-premises. As shown in the following diagram, a typical analytics system receives messages from a message hub, such as Kafka, which buffers incoming messages from the data sources until they can be processed. Most analytics systems have event dashboards and perform rudimentary real-time processing, which may include filtering an aggregated incoming message stream and extracting patterns of interest. These real-time components then deliver messages to data storage, which can include a historian database for logging and query and a data lake for offline, batch processing using big data tools such as Spark:
![]()
Conventional streaming analytics systems run either manual queries or automated, log-based queries to identify actionable events. Since big data analyses can take minutes or hours to run, they are typically used to look for big trends, like the fuel efficiency and on-time delivery rate of a trucking fleet, instead of emerging issues that need immediate attention. These limitations create an opportunity for real-time device tracking to fill the gap.
As shown in the following diagram, an in-memory computing system performing real-time device tracking can run alongside the other components of a conventional streaming analytics solution and provide autonomous introspection of the data streams from each device. Hosted on a cluster of physical or virtual servers, it maintains memory-based state information about the history and dynamically evolving state of every data source. As messages flow in, the in-memory compute cluster examines and analyzes them separately for each data source using application-defined analytics code. This code makes use of the device’s state information to help identify emerging issues and trigger alerts or feedback to the device. In-memory computing has the speed and scalability needed to generate responses within milliseconds, and it can evaluate and report aggregate trends every few seconds.
![]()
Because in-memory computing can store contextual data and process messages separately for each data source, it can organize application code using a software-based digital twin for each device, as illustrated in the diagram above. Instead of using the digital twin concept to model the inner workings of the device, a real-time digital twin tracks the device’s evolving state coupled with its parameters and history to detect and predict issues needing immediate attention. This provides an object-oriented mechanism that simplifies the construction of real-time application code that needs to evaluate incoming messages in the context of the device’s dynamic state. For example, it enables a medical application to determine the importance of a change in heart rate for a device wearer based on the individual’s current activity, age, medications, and medical history.
Summing Up
The complex web of communicating devices that surrounds us needs intelligent, real-time device tracking to extract its full benefits. Conventional streaming analytics architectures have not kept up with the growing demands of IoT. With its combination of fast data storage, low-latency processing and ease of use, in-memory computing can fill the gap while complementing the benefits provided by historian databases and data lakes. It can add the immediate feedback that IoT applications need and boost situational awareness to a new level, finally enabling IoT to deliver on its promises.
The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
]]>The post Adding New Capabilities for Real-Time Analytics to Azure IoT appeared first on ScaleOut Software.
]]>
The population of intelligent IoT devices is exploding, and they are generating more telemetry than ever. Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processing IoT telemetry, from its arrival in the cloud through its storage in databases and data lakes. Acting as a switchboard for incoming and outgoing messages, Azure IoT Hub forms the core of these capabilities. It provides support for a range of message protocols, buffering, and scalable message distribution to downstream services. These services include:
- Azure Event Grid for routing incoming events to a variety of handlers, including serverless functions, webhooks, storage queues, and other services
- Azure IoT Central for managing devices, visualizing incoming telemetry on a dashboard, triggering alerts, and integrating with line-of-business applications
- Azure Stream Analytics for simultaneously analyzing aggregated telemetry streams using extended SQL queries to extract patterns that can be fed to workflows, including alerts, serverless functions, and data storage with offline processing
- Azure Time Series Insights for storing time-series data and then exploring, modeling, and querying it to gain insights, such as identifying anomalies and trends, with a rich set of analytics tools
- Azure Digital Twins for creating a graphical representation of the assets within an organization using the Digital Twin Definition Language, processing events, and visualizing entity graphs to display and query status
While Azure IoT offers a wide variety of services, it focuses on visualizing entities and events, extracting insights from telemetry streams with queries, and migrating events to storage for more intensive offline analysis. What’s missing is continuous, real-time introspection on the dynamic state of IoT devices to predict and immediately react to significant changes in their state. These capabilities are vitally important to extract the full potential of real-time intelligent monitoring.
For example, here are some scenarios in which stateful, real-time introspection can create important insights. Telemetry from each truck in a fleet of thousands can provide numerous parameters about the driver (such as repeated lateral accelerations at the end of a long shift) that might indicate the need for a dispatcher to intervene. A health tracking device might indicate a combination of signals (blood pressure, blood oxygen, heart rate, etc.) that indicate an emerging medical issue for an individual with a known medical history and current medications. A security sensor in a key-card access system might indicate an unusual pattern of building entries for an employee who has given notice of resignation.
In all of these examples, the event-processing system needs to be able to independently analyze events for each data source (IoT device) within milliseconds, and it needs immediate access to dynamic, contextual information about the data source that it can use to perform real-time predictive analytics. In short, what’s needed is a scalable, in-memory computing platform connected directly to Azure IoT Hub which can ingest and process event messages separately for each data source using memory-based state information maintained for that data source.
The ScaleOut Digital Twin Streaming Service provides precisely these capabilities. It does this by leveraging the digital twin concept (not to be confused with Azure Digital Twins) to create an in-memory software object for every data source that it is tracking. This object, called a real-time digital twin, holds dynamic state information about the data source and is made available to the application’s event handling code, which runs within 1-2 milliseconds whenever an incoming event is received. Application developers write event handling code in C#, Java, JavaScript, or using a rules engine; this code encapsulates application logic, such as a predictive analytics or machine learning algorithm. Once the real-time digital twin’s model (that is, its state data and event handling code) has been created, the developer can use an intuitive UI to deploy it to the streaming service and connect to Azure IoT Hub.
As shown in the following diagram, ScaleOut’s streaming service connects to Azure IoT Hub, runs alongside other Azure IoT services, and provides unique capabilities that enhance the overall Azure IoT ecosystem:
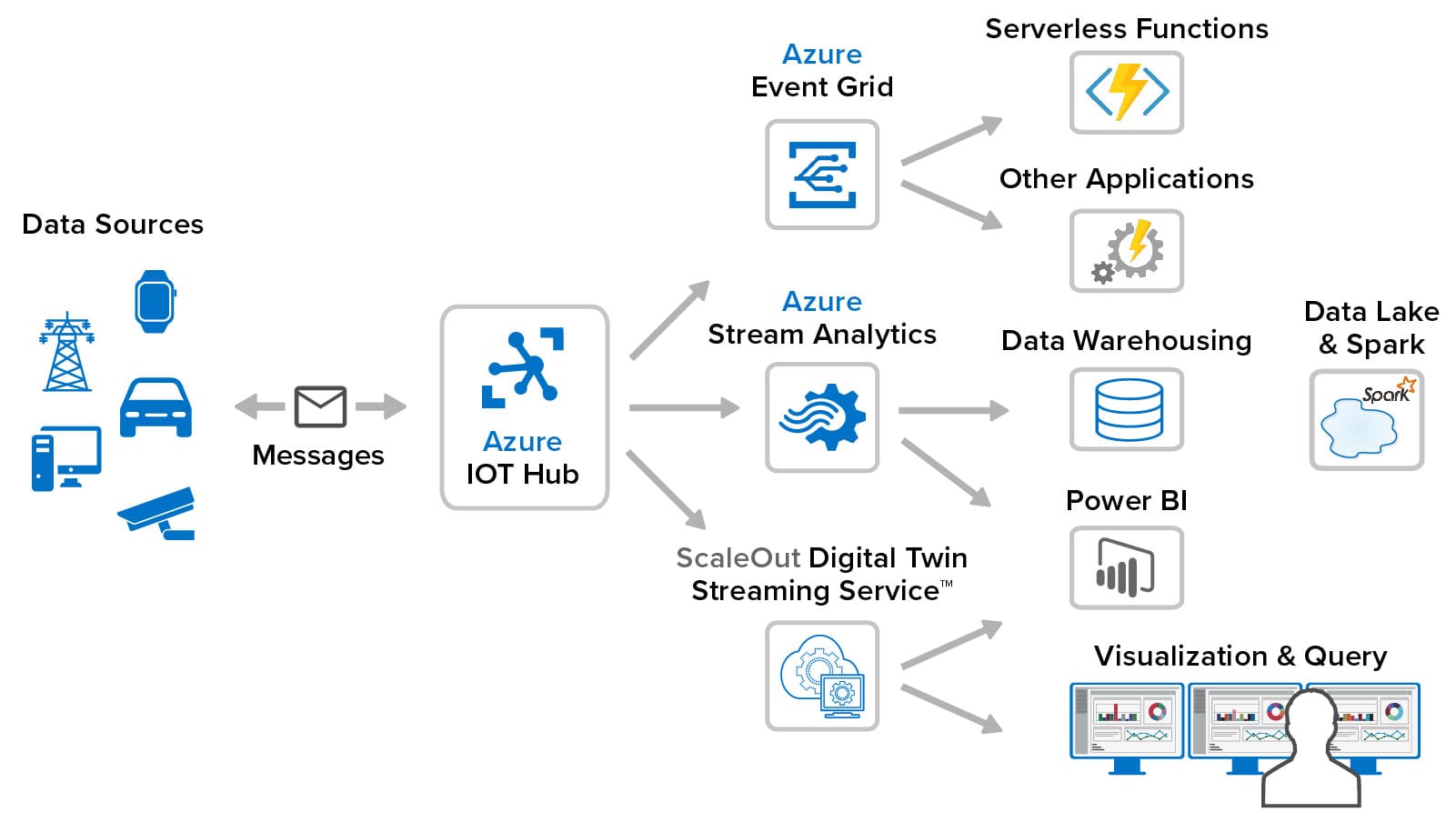
ScaleOut’s streaming service handles all the details of message delivery, data management, code orchestration, and scalable execution. This makes developing streaming analytics code for real-time digital twins fast and easy. The application developer just focuses on writing a single method to process incoming messages, run application-specific analytics, update state information about the data source, and generate alerts as needed. The optional rules engine further simplifies the development process with a UI for specifying state data and a sequential list of business rules for describing analytics code.
How are the streaming service’s real-time digital twins different from Azure digital twins? Both services leverage the digital twin concept by providing a software entity for each IoT device that can track the parameters and state of the device. What’s different is the streaming service’s focus on real-time analytics and its use of an in-memory computing platform integrated with Azure IoT Hub to ensure the lowest possible latency and high scalability. Azure digital twins serve a different purpose. They are intended to maintain a graphical representation of an organization’s entities for management and querying current status; they are not designed to implement real-time analytics using application-defined algorithms.
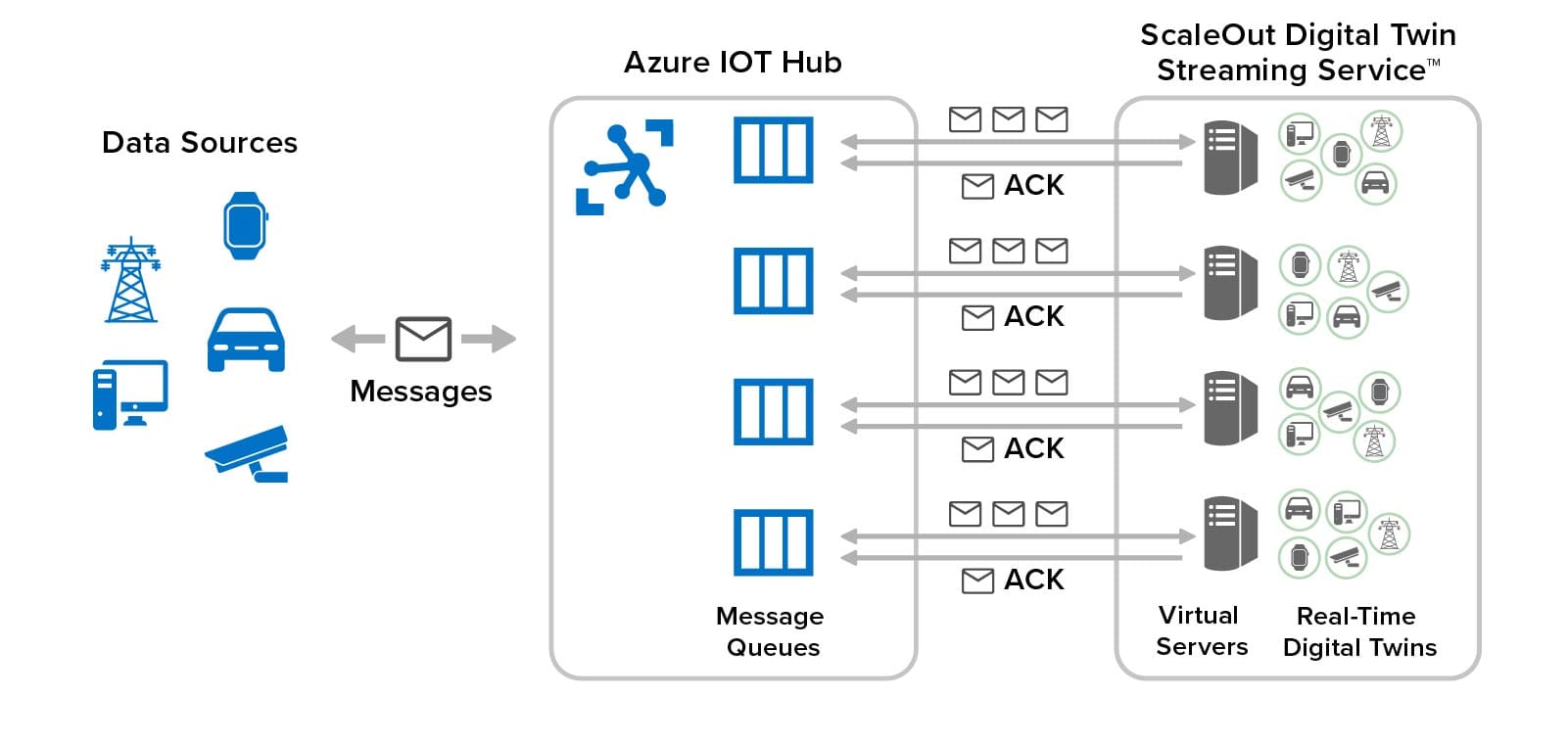
The following diagram illustrates the integration of ScaleOut’s streaming service with Azure IoT Hub to provide fast, scalable event handling with low-latency access to memory-based state for all data sources. It shows how real-time digital twins are distributed across multiple virtual servers organized into an in-memory computing cluster connected to Azure IoT Hub. The streaming service uses multiple message queues in Azure IoT Hub to scale message delivery and event processing:
As IoT devices proliferate and become more intelligent, it’s vital that our cloud-based event-processing systems be able to perform continuous and deep introspection in real time. This enables applications to react quickly, effectively, and autonomously to emerging challenges, such as to security threats and safety issues, as well as to new opportunities, such as real-time ecommerce recommendations. While there is an essential role for query and offline analytics to optimize IoT services, the need for highly granular, real-time analytics continues to grow. ScaleOut’s Digital Twin Streaming Service is designed to meet this need as an integral part of the Azure IoT ecosystem.
To learn more about using the ScaleOut’s Digital Twin Streaming Service in the Microsoft Azure cloud, visit the Azure Marketplace here.
The post Adding New Capabilities for Real-Time Analytics to Azure IoT appeared first on ScaleOut Software.
]]>The post Building the Next Generation in Physical and Cyber Security with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
In-Memory Computing with Real-Time Digital Twins Offers the Intelligence, Responsiveness, Agility, and Scalability that Security and Safety Systems are Missing
Today’s physical and cyber security systems need to quickly detect and respond to unauthorized intrusions. However, these systems typically do not take advantage of in-memory computing techniques to help them immediately assess threats and generate alerts. In-memory computing with real-time digital twins offers a powerful new tool to address these challenges. Because these software components independently analyze telemetry from each data source and maintain dynamic contextual information, they can immediately spot unwanted intrusions and generate alerts. Let’s take a look at how they can add value.
Physical Security and Safety
Consider physical security with key card access control used by countless businesses and industries. Key card access control systems rely on database servers in the back office to authorize key cards for specific card readers and to log usage. As illustrated below, this information propagates to field access panels in the buildings to minimize delays in authorizing access. However, making changes usually requires manual database updates and may take minutes or longer to propagate throughout the system.
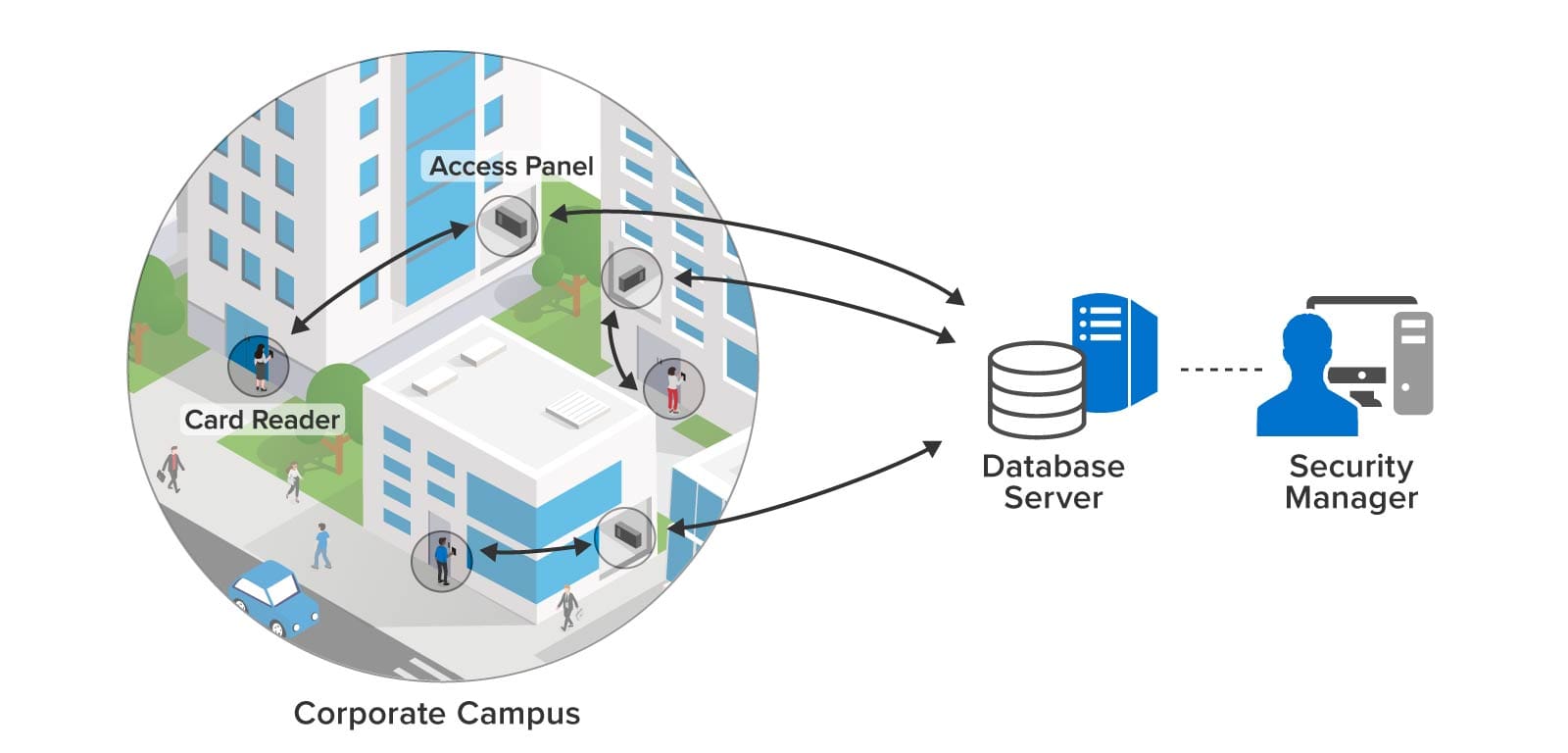
More importantly, subtle patterns of unauthorized access may escape the attention of security personnel and require a review of the logs to detect. For example, an employee who has given notice of resignation may unexpectedly visit buildings or laboratories that were not part of the employee’s known scope of work. Another employee might be put at risk by attempting to enter a hazardous laboratory without having completed the required training. An exit door might record an unusual pattern of entries outside of business hours. In all of these situations, quick detection and response could avoid unwanted intrusions or safety lapses.
To enable immediate alerting, real-time digital twins (RTDTs) can be used to track every key card and key card reader. Since each key card is associated with a specific employee, the RTDT can track that person’s individual authorization to access buildings, entry doors, laboratories, etc. It also can track employment status and level of training to help assess safety issues. This information can be immediately updated by sending a message to the RTDT whenever the employee’s status changes. With this contextual information, each RTDT can implement highly granular access permissions at the card readers while checking authorization within several milliseconds. It also can track the employee’s and entry point’s usage patterns to look for unusual situations that should be alerted.
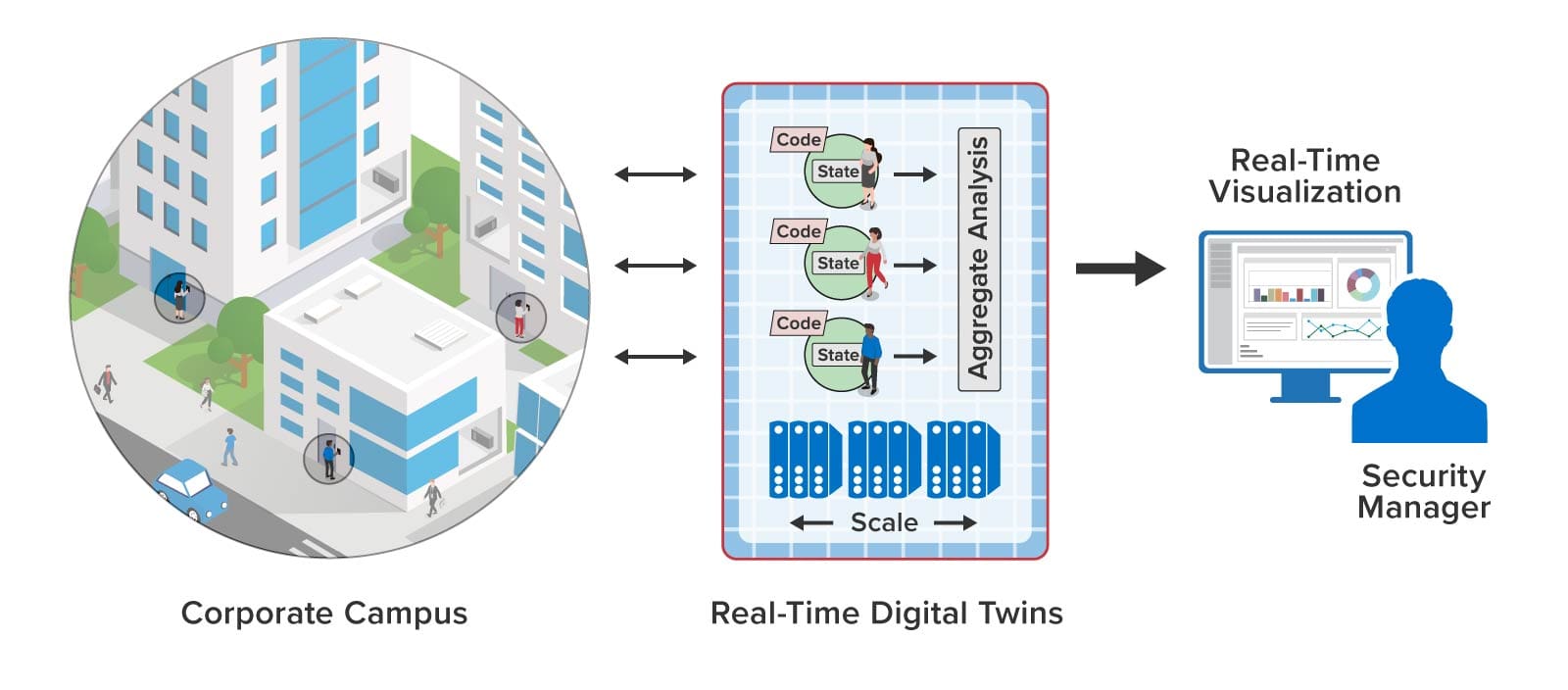
In a typical interaction, the key card reader sends a message to the employee’s key card RTDT with the reader’s identifier and time of day. After analyzing the request and tracking usage patterns, the key card RTDT responds with an authorization reply to the reader. The RTDT also sends a message to the reader’s RTDT to enable it to track usage and generate alerts as necessary, as illustrated below:
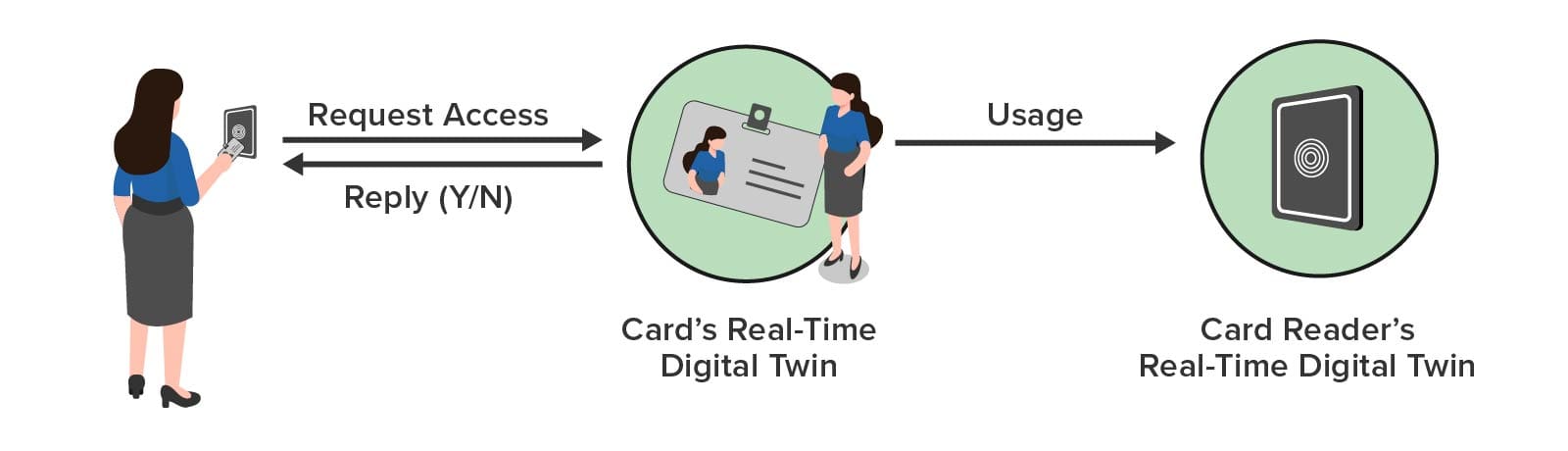
Cyber Security
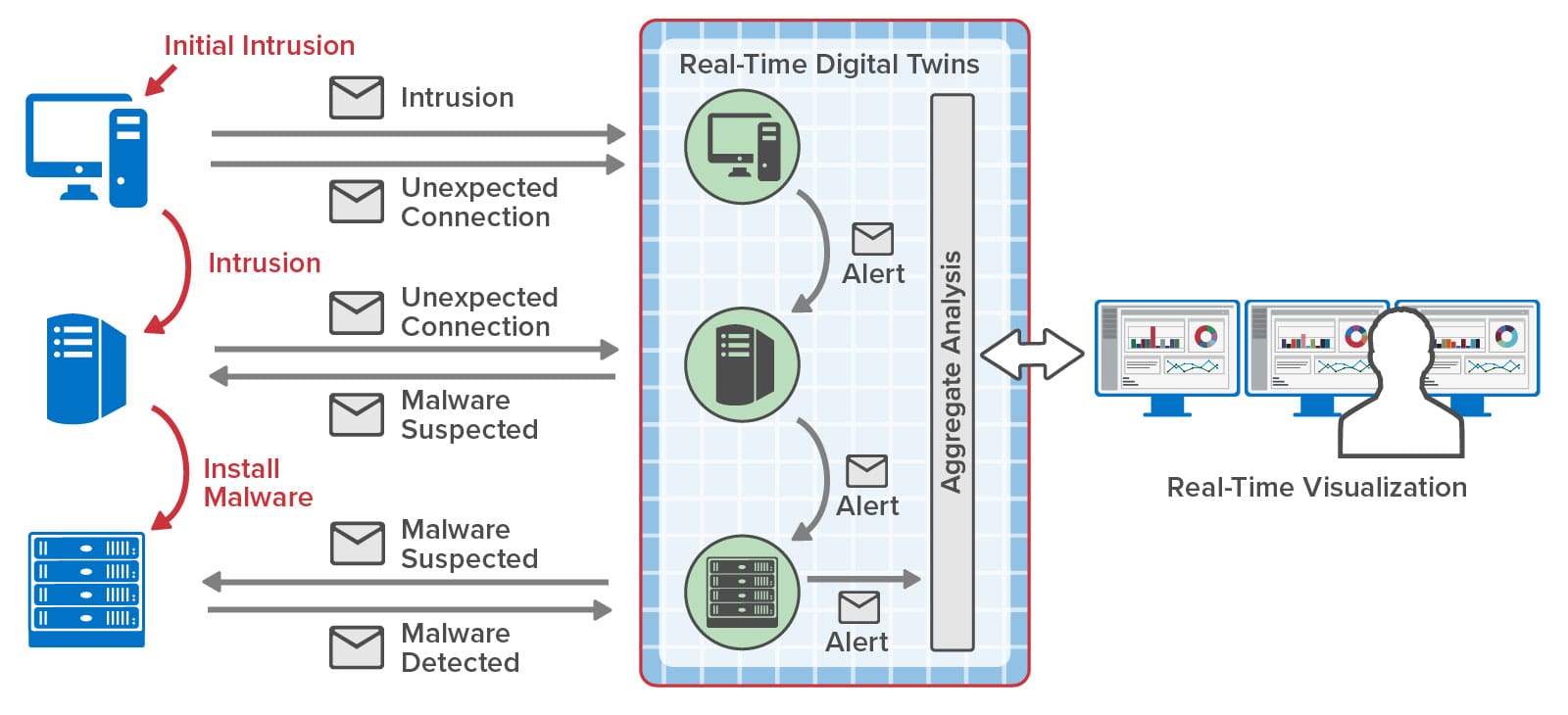
Security information and event management (SIEM) software logs activities, such as user logins, failed attempts, and potentially malicious events so that security managers can detect and prevent or remediate possible intrusions. Typical SIEM software lets managers create and apply rules to event logs to extract information that should be alerted, such as identification of a chain of activity (“kill chain”) that leads to injection of malware or other malicious actions. Dashboards show managers raw telemetry, such as the number of potentially malicious events by region or events recorded over time. The forensic analysis of logs and display of large volumes of aggregated telemetry make it difficult for managers to spot and mitigate emerging kill chains, such as a chain of intrusions within a corporate infrastructure leading to an exploitation:
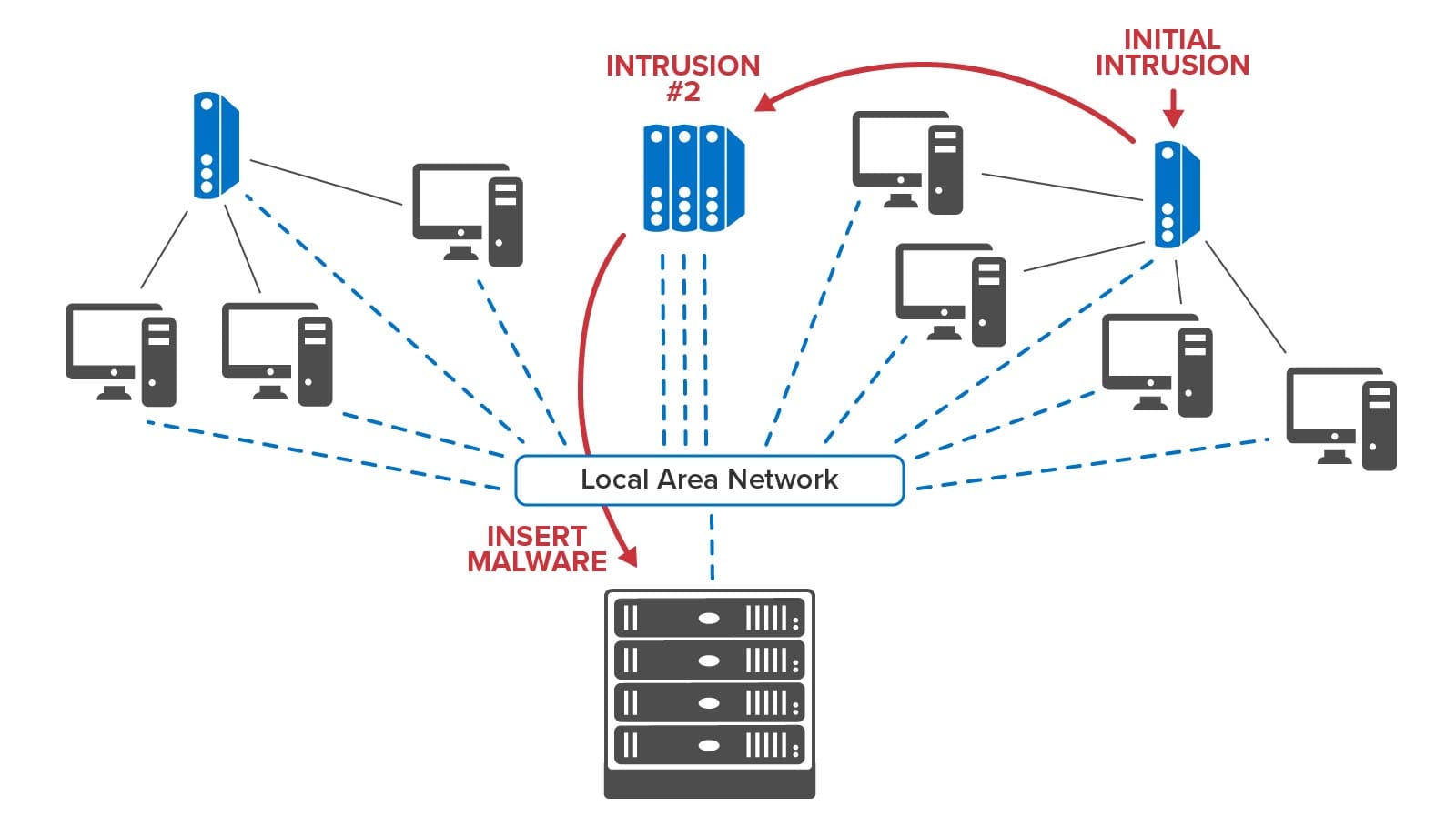
By hosting event tracking in memory with contextual information and by reacting within milliseconds to potential threats, RTDTs can help accelerate the detection and interruption of cyber kill chains. Many SIEM platforms maintain software agents distributed throughout an organization’s IT infrastructure to report suspicious events that could signal a possible intrusion. Instead of just feeding these events to a dashboard and to a log for analysis, they can also be reported to an RTDT for each agent. Each RTDT can immediately run a machine learning algorithm to classify activity and signal alerts when a threat is predicted. Moreover, if an agent’s event includes information about an outbound connection to another node in the network, the RTDT can send a message to that node’s RTDT to enrich its context and assist in detection of a potential kill chain. By dynamically sending messages to and among RTDTs that attempt to track the progression of an intruder within a network, RTDTs can build a real-time map of potential kill chains and possibly get ahead of the intruder to block threats.
The following diagram illustrates the use of RTDTs to map the progression of incoming threats as they migrate among nodes of an organization’s infrastructure:
Summing Up
Physical and cyber security systems, as well as safety systems, require simultaneous, real-time assessment of numerous interactions in the context of allowed and expected usage patterns. Instead of relying on today’s offline computing techniques and forensic analysis to perform the bulk of the work, these systems can dramatically boost their effectiveness by employing next generation in-memory computing techniques, such as real-time digital twins. This software architecture offers a highly attractive combination of intelligence, agility, responsiveness, and scalability to meet the ever-increasing challenges faced by today’s security and safety systems.
The post Building the Next Generation in Physical and Cyber Security with Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Deploying Real-Time Digital Twins On Premises with ScaleOut StreamServer DT appeared first on ScaleOut Software.
]]>
With the ScaleOut Digital Twin Streaming Service, an Azure-hosted cloud service, ScaleOut Software introduced breakthrough capabilities for streaming analytics using the real-time digital twin concept. This new software model enables applications to easily analyze telemetry from individual data sources in 1-3 milliseconds while maintaining state information about data sources that deepens introspection. It also provides a basis for applications to create key status information that the streaming platform aggregates every few seconds to maximize situational awareness. Because it runs on a scalable, highly available in-memory computing platform, it can do all this simultaneously for hundreds of thousands or even millions of data sources.
The unique capabilities of real-time digital twins can provide important advances for numerous applications, including security, fleet telematics, IoT, smart cities, healthcare, and financial services. These applications are all characterized by numerous data sources which generate telemetry that must be simultaneously tracked and analyzed, while maintaining overall situational awareness that immediately highlights problems of concern an/or opportunities of interest. For example, consider some of the new capabilities that real-time digital twins can provide in fleet telematics and vaccine distribution during COVID-19.
To address security requirements or the need for tight integration with existing infrastructure, many organizations need to host their streaming analytics platform on-premises. Scaleout StreamServer® DT was created to meet this need. It combines the scalable, battle-tested in-memory data grid that powers ScaleOut StreamServer with the graphical user interface and visualization features of the cloud service in a unified, on-premises deployment. This gives users all of the capabilities of the ScaleOut Digital Twin Streaming Service with complete infrastructure control.
As illustrated in the following diagram, ScaleOut StreamServer DT installs its management console on a standalone server that connects to ScaleOut StreamServer’s in-memory data grid. This console hosts the graphical user interface that is securely accessed by remote workstations within an organization. It also deploys real-time digital twin models to the in-memory data grid, which hosts instances of digital twins (one per data source) and runs application-defined code to process incoming messages. Message are delivered to the grid using messaging hubs, such as Azure IoT Hub, AWS IoT Core, Kafka, a built-in REST service, or directly using APIs.
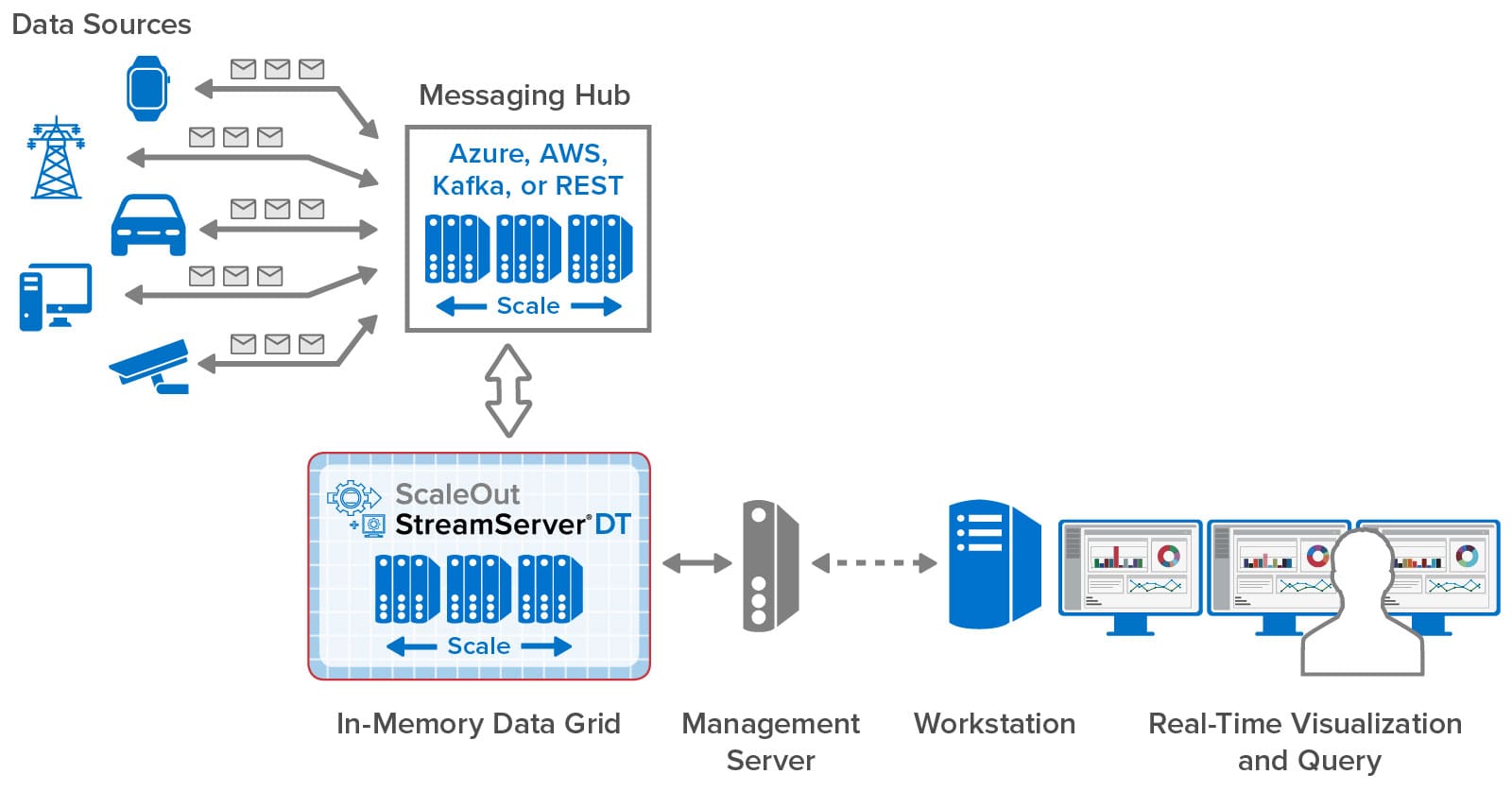
The management console installs as a set of Docker containers on the management server. This simplifies the installation process and ensures portability across operating systems. Once installed, users can create accounts to control access to the console, and all connections are secured using SSL. The results of aggregate analytics and queries performed within the in-memory data grid can then be accessed and visualized on workstations running throughout an organization.
Because ScaleOut’s in-memory data grid runs in an organization’s data center and avoids the requirement to use a cloud-hosted message hub or REST service, incoming messages from data sources can be processed with minimum latency. In addition, application code running in real-time digital twins can access local resources, such as databases and alerting systems, with the best possible performance and security. Use of dedicated computing resources for the in-memory data grid delivers the highest possible throughput for message processing and real-time analytics.
While cloud hosting of streaming analytics as a SaaS (software-as-a-service) offering creates clear advantages in reducing capital costs and providing access to highly elastic computing resources, it may not be suitable for organizations which need to maintain full control of their infrastructures to address security and performance requirements. ScaleOut StreamServer DT was designed to meet these needs and deliver the important, unique benefits of streaming analytics using real-time digital twins to these organizations.
The post Deploying Real-Time Digital Twins On Premises with ScaleOut StreamServer DT appeared first on ScaleOut Software.
]]>The post Building Real-Time Digital Twins with a Rules Engine appeared first on ScaleOut Software.
]]>
Simplified Creation of Analytics Logic Lowers the Learning Curve for Using Digital Twins in Streaming Analytics
As discussed in earlier blog posts, real-time digital twins offer a breakthrough new approach to streaming analytics by providing a means for continuously analyzing each incoming telemetry stream from thousands of data sources. Because they maintain state information about each data source, they can immediately spot issues unique to that data source and generate alerts within a few milliseconds. In contrast, conventional “batch-oriented” streaming analytics typically do not mine this telemetry in real-time and may not uncover important, actionable trends for several minutes or hours. These unique capabilities, combined with real-time data aggregation to boost situational awareness, give real-time digital twins unique advantages in a wide range of applications, including contact tracing, telematics, logistics, smart cities, security, financial services, healthcare, and much more.
Real-time digital twins provide a software technique for orchestrating the execution of analytics code that examines incoming messages from a single data source and maintains state information about that data source. The ScaleOut Digital Twin Streaming Service hosts instances of real-time digital twins in the Microsoft Azure cloud or on-premises, manages the delivery of messages from various message hubs, and implements data aggregation and visualization. Application developers typically implement a single method containing analytics code written in standard programming languages, such as Java, C#, and JavaScript, which take full advantage of the object-oriented, real-time digital twin model. Here is a depiction of a real-time digital twin showing the message processing code and state information unique to a specific data source:
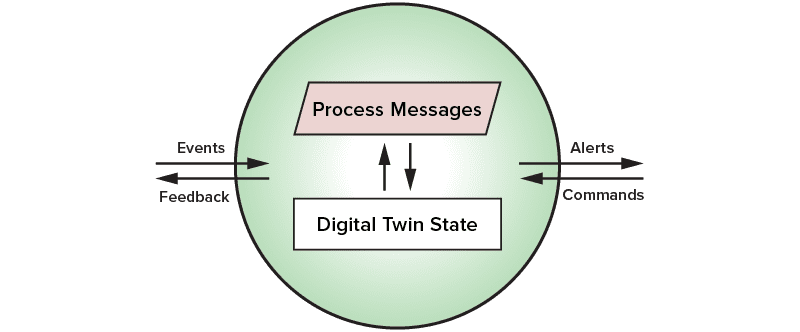
Rules-Based Real-Time Digital Twins
In many applications, a rules-based formulation of analytics logic can simplify application code and open up development of real-time digital twins to analysts who lack object-oriented programming experience. Rules-based algorithms have been widely adopted over the years and proven to provide a straightforward technique for expressing business logic in numerous applications and expert systems. In their simplest form, rules are expressed as “IF condition THEN action” statements which are executed sequentially by a “rules engine.” Other rules which just perform actions, such as calculations or message sending, can be expressed with “DO action” statements. These rules replace programming code with simple, highly readable statements that can be used in many applications where more complex logic is not required.
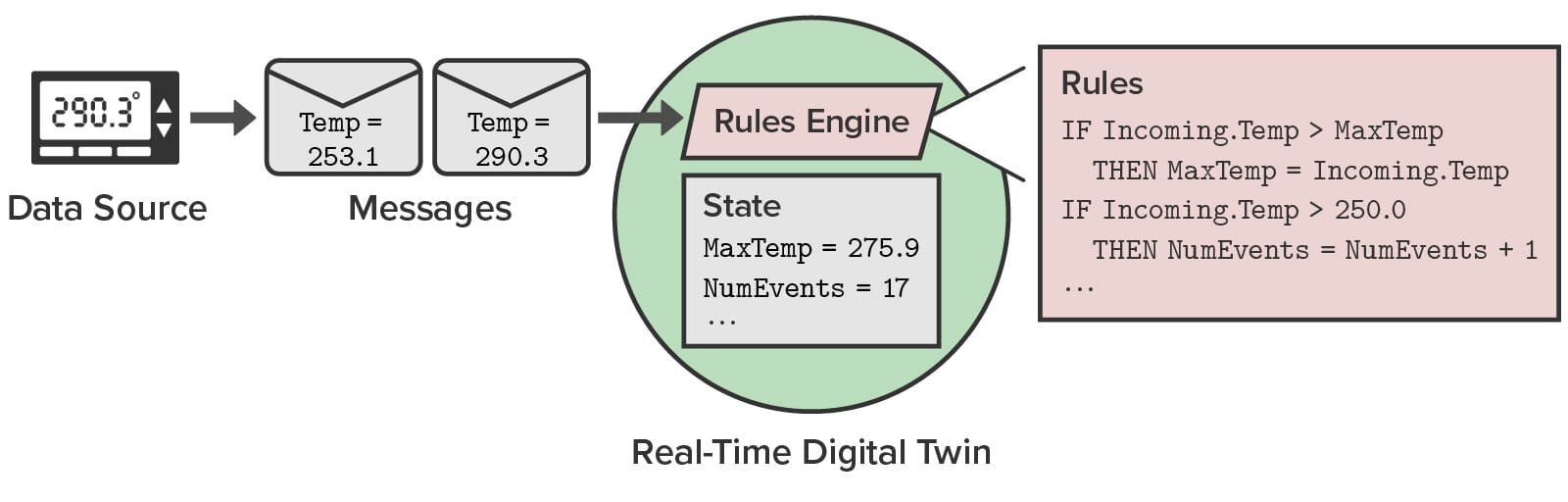
For example, consider an IoT application in which a real-time digital twin is monitoring messages sent from a thermometer and looking for a situation in which the temperature either spikes beyond an allowed limitof 250 deg. or exceeds an allowed average value of 112 deg. This logic could be expressed with the following rules, which are executed for each incoming message. Note that the temperature reading within the message is called Incoming.Temp here, and the other variables maintain state information within the real-time digital twin’s instance for this thermometer. For example, the number of temperature spikes is maintained in the variable NumEvents.
DO CurrentTemp = Incoming.Temp IF CurrentTemp > MaxTemp THEN MaxTemp = CurrentTemp DO AverageTemp = AverageTemp * NumSamples + CurrentTemp DO NumSamples = NumSamples + 1 DO AverageTemp = AverageTemp / NumSamples IF MaxTemp > 250.0 THEN NumEvents = NumEvents + 1 IF MaxTemp > 250.0 THEN LogMessage.Message = "Max temp exceeded" AND LogMessage IF AverageTemp > 112.0 THEN LogMessage.Message = "Average temp exceeded" AND LogMessage
The following diagram shows how message are delivered to a thermometer’s real-time digital twin instance and are analyzed by the rules engine:
Development Tool for Building Rules-Based Models
To simplify the development of rules-based analytics code for real-time digital twins, ScaleOut Software has developed the ScaleOut Rules Engine Development Tool. This Windows-based graphical development environment enables application developers to create and test rule-based digital twin models prior to deploying them on the streaming service for production use. Using this tool, developers create a model by specifying:
- Instance properties to be tracked, such as AverageTemp, MaxTemp, and NumEvents in the example
- Message properties that will be used, such as Incoming.Temp for incoming messages
- Rules to be executed (like the ones listed above)
The tool validates the rules when they are created to make sure that they will execute. Next, the user can test the model by sending it messages and observing changes in the values of the properties. The rules can be run one at a time for each message to verify that they are creating the desired state changes and outgoing messages. The development tool can simulate sending message back to the data source, to another real-time digital twin instance, or to the message log in the service’s UI.
Here is a screenshot of the development tool during a test of a rules-based model for a thermometer:
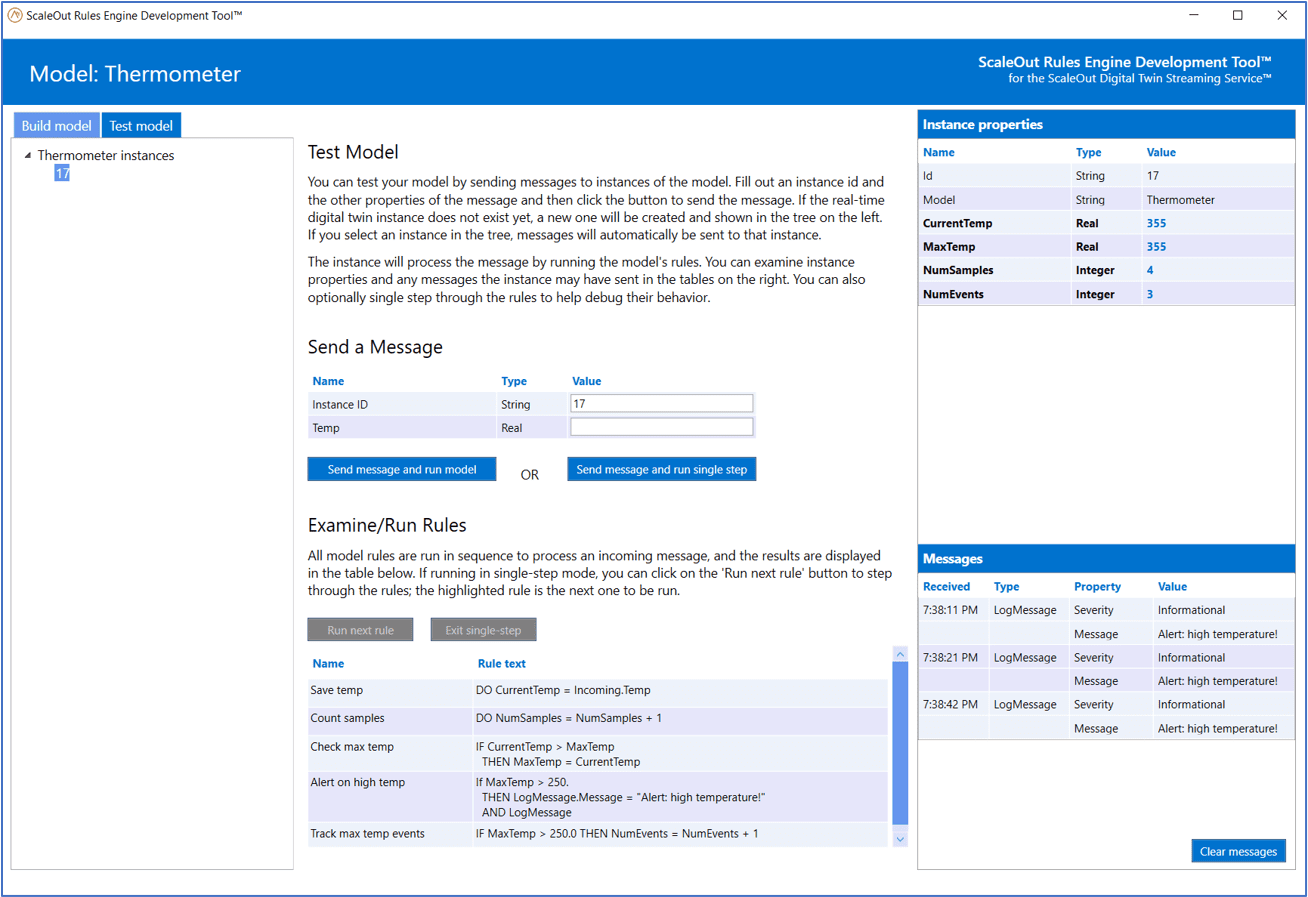
Note that during production use, the streaming service can aggregate instance properties across all real-time digital twin instances and visualize the results. The rules engine running in each real-time digital twin instance updates property values as it processes incoming messages, and the results are immediately aggregated. For example, if the thermometers supplied their locations, the average temperature could be plotted by region. This allows managers to immediately spot patterns in the data across all data sources and direct responses where they are most urgently needed.
Summing Up
The integration of a rules engine within real-time digital twins lowers barriers to entry in creating streaming analytics. The highly intuitive formulation of application logic as a set of rules to be sequentially evaluated makes it straightforward for domain experts to implement streaming analytics for many applications without the need for programming skills. The power of real-time digital twins working together, combined with continuous aggregate analytics, enables telemetry from many thousands of data sources to be simultaneously analyzed and creates a breakthrough in situational awareness.
The post Building Real-Time Digital Twins with a Rules Engine appeared first on ScaleOut Software.
]]>The post Use Digital Twins for the Next Generation in Telematics appeared first on ScaleOut Software.
]]>
Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks
Rapid advances in the telematics industry have dramatically boosted the efficiency of vehicle fleets and have found wide ranging applications from long haul transport to usage-based insurance. Incoming telemetry from a large fleet of vehicles provides a wealth of information that can help streamline operations and maximize productivity. However, telematics architectures face challenges in responding to telemetry in real time. Competitive pressures should spark innovation in this area, and real-time digital twins can help.
Current Telematics Architecture
The volume of incoming telemetry challenges current telematics systems to keep up and quickly make sense of all the data. Here’s a typical telematics architecture for processing telemetry from a fleet of trucks:
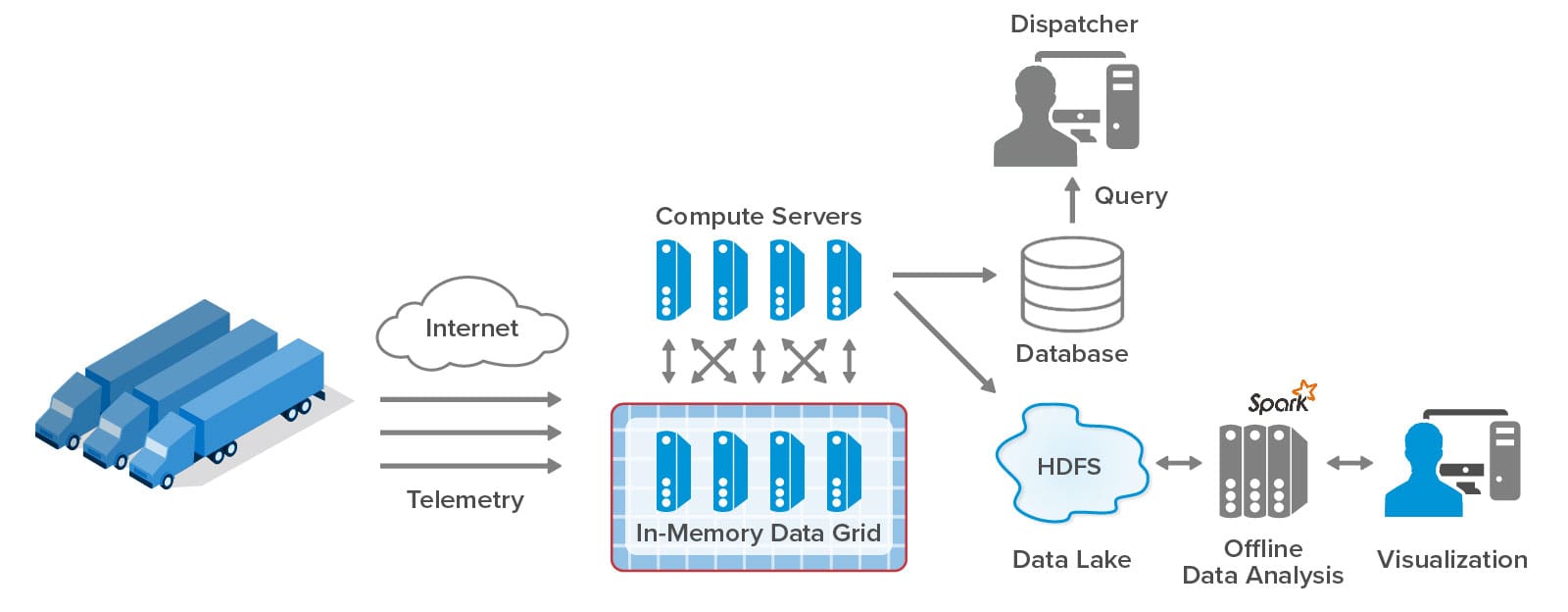
Each truck today has a microprocessor-based sensor hub which collects key telemetry, such as vehicle speed and acceleration, engine parameters, trailer parameters, and more. It sends messages over the cell network to the telematics system, which uses its compute servers (that is, web and application servers) to store incoming messages as snapshots in an in-memory data grid, also known as a distributed cache. Every few seconds, the application servers collect batches of snapshots and write them to the database where they can be queried by dispatchers managing the fleet. At the same time, telemetry snapshots are stored in a data lake, such as HDFS, for offline batch analysis and visualization using big data tools like Spark. The results of batch analysis are typically produced after an hour’s delay or more. Lastly, all telemetry is archived for future use (not shown here).
This telematics architecture has evolved to handle ever increasing message rates (often reaching 2K messages per second), make up-to-the-minute information available to dispatchers, and feed offline analytics. Using a database, dispatchers can query raw telemetry to determine the information they need to manage the fleet in real time. This enables them to answer questions such as:
- “Where is truck 7563?”
- “How long has the driver been on the road?”
- “Which trucks have abnormally high oil temperature?”
Offline analytics can mine the telemetry for longer term statistics that help managers assess the fleet’s overall performance, such as the average length of delivery or routing delays, the fleet’s change in fuel efficiency, the number of drivers exceeding their allowed shift times, and the number and type of mechanical issues. These statistics help pinpoint areas where dispatchers and other personnel can make strategic improvements.
Challenges for Current Architectures
There are three key limitations in this telematics architecture which impact its ability to provide managers with the best possible situational awareness. First, incoming telemetry from trucks in the fleet arrives too fast to be analyzed immediately. The architecture collects messages in snapshots but leaves it to human dispatchers to digest this raw information by querying a database. What if the system could separately track incoming telemetry for each truck, look for changes based on contextual information, and then alert dispatchers when problems were identified? For example, the system could perform continuous predictive analytics on the engine’s parameters with knowledge of the engine’s maintenance history and signal if an impending failure was detected. Likewise, it could watch for hazardous driving with information about the driver’s record and medical condition. Having the system continuously introspect on the telemetry for each truck would enable the dispatcher to spot problems and intervene more quickly and effectively.
A second key limitation is the lack of real-time aggregate analysis. Since this analysis must be performed offline in batch jobs, it cannot respond to immediate issues and is restricted to assessing overall fleet performance. What if the real-time telemetry tracking for each truck could be aggregated within seconds to spot emerging issues that affect many trucks and require a strategic response? These issues could include:
- Unexpected delays in a region due to highway blockages or weather that indicate the need to inform or reroute several trucks
- An unusually large number of soon-to-be timed-out drivers or impending maintenance issues which require making immediate schedule changes to avoid downtime
- Congregated drivers who are impacting on-time deliveries
The current telematics architecture also has inherent scalability issues in the form of network bottlenecks. Because all telemetry is stored in the in-memory data grid and accessed by a separate farm of compute servers, the network between the grid and the server farm can quickly bottleneck as the incoming message rate increases. As the fleet size grows and the message rate per truck increases from once per minute to once per second, the telematics system may not be able to handle the additional incoming telemetry.
Solution: Real-Time Digital Twins
A new software architecture for streaming analytics based on the concept of real-time digital twins can address these challenges and add significant capabilities to telematics systems. This new, object-oriented software technique provides a memory-based orchestration framework for tracking and analyzing telemetry from each data source. It comprises message-processing code and state variables which host dynamically evolving contextual information about the data source. For example, the real-time digital twin for a truck could look like this:
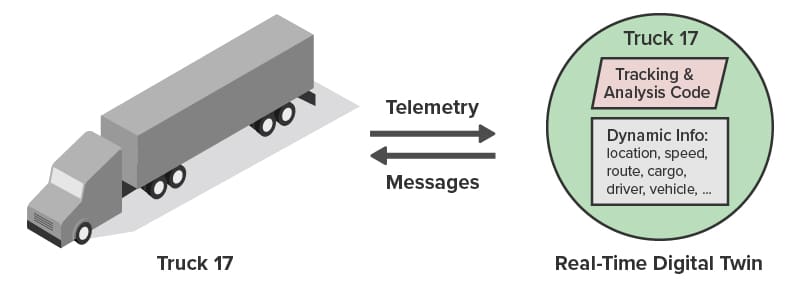
Instead of just snapshotting incoming telemetry, real-time digital twins for every data source immediately analyze it, update their state information about the truck’s condition, and send out alerts or commands to the truck or to managers as necessary. For example, they can track engine telemetry with knowledge of the engine’s known issues and maintenance history. They can track position, speed, and acceleration with knowledge of the route, schedule, and driver (allowed time left, driving record, etc.). Message-processing code can incorporate a rules engine or machine learning to amplify their capabilities.
Real-time digital twins digest raw telemetry and enable intelligent alerting in the moment that assists both drivers and dispatchers in surfacing issues that need immediate attention. They are much easier to develop than typical streaming analytics applications, which have to sift through the telemetry from all data sources to pick out patterns of interest and which lack contextual information to guide them. Because they are implemented using in-memory computing techniques, real-time digital twins are fast (typically responding to messages in a few milliseconds) and transparently scalable to handle hundreds of thousands of data sources and message rates exceeding 100K messages/second.
Here’s a depiction of real-time digital twins running within an in-memory data grid in a telematics architecture:
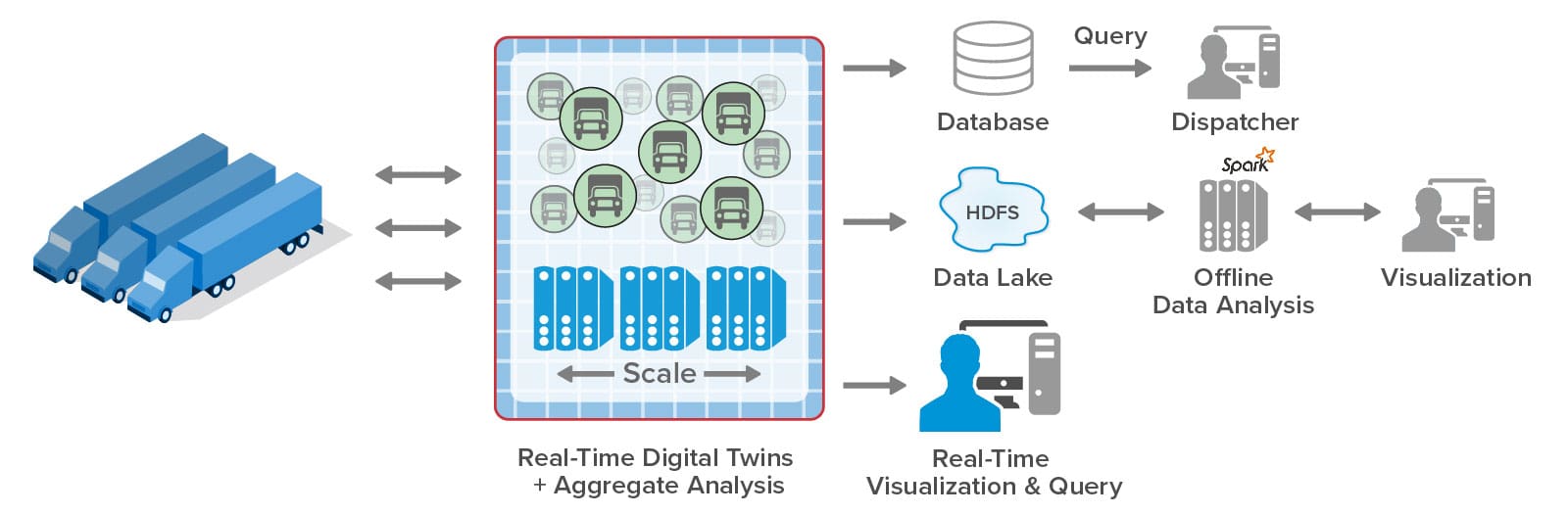
In addition to fitting within an overall architecture that includes database query and offline analytics, real-time digital twins enable built-in aggregate analytics and visualization. They provide curated state information derived from incoming telemetry that can be continuously aggregated and visualized to boost situational awareness for managers, as illustrated below. This opens up an important new opportunity to aggregate performance indicators needed in real time, such as emerging road delays by region or impending scheduling issues due to timed out drivers, that can be acted upon while new problems are still nascent. Real-time aggregate analytics add significant new capabilities to telematics systems.
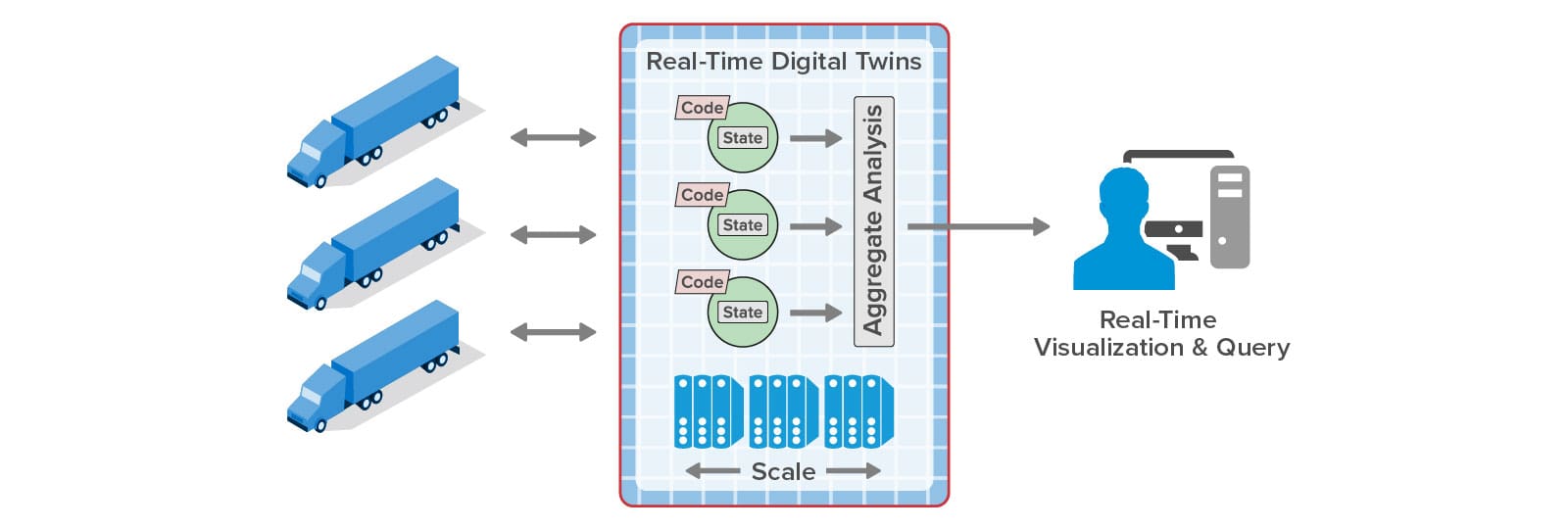
Summing Up
While telematics systems currently provide a comprehensive feature set for managing fleets, they lack the important ability to track and analyze telemetry from each vehicle in real time and then aggregate derived information to maintain continuous situational awareness for the fleet. Real-time digital twins can address these shortcomings with a powerful, fast, easy to develop, and highly scalable software architecture. This new software technique has the potential to make a major impact on the telematics industry.
To learn more about real-time digital twins in action, take a look at ScaleOut Software’s streaming service for hosting real-time digital twins in the cloud or on-premises here.
The post Use Digital Twins for the Next Generation in Telematics appeared first on ScaleOut Software.
]]>The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>
Web applications, such as ecommerce sites and financial services, often need to replicate fast-changing, in-memory data across multiple data centers or cloud regions. As part of an overall strategy for disaster recovery, cross-site data replication ensures that mission-critical data is continuously available, even if one site goes offline.
Many applications need to use two (and sometimes more) sites in an “active-active” manner, distributing the workload across the sites. Here are some real-world applications we have seen. Ecommerce applications need to maintain shopping carts at multiple sites and distribute the workload from their shoppers with a global load-balancer. Cell phone providers need to keep their lists of available mobile numbers consistent across sites as individual stores allocate them. Conference-management companies need to keep attendee lists and schedules consistent at conference sites and their central data center.
Let’s take a closer look at an ecommerce site using a global load-balancer to distribute incoming web requests to multiple sites. This approach lets the web application take advantage of the processing power at multiple sites during normal operations. However, it creates the challenge of coordinating access to in-memory objects which are replicated across two or more sites. This can add substantial complexity if handled by the application.
Here’s an example of an ecommerce site using a global load-balancer to distribute incoming web requests across two sites, each of which hosts shopping carts within an in-memory data grid (also called a distributed cache), such as ScaleOut StateServer®. A web shopper might select a pair of shoes and place them in the shopping cart followed by selecting a tennis racket. As shown in the following diagram, the global load-balancer sends the first request to site 1 and the second request to site 2 in this example:
After the first request completes, the in-memory data grid at site 1 replicates the cart to site 2. The global load-balancer then sends the second request to site 2, which adds the tennis racket to the cart. Finally, site 2 replicates the changes back to site 1 so that both sites have the latest copy of the shopping cart.
What happens if replication from site 1 to site 2 is slightly delayed? After site 2 puts the tennis racket in the cart, the incoming replicated update arrives and overwrites the cart. This causes both sites to lose the update at site 2, and the shopper will undoubtedly be annoyed to find that the tennis racket is missing from the cart:
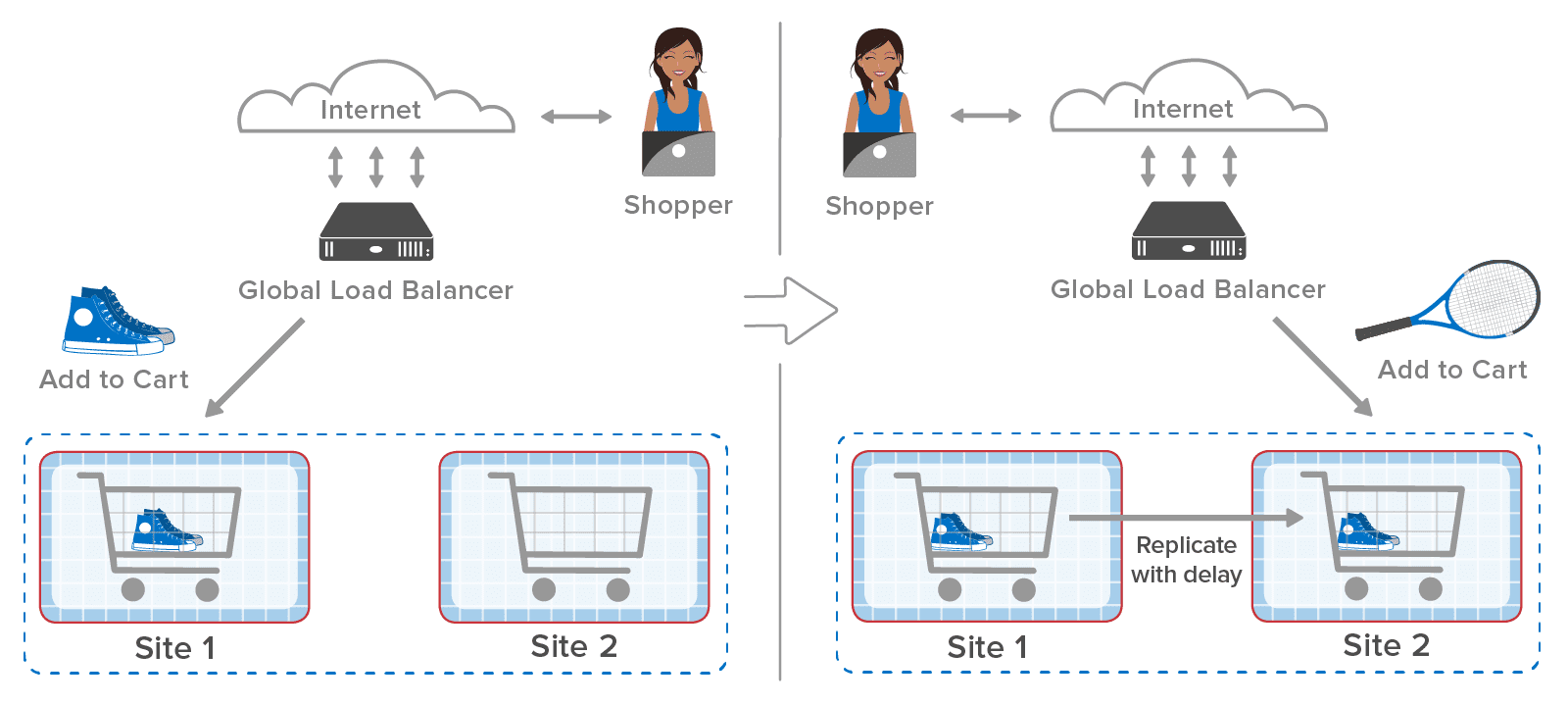
The solution to this problem is to have the web applications at both sites synchronize updates to the shopping carts. This ensures that only one site at a time updates the shopping cart and that each site always sees the latest version of the in-memory object. Using ScaleOut GeoServer Pro, applications can use standard object-locking APIs for this purpose, just as they would to coordinate object access within a single in-memory data grid:
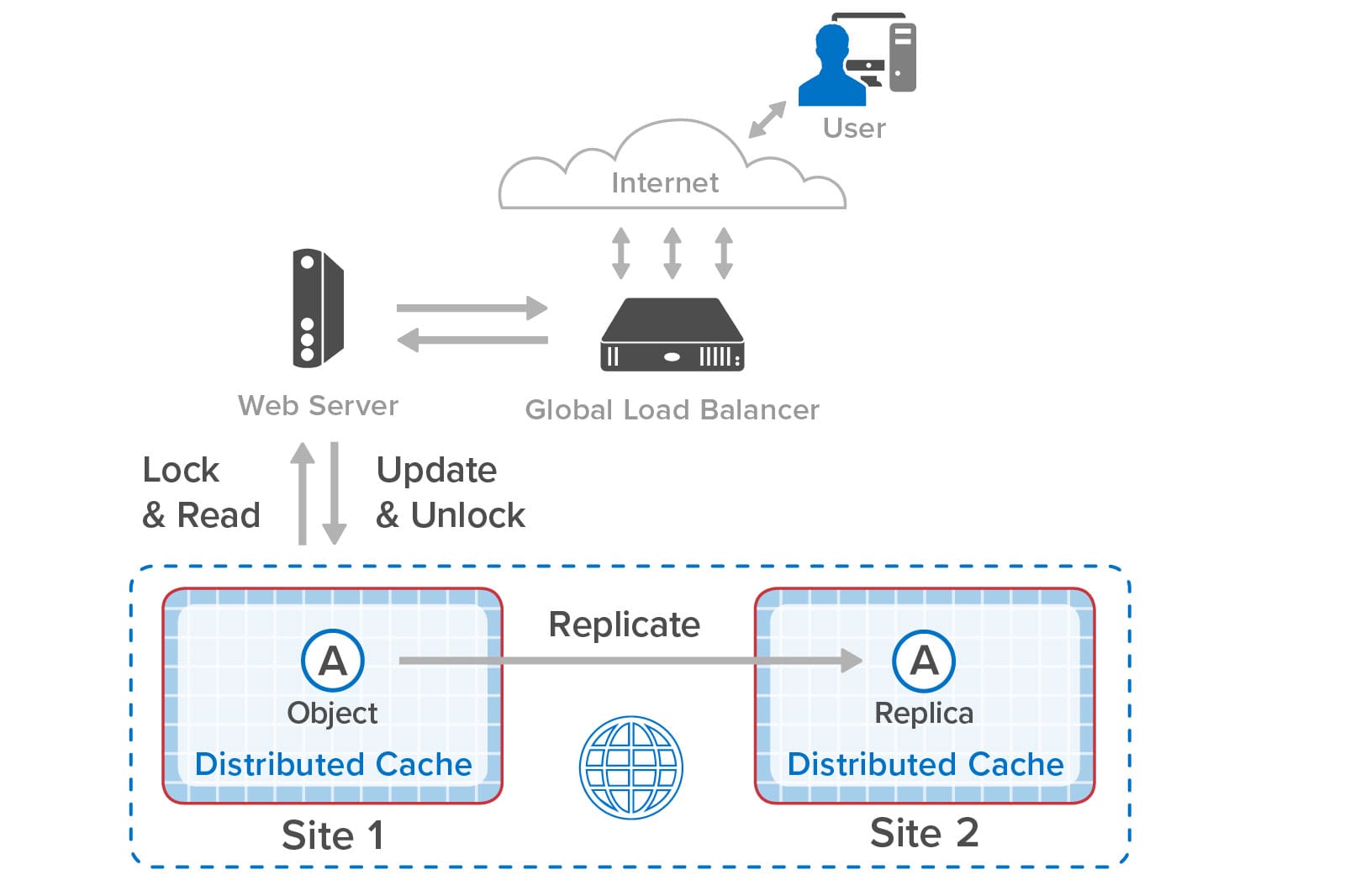
After the web application on site 1 updates and unlocks object A (the shopping cart in our example), site 1 replicates the update to site 2. When the global load-balancer sends the next request to site 2, the web application on that site 2 also locks and reads the object, updates it, and then unlocks it:
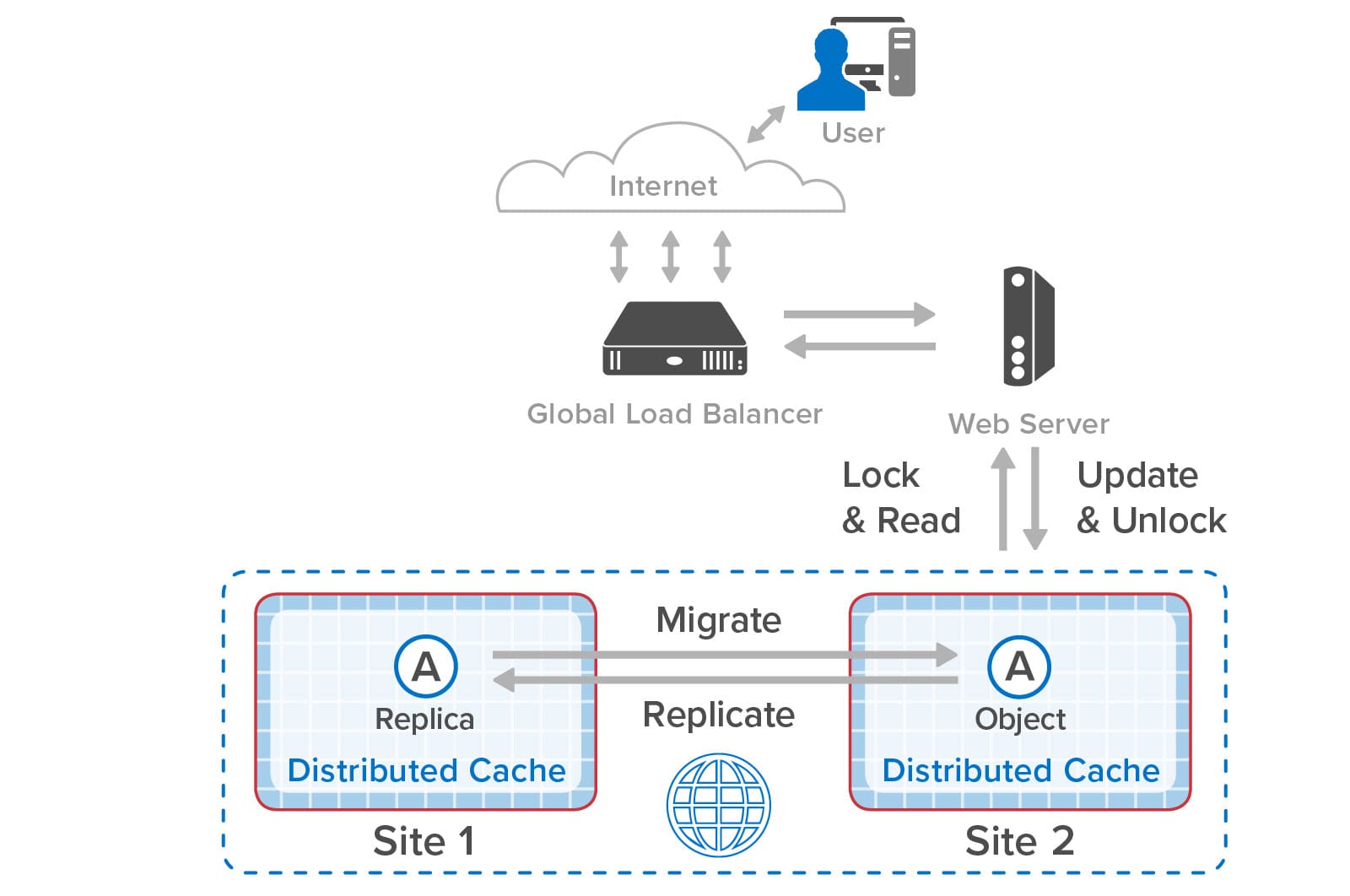
When the object is locked on site 2, ScaleOut GeoServer Pro makes sure that the application sees the latest version of the object. It does so by migrating ownership of the object to site 2 and checking that it has the latest version. Although this requires a round trip to site 1, once a site gains ownership, all further accesses are local until the other site again attempts to lock the object and request ownership. If the global load-balancer avoids ping-ponging between sites with every web request, the latency to lock an object remains low.
Should the wide area network (WAN) connecting the two sites fail, or if the remote site goes offline, the two sites can operate independently; this is called “split brain” mode in distributed systems. They detect the WAN failure and automatically promote local replica objects as needed to gain ownership when requesting a lock. This enables uninterrupted operations that make use of object replicas held at each site. By combining object replication with synchronized access, applications enjoy the full benefits of synchronized object access across sites during normal operations and uninterrupted access during WAN or site outages:
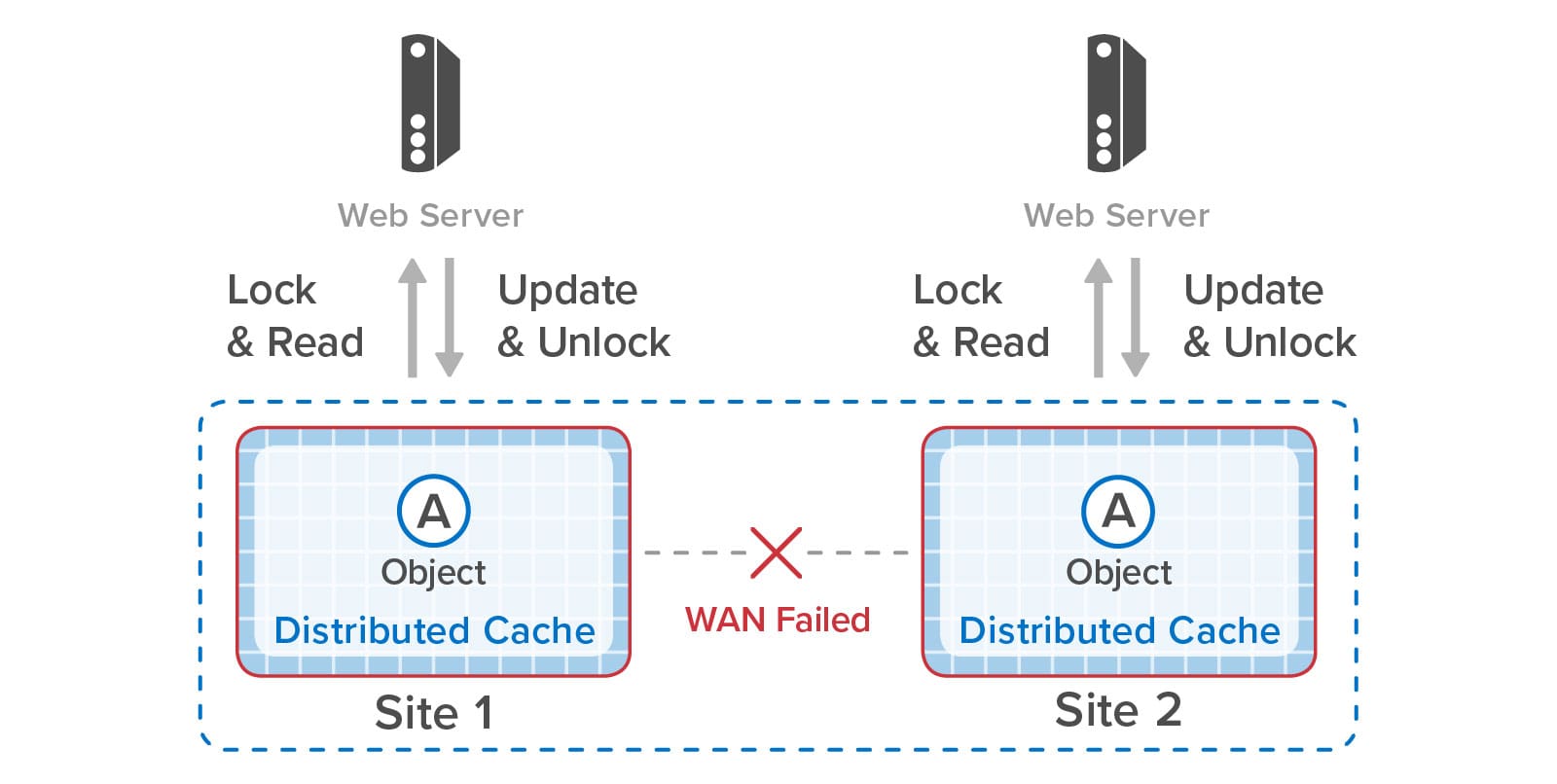
A key challenge created by split-brain mode is how to restore normal operations after an outage has been corrected. For example, the following diagram shows the two sites in our shopping example operating independently during a WAN outage that occurs between the two web requests. Site 1 adds the shoes to its shopping cart but is unable to replicate that update to site 2. The web application on site 2 then places the tennis racket in its shopping cart:
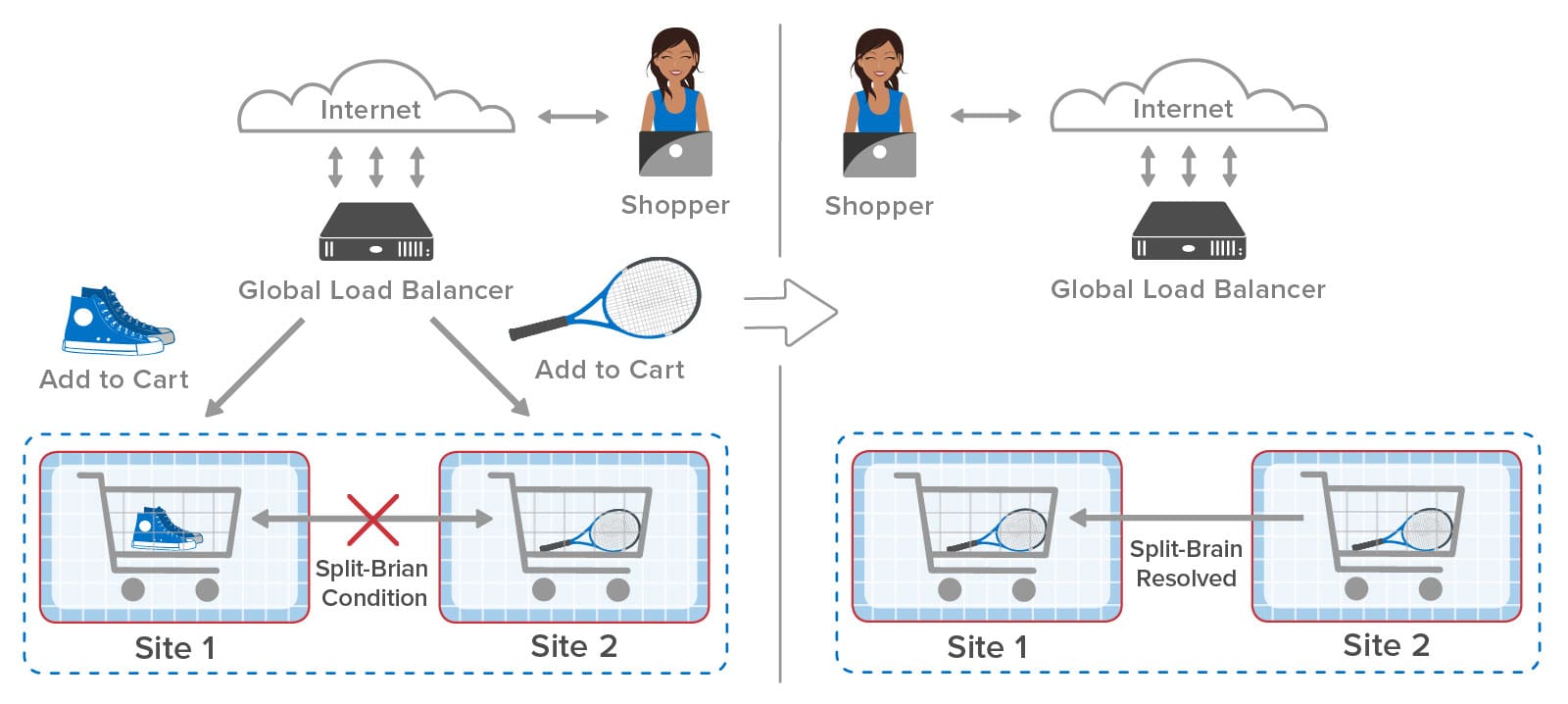
After the WAN is restored, the two sites have to resolve the differences in the contents of their copies of stored objects. Unless the application uses special, conflict-free data types that can be merged (and this is rare for most applications), a heuristic needs to be used to resolve conflicts. ScaleOut GeoServer Pro automatically resolves conflicts for each pair of object copies by selecting the copy with the latest update time or randomly picking one of the copies if the update times are the same. So in this case, both sites are updated with the version of the shopping cart holding the tennis racket. (This will be another source of annoyance for our shopper, but at least the ecommerce site survived a WAN outage without interruption.)
ScaleOut GeoServer Pro resolves split-brain conflicts as it detects them when updates are performed and then are successfully replicated across the WAN. It also has to resolve the fact that both sites now think they own the same object, and it handles this by randomly picking a site to retain ownership. As the two sites attempt to lock and read the object, ownership will then automatically migrate to the site where it’s needed.
One more key benefit of ScaleOut GeoServer Pro is that it lets applications efficiently access objects that have slowly changing contents (such as product descriptions, schedules, and portfolio lists) without making repeated WAN accesses. Sites that are configured for bi-directional replication have immediate access to replicas when just reading but not updating remote objects. Other sites can be configured to maintain local copies of remote objects (called “proxies”) that can periodically poll for updates using a configurable timeout. This minimizes WAN accesses while allowing applications to track changes in objects stored at remote sites.
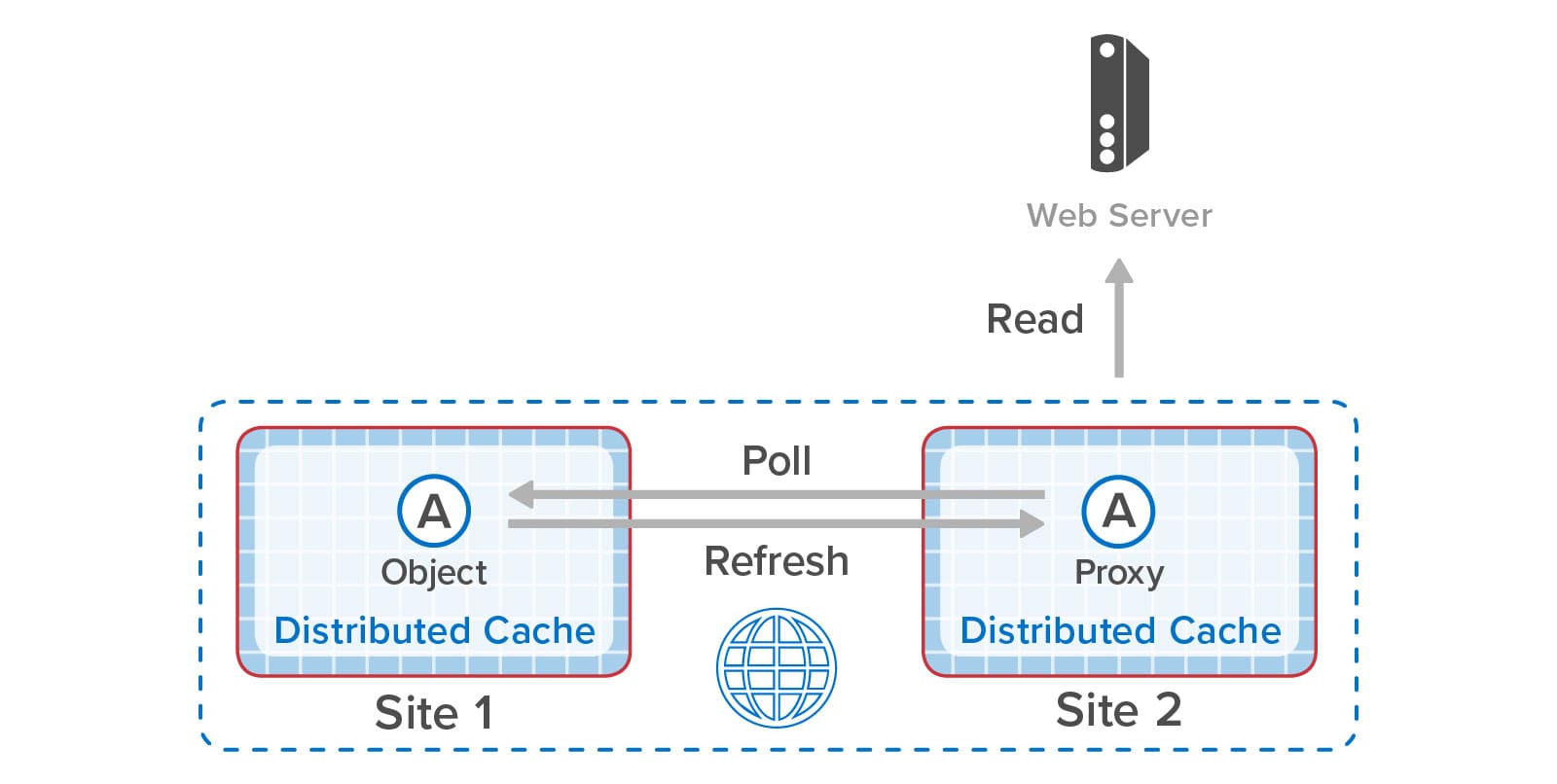
To illustrate how all of these features can work together, the following diagram shows two sites on the west coast of the U.S. configured for bi-directional replication and synchronized access along with additional “satellite” sites in other states that are periodically polling to read data held in the “live” data centers:
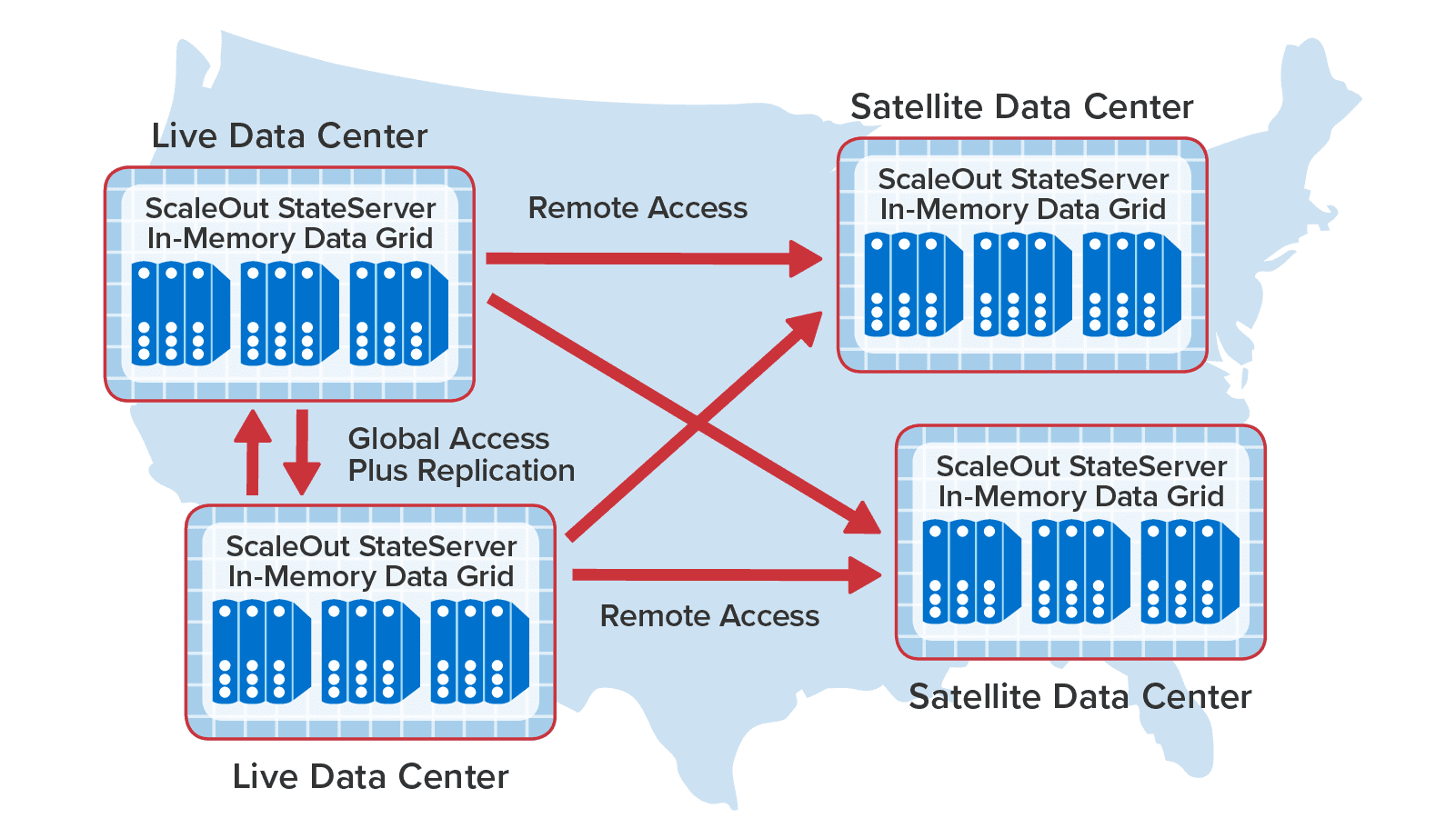
With its advanced capabilities for combining data replication with synchronized access, ScaleOut GeoServer Pro takes a leadership position among commercial in-memory data grids by enabling applications to seamlessly access and update objects replicated across data centers. This solves a long-standing challenge for applications that actively maintain mission-critical data at multiple sites and further extends the power of in-memory data grids to manage fast-changing business data.
The post Combine Data Replication Across Sites with Synchronized Access appeared first on ScaleOut Software.
]]>The post ScaleOut Software Releases New Video on Real-Time Digital Twins appeared first on ScaleOut Software.
]]>
Check out this new video which depicts the challenges in using conventional tools for streaming analytics to track and respond to thousands of data sources in a live system. Whether you are keeping track of a fleet of trucks or sensors in a smart city, the overwhelming amount of incoming telemetry from countless data sources can create a “data monster” that threatens your ability to perform real-time monitoring and maintain the necessary situational awareness.
As the video shows, ScaleOut’s real-time digital twins running in the ScaleOut Digital Twin Streaming Service can tame your data monster by separately tracking each data source using dynamic state information. They enable fast introspection on dynamic changes and immediate, focused responses. In addition, real-time digital twins continuously gather information which the streaming service can aggregate and visualize in real time to quickly surface issues and enable strategic responses.
Grab your popcorn and then click on the image below to watch the video:

We hope you enjoyed the video. Here’s how to learn more:
- To learn more about the value of real-time digital twins in streaming analytics, click here.
- To learn more about the ScaleOut Digital Twin Streaming Service, click here.
- For detailed technical information, take a look at the User Guide here.
- To contact us and talk about how real-time digital twins can help tame your data monster, click here.
The post ScaleOut Software Releases New Video on Real-Time Digital Twins appeared first on ScaleOut Software.
]]>The post Using Real-Time Digital Twins for Corporate Contact Tracing appeared first on ScaleOut Software.
]]>
Until a COVID-19 vaccine is widely available, getting back to work means keeping a close watch for outbreaks and quickly containing them when they occur. While the prospects for accomplishing this within large companies seem daunting, tracking contacts between employees may be much easier than for the public at large. This blog post explains how a software application built with a new software construct called real-time digital twins makes this possible.
Tracking Employees Using Real-Time Digital Twins
In an earlier blog post, we saw how real-time digital twins running in the ScaleOut Digital Twin Streaming Service can be used to track employees within a large company using a technique called “voluntary self-tracing.” In this post, we’ll take a closer look at its implementation in a demo application created by ScaleOut Software. We’ll also look at a companion mobile app that allows employees to log contacts with colleagues outside their immediate teams and to notify the company and their contacts if they test positive for COVID-19.
The demo application creates a memory-based real-time digital twin for each employee. Using information from the company’s organizational database, it populates each twin with the employee’s ID, team ID, department type, and location. The twin also keeps a list of the employee’s contacts within the organization (as well as community contacts, discussed below). This allows immediate colleagues and their contacts to be notified if an employee tests positive. The following diagram illustrates an employee’s real-time digital twin and the state data it holds; details about the contact tracing code are explained below:
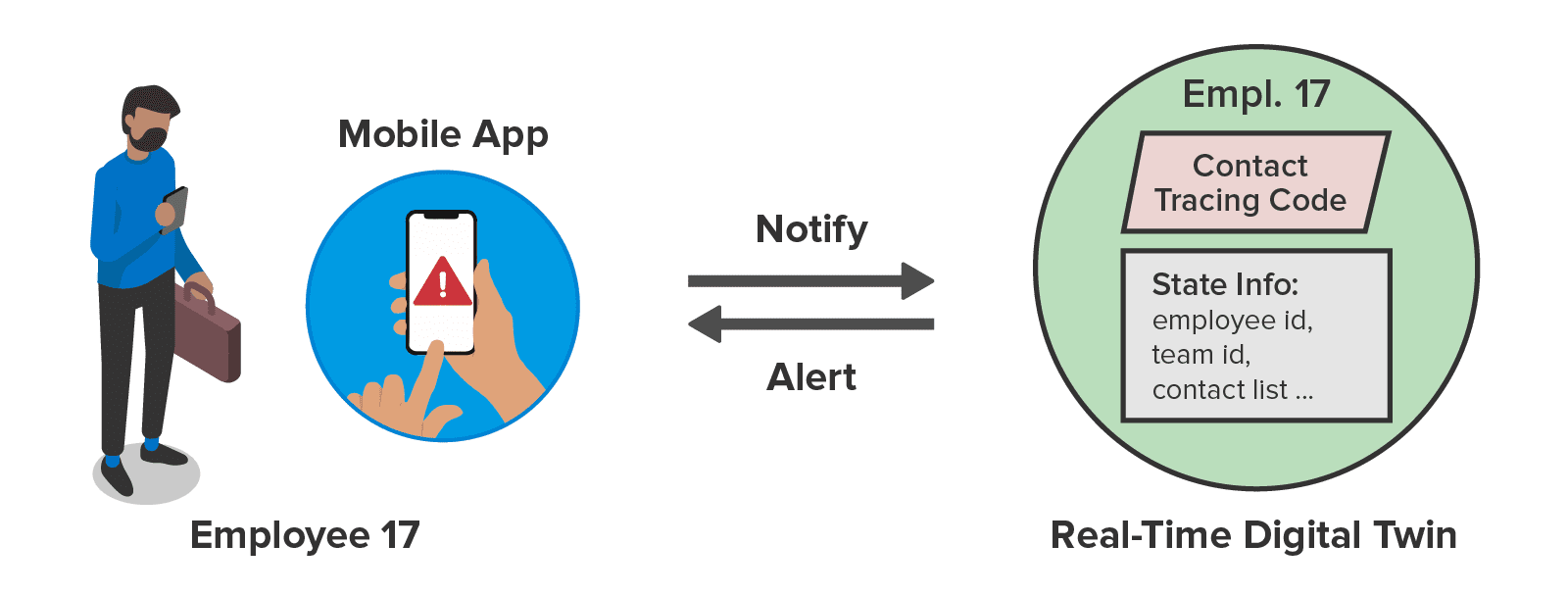
The twin automatically populates its contact list with the other members of the employee’s team, based on the expectation that team members are in daily contact. Using the mobile app, employees can log one-time and recurring contacts with colleagues in other teams, possibly at different office locations. In addition, they can log contacts outside the company, such as taxi rides, airline flights, and meals at restaurants, so that community members can be notified if an employee was exposed to COVID-19.
An employee can use the mobile app to notify their real-time digital twin of a positive test for COVID-19. Code running in the twin then sends messages to the real-time digital twins for all contacts in the employee’s list. These twins in turn send messages to their contacts, and so on, until the twins for all contacts have been notified. (The algorithm avoids unnecessary messages to team members and circular paths among twins.) The twin then sends a push notification to each affected employee through the mobile app, alerting them to the possible exposure and the number of intermediate contacts between themselves and the infected person. Because real-time digital twins are hosted in memory, all of this happens within seconds, enabling affected employees to immediately self-quarantine and obtain COVID-19 tests.
Here’s an illustration of the chain of contacts originating with an employee who reports testing positive. (Note that the outbound notifications from the twins to the employees’ mobile devices are not shown here.)
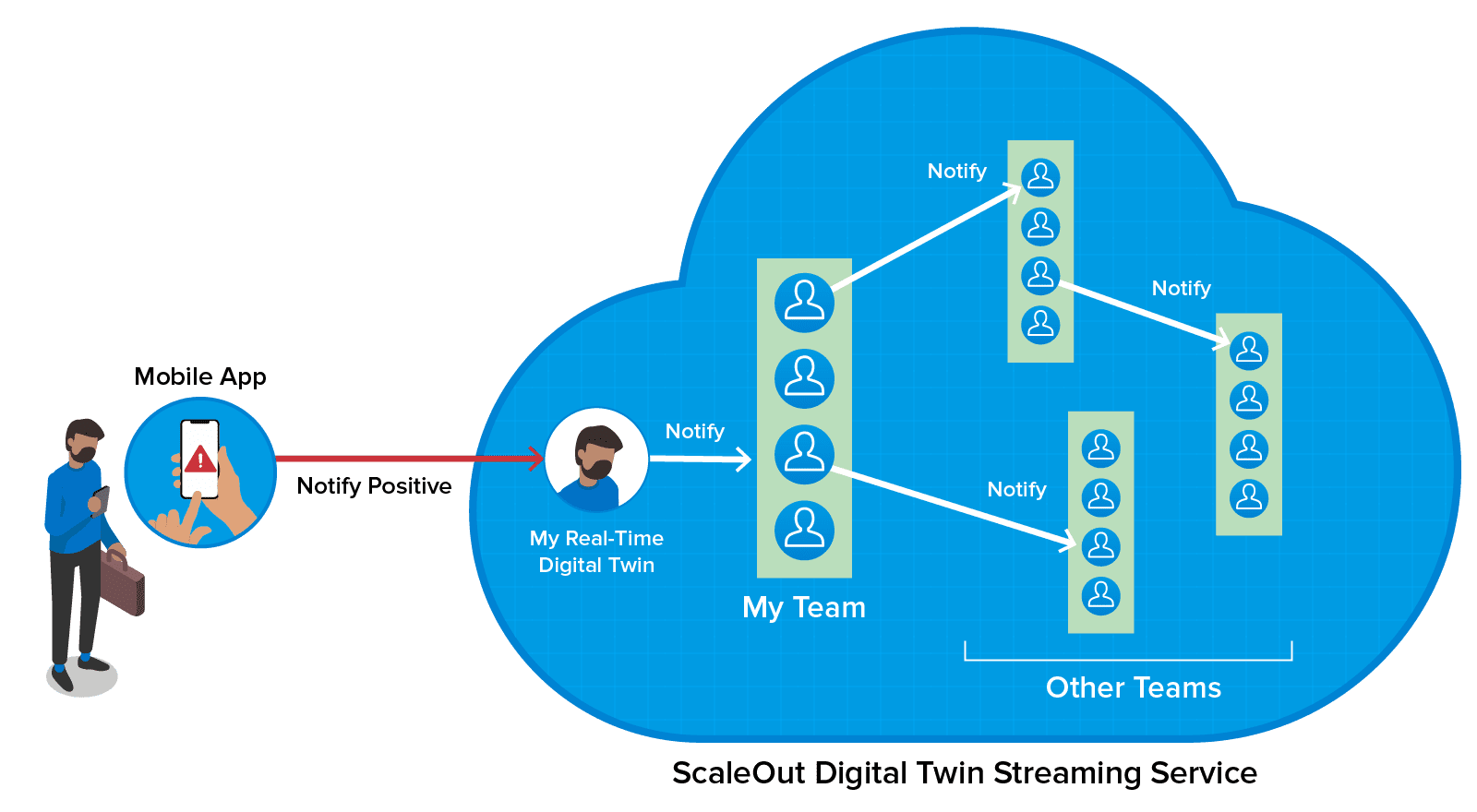
What’s in the Real-Time Digital Twin?
As illustrated in the first diagram, each real-time digital twin hosts two components, state data and a message-processing method. These are defined by the contact tracing application and can be written in C#, Java, or JavaScript. (C# was used for the demo application.) The state data is unique for each employee and contains the employee’s information and contact list, along with useful statistics, such as how often the employee has been alerted about a possible exposure. The message-processing method’s code is shared by all twins. It receives messages from the mobile app or from other twins (each corresponding to a single employee) and uses application-defined code to process these messages.
Messages from the mobile app can request to add or remove a contact from the list. For new contacts, they include parameters such as the employee ID of the contact and whether the contact will be recurring. (Users also can record contacts using calendar events.) Messages from the mobile app can also request the current contact list for display, signal that the employee has tested positive or negative, and request current notifications. Messages from other real-time digital twins signal that the corresponding employees have been exposed and provide additional information, such as the number of intermediate contacts and the location of the initial employee who tested positive.
The application’s message-processing code responds to these messages and implements the spanning-tree notification algorithm that alerts other twins on the contact list. The streaming service handles the rest, namely the details of message delivery, retrieval and updating of state information, and managing the execution platform.
Using the Mobile App
The following animated diagram shows how an employee can add a contact with a company colleague outside of their immediate team or with a community contact during business travel (left screenshot). If the employee tests positive, the employee can use the mobile app to report this to the company (middle screenshot). All employees are then notified using the mobile app, as shown in the right screenshot. Community contacts are reported to managers who communicate with outside points of contact, such as airlines, taxi companies, and restaurants.
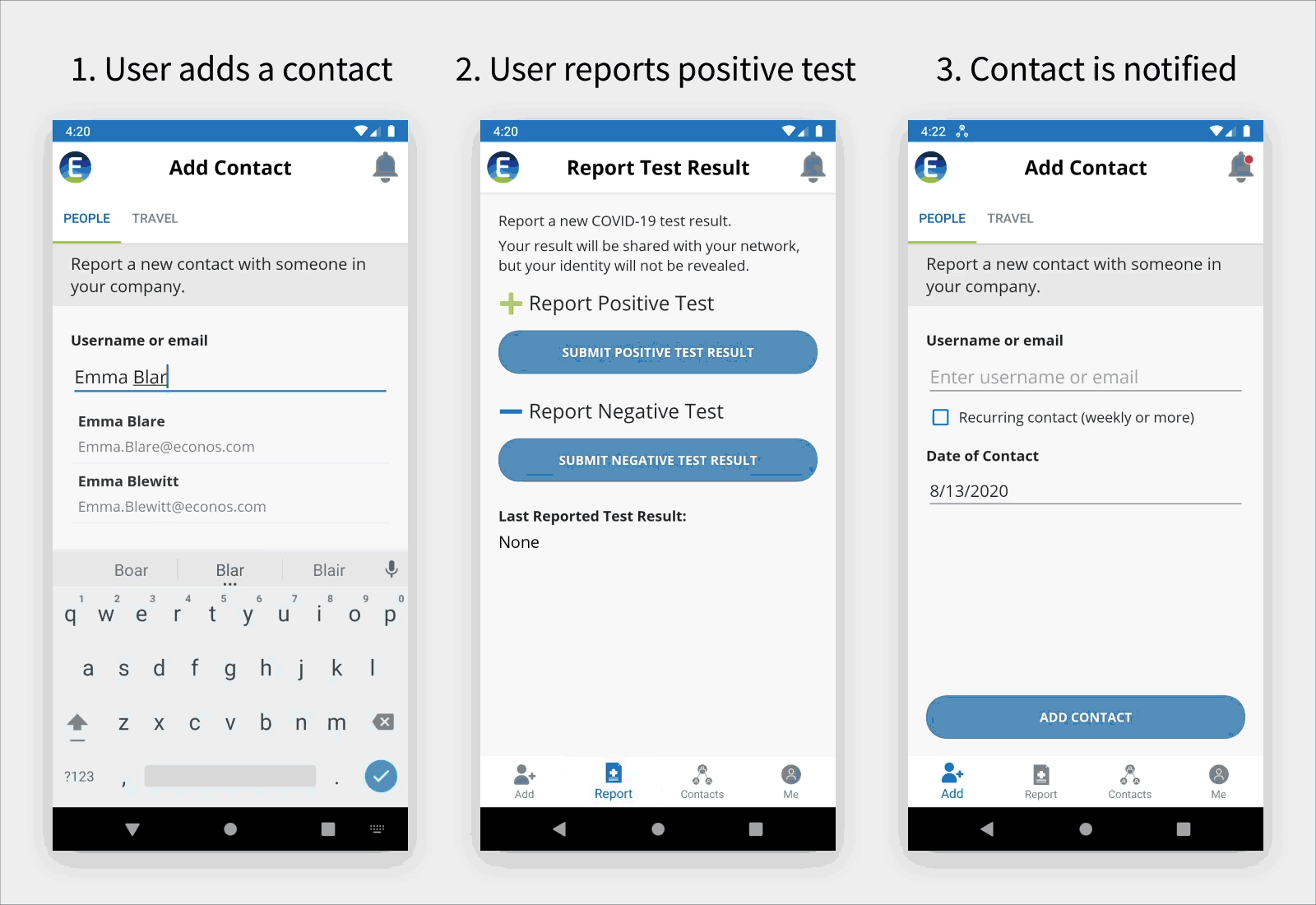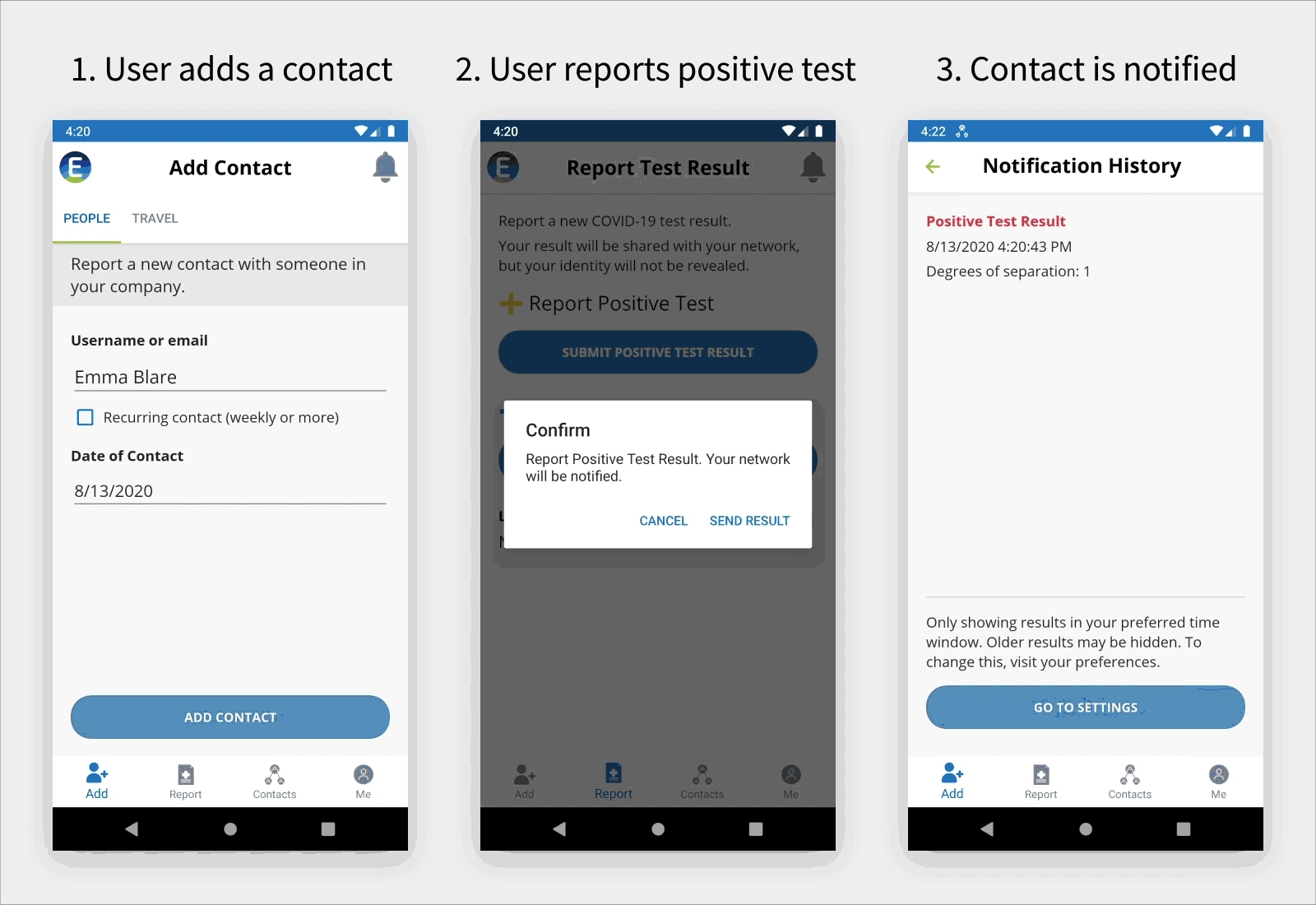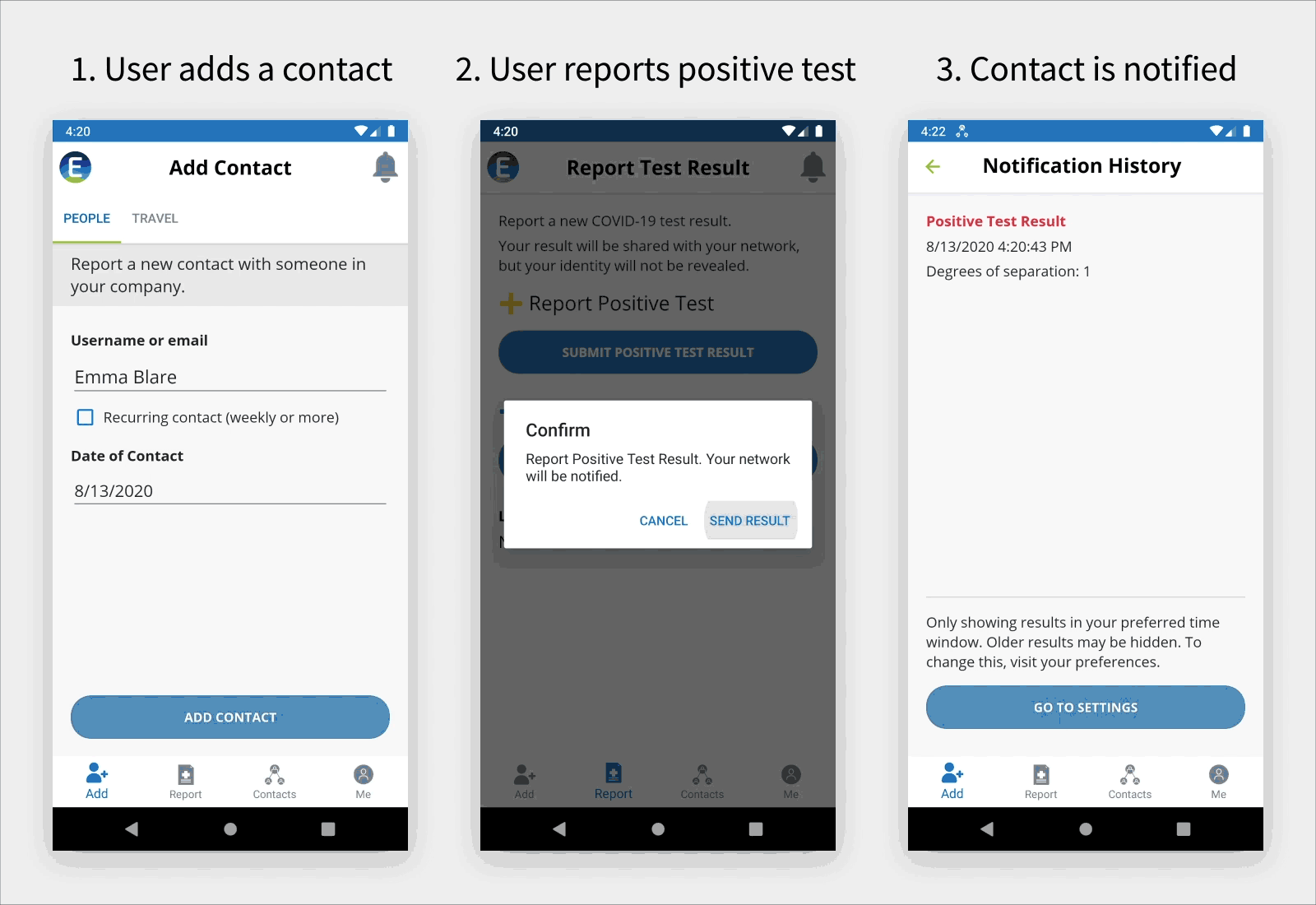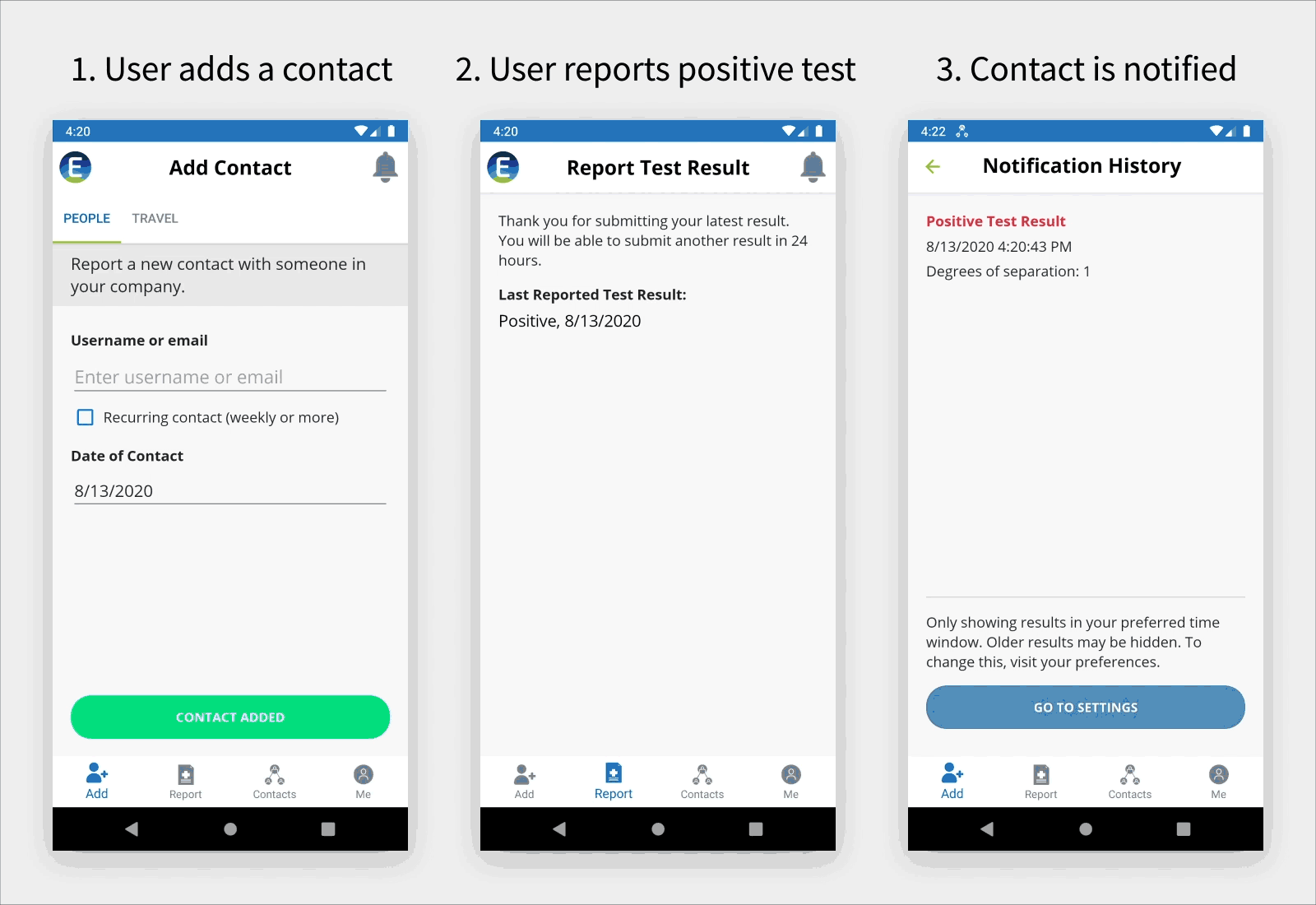
Using Aggregate Statistics to Spot Outbreaks
The streaming service has the built-in capability to aggregate state data from all real-time digital twins. The service then displays the results in charts which are recalculated every few seconds. These charts enable managers to identify emerging issues, such as an outbreak within a specific department or site. With this information, they can take immediate steps to contain the outbreak and minimize the number of affected employees.
To illustrate the value of aggregate statistics in boosting situational awareness, consider a hypothetical company with 30,000 employees and offices in several states across the U.S. Suppose an employee at the Texas site suddenly tests positive. This could be immediately alerted to managers with the following chart generated and continuously updated by the streaming service, which shows all employees who have tested positive:
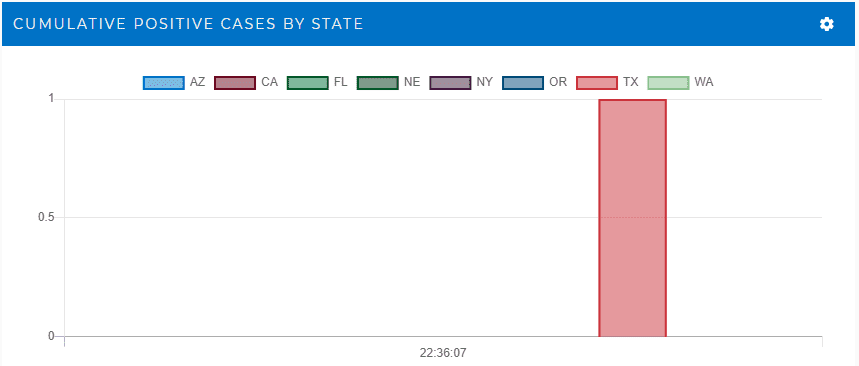
Within a few seconds, the real-time digital twins notify all points of contact. Updates to state data are immediately aggregated in another chart that shows the sites where employees have been notified of a positive contact and the number of employees affected at each site:
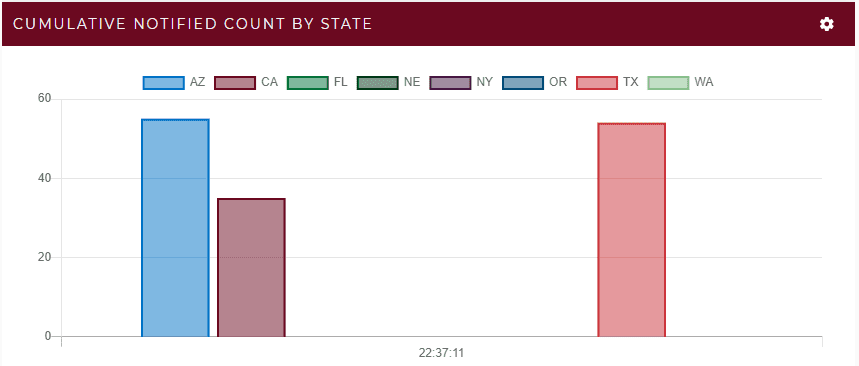
This chart shows that about 140 employees in three states were notified and possibly exposed directly or indirectly. All of these employees are then immediately quarantined to contain the possible spread of COVID-19. After an investigation by company managers, it is determined that the employee had business travel to Arizona and met with a team that subsequently had business travel to California. Instead of taking hours or days to uncover the scope of a COVID-19 exposure, contact tracing using real-time digital twins alerts managers within seconds.
The real-time digital twins can collect additional useful statistics for visualization by the streaming service. Another chart can show the average number of intermediate contacts for all notified employees, which is an indication of how widely employees have been interacting across teams. If this becomes an issue (as it is in the above example), managers can implement policies to further isolate teams. As shown below, a chart can also show the number of notified employees by department so that managers can determine whether certain departments, such as retail outlets, need stricter policies to limit exposure to COVID-19 from outside contacts.
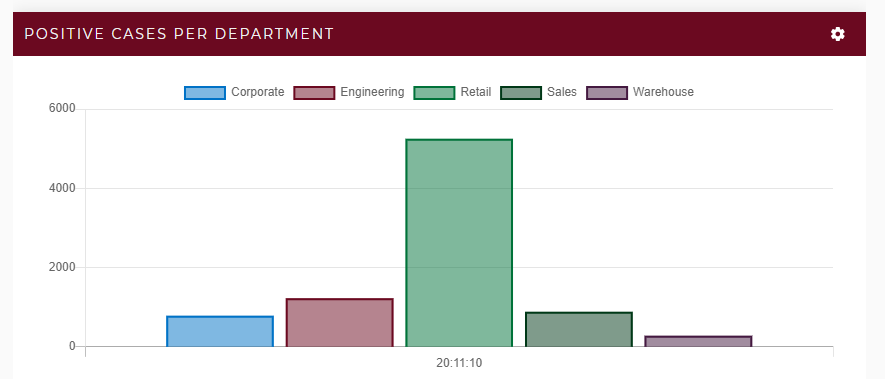
The Benefits of an Integrated Streaming Service
This contact tracing application demonstrates the power of real-time digital twins to enable fast application development with compelling benefits. Because the amount of application code is small, real-time digital twins can be quickly written and tested. (See a recent blog post which describes how to simplify debugging and testing using a mock environment prior to deployment in the cloud.) They also can be easily modified and updated.
The ScaleOut Digital Twin Streaming Service provides the execution platform so that the application code does not have to deal with message distribution, state saving, performance scaling, and high availability. It also includes support for real-time aggregate analytics and visualization integrated with the real-time digital twin model to maximize ease of use.
Compare this approach to the complexity of building out an application server farm, database, analytics application, and visualization to accomplish the same goals at higher cost and lower performance. Cobbling together these diverse technologies would require several skill sets, lengthy development time, and higher operational costs.
Summing Up
This demo contact tracing application was designed to show how companies can take advantage of their organizational structures to track contacts among employees and quickly notify all affected employees when an individual tests positive for COVID-19. By responding quickly to an exposure with immediate, comprehensive information about its extent within the company (and with community contacts), managers can limit the exposure’s impact. The application also shows how the real-time digital twin model enables a quick, agile implementation which can be easily adapted to the specific needs of a wide range of companies.
Please contact us at ScaleOut Software to learn more about this demo application for limiting the impact of COVID-19 and other ways real-time digital twins can help your company monitor and respond to fast-changing events.
The post Using Real-Time Digital Twins for Corporate Contact Tracing appeared first on ScaleOut Software.
]]>The post Developing Real-Time Digital Twins for Cloud Deployment appeared first on ScaleOut Software.
]]>
This blog post explains how a new software construct called a real-time digital twin running in a cloud-hosted service can create a breakthrough for streaming analytics. Development is fast and straightforward using standard object-oriented techniques, and the test/debug cycle is kept short by making use of a mock environment running on the developer’s workstation.
What Are Real-Time Digital Twins?
The ScaleOut Digital Twin Streaming Service offers an exciting new approach to streaming analytics in applications that track large numbers of data sources and need to maximize responsiveness and situational awareness. Examples include tracking a fleet of trucks, analyzing large numbers of banking transactions for potential fraud, managing logistics in the delivery of supplies after a disaster or during a pandemic, recommending products to ecommerce shoppers, and much more.
The key to meeting these challenges is to process incoming telemetry in the context of unique state information maintained for each individual data source. This allows application code to introspect on the dynamic behavior of each data source, maintain synthetic metrics which aid the analysis, and create alerts when conditions require. To make this possible, the Azure-based streaming service hosts a real-time digital twin for each data source. It describes properties to be maintained for the data source and an application-defined algorithm for processing incoming messages from the data source.
Digital twin models used in product lifecycle management (PLM) or in IoT device modeling (for example, Azure Digital Twins) just describe the properties of physical entities, usually to allow querying by business processes. In contrast, real-time digital twins analyze incoming telemetry from each data source and track changes in its state. Their analysis determines whether immediate action needs to be taken to resolve an issue (or identify an opportunity). Real-time digital twins typically employ domain-specific knowledge to analyze incoming messages, maintain relevant state information, and trigger alerts.
For example, a PLM digital twin of a truck engine might describe the properties of the engine, such as its temperature and oil pressure. A real-time digital twin would take the next step by hosting a predictive analytics algorithm that analyzes changes in these properties. It could use dynamic information about recent usage and service history to determine whether a failure is imminent and the driver should be alerted, as shown below:
Implementing Real-Time Digital Twins
Real-time digital twins are designed to be easy to develop and modify. They make use of standard object-oriented concepts and languages (such as C#, Java, and JavaScript). A real-time digital twin consists of two components implemented by the application: a state object which defines the properties to be maintained for each data source, and a message-processing method, which defines an algorithm for analyzing incoming messages from a specific data source. The method contains domain-specific knowledge, such as a predictive analytics algorithm for truck engines. These two components are referred to as a real-time digital twin model, which serves as a template for creating instances, one for every data source.
To simplify development, the ScaleOut Digital Twin Streaming Service provides base classes that can be used to create real-time digital twins and then submit them to the cloud service for execution, as illustrated in the following diagram:
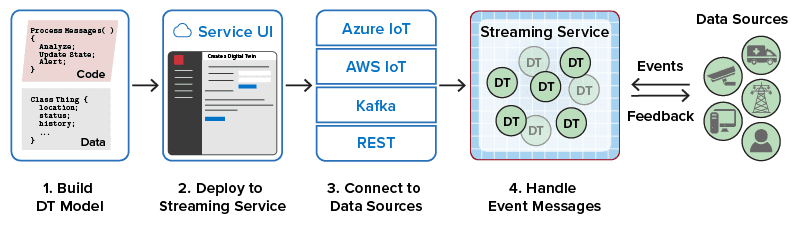
Once the real-time digital twin model has been uploaded, the streaming service automatically creates an instance for every data source and forwards incoming messages from that data source to the instance for processing. Data sources can send messages to their corresponding real-time digital twin instances (and receive replies) using message hubs or a built-in REST service.
Debugging with a Mock Environment
Although these models are simple and easy to build, the number of steps in the deployment process can make it cumbersome to catch coding errors in the early stages of model development. To address this challenge and enable rapid model testing within a controlled environment (for example, within Visual Studio running on a development workstation), the streaming service provides an alternative execution platform, called the mock environment, which can be targeted during development. This environment runs standalone on a workstation and allows an application to create a limited number of real-time digital twin instances. It also provides an API for sending messages to instances and for receiving replies using the same message-exchange protocol that would be used with the cloud-based REST service.
The mock development environment is shown below:
Once a model has been created, it can be tested using a client test program that sends messages that simulate the behavior of one or more data sources. This exercises the model’s code and surfaces issues and exceptions, which can be readily examined and resolved in a controlled environment. When the model behaves as expected, it can then be deployed to the streaming service for execution with live data sources. Note that the model’s code can log messages, which are available for reading in the mock environment and are displayed in the streaming service’s web UI after the model is deployed.
Summing Up
Real-time digital twins offer an important new tool for analyzing telemetry streams from large numbers of data sources, providing immediate feedback for each data source, and maintaining real-time aggregate statistics that boost situational awareness. Unlike PLM-style digital twins, which host the properties of a physical data source for downstream analysis, real-time digital twins provide a means to analyze and respond to a data source’s telemetry within milliseconds, while exposing aggregate trends within seconds. Their functionality fills an important gap in streaming analytics, namely tracking thousands or even a million data sources with fast, individualized feedback.
Amazingly, the power of real-time digital twins can be harnessed with a small amount of application code that contains domain-specific knowledge. The streaming service takes care of all the complexities of message delivery, accessing state data, scaling for thousands of data sources, and high availability. By using a mock development environment, application developers can quickly create, debug, and test real-time digital models prior to their deployment in production. This powerful new approach to streaming analytics solves an important unmet need and offers an impressive combination of power and ease of use.
For detailed information on building real-time digital twin models and using a mock environment, please consult the ScaleOut Digital Twin Streaming Service User Guide.
The post Developing Real-Time Digital Twins for Cloud Deployment appeared first on ScaleOut Software.
]]>The post Why Use “Real-Time Digital Twins” for Streaming Analytics? appeared first on ScaleOut Software.
]]>
What Problems Does Streaming Analytics Solve?
To understand why we need real-time digital twins for streaming analytics, we first need to look at what problems are tackled by popular streaming platforms. Most if not all platforms focus on mining the data within an incoming message stream for patterns of interest. For example, consider a web-based ad-serving platform that selects ads for users and logs messages containing a timestamp, user ID, and ad ID every time an ad is displayed. A streaming analytics platform might count all the ads for each unique ad ID in the latest five-minute window and repeat this every minute to give a running indication of which ads are trending.
Based on technology from the Trill research project, the Microsoft Stream Analytics platform offers an elegant and powerful platform for implementing applications like this. It views the incoming stream of messages as a columnar database with the column representing a time-ordered history of messages. It then lets users create SQL-like queries with extensions for time-windowing to perform data selection and aggregation within a time window, and it does this at high speed to keep up with incoming data streams.
Other streaming analytic platforms, such as open-source Apache Storm, Flink, and Beam and commercial implementations such as Hazelcast Jet, let applications pass an incoming data stream through a pipeline (or directed graph) of processing steps to extract information of interest, aggregate it over time windows, and create alerts when specific conditions are met. For example, these execution pipelines could process a stock market feed to compute the average stock price for all equities over the previous hour and trigger an alert if an equity moves up or down by a certain percentage. Another application tracking telemetry from gas meters could likewise trigger an alert if any meter’s flow rate deviates from its expected value, which might indicate a leak.
What’s key about these stream-processing applications is that they focus on examining and aggregating properties of data communicated in the stream. Other than by observing data in the stream, they do not track the dynamic state of the data sources themselves, and they don’t make inferences about the behavior of the data sources, either individually or in aggregate. So, the streaming analytics platform for the ad server doesn’t know why each user was served certain ads, and the market-tracking application does not know why each equity either maintained its stock price or deviated materially from it. Without knowing the why, it’s much harder to take the most effective action when an interesting situation develops. That’s where real-time digital twins can help.
The Need for Real-Time Digital Twins
Real-time digital twins shift the application’s focus from the incoming data stream to the dynamically evolving state of the data sources. For each individual data source, they let the application incorporate dynamic information about that data source in the analysis of incoming messages, and the application can also update this state over time. The net effect is that the application can develop a significantly deeper understanding about the data source so that it can take effective action when needed. This cannot be achieved by just looking at data within the incoming message stream.
For example, the ad-serving application can use a real-time digital twin for each user to track shopping history and preferences, measure the effectiveness of ads, and guide ad selection. The stock market application can use a real-time digital twin for each company to track financial information, executive changes, and news releases that explain why its stock price starts moving and filter out trades that don’t fit desired criteria.
Also, because real-time digital twins maintain dynamic information about each data source, applications can aggregate this highly curated data instead of just aggregating data in the data stream. This gives users deeper insights into the overall state of all data sources and boosts “situational awareness” that is hard to maintain by just looking at the message stream.
An Example
Consider a trucking fleet that manages thousands of long-haul trucks on routes throughout the U.S. Each truck periodically sends telemetry messages about its location, speed, engine parameters, and cargo status (for example, trailer temperature) to a real-time monitoring application at a central location. With traditional streaming analytics, personnel can detect changes in these parameters, but they can’t assess their significance to take effective, individualized action for each truck. Is a truck stopped because it’s at a rest stop or because it has stalled? Is an out-of-spec engine parameter expected because the engine is scheduled for service or does it indicate that a new issue is emerging? Has the driver been on the road too long? Does the driver appear to be lost or entering a potentially hazardous area?
The use of real-time digital twins provides the context needed for the application to answer these questions as it analyzes incoming messages from each truck. For example, it can keep track of the truck’s route, schedule, cargo, mechanical and service history, and information about the driver. Using this information, it can alert drivers to impending problems, such as road blockages, delays or emerging mechanical issues. It can assist lost drivers, alert them to erratic driving or the need for rest stops, and help when changing conditions require route updates.
The following diagram shows a truck communicating with its associated real-time digital twin. (The parallelogram represents application code.) Because the twin holds unique contextual data for each truck, analysis code for incoming messages can provide highly focused feedback that goes well beyond what is possible with traditional streaming analytics:
As illustrated below, the ScaleOut Digital Twin Streaming Service runs as a cloud-hosted service in the Microsoft Azure cloud to provide streaming analytics using real-time digital twins. It can exchange messages with thousands of trucks across the U.S., maintain a real-time digital twin for each truck, and direct messages from that truck to its corresponding twin. It simplifies application code, which only needs to process messages from a given truck and has immediate access to dynamic, contextual information that enhances the analysis. The result is better feedback to drivers and enhanced overall situational awareness for the fleet.
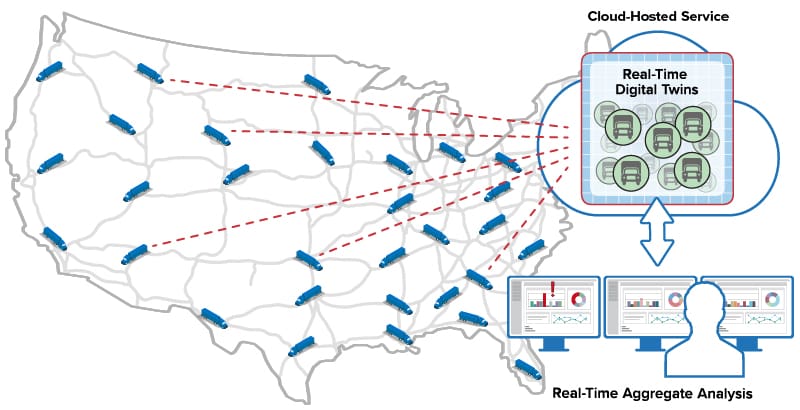
Lower Complexity and Higher Performance
While the functionality implemented by real-time digital twins can be replicated with ad hoc solutions that combine application servers, databases, offline analytics, and visualization, they would require vastly more code, a diverse combination of skill sets, and longer development cycles. They also would encounter performance bottlenecks that require careful analysis to measure and resolve. The real-time digital twin model running on ScaleOut Software’s integrated execution platform sidesteps these obstacles.
Scaling performance to maintain high throughput creates an interesting challenge for traditional streaming analytics platforms because the work performed by their task pipelines does not naturally map to a set of processing cores within multiple servers. Each pipeline stage must be accelerated with parallel execution, and some stages require longer processing time than others, creating bottlenecks in the pipeline.
In contrast, real-time digital twins naturally create a uniformly large set of tasks that can be evenly distributed across servers. To minimize network overhead, this mapping follows the distribution of in-memory objects within ScaleOut’s in-memory data grid, which holds the state information for each twin. This enables the processing of real-time digital twins to scale transparently without adding complexity to either applications or the platform.
Summing Up
Why use real-time digital twins? They solve an important challenge for streaming analytics that is not addressed by other, “pipeline-oriented” platforms, namely, to simultaneously track the state of thousands of data sources. They use contextual information unique to each data source to help interpret incoming messages, analyze their importance, and generate feedback and alerts tailored to that data source.
Traditional streaming analytics finds patterns and trends in the data stream. Real-time digital twins identify and react to important state changes in the data sources themselves. As a result, applications can achieve better situational awareness than previously possible. This new way of implementing streaming analytics can be used in a wide range of applications. We invite you to take a closer look.
The post Why Use “Real-Time Digital Twins” for Streaming Analytics? appeared first on ScaleOut Software.
]]>The post The Power of Integrated Analytics Within an IMDG appeared first on ScaleOut Software.
]]>
In-Memory Data Grids for Fast-Changing Data
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. Typical uses include storing session-state and ecommerce shopping carts, product descriptions, airline reservations, financial portfolios, news stories, online learning data, and many others.
From its inception, the design philosophy behind ScaleOut StateServer has been to simultaneously maximize both performance and ease of use. Because IMDGs have complex internal mechanisms, they need to automate them as much as possible so that the developer can just focus on application concerns and not on the inner workings of the IMDG. For this reason, the product incorporates features such as automatic discovery of servers, transparent load-balancing when servers are added to the cluster or removed, automatic data replication for high availability with transparent placement of replicas, quorum-based updating of replicas to ensure consistency, integrated client libraries, and coherent client-side caching. The net effect is that applications maintain a straightforward view of the IMDG as a unified key/value store for serialized application objects.
The Challenges with Parallel Queries
Although IMDGs are optimized for key-based access, applications often need to retrieve groups of objects with matching properties. For example, if an application is storing shopping carts, it might be useful to find all shopping carts with a total value that exceeds a specified threshold so that these shoppers can be given special attention. To this end, ScaleOut StateServer incorporates a property-based, distributed query API that returns a collection of matching objects. To simplify development for .NET applications, it uses Microsoft’s language integrated query (LINQ) to specify queries. (Java applications use a similar mechanism.)
Queries in an IMDG can create interesting performance challenges. Because IMDGs have highly scalable storage capacity, they can easily return large numbers of matching objects to the client application, and this leads to network bottlenecks transferring large amounts of data from the IMDG back to the client. Once all objects are delivered, the client is then faced with the task of analyzing potentially huge numbers of objects. This can saturate the client’s CPU and delay responses, as illustrated in the following diagram:
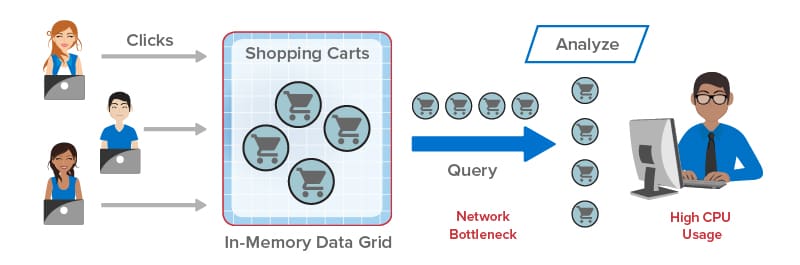
ScaleOut StateServer Pro: Integrated Data Analytics
To address these challenges, ScaleOut Software has introduced ScaleOut StateServer Pro, an advanced version of ScaleOut StateServer that integrates data analytics within the IMDG. Instead of querying objects from the IMDG and analyzing them in the client, applications can now simply run this analysis within the IMDG itself using APIs available in ScaleOut StateServer Pro. Because all the work is performed with the IMDG, this has the two-fold advantage of offloading both the network and the client’s CPU. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
Take a look at how integrated data analytics can help client applications. In the following illustration, the client library sends the application’s analysis method (“Analyze”) to the IMDG for execution in parallel on all shopping carts selected by a query. The results are combined within the IMDG and returned to the application:
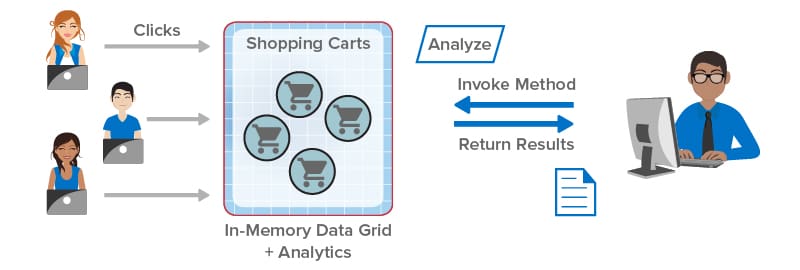
Keeping with the design philosophy of maximizing both performance and ease of use, ScaleOut StateServer Pro lets developers easily construct data analytics by specifying an object-oriented method that analyzes each matching object selected by a query and a second method for combining the results. In .NET applications, this data-parallel execution structure can be described using a distributed version of Microsoft’s popular Parallel.ForEach API, which ScaleOut StateServer Pro integrates with LINQ query. Application code is automatically shipped by the client library to the IMDG for execution and runs fully in parallel across all servers for maximum performance.
Consider the above example of querying shopping carts exceeding a threshold value. Suppose the application’s goal is to periodically analyze high value shopping carts to make upsell offers based on the contents of each cart. Instead of querying the IMDG and returning thousands of shopping carts to the client, the application can implement a method which analyzes these carts within the IMDG to determine which carts should receive upsell offers (and possibly determine which upsell offers to make). This analysis runs in parallel within the IMDG and then returns its results to the client for further action. This dramatically reduces the workload on the network and client, and it ensures consistently high performance.
Summing Up: Extracting Maximum Value from an IMDG
Since their inception, IMDGs have to a large extent been underutilized by viewing them as passive key/value stores. Because they are actually designed as a data-parallel execution platform, they can do much more than just store and serve memory-hosted, live data. They also can perform analysis quickly and efficiently — where the data lives.
Taking full advantage of this powerful capability requires just a shift in thinking about where application work should be performed. In many cases, it’s a much better choice to analyze data within the IMDG instead of transferring it to the client for analysis. ScaleOut StateServer Pro makes it easy to do just that, and it delivers fast, scalable performance. Now developers can finally extract full value from their IMDGs.
The post The Power of Integrated Analytics Within an IMDG appeared first on ScaleOut Software.
]]>The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times. For more than two decades, the answer to this challenge has proven to be a technology called in-memory computing.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers. Assuming bottlenecks are avoided, this enables transparent throughput scaling that matches an increase in workload, which in turn keeps response times low for users. It can also take advantage of the elastic computing resources available in cloud infrastructures to quickly and cost-effectively scale throughput to meet changes in demand.
Harnessing the power of in-memory computing requires software platforms that can make in-memory computing’s scalability readily available to applications using APIs while hiding the complexity of its implementation. Emerging in the early 2000s, the first such platforms provided distributed caching on clustered servers with straightforward APIs for storing and retrieving in-memory objects. When first introduced, distributed caching offered a breakthrough for applications by storing fast-changing data in memory on a server cluster for consistently fast response times, while simultaneously offloading database servers that would otherwise become bottlenecked. For example, ecommerce applications adopted distributed caching to store session-state, shopping carts, product descriptions, and other data that shoppers need to be able to access quickly.
Software platforms for distributed caching, such as ScaleOut StateServer®, which was introduced in 2005, hide internal mechanisms for cluster membership, throughput scaling, and high availability to take full advantage of the cluster’s scalable memory without adding complexity to applications. They transparently distribute stored objects across the cluster’s servers and ensure that data is not lost if a server or network component fails.
As distributed caching has evolved over the last two decades, additional mechanisms for in-memory computing have been incorporated to take advantage of the computing power available in the server cluster. Parallel query enables stored objects on all servers to be scanned simultaneously to retrieve objects with desired properties. Data-parallel computing analyzes objects on the server cluster to extract and report patterns of interest; it scales much better than parallel query by avoiding network bottlenecks and by using the cluster’s computing resources.
Most recently, stream-processing has been implemented with in-memory computing to simultaneously analyze telemetry from thousands or even millions of data sources and track dynamic state information for each data source. ScaleOut Software’s real-time digital twin model provides straightforward APIs for implementing stream-processing applications within its ScaleOut Digital Twin Streaming Service, an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins. Each step in the evolution has built on the previous one to add new capabilities that take advantage of the scalable computing power and fast data access that in-memory computing enables.
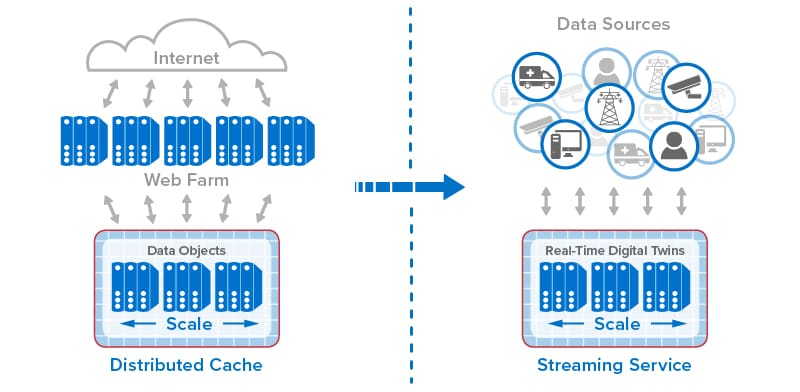
For ecommerce applications, this evolution has created new capabilities that dramatically improve the experience for online shoppers. Instead of just passively hosting session-state and shopping carts, online applications now can mine shopping carts for dynamic trends to evaluate the effectiveness of product descriptions and marketing programs (such as flash sales). They can also employ real-time digital twins or similar techniques to track each shopper’s behavior and make recommendations. By analyzing a click-stream of product selections in the context of knowledge of a shopper’s preferences and demographics, an ecommerce site can make highly focused recommendations to assist the shopper.
For example, one of ScaleOut Software’s customers recently upgraded from just using distributed caching to scale its ecommerce application. This customer now incorporates stream-processing capabilities using ScaleOut StreamServer® to capture click-streams and score users so that its web site can make more effective real-time offers.
The following diagram illustrates how the evolution of in-memory computing has enhanced the online experience for ecommerce shoppers by providing in-the-moment suggestions:
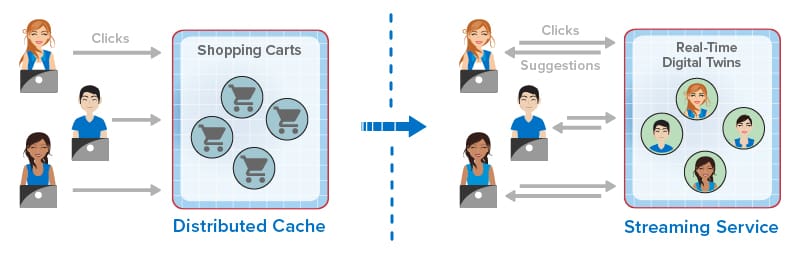
Starting with its development for parallel supercomputing in the late 1990s and evolving into its latest form as a cloud-based service, in-memory computing has offered powerful, software based APIs for building applications that serve large populations of users and data sources. It has helped assure that these applications deliver predictably fast performance and scale to meet the demands of growing workloads. In the next few years, we should continued innovation from in-memory computing to help ecommerce and other applications maintain their competitive edge.
The post The Amazing Evolution of In-Memory Computing appeared first on ScaleOut Software.
]]>The post Using Real-Time Digital Twins for Aggregate Analytics appeared first on ScaleOut Software.
]]>thousands of data sources.
When analyzing telemetry from a large population of data sources, such as a fleet of rental cars or IoT devices in “smart cities” deployments, it’s difficult if not impossible for conventional streaming analytics platforms to track the behavior of each individual data source and derive actionable information in real time. Instead, most applications just sift through the telemetry for patterns that might indicate exceptional conditions and forward the bulk of incoming messages to a data lake for offline scrubbing with a big data tool such as Spark.
Maintain State Information for Each Data Source
An innovative new software technique called “real-time digital twins” leverages in-memory computing technology to turn the Lambda model for streaming analytics on its head and enable each data source to be independently tracked and responded to in real time. A real-time digital twin is a software object that encapsulates dynamic state information for each data source combined with application-specific code for processing incoming messages from that data source. This state information gives the code the context it needs to assess the incoming telemetry and generate useful feedback within 1-3 milliseconds.
For example, suppose an application analyzes heart rate, blood pressure, oxygen saturation, and other telemetry from thousands of people wearing smart watches or medical devices. By holding information about each user’s demographics, medical history, medications, detected anomalies, and current activity, real-time digital twins can intelligently assess this telemetry while updating their state information to further refine their feedback to each person. Beyond just helping real-time digital twins respond more effectively in the moment, maintaining context improves feedback over time.
Use State Information for Aggregate Analytics
State information held within real-time digital twins also provides a repository of significant data that can be analyzed in aggregate to spot important trends. With in-memory computing, aggregate analysis can be performed continuously every few seconds instead of waiting for offline analytics in a data lake. In this usage, relevant state information is computed for each data source and updated as telemetry flows in. It is then repeatedly extracted from all real-time digital twins and aggregated to highlight emerging patterns or issues that may need attention. This provides a powerful tool for maximizing overall situational awareness.
Consider an emergency monitoring system during the COVID-19 crisis that tracks the need for supplies across the nation’s 6,100+ hospitals and attempts to quickly respond when a critical shortage emerges. Let’s assume all hospitals send messages every few minutes to this system running in a central command center. These messages provide updates on various types and amounts of shortages (for example, of PPE, ventilators, and medicines) that the hospitals need to quickly rectify. Using state information, a real-time digital twin for each hospital can both track and evaluate these shortages as they evolve. It can look at key indicators, such as the relative importance of each supply type and the rate at which the shortages are increasing, to create a dynamic measure of urgency that the hospital receive attention from the command center. All of this data is continuously updated within the real-time digital twin as messages arrive to give personnel the latest status.
Aggregate analysis can then compare this data across all hospitals by region to identify which regions have the greatest immediate need and track how fast and where overall needs are evolving. Personnel can then query state information within the real-time digital twins to quickly determine which specific hospitals should receive supplies and what specific supplies should be immediately delivered to them. Using real-time digital twins, all of this can be accomplished in seconds or minutes.
This analysis flow is illustrated in the following diagram:
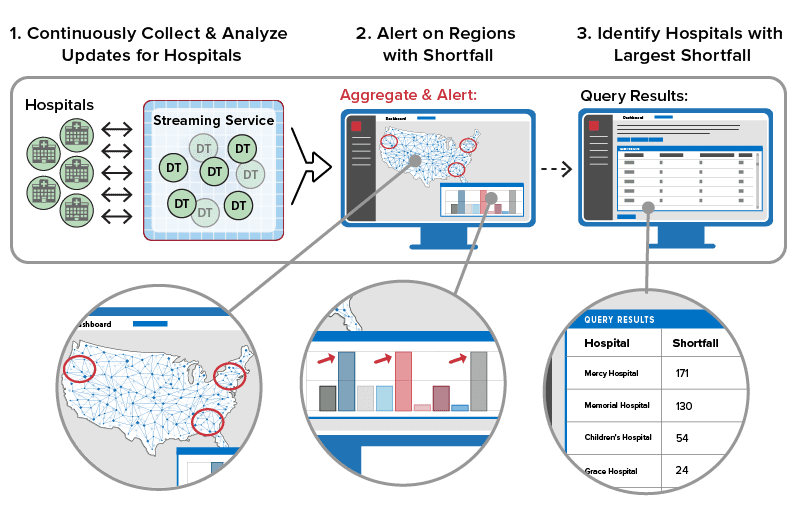
As this example shows, real-time digital twins provide both a real-time filter and aggregator of the data stream from each data source to create dynamic information that is continuously extracted for aggregate analysis. Real-time digital twins also track detailed information about the data source that can be queried to provide a complete understanding of evolving conditions and enable appropriate action.
Numerous Applications Need Real-Time Monitoring
This new paradigm for streaming analytics can be applied to numerous applications. For example, it can be used in security applications to assess and filter incoming telemetry (such as likely false positives) from intrusion sensors and create an overall likelihood of a genuine threat from a given location within a large physical or cyber system. Aggregate analysis combined with queries can quickly evaluate the overall threat profile, pinpoint the source(s), and track how the threat is changing over time. This information enables personnel to assess the strategic nature of the threat and take the most effective action.
Likewise, disaster-recovery applications can use real-time digital twins to track assets needed to respond to emergencies, such as hurricanes and forest fires. Fleets of rental cars or trucks can use real-time digital twins to track vehicles and quickly identify issues, such as lost drivers or breakdowns. IoT applications can use real-time digital twins to implement predictive analytics for mission-critical devices, such as medical refrigerators. The list goes on.
Summing Up: Do More in Real Time
Conventional streaming analytics only attempt to perform superficial analysis of aggregated data streams and defer the bulk of analysis to offline processing. Because of their ability to maintain dynamic, application-specific information about each data source, real-time digital twins offer breathtaking new capabilities to track thousands of data sources in real time, provide intelligent feedback, and combine this with immediate, highly focused aggregate analysis. By harnessing the scalable power of in-memory computing, real-time digital twins are poised to usher in a new era in streaming analytics.
We invite you to learn more about the ScaleOut Digital Twin Streaming Service, which is available for evaluation and production use today.
The post Using Real-Time Digital Twins for Aggregate Analytics appeared first on ScaleOut Software.
]]>The post Announcing the ScaleOut Digital Twin Streaming Service™ appeared first on ScaleOut Software.
]]>, and it’s now available for production use. Sign up to use the service here.
A major challenge for stream-processing applications that track numerous data sources in real time is to analyze telemetry relevant to each specific data source and combine this with dynamic, contextual information about the data source to enable immediate action when necessary. For example, heart-rate telemetry from a smart watch cannot be effectively evaluated in isolation. Instead, it needs to be combined with knowledge of each person’s age, health, medications, and activity to determine when an alert should be generated.
A second and equally daunting challenge for live systems is to maintain real-time situational awareness about the state of all data sources so that strategic responses can be implemented, especially when a rapid sequence of events is unfolding. Whether it’s a rental car fleet with 100K vehicles on the road or a power grid with 40K nodes subject to outages, system managers need to quickly identify the scope of emerging problems and rapidly focus resources where most needed.
Traditional platforms for streaming analytics attempt to look at the entire telemetry pipeline using techniques such as SQL query to uncover and act on patterns of interest. But this approach is complex and leads to superficial analysis in real time, forcing telemetry to be logged into a data lake for later analysis using Spark or other tools. How do you trigger an alert to the wearer of a smart watch at the exact moment that the combination of telemetry fluctuations and knowledge about the individual’s health indicate that an alert is needed?
The key to creating straightforward stream-processing applications that can deal with these challenges lies in a software concept called the “real-time digital twin model.” Borrowed from its use in the field of product life-cycle management, real-time digital twins host application code that analyzes incoming telemetry (event messages) from each individual data source and maintains dynamically evolving information about the data source. This approach refactors and simplifies application code (which can be written in standard Java, C#, or JavaScript) to just focus on a single data source, introspect deeply, and better predict important events.
The following diagram illustrates how the ScaleOut Digital Twin Streaming Service hosts real-time digital twins that receive telemetry from individual data sources and send responses, including commands and alerts:
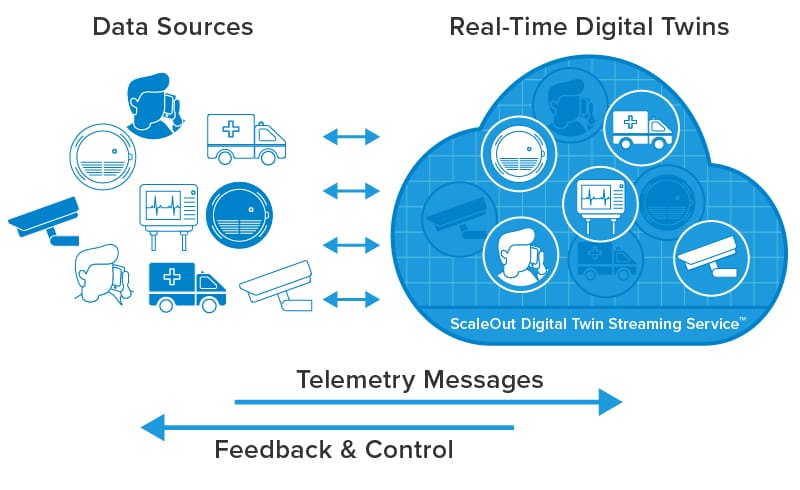
Because real-time digital twins maintain and dynamically update key information about each data source, aggregate analytics — essentially, continuous queries — can continuously look for patterns in this curated data instead of in just the raw telemetry. This enables immediate, focused insights that enhance situational awareness. For example, the streaming service can generate a bar chart every few seconds to aggregate and highlight alerts by region generated by examining properties of real-time digital twins for thousands of data sources:
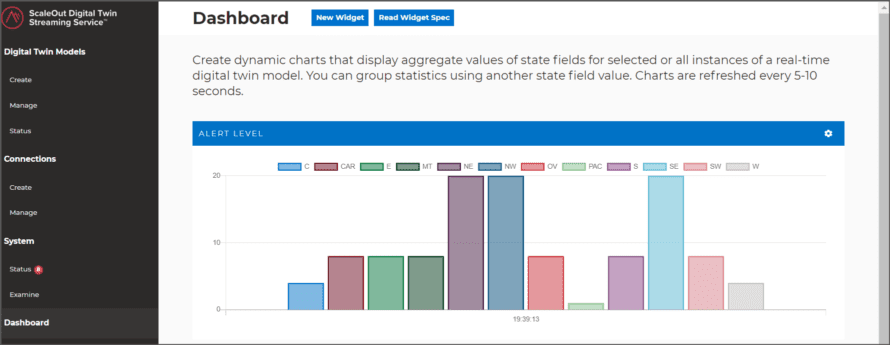
The ScaleOut Digital Twin Streaming Service plugs into popular event hubs, such as Azure IoT Hub, AWS IoT Core, and Kafka, to extract event messages and forward them to real-time digital twin instances, one for each data source. It then triggers application code to process the messages and gives it immediate access to memory-based contextual information for the data source. Application code can generate alerts, command devices, update the contextual information, and read or update databases as needed. This code can be thought of as similar to a serverless function with the major distinction that it is automatically supplied contextual information and does not have to maintain it in an external data store.
This highly scalable cloud service is designed to simultaneously and cost-effectively track telemetry from millions of data sources and provide real-time feedback in milliseconds while simultaneously performing continuous, aggregate analytics every few seconds. A powerful UI enables fast deployment of real-time digital twin models created using the ScaleOut Digital Twin Builder software toolkit. The UI lets users build graphical widgets which create and chart aggregate statistics. Under the floor, a powerful in-memory data grid with an integrated compute engine transparently ensures fast, predictable performance.
Given the current COVID-19 crisis, here’s a use case in which the streaming service can assist in prioritizing the distribution of critical medical supplies to the nation’s hospitals. Hospitals distributed across the United States can send status updates to the cloud service regarding their shortfall of supplies such as ventilators and personal protective equipment. Within milliseconds, a dedicated real-time digital twin instance for each hospital can analyze incoming messages to track and evaluate the need for supplies, determine the hospital’s overall shortfall, and assess the urgency for immediate action, as depicted below:
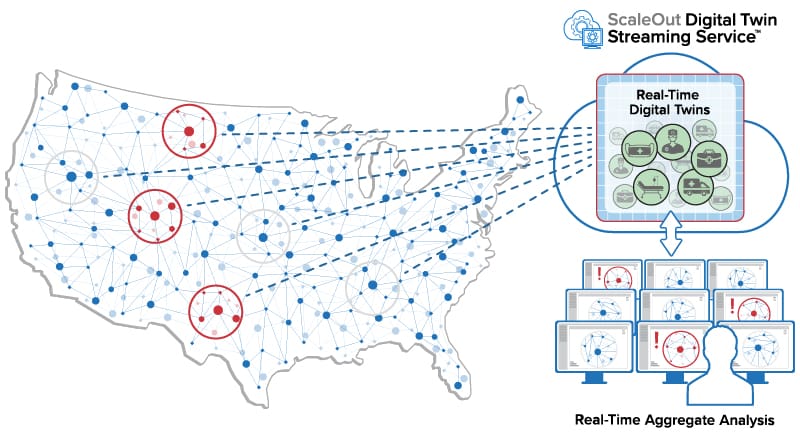
The streaming service can then simultaneously analyze these results across the population of digital twin instances to determine in seconds which regions are exhibiting the most critical shortfall. This alerts logistics managers, who can then query the digital twins to identify specific hospitals and implement a strategic response:
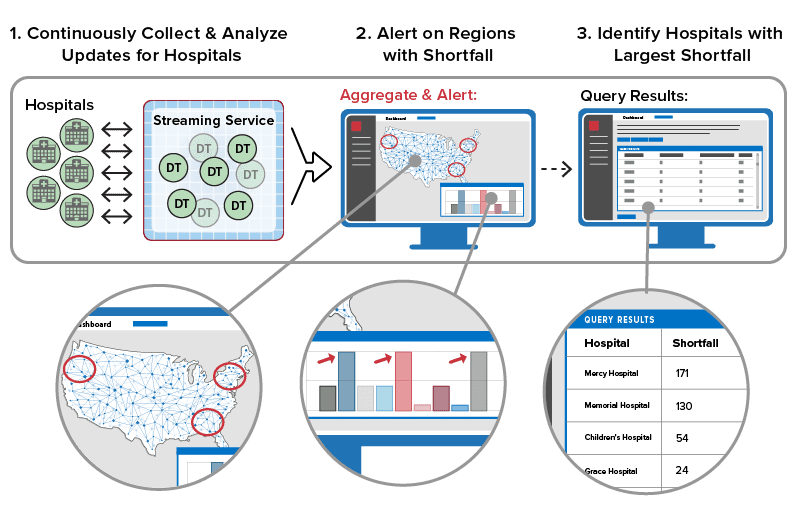
The real-time digital twin approach creates a breakthrough for application developers that both simplifies application development and enhances introspection. It’s ideal for a wide range of applications, including real-time intelligent monitoring (the example above), Industrial Internet of Things (IIoT), logistics, security and disaster recovery, e-commerce recommendations, financial services, and much more. The ScaleOut Digital Twin Streaming Service is available now. We invite interested users to contact us here to learn more.
The post Announcing the ScaleOut Digital Twin Streaming Service™ appeared first on ScaleOut Software.
]]>The post Real-Time Digital Twins Simplify Development appeared first on ScaleOut Software.
]]>Writing applications for streaming analytics can be complex and time consuming. Developers need to write code that extracts patterns out of an incoming telemetry stream and take appropriate action. In most cases, applications just export interesting patterns for visualization or offline analysis. Existing programming models make it too difficult to perform meaningful analysis in real time.
This obstacle clearly presents itself when tracking the behavior of large numbers of data sources (thousands or more) and attempting to generate individualized feedback within several milliseconds after receiving a telemetry message. There’s no easy way to separately examine incoming telemetry from each data source, analyze it in the context of dynamically evolving information about the data source, and then generate an appropriate response.
An Example: Contact Self-Tracing
For example, consider the contact self-tracing application described in a previous blog. This application tracks messages from thousands of users logging risky contacts who might transmit the COVID19 virus to them. For each user, a list of contacts must be maintained. If a user signals the app that he or she has tested positive, the app successively notifies chained contacts until all connected users have been notified.
Implementing this application requires that state information be maintained for each user (such as the contact list) and updated whenever a message from that user arrives. In addition, when an incoming message signals that a user has tested positive, contact lists for all connected users must be quickly accessed to generate outgoing notifications.
In addition to this basic functionality, it would be highly valuable to compute real-time statistics, such as the number of users reporting positive by region, the average length of connection chains for all contacts, and the percentage of connected users who also report testing positive.
A Conventional Implementation
This application cannot be implemented by most streaming analytics platforms. As illustrated below, it requires standing up a set of cooperating services (encompassing a variety of skills), including:
- A web service to process incoming messages (including notifications) by making calls to a backend database
- A database service to host state information for each user
- A backend analytics application (for example, a Spark app) that extracts information from the database, analyzes it, and exports it for visualization
- A visualization tool that displays key statistics
Implementing and integrating these services requires significant work. After that, issues of scaling and high availability must be addressed. For example, how do we keep the database service from becoming a bottleneck when the number of users and update rate grow large? Can the web front end process notifications (which involve recursive chaining) without impacting responsiveness? If not, do we need to offload this work to an application server farm? What happens if a web or application server fails while processing notifications?
Enter the Real-Time Digital Twin
The real-time digital twin (RTDT) model was designed to address these challenges and simplify application development and deployment while also tackling scaling, high availability, real-time analytics, and visualization. This model uses standard object-oriented techniques to let developers easily specify both the state information to be maintained for each data source and the code required to process incoming messages from that data source. The rest is automatically handled by the hosting platform, which makes use of scalable, in-memory computing techniques that ensure high performance and availability.
Another big plus of this approach is that the state information for each instance of an RTDT can be immediately analyzed to provide important statistics in real time. Because this live state information is held in memory distributed across of a cluster of servers, the in-memory computing platform can analyze it and report results every few seconds. There’s no need to suffer the delay and complexity of copying it out to a data lake for offline analysis using an analytics platform like Spark.
The following diagram illustrates the steps needed to develop and deploy an RTDT model using the ScaleOut Digital Twin Streaming Service, which includes built-in connectors for exchanging messages with data sources:
Implementing Contact Self-Tracing Using a Real-Time Digital Twin Model
Let’s take a look at just how easy it is to build an RTDT model for tracking users in the contact self-tracking application. Here’s an example in C# of the state information that needs to be tracked for each user:
public class UserTwin : DigitalTwinBase
{
public string Alias;
public string Email;
public string MobileNumber;
public Status CurrentStatus; // Normal, TestedPositive, or Notified
public int NumHopsIfNotified;
public List<Contact> Contacts;
public Dictionary<string, Contact> Notifiers;
}
This simple set of properties is sufficient to track each user. In additional to phone and/or email, each user’s current status (i.e., normal, reporting tested positive, or notified of a contact who has tested positive) is maintained. In case the user is notified by another contact, the number of hops to the connected user who reported tested positive is also recorded to help create statistics. There’s also a list of immediate contacts, which is updated whenever the user reports a risky interaction. Lastly, there’s a dictionary of incoming notifications to help prevent sending out duplicates.
The RTDT stream-processing platform automatically creates an instance of this state object for every user when the an account is created. The user can then send messages to the platform to either record an interaction or report having been tested positive. Here’s the application code required to process these messages:
foreach (var msg in newMessages)
{
switch (msg.MsgType)
{
case MsgType.AddContact:
newContact = new Contact();
newContact.Alias = msg.ContactAlias;
newContact.ContactTime = DateTime.UtcNow;
dt.Contacts.Add(newContact);
break;
case MsgType.SignalPositive:
dt.CurrentStatus = Status.SignaledPositive;
// signal all of our contacts that we have tested positive:
notifyMsg = new UserTwinMessage();
notifyMsg.Id = dt.Alias;
notifyMsg.MsgType = MsgType.Notify;
notifyMsg.ContactAlias = dt.Alias;
notifyMsg.ContactTime = DateTime.UtcNow;
notifyMsg.NumHops = 0;
foreach (var contact in dt.Contacts)
{
msgResult = context.SendToTwin("UserTwin", contact.Alias,
notifyMsg);
}
break;
}}
Note that when a user signals that he or she has tested positive, this code sends a Notify message to all RTDT instances corresponding to users in the contact list. Handling this message type requires one more case to the above switch statement, as follows:
case MsgType.Notify:
if (dt.CurrentStatus != Status.SignaledPositive)
dt.CurrentStatus = Status.Notified;
// if we have already heard from the root contact, ignore the message:
if (msg.ContactAlias == dt.Alias || dt.Notifiers.ContainsKey(msg.ContactAlias))
break;
// otherwise, add the notifier and signal the user:
else
{
if (dt.NumHopsIfNotified == 0)
dt.NumHopsIfNotified = msg.NumHops;
newContact = new Contact();
newContact.Alias = msg.ContactAlias;
newContact.ContactTime = msg.ContactTime;
newContact.NumHops = msg.NumHops + 1;
dt.Notifiers.Add(msg.ContactAlias, newContact);
notifyMsg = new UserTwinMessage();
notifyMsg.Id = dt.Alias;
notifyMsg.MsgType = MsgType.Notify;
notifyMsg.ContactAlias = msg.ContactAlias;
notifyMsg.ContactTime = msg.ContactTime;
notifyMsg.NumHops = msg.NumHops + 1;
msgResult = context.SendToDataSource(notifyMsg);
// finally, notify all our contacts except the root if it's a contact:
foreach (var contact in dt.Contacts)
{
if (contact.Alias != msg.ContactAlias)
msgResult = context.SendToTwin("UserTwin", contact.Alias,
notifyMsg);
}
}
break;
That’s all there is to it. The key point is that the amount of code required to implement this application is small. Compare that to standing up web, application, database, and analytics services. In addition, integrated, real-time analytics within the RTDT platform can examine state variables to easily generate and visualize key statistics. For example, the CurrentStatus property and a Region property (not shown here) can be used to determine the average number of users who have tested positive by region. Likewise, the NumHopsIfNotified property can be used to determine the average number of connections traversed to notify users.
Summing Up
There’s no doubt that it’s a daunting challenge to create streaming analytics applications that track large numbers of data sources and respond individually to each one while simultaneously generating aggregate statistics that help maintain situational awareness. As we have seen, real-time digital twins can cut through this complexity and enable powerful applications to be quickly built with minimal code. This simplicity also makes them “agile” in the sense that they can be easily modified or extended to handle evolving requirements. You can find detailed information here to help you learn more.
The post Real-Time Digital Twins Simplify Development appeared first on ScaleOut Software.
]]>